小红书技术团队推出全面评估 MLLMs 跨视频推理能力的基准测试 CrossVid,目前测试代码与数据已完全开源。

Qwen3-VL、Gemini-3 等多模态大语言模型(MLLMs)已在单视频理解领域展现出色能力,精准识别内容的同时生成精彩解说。但 AI 是否具备人类般的 "跨视频" 思考能力?例如分辨不同烹饪视频的食材处理方法、串联多个电影片段的剧情逻辑、追踪多视角录像中同一物体运动 ------ 这类能力被称为跨视频推理。
为填补该领域评估空白,小红书技术团队推出全面评估 MLLMs 跨视频推理能力的基准测试 CrossVid,目前测试代码与数据已完全开源。
论文地址:
https://arxiv.org/abs/2511.12263
论文标题:
CrossVid: A Comprehensive Benchmark for Evaluating Cross-Video Reasoning in Multimodal Large Language Models
开源代码:
https://github.com/chuntianli666/CrossVid
01、背景:从"看懂一个"到"理解一组"
在目前的视频理解研究中,绝大多数基准测试都局限于单视频分析。即便是少数涉及多视角的测试,也往往局限于同一场景的不同角度。
然而,现实世界中的视频理解需求远比这复杂。比如,在小红书这样的平台上,用户往往需要同时处理多个视频信息,即跨视频推理(Cross-Video Reasoning, CVR):
- 对比分析: 比较不同博主的探店视频,找出共同推荐的菜品。
- **时序理解:**观看一段长故事被切分成的多个片段,自行脑补中间的剧情。
- 信息聚合: 综合多个教程视频,总结出一个完整的操作步骤。
现有的评测体系无法有效衡量模型在这些复杂场景下的表现。为此,CrossVid 应运而生,旨在推动视频理解从**"单查询、单视频"** 向**"单查询、多视频"**的范式转变。
02、CrossVid是什么?首个方位CVR基准
CrossVid 是专门为评估多模态大模型在跨视频语境下时空推理能力而设计的大型测评基准。

CrossVid 的核心亮点包括:
- 数据规模宏大: 包含 5,331 个精选视频和 9,015 个高质量问答对。
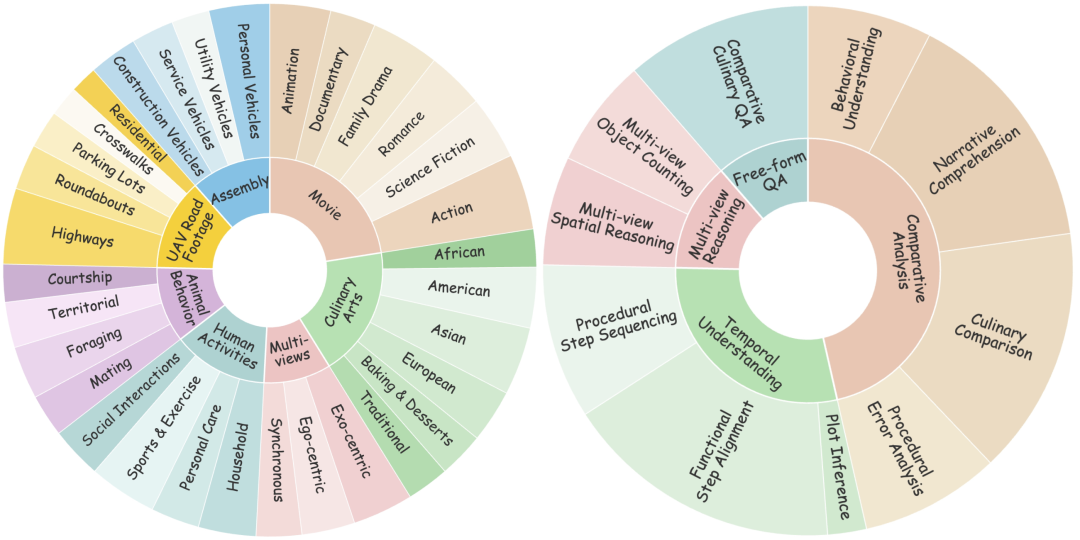
- 任务层级丰富: 设立了 4 个高层维度 (对比分析、时序理解、多视角推理、自由问答)和 10 项具体任务(如行为理解、叙事理解、烹饪对比、多视角计数等)。
- 覆盖场景广泛: 视频平均时长覆盖从短视频到长视频,涵盖 32 种题材,高度还原真实世界的复杂性。
- 严格的质量把控: 采用"半自动化标注流水线",结合 Qwen2.5-VL 和 DeepSeek-R1 生成初稿,再经过 10 位专家标注员的多轮人工清洗与校验,确保数据的高质量。
03、数据标注:高质量数据如何产生?
一个优秀的 Benchmark,数据质量是根本。然而,跨视频推理涉及到复杂的逻辑比对,单纯依赖人工编写效率太低,完全依赖 AI 生成又容易产生幻觉或逻辑漏洞。
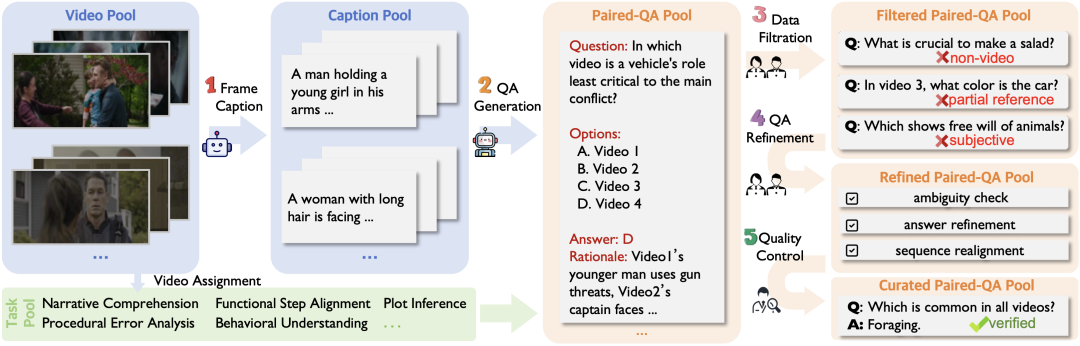
这套流程包含三大核心步骤:
1. AI 生成描述,打好基础
我们首先利用 Qwen2.5-VL-72B 对海量视频帧进行密集描述(Frame Captioning),结合原始元数据生成详尽的视觉上下文。随后,引入具备强大推理能力的 DeepSeek-R1,通过精心设计的 Prompt,让它基于这些描述生成具有挑战性的跨视频问答对。
Tips:为了减少模型"幻觉",我们在 Prompt 中强制 DeepSeek-R1 输出正确答案的推理过程,确保从问题到答案的过程是基于视频内容的正确逻辑。
2. 十位专家精修,去伪存真
AI 生成的数据只是初稿。我们组建了一支由 10 位专业标注员 组成的专家团队,对数据进行了三轮清洗:
- 粗筛(Filtration): 剔除那些"只看一个视频就能回答"的简单问题,确保所有题目都必须结合多个视频才能解出。
- **精修(Refinement):**消除歧义,优化选项。
- 防作弊设计(Anti-Shortcut): 在时序排序任务中,为了防止模型通过镜头切换的边缘"猜"出顺序,标注员对视频片段进行了时序重对齐(Temporal Realignment),强制模型必须理解视频内容的因果关系,而不是靠低级视觉特征作弊。
3. 纯手工打造,质量过关
对于对空间感知要求极高的多视角推理(Multi-view Reasoning)任务(如无人机视角下的车辆计数与定位),由于物体过小且关系复杂,目前的 AI 难以胜任。因此,这部分数据采用了全人工标注。标注员利用定制的标注工具,在同步播放的双视角视频中手动标记物体坐标和关系,确保了数据的绝对精准。
04、实验结果:AI与人类差距依然较大
为了测试当前 AI 的水平,我们在 CrossVid 上对 22 个主流 MLLMs 进行了广泛评测,包括闭源模型(如 GPT-4.1, Gemini-2.5-Pro)和开源模型(如 Qwen2.5-VL, InternVL3 等)。
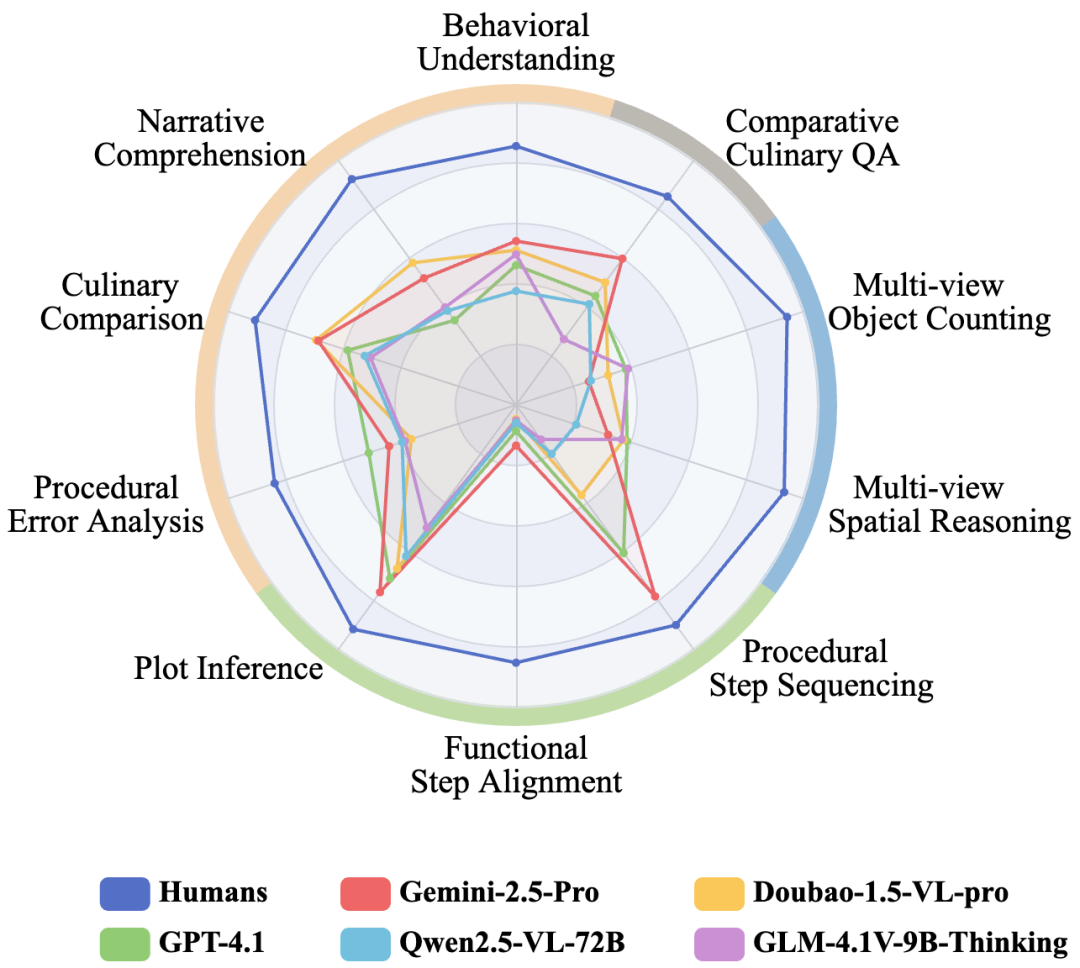
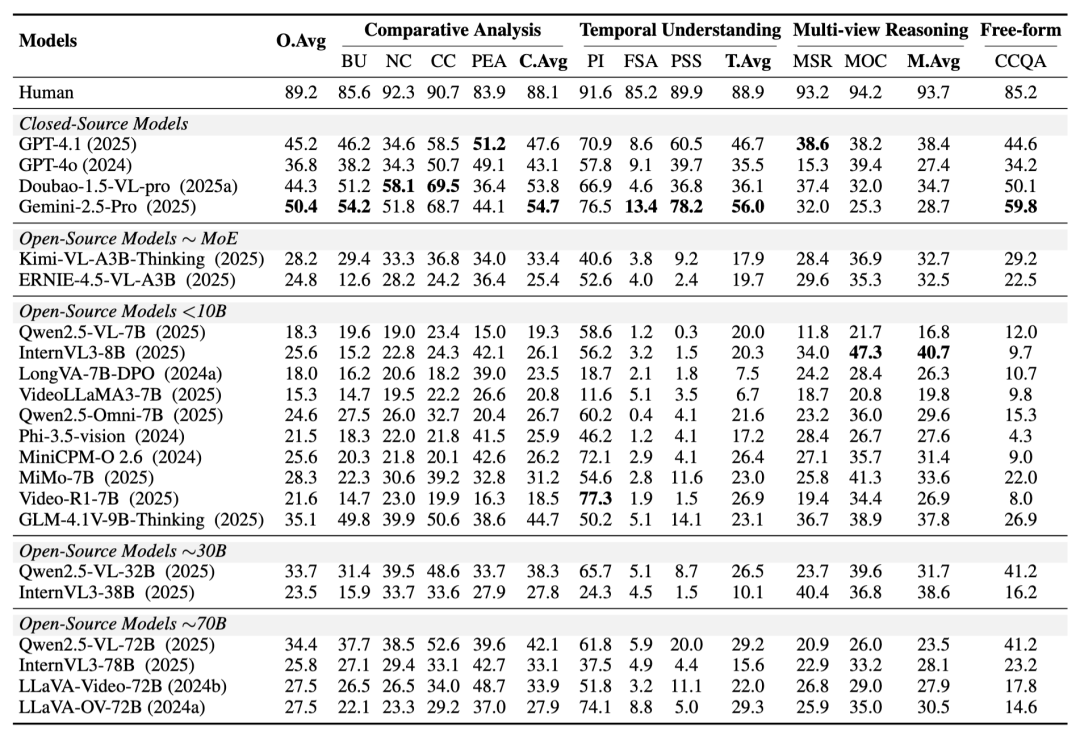
评测结果令人深思:
- 挑战性极高: 即便是在 CrossVid 上表现最好的模型 Gemini-2.5-Pro,其平均准确率也仅为 50.4%。相比之下,人类的平均准确率高达 89.2%。这表明 CVR 对现有模型来说仍是一个巨大的挑战。
- 时空推理短板明显: 在"多视角推理"和"时序理解"任务上,模型与人类的差距尤为巨大。例如在动作对齐任务中,人类准确率为 85.2%,而最强模型仅为 13.4%。
- 闭源模型暂时领先: 闭源模型总体优于开源模型,且具备"思考(Thinking)"机制的模型(如集成思维链能力的模型)表现出更强的推理潜力。
05、深度观察:大模型为什么会"翻车"
通过对模型错误的深入分析,CrossVid 团队揭示了当前 MLLMs 在处理多视频任务时的主要瓶颈:
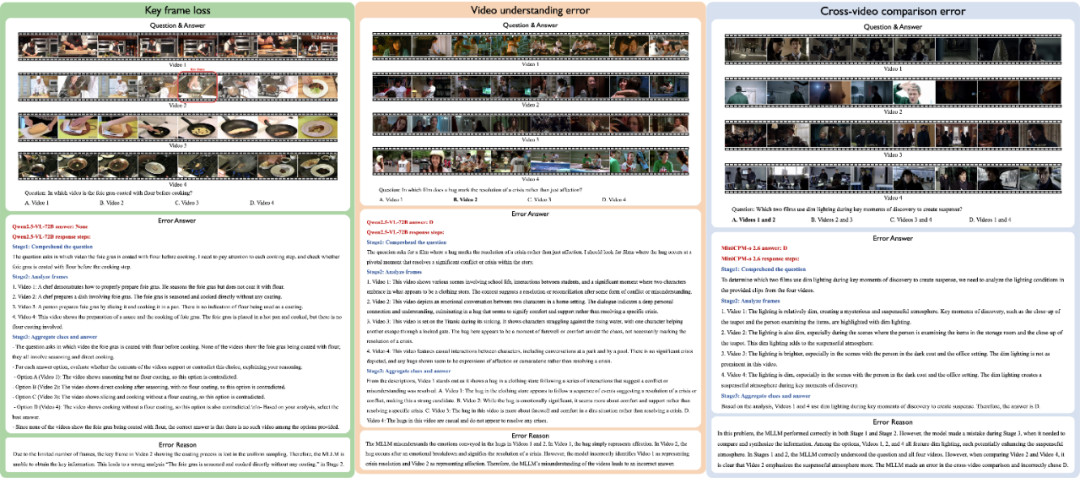
- 关键帧丢失(Key frame loss): 由于同时输入多个视频,模型被迫压缩每个视频的帧数,导致关键细节(如烹饪中是否裹了面粉)丢失。
- **视频理解错误(Video understanding error):**模型对某个单独的视频理解出现偏差,导致在进行跨视频信息整合时出现错误。
- **跨视频对比失效(Cross-video comparison error):**模型可能看懂了单个视频,但在需要将多段视频进行逻辑对比时(例如比较两部电影中"拥抱"含义的不同),往往会产生幻觉或逻辑断裂。
- 无法整合分布式证据: 真正的跨视频推理需要将分散在不同视频中的线索拼在一起,而现有模型更倾向于独立处理每个视频。
06、总结与展望
CrossVid 的提出,不仅揭示了当前多模态大模型在复杂推理任务上的局限性,也为未来的研究指明了方向。
我们认为,提升 MLLMs 的跨视频推理能力,是实现更智能的视频搜索、更精准的推荐系统以及更强大的视频创作助手的关键一步。
未来,我们期待看到:
- 更高效的长上下文处理机制,以容纳更多视频帧。
- 针对 CVR 优化的模型架构,增强多视频间的信息交互。
- 利用 CrossVid 数据集,训练出更懂"视频群"的智能模型。
CrossVid 现已全面开源,欢迎全球开发者与研究者共同挑战!
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。