1 实现架构
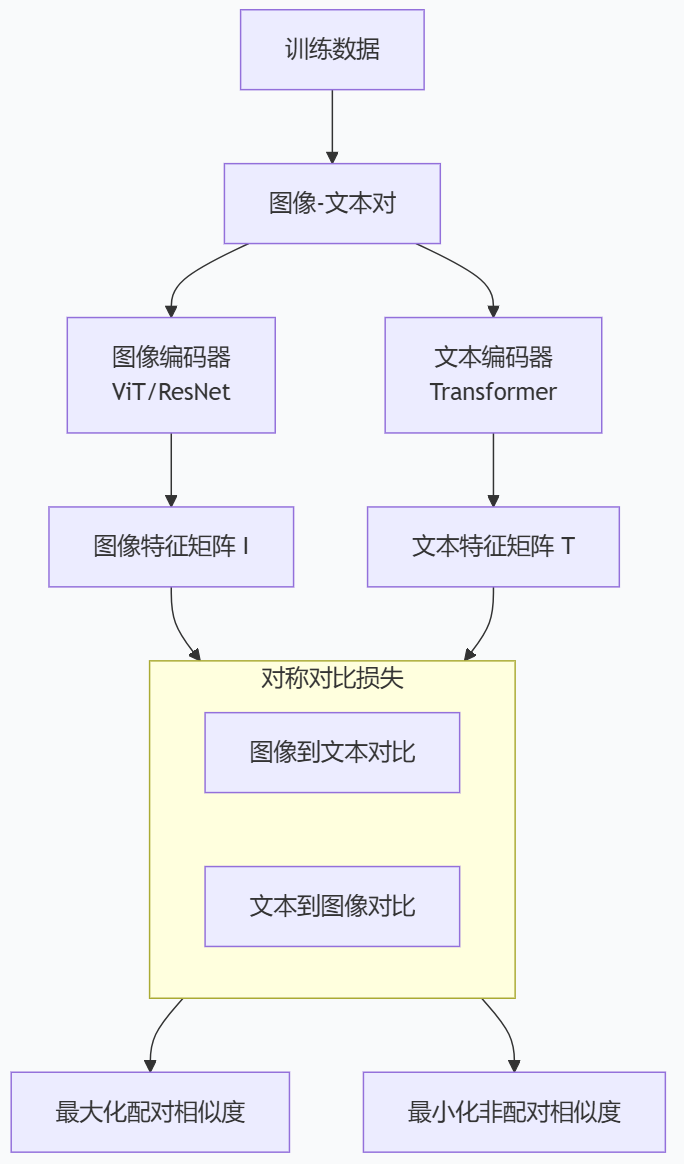
2 代码实现
伪代码表示CLIP损失
def clip_loss(image_features, text_features, temperature=0.07):
归一化特征向量
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
计算相似度矩阵
logits = (image_features @ text_features.T) / temperature
对称对比损失
labels = torch.arange(logits.shape0) # 对角线元素是正样本对
loss_i = F.cross_entropy(logits, labels) # 图像到文本
loss_t = F.cross_entropy(logits.T, labels) # 文本到图像
return (loss_i + loss_t) / 2
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import open_clip # 可以使用open_clip库
import numpy as np
from tqdm import tqdm
class LongTailCLIPClassifier:
"""
基于CLIP的长尾图像分类器,通过提示工程微调优化尾类性能
"""
def init(self, model_name='ViT-B-32', pretrained='laion400m_e32'):
加载CLIP模型和预处理
self.model, _, self.preprocess = open_clip.create_model_and_transforms(
model_name, pretrained=pretrained
)
self.tokenizer = open_clip.get_tokenizer(model_name)
冻结图像编码器,只微调文本编码器
for param in self.model.visual.parameters():
param.requires_grad = False
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device)
def create_context_prompts(self, class_names, context_length=16):
"""
为长尾分类创建可学习的提示模板
参考CoOp方法:Context Optimization for Clip
"""
初始化可学习的上下文token
假设提示模板为:上下文token 类名
n_ctx = context_length # 上下文token数量
ctx_vectors = torch.empty(n_ctx, self.model.text_projection.shape0)
nn.init.normal_(ctx_vectors, std=0.02)
self.ctx = nn.Parameter(ctx_vectors) # 可学习的参数
self.class_names = class_names
self.class_tokens = \[\]
为每个类别创建token
for class_name in class_names:
基础提示:可学习的上下文 + 类名
prompt = f"a photo of a {class_name}"
tokens = self.tokenizer(prompt).to(self.device)
self.class_tokens.append(tokens)
return self.ctx
def encode_text_with_prompts(self, class_idx=None):
"""
使用当前提示模板编码文本
"""
if class_idx is not None:
编码单个类别的提示
tokens = self.class_tokensclass_idx
将可学习的上下文token插入到合适位置
这里简化处理,实际实现需要更精细的token替换
text_features = self.model.encode_text(tokens)
return text_features
else:
编码所有类别的提示
all_features = \[\]
for tokens in self.class_tokens:
features = self.model.encode_text(tokens)
all_features.append(features)
return torch.stack(all_features).squeeze()
def predict(self, image, temperature=1.0):
"""
预测图像类别
"""
预处理图像
image_tensor = self.preprocess(image).unsqueeze(0).to(self.device)
提取图像特征
with torch.no_grad():
image_features = self.model.encode_image(image_tensor)
image_features = F.normalize(image_features, dim=-1)
提取文本特征
text_features = self.encode_text_with_prompts()
text_features = F.normalize(text_features, dim=-1)
计算相似度
logits = (image_features @ text_features.T) * torch.exp(torch.tensor(temperature))
probs = F.softmax(logits, dim=-1)
return probs.cpu().numpy()
def fine_tune_prompts(self, train_dataset, num_epochs=10, lr=1e-3):
"""
微调提示模板,特别关注尾类
"""
optimizer = torch.optim.AdamW(self.ctx, lr=lr, weight_decay=0.001)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs)
重采样平衡数据加载器(关注尾类)
sampler = self._create_balanced_sampler(train_dataset)
dataloader = DataLoader(train_dataset, batch_size=32,
sampler=sampler, num_workers=4)
self.model.train()
for epoch in range(num_epochs):
total_loss = 0
progress_bar = tqdm(dataloader, desc=f'Epoch {epoch+1}/{num_epochs}')
for images, labels in progress_bar:
images = images.to(self.device)
labels = labels.to(self.device)
提取图像特征
image_features = self.model.encode_image(images)
image_features = F.normalize(image_features, dim=-1)
使用当前提示模板提取文本特征
text_features = self.encode_text_with_prompts()
text_features = F.normalize(text_features, dim=-1)
计算对比损失
logits = (image_features @ text_features.T) * 100 # 温度参数
应用类别平衡权重(对尾类赋予更高权重)
weights = self._calculate_class_weights(labels)
loss = F.cross_entropy(logits, labels, weight=weights.to(self.device))
添加正则化项:鼓励提示模板保持语义一致性
reg_loss = torch.norm(self.ctx) * 0.01
total_loss = loss + reg_loss
反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
progress_bar.set_postfix({'loss': total_loss.item()})
scheduler.step()
每个epoch后评估尾类性能
if (epoch + 1) % 2 == 0:
self._evaluate_tail_classes(train_dataset)
def _create_balanced_sampler(self, dataset):
"""
创建平衡采样器,对尾类过采样
"""
from torch.utils.data import WeightedRandomSampler
获取类别分布
class_counts = np.bincount(label for _, label in dataset)
计算采样权重:尾类获得更高权重
weights = 1.0 / class_counts
sample_weights = weights\[label for _, label in dataset]
sampler = WeightedRandomSampler(sample_weights, len(dataset), replacement=True)
return sampler
def _calculate_class_weights(self, labels):
"""
计算类别权重,用于损失函数中平衡长尾分布
"""
class_counts = torch.bincount(labels)
使用逆频率平方根平滑(对极长尾更鲁棒)
weights = 1.0 / torch.sqrt(class_counts.float() + 1e-8)
weights = weights / weights.sum() * len(weights)
return weights
def _evaluate_tail_classes(self, dataset, tail_threshold=50):
"""
专门评估尾类(样本数少于threshold)的性能
"""
self.model.eval()
识别尾类
class_counts = np.bincount(label for _, label in dataset)
tail_classes = np.where(class_counts < tail_threshold)0
if len(tail_classes) == 0:
return
print(f"\n评估尾类(样本数<{tail_threshold}):")
for class_idx in tail_classes:10: # 只显示前10个尾类
收集该类所有样本
class_samples = (img, label) for img, label in dataset if label == class_idx
if len(class_samples) == 0:
continue
correct = 0
for img, label in class_samples:
probs = self.predict(img)
pred = np.argmax(probs)
if pred == label:
correct += 1
accuracy = correct / len(class_samples) * 100
print(f" 类别 {class_idx}: {accuracy:.1f}% ({len(class_samples)}个样本)")
self.model.train()
============ 使用示例 ============
def example_usage():
"""
CLIP长尾分类完整示例
"""
1. 初始化分类器
classifier = LongTailCLIPClassifier()
2. 准备数据(示例)
class_names = [
"african elephant", # 头部类别
"lion",
"tiger",
... 更多常见类别
"saiga antelope", # 尾类:高鼻羚羊
"markhor", # 尾类:捻角山羊
"pangolin" # 尾类:穿山甲
]
3. 创建可学习的提示模板
ctx_parameter = classifier.create_context_prompts(class_names)
4. 加载长尾数据集(示例)
假设有自定义的LongTailImageDataset
train_dataset = LongTailImageDataset(root='path/to/data', transform=preprocess)
5. 微调提示模板(关注尾类)
classifier.fine_tune_prompts(train_dataset, num_epochs=20)
6. 推理示例
test_image = Image.open('test_image.jpg')
probabilities = classifier.predict(test_image)
获取top-5预测
top5_idx = np.argsort(probabilities0)-5:::-1
for idx in top5_idx:
print(f"{class_namesidx}: {probabilities0idx*100:.2f}%")
return classifier
============ 高级技巧:集成多提示模板 ============
class EnsemblePromptCLIP:
"""
使用多个提示模板集成,提升尾类鲁棒性
"""
def init(self, model, class_names, prompt_templates=None):
self.model = model
self.class_names = class_names
if prompt_templates is None:
默认提示模板集
self.prompt_templates = [
"a photo of a {}",
"a blurry photo of a {}",
"a low resolution photo of a {}",
"a close-up photo of a {}",
"a dark photo of a {}",
"a bright photo of a {}",
]
else:
self.prompt_templates = prompt_templates
为每个类别生成所有提示的文本特征
self.text_features = self._precompute_text_features()
def _precompute_text_features(self):
"""预计算所有提示模板的文本特征"""
all_features = \[\]
for class_name in self.class_names:
class_features = \[\]
for template in self.prompt_templates:
text = template.format(class_name)
tokens = self.model.tokenizer(text).to(self.model.device)
with torch.no_grad():
features = self.model.encode_text(tokens)
features = F.normalize(features, dim=-1)
class_features.append(features)
平均所有模板的特征
avg_features = torch.mean(torch.stack(class_features), dim=0)
all_features.append(avg_features)
return torch.stack(all_features).squeeze()
def predict(self, image):
"""使用集成提示进行预测"""
image_tensor = self.model.preprocess(image).unsqueeze(0).to(self.model.device)
with torch.no_grad():
image_features = self.model.encode_image(image_tensor)
image_features = F.normalize(image_features, dim=-1)
计算与所有类别特征的相似度
logits = (image_features @ self.text_features.T) * 100
probs = F.softmax(logits, dim=-1)
return probs.cpu().numpy()
if name == "main":
运行示例
classifier = example_usage()
def distill_clip_to_small_model(teacher_clip, student_model, dataset):
"""
将CLIP知识蒸馏到小模型,特别保留对尾类的识别能力
"""
使用CLIP为数据集生成软标签(包括零样本预测)
soft_labels = generate_soft_labels_with_clip(teacher_clip, dataset)
传统蒸馏损失 + 对比蒸馏损失
loss_fn = CombinedDistillationLoss(
temperature=4.0,
alpha=0.5, # 平衡系数
contrastive_weight=1.0 # 对比学习损失权重
)
训练学生模型
train_student_with_distillation(student_model, teacher_clip,
dataset, soft_labels, loss_fn)
结合你之前了解的知识蒸馏,可以将CLIP作为教师模型: python 复制 下载 def distill_clip_to_small_model(teacher_clip, student_model, dataset): """ 将CLIP知识蒸馏到小模型,特别保留对尾类的识别能力 """ # 使用CLIP为数据集生成软标签(包括零样本预测) soft_labels = generate_soft_labels_with_clip(teacher_clip, dataset) # 传统蒸馏损失 + 对比蒸馏损失 loss_fn = CombinedDistillationLoss( temperature=4.0, alpha=0.5, # 平衡系数 contrastive_weight=1.0 # 对比学习损失权重 ) # 训练学生模型 train_student_with_distillation(student_model, teacher_clip, dataset, soft_labels, loss_fn)
使用集成提示进一步提升性能
ensemble_clf = EnsemblePromptCLIP(classifier.model, classifier.class_names)
