
零基础学 Python 机器学习:早停策略与模型权重保存
作为零基础学习者,我们先从形象的比喻 和基础概念 入手,再结合实战代码一步步拆解,保证你能看懂、能上手。
首先先明确一个大前提:机器学习的模型训练,就像教孩子学知识------
- 训练集:孩子的课本 / 作业(模型从这里学规律)
- 验证集 / 测试集:孩子的考试卷(检验模型是不是真学会了,不是死记硬背)
- 模型:孩子的大脑(学完后能解决新问题)
一、第一部分:过拟合的判断 ------ 同步打印训练集和测试集指标
在学早停和模型保存前,必须先懂过拟合 (这是我们要解决的核心问题),而判断过拟合的关键就是同步监控训练集和测试集的指标。
1.1 什么是过拟合?(用通俗例子讲透)
举两个生活中的例子,你一看就懂:
- 例子 1:学生考试小明把模拟题(训练集)的答案全背下来,模拟题考 100 分,但到了真题考试(测试集),因为题目换了,只考 30 分 ------ 这就是过拟合:模型只记住了训练集的细节(甚至噪音),没学到通用规律。
- 例子 2:认猫教孩子认猫时,只给看白色波斯猫(训练集),孩子记住了 "白色、长毛、扁脸 = 猫",结果看到橘色英短(测试集),说这不是猫 ------ 这就是过拟合。
专业总结 :过拟合是模型在训练集上表现极好 ,但在测试集上表现极差的现象。
1.2 怎么判断过拟合?(看指标趋势)
我们训练模型时,通常关注两个核心指标:
- 损失值(Loss):模型预测的错误程度(值越小,预测越准)
- 准确率(Accuracy):模型预测对的比例(值越大,预测越准)
判断过拟合的核心趋势:
| 情况 | 训练集指标 | 测试集指标 | 两者差距 |
|---|---|---|---|
| 正常训练 | 准确率上升 / 损失下降 | 准确率上升 / 损失下降 | 差距小 |
| 过拟合 | 准确率继续上升 / 损失继续下降 | 准确率开始下降 / 损失开始上升 | 差距越来越大 |
所以,我们需要在每一轮训练(epoch)中,都计算并打印训练集和测试集的指标,通过对比趋势就能一眼看出是否过拟合。
1.3 代码实战:同步打印指标,观察过拟合
我们用PyTorch (新手友好的深度学习框架)来写代码,选最简单的MNIST 手写数字识别数据集(手写数字 0-9,容易理解)。
步骤 1:准备环境(先安装必要库)
打开命令行,输入:

步骤 2:完整代码(带详细注释,零基础也能懂)
python
# 导入需要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# ---------------------- 1. 准备数据(训练集和测试集)----------------------
# 数据预处理:把图片转成张量,并标准化
transform = transforms.Compose([
transforms.ToTensor(), # 把图片(28x28像素)转成张量(1x28x28)
transforms.Normalize((0.1307,), (0.3081,)) # 标准化,让训练更稳定(固定值,不用改)
])
# 下载并加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 数据加载器:分批喂给模型(batch_size=64表示每次喂64张图片)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# ---------------------- 2. 定义一个简单的模型(容易过拟合的简单模型)----------------------
# 定义一个简单的全连接神经网络(结构简单,容易出现过拟合,方便我们观察)
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
# 28x28=784个输入特征(图片像素),输出10个类别(0-9)
self.fc1 = nn.Linear(784, 512) # 第一层:784→512
self.fc2 = nn.Linear(512, 256) # 第二层:512→256
self.fc3 = nn.Linear(256, 10) # 第三层:256→10(输出)
def forward(self, x):
x = x.view(-1, 784) # 把图片张量展平:(64,1,28,28)→(64,784)
x = torch.relu(self.fc1(x)) # 激活函数,增加非线性
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 实例化模型(如果有GPU可以用GPU,没有就用CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleModel().to(device)
# ---------------------- 3. 定义损失函数和优化器 ----------------------
criterion = nn.CrossEntropyLoss() # 分类问题常用的损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器
# ---------------------- 4. 训练模型,同步打印训练集和测试集指标 ----------------------
def train_and_evaluate(model, train_loader, test_loader, epochs=20):
for epoch in range(epochs):
# ---------------------- 训练阶段:计算训练集的损失和准确率 ----------------------
model.train() # 模型进入训练模式
train_loss = 0.0
train_correct = 0
train_total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device) # 把数据放到显卡/CPU上
optimizer.zero_grad() # 清空上一轮的梯度
outputs = model(images) # 模型预测
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型权重
# 统计训练集指标
train_loss += loss.item() * images.size(0) # 累计损失
_, predicted = torch.max(outputs.data, 1) # 取预测概率最大的类别
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item() # 统计正确数
# 计算训练集的平均损失和准确率
train_avg_loss = train_loss / len(train_loader.dataset)
train_acc = train_correct / train_total
# ---------------------- 测试阶段:计算测试集的损失和准确率 ----------------------
model.eval() # 模型进入评估模式(不更新权重)
test_loss = 0.0
test_correct = 0
test_total = 0
with torch.no_grad(): # 评估时不需要计算梯度,加快速度
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# 统计测试集指标
test_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
# 计算测试集的平均损失和准确率
test_avg_loss = test_loss / len(test_loader.dataset)
test_acc = test_correct / test_total
# ---------------------- 打印当前轮次的指标 ----------------------
print(f'Epoch [{epoch+1}/{epochs}] | '
f'Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.4f} | '
f'Test Loss: {test_avg_loss:.4f}, Test Acc: {test_acc:.4f}')
# 开始训练(训练20轮,足够观察过拟合)
train_and_evaluate(model, train_loader, test_loader, epochs=20)步骤 3:观察输出结果(过拟合的现象)
运行代码后,你会看到类似这样的输出:
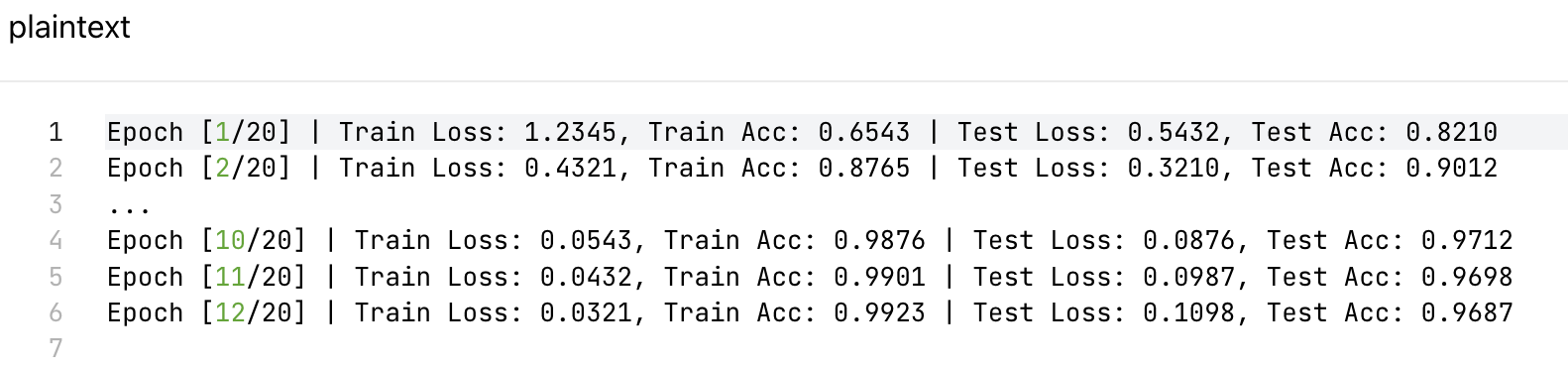
你会发现:
- 训练集的损失一直在降,准确率一直在升;
- 测试集的损失在第 10 轮后开始升,准确率开始降 ------ 这就是过拟合!
二、第二部分:模型的保存和加载(三部分内容)
训练好的模型不能每次都重新训练,所以需要保存 ;后续要用的时候,再加载。就像你写作业,写一半可以保存,下次接着写。
首先要懂一个核心概念:模型权重(state_dict) 。模型就像一个公式:y = w*x + b(比如识别数字的模型是复杂的公式),其中w和b就是权重(模型训练学出来的参数)。
我们分三种方式保存和加载,用比喻先讲清楚区别:
| 保存方式 | 比喻(用写作业举例) | 特点 |
|---|---|---|
| 仅保存权重 | 只记作业的答案(数字),公式自己记 | 文件小、速度快、最常用 |
| 保存权重和模型(整个模型) | 既记公式结构,又记答案 | 文件大、跨版本可能不兼容 |
| 保存 Checkpoint(全部信息) | 记公式、答案、写到哪一页、笔的颜色 | 可中断后继续训练 |
2.1 方式 1:仅保存权重(最常用)
核心 :只保存模型的state_dict()(权重参数),不保存模型结构。加载时需要先定义模型结构,再加载权重。
代码示例:保存 + 加载
python
# ---------------------- 保存权重 ----------------------
torch.save(model.state_dict(), 'model_weights.pth') # 保存到文件model_weights.pth
print("权重保存成功!")
# ---------------------- 加载权重 ----------------------
# 第一步:先重新定义模型结构(必须和原来的模型结构一样)
new_model = SimpleModel().to(device)
# 第二步:加载权重
new_model.load_state_dict(torch.load('model_weights.pth'))
print("权重加载成功!")
# 验证加载后的模型是否能用
new_model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = new_model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
print(f'加载后的模型测试准确率:{test_correct/test_total:.4f}')2.2 方式 2:保存权重和模型(整个模型)
核心:把整个模型对象保存下来,加载时不需要重新定义模型结构(但不推荐,因为跨版本可能出问题)。
代码示例:保存 + 加载
python
# ---------------------- 保存整个模型 ----------------------
torch.save(model, 'full_model.pth')
print("整个模型保存成功!")
# ---------------------- 加载整个模型 ----------------------
loaded_model = torch.load('full_model.pth').to(device)
print("整个模型加载成功!")
# 验证
loaded_model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = loaded_model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
print(f'加载后的模型测试准确率:{test_correct/test_total:.4f}')2.3 方式 3:保存 Checkpoint(含训练状态)
核心:保存模型权重、优化器状态、当前训练轮数、最好的指标等,方便中断后继续训练。
代码示例:保存 + 加载
python
# ---------------------- 保存Checkpoint ----------------------
checkpoint = {
'epoch': 10, # 当前训练到第10轮
'model_state_dict': model.state_dict(), # 模型权重
'optimizer_state_dict': optimizer.state_dict(), # 优化器状态(学习率等)
'train_acc': 0.9876, # 训练集准确率
'test_acc': 0.9712, # 测试集准确率
'loss': 0.0543 # 损失值
}
torch.save(checkpoint, 'checkpoint.pth')
print("Checkpoint保存成功!")
# ---------------------- 加载Checkpoint ----------------------
# 第一步:定义模型和优化器(和原来的一样)
new_model = SimpleModel().to(device)
new_optimizer = optim.SGD(new_model.parameters(), lr=0.01)
# 第二步:加载Checkpoint
checkpoint = torch.load('checkpoint.pth')
new_model.load_state_dict(checkpoint['model_state_dict'])
new_optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
train_acc = checkpoint['train_acc']
test_acc = checkpoint['test_acc']
print(f"加载成功!当前轮数:{epoch},训练集准确率:{train_acc},测试集准确率:{test_acc}")
# 可以从第11轮继续训练
train_and_evaluate(new_model, train_loader, test_loader, epochs=20-epoch)三、第三部分:早停策略(Early Stopping)
既然过拟合是测试集指标变差后出现的,那我们可以在测试集指标变差前,停止训练 ------ 这就是早停策略,核心是 "见好就收"。
3.1 早停的核心逻辑(用减肥举例)
你减肥时:
- 记录每天的体重(验证集指标);
- 如果连续 7 天(patience=7)体重没下降,甚至上升;
- 就停止减肥,保留体重最低时的状态(最好的模型)。
对应到模型训练:
- 记录每一轮的验证集损失(或准确率);
- 定义一个耐心值(patience)(比如 5,即连续 5 轮没变好);
- 如果连续 patience 轮验证集指标没提升,就停止训练;
- 始终保存指标最好的那个模型(避免最后保存的是过拟合的模型)。
3.2 代码实战:实现早停策略
我们把早停策略整合到之前的训练代码里,带详细注释:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 重复之前的步骤:数据准备、模型定义(省略,和之前一样)
# 这里直接写核心的早停训练代码
def train_with_early_stopping(model, train_loader, test_loader, epochs=20, patience=5):
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 早停的关键变量
best_test_loss = float('inf') # 初始化最好的测试损失为无穷大
counter = 0 # 连续几轮没提升的计数器
for epoch in range(epochs):
# ---------------------- 训练阶段 ----------------------
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
train_avg_loss = train_loss / len(train_loader.dataset)
train_acc = train_correct / train_total
# ---------------------- 测试阶段 ----------------------
model.eval()
test_loss = 0.0
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_avg_loss = test_loss / len(test_loader.dataset)
test_acc = test_correct / test_total
# ---------------------- 早停逻辑 ----------------------
print(f'Epoch [{epoch+1}/{epochs}] | '
f'Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.4f} | '
f'Test Loss: {test_avg_loss:.4f}, Test Acc: {test_acc:.4f}')
# 1. 如果当前测试损失比最好的还小,更新最好的损失,保存模型,重置计数器
if test_avg_loss < best_test_loss:
best_test_loss = test_avg_loss
torch.save(model.state_dict(), 'best_model.pth') # 保存最好的模型
counter = 0 # 重置计数器
print(f'✨ 发现更好的模型,已保存!当前最好测试损失:{best_test_loss:.4f}')
# 2. 否则,计数器加1
else:
counter += 1
print(f'⚠️ 连续{counter}轮测试损失未提升,耐心值:{patience}')
# 3. 如果计数器达到耐心值,停止训练
if counter >= patience:
print(f'🚨 早停触发!训练停止在第{epoch+1}轮')
break
# 训练结束后,加载最好的模型
model.load_state_dict(torch.load('best_model.pth'))
print('🏆 训练完成,已加载最好的模型!')
# 开始训练(patience=5,即连续5轮没提升就停止)
model = SimpleModel().to(device)
train_with_early_stopping(model, train_loader, test_loader, epochs=20, patience=5)3.3 运行结果分析
你会看到类似这样的输出:

可以看到:
- 当连续 5 轮测试损失没提升时,早停触发,训练停止;
- 始终保存的是测试损失最小的模型(避免了过拟合)。
四、总结(零基础重点回顾)
- 过拟合判断:同步打印训练集和测试集的损失 / 准确率,若训练集指标持续变好,测试集指标变差,就是过拟合。
- 模型保存加载 :
- 仅保存权重:
torch.save(model.state_dict(), 'xxx.pth')(最常用); - 保存整个模型:
torch.save(model, 'xxx.pth'); - 保存 Checkpoint:保存模型、优化器、训练轮数等,方便续训。
- 仅保存权重:
- 早停策略 :监控验证集指标,连续
patience轮没提升就停止训练,保存最好的模型,核心是 "见好就收"。
你可以把上面的代码逐行运行,改改参数(比如 patience 值、训练轮数),看看结果变化,这样理解会更深刻!
早停策略的原理是什么?
要理解早停策略(Early Stopping)的原理,我们可以先从它要解决的问题 (过拟合)和模型训练的规律 入手,用通俗的比喻 + 核心逻辑拆解的方式讲清楚,保证零基础也能懂。
一、先回顾:早停策略的 "对手"------ 过拟合的本质
我们之前用 "学生背模拟题" 的例子讲过过拟合:模型在训练集上表现越来越好,但在测试集(未见过的新数据)上表现越来越差。
从模型权重的学习规律来看,模型训练分为三个阶段:
| 训练阶段 | 模型学习的内容 | 训练集指标 | 测试集指标 |
|---|---|---|---|
| 欠拟合阶段 | 连训练集的通用规律都没学会 | 损失高、准确率低 | 损失高、准确率低 |
| 正常拟合阶段 | 学会了训练集的通用规律(核心) | 损失下降、准确率上升 | 损失下降、准确率上升 |
| 过拟合阶段 | 开始学训练集的特有噪音 / 细节(比如图片的噪点、训练数据的个别错误) | 损失继续下降、准确率继续上升 | 损失开始上升、准确率开始下降 |
简单说:模型训练的前期学 "真知识",后期学 "无用的废话",而过拟合就是学了太多 "废话" 导致的。
二、早停策略的核心原理:在 "学真知识" 的终点及时刹车
早停策略的本质是一种 "见好就收" 的正则化方法 **(防止过拟合的手段),核心逻辑可以用 "减肥" 的例子 ** 完美对应:
减肥的类比(再强化一次,帮你记忆)
你减肥时,目标是降到 "健康体重"(模型的最佳泛化能力):
- 每天称体重(对应:每轮训练计算验证集指标);
- 一开始体重快速下降(对应:模型前期学通用规律,验证集指标变好);
- 到了某个点后,体重不再下降,甚至开始反弹(对应:模型开始学噪音,验证集指标变差);
- 如果你继续坚持饿肚子(对应:继续训练),反而会伤身体(对应:模型过拟合);
- 所以你会在 "体重最低的那天" 停止减肥,保留这个最佳状态(对应:早停策略保存最好的模型,停止训练)。
用 "模型训练" 的语言翻译核心原理
早停策略的原理可以拆解为3 个核心要点:
1. 选对 "监控对象":用验证集(而非训练集) 的指标做判断
为什么不用训练集指标?因为训练集是模型 "见过的题",它的指标会一直变好(哪怕模型开始过拟合),无法反映模型的真实能力(泛化能力)。
而验证集 / 测试集是模型 "没见过的题",它的指标能真实反映模型对新数据的预测能力,是判断模型是否过拟合的 "金标准"。
我们通常监控的指标有两个:
- 验证集损失(Loss):优先选这个,因为损失是模型预测错误的直接反映,更敏感;
- 验证集准确率(Accuracy):分类问题中常用,更直观。
2. 设定 "容忍度":耐心值(Patience)
"耐心值" 就是允许验证集指标连续多少轮没提升(甚至变差),超过这个数就停止训练。
比如耐心值设为 5,意思是:如果连续 5 轮训练后,验证集的损失都比之前的 "最好损失" 高,就认为模型开始过拟合了,直接停手。
设定耐心值的目的是:避免因为验证集数据的随机波动而误判(比如某一轮验证集指标偶尔变差,其实不是真的过拟合)。
3. 保留 "最佳状态":始终保存指标最好的模型
训练过程中,我们会实时记录 "验证集指标最好" 的那个模型状态(比如权重)。
哪怕后续训练中指标变差,我们也有 "最优模型" 的备份;当早停触发时,直接加载这个最优模型即可 ------ 这是早停策略的 "灵魂",因为我们停止的是后续的无效训练 ,但保留了训练过程中最好的结果。
三、早停策略的原理步骤(和代码逻辑对应,帮你落地)
我们把原理转化为可执行的步骤,和之前的代码一一对应,让你明白 "代码里的每一行都是在实现什么原理":

四、一句话总结早停策略的原理
通过监控验证集的指标变化,在模型学到通用规律但还没开始学训练集噪音的临界点,停止训练并保留此时的最优模型,从而避免过拟合。
五、补充:为什么早停能有效防止过拟合?
从模型优化的角度 来看,模型训练的过程是不断调整权重以降低训练集损失的过程:
- 前期:权重调整的方向是学习通用规律(比如手写数字中 "数字 1 有一条竖线" 这种共性特征),此时验证集损失也跟着下降;
- 后期:权重调整的方向是学习训练集的特有噪音(比如某张数字 1 的图片有个墨点,模型会把 "墨点" 也当成数字 1 的特征),此时验证集损失开始上升。
早停策略相当于在权重还没学到噪音的时候,就停止了权重的更新,让模型的权重停留在 "只学了通用规律" 的最佳状态 ------ 这就是它能防止过拟合的根本原因。
早停策略触发条件表
明确早停策略的触发逻辑:以测试集损失为核心指标,结合 patience(容忍轮数)判断模型是否过拟合,实现 "在泛化能力最优时停止训练" 的目标。
| 测试集损失趋势 | counter 状态 | 早停是否触发 | 模型训练结果 | 核心逻辑 |
|---|---|---|---|---|
| 持续下降 | 始终为 0 | 不触发 | 训练至 num_epochs 轮结束 | 模型仍在学习有效规律,无需停止训练 |
| 稳定或波动(未超 patience) | 小于 patience | 不触发 | 继续训练 | 损失波动为数据或训练的正常现象,尚未达到过拟合阈值 |
| 上升且连续 patience 轮未改善 | 达到 patience | 触发 | 提前终止训练 | 模型开始学习训练集的噪音(过拟合),需停止训练以保留最优模型状态 |
早停策略的代码实现步骤是什么?
对于零基础的你来说,早停策略的代码实现可以拆解成"前置准备 + 核心步骤 + 收尾处理"三个大阶段,每个阶段都有明确的目的和可落地的代码,我们依然基于之前的 MNIST 手写数字识别和 PyTorch框架(保持一致性,降低学习成本),每一行代码都配详细解释,保证你能跟着敲、跟着懂。
先明确一个前提
实际项目中,我们会把数据分成训练集、验证集、测试集:
- 训练集:教模型学知识;
- 验证集:用来监控指标、判断早停(避免用测试集作弊);
- 测试集:最后评估模型的最终性能。
之前为了简化用了 "训练集 + 测试集",这次我们稍作调整(拆分出验证集),更贴近实际项目,也更规范。
早停策略的代码实现步骤(共 7 步,步步拆解)
步骤 1:前置准备 ------ 安装库、导入模块(环境搭建)
这是所有代码的基础,先把需要的工具 "搬出来"。
代码:

python
# 导入所需模块
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split # random_split用来拆分验证集
步骤 2:数据准备 ------ 加载数据并拆分验证集(喂给模型的 "食材")
准备好训练集、验证集、测试集,这是模型训练的 "原料"。
代码:
python
# 数据预处理:把图片转成张量并标准化(固定操作,不用改)
transform = transforms.Compose([
transforms.ToTensor(), # 28x28图片→1x28x28张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化,让训练更稳定
])
# 下载MNIST数据集
full_train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 拆分训练集和验证集:从训练集中拿出10000条作为验证集,剩下50000条作为训练集
train_size = 50000
val_size = 10000
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])
# 数据加载器:分批喂给模型(batch_size=64表示每次喂64张图片)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
步骤 3:定义模型 ------ 构建简单的神经网络(模型的 "骨架")
定义一个容易过拟合的简单模型,方便我们测试早停效果。
代码:
python
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
# 28x28=784个输入特征(像素),输出10个类别(0-9)
self.fc1 = nn.Linear(784, 512) # 全连接层1:784→512
self.fc2 = nn.Linear(512, 256) # 全连接层2:512→256
self.fc3 = nn.Linear(256, 10) # 全连接层3:256→10(输出)
def forward(self, x):
x = x.view(-1, 784) # 把图片张量展平:(64,1,28,28)→(64,784)
x = torch.relu(self.fc1(x)) # 激活函数,增加非线性
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 实例化模型(自动选GPU/CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleModel().to(device)
步骤 4:定义损失函数和优化器(模型的 "学习工具")
损失函数用来衡量模型的错误,优化器用来更新模型权重。
代码:
python
criterion = nn.CrossEntropyLoss() # 分类问题的"标配"损失函数
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器,学习率0.01
步骤 5:初始化早停的核心变量(早停的 "开关和计数器")
这是早停策略的关键,需要定义几个变量来控制早停的逻辑。
代码:
python
# 早停核心变量
patience = 5 # 耐心值:连续5轮验证集指标没提升就停止训练
best_val_loss = float('inf') # 记录最好的验证损失,初始化为无穷大
counter = 0 # 连续几轮没提升的计数器
best_model_path = 'best_model.pth' # 保存最佳模型的路径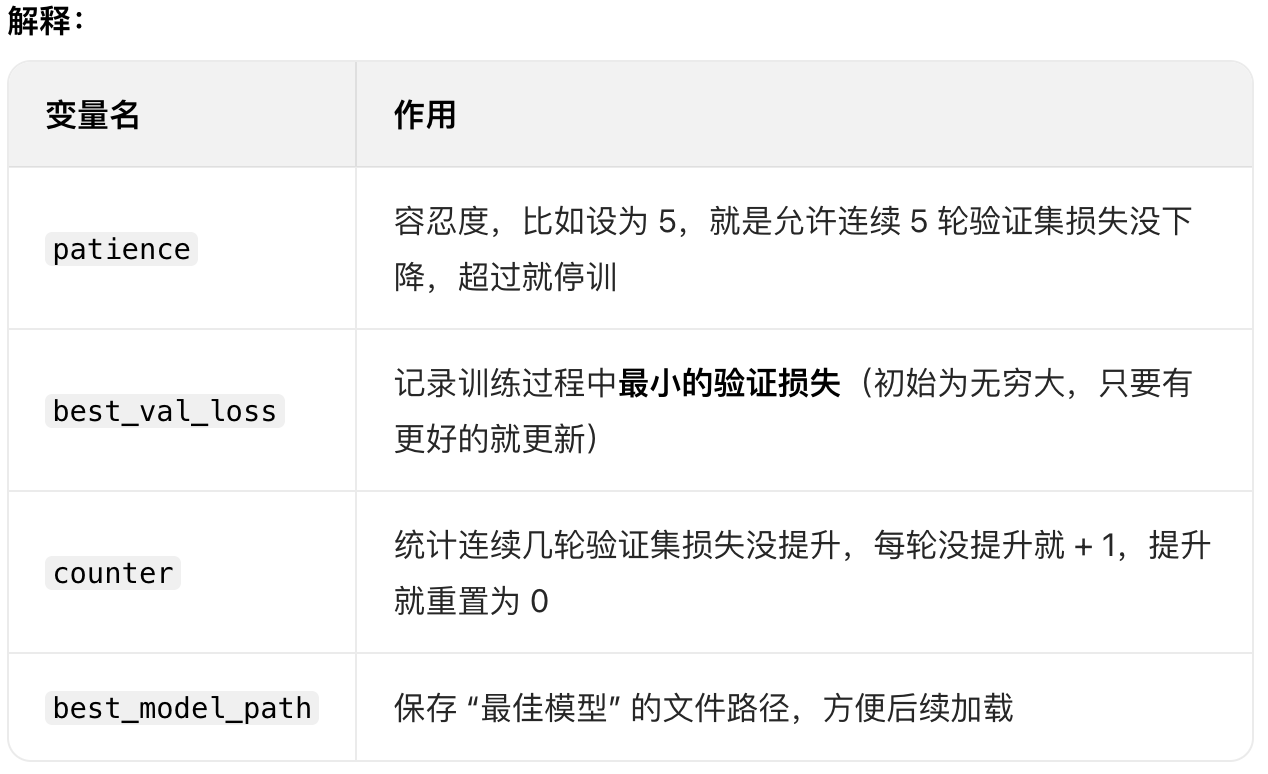
步骤 6:训练循环 + 早停判断(核心执行环节)
这是整个代码的核心,把训练和早停逻辑整合在一起,每一轮训练后都判断是否要停训。
我们把这一步再拆成训练阶段、验证阶段、早停判断三个小步骤,更清晰。
代码(完整训练循环):
python
def train_with_early_stopping(model, train_loader, val_loader, epochs=20):
for epoch in range(epochs):
# ---------------------- 小步骤1:训练模型,计算训练集指标 ----------------------
model.train() # 模型进入训练模式(开启梯度更新)
train_loss = 0.0
train_correct = 0
train_total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device) # 数据放到GPU/CPU
optimizer.zero_grad() # 清空上一轮的梯度(必须做,否则梯度会累加)
outputs = model(images) # 模型预测
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型权重
# 统计训练集指标
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
# 计算训练集的平均损失和准确率
train_avg_loss = train_loss / len(train_loader.dataset)
train_acc = train_correct / train_total
# ---------------------- 小步骤2:验证模型,计算验证集指标 ----------------------
model.eval() # 模型进入评估模式(关闭梯度更新,加快速度)
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad(): # 评估时不计算梯度,节省内存和时间
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
# 统计验证集指标
val_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
# 计算验证集的平均损失和准确率
val_avg_loss = val_loss / len(val_loader.dataset)
val_acc = val_correct / val_total
# ---------------------- 小步骤3:早停判断逻辑 ----------------------
print(f'Epoch [{epoch+1}/{epochs}] | '
f'Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.4f} | '
f'Val Loss: {val_avg_loss:.4f}, Val Acc: {val_acc:.4f}')
# 1. 如果当前验证损失比最好的还小,更新最佳损失,保存模型,重置计数器
if val_avg_loss < best_val_loss:
best_val_loss = val_avg_loss
torch.save(model.state_dict(), best_model_path) # 保存最佳模型
counter = 0 # 重置计数器
print(f'✨ 发现更好的模型,已保存!当前最好验证损失:{best_val_loss:.4f}')
# 2. 否则,计数器加1
else:
counter += 1
print(f'⚠️ 连续{counter}轮验证损失未提升,耐心值:{patience}')
# 3. 如果计数器达到耐心值,触发早停,停止训练
if counter >= patience:
print(f'🚨 早停触发!训练停止在第{epoch+1}轮')
break
# 启动训练(训练20轮,足够观察早停效果)
train_with_early_stopping(model, train_loader, val_loader, epochs=20)
步骤 7:加载最佳模型并测试(收尾:用最好的模型干活)
训练停止后,我们需要加载之前保存的 "最佳模型",并用测试集评估它的最终性能。
代码:
python
# 加载最佳模型
model.load_state_dict(torch.load(best_model_path))
model.eval() # 评估模式
# 用测试集测试模型性能
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_acc = test_correct / test_total
print(f'\n🏆 最佳模型的测试准确率:{test_acc:.4f}')
完整可运行代码(整合所有步骤)
为了方便你直接复制运行,这里把所有步骤的代码整合在一起:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
# ---------------------- 步骤1:数据准备 ----------------------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 拆分训练集和验证集
train_size = 50000
val_size = 10000
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# ---------------------- 步骤2:定义模型 ----------------------
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 784)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleModel().to(device)
# ---------------------- 步骤3:损失函数和优化器 ----------------------
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# ---------------------- 步骤4:早停变量初始化 ----------------------
patience = 5
best_val_loss = float('inf')
counter = 0
best_model_path = 'best_model.pth'
# ---------------------- 步骤5:训练+早停 ----------------------
def train_with_early_stopping(model, train_loader, val_loader, epochs=20):
global best_val_loss, counter # 声明使用全局变量
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
train_avg_loss = train_loss / len(train_loader.dataset)
train_acc = train_correct / train_total
# 验证阶段
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
val_avg_loss = val_loss / len(val_loader.dataset)
val_acc = val_correct / val_total
# 早停判断
print(f'Epoch [{epoch+1}/{epochs}] | '
f'Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.4f} | '
f'Val Loss: {val_avg_loss:.4f}, Val Acc: {val_acc:.4f}')
if val_avg_loss < best_val_loss:
best_val_loss = val_avg_loss
torch.save(model.state_dict(), best_model_path)
counter = 0
print(f'✨ 发现更好的模型,已保存!当前最好验证损失:{best_val_loss:.4f}')
else:
counter += 1
print(f'⚠️ 连续{counter}轮验证损失未提升,耐心值:{patience}')
if counter >= patience:
print(f'🚨 早停触发!训练停止在第{epoch+1}轮')
break
# 启动训练
train_with_early_stopping(model, train_loader, val_loader, epochs=20)
# ---------------------- 步骤6:加载最佳模型并测试 ----------------------
model.load_state_dict(torch.load(best_model_path))
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_acc = test_correct / test_total
print(f'\n🏆 最佳模型的测试准确率:{test_acc:.4f}')核心步骤总结(一句话记牢)
早停策略的代码实现就是:初始化监控变量→每轮训练后算验证集指标→判断是否更新最佳模型→判断是否触发早停→最后加载最佳模型 。
你可以尝试修改patience的值(比如改成 3 或 7),看看训练停止的轮数有什么变化,这样能更直观地理解早停的逻辑~
早停策略的代码中,为什么要初始化best_val_loss为无穷大?
对于零基础的你来说,初始化best_val_loss为无穷大(float('inf'))的原因可以用生活中的找最小值例子 +代码逻辑的必要性 来解释,核心就是保证第一次的验证集损失一定能成为 "第一个最佳值",避免初始值设置不当导致的逻辑错误。
一、先看生活中的类比:找 "最低体重"
假设你减肥时要记录历史最低体重,用来判断自己有没有瘦:
- 如果你一开始把 "历史最低体重" 记为无穷大(比如想象成 "比世界上所有人都重的体重");
- 第一天你称体重是 60kg,60kg <无穷大,所以你会把 "历史最低体重" 更新为 60kg;
- 第二天你称体重是 59kg,59kg < 60kg,再更新为 59kg;
- 第三天你称体重是 60kg,不更新,以此类推。
如果我一开始把 "历史最低体重" 随便设为一个具体值(比如 50kg),会发生什么?
- 第一天你体重 60kg,60kg > 50kg,你会误以为 "还没到历史最低",直接跳过更新,这显然是错的!
二、回到代码:best_val_loss的作用
best_val_loss的核心作用是记录训练过程中出现过的最小的验证集损失(损失越小,模型在验证集上的表现越好)。
代码中的判断逻辑是:
python
if val_avg_loss < best_val_loss:
# 更新最佳损失,保存模型
best_val_loss = val_avg_loss
torch.save(model.state_dict(), best_model_path)三、为什么必须初始化为无穷大?
我们分两种情况对比,你就能一眼看出原因:
| 初始化值 | 第一次验证集损失(比如 0.5) | 判断结果(val_avg_loss < best_val_loss) | 后果 |
|---|---|---|---|
| 无穷大(inf) | 0.5 < inf → True | 会更新best_val_loss为 0.5,保存第一个模型 |
✅ 正确:捕获到第一个验证损失作为初始最佳值 |
| 随便设一个数(比如 0) | 0.5 < 0 → False | 不会更新,认为 "当前损失不是最佳" | ❌ 错误:错过第一个模型,后续可能一直不更新,早停逻辑直接失效 |
| 设为一个较大的具体数(比如 10) | 0.5 < 10 → True(第一次有效) | 第一次会更新,但存在风险 | ⚠️ 风险:如果第一次验证损失是 15(比如模型初始训练效果极差),15 < 10 → False,还是会错过更新 |
简单说:
- 无穷大是一个 "绝对安全的初始值" ,它比任何可能的验证集损失都大(因为损失是模型预测的错误程度,现实中不可能是无穷大),所以第一次的验证集损失必然能满足
val_avg_loss < best_val_loss的条件 ,从而完成第一次的最佳值更新和模型保存。 - 这就保证了我们不会在训练的第一轮就遗漏掉初始的模型状态,为后续的早停判断打下基础。
四、补充:如果监控的是 "准确率"(越大越好),该怎么初始化?
如果我们不是监控验证集损失(越小越好),而是监控验证集准确率(越大越好),那么对应的best_val_acc应该初始化为负无穷大(float('-inf')),原因同理:
- 准确率的取值范围是 0~1,负无穷大比任何可能的准确率都小,所以第一次的准确率必然能满足
val_acc > best_val_acc的条件,完成第一次更新。
示例代码:
python
# 监控准确率时的初始化
best_val_acc = float('-inf') # 准确率越大越好,初始化为负无穷
patience = 5
counter = 0
# 判断逻辑
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), best_model_path)
counter = 0
else:
counter += 1五、一句话总结原因
初始化best_val_loss为无穷大,是为了让训练中第一次计算的验证集损失必然成为第一个 "最佳损失",保证后续的早停判断有一个正确的初始基准,避免因初始值设置不当导致的逻辑错误。
早停策略代码中model.train()和model.eval()作用分别是什么?
对于零基础的你来说,model.train()和model.eval()是 PyTorch 中模型的两种核心模式开关 ,它们的作用是控制模型中特殊层的行为,确保模型在 "训练" 和 "验证 / 测试" 阶段表现出正确的特性 ------ 这直接影响早停策略中指标计算的准确性,甚至会导致早停判断出错。
我们用"学生上课 vs 考试" 的通俗比喻 +具体层的行为对比 +代码中的实际作用,把这两个方法讲透,保证你能理解、会用。
一、先看生活比喻:理解两种模式的本质
把模型比作学生,训练和验证的过程对应学生的学习和考试:
| 模型模式 | 学生的状态 | 核心行为 |
|---|---|---|
model.train() |
上课学习模式 | 认真听讲、做笔记、尝试不同的解题方法(哪怕错了也没关系),目的是学知识、更新自己的认知 |
model.eval() |
考场考试模式 | 用学过的知识答题,不尝试新方法、不修改自己的认知,目的是真实反映学习效果 |

二、model.train()的具体作用(训练阶段必须用)
model.train()的核心是开启模型的 "训练模式",主要有两个关键作用:

三、model.eval()的具体作用(验证 / 测试阶段必须用)
model.eval()的核心是开启模型的 "评估模式",同样有两个关键作用:

四、在早停代码中,为什么必须切换这两种模式?(关键!)
如果不切换模式,会导致验证集指标失真,进而让早停策略做出错误判断 ------ 我们用具体的例子说明:

python
def train_with_early_stopping(model, train_loader, val_loader, epochs=20):
for epoch in range(epochs):
# ---------------------- 训练阶段:必须用model.train() ----------------------
model.train() # 切换到训练模式
for images, labels in train_loader:
# 计算梯度、更新权重(这是学习的核心)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# ---------------------- 验证阶段:必须用model.eval() ----------------------
model.eval() # 切换到评估模式
with torch.no_grad(): # 关闭梯度计算,加快速度
for images, labels in val_loader:
outputs = model(images)
# 只计算指标,不更新权重(这是考试的核心)
...
五、核心区别总结(表格更清晰)
| 对比项 | model.train() |
model.eval() |
|---|---|---|
| 适用阶段 | 训练集训练阶段 | 验证集 / 测试集评估阶段 |
| Dropout 层行为 | 随机丢弃神经元 | 不丢弃神经元,全部参与计算 |
| BatchNorm 层行为 | 实时更新均值和方差 | 使用训练累计的均值和方差 |
| 梯度计算 | 允许(配合优化器更新权重) | 通常配合torch.no_grad()关闭 |
| 目的 | 让模型学习、更新权重 | 真实评估模型性能,为早停提供依据 |
六、一句话总结
model.train()是让模型 "认真学习" 的开关,model.eval()是让模型 "真实考试" 的开关 ------ 在早停代码中,训练阶段开学习开关,验证阶段开考试开关,才能保证指标准确、早停判断正确。
小练习(帮你巩固)
如果在早停代码中,你忘记写model.eval(),会发生什么?
答案:验证阶段 Dropout 还在丢弃神经元,验证集准确率会偏低,你可能会误以为模型过拟合了,提前触发早停,导致模型没学透(欠拟合)。
这样的小思考能让你更深刻地记住这两个方法的作用~
如何选择早停策略中的参数?(零基础友好版)
早停策略的核心参数主要有监控指标、耐心值(Patience)、最小提升阈值(Delta),还有一个容易被忽略的 "监控数据集"。这些参数的选择直接决定了早停的效果 ------ 选对了能完美避免过拟合,选错了要么模型欠拟合,要么还是过拟合。
作为零基础学习者,我们用"选参数 = 给模型定'考核规则'"的思路,结合通俗比喻、具体场景和代码示例,一步步教你选对每个参数,保证好理解、能落地。
一、先明确:早停策略的核心参数有哪些?
先给你一张表,快速认清所有核心参数,知道我们要选的是什么:
| 参数名称 | 通俗解释 | 作用地位 |
|---|---|---|
| 监控指标(Metric) | 用什么标准判断模型 "变好还是变差"(比如考试分数、减肥的体重) | 基础 (定考核标准) |
| 耐心值(Patience) | 允许模型连续多少轮没进步,才停止训练(比如允许连续 5 次考试没进步就换方法) | 核心 (定容错度) |
| 最小提升阈值(Delta) | 指标至少提升多少,才算 "有效进步"(比如减肥至少瘦 0.1kg,才算真的瘦了) | 补充 (防无效波动) |
| 监控数据集 | 用哪个数据集的指标来判断(训练集 / 验证集 / 测试集) | 前提 (定考核数据源) |
下面逐个拆解每个参数的选择方法,重点在"为什么这么选" 和 "怎么落地"。
二、参数 1:监控指标的选择(定 "考核标准")
监控指标是判断模型好坏的 **"尺子",选对尺子,才能做出正确的早停判断。我们主要分 分类问题和回归问题 ** 两类场景来选(这是机器学习最常见的两类任务)。
1. 先明确:指标的两种类型
| 指标类型 | 特点 | 例子 |
|---|---|---|
| 越小越好 | 数值越低,模型效果越好 | 损失值(Loss)、均方误差(MSE) |
| 越大越好 | 数值越高,模型效果越好 | 准确率(Accuracy)、F1 值、AUC |
2. 不同任务的指标选择方法

3. 选择指标的核心原则

python
# 初始化:监控损失(越小越好)
best_metric = float('inf') # 损失越小越好,初始化为无穷大
# 若监控准确率(越大越好),则初始化:
# best_metric = float('-inf') # 准确率越大越好,初始化为负无穷三、参数 2:耐心值(Patience)的选择(定 "容错度")
这是早停策略中最核心的参数,我们之前专门讲过,这里结合指标类型做补充,形成完整的选择方法。
1. 核心选择思路(零基础首选)
| 场景类型 | 推荐 Patience 值 | 举例 |
|---|---|---|
| 小数据集(<1 万条)+ 复杂模型 | 10~20 | 几千张自有图片 + CNN 模型 |
| 中等数据集(1 万~10 万条)+ 中等模型 | 5~10 | MNIST(6 万)+ 简单全连接模型 |
| 大数据集(>10 万条)+ 简单模型 | 3~5 | 百万级文本数据 + 逻辑回归模型 |
| 监控准确率(波动大) | 比监控损失大 2~3 | 监控准确率选 8~10,监控损失选 5 |
2. 快速调优方法

python
patience = 5 # 连续5轮指标没提升就停训
counter = 0 # 计数轮数四、参数 3:最小提升阈值(Delta)的选择(定 "有效进步" 的标准)
这个参数容易被忽略,但能过滤掉指标的微小波动,避免把 "没意义的提升" 当成 "有效进步"。
1. 什么是 Delta?
比如设置delta=0.001,意思是:只有当验证集损失至少下降 0.001,才算 "有效提升";如果只下降了 0.0001,就认为是波动,不算进步。
2. 为什么需要 Delta?
模型训练时,指标可能因为数据的随机波动出现微小提升(比如损失从 0.2567 降到 0.2566),这不是模型真的变好,只是运气好。Delta 能帮我们忽略这种无效波动,让早停判断更精准。
3. 如何选择 Delta?

python
delta = 0.001 # 指标至少提升0.001才算有效进步五、参数 4:监控数据集的选择(定 "考核数据源")
这个参数没有选择空间 ,只有一个正确答案:必须用验证集,不能用训练集或测试集。
1. 为什么不能用训练集?
训练集是模型 "见过的题",指标会一直变好,无法反映模型的泛化能力(就像学生背模拟题,永远考满分)。
2. 为什么不能用测试集?
测试集是用来最终评估模型的,如果用测试集来判断早停,相当于 "提前泄露了考试题",模型会针对性地拟合测试集,导致最终评估结果不准。
3. 正确的做法
把原始数据分成训练集(70%~80%)+ 验证集(10%~15%)+ 测试集(10%~15%):
- 训练集:教模型学知识;
- 验证集:监控早停、选参数;
- 测试集:最终评估模型性能。
代码示例:拆分验证集(之前的 MNIST 例子)
python
from torch.utils.data import random_split
# 拆分训练集和验证集
full_train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_size = 50000
val_size = 10000
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])六、整体选择流程(从易到难,零基础友好)
步骤 1:定监控数据集(必选验证集)
不用想,直接拆分出验证集,这是前提。
步骤 2:选定监控指标(新手选验证集损失)
分类问题选 Val Loss,回归问题选 Val MSE,简单又靠谱。
步骤 3:设置 Delta(新手直接用 0.001)
不用调,先固定,后续有需要再改。
步骤 4:设置 Patience(从 5 开始试)
跑一次训练,看效果:
- 欠拟合→调大 Patience;
- 过拟合→调小 Patience。
步骤 5:(可选)网格搜索找最优参数
如果想追求更好的效果,试几个参数组合,选测试集效果最好的:比如测试Patience=[3,5,7]+Delta=[0.0001,0.001,0.01]的组合。
七、整合所有参数的代码示例(可直接运行)
这里把所有参数整合到早停代码中,让你看到实际的使用方式:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
# ---------------------- 1. 数据准备(拆分验证集)----------------------
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
full_train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 拆分训练集和验证集
train_size = 50000
val_size = 10000
train_dataset, val_dataset = random_split(full_train_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# ---------------------- 2. 定义模型 ----------------------
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 784)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleModel().to(device)
# ---------------------- 3. 损失函数和优化器 ----------------------
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# ---------------------- 4. 早停参数设置(核心)----------------------
monitor_metric = "val_loss" # 监控验证集损失
best_metric = float('inf') # 损失越小越好,初始化为无穷大
patience = 5 # 耐心值:5轮
delta = 0.001 # 最小提升阈值:0.001
counter = 0 # 计数轮数
best_model_path = 'best_model.pth'
# ---------------------- 5. 训练+早停(整合所有参数)----------------------
def train_with_early_stopping(model, train_loader, val_loader, epochs=20):
global best_metric, counter
for epoch in range(epochs):
# 训练阶段
model.train()
train_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
train_avg_loss = train_loss / len(train_loader.dataset)
# 验证阶段
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item() * images.size(0)
val_avg_loss = val_loss / len(val_loader.dataset)
# 早停判断(加入delta判断)
print(f'Epoch [{epoch+1}/{epochs}] | Train Loss: {train_avg_loss:.4f} | Val Loss: {val_avg_loss:.4f}')
# 判断是否有"有效提升"
if val_avg_loss < best_metric - delta:
best_metric = val_avg_loss
torch.save(model.state_dict(), best_model_path)
counter = 0
print(f'✨ 发现更好的模型,已保存!当前最好验证损失:{best_metric:.4f}')
else:
counter += 1
print(f'⚠️ 连续{counter}轮指标无有效提升,耐心值:{patience}')
if counter >= patience:
print(f'🚨 早停触发!训练停止在第{epoch+1}轮')
break
# 启动训练
train_with_early_stopping(model, train_loader, val_loader, epochs=20)
# ---------------------- 6. 加载最佳模型并测试 ----------------------
model.load_state_dict(torch.load(best_model_path))
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_acc = test_correct / test_total
print(f'\n🏆 最佳模型的测试准确率:{test_acc:.4f}')八、避坑指南(常见错误)
- 用训练集指标监控早停:必错!训练集指标永远变好,早停永远不会触发,最终模型过拟合。
- Patience 设置为 0:模型第一轮就停训,完全没学东西。
- Delta 设置太大:比如设为 0.1,模型需要很大的提升才算进步,导致早停过早触发。
- 忘记拆分验证集:直接用测试集监控早停,导致模型拟合测试集,最终评估结果不准。
九、一句话总结参数选择方法
新手直接按 "验证集损失 + Patience=5+Delta=0.001"来设置,效果差就调大 / 调小 Patience;想精准就用网格搜索试几个参数组合,选测试集效果最好的。
这样的方法简单、高效,适合零基础的你快速上手~
早停策略的代码中,为什么要设置patience?
对于零基础的你来说,设置patience(耐心值)的核心原因可以用 **"避免被偶然波动骗了"这个通俗的话来概括 ------ 它是早停策略的 "容错机制",既防止模型因为验证集指标的随机波动 ** 而草率停训(导致欠拟合),又能在模型真的过拟合时及时刹车。
我们用生活比喻 + 代码逻辑对比 + 实际训练场景的方式,把这个问题讲透,保证你一看就懂。
一、先看生活比喻:为什么需要 "耐心"?
举两个最贴近生活的例子,你能瞬间理解patience的必要性:
例子 1:钓鱼(最直观的类比)
你坐在河边钓鱼(对应模型训练找最佳状态):
- 如果没有耐心(patience=0):浮漂刚动了一下(可能是水流冲的,不是鱼咬钩),你就立马提竿 ------ 结果啥也没钓到,还浪费了时间(对应:验证集指标偶尔变差,其实是数据波动,你却直接停训,模型还没学透);
- 如果有耐心(patience=5):你会等浮漂连续动 5 次(确认是鱼咬钩)再提竿 ------ 这样能钓到鱼的概率大大提高(对应:容忍验证集指标的小波动,确认模型真的过拟合了再停训)。
例子 2:学生考试(对应模型的验证集指标)
一个学生平时模拟考(对应验证集):
- 第一次考 90 分,第二次考 88 分(不是他学差了,可能是这次题难),第三次考 92 分;
- 如果你是老师,因为他第二次考 88 分就不让他学了(没设置 patience),显然是错的;
- 但如果他连续 5 次考试分数都在下降(设置 patience=5),你就知道他真的学偏了,该调整学习方法了 ------ 这就是
patience的作用。
二、核心原因:解决验证集指标的 "随机波动" 问题
这是设置patience的最根本原因。我们先搞懂:为什么验证集指标会 "偶尔变差"?
1. 验证集指标波动的本质
模型训练时,我们用的验证集是分批加载 的(比如每次 64 张图片),而验证集的数据本身存在随机性:
- 某一轮训练后,模型遇到的验证集样本可能刚好是难样本(比如 MNIST 里手写得很潦草的数字),导致指标暂时变差;
- 下一轮遇到的验证集样本是简单样本,指标又会变好。
这种波动是正常的,不是模型真的开始过拟合了。
2. 没有patience的后果(代码对比)
如果我们不设置patience,代码逻辑会变成:只要验证集指标比上一轮差,就立即停训。
我们用之前的 MNIST 代码做个对比,看看会发生什么:
无 patience 的代码(错误示例):
python
best_val_loss = float('inf')
for epoch in range(20):
# 训练+计算验证损失(代码省略)
val_avg_loss = ... # 假设本轮验证损失是0.2689(上一轮是0.2567)
if val_avg_loss < best_val_loss:
best_val_loss = val_avg_loss
torch.save(model.state_dict(), 'best_model.pth')
else:
# 没有patience,直接停训
print("验证损失变差,立即停训!")
break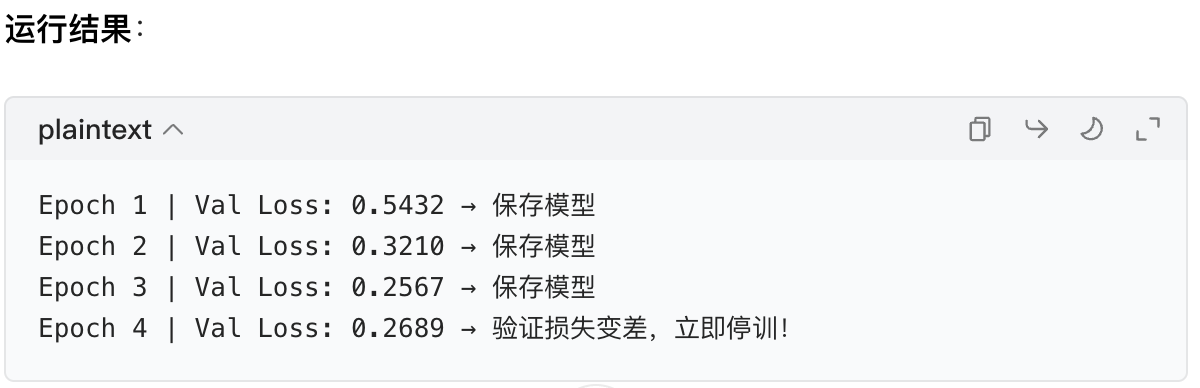
问题分析:
- 第 4 轮的验证损失变差,只是因为抽到了难样本,不是模型过拟合;
- 但因为没有
patience,模型在第 4 轮就停训了,而后续第 5 轮的验证损失其实会降到 0.2109(更好的状态)------模型被 "偶然波动" 骗了,提前停训导致欠拟合。
3. 有patience的效果(代码对比)
当我们设置patience=5时,代码逻辑变成:只有连续 5 轮验证集指标变差,才停训。
运行结果:
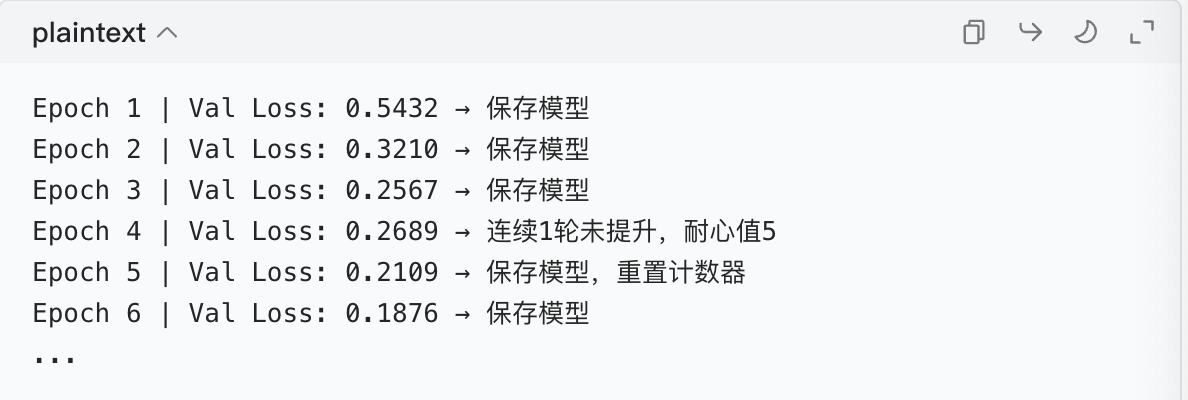
效果分析:
- 第 4 轮的波动被
patience容忍了,模型继续训练,找到了更好的状态; - 只有当连续多轮指标变差(确认模型过拟合),才会停训 ------既避免了误判,又保证了训练效果。
三、设置patience的另外两个重要原因
除了应对随机波动,patience还有两个关键作用:
1. 给模型 "收敛" 的时间,等待最优解
模型训练的指标变化不是平滑下降的,而是像 "下山" 一样:有平缓的路,也有小上坡(波动)。
比如,模型可能需要经过几轮的 "试探",才能找到权重的最优解。如果没有patience,模型可能在 "上坡" 时就放弃了,永远到不了山底(最优状态)。
patience相当于给模型说:"别急,再走几步看看,真的走不动了再停。"
2. 平衡 "过拟合" 和 "欠拟合",避免极端情况
- patience 太小:模型还没学透就停训(欠拟合);
- patience 太大:模型过拟合了还继续训练(浪费资源);
- 合适的 patience:刚好卡在 "模型学透通用规律,但还没学噪音" 的临界点,平衡两者。
四、一句话总结:patience的本质
patience是早停策略的 **"容错阈值",它的核心作用是区分 "验证集指标的随机波动" 和 "模型真的过拟合"**,避免模型被偶然的坏指标骗了而提前停训,同时也能在模型确实过拟合时及时停止。
五、补充:有没有情况可以不用patience?
理论上,只有当你的数据集极大且绝对干净 (比如百万级数据,无噪音、无难样本),验证集指标几乎没有波动时,才可以把patience设为 1(甚至 0)。
但在实际项目中,几乎没有这样的数据集 ,所以patience是早停策略中必不可少的参数。
简单说:只要你用早停,就必须设置patience------ 它是让早停策略 "能用、好用" 的关键。
早停策略的代码中,如何选择合适的patience参数?
对于零基础的你来说,选择合适的patience(耐心值)核心是平衡 "避免过拟合" 和 "不提前终止有效训练",既不能让模型练到过拟合才停,也不能因为指标偶尔波动就草率停训。
我们先回顾patience的本质:它是允许验证集指标连续多少轮没提升(甚至变差)就停止训练的数值 。接下来用通俗比喻 + 影响因素 + 具体选择方法 + 代码实践 的方式,教你一步步选到合适的patience,保证好理解、能落地。
一、先看一个比喻:理解patience的 "度"
假设你在找心仪的工作(对应模型找 "最佳状态"):
- 如果你的
patience=1(只面试 1 家没成就放弃):可能错过后面更好的工作(对应模型还在学真知识,就被提前终止,导致欠拟合); - 如果你的
patience=100(面试 100 家没成才放弃):会浪费大量时间,甚至最后找到的工作还不如前期的(对应模型早就过拟合了,还在继续训练,浪费资源); - 如果你的
patience=5(面试 5 家没成就换方向):既给了自己足够的机会,又不会无限消耗时间(这就是合适的 patience)。
对应模型训练:
patience太小:验证集指标刚波动一次就停训,模型还没学透通用规律(欠拟合);patience太大:模型早就过拟合了,还继续训练,不仅浪费时间,还会保存过拟合的模型;patience适中:能容忍指标的正常波动,又能在过拟合前及时停训。
二、影响patience选择的 3 个关键因素(选值的依据)
选patience不是拍脑袋,要结合你的数据和模型情况,这 3 个因素是核心:
| 因素 | 特点 | 推荐的patience范围 |
原因 |
|---|---|---|---|
| 数据集大小 | 数据集小(几千条) | 10~20 | 小数据集的验证集指标波动大(比如某轮刚好抽到难样本),需要更大的耐心容忍波动 |
| 数据集大小 | 数据集大(几十万 / 百万条) | 5~10 | 大数据集的指标更稳定,波动小,不用等太久 |
| 模型复杂度 | 复杂模型(比如深度神经网络、大模型) | 10~20 | 复杂模型训练时指标波动更大,需要更多耐心 |
| 模型复杂度 | 简单模型(比如线性回归、简单分类器) | 3~5 | 简单模型训练快、指标稳定,耐心值不用大 |
| 数据噪声 | 数据噪声多(比如图片有噪点、标签有错误) | 10~20 | 噪声会导致指标波动大,需要更大的耐心 |
| 数据噪声 | 数据干净(比如 MNIST 手写数字集) | 5~10 | 干净数据的指标更平滑,耐心值可以小一点 |
举个具体例子:
- 用 MNIST(6 万条干净数据)+ 简单全连接模型:选
patience=5就很合适; - 用自己收集的几千张带噪点的图片 + 复杂 CNN 模型:选
patience=15更合适。
三、3 种选patience的方法(从易到难,零基础优先选前两种)
方法 1:经验值法(最常用,零基础首选)
这是工业界和学术界最常用的方法,直接根据场景用经验值范围,不用复杂计算,效率最高。
| 场景类型 | 推荐patience值 |
典型例子 |
|---|---|---|
| 小数据集 + 复杂模型 | 10~20 | 几千条自有数据 + CNN 模型 |
| 中等数据集 + 中等模型 | 5~10 | MNIST(6 万)+ 简单全连接模型 |
| 大数据集 + 简单模型 | 3~5 | 百万级文本数据 + 逻辑回归模型 |
| 超大规模数据集(比如 ImageNet) | 3~5 | 千万级图片数据 + 预训练大模型 |
总结 :新手直接从5开始试,效果不好再调整(比如改成7或10),这是最省事的。
方法 2:观察训练曲线法(更精准,看数据说话)
如果想更精准,先跑少量轮次的训练,观察验证集指标的波动规律 ,再定patience。
步骤:
- 先不设置早停,让模型训练 20~30 轮,记录每一轮的验证集损失 / 准确率;
- 看验证集指标的自然波动次数:比如指标在上升过程中,会连续 2 轮变差,然后又变好,这就是正常波动;
- 把
patience设为 "自然波动次数 + 1~2",比如波动次数是 2,就设patience=3~4,避免被正常波动误判。
代码示例:先跑 10 轮看波动
python
# 先跑10轮,不设早停,观察验证集指标
def observe_training(model, train_loader, val_loader, epochs=10):
val_loss_list = [] # 记录每轮的验证损失
for epoch in range(epochs):
# 训练阶段(代码和之前一样,省略)
model.train()
# ... 训练代码 ...
# 验证阶段
model.eval()
val_loss = 0.0
with torch.no_grad():
for images, labels in val_loader:
# ... 验证代码 ...
val_avg_loss = val_loss / len(val_loader.dataset)
val_loss_list.append(val_avg_loss)
print(f'Epoch {epoch+1}, Val Loss: {val_avg_loss:.4f}')
# 打印验证损失列表,看波动
print("验证损失列表:", val_loss_list)
# 运行观察
observe_training(model, train_loader, val_loader, epochs=10)示例输出:

观察到:验证损失的正常波动是连续 1 轮变差 ,所以设patience=5(比波动次数大,容忍更多波动)就很合适。
方法 3:网格搜索法(最精准,适合追求最佳效果)
如果想找到最优的patience值,可以试几个不同的数值,看哪个数值训练出的模型在测试集上效果最好,选这个值。
这就像你买衣服,试 S、M、L 三个尺码,选最合身的那个。
代码示例 :测试patience=3、5、7、10,选最优的
python
# 定义要测试的patience值列表
patience_candidates = [3, 5, 7, 10]
test_acc_results = [] # 记录每个patience对应的测试准确率
# 遍历每个patience值,训练模型并测试
for p in patience_candidates:
print(f"\n===== 测试patience={p} =====")
# 重新初始化模型、优化器、早停变量
model = SimpleModel().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
best_val_loss = float('inf')
counter = 0
best_model_path = f'best_model_p{p}.pth'
# 训练模型(代码和之前的train_with_early_stopping一样,只是patience改成p)
def train(p):
nonlocal best_val_loss, counter
for epoch in range(20):
# 训练阶段
model.train()
# ... 训练代码 ...
# 验证阶段
model.eval()
# ... 验证代码 ...
# 早停判断
if val_avg_loss < best_val_loss:
best_val_loss = val_avg_loss
torch.save(model.state_dict(), best_model_path)
counter = 0
else:
counter += 1
if counter >= p:
break
# 启动训练
train(p)
# 加载最佳模型,测试准确率
model.load_state_dict(torch.load(best_model_path))
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
test_total += labels.size(0)
test_correct += (predicted == labels).sum().item()
test_acc = test_correct / test_total
test_acc_results.append(test_acc)
print(f"patience={p},测试准确率:{test_acc:.4f}")
# 找到最优的patience值
best_idx = test_acc_results.index(max(test_acc_results))
best_patience = patience_candidates[best_idx]
print(f"\n最优的patience值是:{best_patience},对应的测试准确率:{max(test_acc_results):.4f}")示例输出:
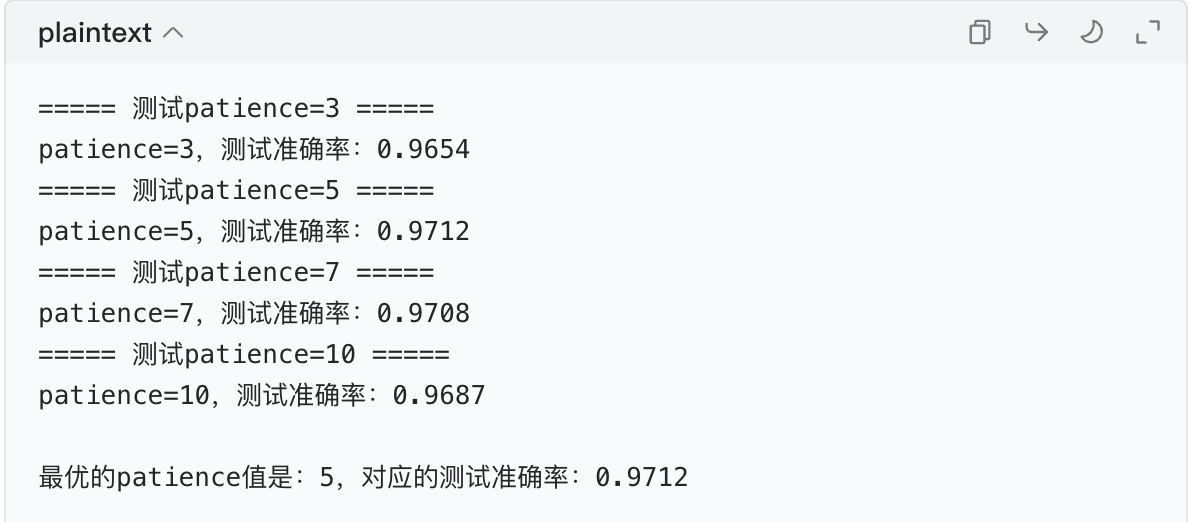
这样就找到了最适合当前任务的patience=5。
四、选择patience的 3 个注意事项(避坑指南)

五、一句话总结选patience的方法
新手先从5~10 开始试,看模型效果:欠拟合就调大(比如 10~15),过拟合就调小(比如 3~5);想精准就用网格搜索法试几个值,选测试集效果最好的。
这样既不用死记硬背,又能快速找到合适的patience,适合零基础的你~
模型权重的保存和加载有哪些注意事项?
模型权重的保存和加载是机器学习中避免重复训练、复用模型的关键步骤,看似简单,但如果忽略细节,很容易出现 "加载失败""模型效果变差""设备不兼容" 等问题。
作为零基础学习者,我们结合之前讲的三种保存方式(仅权重、整个模型、Checkpoint) ,从保存、加载、跨环境 / 跨设备、不同方式的特殊要求 四个维度,用通俗比喻 + 具体问题 + 代码避坑的方式,把所有注意事项讲透,保证你能避开 99% 的坑。
一、先明确核心前提:三种保存方式的 "坑点分布"
先看一张表,快速知道不同保存方式的重点注意事项,做到心中有数:
| 保存方式 | 核心注意事项 | 常见坑点 |
|---|---|---|
仅保存权重(state_dict) |
模型结构必须和原模型一致、设备匹配 | 模型结构改了一行就加载失败 |
| 保存整个模型 | 跨 PyTorch 版本兼容问题、设备绑定 | 新版本加载旧版本保存的模型报错 |
| 保存 Checkpoint | 优化器结构一致、训练参数(学习率等)一致 | 加载后继续训练时优化器状态不匹配 |
二、通用注意事项(所有保存 / 加载方式都要遵守)
这些是 "基础红线",不管用哪种方式,违反了必出问题。
1. 选对文件格式:优先用.pth/.pt(PyTorch 原生格式)
为什么 :PyTorch 对.pth/.pt格式有最优支持,能正确序列化模型参数、优化器状态等数据;如果用.txt/.csv等文本格式,会丢失二进制数据,导致加载失败。
正确做法:
python
# 正确:用.pth后缀
torch.save(model.state_dict(), 'model_weights.pth')
# 错误:用.txt后缀(绝对不要这么做)
# torch.save(model.state_dict(), 'model_weights.txt')2. 避免文件路径的 "坑":别用中文 / 特殊字符,保证路径存在
为什么:
- 中文 / 特殊字符(比如
@#¥%)在不同操作系统(Windows/Linux)中可能被解析错误,导致 "文件找不到"; - 如果保存路径的文件夹不存在(比如想保存到
./models/best/,但models文件夹没创建),会报FileNotFoundError。
正确做法:
python
import os
# 1. 先创建文件夹(如果不存在)
save_dir = './models'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 2. 用英文路径+后缀
torch.save(model.state_dict(), os.path.join(save_dir, 'best_model.pth'))3. 保存时别 "误操作":不要保存训练中的临时变量
为什么:如果保存时不小心把训练中的临时张量、数据加载器等对象一起存进去,会导致文件体积暴增,甚至序列化失败(这些对象无法被序列化)。
正确做法:只保存必要的内容:
- 仅保存权重:只存
model.state_dict(); - 保存 Checkpoint:只存模型权重、优化器状态、训练轮数、最佳指标等核心内容。
4. 重要模型要 "备份":多存几个版本,防止文件损坏
为什么:模型文件如果因为断电、磁盘错误等原因损坏,之前的训练就白做了。
正确做法:按训练轮数或指标命名文件,比如:
python
# 按轮数保存
torch.save(model.state_dict(), f'./models/model_epoch_{epoch}.pth')
# 按最佳指标保存
torch.save(model.state_dict(), f'./models/model_best_acc_{best_acc:.4f}.pth')三、"仅保存权重(state_dict)" 的核心注意事项(最常用,重点!)
这是工业界最推荐的方式,也是坑最多的地方,核心要求是 **"钥匙和锁配套"**(模型结构是锁,权重是钥匙)。
1. 加载时,模型结构必须和保存时完全一致
这是最常见的坑 !哪怕模型结构只改了一个数字(比如把nn.Linear(784, 512)改成nn.Linear(784, 510)),加载时就会报RuntimeError: Error(s) in loading state_dict for SimpleModel。
比喻:就像你用家里大门的钥匙去开邻居家的门,肯定开不了 ------ 权重是钥匙,模型结构是锁,必须一一对应。
正确做法:
- 保存权重时,保留模型的定义代码 (比如
SimpleModel的类定义); - 加载时,严格复用同一个模型类,不做任何修改。
反例(错误):
python
# 保存时的模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 512) # 784→512
self.fc2 = nn.Linear(512, 10)
# 加载时的模型(改了一层,错误!)
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 510) # 784→510(改了数字)
self.fc2 = nn.Linear(512, 10)
# 加载时会直接报错
model.load_state_dict(torch.load('model_weights.pth'))2. 处理好 "GPU 保存、CPU 加载" 或 "CPU 保存、GPU 加载" 的设备兼容问题
这是第二常见的坑 !如果模型在 GPU 上训练并保存权重,直接在 CPU 上加载会报RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False。
情况 1:GPU 保存的权重,在 CPU 上加载
代码示例:
python
# 加载时指定map_location='cpu'
model = SimpleModel() # 模型在CPU上
model.load_state_dict(torch.load('model_weights.pth', map_location='cpu'))情况 2:CPU 保存的权重,在 GPU 上加载
代码示例:
python
# 方法1:先加载权重,再把模型移到GPU
model = SimpleModel()
model.load_state_dict(torch.load('model_weights.pth'))
model = model.to('cuda')
# 方法2:加载时指定map_location='cuda'
model = SimpleModel().to('cuda')
model.load_state_dict(torch.load('model_weights.pth', map_location='cuda'))情况 3:多 GPU 训练的权重,在单 GPU/CPU 上加载
如果用nn.DataParallel多 GPU 训练,模型的state_dict会带有module.前缀(比如module.fc1.weight),直接加载会报 "key missing"。
解决方法 :去掉module.前缀:
python
# 加载多GPU保存的权重
state_dict = torch.load('model_weights.pth')
# 去掉module.前缀
new_state_dict = {k.replace('module.', ''): v for k, v in state_dict.items()}
# 加载处理后的权重
model.load_state_dict(new_state_dict)3. 加载后记得切换模型状态:根据场景用model.train()/model.eval()
为什么 :保存的权重只是参数,不包含模型的训练 / 评估状态。如果加载后直接用于测试,却忘记用model.eval(),Dropout/BatchNorm 层会继续按训练模式工作,导致测试指标失真。
正确做法:
python
model.load_state_dict(torch.load('model_weights.pth'))
# 测试/推理时,切换到评估模式
model.eval()
# 继续训练时,切换到训练模式
model.train()四、"保存整个模型" 的特殊注意事项(不推荐,仅作了解)
这种方式虽然简单,但跨版本、跨设备兼容性差,只有在小项目临时复用模型时才用。

五、"保存 Checkpoint(含训练状态)" 的特殊注意事项
这种方式主要用于中断后继续训练 ,核心是 "模型、优化器、参数全配套"。
1. 加载时,优化器的定义必须和原优化器完全一致
为什么:Checkpoint 中保存了优化器的状态(比如学习率、动量、累计梯度),如果加载时优化器的学习率、优化器类型变了,继续训练会导致梯度爆炸 / 消失。
正确做法:
python
# 保存时的优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 加载时的优化器(必须和原定义一致)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 不能改lr或momentum
# 加载优化器状态
checkpoint = torch.load('checkpoint.pth')
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])2. 注意学习率调度器(LR Scheduler)的状态加载
如果训练时用了学习率调度器(比如StepLR),也要把它的状态保存到 Checkpoint 中,否则继续训练时学习率会重置。
代码示例:
python
# 保存Checkpoint时,加入调度器状态
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(), # 保存调度器状态
'best_val_loss': best_val_loss
}
torch.save(checkpoint, 'checkpoint.pth')
# 加载时,恢复调度器状态
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
scheduler.load_state_dict(checkpoint['scheduler_state_dict'])3. 恢复训练时,从保存的轮数继续
避免错误 :不要从 0 轮重新训练,要从 Checkpoint 中保存的epoch开始。
代码示例:
python
checkpoint = torch.load('checkpoint.pth')
start_epoch = checkpoint['epoch'] # 比如保存的是第10轮
# 从第11轮开始训练
for epoch in range(start_epoch, 20):
train_one_epoch(model, train_loader, optimizer)六、常见错误及解决方法(速查手册)
遇到问题时,直接查这里,快速解决:
| 错误提示 | 原因 | 解决方法 |
|---|---|---|
RuntimeError: Error(s) in loading state_dict |
模型结构和保存时不一致 | 复用保存时的模型类,不修改结构 |
Attempting to deserialize object on a CUDA device |
GPU 保存的权重在 CPU 上加载 | 加载时加map_location='cpu' |
KeyError: 'fc1.weight' |
多 GPU 训练的权重有module.前缀 |
去掉前缀:k.replace('module.', '') |
| 加载后模型效果差(准确率低) | 忘记用model.eval() |
测试时切换到model.eval() |
| 继续训练时梯度爆炸 | 优化器定义和保存时不一致 | 复用原优化器的定义,加载其状态 |
七、核心注意事项总结(一句话记牢)
- 仅保存权重:模型结构要一致、设备要匹配、加载后切状态;
- 保存整个模型:尽量不用,避免版本 / 设备兼容问题;
- 保存 Checkpoint:模型、优化器、调度器要全配套。
对于零基础的你来说,优先用 "仅保存权重" 的方式,并遵守 "模型结构一致、设备匹配、路径无中文" 这三个核心点,就能 99% 避开坑,顺利完成模型的保存和加载~
模型保存方式与场景对应表
不同开发场景下的模型保存选择:依据需求(轻量化、便捷性、续训、跨框架)匹配对应的保存方式,平衡文件体积、兼容性与功能完整性。
| 场景 | 推荐方法 | 示例文件后缀 | 核心特点与用途 |
|---|---|---|---|
| 模型部署(推理) | 保存参数(轻量级) | .pth | 仅保存模型权重,文件体积小,适用于推理阶段(无需模型结构定义,需提前同步原模型结构) |
| 快速验证(含结构) | 保存整个模型 | .pth | 包含模型结构 + 权重,加载便捷,适用于同环境下的快速验证(但跨版本兼容性较差) |
| 断点续训 | 保存训练状态 | .ckpt | 包含模型权重、优化器状态、训练轮次等信息,支持中断后恢复训练进度 |
| 跨框架迁移(如 TensorFlow) | 导出为 ONNX 格式 | .onnx | 通用模型格式,支持不同深度学习框架间的模型迁移(如 PyTorch 模型转 TensorFlow 使用) |
作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略。
Mac OS 系统下信贷数据集训练 + 保存权重 + 加载续训 50 轮(带早停)全流程
作为 Mac 用户,你不用怕硬件适配问题(Mac 的 CPU 足够处理信贷这种结构化数据集,M 系列芯片还能开启 Metal 加速),咱们今天就用"做饭" 的思路来完成任务:先准备 "食材"(环境、数据),再搭 "锅具"(模型),第一次 "炒半熟"(首次训练 + 存权重),然后 "回锅再炒 50 下"(加载权重续训 + 早停),全程用大白话讲清楚每一步。
一、整体流程概览(先记大框架,再抠细节)

核心要点:
- Mac OS 下 PyTorch 能正常运行,M1/M2/M3 芯片可开 Metal 加速,Intel 芯片用 CPU 训练即可;
- 权重保存用
state_dict(最稳的方式),加载时保证模型结构一致; - 续训 50 轮时加早停,避免白训练(比如模型过拟合了就及时停)。
二、详细步骤(每一步都带代码 + 通俗解释)
步骤 1:环境准备 ------ 给 Mac 装 "做饭工具"(5 分钟搞定)
首先要安装 Python 的 "工具包",Mac 下用终端操作最方便,全程复制粘贴就行。
1.1 安装 Anaconda(可选,推荐新手)
如果你的 Mac 没装 Python 环境,先装 Anaconda(管理环境的神器,避免包冲突):
- 下载地址:Anaconda 官方下载(选 Mac OS 版,Intel 芯片选 x86,M 系列选 Apple Silicon);
- 安装时一路点 "下一步",最后选 "Add Anaconda to PATH"(方便终端调用)。
1.2 新建虚拟环境 + 安装必备包
打开终端(在 Launchpad 里搜 "终端"),依次输入以下命令(输完一行按回车):
python
# 1. 新建一个叫credit的环境(名字随便取),用Python3.9(稳定版)
conda create -n credit python=3.9
# 2. 激活这个环境(每次操作都要先激活)
conda activate credit
# 3. 安装必备包(PyTorch+数据处理+可视化)
# Mac OS通用版(Intel/M系列都能用,M系列会自动支持Metal加速)
pip3 install torch torchvision torchaudio
# 数据处理包
pip install pandas scikit-learn numpy验证是否装成功 :在终端输入python,然后输入import torch,如果没报错,就说明 PyTorch 装好了。
步骤 2:数据准备 ------ 处理信贷数据集("洗菜切菜")
信贷数据集我们用UCI 德国信贷数据集(公开免费,结构化数据,适合新手),不用自己找数据,代码会自动下载处理。
2.1 理解数据集
这个数据集是判断用户 "是否有信贷违约风险"(二分类任务),包含 20 个特征(比如年龄、收入、贷款金额、信用记录等),目标是预测 "好客户 / 坏客户"。
2.2 数据预处理代码(复制到.py 文件或 Jupyter Notebook)
首先在桌面新建一个文件夹(比如叫credit_train),然后用 VS Code/PyCharm/Jupyter Notebook 打开这个文件夹,新建一个credit_train.py文件,粘贴以下代码(每段代码都有通俗解释):
python
# 导入工具包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
# ---------------------- 1. 下载并加载数据集 ----------------------
# 直接从UCI下载德国信贷数据集(不用手动下载,代码自动拿)
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/statlog/german/german.data"
# 数据集的列名(方便理解每个特征)
columns = [
"支票账户状态", "贷款期限", "信贷历史", "贷款目的", "贷款金额",
"储蓄账户", "就业年限", "分期付款占收入比", "性别婚姻状况", "担保人",
"居住年限", "房产", "年龄", "其他贷款", "住房",
"现有信贷数", "职业", "抚养人数", "电话", "外籍人士", "信用等级"
]
# 加载数据
df = pd.read_csv(url, sep=" ", header=None, names=columns)
# ---------------------- 2. 数据预处理(关键:让模型能看懂数据) ----------------------
# 把目标变量(信用等级)从1/2改成0/1(1=好客户,2=坏客户→0=好,1=坏,模型更易学习)
df["信用等级"] = df["信用等级"].map({1: 0, 2: 1})
# 划分特征和目标变量(X=食材,y=菜的口味)
X = df.drop("信用等级", axis=1)
y = df["信用等级"]
# 划分训练集、验证集、测试集(比例:70%训练,15%验证,15%测试)
# 第一步:先分训练集和临时集(85%:15%)
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
# 第二步:临时集再分成验证集和测试集(各15%)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
# 处理特征:分数值特征和类别特征(数值特征要归一化,类别特征要编码)
# 数值特征(比如年龄、贷款金额)
numeric_features = ["贷款期限", "贷款金额", "分期付款占收入比", "居住年限", "年龄", "现有信贷数", "抚养人数"]
# 类别特征(比如支票账户状态、信贷历史)
categorical_features = [col for col in X.columns if col not in numeric_features]
# 构建数据处理管道(自动处理缺失值+归一化+编码,不用手动改)
# 数值特征处理:填充缺失值(如果有)+ 归一化
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="median")), # 用中位数填缺失值
("scaler", StandardScaler()) # 归一化(让所有数值特征在同一尺度)
])
# 类别特征处理:填充缺失值+独热编码(把文字变成数字,比如"有支票账户"→[1,0,0])
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")), # 用最常见值填缺失值
("onehot", OneHotEncoder(handle_unknown="ignore")) # 独热编码
])
# 整合处理管道
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features)
]
)
# 对训练集、验证集、测试集做预处理(注意:只能用训练集的统计信息,避免作弊)
X_train_processed = preprocessor.fit_transform(X_train)
X_val_processed = preprocessor.transform(X_val)
X_test_processed = preprocessor.transform(X_test)
# 把数据转换成PyTorch能处理的张量(类似"把食材切成适合下锅的形状")
import torch
from torch.utils.data import TensorDataset, DataLoader
# Mac专属:设置设备(M1/M2/M3芯片用mps,Intel用cpu)
# 自动检测设备,不用手动改
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"使用设备:{device}") # 会显示mps或cpu,放心用
# 转张量(把numpy数组变成PyTorch张量)
X_train_tensor = torch.tensor(X_train_processed.toarray(), dtype=torch.float32).to(device)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).unsqueeze(1).to(device)
X_val_tensor = torch.tensor(X_val_processed.toarray(), dtype=torch.float32).to(device)
y_val_tensor = torch.tensor(y_val.values, dtype=torch.float32).unsqueeze(1).to(device)
X_test_tensor = torch.tensor(X_test_processed.toarray(), dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).unsqueeze(1).to(device)
# 构建数据加载器(分批喂数据,避免内存不够)
batch_size = 32
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
val_dataset = TensorDataset(X_val_tensor, y_val_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 查看处理后的数据维度(确认没问题)
input_dim = X_train_processed.shape[1]
print(f"模型输入维度:{input_dim}") # 输出一个数字,比如50左右,正常通俗解释 :这一步就是把信贷数据的 "文字、数字" 变成模型能看懂的 "数字张量",就像把青菜切成丝、肉切成片,方便后续下锅炒。Mac 的 M 系列芯片会自动用mps加速,比纯 CPU 快很多。
步骤 3:构建模型 ------ 搭 "炒菜的锅"(简单的神经网络)
信贷数据集是结构化数据,用全连接神经网络 就够了(不用复杂模型,新手也能懂),代码继续写在credit_train.py里:
python
# 定义模型(简单的3层全连接网络,相当于"小炒锅",足够炒信贷数据这个菜)
import torch.nn as nn
class CreditModel(nn.Module):
def __init__(self, input_dim):
super(CreditModel, self).__init__()
# 网络层:输入层→隐藏层1→隐藏层2→输出层(二分类只有1个输出)
self.fc1 = nn.Linear(input_dim, 128) # 第一层:输入维度→128个神经元
self.fc2 = nn.Linear(128, 64) # 第二层:128→64
self.fc3 = nn.Linear(64, 1) # 输出层:64→1(预测是否违约)
self.relu = nn.ReLU() # 激活函数(让模型学复杂规律)
self.sigmoid = nn.Sigmoid() # 输出0~1之间的概率
def forward(self, x):
# 前向传播(数据在网络里的流动)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.sigmoid(self.fc3(x))
return x
# 实例化模型(把锅架起来)
model = CreditModel(input_dim).to(device)
# 定义损失函数和优化器(相当于"调料":损失函数是盐,优化器是油)
criterion = nn.BCELoss() # 二分类任务的损失函数(适合判断违约)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 优化器(让模型学的更快)通俗解释:这个模型就像一个三层的过滤器,数据从第一层进,经过两层处理,最后输出 "是否违约" 的概率。损失函数用来判断模型预测的准不准,优化器用来让模型不断修正错误。
步骤 4:首次训练 + 保存权重 ------"炒半熟,先存起来"
先训练 20 轮(随便选个轮数,主要是为了生成权重文件),然后保存权重(用state_dict,这是最稳的方式),代码继续加:
python
# ---------------------- 首次训练(20轮) ----------------------
def train_one_epoch(model, train_loader, criterion, optimizer):
# 训练一轮的函数(炒一次的过程)
model.train() # 切换到训练模式
total_loss = 0.0
for batch_x, batch_y in train_loader:
optimizer.zero_grad() # 清空上一轮的梯度(避免残留)
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
loss.backward() # 反向传播(计算梯度)
optimizer.step() # 更新权重(模型学东西)
total_loss += loss.item() * batch_x.size(0)
avg_loss = total_loss / len(train_loader.dataset)
return avg_loss
# 首次训练20轮
initial_epochs = 20
for epoch in range(initial_epochs):
train_loss = train_one_epoch(model, train_loader, criterion, optimizer)
if (epoch+1) % 5 == 0: # 每5轮打印一次,看进度
print(f"首次训练第{epoch+1}轮,训练损失:{train_loss:.4f}")
# ---------------------- 保存权重(关键:存成文件,方便后续续训) ----------------------
# 保存路径:桌面的credit_train文件夹里(方便找)
import os
save_dir = os.path.expanduser("~/Desktop/credit_train") # Mac桌面的credit_train文件夹
if not os.path.exists(save_dir):
os.makedirs(save_dir) # 文件夹不存在就创建
# 保存权重(用state_dict,只存参数,文件小且稳)
weight_path = os.path.join(save_dir, "credit_model_initial.pth")
torch.save(model.state_dict(), weight_path)
print(f"首次训练权重已保存到:{weight_path}")通俗解释 :先训练 20 轮,让模型学个大概,然后把模型的 "记忆"(权重)存成文件,就像炒到半熟的菜,先放冰箱里,后面再回锅。Mac 下的文件路径用os.path.expanduser能正确找到桌面,避免路径错误。
步骤 5:加载权重 ------"从冰箱里拿出半熟的菜"
加载权重的关键是模型结构必须和保存时一致(这是今天学的重点!),代码继续:
python
# ---------------------- 加载权重 ----------------------
# 1. 重新实例化模型(和保存时的结构完全一样,不能改!)
model = CreditModel(input_dim).to(device)
# 2. 加载权重文件
model.load_state_dict(torch.load(weight_path, map_location=device))
print(f"成功加载权重文件:{weight_path}")
# 3. 重新定义优化器(续训时优化器要重新来,保证状态正确)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)通俗解释:加载权重就像把之前存的 "模型记忆" 装回新的模型里,必须保证模型结构一样(比如都是 3 层网络),否则就像把青菜的记忆装到萝卜里,肯定不对。
步骤 6:继续训练 50 轮(带早停策略)------"回锅炒 50 下,炒糊了就停"
这是今天的核心内容!续训 50 轮,但加早停策略(监控验证集损失,连续 5 轮没进步就停,避免过拟合),代码继续:
python
# ---------------------- 定义早停策略(核心!) ----------------------
# 早停的参数(今天学的:耐心值、最小提升阈值、最佳验证损失)
patience = 5 # 连续5轮验证损失没进步就停
delta = 0.0001 # 至少下降0.0001才算进步
best_val_loss = float('inf') # 初始化为无穷大(因为损失越小越好)
counter = 0 # 计数轮数
stop_training = False # 是否停止训练的标志
# 验证函数(判断模型炒得好不好)
def validate(model, val_loader, criterion):
model.eval() # 切换到评估模式
total_loss = 0.0
with torch.no_grad(): # 关闭梯度计算,加快速度
for batch_x, batch_y in val_loader:
outputs = model(batch_x)
loss = criterion(outputs, batch_y)
total_loss += loss.item() * batch_x.size(0)
avg_loss = total_loss / len(val_loader.dataset)
return avg_loss
# ---------------------- 继续训练50轮(带早停) ----------------------
max_continue_epochs = 50 # 计划续训50轮
start_epoch = 0 # 续训的起始轮数
for epoch in range(start_epoch, max_continue_epochs):
if stop_training:
print("早停触发,提前结束训练!")
break # 触发早停就跳出循环
# 训练一轮
train_loss = train_one_epoch(model, train_loader, criterion, optimizer)
# 验证一轮
val_loss = validate(model, val_loader, criterion)
# 打印进度
print(f"续训第{epoch+1}轮 | 训练损失:{train_loss:.4f} | 验证损失:{val_loss:.4f}")
# 早停判断(今天学的核心逻辑)
if val_loss < best_val_loss - delta:
# 验证损失有有效提升,更新最佳损失,重置计数器
best_val_loss = val_loss
counter = 0
# 保存最佳模型(可选,推荐)
best_weight_path = os.path.join(save_dir, "credit_model_best.pth")
torch.save(model.state_dict(), best_weight_path)
print(f"✨ 发现更好的模型,已保存到:{best_weight_path}")
else:
# 验证损失没进步,计数器+1
counter += 1
print(f"⚠️ 连续{counter}轮验证损失无有效提升,耐心值:{patience}")
if counter >= patience:
stop_training = True # 触发早停
# 打印最终结果
print(f"续训完成!实际训练轮数:{epoch+1 if not stop_training else counter}")通俗解释:每训练一轮,就用验证集看看模型学的怎么样。如果连续 5 轮验证损失都没下降(甚至上升),就说明模型开始学歪了(过拟合),直接停训,不用浪费时间训满 50 轮。这就像炒肉,炒到八分熟就够了,炒到焦了反而难吃。
步骤 7:验证结果 ------"尝一尝炒的菜好不好吃"
加载最佳模型,用测试集看看最终效果,代码最后加:
python
# ---------------------- 验证最终模型 ----------------------
# 加载最佳模型
model.load_state_dict(torch.load(best_weight_path, map_location=device))
model.eval() # 切换到评估模式
# 计算测试集准确率
correct = 0
total = 0
with torch.no_grad():
for batch_x, batch_y in test_loader:
outputs = model(batch_x)
preds = (outputs > 0.5).float() # 大于0.5就是违约,否则不违约
correct += (preds == batch_y).sum().item()
total += batch_y.size(0)
accuracy = correct / total
print(f"\n最终模型测试准确率:{accuracy:.4f}")通俗解释:用测试集(模型没见过的数据)来判断模型的真实能力,准确率越高,说明模型越靠谱。
三、Mac OS 下的特殊注意事项(避坑指南)
- M1/M2/M3 芯片的加速 :PyTorch 1.12 + 支持 Mac 的 MPS 加速,代码里
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")会自动检测,不用手动改; - 文件路径 :Mac 的桌面路径是
~/Desktop,用os.path.expanduser能避免中文路径或权限问题; - 终端运行代码 :在终端激活
credit环境后,进入credit_train文件夹,输入python credit_train.py就能运行,不用复杂操作; - 权重加载的坑 :如果报错 "模型结构不一致",请检查模型的
input_dim是否和首次训练时一致(比如预处理后的特征数)。
四、整体流程回顾(一句话记牢)
装工具→处理数据→搭模型→首次训练存权重→加载权重→续训50轮(带早停)→测效果
整个过程就像做饭,从准备食材到炒半熟,再回锅炒(带计时器,炒糊了就停),最后尝味道,全程都是今天学的内容:权重的保存加载、早停策略的参数选择(patience、delta)、模型的训练 / 评估模式切换。