知识点回顾:
- tensorboard 的发展历史和原理
- tensorboard 的常见操作
- tensorboard 在 cifar 上的实战:MLP 和 CNN 模型
你作为零基础的 Python 和机器学习学习者,想要系统掌握 TensorBoard 的核心知识(发展历史与原理、常见操作、CIFAR 数据集上的 MLP/CNN 实战),我会用最通俗的语言、贴近生活的例子,配合完整的代码步骤,一步步拆解,确保你能完全理解。
一、TensorBoard 的发展历史和原理(零基础友好版)
1. 发展历史:一句话讲清
TensorBoard 是TensorFlow 官方配套的可视化工具,最早在 2015 年随 TensorFlow 1.x 一起发布(当时 TensorFlow 刚开源);2019 年 TensorFlow 2.x 重构后,TensorBoard 变得更易用(比如和 Keras 深度整合),现在不仅支持 TensorFlow,还能适配 PyTorch 等框架,是机器学习领域最常用的 "可视化仪表盘"。
2. 核心原理:用生活例子讲透
先给你一个核心比喻:
你可以把训练机器学习模型比作 "熬一锅汤":
- 汤的味道(模型准确率)、火候大小(损失值)、食材比例(模型权重)是关键指标;
- 如果只看数字(比如 "第 10 步损失 = 0.8,第 20 步 = 0.7"),很难直观判断汤熬得好不好;
- TensorBoard 就是 "厨房仪表盘":把这些数字转换成曲线图、结构图、图片,让你一眼看清 "熬汤进度"。
原理拆解(3 个核心步骤)
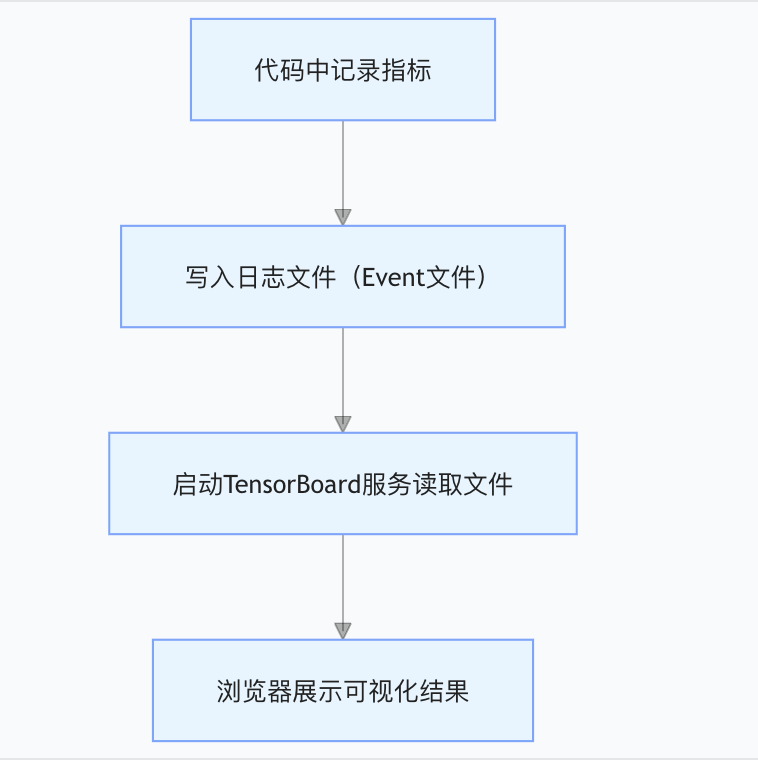
- 数据写入:在训练代码里,告诉 TensorBoard "要记录哪些指标"(比如每步的损失、准确率),这些数据会被保存到指定文件夹的 "Event 文件" 里(类似熬汤时记的 "烹饪日志");
- 服务启动:在终端输入命令,让 TensorBoard "读取烹饪日志";
- 网页展示:打开浏览器,就能看到可视化的指标曲线、模型结构图等(类似看仪表盘)。
二、TensorBoard 的常见操作(手把手教)
前置准备:安装
TensorBoard 是 TensorFlow 的配套工具,安装 TensorFlow 后自动附带,执行以下命令安装(新手建议用 pip):

pip install tensorflow # 安装TensorFlow(含TensorBoard)
操作 1:基础使用(记录模拟的 "损失值")
先写一段极简代码,模拟训练时的损失值变化,带你走完 "写入日志→启动 TensorBoard→查看结果" 的完整流程。
步骤 1:编写代码(写入模拟损失值)
python
# 导入TensorFlow库(零基础记:import是"拿工具")
import tensorflow as tf
# 导入时间模块,生成唯一日志文件夹(避免覆盖)
from datetime import datetime
# 1. 创建日志文件夹(格式:logs/年-月-日_时-分-秒)
log_dir = f"logs/basic/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
# 2. 初始化"日志写入器"(相当于打开"烹饪日志本")
writer = tf.summary.create_file_writer(log_dir)
# 3. 模拟训练100步,记录每步的损失值(损失从10逐渐降到1)
with writer.as_default(): # 表示接下来的记录都写入这个日志
for step in range(100):
# 模拟损失值:step越大,损失越小(符合训练规律)
loss = 10 - step * 0.09
# 记录标量(scalar):参数1=指标名,参数2=指标值,参数3=步数
tf.summary.scalar('训练损失', loss, step=step)
# 强制写入(避免数据缓存)
writer.flush()
# 4. 关闭写入器(相当于写完日志合上书)
writer.close()
print(f"日志已写入:{log_dir}")步骤 2:启动 TensorBoard
- 打开电脑的 "终端"(Windows 是 CMD/PowerShell,Mac/Linux 是终端);
- 输入以下命令(注意替换
log_dir为你代码里的实际路径,比如logs/basic):

tensorboard --logdir=logs/basic --port=6006
--logdir:指定日志文件夹路径(只需要到basic层,TensorBoard 会自动找子文件夹);--port=6006:指定端口(默认 6006,避免端口冲突)。
步骤 3:查看可视化结果
- 终端会输出类似
TensorBoard 2.15.0 at http://localhost:6006/ (Press CTRL+C to quit)的信息; - 打开浏览器,输入
http://localhost:6006,就能看到 TensorBoard 界面:- 点击左侧的Scalars(标量面板),就能看到 "训练损失" 的曲线(从 10 逐渐下降到 1);
- 这个面板是 TensorBoard 最常用的,专门看 "损失、准确率" 等数值的变化趋势。
操作 2:常见可视化面板介绍
| 面板名称 | 作用(通俗解释) | 适用场景 |
|---|---|---|
| Scalars | 看数值变化曲线(比如损失、准确率) | 训练过程监控(必用) |
| Graphs | 看模型的结构图(比如神经网络的层) | 检查模型结构是否正确 |
| Images | 可视化图片样本(比如 CIFAR 的图片) | 查看输入数据、模型输出的图片 |
| Histograms | 看权重 / 偏置的分布变化 | 分析模型参数是否合理 |
| Projector | 高维数据降维可视化(比如图片的特征向量) | 分析数据的聚类效果 |
新手先重点掌握Scalars 和Graphs,这两个是最核心的。
三、TensorBoard 在 CIFAR-10 上的实战(MLP 和 CNN)
先了解 CIFAR-10 数据集
CIFAR-10 是机器学习入门的 "标配数据集":
- 包含 10 类彩色图片(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车);
- 每张图片 32×32 像素(很小,适合新手训练);
- 分为 5 万张训练集、1 万张测试集。
实战 1:MLP(多层感知机)+ TensorBoard
MLP 是 "全连接神经网络",特点是只能处理一维数据,所以需要把 32×32×3 的图片展平成 3072 维的一维向量(32×32×3=3072)。
完整代码(带详细注释)
python
import tensorflow as tf
from datetime import datetime
# ====================== 步骤1:加载并预处理CIFAR-10 ======================
# 加载数据集(自动下载,第一次运行会慢一点)
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
# 预处理:
# 1. 归一化:把像素值从0-255转换成0-1(神经网络对0-1的数值更敏感)
x_train = x_train / 255.0
x_test = x_test / 255.0
# 2. MLP需要一维数据,把32×32×3的图片展平成3072维向量
x_train_flat = tf.reshape(x_train, [-1, 32*32*3]) # -1表示自动计算样本数
x_test_flat = tf.reshape(x_test, [-1, 32*32*3])
# ====================== 步骤2:构建MLP模型 ======================
def build_mlp_model():
model = tf.keras.Sequential([
# 输入层:指定输入形状为3072维
tf.keras.layers.Input(shape=(32*32*3,)),
# 隐藏层1:512个神经元,激活函数ReLU(常用)
tf.keras.layers.Dense(512, activation='relu'),
# 隐藏层2:256个神经元
tf.keras.layers.Dense(256, activation='relu'),
# 输出层:10个神经元(对应10类),激活函数softmax(分类任务专用)
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型:指定优化器、损失函数、评估指标
model.compile(
optimizer='adam', # 常用优化器,自动调整学习率
loss='sparse_categorical_crossentropy', # 分类任务损失函数
metrics=['accuracy'] # 监控准确率
)
return model
# ====================== 步骤3:配置TensorBoard回调 ======================
# 创建MLP专属日志文件夹
log_dir_mlp = f"logs/cifar10/mlp/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
# 定义TensorBoard回调(Keras内置,自动记录训练指标)
tensorboard_callback_mlp = tf.keras.callbacks.TensorBoard(
log_dir=log_dir_mlp, # 日志保存路径
histogram_freq=1, # 每1个epoch记录一次权重直方图
write_graph=True, # 保存模型结构图
write_images=True # 保存图片(如果有)
)
# ====================== 步骤4:训练模型 ======================
mlp_model = build_mlp_model()
# 开始训练(epochs=5:训练5轮,新手先少训点,快一点)
history_mlp = mlp_model.fit(
x_train_flat, y_train,
epochs=5,
batch_size=64, # 每次喂64个样本给模型
validation_split=0.2, # 用20%的训练集做验证
callbacks=[tensorboard_callback_mlp] # 加入TensorBoard回调
)
# 测试模型
test_loss, test_acc = mlp_model.evaluate(x_test_flat, y_test)
print(f"MLP模型测试准确率:{test_acc:.2f}")实战 2:CNN(卷积神经网络)+ TensorBoard
CNN 是 "卷积神经网络",专门处理二维图片数据,不需要展平,能直接提取图片的空间特征(比如边缘、纹理),效果比 MLP 好很多。
完整代码(带详细注释)
python
import tensorflow as tf
from datetime import datetime
# ====================== 步骤1:加载并预处理CIFAR-10(和MLP一致,无需展平) ======================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# ====================== 步骤2:构建CNN模型 ======================
def build_cnn_model():
model = tf.keras.Sequential([
# 输入层:32×32×3的彩色图片
tf.keras.layers.Input(shape=(32, 32, 3)),
# 卷积层1:提取基础特征(比如边缘)
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', padding='same'),
# 池化层1:缩小图片尺寸,减少计算量
tf.keras.layers.MaxPooling2D((2, 2)),
# 卷积层2:提取更复杂的特征(比如形状)
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
# 池化层2
tf.keras.layers.MaxPooling2D((2, 2)),
# 卷积层3
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
# 展平层:把二维特征转换成一维,供全连接层使用
tf.keras.layers.Flatten(),
# 全连接层
tf.keras.layers.Dense(64, activation='relu'),
# 输出层:10类分类
tf.keras.layers.Dense(10, activation='softmax')
])
# 编译模型
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
# ====================== 步骤3:配置TensorBoard回调 ======================
# 创建CNN专属日志文件夹(和MLP分开,方便对比)
log_dir_cnn = f"logs/cifar10/cnn/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
tensorboard_callback_cnn = tf.keras.callbacks.TensorBoard(
log_dir=log_dir_cnn,
histogram_freq=1,
write_graph=True,
write_images=True
)
# ====================== 步骤4:训练模型 ======================
cnn_model = build_cnn_model()
history_cnn = cnn_model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.2,
callbacks=[tensorboard_callback_cnn]
)
# 测试模型
test_loss, test_acc = cnn_model.evaluate(x_test, y_test)
print(f"CNN模型测试准确率:{test_acc:.2f}")实战 3:启动 TensorBoard 对比两个模型
- 打开终端,输入以下命令(日志文件夹是
logs/cifar10,包含 MLP 和 CNN 的子文件夹):

- 打开浏览器
http://localhost:6006,查看关键面板:
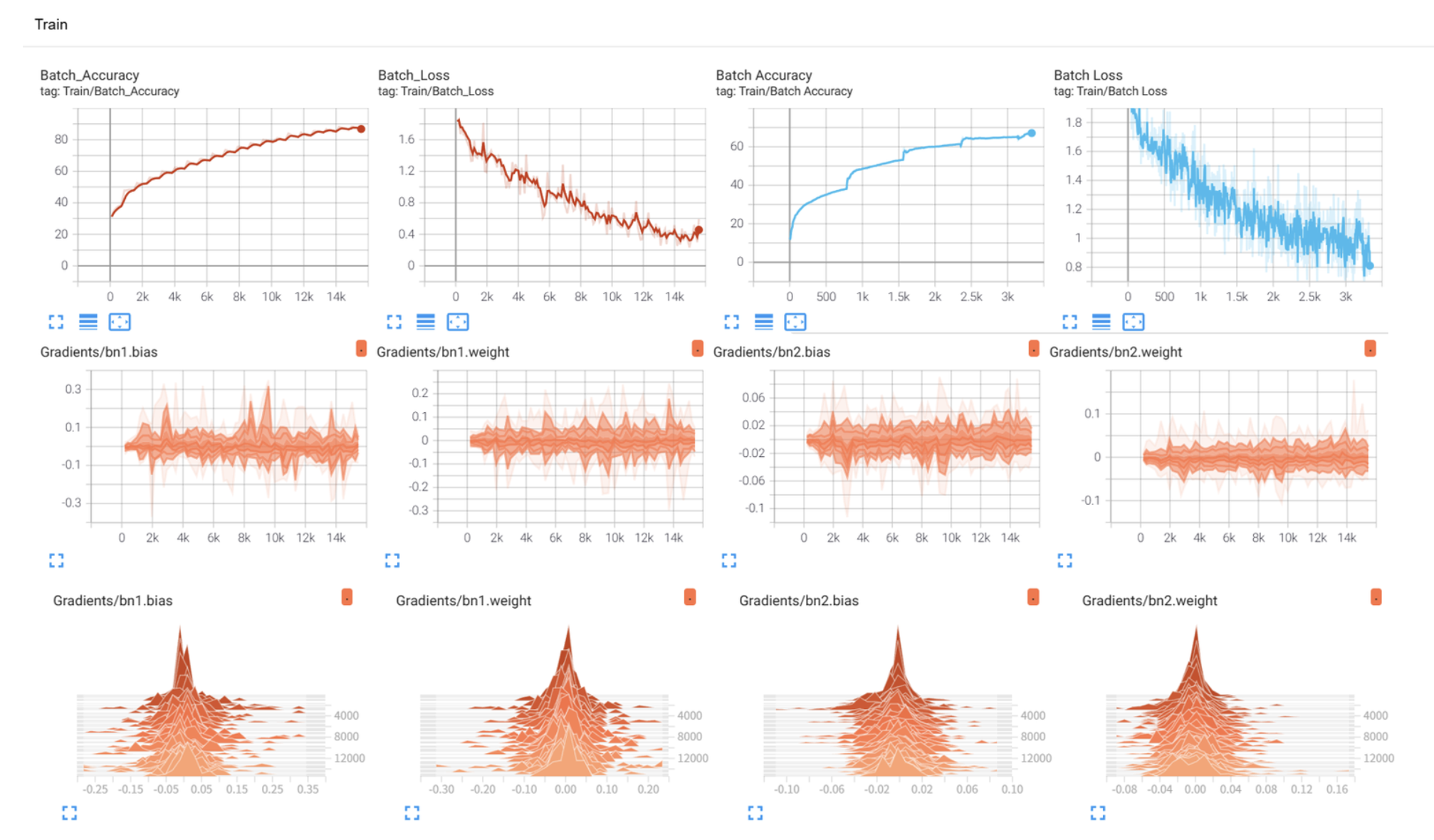
- Scalars:能看到 MLP 和 CNN 的 "loss"(损失)、"accuracy"(准确率)曲线,你会发现 CNN 的准确率更高、损失下降更快;
- Graphs:切换到 "mlp" 和 "cnn" 的标签,能看到两个模型的结构图,CNN 有卷积层、池化层,结构更复杂;
- Images:能看到 CIFAR-10 的图片样本,验证输入数据是否正确。
总结(核心知识点回顾)
- TensorBoard 核心逻辑:代码中通过 "回调 / 写入器" 记录指标→保存到日志文件夹→启动服务→浏览器查看可视化结果;
- 新手必掌握操作:Scalars 面板看损失 / 准确率曲线(监控训练效果)、Graphs 面板看模型结构(检查是否搭建正确);
- 实战关键结论:在 CIFAR-10 上,CNN(处理二维图片)的效果远好于 MLP(处理一维数据),TensorBoard 能直观对比两者的训练差异。
用代码展示如何使用SummaryWriter写入数据?
你想要通过具体的代码示例,清晰地展示如何使用SummaryWriter向 TensorBoard 写入各类数据,作为零基础学习者,我会用最简洁的代码、最详细的注释,覆盖SummaryWriter最常用的写入场景,确保你能直接运行并看懂每一步。
注意:
SummaryWriter是PyTorch 生态 中用于 TensorBoard 的核心类(和上一轮 TensorFlow 的tf.summary对应),先明确这个背景,避免你混淆框架。
前置准备
首先确保安装了必要的依赖(PyTorch 和 TensorBoard),打开终端执行:

完整代码示例:SummaryWriter 写入各类数据
下面的代码会演示写入标量(最常用)、图片、直方图、文本 这 4 类核心数据,每一步都有详细注释,你可以直接复制运行。
python
# 1. 导入核心库
import torch
# 导入SummaryWriter(PyTorch对接TensorBoard的核心类)
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from datetime import datetime
# 2. 初始化SummaryWriter(关键步骤)
# 日志路径:logs/summary_writer/时间戳(避免覆盖旧日志)
log_dir = f"logs/summary_writer/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
# 初始化Writer:相当于打开"日志本",所有写入操作都通过这个对象完成
writer = SummaryWriter(log_dir=log_dir)
# ====================== 场景1:写入标量(Scalar)(最常用) ======================
# 标量用于记录:损失值、准确率、学习率等单一数值的变化
# 模拟训练100步,记录"训练损失"和"验证准确率"
for step in range(100):
# 模拟损失:从2.0逐渐下降到0.1(符合训练规律)
train_loss = 2.0 - step * 0.019
# 模拟验证准确率:从0.5逐渐上升到0.95
val_acc = 0.5 + step * 0.0045
# 写入标量:参数1=指标名称(支持多级目录,比如"loss/train"),参数2=数值,参数3=步数
writer.add_scalar(tag="loss/train", scalar_value=train_loss, global_step=step)
writer.add_scalar(tag="accuracy/val", scalar_value=val_acc, global_step=step)
# ====================== 场景2:写入图片(Image) ======================
# 用于可视化:数据集样本、模型输出图片、特征图等
# 生成3张模拟的32×32彩色图片(形状:[数量, 通道数, 高度, 宽度],PyTorch图片格式)
# np.random.randn生成随机像素值,范围(-1,1),后续调整到(0,1)
fake_images = np.random.randn(3, 3, 32, 32) # 3张图、3通道(RGB)、32×32像素
fake_images = (fake_images - fake_images.min()) / (fake_images.max() - fake_images.min()) # 归一化到0-1
# 写入图片:参数1=图片标签,参数2=图片数据,参数3=步数,参数4=每行显示的图片数
writer.add_images(
tag="fake_cifar_images", # 标签名
img_tensor=fake_images, # 图片数据(必须是CHW或NCHW格式)
global_step=0, # 步数(固定0即可,因为只写一次)
dataformats="NCHW" # 数据格式:N(数量)-C(通道)-H(高)-W(宽)
)
# ====================== 场景3:写入直方图(Histogram) ======================
# 用于可视化:模型权重、偏置的分布,查看参数是否合理
# 模拟一组模型权重(正态分布)
fake_weights = torch.randn(1000) # 1000个随机数,模拟一层神经网络的权重
# 写入直方图:参数1=标签,参数2=数据,参数3=步数
writer.add_histogram(tag="model/weight", values=fake_weights, global_step=0)
# ====================== 场景4:写入文本(Text) ======================
# 用于记录:训练参数、备注信息等
writer.add_text(
tag="training_info", # 标签名
text_string=f"训练时间:{datetime.now()}\n学习率:0.001\n批次大小:64", # 要写入的文本
global_step=0
)
# ====================== 收尾:关闭SummaryWriter ======================
# 关闭Writer,确保所有数据都写入日志文件(避免数据丢失)
writer.close()
print(f"所有数据已写入日志文件夹:{log_dir}")
print("接下来在终端执行以下命令启动TensorBoard:")
print(f"tensorboard --logdir={log_dir} --port=6006")运行代码 + 查看结果的步骤
步骤 1:运行代码
将上述代码保存为summary_writer_demo.py,在终端执行:

python summary_writer_demo.py
运行完成后,会在当前目录生成logs/summary_writer/时间戳文件夹,里面就是 TensorBoard 需要的日志文件。
步骤 2:启动 TensorBoard
在终端输入以下命令(路径和代码中log_dir一致):

tensorboard --logdir=logs/summary_writer --port=6006
提示:只需要指定到
summary_writer层即可,TensorBoard 会自动扫描子文件夹。
步骤 3:查看可视化结果
打开浏览器,输入http://localhost:6006,就能看到对应的数据:
- 点击左侧
Scalars:能看到 "训练损失" 下降、"验证准确率" 上升的曲线(核心!); - 点击左侧
Images:能看到 3 张随机生成的模拟图片; - 点击左侧
Histograms:能看到模拟权重的分布直方图; - 点击左侧
Text:能看到我们写入的训练备注信息。
关键代码解释(零基础友好)
| 代码行 | 作用解释 |
|---|---|
writer = SummaryWriter(log_dir=log_dir) |
初始化日志写入器,指定日志保存路径,是所有写入操作的基础 |
writer.add_scalar(tag, value, step) |
写入标量(最常用),tag是指标名(支持多级目录,比如loss/train),step是训练步数 |
writer.add_images() |
写入多张图片,注意数据格式必须是NCHW(数量 - 通道 - 高 - 宽),这是 PyTorch 的标准格式 |
writer.close() |
关闭写入器,强制将缓存的数据写入文件,避免数据丢失(新手一定要加!) |
总结
SummaryWriter的核心流程:初始化(指定日志路径)→ 调用 add_* 方法写入数据 → 关闭写入器;- 最常用的方法是
add_scalar,用于监控训练损失、准确率等核心指标; - 启动 TensorBoard 时,
--logdir只需指定到包含日志的父文件夹,无需到具体时间戳子文件夹,方便对比多组实验。
如果运行时遇到 "端口被占用"(比如提示Port 6006 is already in use),只需把端口改成 6007 即可:tensorboard --logdir=logs/summary_writer --port=6007。
用代码展示如何使用SummaryWriter写入标量数据?
你想要一份只聚焦标量数据写入 的极简代码示例,清晰展示SummaryWriter如何记录训练过程中的核心标量(比如损失、准确率),作为零基础学习者,我会剔除所有无关代码,只保留标量相关的核心逻辑,同时配上详细的操作步骤和通俗解释。
标量数据是 TensorBoard 中最常用、最核心的可视化内容(比如训练损失、验证准确率、学习率等单一数值),掌握这个就能满足 80% 的 TensorBoard 使用场景。
前置准备(仅需 1 步)
确保安装了 PyTorch 和 TensorBoard(如果已安装可跳过),打开终端执行:
完整代码(仅标量写入)
这份代码模拟了 100 步训练过程,只记录 "训练损失" 和 "验证准确率" 两个标量,每一行都有通俗注释,可直接复制运行:
python
# 1. 导入核心工具:SummaryWriter是写入TensorBoard的核心类
from torch.utils.tensorboard import SummaryWriter
# 导入时间模块:生成唯一日志文件夹,避免覆盖旧数据
from datetime import datetime
# 2. 初始化SummaryWriter(关键!相当于打开一个"标量日志本")
# 日志保存路径:logs/scalar_demo/当前时间(比如20251226-153000)
log_dir = f"logs/scalar_demo/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
writer = SummaryWriter(log_dir=log_dir) # 传入路径,初始化写入器
# 3. 模拟训练过程,写入标量数据(核心操作)
# 循环100步,模拟每一步的训练损失和验证准确率变化
for step in range(100):
# 模拟训练损失:从2.0逐步降到0.1(符合训练时损失下降的规律)
train_loss = 2.0 - (step * 0.019)
# 模拟验证准确率:从0.5逐步升到0.95(符合训练时准确率上升的规律)
val_acc = 0.5 + (step * 0.0045)
# 写入"训练损失"标量
# 参数说明:
# tag:标量名称(支持多级目录,比如"loss/train",方便分类)
# scalar_value:标量的具体数值
# global_step:训练步数(对应x轴,必须传,否则曲线无法按步骤展示)
writer.add_scalar(tag="loss/train", scalar_value=train_loss, global_step=step)
# 写入"验证准确率"标量(和损失分开,方便TensorBoard中分类查看)
writer.add_scalar(tag="accuracy/val", scalar_value=val_acc, global_step=step)
# 4. 关闭写入器(重要!确保所有数据都写入文件,避免丢失)
writer.close()
# 打印提示信息,方便后续操作
print(f"✅ 标量数据已写入日志文件夹:{log_dir}")
print("\n📌 下一步操作(复制到终端执行):")
print(f"tensorboard --logdir=logs/scalar_demo --port=6006")运行代码 + 查看结果(3 步搞定)
步骤 1:运行代码
将上述代码保存为scalar_writer_demo.py,打开终端,进入代码所在文件夹,执行:

python scalar_writer_demo.py
运行后会在当前目录生成logs/scalar_demo/时间戳文件夹,里面就是 TensorBoard 能识别的标量日志。
步骤 2:启动 TensorBoard
在终端执行以下命令(无需指定到具体时间戳子文件夹,TensorBoard 会自动扫描):

终端会输出类似TensorBoard 2.16.2 at http://localhost:6006/ (Press CTRL+C to quit)的提示,说明启动成功。
步骤 3:查看标量曲线
打开浏览器,输入http://localhost:6006,就能看到 TensorBoard 界面:
- 点击左侧菜单栏的
Scalars(标量面板); - 右侧会显示两个曲线:
loss/train:从 2.0 逐渐下降到 0.1 的曲线(红色 / 蓝色);accuracy/val:从 0.5 逐渐上升到 0.95 的曲线;
- 可以用鼠标滚轮放大 / 缩小曲线,也能拖动查看某一步的具体数值(鼠标悬停在曲线上即可显示)。
核心代码通俗解释(零基础友好)
| 代码行 | 通俗解释 |
|---|---|
writer = SummaryWriter(log_dir=log_dir) |
初始化写入器,相当于 "打开一个专门记录标量的日志本",指定日志存在哪个文件夹 |
writer.add_scalar("loss/train", train_loss, step) |
往日志本里写一行:"第 step 步,训练损失是 train_loss",tag用/分隔是为了分类(比如 loss 和 accuracy 分开) |
writer.close() |
写完日志后 "合上本子",强制把内存中的数据写入文件,避免数据丢失(新手一定要加!) |
常见小问题解决
- 端口被占用 :如果提示
Port 6006 is already in use,把端口改成 6007 即可: tensorboard --logdir=logs/scalar_demo --port=6007
tensorboard --logdir=logs/scalar_demo --port=6007 - 曲线不显示 :检查
global_step是否传了(必须传,否则 x 轴无数据),或日志路径是否正确。 - 中文乱码:如果后续要写中文标签,无需额外设置,TensorBoard 默认支持中文。
总结
SummaryWriter写入标量的核心流程:初始化写入器 → 循环调用 add_scalar 写入(tag + 数值 + 步数) → 关闭写入器;tag建议用分类/名称的格式(比如loss/train),方便在 TensorBoard 中分类查看;global_step是标量曲线的 x 轴,必须和训练步数对应,才能看到 "随训练过程变化" 的趋势。
这是 TensorBoard 最基础也最核心的用法,掌握后就能监控自己的模型训练效果了。
如何使用SummaryWriter在TensorBoard中可视化模型结构?
你想知道如何通过SummaryWriter在 TensorBoard 中直观可视化 PyTorch 模型的结构(比如神经网络的层、输入输出形状、参数流向),作为零基础学习者,我会用极简的代码、通俗的解释,带你完成从搭建模型到可视化结构的全流程 ------ 这是检查模型是否搭建正确的核心技巧。
核心原理:
SummaryWriter的add_graph()方法能解析 PyTorch 模型的计算图,结合模拟输入数据(必须!),在 TensorBoard 中生成可视化的模型结构图,让你一眼看清 "数据从输入层→隐藏层→输出层" 的流向。
前置准备(已安装可跳过)
确保依赖齐全,终端执行:
完整代码示例(可视化 MLP+CNN 模型结构)
下面的代码会搭建两个经典模型(MLP 多层感知机、CNN 卷积神经网络),并分别可视化它们的结构,每一步都有详细注释,可直接复制运行:
python
# 1. 导入核心库
import torch
import torch.nn as nn # PyTorch构建模型的核心库
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
# 2. 定义要可视化的模型(先搭两个简单模型)
# 模型1:MLP(多层感知机,处理一维数据,比如展平的图片)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
# 定义模型层:输入层(3072) → 隐藏层1(512) → 隐藏层2(256) → 输出层(10)
self.layers = nn.Sequential(
nn.Linear(32*32*3, 512), # 32×32×3是CIFAR-10图片展平后的维度
nn.ReLU(), # 激活函数
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, 10) # 10类分类任务的输出层
)
def forward(self, x):
# 前向传播:定义数据如何流过模型
return self.layers(x)
# 模型2:CNN(卷积神经网络,处理二维图片数据)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 卷积层:提取图片特征
self.conv_layers = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1), # 输入3通道,输出32通道
nn.ReLU(),
nn.MaxPool2d(2, 2), # 池化层缩小尺寸
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 全连接层:分类
self.fc_layers = nn.Sequential(
nn.Flatten(), # 展平卷积特征
nn.Linear(64*8*8, 64), # 8×8是池化后的尺寸
nn.ReLU(),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.conv_layers(x)
x = self.fc_layers(x)
return x
# 3. 初始化SummaryWriter(指定日志路径)
log_dir = f"logs/model_structure/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
writer = SummaryWriter(log_dir=log_dir)
# 4. 可视化模型结构(核心操作)
# ========== 可视化MLP模型 ==========
# 关键:创建和模型输入形状匹配的模拟数据(MLP输入是展平的32×32×3图片)
mlp_model = MLP() # 实例化MLP模型
mlp_dummy_input = torch.randn(1, 32*32*3) # 模拟输入:1个样本,3072维(32×32×3)
# 写入模型结构:参数1=模型实例,参数2=模拟输入(告诉TensorBoard输入形状)
writer.add_graph(mlp_model, input_to_model=mlp_dummy_input)
# ========== 可视化CNN模型 ==========
# 关键:CNN输入是32×32×3的图片(形状:[样本数, 通道数, 高, 宽])
cnn_model = CNN() # 实例化CNN模型
cnn_dummy_input = torch.randn(1, 3, 32, 32) # 模拟输入:1个样本,3通道,32×32像素
writer.add_graph(cnn_model, input_to_model=cnn_dummy_input)
# 5. 关闭SummaryWriter(确保数据写入文件)
writer.close()
print(f"✅ 模型结构已写入日志文件夹:{log_dir}")
print("\n📌 启动TensorBoard(复制到终端执行):")
print(f"tensorboard --logdir=logs/model_structure --port=6006")运行代码 + 查看模型结构(3 步搞定)
步骤 1:运行代码
将代码保存为visualize_model.py,终端执行:

运行后会生成logs/model_structure/时间戳文件夹,里面包含模型结构的日志数据。
步骤 2:启动 TensorBoard
终端执行以下命令(无需指定到具体时间戳子文件夹):

启动成功后,终端会输出http://localhost:6006的访问地址。
步骤 3:查看模型结构(核心!)
打开浏览器输入http://localhost:6006,按以下步骤操作:

核心代码通俗解释(零基础友好)
| 代码行 | 通俗解释 |
|---|---|
mlp_model = MLP() |
实例化 MLP 模型,相当于 "造一个 MLP 神经网络出来" |
mlp_dummy_input = torch.randn(1, 32*32*3) |
造一个 "假的输入数据",告诉 TensorBoard:这个模型的输入是 "1 个样本、3072 维" 的向量(必须!因为 PyTorch 模型需要知道输入形状才能确定各层的维度) |
writer.add_graph(mlp_model, mlp_dummy_input) |
核心操作:让 TensorBoard "解析这个模型",结合假输入画出完整的结构流程图 |
cnn_dummy_input = torch.randn(1, 3, 32, 32) |
CNN 的假输入要匹配 "图片格式":1 个样本、3 通道(RGB)、32×32 像素 |
常见问题解决(新手必看)
问题 1:模型结构不显示 / 报错
- 原因:没传模拟输入,或模拟输入的形状和模型实际输入不匹配;
- 解决:确保
input_to_model的形状和模型forward方法的输入一致(比如 CNN 必须是[N, C, H, W],MLP 必须是展平的一维)。
问题 2:结构太复杂看不清
- 解决:切换到
Hierarchical视图(顶部下拉框),或把模型拆分成多个Sequential模块(比如代码中 CNN 拆成conv_layers和fc_layers),结构会更清晰。
问题 3:看不到层的参数信息
- 解决:点击结构图中的某一层(比如
Conv2d),右侧会弹出 "Attributes" 面板,显示该层的in_channels(输入通道)、out_channels(输出通道)等关键参数。
总结
- 可视化模型结构的核心:
SummaryWriter.add_graph(模型实例, 模拟输入),模拟输入是关键(告诉 TensorBoard 模型的输入形状); - 模拟输入形状必须和模型
forward方法的输入一致(CNN 是[N, C, H, W],MLP 是一维向量); - 在 TensorBoard 的
Graphs面板中,用Hierarchical视图能更清晰地看到模型的层级结构,点击层可查看参数细节。
这个技巧能帮你快速检查模型是否搭建正确(比如层的顺序、输入输出形状是否符合预期),是机器学习调试模型的必备技能。
如何使用SummaryWriter在TensorBoard中可视化训练过程中的准确率和损失值曲线?
你想知道如何结合实际的模型训练循环 ,用SummaryWriter把训练 / 验证过程中的准确率、损失值实时写入 TensorBoard,并可视化成直观的曲线 ------ 这是监控模型训练效果的核心方法,我会用零基础友好的代码(基于 MNIST 手写数字数据集,简单易运行),带你完成从训练到可视化的全流程,每一步都有通俗解释。
核心逻辑:在训练的每一轮(epoch) 或每一步(step) ,调用
add_scalar()将损失 / 准确率写入日志,TensorBoard 会自动根据global_step(步数 / 轮数)绘制曲线,让你一眼看清 "损失是否下降、准确率是否上升"。
前置准备(已安装可跳过)
完整代码示例(训练 + 可视化损失 / 准确率)
这份代码包含 "加载数据集→搭建简单模型→训练循环→写入 TensorBoard→可视化" 全流程,用 MNIST 数据集(手写数字,数据量小、训练快),注释详细到每一行:
python
# 1. 导入核心库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
# 2. 配置基础参数(新手可直接用,不用改)
BATCH_SIZE = 64 # 每次喂给模型的样本数
EPOCHS = 5 # 训练轮数(5轮足够看到曲线变化)
LEARNING_RATE = 0.001 # 学习率(控制模型更新速度)
DEVICE = torch.device("cpu") # 用CPU训练(新手无需GPU)
# 3. 加载MNIST数据集(手写数字,0-9分类)
# 数据预处理:转成Tensor+归一化
transform = transforms.Compose([
transforms.ToTensor(), # 把图片转成PyTorch能处理的Tensor格式
transforms.Normalize((0.1307,), (0.3081,)) # 归一化(MNIST的均值/标准差)
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(
root='./data', train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(
root='./data', train=False, download=True, transform=transform
)
# 数据加载器(批量读取数据)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 4. 搭建简单的MLP模型(适合MNIST分类)
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.model = nn.Sequential(
nn.Flatten(), # 展平28×28的图片成784维向量
nn.Linear(784, 128), # 隐藏层1:784→128
nn.ReLU(), # 激活函数
nn.Linear(128, 64), # 隐藏层2:128→64
nn.ReLU(),
nn.Linear(64, 10) # 输出层:64→10(对应0-9分类)
)
def forward(self, x):
return self.model(x)
# 5. 初始化SummaryWriter(关键!指定日志保存路径)
# 路径格式:logs/train_metrics/时间戳(避免覆盖旧日志)
log_dir = f"logs/train_metrics/{datetime.now().strftime('%Y%m%d-%H%M%S')}"
writer = SummaryWriter(log_dir=log_dir)
# 6. 初始化模型、损失函数、优化器
model = SimpleMLP().to(DEVICE) # 实例化模型并放到CPU
criterion = nn.CrossEntropyLoss() # 分类任务的损失函数
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 优化器
# 7. 训练+验证循环(核心:写入损失/准确率到TensorBoard)
global_step = 0 # 全局步数(用于TensorBoard的x轴)
for epoch in range(EPOCHS):
# ========== 训练阶段 ==========
model.train() # 模型切换到训练模式
train_loss_sum = 0.0 # 累计训练损失
train_correct = 0 # 累计正确数
train_total = 0 # 累计样本数
for batch_idx, (data, target) in enumerate(train_loader):
# 数据放到CPU
data, target = data.to(DEVICE), target.to(DEVICE)
# 前向传播
output = model(data)
loss = criterion(output, target) # 计算训练损失
# 反向传播+更新参数
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 统计训练指标
train_loss_sum += loss.item()
_, predicted = torch.max(output.data, 1) # 预测结果
train_total += target.size(0)
train_correct += (predicted == target).sum().item()
# 🔥 关键:每一批次写入训练损失(按global_step)
writer.add_scalar('train/loss', loss.item(), global_step=global_step)
global_step += 1 # 步数+1
# 计算本轮训练的平均损失和准确率
train_avg_loss = train_loss_sum / len(train_loader)
train_acc = train_correct / train_total
# ========== 验证阶段 ==========
model.eval() # 模型切换到验证模式
val_loss_sum = 0.0
val_correct = 0
val_total = 0
with torch.no_grad(): # 验证阶段不计算梯度(节省资源)
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
loss = criterion(output, target) # 计算验证损失
# 统计验证指标
val_loss_sum += loss.item()
_, predicted = torch.max(output.data, 1)
val_total += target.size(0)
val_correct += (predicted == target).sum().item()
# 计算本轮验证的平均损失和准确率
val_avg_loss = val_loss_sum / len(test_loader)
val_acc = val_correct / val_total
# 🔥 关键:每一轮写入训练/验证的平均损失和准确率(按epoch)
writer.add_scalar('train/avg_loss', train_avg_loss, global_step=epoch)
writer.add_scalar('train/accuracy', train_acc, global_step=epoch)
writer.add_scalar('val/avg_loss', val_avg_loss, global_step=epoch)
writer.add_scalar('val/accuracy', val_acc, global_step=epoch)
# 打印本轮结果(方便终端查看)
print(f"Epoch [{epoch+1}/{EPOCHS}]")
print(f"Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.4f}")
print(f"Val Loss: {val_avg_loss:.4f}, Val Acc: {val_acc:.4f}\n")
# 8. 收尾:关闭SummaryWriter(确保数据全部写入)
writer.close()
# 提示后续操作
print(f"✅ 训练完成!所有指标已写入日志文件夹:{log_dir}")
print("\n📌 启动TensorBoard(复制到终端执行):")
print(f"tensorboard --logdir=logs/train_metrics --port=6006")运行代码 + 查看可视化曲线(3 步搞定)
步骤 1:运行代码
将代码保存为train_visualize.py,终端执行:

- 第一次运行会自动下载 MNIST 数据集(约 10MB,速度快);
- 训练过程中终端会打印每一轮的损失 / 准确率;
- 运行完成后生成
logs/train_metrics/时间戳日志文件夹。
步骤 2:启动 TensorBoard
终端执行以下命令(无需指定到具体时间戳子文件夹):

步骤 3:查看损失 / 准确率曲线(核心!)
打开浏览器输入http://localhost:6006,操作如下:

核心代码通俗解释(零基础友好)
| 代码行 | 通俗解释 |
|---|---|
writer = SummaryWriter(log_dir=log_dir) |
初始化日志写入器,相当于 "打开一个专门记录训练指标的本子" |
writer.add_scalar('train/loss', loss.item(), global_step) |
每批数据训练完,往本子里记:"第 global_step 步,训练损失是 loss.item ()",train/loss是标签(分类用) |
writer.add_scalar('val/accuracy', val_acc, epoch) |
每轮验证完,记:"第 epoch 轮,验证准确率是 val_acc" |
global_step += 1 |
每训练一批数据,步数 + 1(保证 x 轴连续,曲线不重叠) |
writer.close() |
训练结束,"合上本子",确保所有数据写入文件(避免丢失) |
新手常见问题解决
问题 1:曲线波动太大(train/loss)
- 原因:
train/loss是单批次的损失,本身就会波动; - 解决:重点看
train/avg_loss(每轮平均损失),这条曲线更平滑,能反映整体趋势。
问题 2:验证准确率不上升甚至下降
- 原因:模型过拟合 / 学习率不合适 / 训练轮数不够;
- 解决:通过 TensorBoard 曲线能快速发现这个问题,比如 "训练准确率 95%,验证准确率 70%" 就是过拟合,需要调整模型。
问题 3:TensorBoard 中看不到曲线
- 原因 1:
global_step传错(比如重复传 0); - 原因 2:日志路径指定错误(启动 TensorBoard 时
--logdir要指向train_metrics,不是具体时间戳); - 解决:检查
add_scalar的global_step参数,重新启动 TensorBoard 并确认路径。
总结
- 可视化损失 / 准确率的核心流程:初始化 SummaryWriter → 训练 / 验证中调用 add_scalar 写入指标(标签 + 数值 + 步数 / 轮数) → 关闭 Writer → 启动 TensorBoard 查看曲线;
- 标签建议用
分类/指标名格式(如train/loss、val/accuracy),方便在 TensorBoard 中分类查看; global_step(步数)用于批次级指标,epoch(轮数)用于轮级指标,确保 x 轴和训练进度对应。
这是机器学习中最常用的 TensorBoard 用法,掌握后能快速判断模型训练是否正常(比如损失是否下降、是否过拟合),是调试模型的必备技能。
除了Tensorboard,还有哪些类似的可视化工具?
TensorBoard 替代工具全览
除 TensorBoard 外,机器学习领域有多种可视化工具,它们在功能、易用性和适用场景上各有侧重。下面按功能类型分类介绍主流替代工具:
一、实验跟踪与可视化全能型工具
1. Weights & Biases (W&B)
核心优势:
- 云端协作:团队成员实时共享实验结果,一键生成可分享链接
- 强大可视化:自动生成损失 / 准确率曲线,支持直方图、3D 图等高级可视化
- 超参数优化:内置搜索工具,支持随机 / 网格 / 贝叶斯搜索 Weights & Biases
- 模型版本控制:自动保存模型权重,方便对比不同版本
价格:个人版免费,团队版起价 $9 / 月 / 人 Weights & Biases
适用场景:深度学习研究、需要团队协作的项目、快速迭代的实验环境
极简使用示例:
python
import wandb
wandb.init(project="my-project") # 初始化
wandb.log({"loss": 0.5, "accuracy": 0.8}) # 记录指标2. MLflow Tracking
核心优势:
- 全生命周期管理:从实验到模型部署的完整跟踪
- 开源自托管:可部署在私有环境,数据完全可控
- 多框架支持:无缝集成 TensorFlow、PyTorch、scikit-learn 等 MLflow
- 与 Databricks 深度集成:企业级大数据处理能力
价格:完全开源免费
适用场景:企业级 MLOps、需要模型部署的生产环境、大数据与 AI 结合项目
极简使用示例:
python
import mlflow
mlflow.log_metric("loss", 0.5) # 记录标量指标
mlflow.log_param("learning_rate", 0.001) # 记录参数3. Comet.ml
核心优势:
- 可视化 + 数据洞察:一键生成专业图表和报告
- 内置 A/B 测试:自动对比不同实验效果
- LLM 支持:专门优化的提示词工程和评估功能
- CI/CD 集成:自动化测试与部署流程
价格:个人版免费 (5 个团队成员限制),专业版 $179 / 月起
适用场景:快速迭代的 AI 产品开发、需要精细化实验对比的团队
极简使用示例:
python
from comet_ml import Experiment
experiment = Experiment(project_name="my-project")
experiment.log_metric("loss", 0.5)4. Neptune.ai
核心优势:
- 轻量级与可扩展性:专为大规模模型训练设计,无延迟监控
- 自定义仪表盘:支持 Bokeh、Altair、Plotly 等多种可视化库
- 模型内部监控:可深入查看每一层的损失、梯度和激活值
- 比较功能:提供参数差异表、并行坐标图等对比视图
价格:个人版免费,团队版按需定价
适用场景:大规模深度学习模型训练、需要深入分析模型内部状态的研究
极简使用示例:
python
import neptune
run = neptune.init(project="my-project")
run["metrics/loss"] = 0.5二、轻量级 / 本地可视化工具
1. SwanLab (国产)
核心优势:
- 离线 + 云端双模式:弥补 TensorBoard 只能离线的不足
- 现代化 UI:界面简洁直观,交互体验优秀
- 多框架支持:集成 30 + 深度学习框架,包括 PyTorch、TensorFlow 等
- 多媒体支持:可视化图像、音频、文本等多种数据类型
价格:开源免费,企业版提供高级功能
适用场景:个人研究、教育环境、需要快速搭建可视化的小型团队
极简使用示例:
python
import swanlab
swanlab.log({"loss": 0.5, "accuracy": 0.8})2. Visdom
核心优势:
- PyTorch 官方推荐:专为 PyTorch 设计的 "轻量级实时 TensorBoard"
- 快速搭建:几行代码实现数据可视化
- 支持多种图表:折线图、散点图、热力图等
价格:完全开源免费
适用场景:PyTorch 用户、需要快速查看训练指标的研究人员
极简使用示例:
python
from visdom import Visdom
vis = Visdom()
vis.line(Y=[0.5], X=[1], win="loss", opts=dict(title="Loss Curve"))三、模型结构可视化专用工具
1. Netron
核心优势:
- 多框架支持:兼容 PyTorch、TensorFlow、Keras 等模型格式
- 直观界面:清晰展示模型层次结构和参数流动
- 轻量级:无需安装额外依赖,直接通过网页查看模型
价格:完全开源免费,提供 Web 版和桌面版
适用场景:模型架构理解、跨框架模型交流、论文写作中的模型展示
2. TensorBoardX (现已合并到 TensorBoard)
核心优势:
- PyTorch 友好:为 PyTorch 提供与 TensorBoard 相同的可视化体验
- 支持多种数据:标量、图像、直方图、模型图等
价格:开源免费
适用场景:PyTorch 用户想使用 TensorBoard 风格可视化的情况
四、其他实用工具
1. ClearML
核心优势:
- 资源监控:自动跟踪 CPU/GPU 使用情况,优化资源分配
- 任务调度:支持分布式训练任务管理
- 可自托管:支持本地部署或云服务
价格:社区版免费,企业版付费
2. ML Visuals
核心优势:
- 免费专业图表:专为机器学习设计的高质量可视化模板
- 科学交流优化:生成适合论文发表的图表
价格:完全免费
3. DVC Live
核心优势:
- 与 DVC 集成:数据版本控制与可视化无缝结合
- 轻量级:无需额外服务,直接在终端生成可视化
价格:开源免费
五、功能对比速查表
| 工具 | 云端支持 | 团队协作 | 自动可视化 | 模型结构 | 轻量级 | 价格 |
|---|---|---|---|---|---|---|
| TensorBoard | ❌ | ❌ | ✅(基础) | ✅ | ✅ | 免费 (开源) |
| W&B | ✅ | ✅(强) | ✅(丰富) | ✅ | ❌ | 个人免费 |
| MLflow | ⚠️(需自部署) | ✅ | ✅(基础) | ✅ | ⚠️ | 免费 (开源) |
| Comet.ml | ✅ | ✅(中) | ✅(丰富) | ✅ | ❌ | 个人免费 (有限) |
| Neptune.ai | ✅ | ✅(中) | ✅(可定制) | ✅ | ⚠️ | 个人免费 |
| SwanLab | ✅ | ✅(中) | ✅(现代) | ✅ | ✅ | 免费 (开源) |
| Visdom | ❌ | ❌ | ✅(基础) | ❌ | ✅ | 免费 (开源) |
| Netron | ❌ | ❌ | ❌ | ✅(专业) | ✅ | 免费 (开源) |
六、如何选择适合你的工具?
1. 如果你是个人研究者 / 学生
- 简单本地使用: 优先选 TensorBoard 或 Visdom (免费、轻量、足够基础可视化)
- 需要云支持: 选择 W&B 或 SwanLab (个人版免费,功能强大)
2. 如果你在团队中做深度学习研究
- 需要强协作: W&B 是首选 (实时共享、评论、对比实验)
- 大规模模型: Neptune.ai (监控深层模型内部状态,无延迟)
3. 如果你在企业环境做 AI 开发
- 完整 MLOps 流程: MLflow (从实验到部署全生命周期管理)
- 合规与数据安全: 可自托管的 MLflow 或 ClearML (数据不出内网)
4. 如果你特别关注模型结构可视化
- Netron (支持几乎所有框架,开箱即用)
- TensorBoard (原生支持 TensorFlow/Keras 模型结构)
总结
除 TensorBoard 外,W&B、MLflow、Comet.ml 和 Neptune.ai 是功能最全面的可视化工具,各有专长;SwanLab 和 Visdom 适合轻量级使用;Netron 专注模型结构可视化。建议根据项目规模、团队需求和技术栈选择,许多工具支持同时集成 (如 W&B+TensorBoard),取长补短。
下一步建议: 从 W&B 或 SwanLab 开始尝试 (免费且功能强大),同时保留 TensorBoard 用于模型结构可视化,体验不同工具的优势。
Weights & Biases;MLflow;SwanLab各自的核心优势分别是什么?
你想清晰区分 Weights & Biases(W&B)、MLflow、SwanLab 这三款工具的核心优势,作为零基础的机器学习学习者,我会用通俗易懂的语言(搭配生活化比喻),聚焦每款工具最核心、最实用的价值,帮你快速判断哪款适合自己的使用场景。
一、Weights & Biases(W&B):云端优先的「实验协作管家」
W&B 的核心定位是面向研究者 / 小团队的云端实验可视化与协作工具,核心优势围绕 "云端、协作、易用" 展开:
核心优势(新手最关心的 3 点)

二、MLflow:全流程覆盖的「模型生命周期管家」
MLflow 的核心定位是面向企业 / 专业团队的机器学习全流程管理工具,核心优势围绕 "全流程、开源、自托管" 展开:
核心优势(新手最关心的 3 点)

三、SwanLab:国产轻量的「本地化实验看板」
SwanLab 是国产开源工具,核心定位是兼顾本地易用性与云端协作的轻量级可视化工具,核心优势围绕 "国产、轻量、友好" 展开:
核心优势(新手最关心的 3 点)

核心优势对比表(新手速记)
| 工具 | 核心优势关键词 | 最适合的场景 | 新手友好度 |
|---|---|---|---|
| W&B | 云端、协作、实验对比、易用 | 个人学习 / 小团队研究、快速迭代实验 | ⭐⭐⭐⭐⭐ |
| MLflow | 全流程、开源自托管、通用性强 | 企业项目、模型部署、传统 + 深度学习混合 | ⭐⭐⭐ (需学基础概念) |
| SwanLab | 国产、轻量、离线 + 云端、中文友好 | 国内学习者、本地化可视化、简单小项目 | ⭐⭐⭐⭐⭐ |
总结
- 如果你是纯新手,只想快速可视化训练曲线、对比实验:优先选 W&B(个人免费)或 SwanLab(国产更适配),零门槛上手;
- 如果你想接触工业界全流程,或需要部署模型:选 MLflow(开源免费,学完能对接实际工作);
- 如果你在意数据隐私,不想用国外云端:选 SwanLab(本地运行)或 MLflow(自托管)。
这三款工具都支持和 TensorBoard 互补使用(比如用 W&B 看指标、用 TensorBoard 看模型结构),新手可以先从 W&B/SwanLab 入手,后续再拓展 MLflow。
作业:对resnet18 在 cifar10上采用微调策略下,用tensorboard 监控训练过程。
完整代码实现(ResNet18 微调 + TensorBoard 监控)
在 VS Code 中新建train_resnet18_cifar10.py文件,复制以下代码(每一行都有详细注释,适配 Mac OS):
python
# ====================== 1. 导入核心库 ======================
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
import os
# ====================== 2. 基础配置(适配Mac OS) ======================
# 设备配置:Mac M系列芯片用mps,Intel用cpu
DEVICE = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f"使用设备:{DEVICE}") # 打印当前设备,确认是否正确
# 训练参数(新手可直接用,不用改)
BATCH_SIZE = 64 # 批次大小(Mac内存小的话可改32)
EPOCHS = 10 # 训练轮数(微调不用太多)
LEARNING_RATE = 0.001 # 微调学习率要小(避免覆盖预训练权重)
LOG_DIR = f"logs/resnet18_cifar10/{datetime.now().strftime('%Y%m%d-%H%M%S')}" # TensorBoard日志路径
# ====================== 3. 数据预处理(适配ResNet18输入) ======================
# ResNet18预训练模型要求输入224×224,CIFAR10是32×32,所以需要resize
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪+缩放至224×224
transforms.RandomHorizontalFlip(), # 随机水平翻转(数据增强)
transforms.ToTensor(), # 转Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet预训练的均值
std=[0.229, 0.224, 0.225]) # ImageNet预训练的标准差
])
transform_test = transforms.Compose([
transforms.Resize(256), # 缩放至256×256
transforms.CenterCrop(224), # 中心裁剪至224×224
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 加载CIFAR10数据集(Mac下自动下载到当前文件夹的data目录)
train_dataset = datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
test_dataset = datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test
)
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# CIFAR10类别名称(方便后续理解)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# ====================== 4. 微调ResNet18(核心步骤) ======================
# 步骤1:加载预训练的ResNet18模型
model = models.resnet18(pretrained=True) # 加载ImageNet预训练权重
# 步骤2:冻结特征提取层(微调核心:只训练分类头)
# ResNet18的features层是特征提取部分,fc是分类头
for param in model.parameters():
param.requires_grad = False # 冻结所有参数
# 步骤3:修改分类头(适配CIFAR10的10类,原ResNet18是1000类)
num_ftrs = model.fc.in_features # 获取分类头输入维度
model.fc = nn.Linear(num_ftrs, 10) # 替换为10类分类头
# 步骤4:将模型移到Mac的设备(MPS/CPU)
model = model.to(DEVICE)
# ====================== 5. 配置训练组件 ======================
criterion = nn.CrossEntropyLoss() # 分类损失函数
# 优化器:只优化分类头的参数(因为特征层已冻结)
optimizer = optim.Adam(model.fc.parameters(), lr=LEARNING_RATE)
# 初始化TensorBoard的SummaryWriter(Mac路径无乱码)
writer = SummaryWriter(log_dir=LOG_DIR)
# ====================== 6. 训练+验证循环(写入TensorBoard) ======================
global_step = 0 # 全局步数,用于TensorBoard的x轴
for epoch in range(EPOCHS):
# ---------- 训练阶段 ----------
model.train() # 切换到训练模式
train_loss = 0.0
train_correct = 0
train_total = 0
for batch_idx, (inputs, labels) in enumerate(train_loader):
# 数据移到设备
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计指标
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
train_total += labels.size(0)
train_correct += (predicted == labels).sum().item()
# 写入TensorBoard:每批次的训练损失
writer.add_scalar('train/batch_loss', loss.item(), global_step=global_step)
global_step += 1
# 计算本轮训练的平均损失和准确率
train_avg_loss = train_loss / len(train_loader)
train_acc = 100 * train_correct / train_total
# ---------- 验证阶段 ----------
model.eval() # 切换到验证模式
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad(): # 验证阶段不计算梯度,节省Mac资源
for inputs, labels in test_loader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
# 计算本轮验证的平均损失和准确率
val_avg_loss = val_loss / len(test_loader)
val_acc = 100 * val_correct / val_total
# ---------- 写入TensorBoard:每轮的平均指标 ----------
writer.add_scalar('train/avg_loss', train_avg_loss, global_step=epoch)
writer.add_scalar('train/accuracy', train_acc, global_step=epoch)
writer.add_scalar('val/avg_loss', val_avg_loss, global_step=epoch)
writer.add_scalar('val/accuracy', val_acc, global_step=epoch)
# 打印本轮结果(Mac终端可见)
print(f'Epoch [{epoch+1}/{EPOCHS}]')
print(f'Train Loss: {train_avg_loss:.4f}, Train Acc: {train_acc:.2f}%')
print(f'Val Loss: {val_avg_loss:.4f}, Val Acc: {val_acc:.2f}%\n')
# ====================== 7. 收尾工作 ======================
# 关闭SummaryWriter,确保所有数据写入文件(Mac下避免数据丢失)
writer.close()
# 保存微调后的模型(Mac路径)
model_save_path = f'./resnet18_cifar10_finetuned.pth'
torch.save(model.state_dict(), model_save_path)
print(f'微调后的模型已保存到:{model_save_path}')
print(f'TensorBoard日志路径:{LOG_DIR}')
print('训练完成!请在终端执行以下命令启动TensorBoard:')
print(f'tensorboard --logdir={LOG_DIR} --port=6006')运行代码 + 查看 TensorBoard(Mac OS + VS Code 操作)
步骤 1:运行训练代码
步骤 2:启动 TensorBoard(Mac OS 无端口冲突)
步骤 3:查看可视化结果

关键知识点解释(Mac 适配 + 微调核心)
1. Mac 设备适配
- 代码中
DEVICE = torch.device("mps" if torch.backends.mps.is_available() else "cpu"):自动识别 Mac M1/M2/M3 芯片的 MPS 加速(比 CPU 快 3-5 倍),Intel Mac 自动用 CPU; - Mac 的文件路径无需转义,代码中
LOG_DIR和模型保存路径直接用相对路径即可。
2. ResNet18 微调核心
- 冻结特征层 :
for param in model.parameters(): param.requires_grad = False,只让分类头的参数参与训练,避免预训练的特征提取权重被破坏; - 修改分类头:ResNet18 原分类头是 1000 类(ImageNet),替换为 10 类(CIFAR10),这是微调的核心适配步骤;
- 小学习率:微调时学习率用 0.001(比从头训练小 10 倍),避免大学习率覆盖预训练权重。
3. TensorBoard 监控重点
- 看
val/accuracy是否持续上升:若上升说明微调有效,若停滞说明训练轮数不够或学习率不合适; - 对比
train/accuracy和val/accuracy:若差距过大(比如训练 90%,验证 70%),说明过拟合,可增加数据增强或减小学习率。
总结
- Mac OS 适配关键:用 MPS 加速(M 系列芯片)、相对路径、虚拟环境避免依赖冲突;
- ResNet18 微调核心:冻结特征层 + 替换分类头 + 小学习率,利用预训练权重适配小数据集;
- TensorBoard 监控核心:写入批次 / 轮级损失 / 准确率,通过曲线判断微调效果(验证准确率上升 = 微调成功)。
如果训练中遇到 "内存不足"(Mac 内存 8G 以下),可将BATCH_SIZE改为 32;若验证准确率低,可增加训练轮数到 15,或解冻 ResNet18 的最后 1-2 层特征层(代码中取消部分层的冻结)。