**郑重声明:**本文所涉安全技术仅限用于合法研究与学习目的,严禁任何形式的非法利用。因不当使用所导致的一切法律与经济责任,本人概不负责。任何形式的转载均须明确标注原文出处,且不得用于商业目的。
🔋 点赞 | 能量注入 ❤️ 关注 | 信号锁定 🔔 收藏 | 数据归档 ⭐️ 评论| 保持连接💬
🌌 立即前往 👉 晖度丨安全视界 🚀

▶ 信息收集
▶ 漏洞检测
▶ 初始立足点 ➢ 查找漏洞的公共利用 ➢ 缓冲区 & 栈结构🔥🔥🔥
▶ 权限提升
▶ 横向移动
▶ 报告/分析
▶ 教训/修复
目录
[1.1 缓冲区溢出漏洞](#1.1 缓冲区溢出漏洞)
[1.1.1 缓冲区介绍](#1.1.1 缓冲区介绍)
[1.1.1.1 什么是缓冲区(Buffer)](#1.1.1.1 什么是缓冲区(Buffer))
[1.1.1.2 几个类似的概念](#1.1.1.2 几个类似的概念)
[1.1.1.3 缓冲区溢出](#1.1.1.3 缓冲区溢出)
[1.1.1.4 堆和栈的概念](#1.1.1.4 堆和栈的概念)
[1.1.2 栈内存分配与函数调用入栈顺序(重点)](#1.1.2 栈内存分配与函数调用入栈顺序(重点))
[1.1.2.1 函数调用栈帧构建顺序](#1.1.2.1 函数调用栈帧构建顺序)
[1.1.2.2 EBP 与 ESP 解释:x86架构中的关键栈寄存器](#1.1.2.2 EBP 与 ESP 解释:x86架构中的关键栈寄存器)
[1.1.2.3 栈内存布局图示](#1.1.2.3 栈内存布局图示)
[1.1.2.4 与缓冲区溢出的关键联系](#1.1.2.4 与缓冲区溢出的关键联系)
[欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论](#欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论)
1.修改漏洞利用脚本
1.1 缓冲区溢出漏洞
内存损坏漏洞利用(如缓冲区溢出 )是相对复杂且难以修改的。这类漏洞利用的修改通常涉及:
🔍 理解高级缓冲区溢出理论
⚙️ 交叉编译二进制文件
🛠️ 修改和更新内存损坏漏洞
本文以缓冲区溢出漏洞作为示例。
1.1.1 缓冲区介绍
1.1.1.1 什么是缓冲区(Buffer)
缓冲区是计算机中的一块内存区域,用于暂时存储数据。在程序运行时,它常用于:
-
处理输入/输出操作
-
存储临时数据
-
提高数据处理效率
缓冲区可保存用户经常发送的内容以供后续处理。根据内存管理方式,可分为:
-
动态大小缓冲区(堆分配,开发人员定义)
-
固定大小缓冲区(栈分配,系统分配)
例如:当你从硬盘读取数据时,操作系统可能先将数据存入内存缓冲区,待程序准备好后再处理。这种方式能减少频繁访问硬盘的性能损耗,使程序运行更流畅。
1.1.1.2 几个类似的概念
以下几个重要概念在此进行梳理:
****缓冲区(Buffer)、寄存器(Register)、缓存(Cache)、虚拟内存(Virtual Memory)****的区别与联系?
①定义
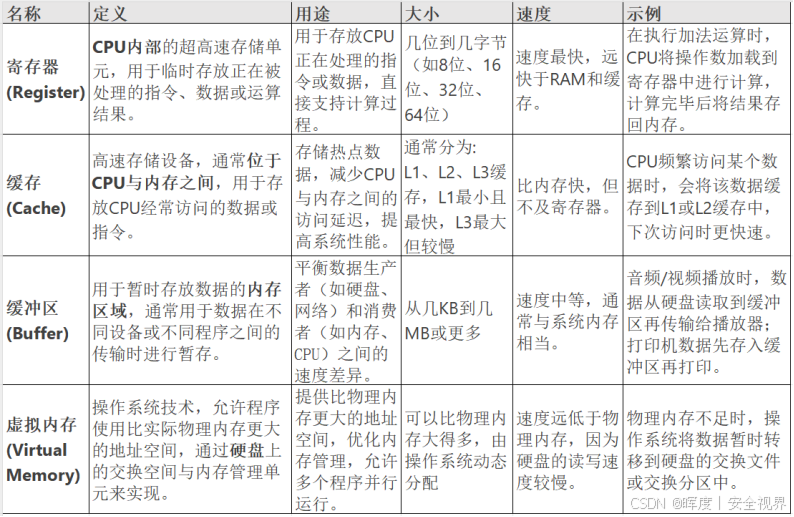
②区别
· 速度与位置
寄存器 > 缓存 > 缓冲区(内存) > 虚拟内存(硬盘)
· 用途
寄存器:存储当前CPU正在处理的指令和数据(如 EAX、ESP)。
缓存:加速CPU对内存的访问(缓存热点数据)。
缓冲区:协调速度不匹配的设备(如键盘输入、磁盘读写)。
虚拟内存:解决物理内存不足的问题,让程序"感觉"内存无限大。
· 可控性
寄存器和缓存:由硬件自动管理,程序员无法直接控制。
缓冲区:程序员可显式分配(如 char buffer1024)。
虚拟内存:由操作系统管理,程序员仅使用虚拟地址。
③形象比喻

④ 协作关系
CPU 需要数据时:
先查 寄存器 → 没有则查 缓存 → 没有则读 内存(含缓冲区) →若内存不足,触发 虚拟内存(换页到硬盘)。
写数据时:
数据可能先写入 缓冲区 或 缓存 ,再由系统同步到 内存/硬盘。
⑤ 程序员需要关心这些吗?
高级语言(如Python/Java):通常无需直接管理,但理解原理有助于优化性能。
低级开发(如C/汇编):需考虑寄存器、缓存命中率、缓冲区溢出等。
1.1.1.3 缓冲区溢出
自20世纪80年代末,缓冲区溢出(Buffer Overflow)一直是破坏软件安全的最早、最常见的内存损坏漏洞之一 。当程序向缓冲区写入数据时,如果写入的数据量超出缓冲区容量,就会发生溢出,可能覆盖相邻内存区域,进而被攻击者利用以执行恶意代码。
✅ 本质 :用户输入超出堆栈限制,溢出到相邻内存区域,从而被攻击者利用来执行恶意代码。
📊 示例图示:
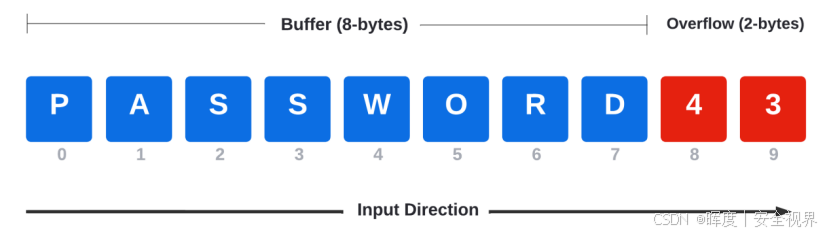
缓冲区设计容量:8字节(例如存储密码)
用户输入:"password43"(共10字节)
[ p | a | s | s | w | o | r | d ] 4 3
---------缓冲区(8字节)--------- ↑
溢出部分(2字节)如上例,若程序未正确处理超长输入,最后两个字符"4"和"3"将溢出缓冲区,可能导致程序崩溃或被利用执行非预期操作。
1.1.1.4 堆和栈的概念
缓冲区溢出是内存损坏漏洞的一种,但并非唯一类型。这类漏洞出现在程序的不同内存区域:
| 内存区域 | 特点 |
|---|---|
| 堆(Heap) | 动态管理,通常存储全局可访问的大块数据 |
| 栈(Stack) | 存储局部函数数据,大小通常固定 |
在程序运行过程中,内存管理主要涉及堆(Heap) 和栈(Stack) 这两个关键区域。它们负责存储不同类型的数据,并在管理方式、性能和生命周期上存在根本性差异。
堆(Heap) 和栈(Stack)的区别?
特性 栈 (Stack) 堆 (Heap) 主要用途 存储临时数据,如函数参数、局部变量。 存储动态分配的数据,其大小或生命周期在编译时不确定。 管理方式 ⚙️ 自动管理(由编译器/系统控制)。 🛠️ 手动管理(需程序员显式申请和释放)。 生命周期 ⏳ 短暂,随函数调用结束而自动回收。 ⏳ 灵活持久,从分配持续到显式释放。 分配速度 ⚡ 极快(仅移动栈指针)。 ⚡ 相对较慢(需在复杂结构中寻找合适空间)。 内存分配 🔄 地址连续分配(LIFO - 后进先出)。 🔄 地址碎片化分配(按需在空闲区域分配)。 典型问题 🚨 栈溢出(如深度递归)。 🚨 内存泄漏 、使用已释放内存。 访问方式 直接通过变量名(系统自动寻址)。 间接通过指针(程序员管理地址)。
高地址 ┌─────────────────┐ │ 堆 │ ← 动态分配,向上增长 │ (Heap) │ ├─────────────────┤ │ │ │ 未使用空间 │ │ │ ├─────────────────┤ │ 栈 │ ← 自动管理,向下增长 │ (Stack) │ └─────────────────┘ 低地址🎯 生动比喻
🥪 栈(Stack)的比喻:自助旋转寿司店
自动传送 :菜品(数据)按照固定顺序和轨道(调用顺序)自动传送到你面前。你只需取用最靠近你的那一盘(后进先出)。
即时清理 :吃完的盘子(函数执行完毕)会被服务员快速自动收走(内存自动回收),位置立刻腾出给下一盘。
空间固定 :传送带(栈空间)的长度和容量是预先设定、相对有限 的。如果你疯狂点单(例如无限递归),盘子堆满传送带却来不及吃,就会导致 "栈溢出" ------ 盘子掉落,秩序崩溃。
高效但短暂 :整个过程非常高效、快速,但每盘寿司的"生命周期"都很短,仅存在于从取用到吃完的这段时间。
核心对应:
传送带与自动清理 → 系统自动管理内存
固定容量与可能溢出 → 空间有限,可能栈溢出
短暂的生命周期 → 随函数调用结束而释放
🧱 堆(Heap)的比喻:大型乐高积木仓库
按需自取 :你需要多大的积木块(内存),就自己去仓库里找一块合适大小的,并登记租用 (手动分配,如
malloc)。自己管理 :用完后,你必须亲自将积木块归还 (手动释放,如
free)到仓库的指定区域。如果忘记归还,这块积木就会一直占用着,导致其他人可用的积木变少(内存泄漏)。灵活持久 :你可以租用一块积木很久,用来搭建一个长期存在的复杂模型(长久存在的对象)。仓库空间很大,但可能被分割得零散不连续(内存碎片化)。
自由但需负责 :你拥有极高的自由度 (动态分配任意大小),但也承担着管理责任 。如果你把一块已经归还的积木误认为是自己的继续使用,会引发混乱(使用已释放内存)。
核心对应:
自取与归还 → 程序员手动申请和释放内存
大型公共仓库 → 空间大,可动态增长
忘记归还导致减少 → 内存泄漏
仓库空间零散 → 内存碎片
栈是"自动的、快速的临时工位",而堆是"手动的、灵活的长期仓库"。理解它们的区别对于编写高效、安全的程序,尤其是分析和防御内存损坏漏洞至关重要。
内存损坏不仅包括缓冲区溢出,还可能包括释放后使用(Use-After-Free)、双重释放(Double Free) 等其他类型,但缓冲区溢出因其历史长、影响广而尤为典型。
1.1.2 栈内存分配与函数调用入栈顺序(重点)
| 环节 | 关键机制与顺序 |
|---|---|
| 栈的职责 | 为函数的局部变量 (如buffer[64])、参数 、返回地址等提供临时的、自动管理的空间。 |
| 生命周期 | 函数调用时分配,函数结束后自动清除(栈指针复位)。 |
| 增长方向 | 从高地址向低地址增长("向下生长")。 |
| 操作原则 | 先进后出(LIFO),像叠盘子,后放入的先取出。 |
1.1.2.1 函数调用栈帧构建顺序
以下是函数调用时栈内存入栈顺序与布局,以 x86 架构 和 cdecl 调用约定,以下是C代码示例:

通过x86汇编(32位)了解入栈过程:

🔄 入栈顺序(四步流程)
当调用 func(a, b) 时,栈的构建严格遵循以下顺序(从高地址向低地址生长):
| 步骤 | 操作 | 汇编指令示例 | 作用与说明 |
|---|---|---|---|
| ① 参数压栈 | 参数从右向左依次压入栈 | push b push a |
为函数传递参数,先压最右边的参数b,再压a |
| ② 保存返回地址 | call 指令自动完成 |
call func (隐含 push eip) |
函数执行完毕后应返回的指令地址压栈 |
| ③ 保存调用者栈基址 | 进入函数后首先保存EBP | push ebp mov ebp, esp |
保存旧栈帧基准,并设置当前函数的栈帧基址 |
| ④ 分配局部变量空间 | 调整栈指针ESP | sub esp, N (N为局部变量总大小) |
为函数内的局部变量(如数组、临时变量)预留空间 |
1.1.2.2 EBP 与 ESP 解释:x86架构中的关键栈寄存器
在 x86 架构中,EBP 和 ESP 是两个专门用于管理栈内存的核心寄存器。它们协同工作,定义了当前函数栈帧的范围与结构。
EBP 和ESP 寄存器 里存放的都是内存地址,通常以十六进制形式表示,形如:
ESP,存储的是当前栈顶的内存地址(比如 0x7FFFFFFC)。
📌 EBP:基址指针寄存器
-
EBP (Extended Base Pointer)即扩展基址指针 ,又称帧指针(Frame Pointer)。
-
它通常指向当前函数栈帧的底部(基址) ,在整个函数执行期间保持固定不变(除非显式修改)。
主要作用:
-
栈帧基准 :为函数内的局部变量和参数提供稳定的寻址参考点。
-
访问局部变量 :通过
EBP - 偏移的方式访问局部变量(例如[EBP-4]访问第一个局部变量)。 -
访问函数参数 :通过
EBP + 偏移的方式访问传入的参数(例如[EBP+8]访问第一个参数)。 -
栈帧恢复 :在函数退出时,用于恢复调用者的栈帧(
mov ESP, EBP;然后pop EBP)。
类比 :EBP 像书签 ,标记了当前函数栈帧的起始位置,让你在阅读(执行函数)时能快速定位到当前章节(栈帧)的开头。
📌 ESP:栈指针寄存器
-
ESP (Extended Stack Pointer)即扩展栈指针 ,又称栈顶指针。
-
它始终指向当前栈的顶部 (即最后一个压入栈的数据地址),其值随栈操作动态变化。
主要作用:
-
栈顶跟踪 :实时指示栈的当前可用位置。
-
压栈与弹栈 :执行
push指令时,ESP 减小 (栈向低地址生长)并存入数据;执行pop指令时,从 ESP 指向处取出数据,ESP 增大。 -
动态空间分配 :通过
sub ESP, N为局部变量动态分配空间 ;函数返回时通过add ESP, N或移动 ESP 来释放空间。
类比 :ESP 你手指的位置 ,始终指向书架上下一个可放书的位置,随着放书(压栈)或取书(弹栈)而实时移动。每放一本书,手指就往上移一点
核心区别总结:
| 寄存器 | 名称 | 指向 | 稳定性 | 主要用途 |
|---|---|---|---|---|
| EBP | 基址指针 | 当前栈帧底部(基址) | 固定(函数内不变) | 局部变量与参数寻址的基准 |
| ESP | 栈指针 | 当前栈顶部(最新数据) | 动态变化(随push/pop而变) | 管理栈顶,动态分配空间 |
1.1.2.3 栈内存布局图示
调用 add(3, 5):
函数 int add(int a, int b),其栈帧在函数执行中的典型布局如下:
高地址 (栈底方向)
┌─────────────────┐ ← 调用者栈帧结束处
│ ... │
├─────────────────┤
│ 参数 b = 5 │ ← 步骤①:先压入的第二个参数(高地址)
│ (地址:EBP+12) │
├─────────────────┤
│ 参数 a = 3 │ ← 步骤①:后压入的第一个参数(低地址)
│ (地址:EBP+8) │
├─────────────────┤
│ 返回地址 │ ← 步骤②:call 指令自动压入
│ (地址:EBP+4) │
├─────────────────┤ ← **当前 EBP 指向此处**(保存的EBP)
│ 保存的 EBP │ ← 步骤③:push ebp
├─────────────────┤ ← **当前 ESP 指向此处**(栈顶)
│ 局部变量 result │ ← 步骤④:sub esp, 4 分配的空间
│ (地址:EBP-4) │
└─────────────────┘
低地址 (栈顶方向)关键理解 :栈中数据的地址关系 是固定的。通过 EBP 可以稳定地定位参数和局部变量:
参数位于 EBP + 偏移 (如
a在EBP+8,b在EBP+12)局部变量位于 EBP - 偏移 (如
result在EBP-4)
典型函数序言(Prologue)与结语(Epilogue):
; add() 函数开始(序言)
push ebp ; 1. 保存调用者的EBP
mov ebp, esp ; 2. 设置当前栈帧基址(EBP = 当前ESP)
sub esp, 16 ; 3. 分配16字节局部变量空间(ESP下移)
; ... add() 函数体执行 ...
; add() 函数结束(结语)
mov esp, ebp ; 1. 释放局部变量空间(ESP = EBP,恢复栈顶)
pop ebp ; 2. 恢复调用者的EBP
ret ; 3. 返回到main(弹出返回地址到EIP)1.1.2.4 与缓冲区溢出的关键联系
-
溢出方向 :当局部变量(如
buffer)溢出时,数据向高地址(即向 EBP 方向)覆盖。 -
覆盖路径 :首先覆盖其他局部变量 → 覆盖保存的 EBP → 最终覆盖返回地址。
-
JMP的作用 :攻击者常利用 JMP ESP 等指令,因为 ESP 在函数返回时通常指向返回地址之后的位置,适合跳转到注入的 Shellcode。
-
攻击基础 :攻击者通过精确计算偏移,可以用恶意地址替换返回地址 ,从而在函数返回时(
ret指令)劫持程序流程。
EBP 是"栈帧的锚点",提供稳定寻址;ESP 是"栈顶的指针",实时跟踪可用空间。
两者共同构成了栈内存管理的骨架,也是理解缓冲区溢出攻击机制的基石。
欢迎❤️ 点赞 | 🔔 关注 | ⭐️ 收藏 | 💬 评论
每一份支持,都是我持续输出的光。感谢阅读,下一篇文章见。
