在生产环境中,单节点 Redis 无法满足高可用、高并发、大容量的需求 ------ 一旦节点宕机,服务直接中断;单节点内存 / 性能上限也无法支撑海量数据和高并发请求。Redis 提供了三种核心架构方案:主从复制(Master-Slave) 、哨兵模式(Sentinel) 、集群模式(Cluster),分别解决 "数据备份""自动故障转移""水平扩展" 三大核心问题。
本文将从「核心目标、架构原理、工作流程、优缺点、适用场景」五个维度,系统拆解这三种架构,帮你理清选型逻辑和落地要点。
一、先明确:三种架构的核心定位
在深入讲解前,先理清三者的核心目标,避免混淆:
- 主从复制:核心是 "数据备份"+"读写分离",解决单节点数据丢失和读压力过大问题;
- 哨兵模式:核心是 "自动故障转移",在主从复制基础上,解决主节点宕机后手动切换的痛点;
- 集群模式:核心是 "水平扩展",解决单节点内存 / 性能上限问题,支持海量数据存储和高并发访问。
三者是递进关系:主从复制是基础,哨兵模式是主从的 "高可用增强",集群模式是 "分布式扩展" 的终极方案。
二、3.1 Redis 主从复制(Master-Slave):高可用的基石
核心目标
- 数据备份:主节点(Master)的数据实时同步到从节点(Slave),避免单节点数据丢失;
- 读写分离:主节点负责写操作(增删改),从节点负责读操作(查询),分流主节点的读压力。
架构原理
- 架构组成:1 个 Master 节点 + 1 个或多个 Slave 节点(通常 2-3 个 Slave,避免单点故障);
- 数据流向:仅 Master → Slave 单向同步,Slave 不允许主动写数据(只读节点);
- 核心机制:基于 "复制偏移量" 和 "环形缓冲区" 实现增量同步,首次连接时触发全量同步。
工作流程(同步过程)
1. 初始化同步(全量同步)
Slave 节点启动后,首次连接 Master 时触发全量同步,流程如下:
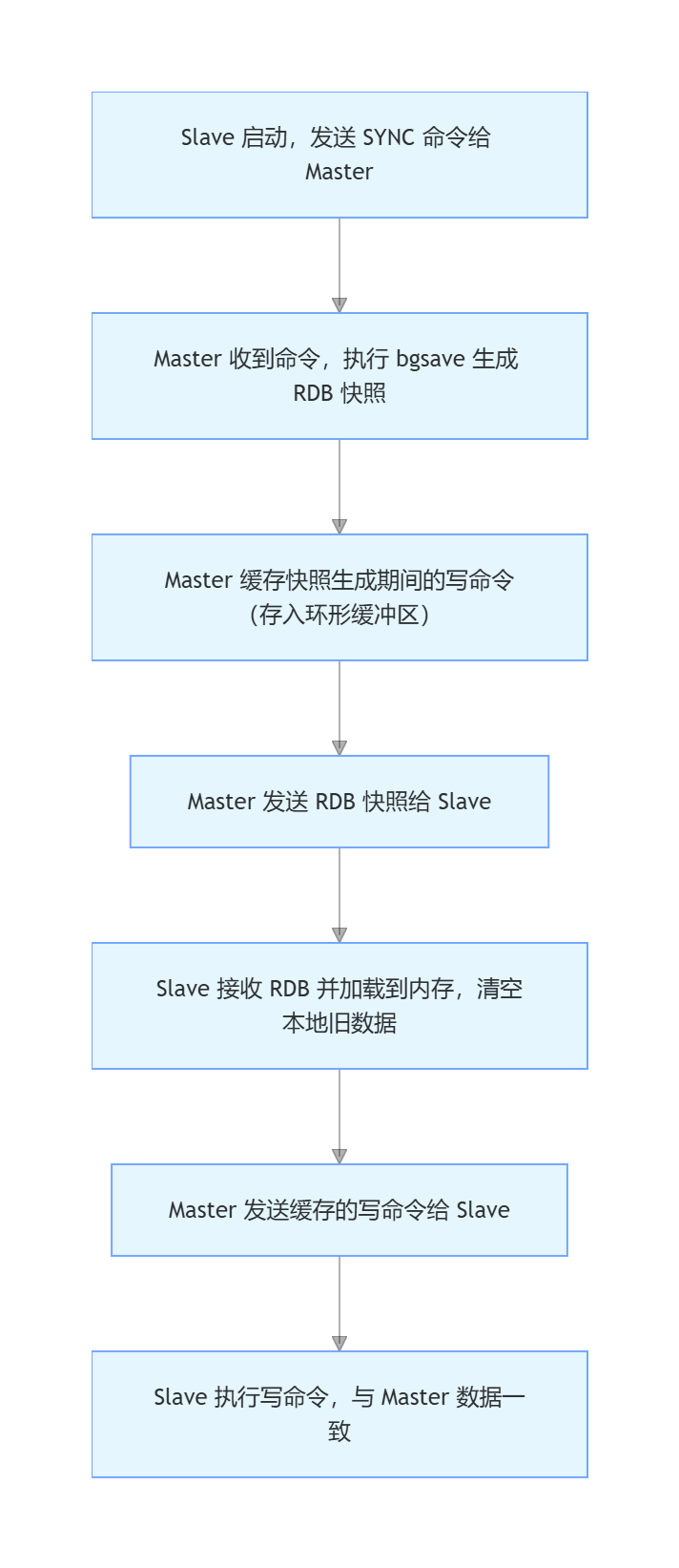
2. 增量同步(常态同步)
全量同步完成后,Master 每执行一次写命令,都会将命令同步到 Slave,流程如下:
- Master 执行写命令(如 set、incr),同时记录 "复制偏移量"(offset)和命令到环形缓冲区;
- Slave 定期向 Master 发送 "心跳包",携带自己的复制偏移量;
- Master 对比 Slave 的 offset 与自身 offset,若存在差值,发送缓冲区中缺失的命令给 Slave;
- Slave 执行命令,更新自身 offset,保持与 Master 数据一致。
关键配置(极简示例)
Master 节点配置(redis.conf)
无需特殊配置,默认即可作为 Master(仅需确保 daemonize yes 后台运行,bind 0.0.0.0 允许远程连接)。
Slave 节点配置(redis.conf)
bash# 绑定 Master 节点的 IP 和端口 replicaof 192.168.1.100 6379 # 若 Master 开启密码认证,需配置密码 masterauth 123456 # 设为只读节点(默认就是只读,显式配置更安全) replica-read-only yes
优缺点分析
优点:
- 架构简单:部署和维护成本低,适合中小型业务;
- 读写分离:分流读压力(如 Master 扛写,Slave 扛读),提升系统吞吐量;
- 数据备份:Slave 节点作为备份,Master 宕机后可手动切换到 Slave(需人工干预);
- 无性能损耗:增量同步仅传输写命令,开销小,Master 性能影响低。
缺点:
- 无自动故障转移:Master 宕机后,Slave 无法自动升级为 Master,需人工操作(导致服务中断);
- 单 Master 瓶颈:写操作全部集中在 Master,Master 性能 / 内存达到上限后无法扩展;
- 复制延迟:Slave 数据同步存在微小延迟(毫秒级),极端场景下可能读到旧数据;
- Slave 故障影响读性能:若 Slave 节点宕机,读压力会转移到其他节点,可能导致读性能下降。
适用场景
- 读多写少的业务(如电商商品详情查询、用户信息查询);
- 中小型系统,对高可用要求不高(可接受短时间人工干预);
- 需要数据备份,但预算有限(无需额外部署哨兵 / 集群)。
三、3.2 Redis Sentinel(哨兵模式):主从架构的高可用增强
核心目标
在主从复制基础上,解决 "Master 宕机后自动故障转移" 问题,无需人工干预,实现 Redis 服务高可用(HA)。
架构原理
- 架构组成:1 个主从复制集群 + 3 个或多个 Sentinel 节点(推荐 3 个,避免 Sentinel 自身单点故障);
- Sentinel 核心职责:
- 监控:实时检测 Master、Slave 节点的健康状态;
- 通知:当节点故障时,通过 API 通知管理员或其他应用;
- 自动故障转移:Master 宕机后,自动从 Slave 中选举新 Master,并重配置其他 Slave 同步新 Master;
- 配置中心:客户端通过 Sentinel 获取当前 Master 节点地址(无需硬编码 Master IP)。
工作流程
1. 监控机制
- Sentinel 节点定期(默认 1 秒)向所有 Master、Slave 发送
PING命令,检测节点存活; - 若节点在 "down-after-milliseconds" 配置时间内(如 3000 毫秒)未回复
PONG,Sentinel 标记该节点为 "主观下线(SDOWN)"; - 若被标记为 SDOWN 的是 Master 节点,其他 Sentinel 节点会在 "quorum" 配置时间内(如 5000 毫秒)确认该 Master 确实下线,标记为 "客观下线(ODOWN)"------ 此时触发故障转移。
2. 自动故障转移流程
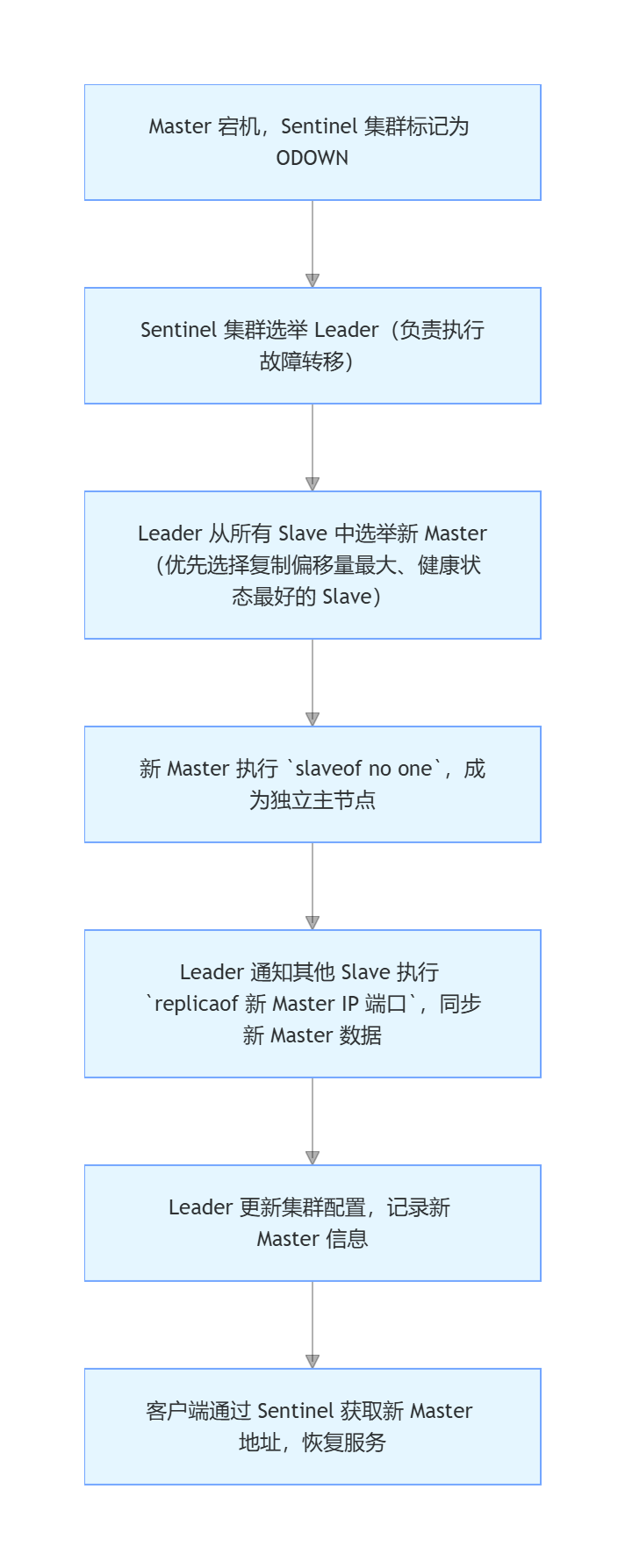
关键配置(极简示例)
Sentinel 配置文件(sentinel.conf)
bash
# 后台运行
daemonize yes
# 监控目标 Master:名称(自定义)、IP、端口、quorum(确认下线的 Sentinel 最小数量)
sentinel monitor mymaster 192.168.1.100 6379 2
# Master 宕机后,多少毫秒内未回复视为下线(主观下线阈值)
sentinel down-after-milliseconds mymaster 3000
# 故障转移超时时间(若超过该时间未完成转移,视为失败)
sentinel failover-timeout mymaster 180000
# 若 Master 开启密码认证,Sentinel 需配置密码
sentinel auth-pass mymaster 123456
# 故障转移时,最多允许多少个 Slave 同时同步新 Master(避免同步压力过大)
sentinel parallel-syncs mymaster 1客户端连接方式(Java 示例)
客户端不再直接连接 Master,而是通过 Sentinel 集群获取 Master 地址:
java
// 配置 Sentinel 节点列表
Set<String> sentinelSet = new HashSet<>();
sentinelSet.add("192.168.1.101:26379");
sentinelSet.add("192.168.1.102:26379");
sentinelSet.add("192.168.1.103:26379");
// 连接 Sentinel,指定 Master 名称
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinelSet, "123456");
// 获取 Jedis 实例(自动连接当前 Master)
Jedis jedis = pool.getResource();
jedis.set("key", "value");
System.out.println(jedis.get("key"));优缺点分析
优点:
- 自动故障转移:Master 宕机后无需人工干预,秒级切换,服务可用性高;
- 架构兼容:基于主从复制扩展,无需重构原有主从架构;
- 客户端透明:客户端通过 Sentinel 获取 Master 地址,无需关心 Master 切换;
- Sentinel 高可用:多个 Sentinel 节点组成集群,避免 Sentinel 自身单点故障。
缺点:
- 单 Master 瓶颈:仍未解决 Master 写性能 / 内存上限问题(写操作仍集中在单个 Master);
- 故障转移期间短暂不可写:故障转移过程中(约 1-3 秒),Master 处于切换状态,写操作会暂时失败(需客户端重试);
- 配置复杂:相比主从复制,Sentinel 配置和维护成本更高(需管理多个 Sentinel 节点);
- 复制延迟:仍存在 Slave 数据同步延迟问题(与主从复制一致)。
适用场景
- 读多写少,对高可用要求高(如电商订单、支付系统);
- 写压力适中,单 Master 可支撑(无需水平扩展写性能);
- 不希望人工干预节点故障(如 7×24 小时服务)。
四、3.3 Redis Cluster(集群模式):分布式扩展的终极方案
核心目标
解决 "单节点内存 / 性能上限" 问题,通过分片(Sharding)将数据分散到多个节点,实现:
- 水平扩展:存储容量(内存)和并发性能(读写吞吐量)随节点数量线性提升;
- 高可用:每个分片(Shard)都有主从复制,支持自动故障转移(类似 Sentinel);
- 分布式存储:数据按规则分片,每个节点仅存储部分数据(避免单节点存储海量数据)。
架构原理
1. 核心概念
- 集群组成:至少 3 个主节点(Master),每个主节点可配置 1 个或多个从节点(Slave);
- 数据分片:Redis Cluster 采用 "哈希槽(Hash Slot)" 分片机制,共 16384 个哈希槽(0-16383);
- 槽位分配:每个 Master 节点负责一部分槽位(如 3 个 Master 节点,分别负责 0-5460、5461-10922、10923-16383 槽位);
- 数据路由:客户端计算 Key 的哈希值(
CRC16(key) % 16384),得到对应的槽位,再将请求路由到负责该槽位的 Master 节点; - 自动故障转移:每个分片的 Master 宕机后,其 Slave 会自动升级为 Master(无需额外部署 Sentinel)。
2. 架构示意图
bash
[Master 1] 负责槽位 0-5460 → 从节点 Slave 1-1、Slave 1-2
[Master 2] 负责槽位 5461-10922 → 从节点 Slave 2-1、Slave 2-2
[Master 3] 负责槽位 10923-16383 → 从节点 Slave 3-1、Slave 3-2
↓ ↑
客户端请求 → 计算 Key 槽位 → 路由到对应 Master 节点故障转移流程(某 Master 宕机)
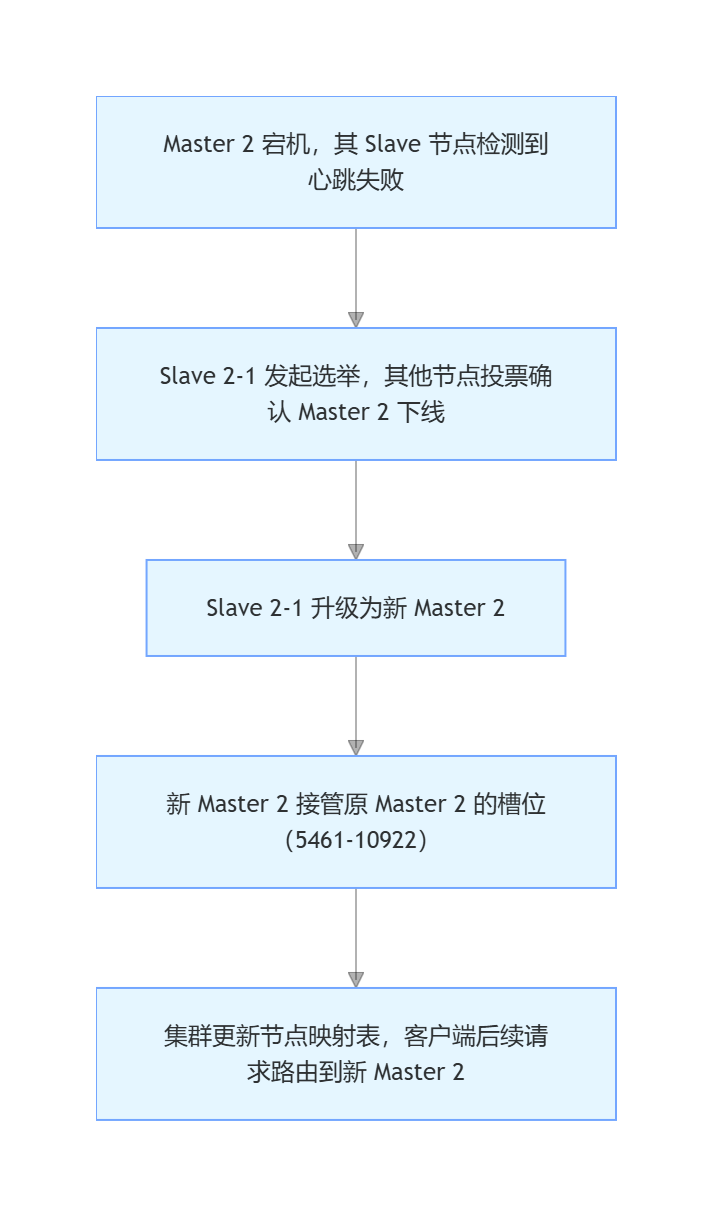
关键配置(极简示例)
节点配置文件(redis.conf)
bash
# 开启集群模式
cluster-enabled yes
# 集群配置文件(自动生成和更新,无需手动修改)
cluster-config-file nodes-6379.conf
# 节点超时时间(毫秒,超过该时间未响应视为下线)
cluster-node-timeout 15000
# 后台运行
daemonize yes
# 绑定 IP(允许远程连接)
bind 0.0.0.0
# 密码认证(可选)
requirepass 123456
masterauth 123456集群搭建关键命令(redis-cli)
bash
# 1. 启动 6 个节点(3 主 3 从,端口 6379-6384)
redis-server redis-6379.conf
redis-server redis-6380.conf
...
redis-server redis-6384.conf
# 2. 创建集群(--replicas 1 表示每个主节点配 1 个从节点)
redis-cli --cluster create 192.168.1.100:6379 192.168.1.100:6380 192.168.1.100:6381 192.168.1.100:6382 192.168.1.100:6383 192.168.1.100:6384 --cluster-replicas 1
# 3. 查看集群状态
redis-cli -c -h 192.168.1.100 -p 6379 cluster info客户端连接方式(Java 示例)
客户端需支持集群模式(如 JedisCluster),自动处理数据路由:
bash
// 配置集群节点列表
Set<HostAndPort> nodeSet = new HashSet<>();
nodeSet.add(new HostAndPort("192.168.1.100", 6379));
nodeSet.add(new HostAndPort("192.168.1.100", 6380));
nodeSet.add(new HostAndPort("192.168.1.100", 6381));
nodeSet.add(new HostAndPort("192.168.1.100", 6382));
nodeSet.add(new HostAndPort("192.168.1.100", 6383));
nodeSet.add(new HostAndPort("192.168.1.100", 6384));
// 创建 JedisCluster 实例(自动路由)
JedisCluster cluster = new JedisCluster(nodeSet, 10000, 10000, 3, "123456", new GenericObjectPoolConfig<>());
// 执行命令(无需关心路由,客户端自动处理)
cluster.set("user:1001", "张三");
System.out.println(cluster.get("user:1001"));优缺点分析
优点:
- 水平扩展:存储容量和读写性能随节点数量线性提升(支持数十个 Master 节点);
- 高可用:每个分片支持主从复制和自动故障转移,无单点故障;
- 分布式存储:数据分片存储,避免单节点内存溢出;
- 无需 Sentinel:集群内置故障转移机制,简化架构(无需额外部署 Sentinel);
- 客户端透明:客户端自动处理数据路由和节点切换,无需关心集群拓扑。
缺点:
- 架构复杂:部署、维护、监控成本高(需管理多个节点和分片);
- 不支持跨槽位操作:如
MSET key1 value1 key2 value2若 key1 和 key2 属于不同槽位,命令会失败(需手动指定槽位或使用 Hash Tag 绑定); - 数据迁移成本高:扩容 / 缩容时需要迁移槽位和数据,过程复杂(需工具支持);
- 学习成本高:需理解哈希槽、分片、故障转移等分布式概念;
- 内存开销大:每个节点需存储集群拓扑、槽位映射等信息,内存占用比单节点高。
适用场景
- 海量数据存储(如千万级用户信息、亿级商品数据);
- 高并发读写场景(如秒杀、直播带货,读写 QPS 达 10 万 +);
- 写压力大,单 Master 无法支撑(需水平扩展写性能);
- 对系统可用性和扩展性要求极高的大型互联网应用。
五、三种架构核心对比与选型建议
核心对比表
| 对比维度 | 主从复制(Master-Slave) | 哨兵模式(Sentinel) | 集群模式(Cluster) |
|---|---|---|---|
| 核心目标 | 数据备份 + 读写分离 | 自动故障转移(高可用) | 水平扩展(存储 + 性能)+ 高可用 |
| 节点组成 | 1 主 N 从 | 1 主 N 从 + 3+ 哨兵 | 3+ 主 N 从(每个主节点是分片) |
| 写性能 | 单节点上限 | 单节点上限 | 线性扩展(随主节点数量增加) |
| 存储容量 | 单节点上限 | 单节点上限 | 线性扩展(随节点数量增加) |
| 故障转移 | 手动切换 | 自动切换(秒级) | 自动切换(分片级) |
| 数据分片 | 无(所有节点存储全量数据) | 无(所有节点存储全量数据) | 有(哈希槽分片,部分数据) |
| 部署维护成本 | 低 | 中 | 高 |
| 跨节点操作支持 | 支持(全量数据) | 支持(全量数据) | 有限(不支持跨槽位批量操作) |
| 适用并发量级 | 低 - 中(QPS 万级) | 中(QPS 万 - 10 万级) | 高(QPS 10 万 +) |
选型建议(从简单到复杂,逐步升级)
-
初创 / 小型系统:优先选「主从复制」
- 场景:数据量小(GB 级)、并发低(QPS 万级以下)、对高可用要求不高;
- 优势:开发部署简单,成本低,能满足基础的读写分离和数据备份需求。
-
中型系统(读多写少):升级为「哨兵模式」
- 场景:数据量中等(GB 级)、并发中(QPS 万 - 10 万级)、要求 7×24 小时高可用;
- 优势:在主从复制基础上,实现自动故障转移,无需人工干预,保障服务连续性。
-
大型 / 高并发系统:最终升级为「集群模式」
- 场景:数据量大(10GB+)、并发高(QPS 10 万 +)、写压力大(单 Master 无法支撑);
- 优势:通过分片实现存储和性能的水平扩展,同时内置高可用机制,满足大型应用需求。
避坑指南
- 不要过度设计:先从主从复制落地,再根据业务增长逐步升级到哨兵 / 集群,避免一开始就承担高维护成本;
- 集群模式注意槽位均衡:扩容时确保槽位均匀分配到新节点,避免单节点负载过高;
- 哨兵模式建议 3 个节点:1 个或 2 个 Sentinel 节点存在单点故障风险,3 个节点可满足 "多数投票" 需求;
- 主从复制注意复制延迟:读多写少场景下,可将非核心读请求路由到 Slave,核心读请求路由到 Master,避免读到旧数据。
总结
Redis 三种架构的演进,本质是 "从单节点到分布式" 的升级过程:
- 主从复制解决 "数据备份和读分离",是高可用的基础;
- 哨兵模式解决 "自动故障转移",是主从架构的高可用增强;
- 集群模式解决 "水平扩展",是海量数据和高并发场景的终极方案。
选型的核心原则是:匹配业务规模和需求,以 "最小成本满足业务" 为目标。大多数业务无需一开始就上集群,先通过主从复制 + 哨兵模式支撑业务增长,当数据量和并发达到单节点上限时,再升级到集群模式。