来介绍一下卡方。
卡方是用数据来判断某些东西的相关程度的一个数值,我们将这些判断的事物称之为分类变量。注意这里是相关程度,也就意味着结果是以概率来定义的。因此可以得到卡方的一个核心思想
卡方检验主要用于判断分类变量之间是否存在显著关系,但其本身不揭示关联的具体性质或因果关系。
我们都知道,不同性别的人喜欢阅读不同种类的书籍,可能男生比较喜欢科幻悬疑类的,女生比较喜欢青春恋爱之类的。我们就可以说性别与阅读喜好有关(在科学上已经得到证明了),但是我们不能说性别决定阅读喜好,如果是那样的话,你怎么可能还能看到一个女孩子在看武侠小说?关联性强调的是一种概率上的发生,而不是因果关系。
另外,我们要得到卡方,就必须要先得到许多个数据。从这些数据的来源出发,我们又可以得到一个性质
卡方的结果是有一定范围的普遍性的
这里说是一定范围,也就意味着你不能用对于一个学校的学生的调查研究来断定一个外省人口的关于性别与阅读爱好的关系。这样真的太离谱了!
那么它的结果表示什么?
简单的说
卡方的结果是衡量实际观测数据与理论期望偏离程度的一个统计量。
只要大于这个临界值就有这个临界值对应的把握认为某某有关或无关。
这个临界值是在一个叫卡方分布的表格中查出来的。
每个临界值都会对应一个期望(就是把握)
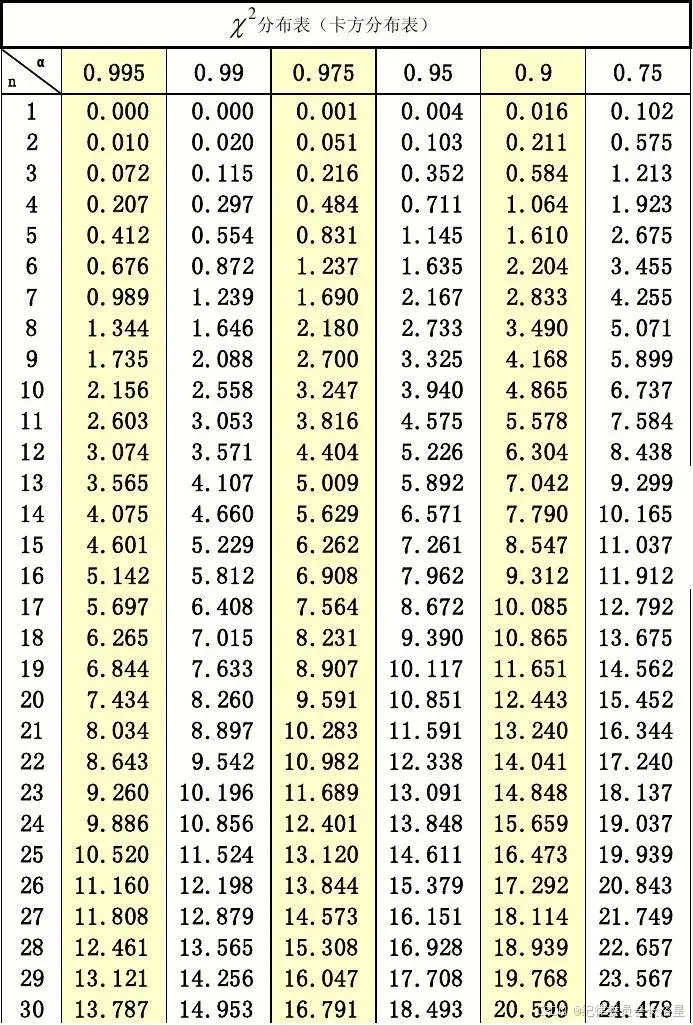
不用完全记下来。只要知道一些常见的,比如99%,95%。
其应用就非常广泛了,就讲几个常见的。
1.内容推荐
又是内容推荐,上次是回归线,这次是卡方,但他们的原理是不一样的,对象都不一样。卡方一般用于群体的内容推荐,而不仅仅针对单个用户。当然,开发者肯定是以个人为主,群体为辅了,毕竟我们用的是个人设备。他会从群体当中提取多个属性,比如年龄、性别。然后再以这些基准对一群用户进行分析,得到一些与之前提取到的属性关系比较密切的喜好。分析其卡方,如果关联性很强,那么就会按照用户的一些属性进行内容推荐。
就拿我们常见的社交平台来说,如果一群北京用户经常观看关于北京的纪录片,而其他地区的用户却没有这个习惯。那么系统就很有可能会给刚刚注册的北京地区的用户推荐关于北京的纪录片。
但实际上现实比这更加复杂,因为一个人的基本信息中是有很多可以提取到的关键信息的。平台肯定不会只收集一个信息吧?
有一说一,那些面向年轻用户的社交软件又吃到了算法的红利。
2.信息过滤
这种算法最常见于垃圾邮件的过滤。系统会对许多封邮件进行数据采集,分析其中的内容,提出一些关键词语,将邮件分为两组------垃圾邮件和普通邮件。根据关键词的各种排列组合数量,再结合各组对应的关键词数量。判断如果这封邮件中出现了某某个关键词,应该有多少的把握认为它是垃圾邮件。如果这个把握大于某个固定值,那么系统就会视为垃圾邮件。
运用到的也就是一个方差分析,用多个数据来分析一个单个数据。
不过这种分析法在如今已经慢慢退出市场了,因为它的局限性太明显了。只能提炼关键词,像一些关键词在许多普通的邮件中也会出现。比如说"你中奖了",原本只是同事发的一个好消息,却被当成了垃圾邮件过滤。为了减少这种事情的发生,工程师们在后来推出了上下文理解法,这也开始加速大数据时代的来临。
3.人工智能学习
卡方分析是一种很基础、很成熟的人工智能学习方法。其核心思想就是根据一个事物的特征判断这个事物。比如给系统输入1万张猫的照片,再输入2000张狗的照片。猫的耳朵是三角形,尖尖的,狗的耳朵是垂下来的。可以得到一个观点:有99%的把握认为在猫和狗中长三角耳朵的动物是猫。这样一来,系统就可以根据动物耳朵的特性来判断它是猫还是狗了。可惜这种方法还是有严重的缺点,只能捕捉到几个局部的特征,无法对拥有这几个局部特征的其他物种进行判断。系统很有可能会把一个在漫展上戴着猫耳的少女识别成猫,然后对她说宠物不得入内。为了防止这种事件的产生,工程师们发明了更先进的训练人工智能的方法。
但是这种以偏概全的训练方法,依然是许多人工智能开发者最先使用的,因其成本低,而且难度低。