YOLOv5 完整入门与实践指南
本文从零开始,详细介绍 YOLOv5 的安装、数据准备、模型训练到实际部署的全过程,适合初学者和需要快速上手的开发者。
温馨提示:实际动手操作一次完整的训练流程(数据准备→标注→训练→测试),比看10篇教程更有用!
目录
- [1. YOLOv5 概览:历史、原理与特点](#1. YOLOv5 概览:历史、原理与特点)
- 快速开始
- 第一章:环境配置
- 第二章:数据集的制作与标注
- 第三章:模型训练与调优
- 第四章:模型应用与部署
- 第五章:进阶学习与应用拓展
- 常见问题与解决方案
- 总结与后续学习
1. YOLOv5 概览:历史、原理与特点
在进入实战之前,了解YOLO系列的发展脉络和YOLOv5的核心思想至关重要。这能帮助您理解其设计选择,并在遇到问题时更好地进行调优。
1.1 YOLO:目标检测的范式革命
YOLO(You Only Look Once)的出现是目标检测领域的一个里程碑。在YOLO之前,主流的两阶段检测器(如R-CNN系列)将任务分解为"生成候选框"和"对候选框分类"两步,虽然准确但速度慢。YOLO开创性地提出了 "单阶段(One-Stage)" 检测思想:
- 核心思想: 将目标检测视为一个单次的回归问题。将输入图像划分为 S×S 的网格,每个网格单元直接预测边界框(Bounding Box)的位置、大小和类别概率。
- 工作流程: 只需将图像输入一个卷积神经网络,网络会一次性输出所有目标的预测结果。
- 最大优势: 极致的速度。YOLO可以实现实时检测,为视频分析、自动驾驶、机器人等对延迟要求高的场景打开了大门。
1.2 YOLOv5 的定位与争议
YOLOv5 由 Ultralytics 公司于2020年6月发布。需要注意的是,它与YOLO原作者Joseph Redmon的官方系列(v1-v3)没有直接继承关系,这也是它名称引发一些讨论的原因。然而,它迅速流行开来,并已成为工业界和学术界最广泛使用的YOLO实现之一,这归功于其卓越的工程化优势:
- 框架友好: 完全基于 PyTorch 框架开发,与PyTorch生态无缝集成,对于熟悉PyTorch的开发者来说,安装、调试和二次开发极其方便。
- 易于使用: 提供了极其清晰、模块化的代码结构和详尽的文档。其命令行接口设计得非常人性化,几行命令即可完成训练、验证、测试和推理全过程。
- 高性能: 在保持高检测精度的同时,推理速度非常快,并且对硬件资源(从服务器GPU到边缘设备)的适应性很好。
- 生态丰富: 拥有庞大的社区支持,有大量针对不同场景(如无人机、医疗、工业质检)的预训练模型和微调教程。
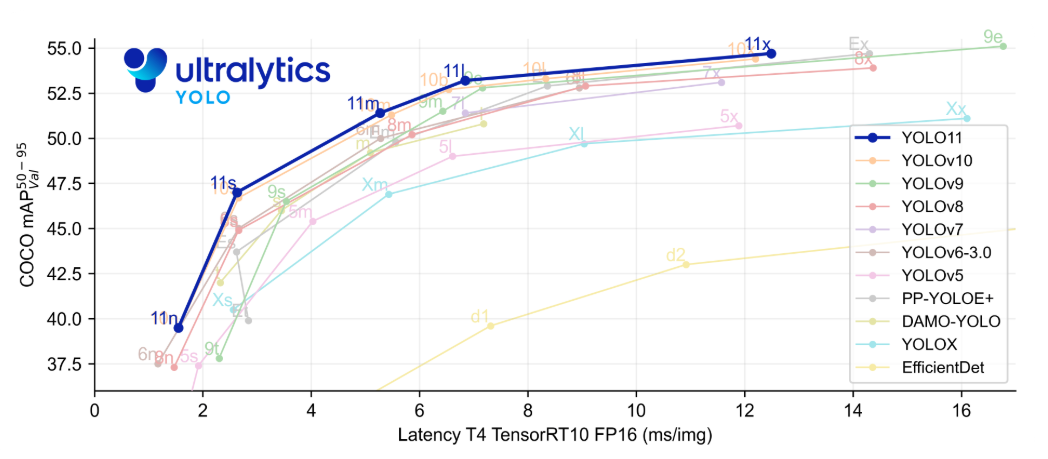
一句话总结:YOLOv5 可能不是理论创新最多的,但它是迄今为止最"好用"、最"接地气"的YOLO实现之一。
1.3 YOLOv5 网络结构与核心组件
YOLOv5 的网络结构可以清晰地分为四个部分:
-
Backbone(主干网络): CSPDarknet。这是YOLOv5特征提取的核心。它借鉴了CSPNet(Cross Stage Partial Networks)的思想,通过将特征图分成两部分并进行不同处理后再合并,在增强特征学习能力的同时,显著减少了计算量,并缓解了梯度消失问题。
-
Neck(颈部): PANet(Path Aggregation Network) 。为了有效检测不同尺度的目标(如近处的大目标和远处的小目标),YOLOv5在Backbone之后使用了PANet作为特征金字塔。它通过自上而下和自下而上的双向路径,将深层语义特征(利于分类)和浅层细节特征(利于定位)进行充分融合,提升了多尺度检测能力。
-
Head(检测头): 最终负责预测的部分。YOLOv5采用了三个不同尺度的检测头,分别对应大、中、小目标的检测。每个检测头会输出三种信息:
- 边界框(BBox): 预测框的中心坐标 (x, y)、宽高 (w, h)。
- 置信度(Confidence): 该框内包含目标的可信度。
- 类别概率(Class Probability): 该目标属于各个类别的概率。
-
损失函数(Loss Function): YOLOv5的损失函数是多项之和,用于指导网络训练:
- 分类损失(Class Loss): 通常使用二元交叉熵(BCE)损失,衡量预测类别与真实类别的差异。
- 定位损失(Box Loss): YOLOv5默认使用 CIoU Loss。它比传统的IoU Loss更优,不仅考虑重叠面积,还考虑了中心点距离和宽高比的差异,使边界框回归更精准。
- 置信度损失(Objectness Loss): 同样是BCE损失,用于判断网格内是否有目标。
1.4 YOLOv5 的模型家族

YOLOv5 提供了多个预定义模型,以适应不同的速度与精度权衡:
- YOLOv5n / YOLOv5s: 轻量级模型,参数量小,速度快,适合移动端或嵌入式设备。
- YOLOv5m: 中等模型,平衡了速度和精度。
- YOLOv5l / YOLOv5x: 大型模型,参数量大,精度最高,但速度较慢,适合服务器端部署。
您可以根据自己的具体需求(是追求实时性还是追求最高准确率)来选择合适的模型作为起点。
了解了这些核心概念,您就能更胸有成竹地进入接下来的实战环节。让我们开始配置环境,准备数据,亲手训练一个属于自己的YOLOv5模型吧!
快速开始
最简单的代码示例 - 5分钟内体验YOLOv5的强大功能
python
import torch
import cv2
import os
# 检测模型
if "yolov5s.pt" not in os.listdir("."):
# 自动下载模型
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
else:
# 加载模型 + 打开摄像头
model = torch.hub.load('ultralytics/yolov5', 'custom', path='./yolov5s.pt')
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
results = model(frame)
# 显示画面
cv2.imshow('检测', results.render()[0])
# 打印结果(每帧)
for *box, conf, cls in results.xyxy[0]:
print(f"{results.names[int(cls)]}: {float(conf):.2%}")
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()运行上述代码,将开始进行实时目标检测。每帧图像会显示检测结果,并打印出每帧的检测结果。
第一章:环境配置
1.1 前置环境清单
- 必须: Python 环境、Anaconda 环境、Git 环境
- 可选但推荐: CUDA 环境(GPU加速需要)、PyTorch 环境
1.2 详细安装步骤
注意: 如果你不想从头开始配置,可以使用我们的YOLOv5 整合包,包含了完整的图片数据、模型文件、标注过程和执行方法。
从零开始安装:
bash
# 1. 克隆项目
git clone https://github.com/ultralytics/yolov5
cd yolov5-7.0
# 2. 创建虚拟环境
conda create -n yolov5 python=3.8
conda activate yolov5
# 3. 配置国内镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 安装依赖包
pip install -r requirements.txt
# 5. 下载预训练模型
# Windows
wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt
# Linux
wget https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt -O yolov5s.pt
# 6. 安装PyTorch(根据你的硬件选择)
# CPU版本
conda install pytorch torchvision torchaudio cpuonly -c pytorch
# GPU版本(CUDA 12.x)
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu121验证安装:
bash
# 查看GPU信息(如果有的话)
nvidia-smi
# 运行测试
python detect.py --weights yolov5s.pt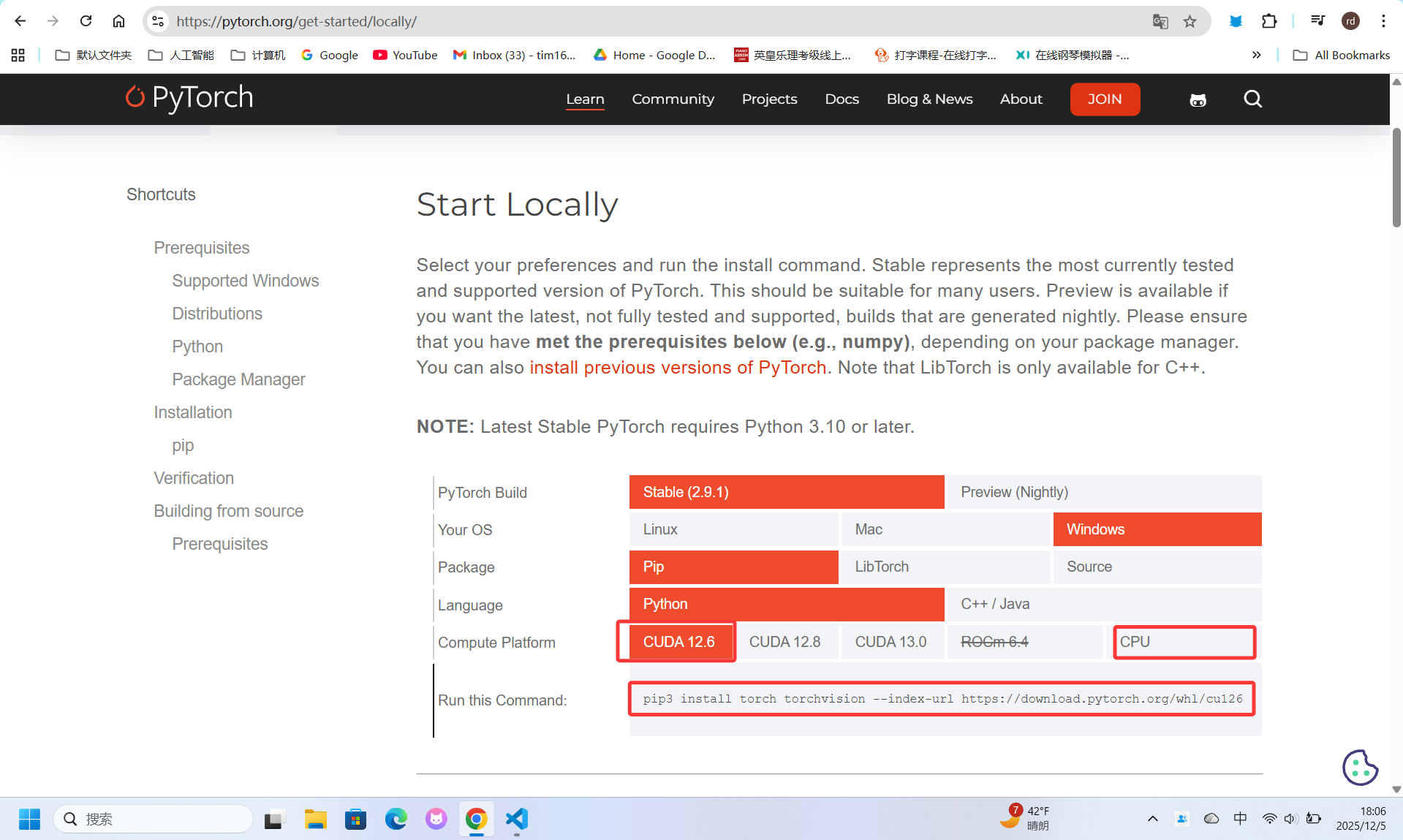
1.3 高级运行选项
YOLOv5支持多种输入源和输出格式:
bash
# 基本格式
python detect.py --weights yolov5s.pt --source [输入源]
# 输入源示例:
--source 0 # 摄像头
--source img.jpg # 单张图片
--source vid.mp4 # 视频文件
--source path/ # 图片文件夹
--source 'path/*.jpg' # 通配符匹配
--source 'https://youtu.be/xxx' # YouTube视频
--source 'rtsp://...' # RTSP流
# 输出格式支持:
--weights yolov5s.pt # PyTorch
--weights yolov5s.onnx # ONNX格式
--weights yolov5s.tflite # TensorFlow Lite
--weights yolov5s_openvino_model # OpenVINO
# ... 更多格式见官方文档
# 常用参数:
--view-img # 实时显示结果
--save-txt # 保存检测结果为txt文件
--save-conf # 保存置信度
--conf-thres 0.25 # 置信度阈值
--iou-thres 0.45 # IOU阈值实战示例:
bash
# 开启摄像头实时识别并显示
python detect.py --weights yolov5s.pt --source 0 --view-img
# 检测视频并保存结果
python detect.py --weights yolov5s.pt --source video.mp4 --save-txt检测效果示例:

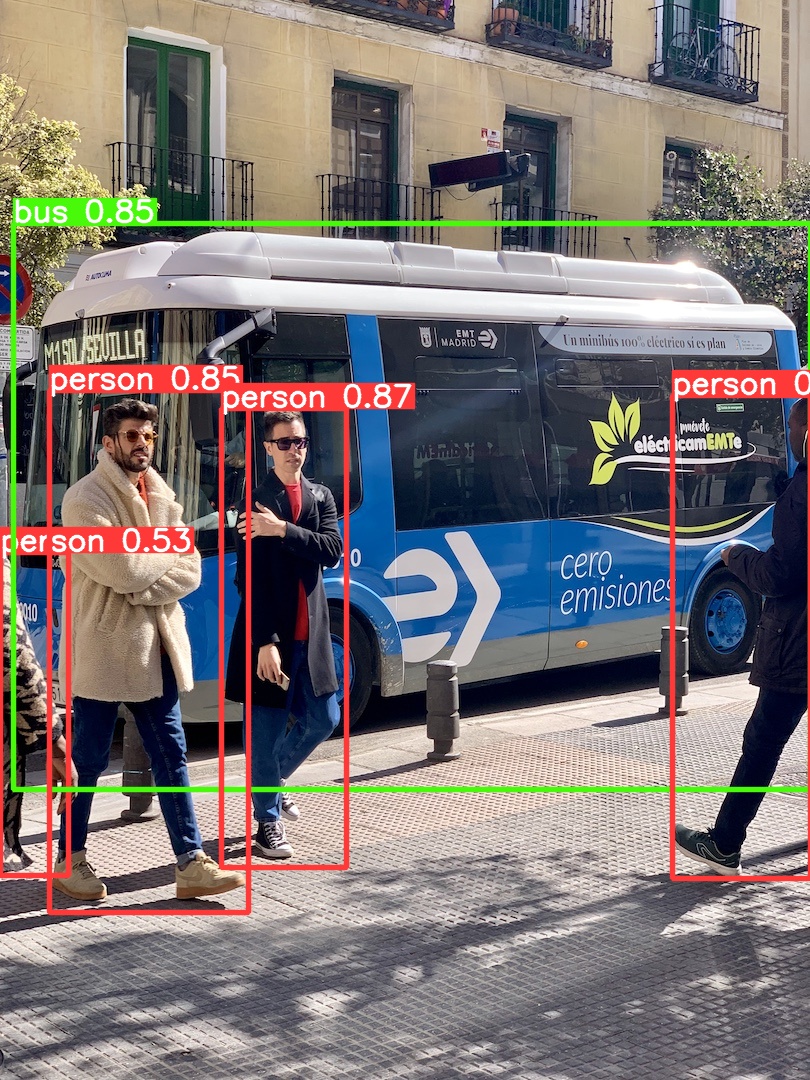
第二章:数据集的制作与标注
2.1 数据收集方法
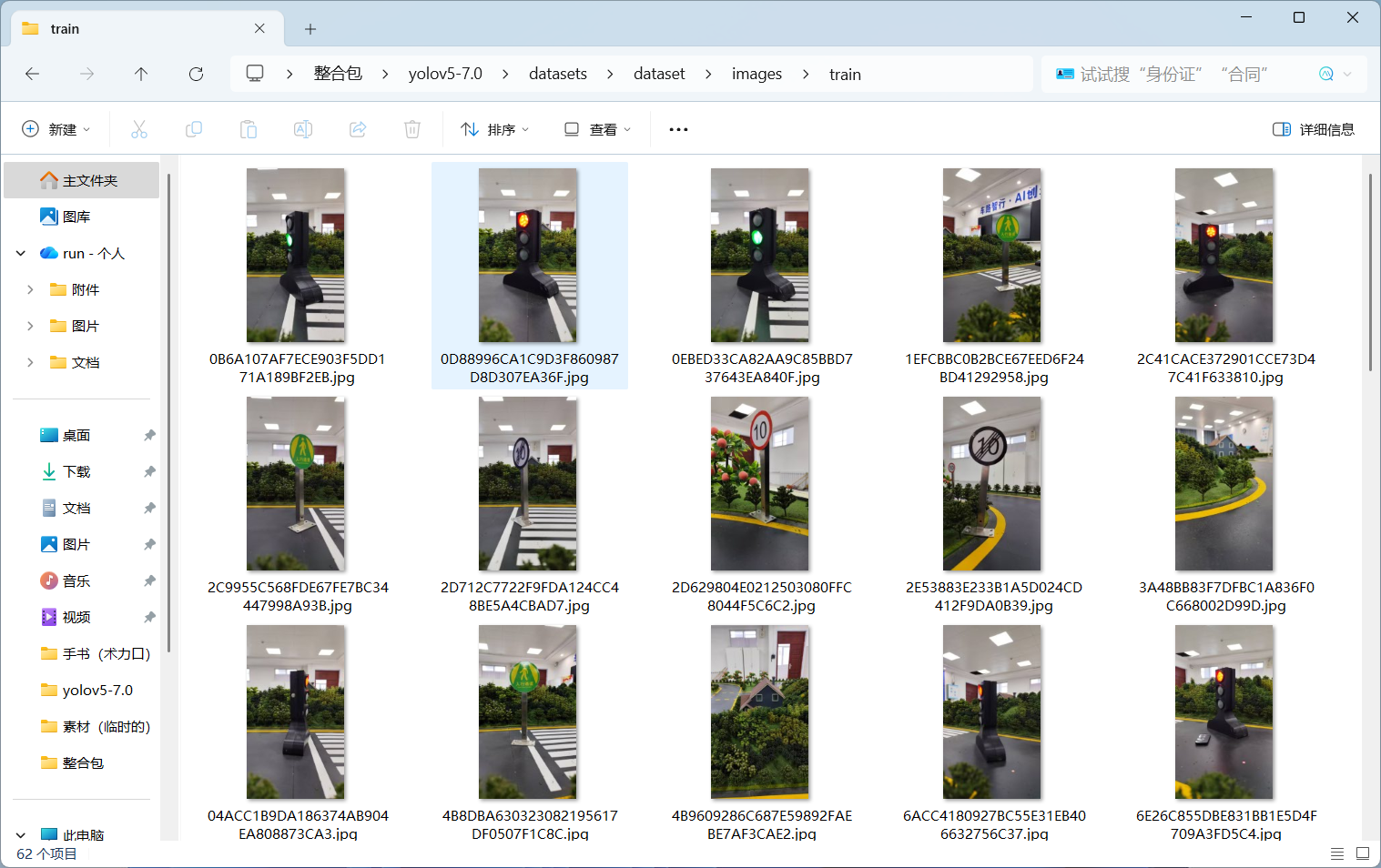
三种主要数据收集方式:
- 直接拍照 - 适合特定场景的定制化数据集
- 视频提取 - 从视频中抽取关键帧
- 网络收集 - 从公开数据集或网络上收集
2.2 视频帧提取工具
python
# cv2video.py - 高级视频帧提取工具
import cv2
import os
import argparse
from tqdm import tqdm
def extract_frames_advanced(video_path, output_folder,
interval=1,
quality=95,
format='jpg',
start_time=0,
end_time=None,
resize=None):
"""
高级视频帧提取功能
参数:
video_path: 视频路径
output_folder: 输出文件夹
interval: 帧间隔(每隔多少帧取一张)
quality: 图片质量(1-100)
format: 图片格式(jpg, png)
start_time: 开始时间(秒)
end_time: 结束时间(秒)
resize: 调整尺寸 (宽,高),如(640,480)
"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise ValueError("无法打开视频文件")
# 获取视频信息
fps = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
duration = total_frames / fps
# 计算开始和结束帧
start_frame = int(start_time * fps)
end_frame = total_frames if end_time is None else int(end_time * fps)
end_frame = min(end_frame, total_frames)
print(f"视频时长: {duration:.2f}s")
print(f"提取范围: {start_time}s - {end_time if end_time else duration:.2f}s")
print(f"帧间隔: {interval}帧")
# 设置起始帧
cap.set(cv2.CAP_PROP_POS_FRAMES, start_frame)
saved_count = 0
current_frame = start_frame
# 创建进度条
with tqdm(total=(end_frame - start_frame) // interval, desc="提取进度") as pbar:
while current_frame < end_frame:
ret, frame = cap.read()
if not ret:
break
if current_frame % interval == 0:
# 调整尺寸
if resize:
frame = cv2.resize(frame, resize)
# 生成文件名
timestamp = current_frame / fps
filename = f"frame_{saved_count:06d}_{timestamp:.2f}s.{format}"
filepath = os.path.join(output_folder, filename)
# 保存图片
if format.lower() == 'jpg':
cv2.imwrite(filepath, frame, [cv2.IMWRITE_JPEG_QUALITY, quality])
else:
cv2.imwrite(filepath, frame)
saved_count += 1
pbar.update(1)
current_frame += 1
cap.release()
print(f"完成! 共保存 {saved_count} 张图片到 {output_folder}")
return saved_count
# 命令行接口
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="视频帧提取工具")
parser.add_argument("video", help="输入视频文件路径")
parser.add_argument("-o", "--output", default="frames", help="输出文件夹")
parser.add_argument("-i", "--interval", type=int, default=30, help="帧间隔")
parser.add_argument("-q", "--quality", type=int, default=95, help="图片质量")
parser.add_argument("-f", "--format", default="jpg", help="图片格式")
parser.add_argument("-s", "--start", type=float, default=0, help="开始时间(秒)")
parser.add_argument("-e", "--end", type=float, help="结束时间(秒)")
parser.add_argument("-r", "--resize", help="调整尺寸,如 640x480")
args = parser.parse_args()
# 解析resize参数
resize = None
if args.resize:
w, h = map(int, args.resize.split('x'))
resize = (w, h)
extract_frames_advanced(
video_path=args.video,
output_folder=args.output,
interval=args.interval,
quality=args.quality,
format=args.format,
start_time=args.start,
end_time=args.end,
resize=resize
)使用示例:
bash
# 基本使用:提取视频前10秒,每秒2帧
python cv2video.py video.mp4 -o frames_output -i 15 -s 0 -e 10
# 高级使用:提取完整视频,每30帧一张,调整为640x480
python cv2video.py video.mp4 -o my_frames -i 30 -r 640x480 -q 90
# Python脚本调用
extract_frames_advanced("video.mp4", "frames_output", interval=15,
start_time=0, end_time=10, resize=(640, 480), quality=90)2.3 使用LabelImg进行标注
安装(推荐Python 3.7环境):
bash
# 创建专用环境
conda create -n labelimg python=3.7
conda activate labelimg
# 安装labelimg
pip install labelimg
# 启动
labelimg标注步骤:
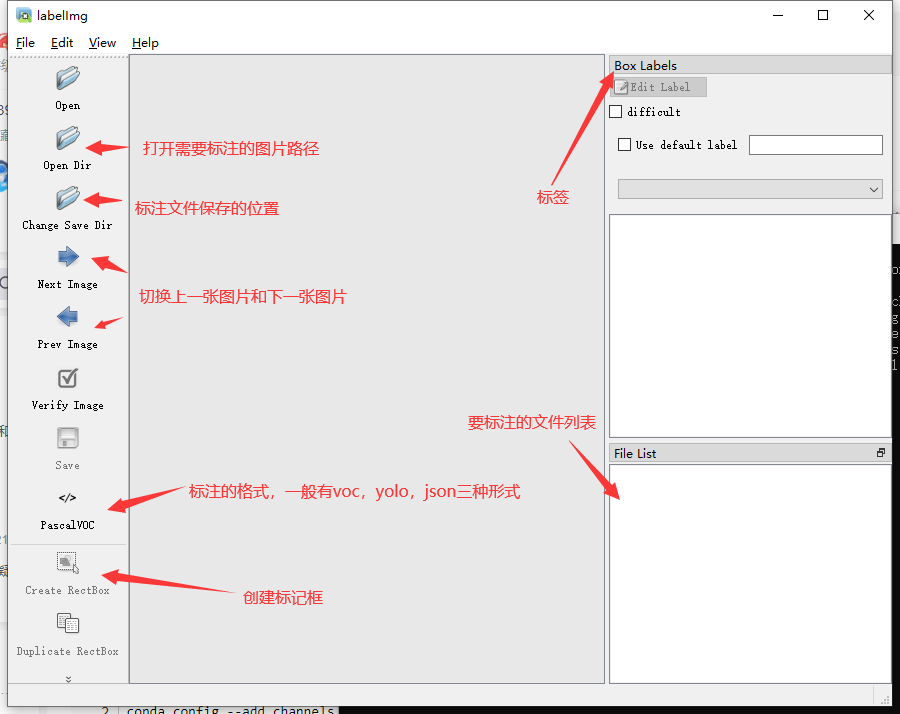
- 打开图片文件夹 - 点击"Open Dir"选择图片所在目录
- 设置标注格式 - 在菜单栏选择"PascalVOC"或"YOLO"格式(推荐YOLO)
- 开始标注 - 使用快捷键
W创建矩形框,Ctrl+S保存
YOLO格式说明:
- 保存为
.txt文件,与图片同名 - 每行格式:
class_id x_center y_center width height - 所有坐标值都是归一化的(0-1之间)
常用快捷键:
W- 创建矩形框Ctrl + S- 保存当前标注D- 下一张图片A- 上一张图片Ctrl + D- 复制当前标注框
效率提示: 对于大量数据,可以考虑使用Roboflow等自动标注工具,或雇佣标注团队。
第三章:模型训练与调优
3.1 数据集目录结构与配置
目录结构要求:
datasets/
├── images/
│ ├── train/ # 训练集图片
│ └── val/ # 验证集图片
└── labels/
├── train/ # 训练集标签
└── val/ # 验证集标签数据量建议:
- 每个类别至少50-100张图片(训练集)
- 验证集占总数据的10-20%
- 类别要平衡,避免某些类别样本过少
配置data.yaml:
yaml
# data.yaml 配置文件
train: datasets/images/train # 训练集路径
val: datasets/images/val # 验证集路径
test: # 测试集路径(可选)
# 类别信息
nc: 6 # 类别数量
names: # 类别名称列表
0: lamp-green
1: lamp-red
2: sidewalk
3: speedlimit-10
4: speed-10
5: house3.2 执行训练命令
基础训练命令:
bash
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5s.pt参数说明:
--img 640- 输入图片尺寸--batch 16- 批次大小(根据GPU内存调整)--epochs 50- 训练轮数--data data.yaml- 数据配置文件--weights yolov5s.pt- 预训练模型
进阶训练选项:
bash
# 使用GPU加速
python train.py --device 0 # 使用第一块GPU
# 多GPU训练
python train.py --device 0,1 # 使用两块GPU
# 恢复训练
python train.py --resume runs/train/exp/weights/last.pt
# 早停机制(防止过拟合)
python train.py --early-stopping --patience 503.3 训练概念:欠拟合与过拟合
在机器学习模型训练过程中,欠拟合(Underfitting)和过拟合(Overfitting)是两个最核心且必须理解的概念。它们是模型学习能力与数据复杂度之间平衡关系的两种极端表现,直接影响模型的泛化能力(即模型在未见数据上的表现)。
基本概念对比
| 特征 | 欠拟合 (Underfitting) | 过拟合 (Overfitting) |
|---|---|---|
| 定义 | 模型过于简单,无法捕捉数据规律 | 模型过于复杂,记住了噪声和细节 |
| 训练集表现 | 差(高误差) | 好(低误差) |
| 验证集表现 | 差(高误差) | 差(高误差) |
| 模型状态 | "学得太少" | "学得太多太细" |
可视化理解
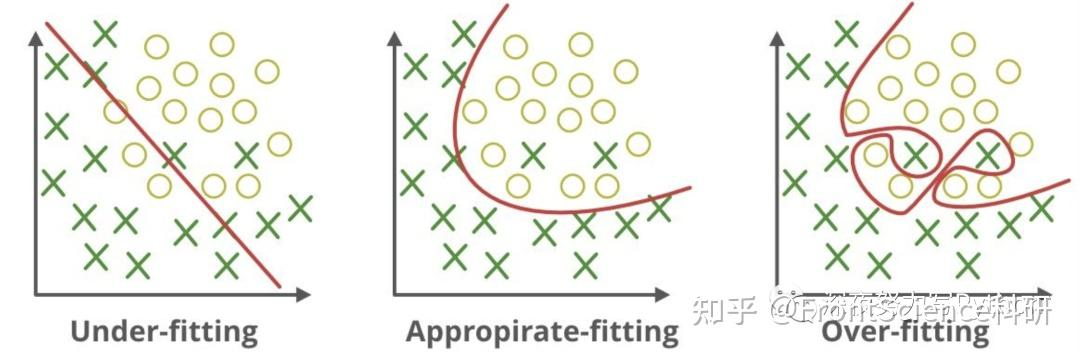
- 欠拟合:用直线拟合曲线数据,无法捕捉数据的真实分布
- 适度拟合:用适当复杂度的曲线较好地拟合数据
- 过拟合:用极其复杂的曲线"完美"穿过所有数据点,包括噪声点
在YOLOv5中的表现
欠拟合迹象:
- 训练集mAP很低(如<0.3)
- 损失曲线下降缓慢,很快趋于平缓
- 预测结果糟糕,漏检严重
过拟合迹象:
- 训练集mAP很高(如>0.95),但验证集mAP明显偏低
- 训练损失持续下降,但验证损失在某个点后开始上升
- 在新数据上表现不稳定
解决方案
解决欠拟合:
- 增加模型复杂度(使用更大的YOLOv5模型)
- 延长训练时间(增加epochs)
- 改进特征工程(增加数据增强)
- 降低正则化强度
解决过拟合:
- 获取更多训练数据
- 使用数据增强:
yaml
# YOLOv5数据增强配置
augmentation:
hsv_h: 0.015 # 色调增强
hsv_s: 0.7 # 饱和度增强
hsv_v: 0.4 # 明度增强
fliplr: 0.5 # 水平翻转
mosaic: 1.0 # 马赛克增强- 使用正则化技术(权重衰减、Dropout)
- 早停法(Early Stopping)
3.4 TensorBoard 配置与监控
安装与使用:
bash
# 安装TensorBoard
pip install tensorboard
# 启动TensorBoard(在项目根目录)
tensorboard --logdir runs/train
# 浏览器访问
# http://localhost:6006监控指标:
- 损失曲线 - 训练损失、验证损失
- 精度指标 - mAP@0.5、mAP@0.5:0.95
- 学习率变化 - 学习率调度曲线
- 验证结果 - 预测示例图片
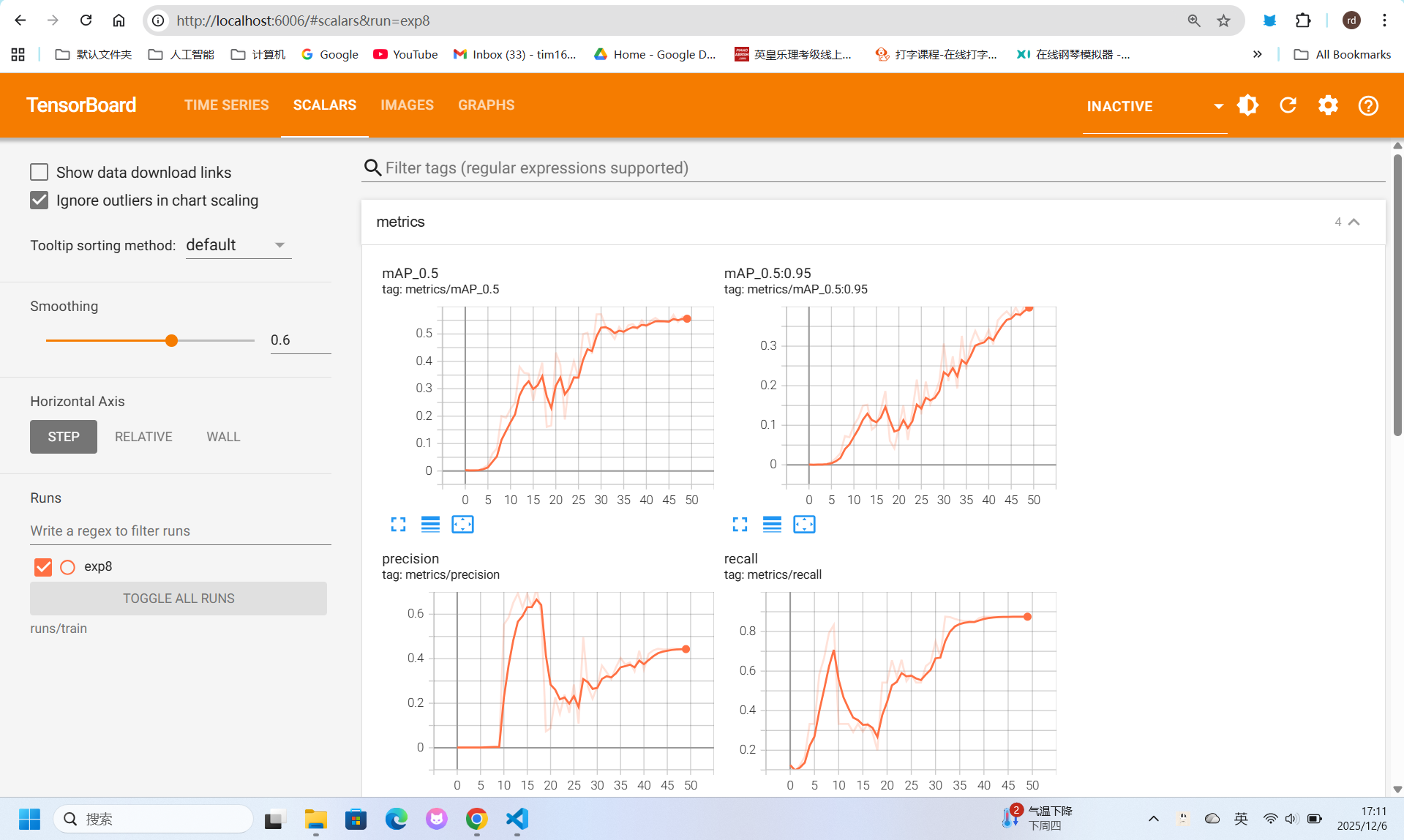
训练结果分析:
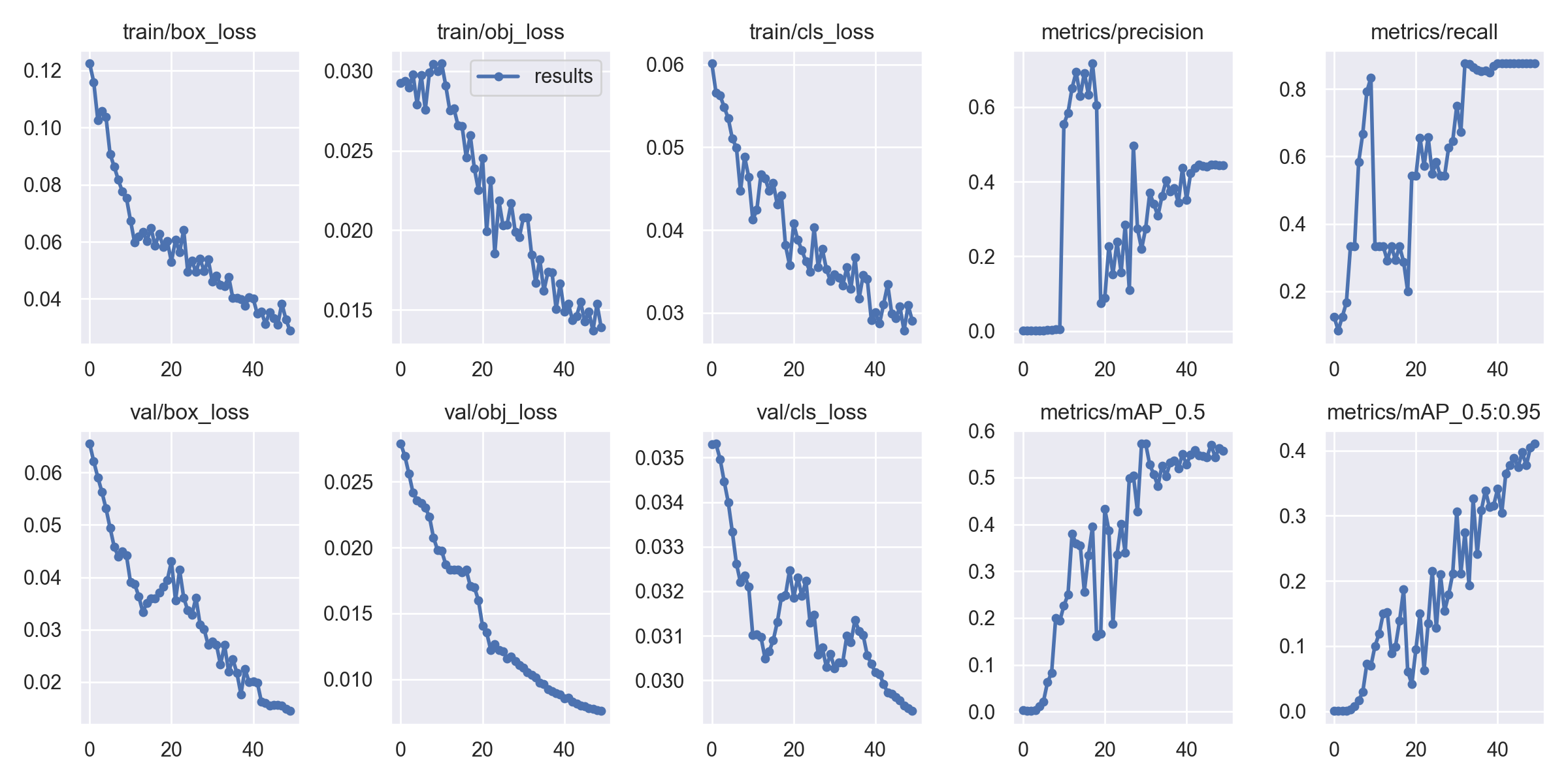
模型推理测试:
bash
# 使用训练好的模型进行推理
python detect.py --weights runs/train/exp/weights/best.pt \
--img 640 \
--conf 0.25 \
--source data/images/test # 测试图片路径第四章:模型应用与部署
4.1 实时检测与效果展示
bash
# 使用训练好的模型进行实时摄像头检测
python detect.py --weights runs/train/exp/weights/best.pt --source 0 --view-img
# 检测视频文件
python detect.py --weights best.pt --source video.mp4 --save-txt --save-conf4.2 在自定义Python程序中使用模型
python
import torch
import cv2
import numpy as np
class YOLOv5Detector:
def __init__(self, model_path='best.pt', device='cpu'):
"""初始化检测器"""
self.device = device
# 加载自定义训练的模型
self.model = torch.hub.load('ultralytics/yolov5', 'custom',
path=model_path,
source='local',
device=self.device)
self.model.conf = 0.25 # 置信度阈值
self.model.iou = 0.45 # IOU阈值
def detect_image(self, image):
"""检测单张图片"""
results = self.model(image)
# 获取检测结果
detections = []
for *box, conf, cls in results.xyxy[0]:
detections.append({
'class': results.names[int(cls)],
'confidence': float(conf),
'bbox': [int(x) for x in box]
})
return detections, results.render()[0]
def detect_video(self, video_path=0):
"""实时视频检测"""
cap = cv2.VideoCapture(video_path)
while True:
ret, frame = cap.read()
if not ret:
break
# 进行检测
detections, rendered_frame = self.detect_image(frame)
# 显示结果
cv2.imshow('YOLOv5 Detection', rendered_frame)
# 打印检测信息
for det in detections:
print(f"{det['class']}: {det['confidence']:.2%}")
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 使用示例
if __name__ == "__main__":
# 初始化检测器
detector = YOLOv5Detector(model_path='runs/train/exp/weights/best.pt', device='cuda')
# 检测单张图片
# img = cv2.imread('test.jpg')
# results, output_img = detector.detect_image(img)
# 实时摄像头检测
detector.detect_video(0) # 0表示默认摄像头第五章:进阶学习与应用拓展
5.1 计算机视觉的发展与经典网络
关键演进脉络:
- AlexNet (2012) - 开启深度学习CV时代
- VGGNet (2014) - 展示网络深度的重要性
- GoogLeNet/Inception (2014) - 引入Inception模块
- ResNet (2015) - 残差学习解决梯度消失问题
残差神经网络(ResNet)详解:

ResNet的核心创新是"残差学习"。它让网络学习残差映射 ( F(x) = H(x) - x ),而不是直接学习目标映射 ( H(x) )。通过跳跃连接实现恒等映射,解决了深度网络的退化问题。
5.2 姿态检测与人脸识别实践
姿态检测:

推荐项目:
- OpenPose - 实时多人姿态检测,支持身体、手部、面部关键点
- pose_estimation - 轻量化姿态检测
人脸识别:
推荐项目:
- Dlib人脸识别 - 基于传统机器学习方法
- 个人实现项目 - 基于深度学习的人脸识别系统(代码整理中)
5.3 强化学习与仿真环境
Isaac Gym:高性能机器人仿真平台
核心优势: GPU上的大规模并行物理仿真,比传统CPU仿真快数千倍。
学习资源:
- 论文:Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
- 官方代码:IsaacSim
- 示例环境:IsaacGymEnvs
5.4 图像生成(Stable Diffusion)拓展
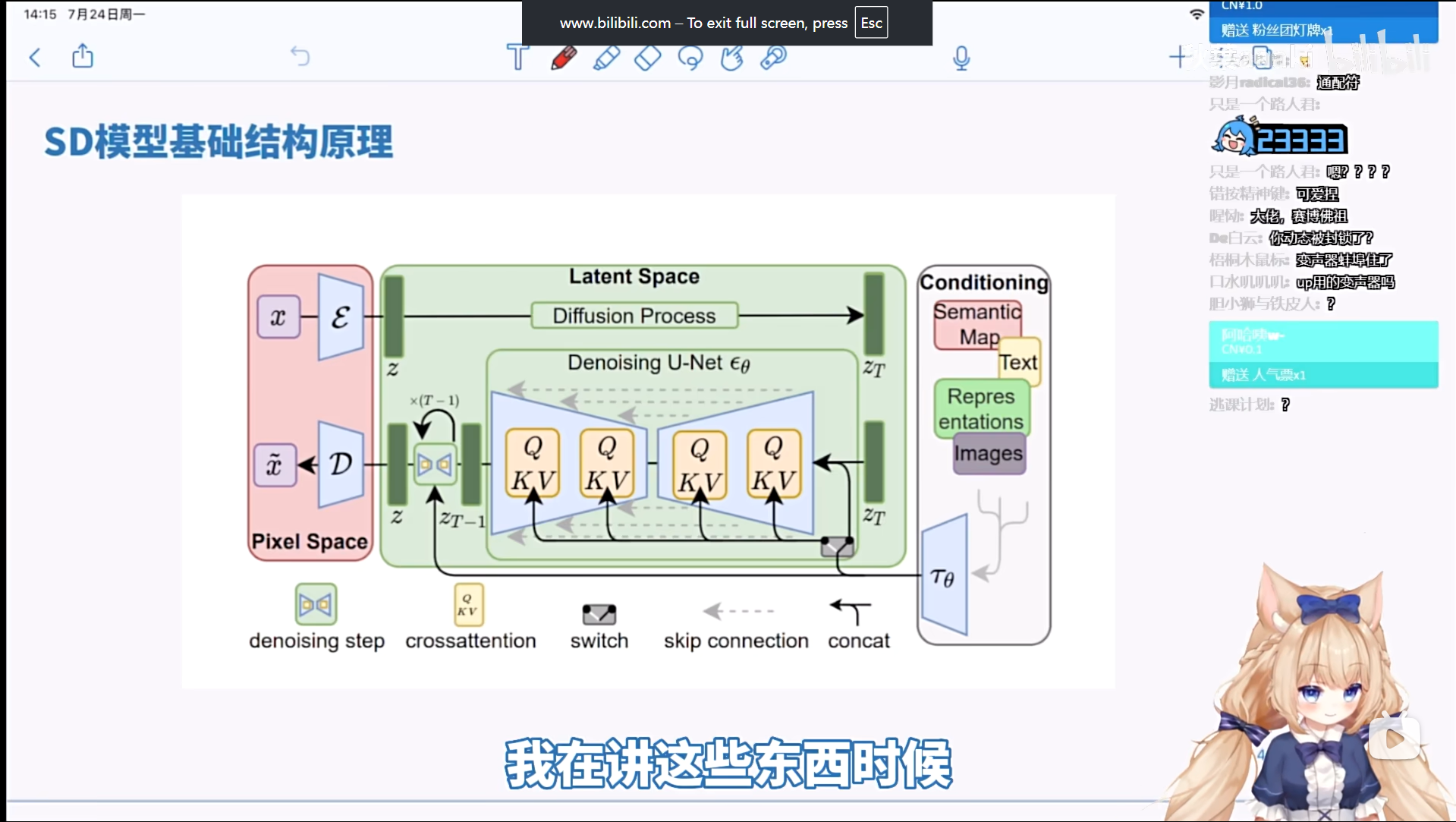
核心原理:
- 前向扩散 - 逐步添加噪声
- 反向扩散 - 学习去噪过程
- 条件控制 - 通过文本提示词引导生成
学习资源:
- 视频教程:深入理解Stable Diffusion
- 实践方向:LoRA微调、ControlNet控制、动画生成
5.5 关于AI模型应用的思考
实际问题探讨:
- 医疗肿瘤检测 - 如何实现精准分类?需要大量标注数据+专业医学知识
- 自动驾驶系统 - 不仅是识别,还需要路径规划、决策制定
- 蔬果成熟度检测 - 可以通过多模态(视觉+光谱)提高准确率
- 人脸/指纹识别 - 已在实际中广泛应用,但存在隐私和安全考虑
个人实践:
我曾基于OpenCV的14000张人脸数据训练了一个小型人脸识别模型,虽然精度有待提升,但验证了基本流程。这让我意识到,工业级系统需要更复杂的数据处理、模型优化和工程部署。
常见问题与解决方案
问题1:OMP库冲突
错误信息:
OMP: Error #15: Initializing libomp.dll, but found libiomp5md.dll already initialized.解决方案:
bash
# Windows PowerShell
$env:KMP_DUPLICATE_LIB_OK = "TRUE"
# Windows CMD
set KMP_DUPLICATE_LIB_OK=TRUE
# Linux/Mac
export KMP_DUPLICATE_LIB_OK=TRUE问题2:CUDA内存不足
解决方案:
bash
# 减小批次大小
python train.py --batch 8 # 原来是16
# 减小图片尺寸
python train.py --img 416 # 原来是640
# 使用梯度累积
python train.py --batch 4 --accumulate 4 # 等效batch=16问题3:训练过程中断
解决方案:
bash
# 恢复训练
python train.py --resume runs/train/exp/weights/last.pt
# 使用检查点
python train.py --save-period 10 # 每10个epoch保存一次问题4:模型精度低
检查清单:
- 数据集是否足够?每个类别至少50-100张
- 标注是否准确?检查标签文件
- 类别是否平衡?避免某些类别样本过少
- 训练参数是否合适?调整学习率、数据增强
总结与后续学习
本文内容回顾
我们已经完成了YOLOv5的完整学习路径:
- 基础理论 - 了解YOLOv5的原理和架构
- 环境配置 - 安装所有必要的软件和依赖
- 数据准备 - 收集、标注和组织数据集
- 模型训练 - 配置参数、监控训练过程
- 应用部署 - 在自定义程序中使用训练好的模型
- 进阶拓展 - 探索计算机视觉的更多可能性
下一步学习建议
1. 深化理解
- 阅读论文 :
- 分析源码:深入阅读YOLOv5的PyTorch实现
2. 动手实践项目
python
# 项目思路示例
项目1:智能安防监控系统
- 功能:人脸识别+异常行为检测
- 技术:YOLOv5 + 人脸识别 + 报警系统
项目2:工业质检系统
- 功能:产品缺陷自动检测
- 技术:YOLOv5 + 高分辨率图像处理
项目3:自动驾驶感知模块
- 功能:车辆、行人、交通标志检测
- 技术:YOLOv5 + 多目标跟踪3. 技术拓展方向
| 方向 | 技术栈 | 应用场景 |
|---|---|---|
| 模型优化 | 剪枝、量化、蒸馏 | 移动端部署、边缘计算 |
| 多任务学习 | 检测+分割+分类 | 自动驾驶、医疗影像 |
| 实时系统 | TensorRT、ONNX | 视频监控、机器人 |
| 3D视觉 | 点云处理、深度估计 | AR/VR、自动驾驶 |
4. 社区参与
- GitHub:关注ultralytics/yolov5,参与issue讨论
- 论坛:Stack Overflow、Reddit的r/MachineLearning
- 比赛:参加Kaggle、天池等数据科学竞赛
资源汇总
官方资源
学习资料
实用工具
推荐阅读:博客园博文管理与维护规范
其他相关资料
-
Vision Language Models某个大佬的博文
后记:
写这篇教程的过程中,我深刻体会到理论与实践结合的重要性。YOLOv5虽然"好用",但要真正掌握它,还需要大量的实践和调试。
有时候我在想:写这么详细的博文,不如录个视频来得直观?但考虑到有些同学更喜欢文字教程(可以随时查阅),而且我有点"社恐"不太想露脸录音... 嗯,或许下次可以尝试一下。
无论如何,希望这篇教程能帮助到你。如果在实践中遇到问题,欢迎在评论区留言讨论。记住:动手做一遍,比看十遍更有用!
最后,感谢所有开源项目的贡献者,正是因为有你们的付出,AI技术才能如此快速地普及和发展。
更新计划:
- 录制配套视频教程
- 添加更多实战项目案例
- 更新到YOLOv8/v10的内容
- 添加模型部署到移动端的教程
版权声明:本文欢迎转载,但请注明出处。文中涉及的所有代码和配置均可自由使用,但请注意遵守相关开源协议的约束。
联系作者:如有问题或合作意向,欢迎通过博客园私信联系。
最后更新 :2024年12月6日
版本:v1.0