Kafka最初诞⽣于LinkedIn公司,其核⼼作⽤就是⽤来收集并处理庞⼤复杂的应⽤⽇志。⼀个典型的⽇志聚合 应⽤场景如下:
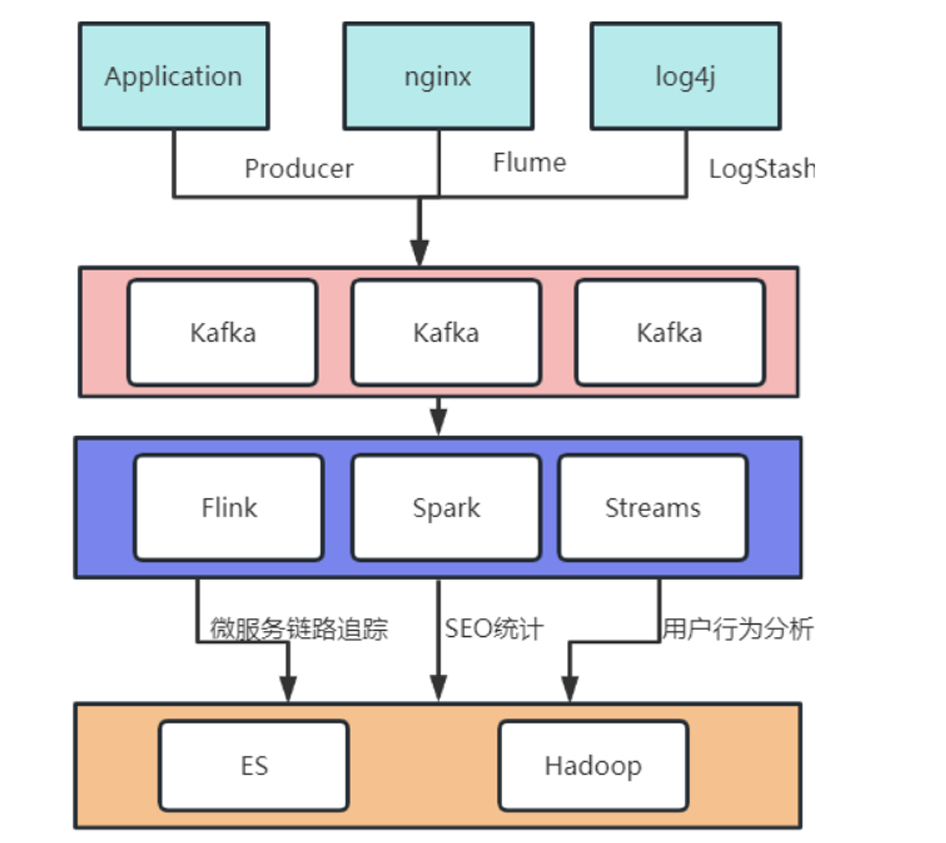
业务场景决定了产品的特点。所以Kafka最典型的产品特点有以下⼏点: 1、数据吞吐量很⼤: 需要能够快速收集各个渠道的海量⽇志 2、集群容错性⾼:允许集群中少量节点崩溃 3、功能不需要太复杂:Kafka的设计⽬标是⾼吞吐、低延迟和可扩展,主要关注消息传递⽽不是消息处理。所 以,Kafka并没有⽀持死信队列、顺序消息等⾼级功能。 4、允许少量数据丢失:在海量的应⽤⽇志中,少量的⽇志丢失是不会影响结果的。所以Kafka的设计初衷是允 许少量数据丢失的。当然Kafka本身也在不断优化数据安全问题
快速上⼿Kafka
1.快速搭建单机服务
Kafka的运⾏环境⾮常简单,只要有JVM虚拟机就可以进⾏。这⾥,我们使⽤⼀台安装了JDK1.8的kakfka。 JDK的安装过程略 下载Kafka。
官⽹下载地址: https://kafka.apache.org/downloads 这⾥我们选择下载kafka_2.13-3.8.0.tgz 关于kafka的版本,前⾯的2.13是开发kafka的scala语⾔的版本,后⾯的3.8.0是kafka应⽤的版本。 Scala是⼀种运⾏于JVM虚拟机之上的语⾔。
在运⾏时,只需要安装JDK就可以了,选哪个Scala版本没有 区别。但是如果要调试源码,就必须选择对应的Scala版本。因为Scala语⾔的版本并不是向后兼容的。
。 kafka的安装程序中⾃带了Zookeeper,可以在kafka的安装包的libs⽬录下查看到zookeeper的客户端jar 包。但是,通常情况下,为了让应⽤更好维护,我们会使⽤单独部署的Zookeeper,⽽不使⽤kafka⾃带 的Zookeeper。
下载下来的Kafka安装包不需要做任何的配置,就可以直接单击运⾏。这通常是快速了解Kafka的第⼀步。 启动Kafka之前需要先启动Zookeeper 这⾥就⽤Kafka⾃带的Zookeeper。启动脚本在bin⽬录下

优先启动zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
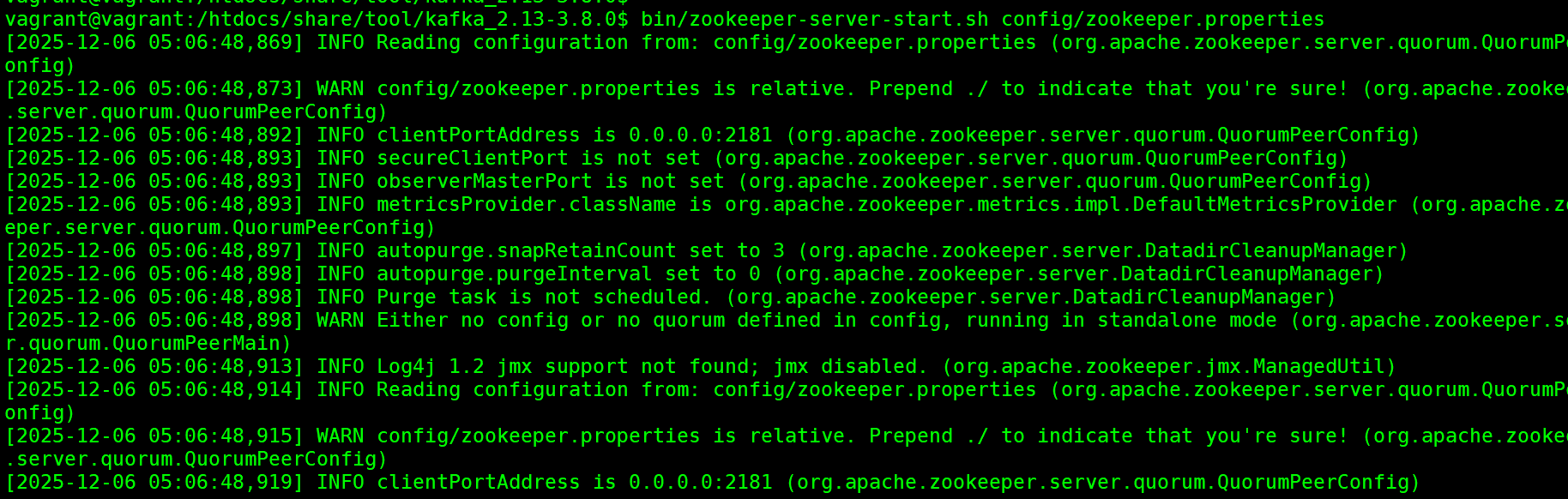
可以看到zookeeper默认会在2181端⼝启动。通过进程指令看到⼀个QuorumPeerMain进程,确 定服务启动成功
启动Kafka
bin/kafka-server-start.sh config/server.properties
看到端口9092已经启动,kakfka已经启动了。
2、简单收发消息
Kafka的基础⼯作机制是消息发送者可以将消息发送到kafka上指定的topic,⽽消息消费者,可以从指定的 topic上消费消息
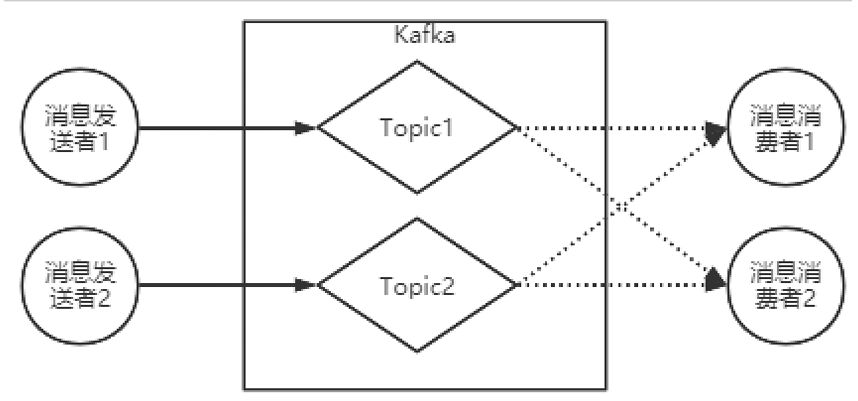
⾸先,可以使⽤Kafka提供的客户端脚本创建Topic
创建
Topic
bin/kafka-topics.sh --create --topic test --bootstrap-server 192.168.33.10:9092

查看
Topic
bin/kafka-topics.sh --describe --topic test --bootstrap-server 192.168.33.10:9092

然后,启动⼀个消息发送者端。往⼀个名为test的Topic发送消息。
bin/kafka-console-producer.sh --broker-list 192.168.33.10:9092 --topic test
 当命令⾏出现 > 符号后,随意输⼊⼀些字符。Ctrl+C 退出命令⾏。这样就完成了往kafka发消息的操作。
当命令⾏出现 > 符号后,随意输⼊⼀些字符。Ctrl+C 退出命令⾏。这样就完成了往kafka发消息的操作。
然后启动⼀个消息消费端,从名为test的Topic上接收消息。
bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.10:9092 --topic test

这样就完成了⼀个基础的交互。这其中,⽣产者和消费者并不需要同时启动。他们之间可以进⾏数据交互,但 是⼜并不依赖于对⽅。没有⽣产者,消费者依然可以正常⼯作,反过来,没有消费者,⽣产者也依然可以正常 ⼯作。这也体现出了⽣产者和消费者之间的解耦
3.其他消费模式
之前我们通过kafka提供的⽣产者和消费者脚本,启动了⼀个简单的消息⽣产者以及消息消费者,实际上, kafka还提供了丰富的消息消费⽅式
之前我们通过kafka提供的⽣产者和消费者脚本,启动了⼀个简单的消息⽣产者以及消息消费者,实际上, kafka还提供了丰富的消息消费⽅式。 指定消费进度 通过kafka-console.consumer.sh启动的控制台消费者,会将获取到的内容在命令⾏中输出。如果想要消费之 前发送的消息,可以通过添加--from-begining参数指定
bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.10:9092 --from-beginning --topic
test
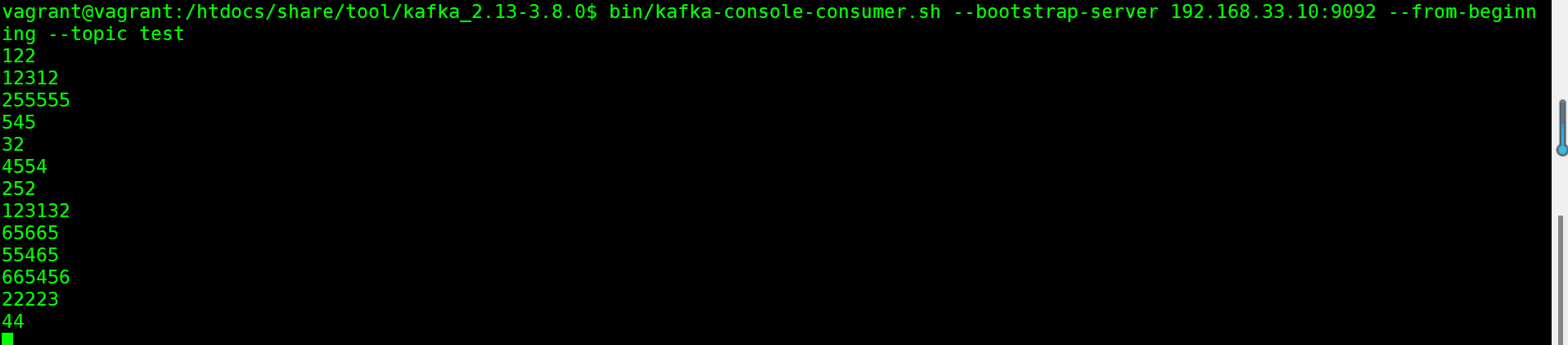
如果需要更精确的消费消息,甚⾄可以指定从哪⼀条消息开始消费。
bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.10:9092 --partition 0 --offset 4 --topic test

可以看到从第4条消息开始消费。
4、消费者组
对于每个消费者,可以指定⼀个消费者组。kafka中的同⼀条消息,只能被同⼀个消费者组下的某⼀个消费者 消费。⽽不属于同⼀个消费者组的其他消费者,也可以消费到这⼀条消息。在kafka-console-consumer.sh脚 本中,可以通过--consumer-property group.id=testGroup来指定所属的消费者组。例如,可以启动三个消费 者组,来验证⼀下分组消费机制
这个消费者实例属于不同的消费者组
bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.10:9092 --consumer-property group.id=xxyjGroup --topic test

这个消费者实例属于不同的消费者组
bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.10:9092 --consumer-property group.id=xxyjGroup2 --topic test

接下来,还可以使⽤kafka-consumer-groups.sh观测消费者组的情况。包括他们的消费进度。
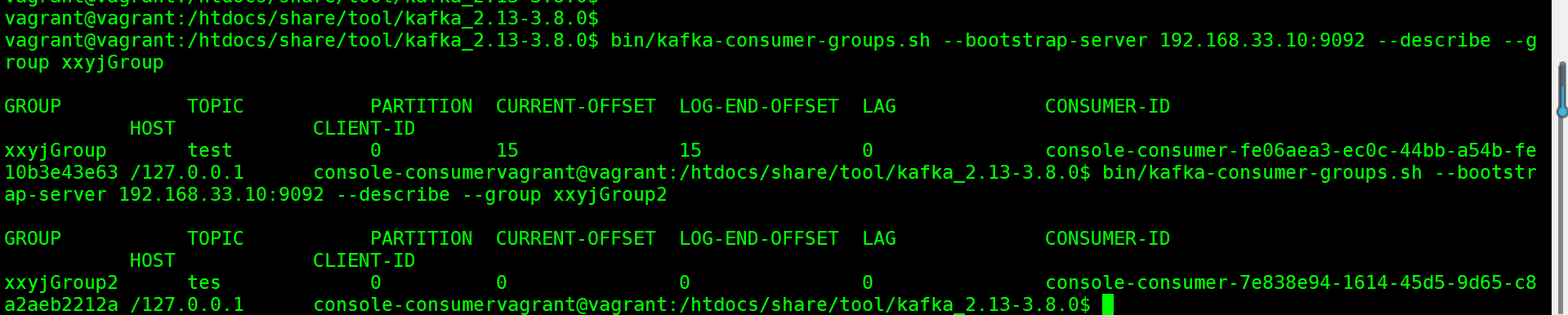
下面可以通过代码来实现生产者消费着的过程;
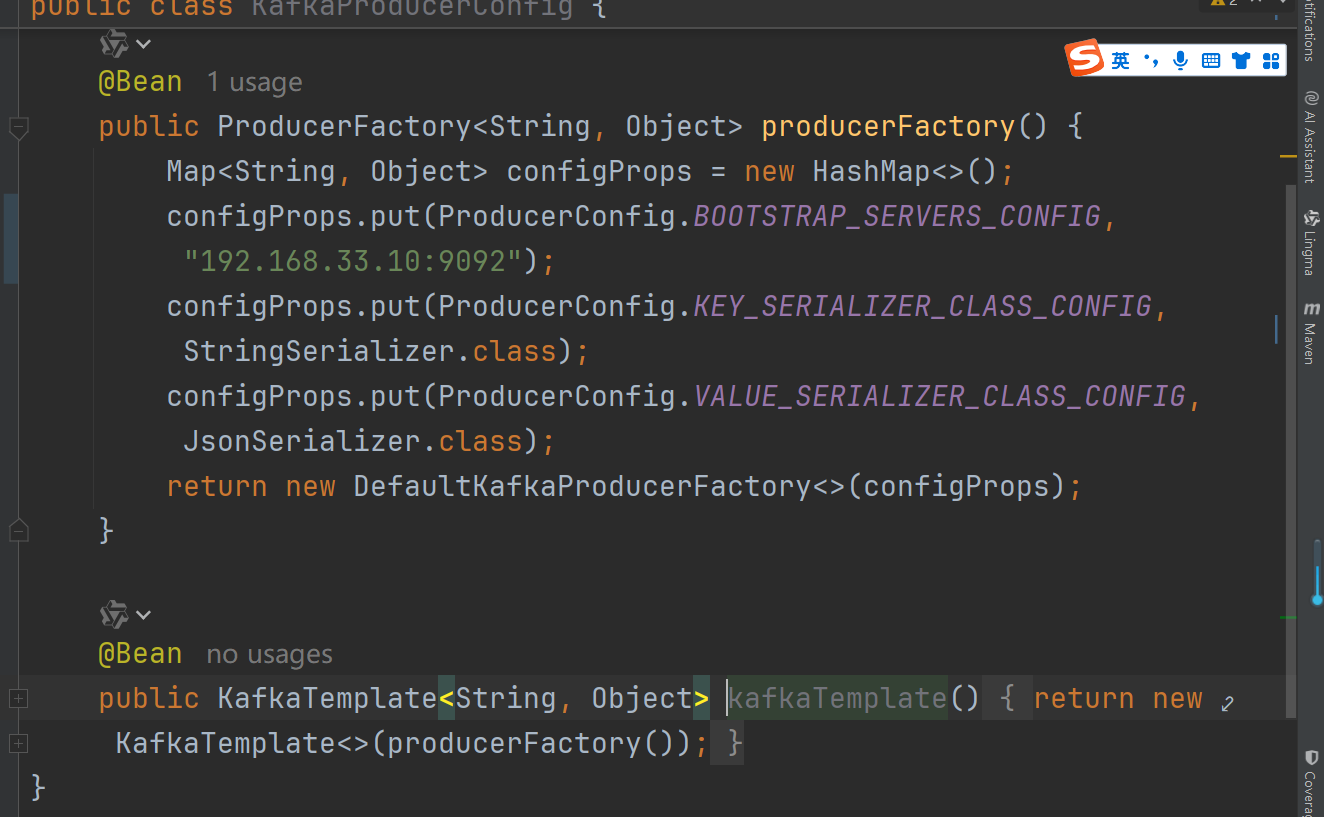
pom文件引入kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>application.properties配置kafka信息:spring.kafka.bootstrap-servers=192.168.33.10:9092
spring.kafka.consumer.group-id=my-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.springframework.kafka.support.serializer.JsonDeserializer
spring.kafka.consumer.properties.spring.json.trusted.packages=*
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.JsonDeserializer注入bean
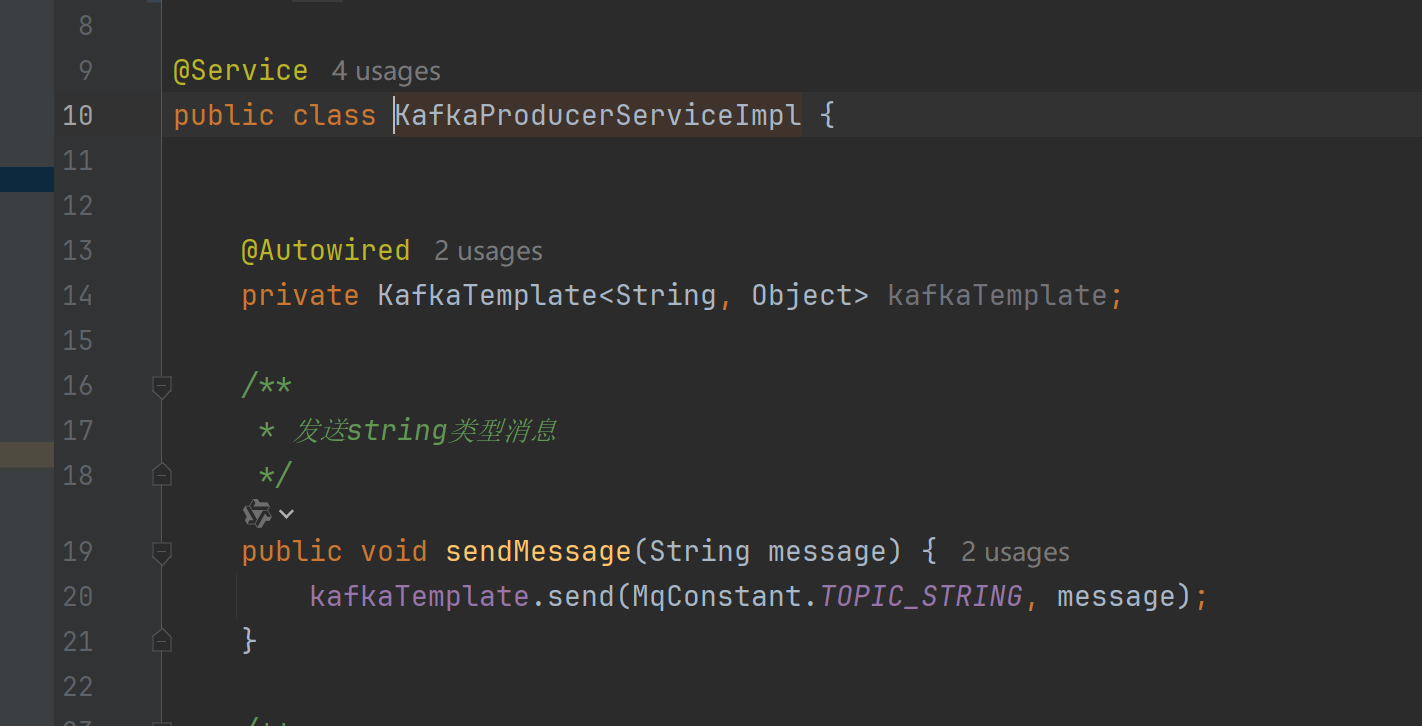
实现类:
注入监听消费者KafkaListener
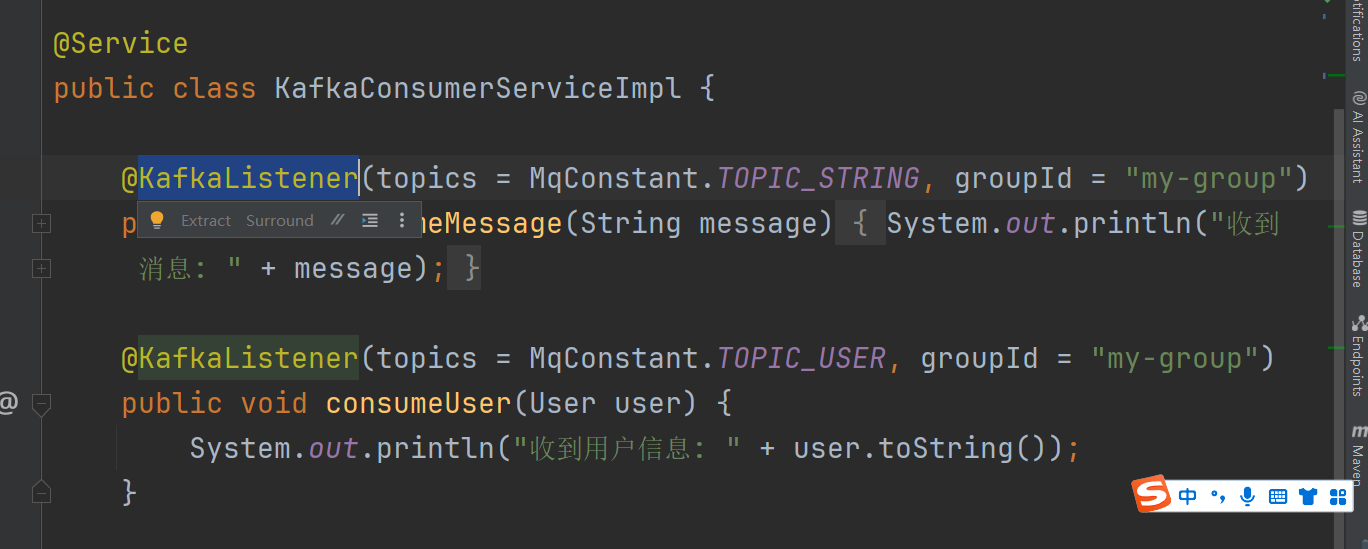
接口:
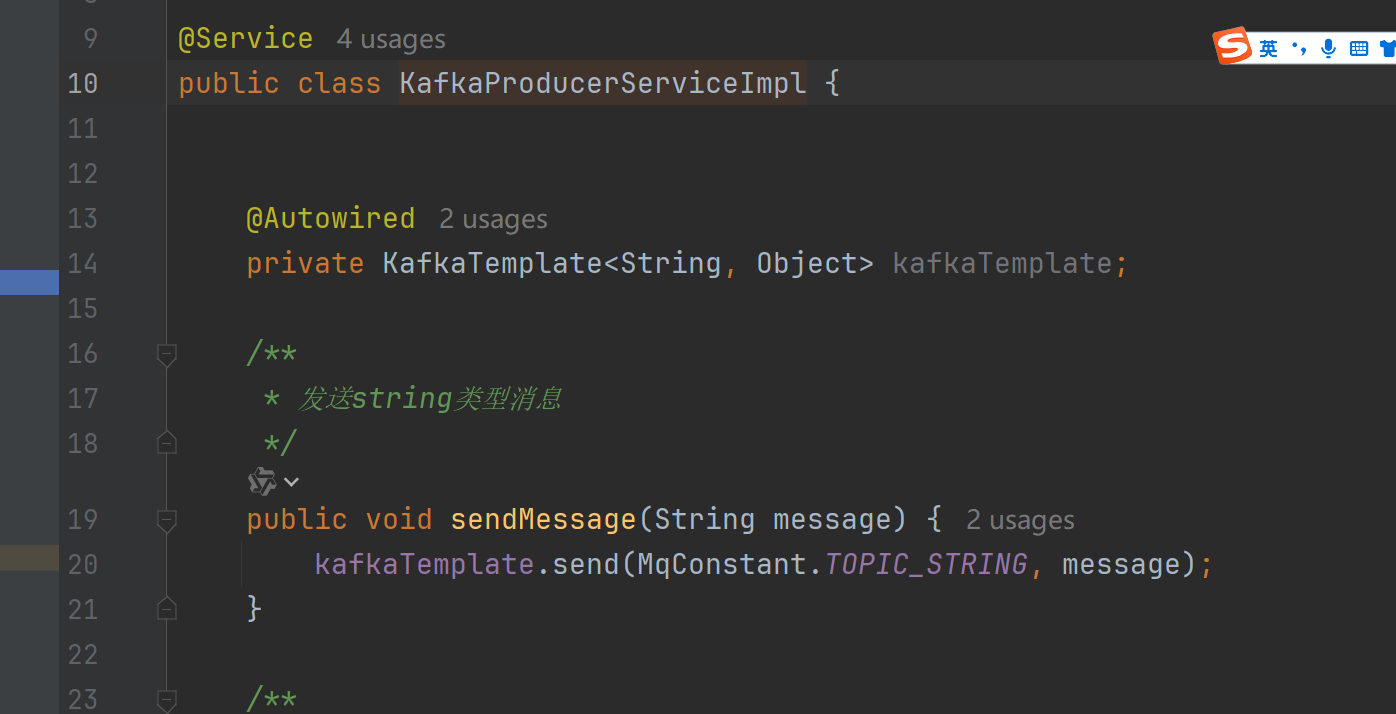
启动后通过接口发送消息:
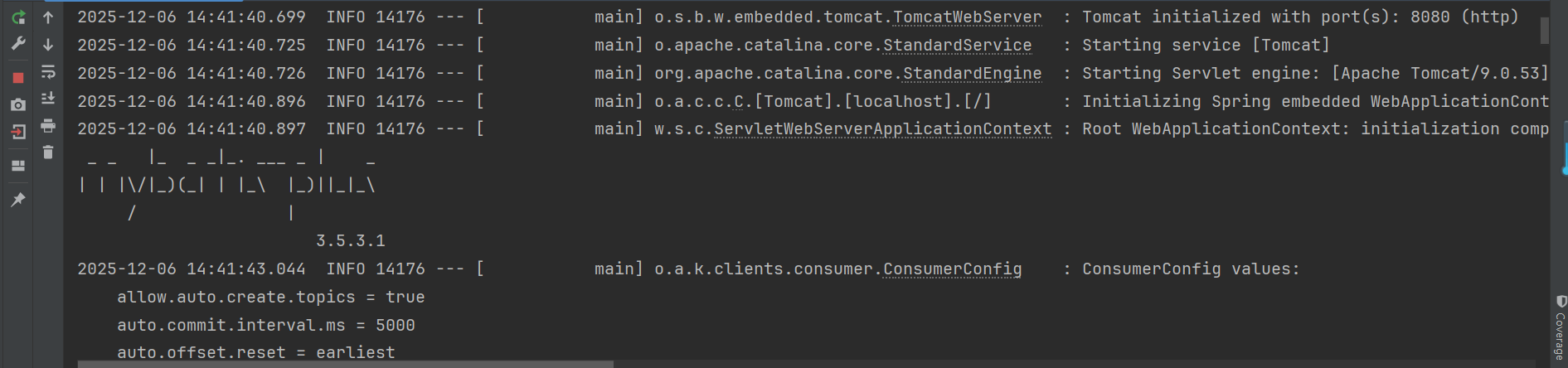
发送消息:
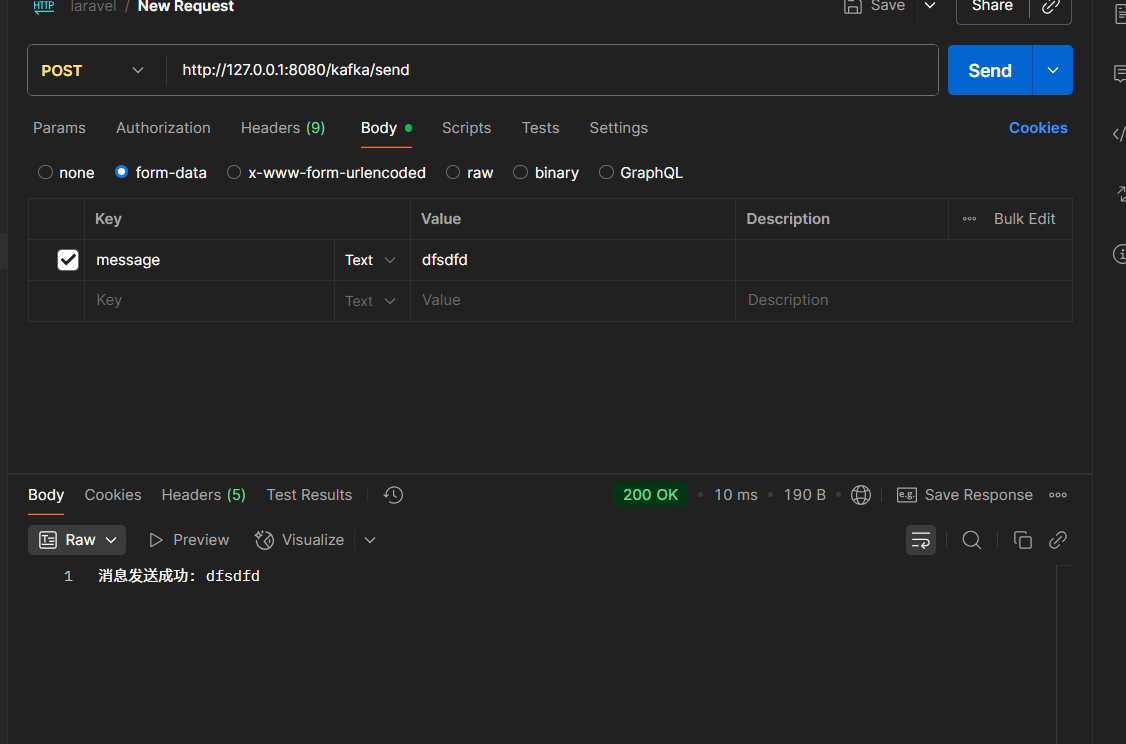
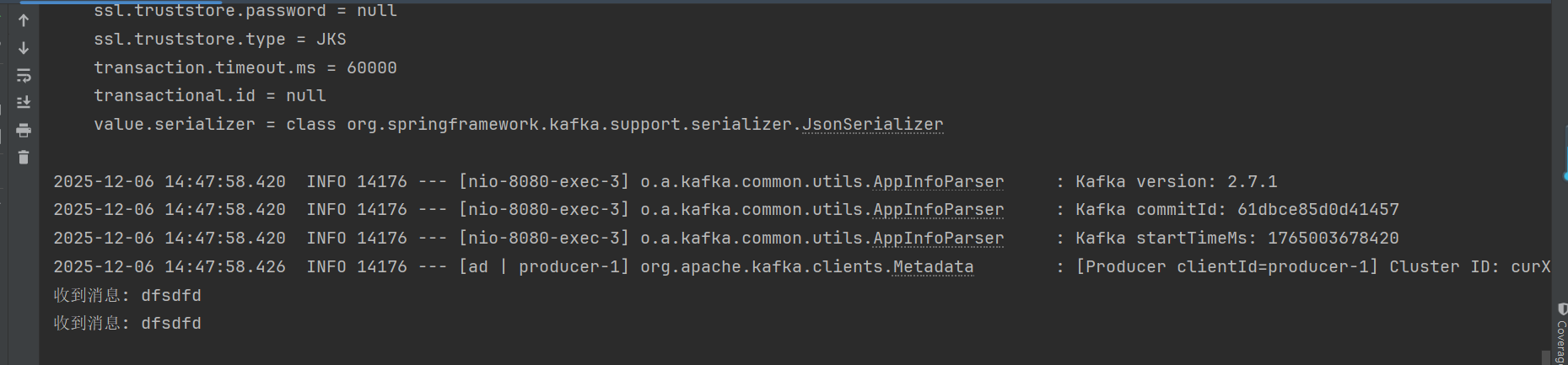
通过对象也一样:

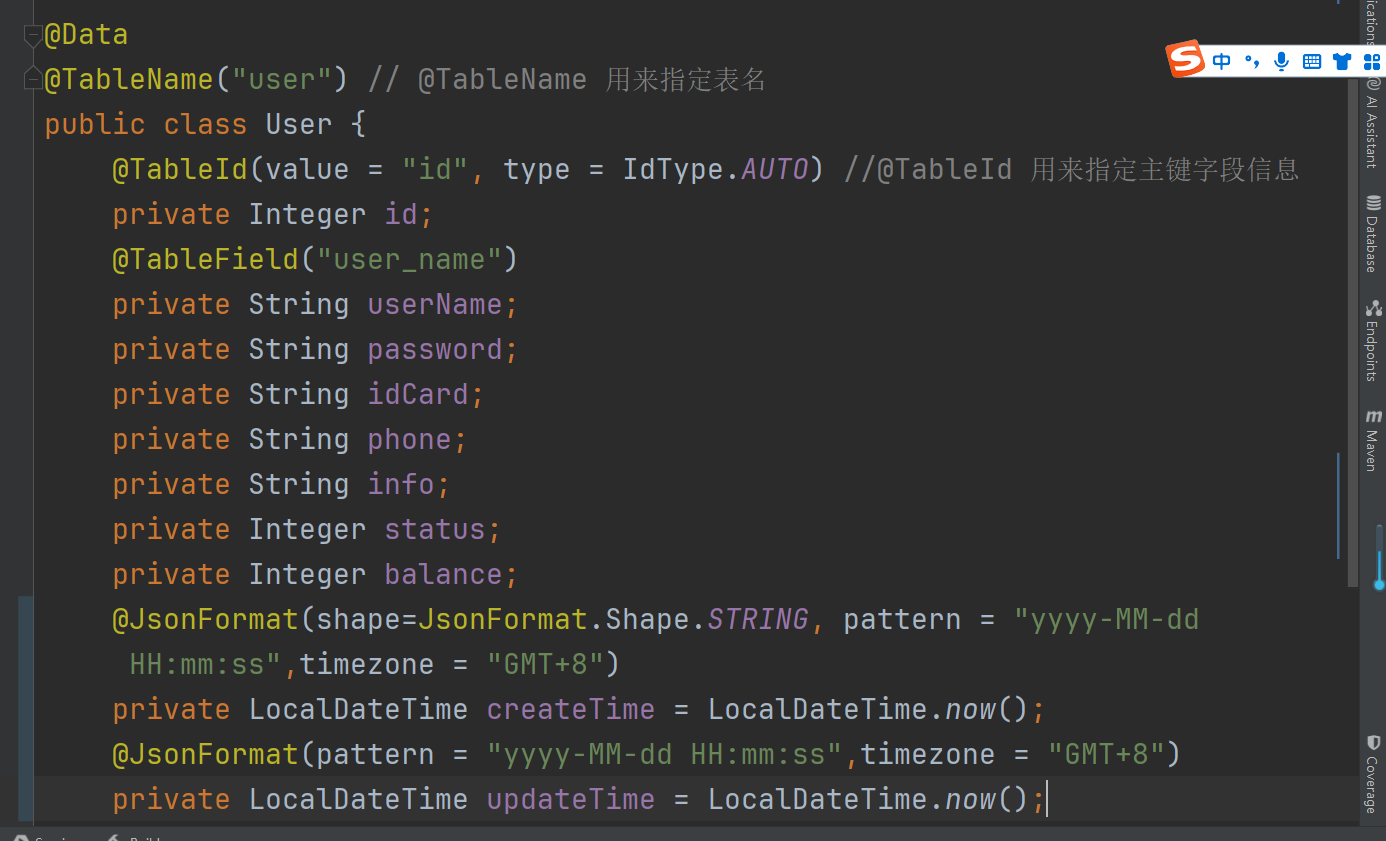
监听消费:
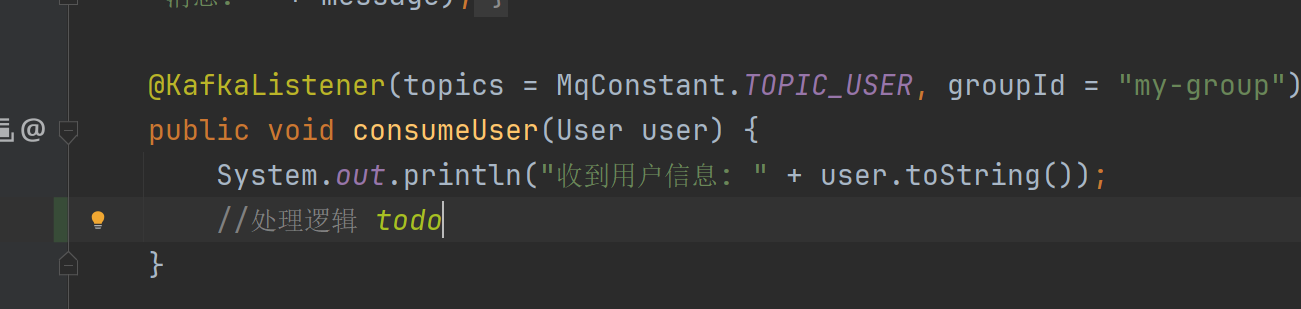
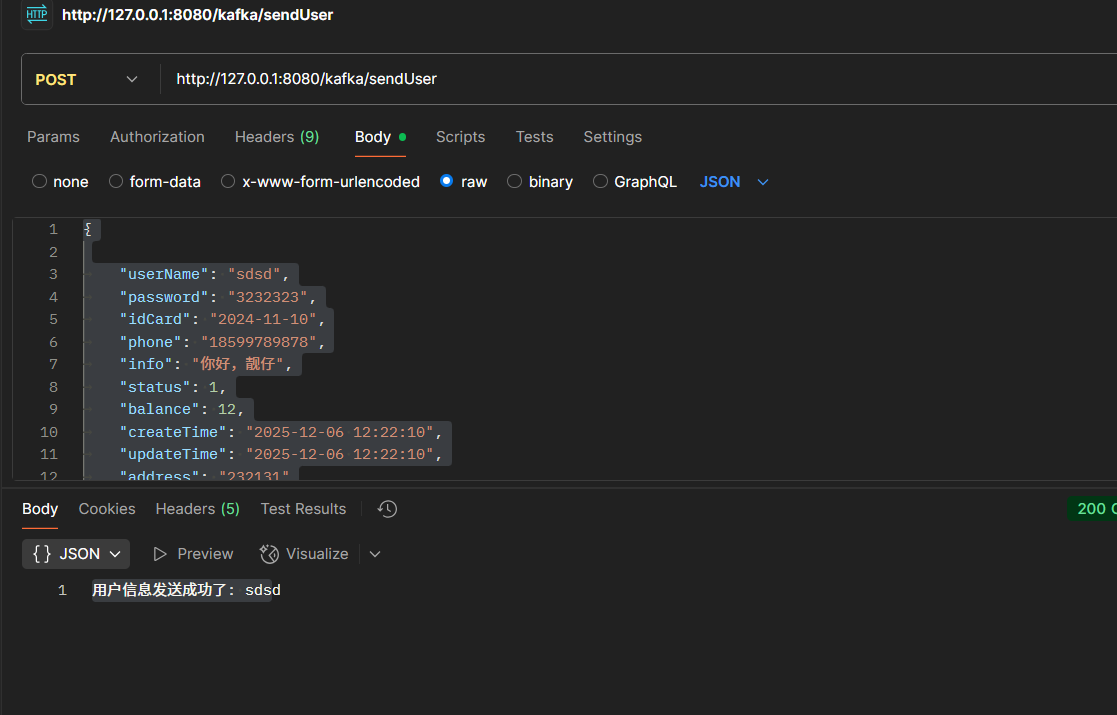

以上简单介绍kafka 的单机部署实例,后面讲集群部署,不像rocketmq消息集群,kafka依赖于zookeeper做负载均衡