1. 一张图理解"窗口"这件事
先看下面这张图(就是你提供的那张):
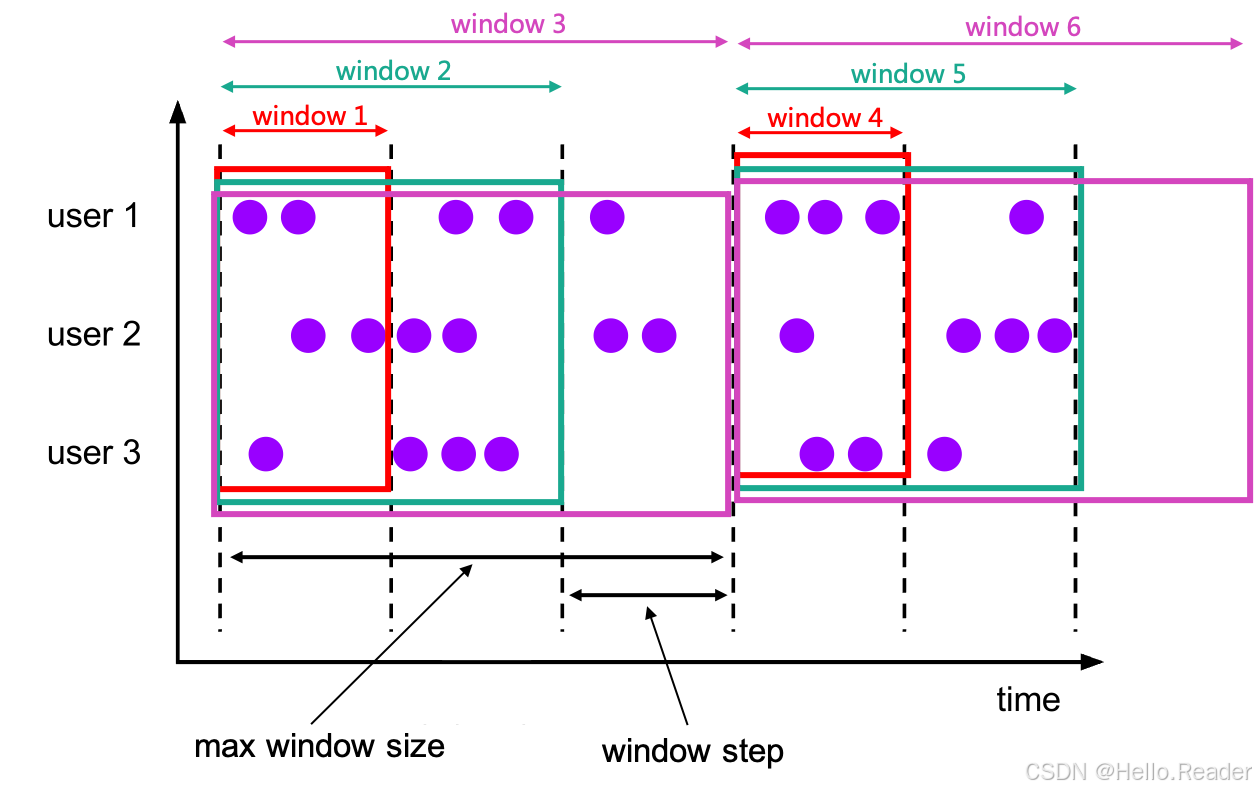
图里的紫色小圆点代表事件,横轴是时间。
你能看到好几层彩色矩形(window1 ~ window6):
- 红色窄窗口:
window1、window4 - 青绿色中等宽度窗口:
window2、window5 - 紫色大窗口:
window3、window6
它们有两个关键特征:
- 窗口之间会重叠 :比如紫色的
window3覆盖了window1、window2的范围; - 同一个事件可以属于多个窗口:一颗紫色点,只要落在某个窗口的时间范围内,就会被分配进去。
这其实就是 Flink 里 HOP / CUMULATE 这类窗口的核心直觉:
- 对于 HOP(滑动窗口):同一个起点向右不断滑动,窗口大小固定,但相邻窗口会重叠;
- 对于 CUMULATE(累积窗口):起点不动,不断向右扩展窗口终点,窗口大小越来越大,也必然重叠。
理解了这张图,再看后面的 SQL 会轻松很多。
2. Windowing TVF 的统一模型
四种窗口 TVF 的共同点:
sql
TUMBLE / HOP / CUMULATE / SESSION (TABLE data, ...)-
输入 :一张包含时间字段的表
data; -
输出:一张"新表",包含:
-
原表所有字段;
-
额外 3 列:
window_startwindow_endwindow_time
-
其中:
- 在 流模式 下,
window_time是一个真正的时间属性,可以继续用于窗口、interval join、over 聚合等; - 在 批模式 下,
window_time是TIMESTAMP/TIMESTAMP_LTZ类型; window_time的值总是:window_end - 1ms(可以简单理解为"窗口的最后一刻")。
同时,输入里的时间属性列(比如 bidtime)在通过窗口 TVF 之后,会变成普通时间戳列,真正代表窗口时间的是 window_* 这三列。
有了这三列,我们就可以:
- 在窗口粒度上做
GROUP BY; - 做窗口级的 TopN;
- 用窗口时间做 Join;
- 再套一层窗口 TVF......
这也是 Windowing TVF 比老式 Grouped Window 强大的根本原因:先把"时间"变成显式字段,再用标准 SQL 玩出花来。
3. TUMBLE:固定大小、不重叠的滚动窗口
3.1 语义 & 典型场景
TUMBLE 是最基础的窗口:固定大小、不重叠,一条记录只属于一个窗口。
适用场景:
- 每 5 分钟统计一次订单金额;
- 每小时计算一次活跃用户数;
- 对离线批数据做按天 / 按小时聚合。
3.2 基本语法
sql
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset])参数说明:
data:任意包含时间属性列的表;timecol:要用来划分窗口的时间属性列;size:窗口大小(例如INTERVAL '10' MINUTES);offset:可选,窗口起点偏移。
3.3 示例:对 Bid 表做 10 分钟滚动窗口汇总
先看表结构与原始数据:
sql
DESC Bid;
+-------------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+-------------+------------------------+------+-----+--------+---------------------------------+
| bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND |
| price | DECIMAL(10, 2) | true | | | |
| item | STRING | true | | | |
+-------------+------------------------+------+-----+--------+---------------------------------+
SELECT * FROM Bid;
+------------------+-------+------+
| bidtime | price | item |
+------------------+-------+------+
| 2020-04-15 08:05 | 4.00 | C |
| 2020-04-15 08:07 | 2.00 | A |
| 2020-04-15 08:09 | 5.00 | D |
| 2020-04-15 08:11 | 3.00 | B |
| 2020-04-15 08:13 | 1.00 | E |
| 2020-04-15 08:17 | 6.00 | F |
+------------------+-------+------+把它丢进 TUMBLE:
sql
SELECT *
FROM TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES);得到:
text
bidtime price item window_start window_end window_time
-----------------------------------------------------------------------------------------
2020-04-15 08:05 4.00 C 2020-04-15 08:00 08:10 08:09:59.999
2020-04-15 08:07 2.00 A 2020-04-15 08:00 08:10 08:09:59.999
2020-04-15 08:09 5.00 D 2020-04-15 08:00 08:10 08:09:59.999
2020-04-15 08:11 3.00 B 2020-04-15 08:10 08:20 08:19:59.999
2020-04-15 08:13 1.00 E 2020-04-15 08:10 08:20 08:19:59.999
2020-04-15 08:17 6.00 F 2020-04-15 08:10 08:20 08:19:59.999在此基础上做窗口聚合就很自然了:
sql
SELECT window_start, window_end, SUM(price) AS total_price
FROM TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES)
GROUP BY window_start, window_end;4. HOP:滑动窗口 / 跳跃窗口(与图示强相关)
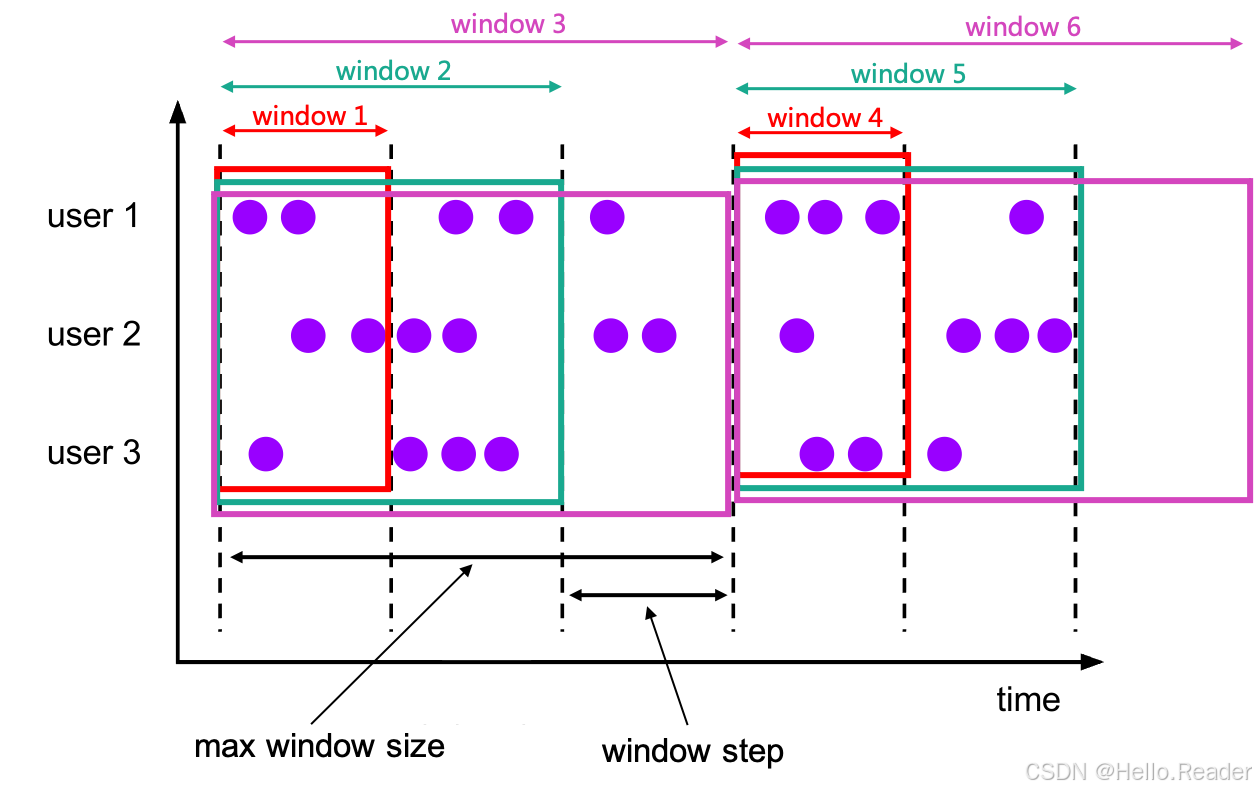
4.1 语义
HOP 也是固定窗口大小,但多了一个概念:滑动步长 slide。
size:窗口的覆盖时长;slide:相邻窗口起点之间的间隔;- 当
slide < size时,窗口之间会重叠,一条记录可能属于多个窗口。
这就是图里那种多层彩色矩形 的情况:
比如 size=10min, slide=5min 时,一条落在 08:07 的事件会被放进:
- [08:00, 08:10)
- [08:05, 08:15)
两个窗口里。
4.2 基本语法
sql
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset])4.3 示例:5 分钟滑动 10 分钟窗口
sql
SELECT *
FROM HOP(TABLE Bid,
DESCRIPTOR(bidtime),
INTERVAL '5' MINUTES, -- slide
INTERVAL '10' MINUTES); -- size结果里你会看到每条记录出现两次(除了边缘):
text
bidtime price item window_start window_end window_time
---------------------------------------------------------------------------
08:05 4.00 C 08:00 08:10 08:09:59.999
08:05 4.00 C 08:05 08:15 08:14:59.999
...配上你给的那张图来理解:
- 红框可以看作"窄窗口"(size 小,slide 等于 size,不重叠);
- 青框可以看作"稍大一点的窗口";
- 紫框则是"覆盖更长时间的窗口"。
真正的 HOP 是"窗口大小固定、起点按 slide 平移",所以如果你用图里的方式画:
window1、window2、window3的起点依次往右移;- 它们之间会像图中那样层层重叠。
这也是为什么在滑动窗口统计里,我们经常会看到同一条记录被重复计算,这本身就是语义要求(比如"最近 10 分钟指标,每 5 分钟更新一次")。
5. CUMULATE:从小到大的累积窗口(图片里的"套娃窗口")
再回到图里那几层彩色矩形:
- 同一时间起点左边对齐;
- 右边一个比一个长;
- 同一批事件会出现在多个"越来越大"的窗口中。
这就是 CUMULATE 最典型的视觉效果。
5.1 语义
CUMULATE 的设计目标是:在一个更大的时间范围里,按固定步长输出一系列"从小到大的累计窗口"。
你可以把它理解成:
- 先按
size做一个滚动窗口; - 在每个滚动窗口内部,从
window_start开始,每隔step扩大一次右边界,生成一个新窗口。
因此:
step:累积增长的步长;size:最终最大的窗口宽度,必须是step的整数倍。
典型场景:
- 每分钟展示"当天到当前时刻"的累计 UV;
- 每小时展示"本周当前小时之前"的累计 GMV。
5.2 基本语法
sql
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size [, offset])5.3 示例:2 分钟步长,10 分钟最大窗口
sql
SELECT *
FROM CUMULATE(TABLE Bid,
DESCRIPTOR(bidtime),
INTERVAL '2' MINUTES, -- step
INTERVAL '10' MINUTES); -- size结果非常有"套娃感":
-
对于 08:00 开始的窗口,会产生:
- [08:00, 08:06)
- [08:00, 08:08)
- [08:00, 08:10)
所有 bidtime 落在 08:05 的事件,都会被放进这三个窗口中;
这对应到你那张图里,从左侧同一个起点不断向右拉长的多个矩形。
这样在做统计时就可以得到"从短到长"的一系列累计值,非常适合监控、看板类场景。
6. SESSION:按行为"自然分段"的会话窗口
上面几种窗口都是时间驱动:每过一段时间就切一次。
SESSION 走的思路完全不同:它是事件驱动的------只要长时间没有事件,就认为上一个"会话"已经结束。
6.1 语义
配置一个 gap,比如 10 分钟:
-
对同一个 key(比如用户、设备):
- 两条事件之间的间隔 < 10 分钟 → 认为属于同一个 Session;
- 间隔 ≥ 10 分钟 → 前一个 Session 结束,新的 Session 开启。
-
会话窗口没有固定大小,也没有固定起止时间,结束时间取决于最后一条事件的时间戳 + gap。
6.2 基本语法
sql
SESSION(TABLE data [PARTITION BY (keycols, ...)],
DESCRIPTOR(timecol),
gap)PARTITION BY可选,但实际业务中几乎都会按 user / device 做分区会话。
6.3 示例:按 item 维度开 5 分钟会话窗口
sql
SELECT window_start, window_end, item, SUM(price) AS total_price
FROM SESSION(
TABLE Bid PARTITION BY item,
DESCRIPTOR(bidtime),
INTERVAL '5' MINUTES
)
GROUP BY item, window_start, window_end;你会看到同一个 item 的多条事件,被聚成一个"自然会话"的窗口,而另一些分散在更远的地方,就被拆成多个 Session。
需要注意的是:
- 当前 Session TVF 只支持流模式;
- 相关优化还在演进中,性能调优上暂时没有太多花活,但语义已经非常好用。
7. 窗口 Offset:让窗口对齐业务时间
很多真实业务的"自然边界"并不是 00:00:
- 跨国业务需要按照目标时区的 0 点对齐;
- 某些业务日从每天早上 8 点开始;
- 某些报表希望从 9:30 开盘开始对齐......
这时候就可以用窗口 TVF 的 offset 参数来平移窗口的起点。
7.1 例子:10 分钟滚动窗口,整体向右偏移 1 分钟
sql
SELECT *
FROM TUMBLE(
TABLE Bid,
DESCRIPTOR(bidtime),
INTERVAL '10' MINUTES,
INTERVAL '1' MINUTES -- offset
);这会让窗口从 08:01、08:11、08:21... 开始:
text
window_start window_end
-----------------------------
08:01 08:11
08:11 08:21
...同样的时间戳,会被分配到跟默认 offset=0 完全不同的窗口。
需要记住两点:
- offset 可以是正数,也可以是负数,本质就是改变窗口对齐点;
- offset 只影响窗口划分,不影响 Watermark。
8. 选什么窗口?一些实践经验
最后简单给几个"选型小抄":
-
固定时间粒度报表 → TUMBLE
- 每 5 分钟 / 每小时 / 每天一份完整报表;
- 和离线数仓里的"按天按小时汇总"思路最接近。
-
最近 N 时间的实时指标 → HOP
- "最近 10 分钟 PV,每 1 分钟更新一次";
- "最近 1 小时错误率,每 5 分钟更新一次"。
-
阶梯式累加曲线 → CUMULATE
- 实时看板、运营大屏上常见的"从零开始一路累积"的折线;
- 典型配置是
step=1min, size=1day。
-
用户行为会话分析 → SESSION
- UV、停留时长、单次会话浏览深度等;
- 通常配合
PARTITION BY user_id使用。
-
窗口边界对不齐业务时间 → offset
- 业务日 08:00 对齐;
- 不同国家时区统一口径。
9. 小结
Flink SQL 的窗口表值函数把"时间"这件事情做了一个非常漂亮的抽象:
- 用
TUMBLE / HOP / CUMULATE / SESSION这四种 TVF,把无限流切成了各种形态的时间片; - 用
window_start / window_end / window_time三个字段,把原本隐含在算子里的时间语义显式化; - 在这个基础上,你可以用纯 SQL 的方式,构建窗口聚合、窗口 TopN、窗口 Join、窗口去重等一整套复杂计算。
配合那张"多层彩色窗口"的图片来看,你可以把它记成一个简单的心智模型:
- TUMBLE:一层不重叠的块;
- HOP:同尺寸的块不断滑动,层层叠加;
- CUMULATE:同一个起点的块越拉越长,像套娃一样;
- SESSION:按用户行为自然分段,块的长短由数据说了算。
掌握了这一套,你在 Flink 上遇到绝大多数"时间 + 聚合"的问题,都能找到对应的窗口形式来解决。