掌握 Dubbo 监控数据采集的核心技术,让你的微服务运行状态尽在掌握
文章目录
-
- 引言:为什么我们需要可观测性?
- [一、Dubbo 可观测性全景图](#一、Dubbo 可观测性全景图)
- [二、核心原理:Dubbo-metrics 模块深度解析](#二、核心原理:Dubbo-metrics 模块深度解析)
-
- [2.1 指标样本的收集与存储](#2.1 指标样本的收集与存储)
- [2.2 指标数据的流转与抽象模型](#2.2 指标数据的流转与抽象模型)
- 三、实战:四种主流数据采集方案
-
- [3.1 方案一:使用 Prometheus + Grafana(云原生首选)](#3.1 方案一:使用 Prometheus + Grafana(云原生首选))
- [3.2 方案二:集成分布式追踪系统(全链路分析)](#3.2 方案二:集成分布式追踪系统(全链路分析))
- [3.3 方案三:启用 Dubbo Admin 与简易监控中心(轻量级)](#3.3 方案三:启用 Dubbo Admin 与简易监控中心(轻量级))
- [3.4 方案四:配置日志与访问日志(问题排查基石)](#3.4 方案四:配置日志与访问日志(问题排查基石))
- [四、可视化、告警与最佳实践 🛡️](#四、可视化、告警与最佳实践 🛡️)
-
- [4.1 构建统一可视化仪表板](#4.1 构建统一可视化仪表板)
- [4.2 设置智能告警机制](#4.2 设置智能告警机制)
- [4.3 性能数据联动与闭环](#4.3 性能数据联动与闭环)
- 总结:构建面向未来的可观测性体系
- [参考资料 📖](#参考资料 📖)
引言:为什么我们需要可观测性?
在微服务架构中,一次简单的用户请求可能跨越数十个服务节点。任何一个环节的延迟或错误都可能导致 "雪崩效应" ,引发整体系统性能下降甚至崩溃。Dubbo 作为承载企业核心业务逻辑的 RPC 框架,其内部状态与交互过程具有高度复杂性,这对系统的可观测性提出了极高要求。
想象一下,当生产环境出现服务响应变慢,你如何快速回答:
- 是哪个具体服务或方法出现了问题?
- 问题的根本原因是网络、资源还是代码?
- 影响范围有多大?
一个完善的监控数据采集体系,就是你诊断系统健康状况的 "X光机" 和 "心电图" 。Dubbo 从设计之初就将可观测性作为核心能力,提供了从指标(Metrics)、追踪(Tracing)到日志(Logging) 的全方位数据采集方案。本文将为你深入剖析 Dubbo 监控数据采集的底层原理、多种技术方案与实战配置,助你构建坚如磐石的可观测性体系。
一、Dubbo 可观测性全景图
Dubbo 的可观测性方案旨在提升分布式框架的监控、诊断及调试能力,确保系统稳定运行并及时发现、定位、解决问题。其数据采集主要围绕以下三个维度展开,共同构成微服务系统的"生命体征"监测仪:
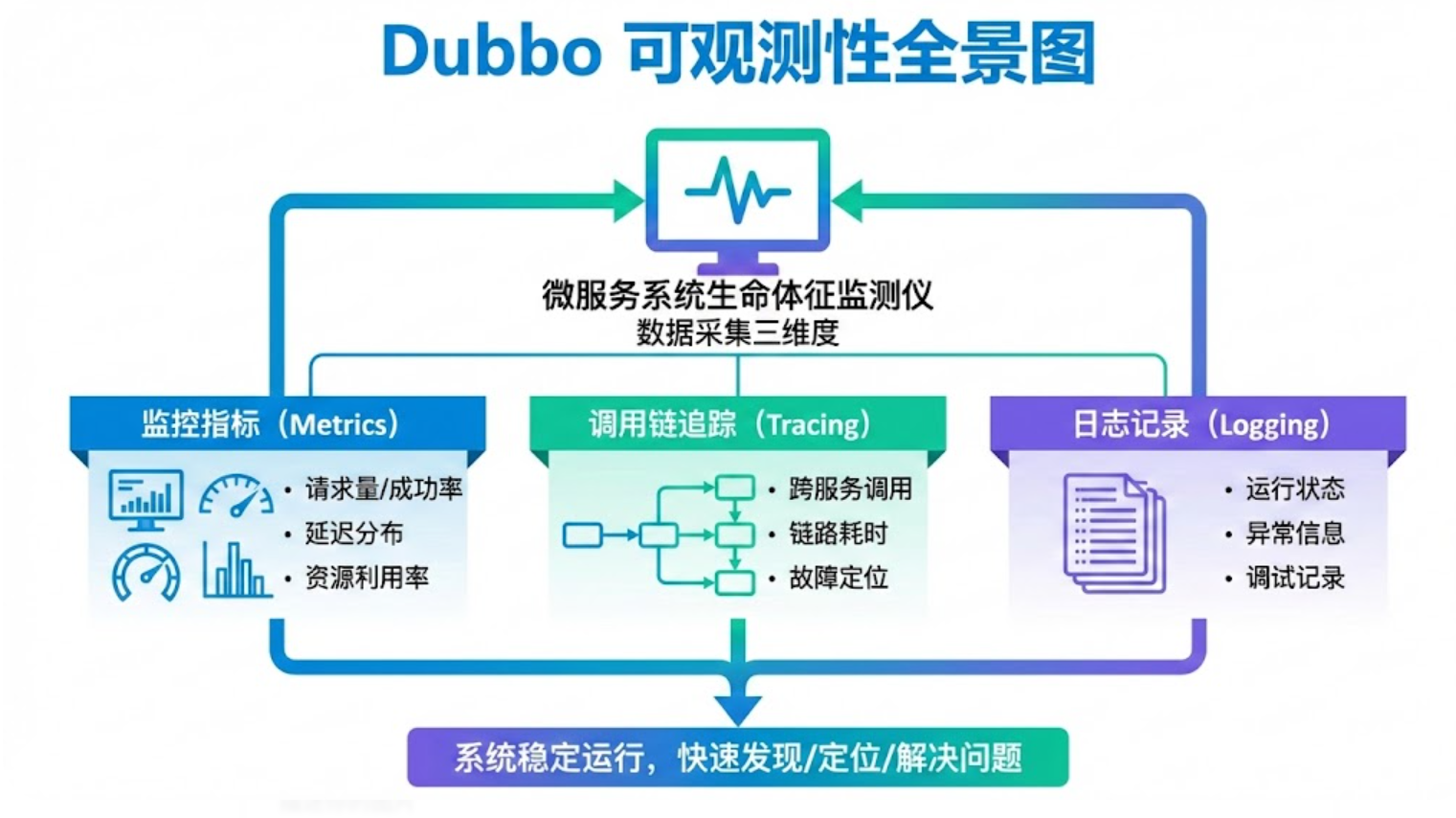
核心观测维度
-
维度名称 :指标(Metrics)
-
采集内容 :服务的定量性能数据
-
典型数据:QPS(每秒查询次数)、RT(响应时间)、成功/失败调用次数、线程池状态
-
核心价值:反映系统实时性能与健康度,用于告警与容量规划
-
维度名称 :追踪(Tracing)
-
采集内容 :单次请求的完整调用链路
-
典型数据:服务间调用关系、各环节耗时、层级依赖
-
核心价值:分析跨服务性能瓶颈、理清复杂依赖关系
-
维度名称 :日志(Logging)
-
采集内容 :系统运行的离散事件与上下文文本
-
典型数据:访问日志(Access Log)、错误堆栈、业务信息
-
核心价值:记录详细运行轨迹,用于问题根因分析与审计
这三个维度如同诊断疾病的"望、闻、问、切",指标告诉你"体温多少"(宏观状态),追踪告诉你"疼痛路径"(因果关系),日志则提供了"病史细节"(具体上下文)。接下来,我们将深入这三大支柱的内部实现。
二、核心原理:Dubbo-metrics 模块深度解析
从 Dubbo 3 开始,指标采集功能被整合到一个独立、解耦的 dubbo-metrics 模块中。理解其架构是掌握数据采集原理的关键。
2.1 指标样本的收集与存储
指标收集的入口是 MetricsCollector(指标收集器) 接口。它是一个SPI(服务提供接口),定义了如何收集某一类指标的样本(MetricSample)。Dubbo 内置了多种收集器,各司其职:
主要指标收集器及其职责
-
收集器名称 :
DefaultMetricsCollector(默认指标收集器) -
采集目标 :RPC调用核心指标
-
关键指标举例:方法调用次数、成功/失败计数、响应时间
-
收集器名称 :
RegistryMetricsCollector(注册中心指标收集器) -
采集目标 :服务注册与发现行为
-
关键指标举例:注册/订阅成功与失败次数、耗时
-
收集器名称 :
MetadataMetricsCollector(元数据指标收集器) -
采集目标 :元数据推送与拉取操作
-
关键指标举例:元数据操作次数与耗时
-
收集器名称 :
ConfigCenterMetricsCollector(配置中心指标收集器) -
采集目标 :配置变更事件
-
关键指标举例:配置变更次数
这些收集器采集到的原始数据,被存储在 BaseStatComposite(基本数据聚合器) 中。聚合器内部按不同粒度进行统计:
ApplicationStatComposite:应用级别聚合ServiceStatComposite:服务级别聚合MethodStatComposite:方法级别聚合RtStatComposite:响应时间聚合
这种分层设计使得 Dubbo 能够同时提供应用、服务、方法三个层次的监控视图,满足不同粒度的观测需求。
2.2 指标数据的流转与抽象模型
数据在 Dubbo-metrics 模块中的流转遵循一个清晰的管道模型:采集 → 聚合 → 导出。
- 采集 :当 RPC 调用发生时,框架内部会发布相应的指标事件 (
TimeCounterEvent)。各类MetricsSampler(指标采样器)或MetricsListener(指标监听器)会捕获这些事件,并调用对应收集器的increment、addRt等方法更新数据。 - 聚合 :收集器将数据写入底层的聚合器(
BaseStatComposite)进行累加和计算。例如,RtStatComposite会统计并计算平均响应时间、分位数等。 - 导出 :外部监控系统(如 Prometheus)通过调用收集器的
collect方法,触发export操作,将聚合好的数据以标准格式(如MetricSample列表)导出。
为了兼容业界标准并提供强大扩展性,Dubbo-metrics 设计了一套通用的 Metric(指标)抽象接口,主要包括:
Gauge(计量器):反映瞬态值,如当前连接数。Counter(计数器):只增不减的累计值,如总调用次数。Timer(计时器):记录事件耗时和频率,如方法响应时间分布。Histogram(直方图):统计值的分布情况,如响应时间百分比。
这套抽象允许 Dubbo 以统一的方式处理各类监控数据,并方便地对接不同的外部监控系统。
三、实战:四种主流数据采集方案
理解了原理,我们来看如何落地。以下是四种经过验证的 Dubbo 监控数据采集方案,你可以根据技术栈和运维复杂度进行选择。
3.1 方案一:使用 Prometheus + Grafana(云原生首选)
这是目前最流行、功能最强大的组合。Prometheus 负责拉取和存储时间序列指标,Grafana 负责可视化展示。
1. 接入与配置
Dubbo 应用通过集成 dubbo-metrics-prometheus 模块暴露指标端点。对于 Spring Boot 应用,可以结合 Micrometer 来桥接 Dubbo 指标。关键步骤如下:
-
在
pom.xml中添加依赖:xml<dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-metrics-prometheus</artifactId> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency> -
在
application.yml中暴露 Prometheus 端点:yamlmanagement: endpoints: web: exposure: include: "prometheus,metrics,dubbo" metrics: export: prometheus: enabled: true
2. 数据拉取与可视化
配置 Prometheus 的 scrape_configs,定期从 Dubbo 应用的 actuator/prometheus 端点拉取数据。随后,在 Grafana 中导入或创建仪表盘,即可实时监控 QPS、成功率、平均耗时、P99耗时等核心指标。
3.2 方案二:集成分布式追踪系统(全链路分析)
当需要分析跨多个服务的单次请求性能时,分布式追踪是不二之选。Dubbo 通过 Filter 拦截器实现运行时切点跟踪,可以轻松集成主流追踪系统。
1. 与 SkyWalking 集成
SkyWalking 通过无侵入的 Java Agent 实现监控,对 Dubbo 支持良好。
-
部署 :在应用启动命令中添加 Agent:
bash-javaagent:/path/to/skywalking-agent.jar -Dskywalking.agent.service_name=your-dubbo-service -
效果 :Agent 会自动捕获 Dubbo 调用,在 SkyWalking UI 中生成完整的服务拓扑图 和调用链路追踪,精确显示每个 Dubbo Span 的耗时和状态。
2. 与 Zipkin/Jaeger 集成
Dubbo 官方也提供了对 Zipkin 和 Jaeger 等开源追踪系统的适配。通常只需添加对应的依赖(如 dubbo-tracing-zipkin)并进行简单配置,即可将追踪数据上报。
3.3 方案三:启用 Dubbo Admin 与简易监控中心(轻量级)
对于中小规模或快速起步的项目,Dubbo 自带的治理工具是更轻量的选择。
1. Dubbo Admin
Dubbo Admin 是一个功能丰富的 Web 管理控制台。它不仅提供服务与实例的查询、配置管理等治理功能,还能直观地展示服务调用关系、实时状态和健康度,是日常运维的得力助手。
2. Dubbo Simple Monitor
这是一个独立的简易监控中心组件,历史较久但部署简单。
- 工作原理:Provider 和 Consumer 会定期将统计信息(如调用次数、成功次数、平均耗时)发送到 Monitor 服务器,后者将数据持久化到磁盘。
- 特点与局限:部署简单,挂掉不影响业务调用。但其数据通常不是实时的,聚合能力和可视化效果也较为基础,适用于对监控要求不高的场景。
3.4 方案四:配置日志与访问日志(问题排查基石)
日志是故障排查的最终依据。Dubbo 提供了灵活的日志配置。
1. 框架日志
Dubbo 适配了主流的日志框架(Slf4j, Log4j2, Logback等)。你可以通过系统属性 dubbo.application.logger 指定框架,或在 logback.xml 中调整 Dubbo 相关日志包的级别。
xml
<logger name="org.apache.dubbo" level="DEBUG" />2. 访问日志(Access Log)
这是一个特别有用的功能,用于记录每一次服务调用的入口和出口。启用后,Dubbo 会将所有请求的摘要信息(如调用方、方法名、耗时)记录到独立日志文件中,是分析流量模式和慢请求的利器。可以在服务提供方配置开启:
xml
<dubbo:provider accesslog="true"/>
<!-- 或指定日志文件 -->
<dubbo:provider accesslog="/logs/dubbo.access.log"/>四、可视化、告警与最佳实践 🛡️
采集数据不是目的,让数据产生价值才是关键。
4.1 构建统一可视化仪表板
利用 Grafana 或 Kibana 等工具,将来自 Prometheus、追踪系统和日志的关键信息整合到一个统一的仪表板中。一个典型的运维仪表板应包含:
- 全局概览:总 QPS、整体成功率、平均响应时间。
- 服务排行:按耗时或错误率排序的"服务热点图"。
- 依赖拓扑:动态的服务间调用关系图。
- 链路查询:便捷的分布式追踪查询入口。
4.2 设置智能告警机制
基于采集到的指标,设定合理的告警规则。
- 基础阈值告警:例如,某服务错误率连续5分钟超过1%,或P99响应时间大于1秒。
- 同比/环比异常告警:例如,当前QPS较昨日同一时段暴跌50%。
- 关联告警:当数据库出现慢查询时,关联告警可能受影响的Dubbo服务。
告警通知应集成到邮件、短信或企业内部协作工具(如钉钉、企业微信)中,确保及时送达。
4.3 性能数据联动与闭环
1. 链路追踪与日志联动
确保将追踪系统产生的 Trace ID 注入到业务日志中。这样,当在仪表板上发现一条慢追踪时,可以通过 Trace ID 快速检索到该次请求在所有相关服务中打印的完整日志,实现"监控-日志-代码"的三维闭环排查。
2. 性能数据驱动优化
定期分析监控数据,识别性能瓶颈。例如:
- 发现某个方法平均响应时间过长,可结合链路追踪定位是网络延迟、数据库查询还是计算逻辑问题。
- 观察线程池指标,动态调整大小以防止资源耗尽。
总结:构建面向未来的可观测性体系
Dubbo 的监控数据采集能力,已经从简单的统计计数,演进为一个涵盖 Metrics、Tracing、Logging 的立体化、全方位的可观测性解决方案。通过本文对核心原理 dubbo-metrics 模块的剖析以及对四种实战方案的详解,相信你已经掌握了构建这套体系的钥匙。
记住,可观测性建设的核心思想是:"面向失败设计,为未知而建"。一个强大的监控体系,不仅能让你在故障发生时快速定位和恢复(降低MTTR),更能帮助你提前发现系统隐患,主动进行性能优化和容量规划,最终为业务的稳定性和连续性提供坚实保障。
架构师视角:可观测性不是功能的堆砌,而是一种贯穿于系统设计、开发、运维全周期的工程文化。将 Dubbo 强大的数据采集能力与你的运维平台、流程深度结合,才能真正释放微服务架构的潜力,做到"运筹帷幄,了然于胸"。