博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、唯品会网站、requests爬虫、Echarts可视化、数据清洗、HTML
2、项目界面
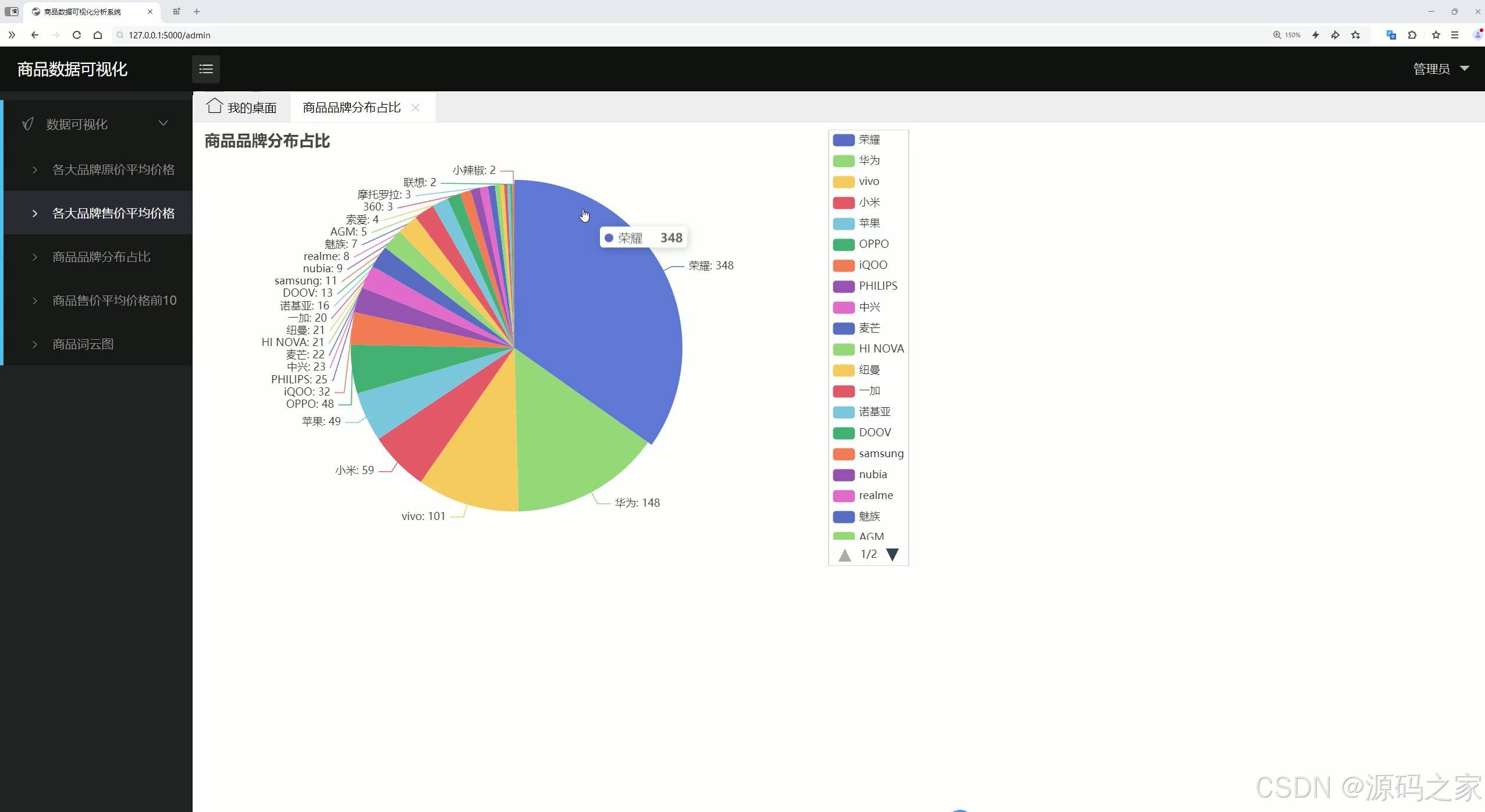
(1)商品品牌分布占比分析
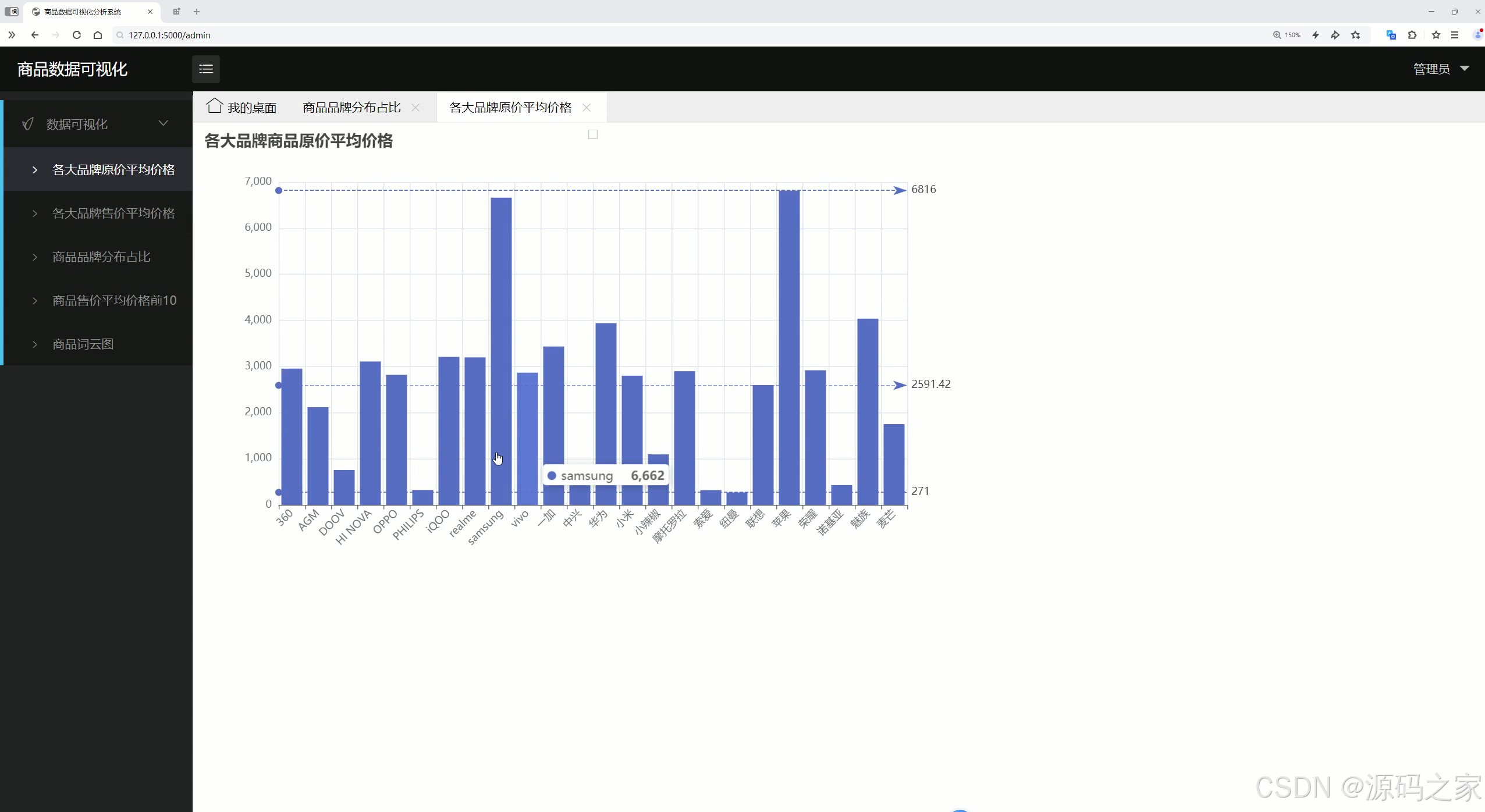
(2)各大品牌商品原价平均价格分析
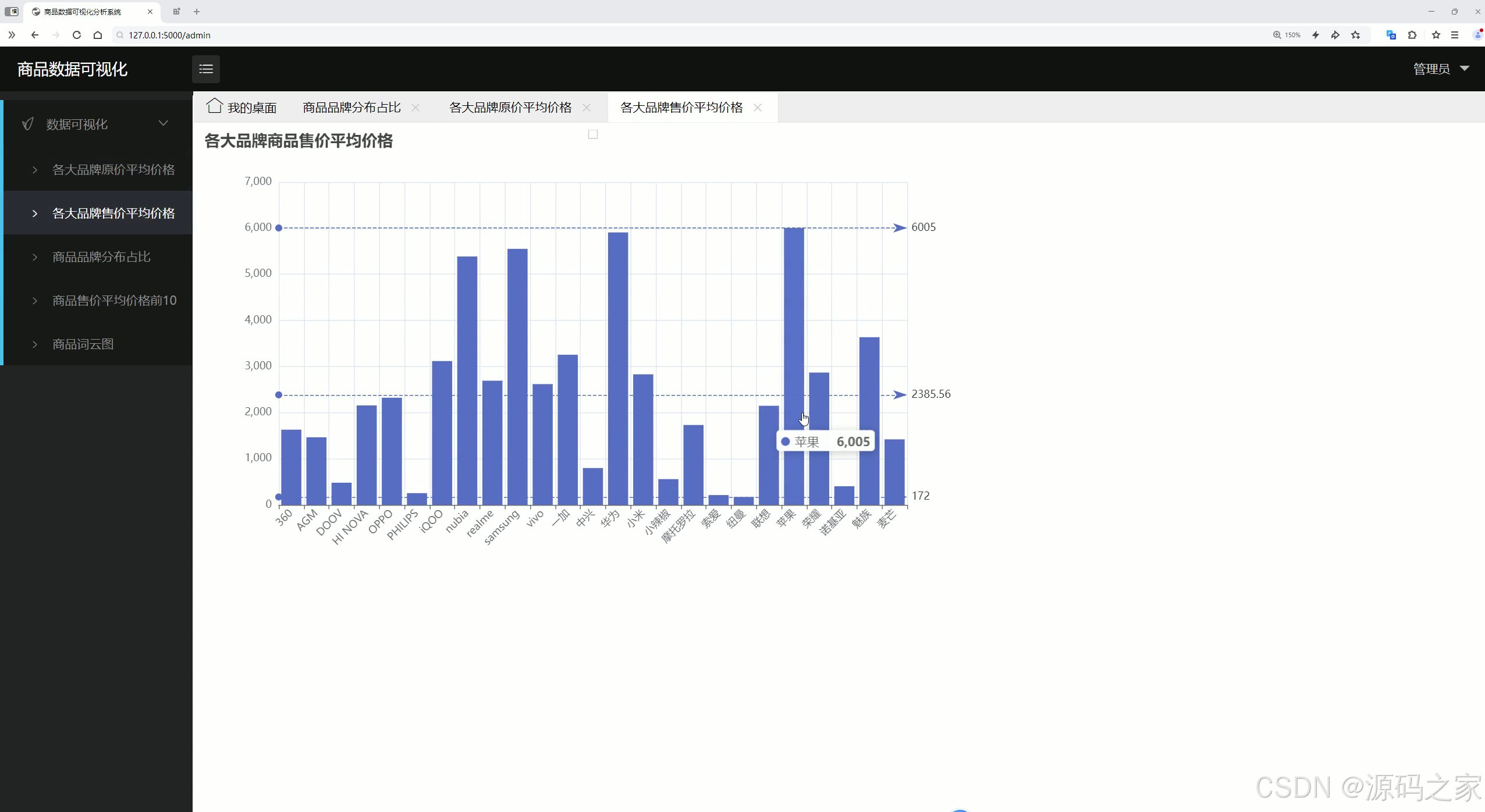
(3)各大品牌商品售价平均价格分析
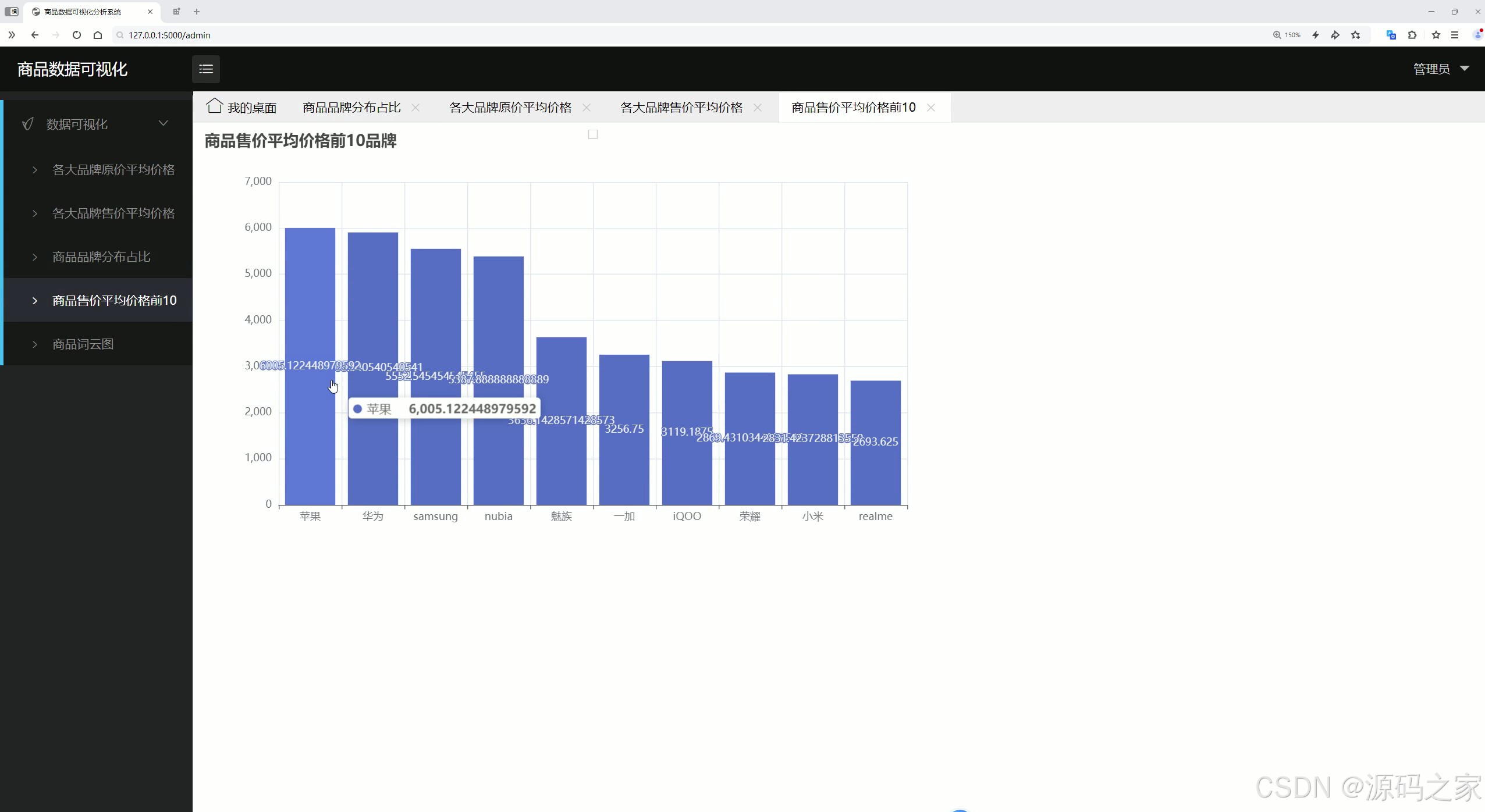
(4)商品平均加工前10
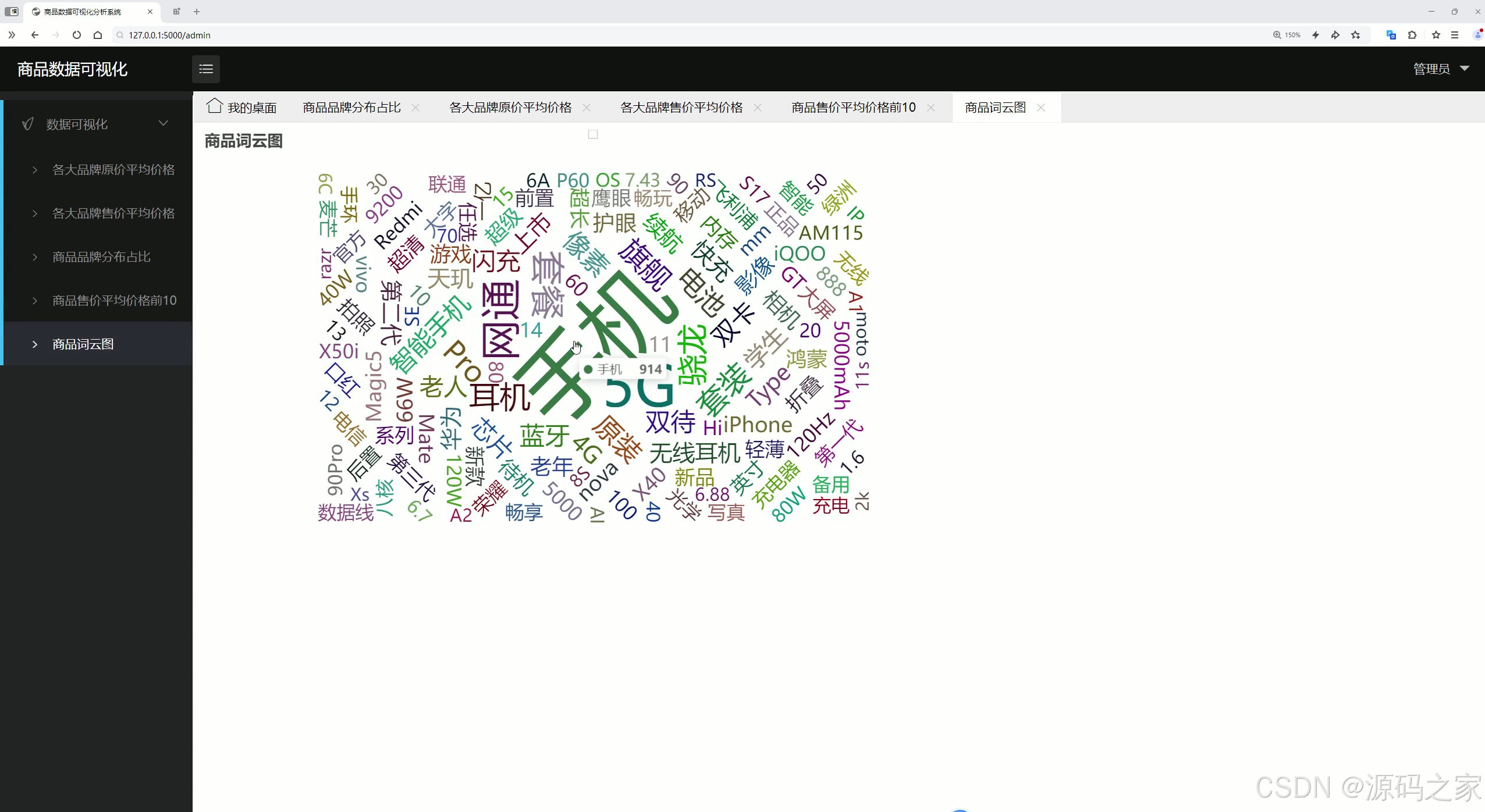
(5)商品词云图分析
(6)首页
(7)注册登录
3、项目说明
该项目是一个针对唯品会网站商品数据的分析系统。通过requests爬虫技术从唯品会获取商品数据,利用Python语言和Flask框架进行数据处理和后端开发,结合Echarts实现数据可视化,并运用HTML构建前端页面。系统能够对商品品牌分布、价格等多维度数据进行分析展示,还具备用户注册登录功能。
功能模块
商品品牌分布占比分析:以图表形式展示不同品牌商品在唯品会的分布占比情况,帮助用户和商家了解各品牌的市场占有率。
各大品牌商品原价平均价格分析:分析并展示各大品牌商品的原价平均价格,为用户购买决策和商家定价策略提供参考依据。
各大品牌商品售价平均价格分析:与原价平均价格分析类似,但关注的是商品的售价平均价格,反映各品牌商品在唯品会的实际销售价格水平。
商品平均加工前10:展示商品平均加工时间排名前10的商品,可能涉及商品的生产、上架等环节的效率分析,为商家优化供应链提供数据支持。
商品词云图分析:生成商品相关的词云图,直观展示商品的热门关键词、用户关注焦点等信息,挖掘市场趋势和用户需求。
首页:作为用户进入系统的入口页面,展示系统的特色功能、重要数据分析结果等,引导用户进行深入探索和使用。
注册登录:提供用户注册和登录功能,方便用户保存浏览记录、收藏商品等,增强用户粘性和系统安全性。
项目特点
数据驱动的市场洞察:通过对唯品会商品数据的多维度分析,为用户和商家提供深入的市场洞察,帮助其做出更明智的决策。
直观的数据可视化:借助Echarts等工具,将复杂的数据以直观的图表形式呈现,降低数据理解难度,提升用户体验。
用户友好的交互设计:采用HTML等技术构建前端页面,确保页面布局合理、操作流畅,提供良好的用户交互体验。
实用的用户管理功能:注册登录功能的加入,使得系统能够为用户提供个性化的服务,如个性化推荐、收藏夹等,提升用户满意度。
4、核心代码
python
from sqlalchemy import create_engine
from pyecharts.charts import Bar
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
import pandas as pd
from pyecharts.charts import Pie
from pyecharts.charts import WordCloud
import jieba
from pyecharts import options as opts
# 连接数据库,读取数据
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/vipshop')
sql1 = "select * from data"
df = pd.read_sql_query(sql1, engine)
df.head()
shop_num = df['品牌'].value_counts().to_list()
shop_type = df['品牌'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(shop_type, shop_num)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="商品品牌分布占比"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render("templates/商品品牌分布占比饼图.html")
avg_salary = df.groupby('品牌')['售价'].mean()
ShopType = avg_salary.index.tolist()
ShopNum = [int(a) for a in avg_salary.values.tolist()]
c = (
Bar()
.add_xaxis(ShopType)
.add_yaxis("", ShopNum)
.set_global_opts(
title_opts=opts.TitleOpts(title="各大品牌商品售价平均价格"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度
)
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="min", name="最小值"),
opts.MarkLineItem(type_="max", name="最大值"),
opts.MarkLineItem(type_="average", name="平均值"),
]
),
)
)
c.render("templates/各大品牌商品售价平均价格柱状图.html")
avg_salary = df.groupby('品牌')['原价'].mean().dropna()
ShopType_1 = avg_salary.index.tolist()
ShopNum_1 = [int(a) for a in avg_salary.values.tolist()]
c = (
Bar()
.add_xaxis(ShopType_1)
.add_yaxis("", ShopNum_1)
.set_global_opts(
title_opts=opts.TitleOpts(title="各大品牌商品原价平均价格"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)) # 设置X轴标签旋转角度为45度
)
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="min", name="最小值"),
opts.MarkLineItem(type_="max", name="最大值"),
opts.MarkLineItem(type_="average", name="平均值"),
]
),
)
)
c.render("templates/各大品牌商品原价平均价格柱状图.html")
w = df.groupby('品牌')['售价'].mean()
top_10_indices = w.nlargest(10).index.tolist()
top_10_prices = w[top_10_indices].tolist()
c = (
Bar()
.add_xaxis(top_10_indices)
.add_yaxis("", top_10_prices)
.set_global_opts(
title_opts=opts.TitleOpts(title="商品售价平均价格前10品牌")
)
)
c.render("templates/商品售价平均价格前10品牌柱状图.html")
df1 = df["标题"]
df1 = df1.values.tolist()
dict = {}
for item in df1:
wordlist = jieba.cut(item)
for key in wordlist:
dict[key] = dict.get(key, 0) + 1
words = list(dict.keys())
counts = list(dict.values())
data1 = []
for i in range(len(words)):
if len(words[i])>=2:
data1.append((words[i], counts[i],))
else:
pass
c = (
WordCloud()
.add(
"",
data1,
word_size_range=[20, 100],
textstyle_opts=opts.TextStyleOpts(font_family="cursive"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="商品词云图"))
.render("templates/商品词云图.html")
)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式

🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻