前言
随着多模态大模型(LMM)的发展,不仅图像理解能力突飞猛进,视频理解(Video Understanding)也迎来了新的爆发。InternVL 2.5 系列中的 InternVideo2_5_Chat_8B 是一款强大的多模态模型,它具备视频内容分析、总结、视觉问答(VQA)以及多轮对话的能力。
本文将基于官方推理代码,分步骤解析如何利用该模型处理视频数据,实现"看视频说话"的功能。
1. 核心架构与原理解析
InternVideo2.5 的核心逻辑在于如何将时间维度的视频数据和空间维度的图像细节高效地输入给 LLM。代码中采用了 动态高分辨率预处理(Dynamic High-Resolution Preprocessing) 策略。
架构流程图
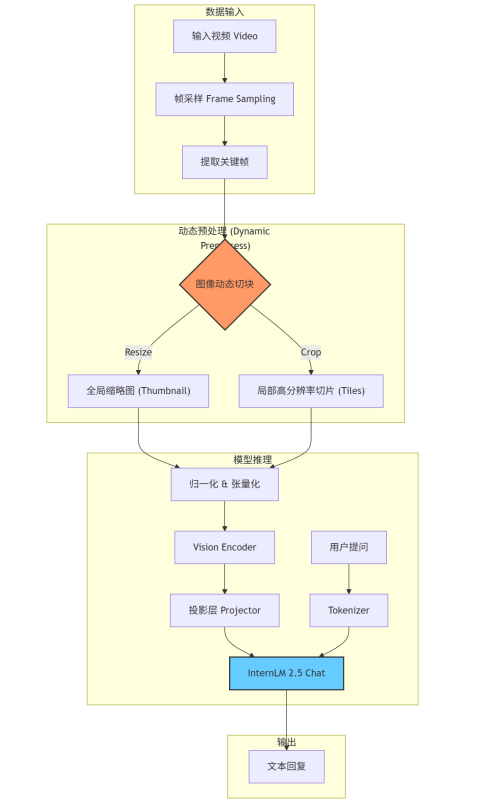
核心机制说明:
- 帧采样:从视频中按时间均匀或固定数量提取帧。
- 动态切块:为了保留细节,模型不只是简单缩放图片,而是将每一帧切分成多个局部 Patch(切片),同时保留一张缩略图作为全局信息。
- 多轮对话 :通过维护
chat_history,模型能够记住之前的视频内容和问答上下文。
2. 代码实现详解
步骤一:环境准备与模型加载
首先,我们需要下载模型权重并初始化模型。这里使用的是 ModelScope 社区的源。
python
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
# 1. 下载模型 (如果已下载可注释)
model_dir = snapshot_download('OpenGVLab/InternVideo2_5_Chat_8B', cache_dir='/root/autodl-tmp/models')
# 2. 加载模型与分词器
model_path = '/root/autodl-tmp/models/OpenGVLab/InternVideo2_5_Chat_8B'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 使用 bfloat16 精度加载模型以节省显存并加速推理
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda().to(torch.bfloat16)步骤二:构建图像预处理管道
视频的每一帧本质上都是图片。为了适配 Vision Transformer 的输入,我们需要标准的 ImageNet 归一化处理。
python
import torchvision.transforms as T
from torchvision.transforms.functional import InterpolationMode
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
"""构建标准的图像预处理流程:Resize -> ToTensor -> Normalize"""
transform = T.Compose([
T.Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)
])
return transform步骤三:动态高分辨率预处理 (核心逻辑)
这是 InternVL 系列最关键的代码。dynamic_preprocess 函数会根据图像(帧)的宽高比,将其动态切分为多个 image_size x image_size 的块,并附加一张缩略图。
为什么这么做? 传统的 Resize 会导致严重的信息丢失(如看不清车牌、文字)。切片策略让模型既能看清局部细节,又能掌握全局关系。
python
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# 1. 计算最佳的切块布局 (例如 1x2, 2x2, 2x3 等)
target_ratios = set((i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
target_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# 2. 计算目标尺寸并Resize
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
resized_img = image.resize((target_width, target_height))
# 3. 执行切块操作
processed_images = []
for i in range(blocks):
# ... (计算坐标并 crop)
box = (...)
split_img = resized_img.crop(box)
processed_images.append(split_img)
# 4. 添加缩略图 (Global View)
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images步骤四:视频加载与采样
使用 decord 库读取视频,并根据设定的 num_segments(段数)进行均匀采样。
python
from decord import VideoReader, cpu
import numpy as np
from PIL import Image
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32, get_frame_by_duration=False):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
# ... (计算需要采样的帧索引 frame_indices) ...
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
# 遍历每一帧进行处理
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert("RGB")
# 对每一帧应用动态预处理
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
# 记录每一帧被切成了多少块 (用于后续 Attention Mask)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list步骤五:多轮推理实现
最后,我们将处理好的视频张量传入模型。注意 Prompt 的构建方式,需要为每一帧添加 <image> 占位符。
python
video_path = "car.mp4" # 替换为你的视频路径
num_segments = 128 # 采样的帧数,越多效果越好显存占用越高
with torch.no_grad():
# 1. 加载数据
pixel_values, num_patches_list = load_video(video_path, num_segments=num_segments, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).to(model.device)
# 2. 构建视频 Prompt 前缀
# 格式: "Frame1: <image>\nFrame2: <image>\n..."
video_prefix = "".join([f"Frame{i+1}: <image>\n" for i in range(len(num_patches_list))])
# 3. 第一轮对话:通用描述
question1 = "车的哪个部位损伤了?"
question = video_prefix + question1 # 将前缀加在第一个问题前
# 调用 chat 接口
# history=None 表示第一轮
output1, chat_history = model.chat(
tokenizer,
pixel_values,
question,
generation_config,
num_patches_list=num_patches_list,
history=None,
return_history=True
)
print("AI回答 1:", output1)
# 4. 第二轮对话:追问细节
# 传入上一轮的 chat_history 实现上下文记忆
question2 = "车撞到哪里了?"
output2, chat_history = model.chat(
tokenizer,
pixel_values,
question2,
generation_config,
num_patches_list=num_patches_list,
history=chat_history,
return_history=True
)
print("AI回答 2:", output2)requirements.txt
python
decord==0.6.0
modelscope==1.25.0
numpy==2.2.5
Pillow==11.2.1
torch==2.5.1+cu121
torchvision==0.20.1+cu1213. 总结
通过上述代码,我们成功实现了基于 InternVideo2.5 的视频理解应用。该方案的亮点在于:
- 动态分辨率 :通过
dynamic_preprocess解决了大模型输入分辨率受限与视频细节丢失之间的矛盾。 - 长视频支持 :通过
num_segments控制采样密度,配合num_patches_list让模型理解时间序列。 - 多轮交互 :利用
history参数轻松实现连续追问。
这套代码可以广泛应用于智能监控分析、视频内容摘要生成、以及辅助驾驶场景分析等领域。
注意 :运行此代码需要约 24GB+ 显存(取决于
num_segments和max_num的设置),建议在 A100 或 3090/4090 等高端显卡上运行。