TL;DR
- 场景:在日志检索、电商搜索等场景中,需要在 Elasticsearch 中组合过滤、排序、分页、高亮与批量操作。
- 结论:Filter DSL 负责"是否匹配"、Query 负责"匹配程度",再配合 sort/from/size/highlight/_mget/_bulk 形成一整套检索实战组合拳。
- 产出:一篇覆盖 Filter DSL、排序分页、高亮展示与批量读写的实战笔记,可直接套用到线上检索与数据写入链路。

版本矩阵
| Elasticsearch 版本 | 已验证 | 说明 |
|---|---|---|
| 7.x(7.6+) | 是 | 开发/测试环境常规使用,Filter DSL、sort、highlight、_mget、_bulk 语法均兼容当前示例。 |
| 8.x(8.0+) | 是 | 官方仍兼容本文的 DSL 写法,个别默认映射策略与安全配置略有变化,需按实际集群调整索引与权限。 |
| 6.x 及以下 | 否 | 核心概念相同,但部分 REST API 路径与字段映射细节有差异,需结合对应版本官方文档确认。 |
Filter DSL
基本介绍
Filter DSL:过滤器查询语言) Filter DSL 是 Elasticsearch 提供的一种用于构建过滤查询的方式。与 query 语句不同,过滤器不会计算与文档相关的评分,而是简单地筛选出符合条件的文档。这通常用于只关心是否匹配而不考虑匹配度的情况,如日志分析、数据分类等场景。Filter 查询更高效,适合不需要计算相关性的操作。
实际使用
Elasticsearch中的所有的查询都会触发相关度得分计算,对于那些不需要相关度得分的场景下,Elasticsearch以过滤器的形式提供了另一种查询功能,过滤器在概念上类似于查询,但是他们有非常快的执行速度,执行速度快主要有以下两个原因:
- 过滤器不会计算相关度的得分,所以它们在计算上更快一些
- 过滤器可以被缓存到内存中,这使得他在重复的搜索查询上,其要比相应的查询快的多
为了理解过滤器,可以将一个查询(像是match_all,match,bool等)和一个过滤器结合起来,我们以范围过滤器为例,它允许我们通过一个区间值来过滤文档,这通常被用在数字和日期的过滤上,下面这个例子使用一个被过滤的 查询,其返回值是200到1000之间(闭区间)的书:
json
POST /book/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"range": {
"price": {
"gte": 200,
"lte": 1000
}
}
}
}
}
}运行的结果如下图所示: 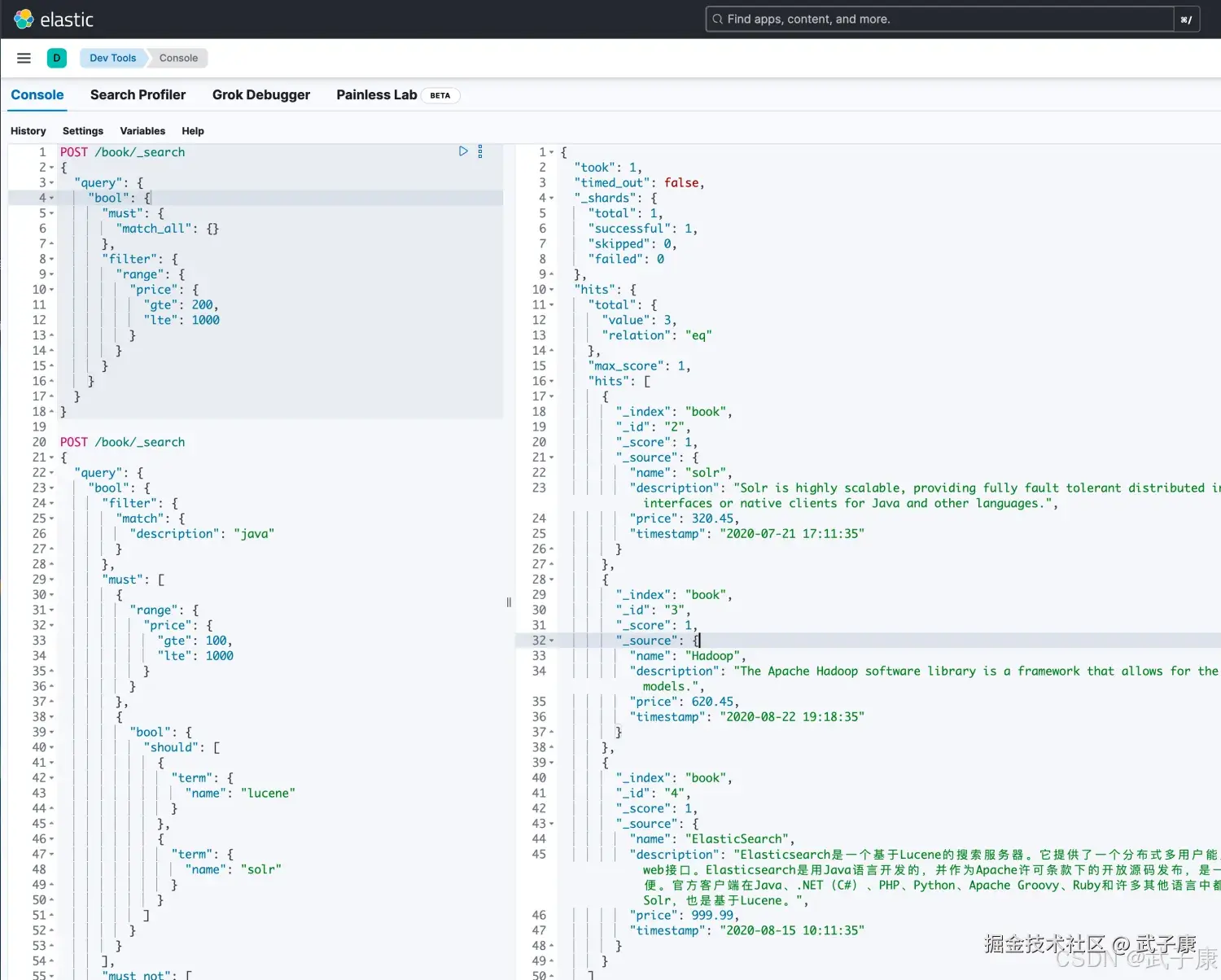 分解上面的例子,被过滤的查询包含一个match_all查询和一个过滤器。可以在查询部分放入其他查询,在Filter部分放入其他过滤器,在上面的应用场景中,由于所有的在这个范围之内的文档都是平等的(相关度都一样),没有一个文档比另一个文档更相关。所以这个时候就要使用范围过滤器。 通常情况下,要决定使用过滤器还是查询,你就需要问自己是否需要相关度得分,如果相关度不重要,那就使用过滤器,否则使用查询。查询和过滤器在概念上类似于SELECT WHERE语句。
分解上面的例子,被过滤的查询包含一个match_all查询和一个过滤器。可以在查询部分放入其他查询,在Filter部分放入其他过滤器,在上面的应用场景中,由于所有的在这个范围之内的文档都是平等的(相关度都一样),没有一个文档比另一个文档更相关。所以这个时候就要使用范围过滤器。 通常情况下,要决定使用过滤器还是查询,你就需要问自己是否需要相关度得分,如果相关度不重要,那就使用过滤器,否则使用查询。查询和过滤器在概念上类似于SELECT WHERE语句。
查询排序
在 Elasticsearch 中,查询结果可以按不同的字段进行排序,默认情况下是按 _score(相关性得分)排序。如果想根据其他字段排序,比如时间戳或价格,可以通过在查询请求中指定 sort 参数来完成。排序可以是升序(asc)或降序(desc),常用于电商、日志分析等需要按时间或数值排序的场景。
相关性评分
默认情况下,返回的结果都是按照相关性进行排序的,最相关的文档排在最前面,首先看看sort参数以及如何使用它。 为了按照相关性来排序,需要将相关性表示为一个数值,在Elasticsearch中,相关性得分由一个浮点数进行表示,并在搜索结果中通过_score参数返回,默认排序是_score降序,按照相关性评分升序排序如下:
json
# 默认查询时的排序
POST /book/_search
{
"query": {
"match": {"description":"solr"}
}
}执行结果如下图所示: 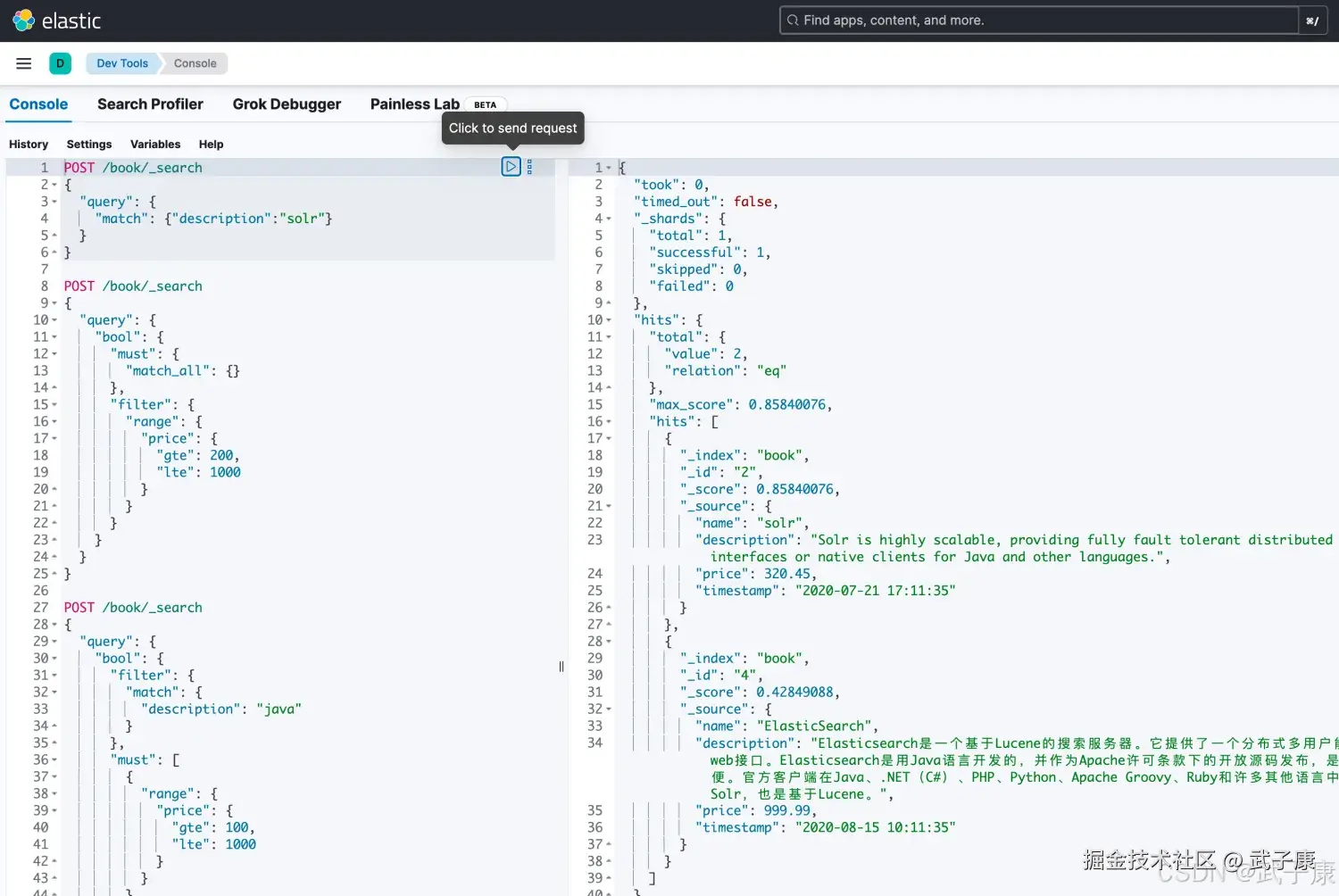
字段值排序
json
# 按照 order 字段进行排序
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}执行的结果如下图所示: 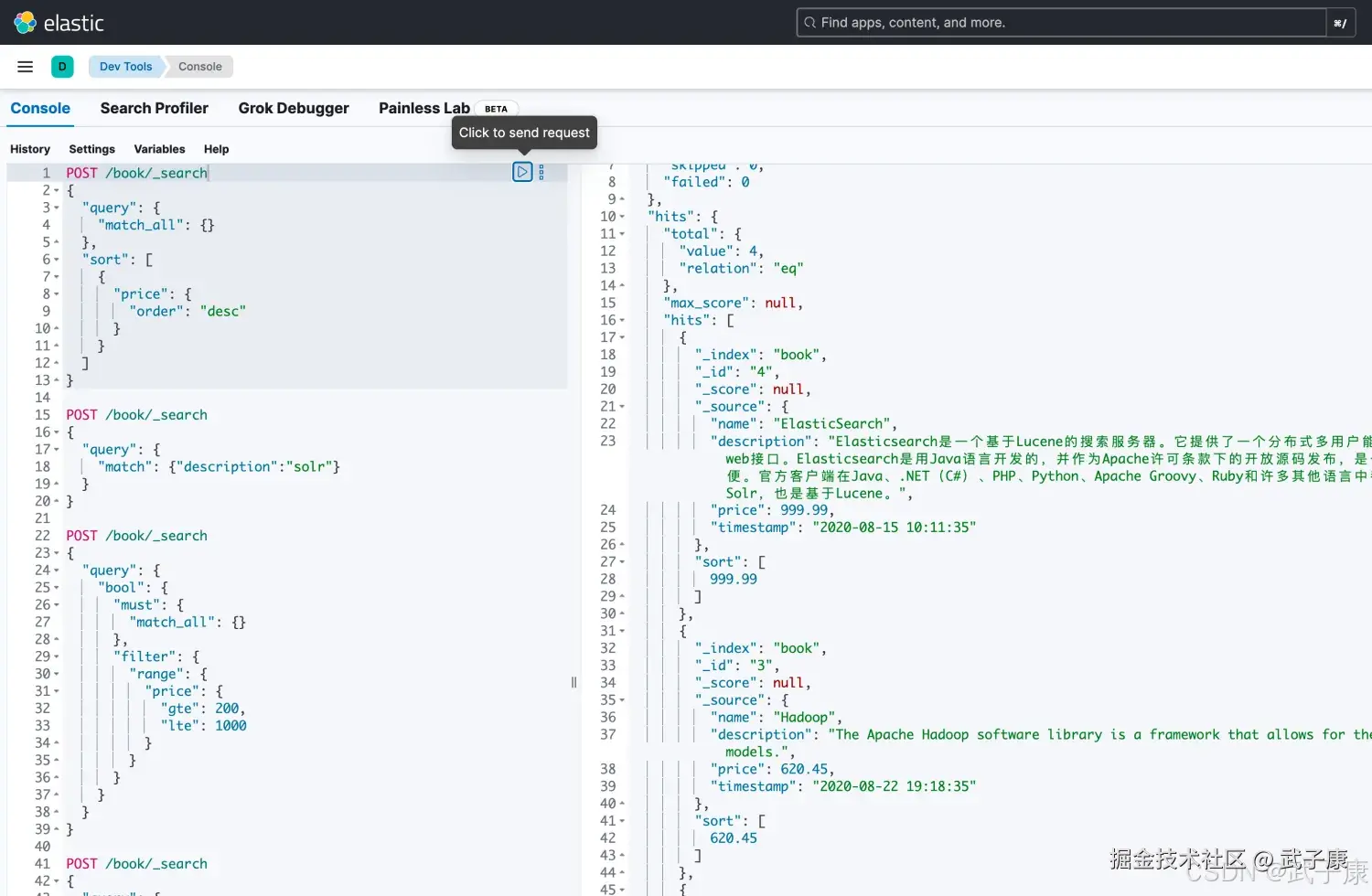
多级排序
json
# 多种排序字段
POST /book/_search
{
"query":{
"match_all":{}
},
"sort": [
{ "price": {
"order": "desc"
}
},
{
"timestamp": {
"order": "desc"
}
}
]
}执行结果如下图所示: 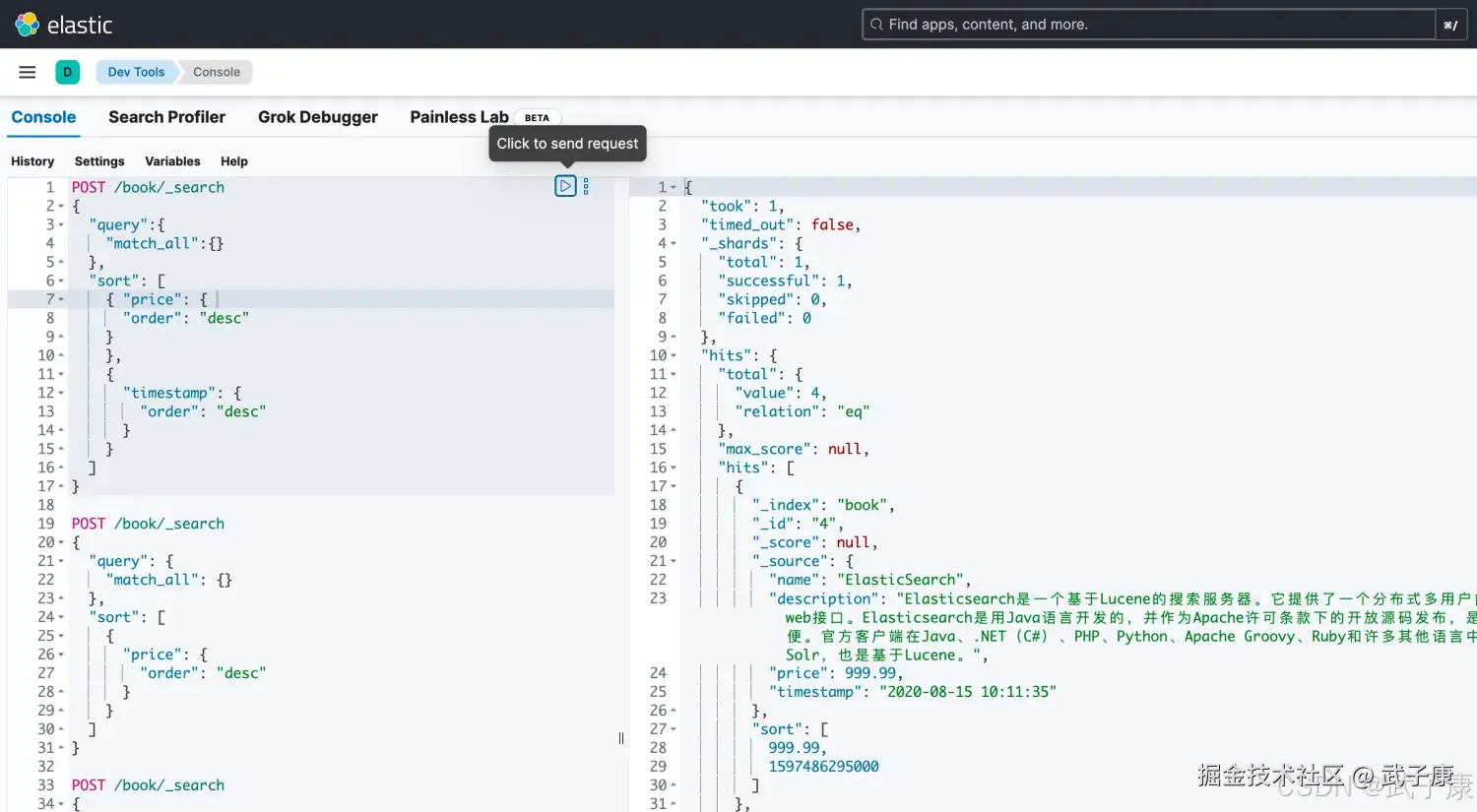
分页查询
Elasticsearch分页的方式是非常简单的:
json
# 分页查询
POST /book/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"size": 2,
"from": 0
}执行结果如下图所示: 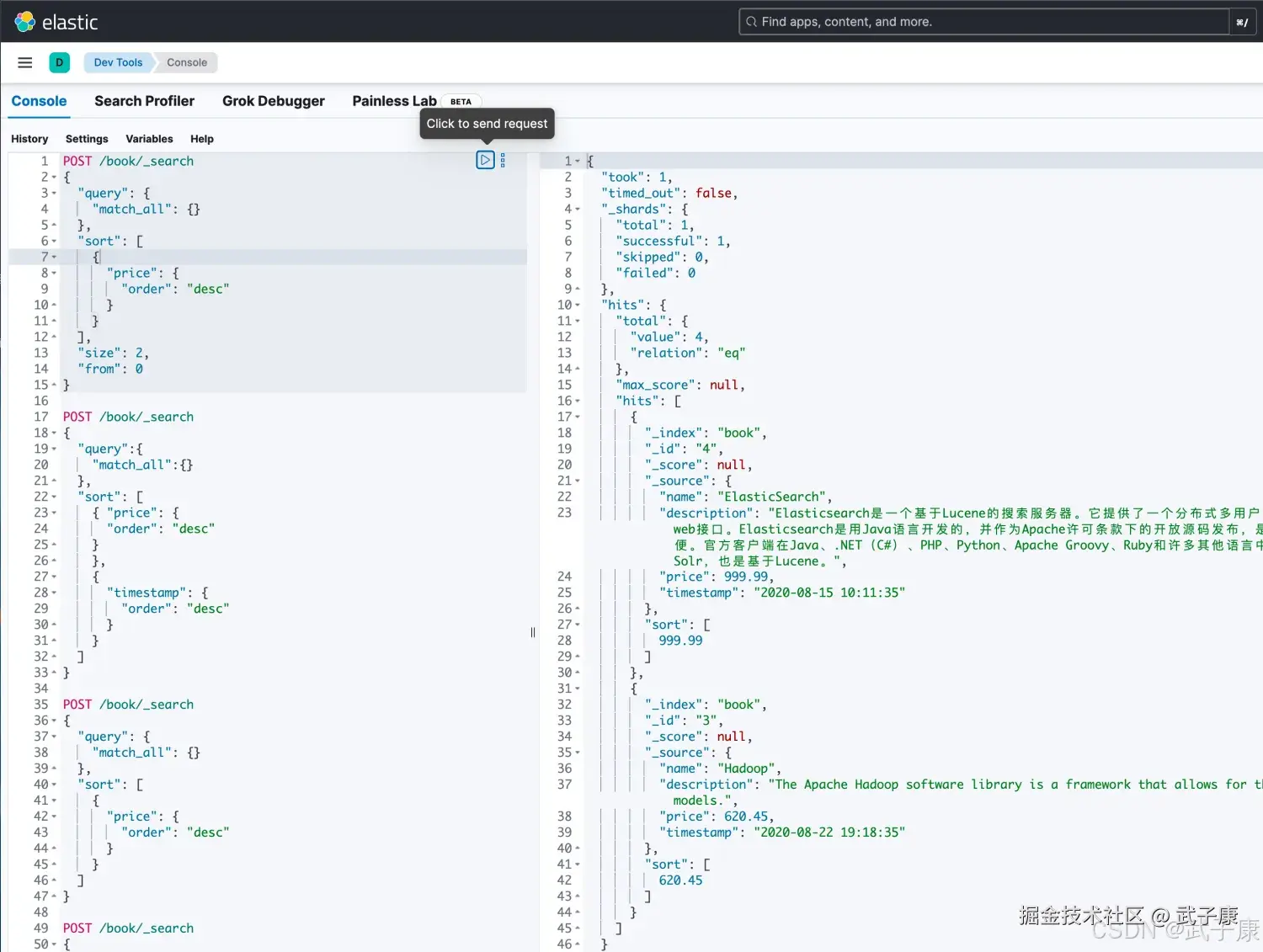
结果高亮
结果高亮功能用于在查询结果中突出显示匹配的关键词。当用户搜索特定的词时,Elasticsearch 可以在返回的文档中用 <em> 标签或其他 HTML 元素将匹配的关键词包裹起来,方便前端展示。这个功能常用于搜索引擎或全文检索的结果展示中,提升用户体验。
json
POST /book/_search
{
"query": {
"match": {
"name": "elasticsearch"
}
},
"highlight": {
"pre_tags": "<font color='pink'>",
"post_tags": "</font>",
"fields": [{"name":{}}]
}
}执行的结果如下图所示: 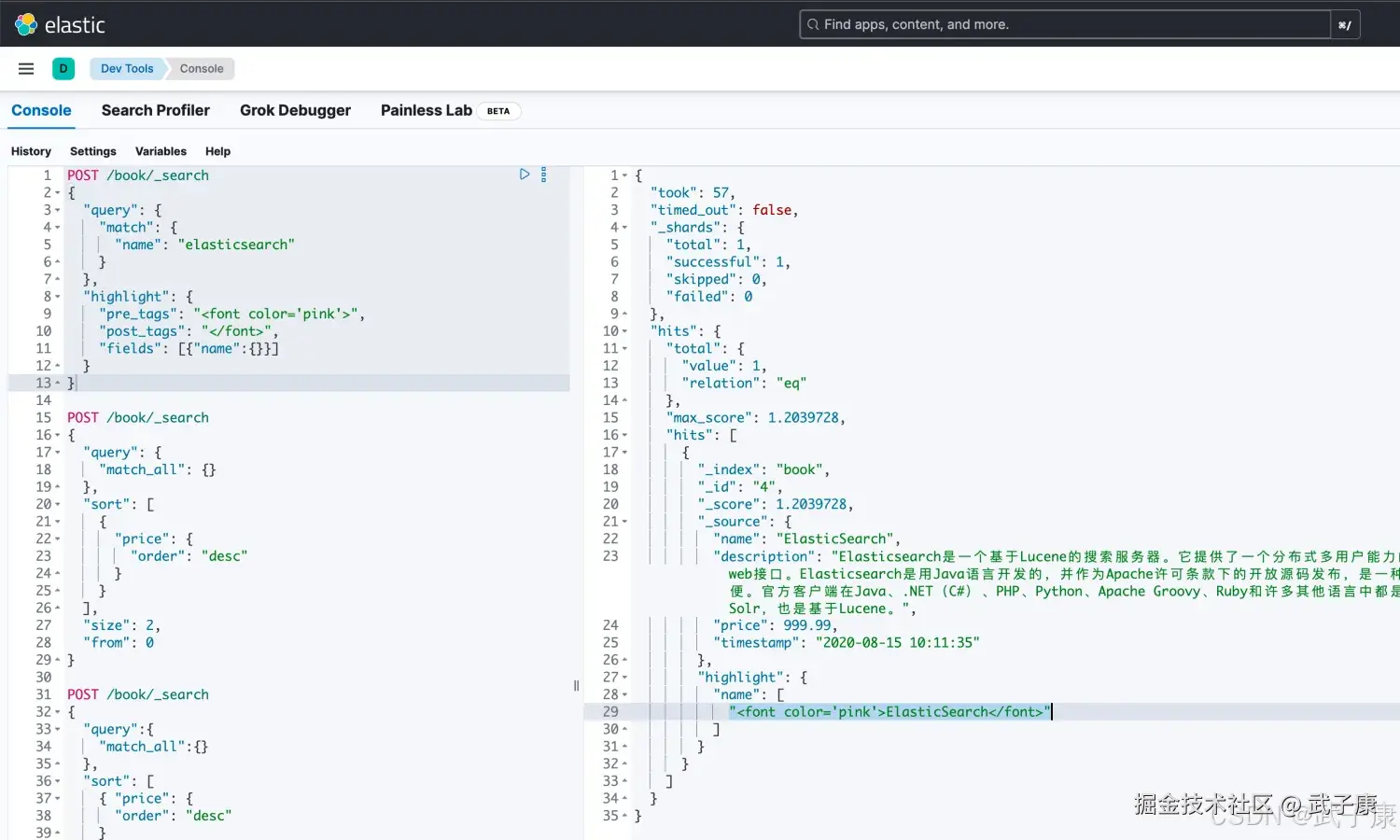 使用match 查询的同时,加上一个highlight属性:
使用match 查询的同时,加上一个highlight属性:
- pre_tags 前置标签
- post_tags 后置标签
- fields 需要高亮的字段,name这里声明title字段需要高亮
批量操作
Elasticsearch 提供了批量操作的 API,用于一次性执行多个操作,如插入、更新、删除等。这种批量操作可以显著提高处理大量数据的效率,减少与服务器的交互次数。Bulk API 在需要进行大规模数据处理或日志批量写入时非常有用。
批量查询
可以使用 mget 提供批量查询 单条查询ID的时候,比如很多个ID,一条一条的查询,网络开销是非常大的。
json
# 批量查询
POST /_mget
{
"docs" : [
{
"_index" : "book",
"_id" : 1
},
{
"_index" : "book",
"_id" : 2
}
]
}运行的结果如下图所示: 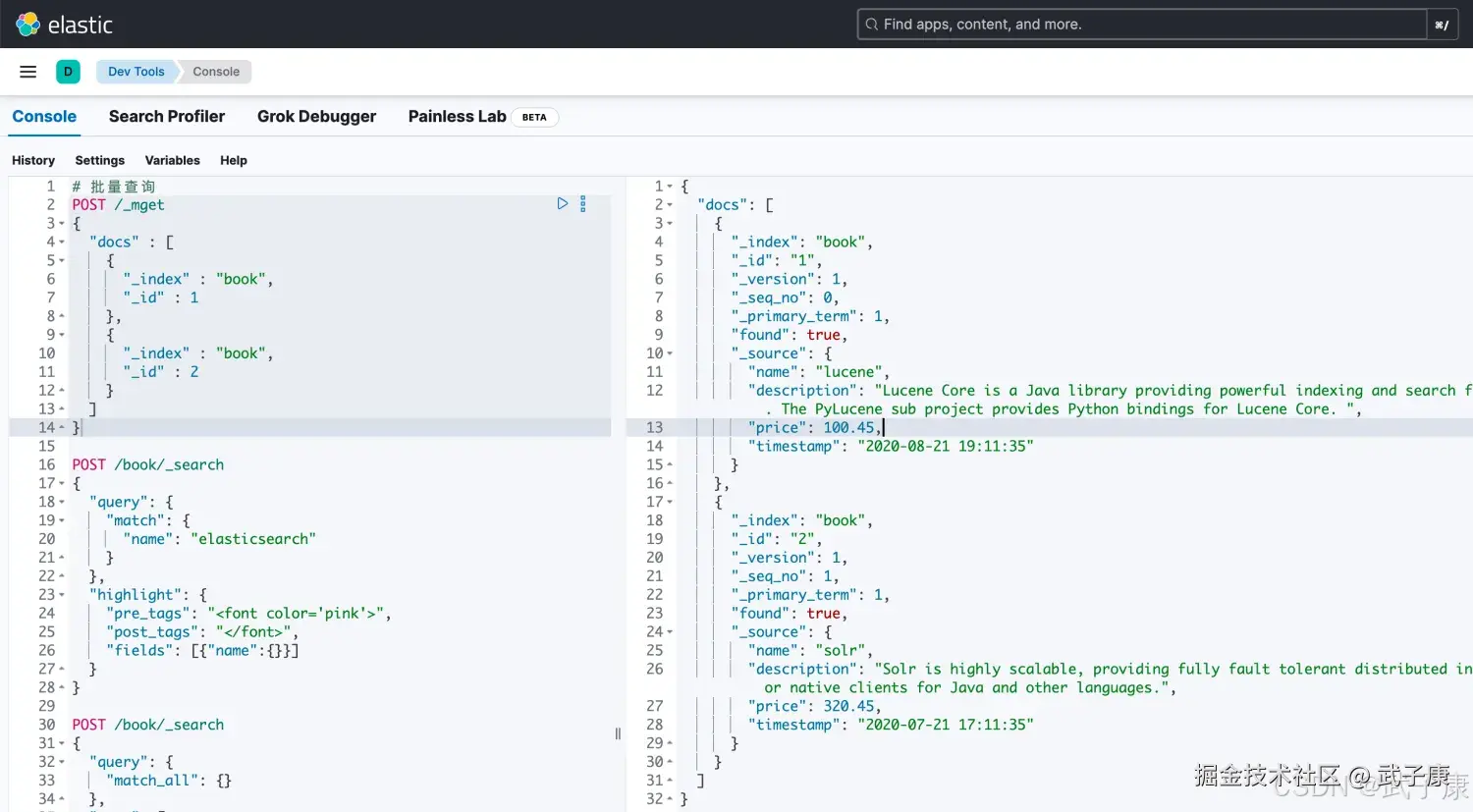
同一索引批量查询
json
# book索引下检索
POST /book/_mget
{
"docs" : [
{
"_id" : 2
},
{
"_id" : 3
}
]
}
# 当然也有一个简化的写法
POST /book/_search
{
"query": {
"ids" : {
"values" : ["1", "4"]
}
}
}执行的结果如下图所示: 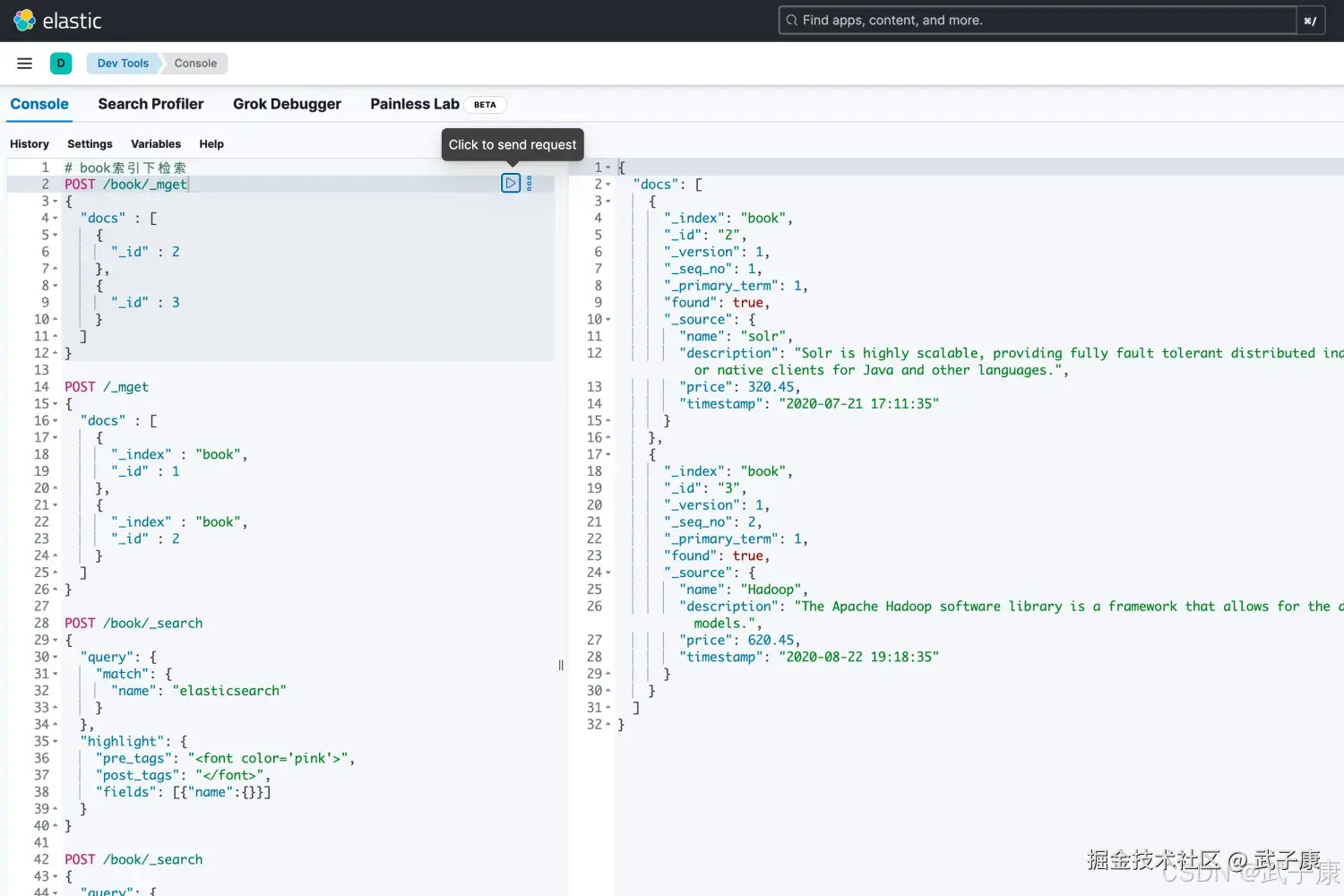
bulk 批量增删改
Bulk 操作解释将文档的增删改查一系列操作,通过一次请求全部做完,减少网络的传输次数。
shell
POST /_bulk
{"action": {"metadata"}}
{"data"}示例:
shell
# 批量的操作,增删改查
POST /_bulk
{ "delete": { "_index": "book", "_id": "1" }}
{ "create": { "_index": "book", "_id": "5" }}
{ "name": "test14","price":100.99 }
{ "update": { "_index": "book", "_id": "2"} }
{ "doc" : {"name" : "test"} }功能:
- delete 删除一个文档,只要1个JSON串就可以 删除的批量操作不需要请求体
- create 相当于强制创建 PUT /index/type/id/_create
- index 普通的put操作,可以是创建文档,也可以是全量替换文档
- update 执行的是局部更新partial update操作
格式:
- 每个JSON不能换行,相邻JSON换行
隔离:
- 每个操作互不影响,操作失败的行会返回其失败信息
实际用法:
-
bulk请求一次不要太大,否则一下会挤压到内存中,性能会下降。
-
一次请求几千个操作,大小在几M正好
-
bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据量不是一个确定的值。取决于你的硬件能力、文档复杂性、索引以及搜索的负载
-
一般建议1万-5万个文档,大小建议是15MB,默认不能超过100MB,可以在(ES) config/elasticsearch.yml中进行设置 http.max_content_length: 10mb
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| bool + filter 写了但"看起来没生效" | 过滤字段类型不匹配(如字符串写成 range)、索引中无满足条件文档 | 使用 GET index/_mapping 查看字段类型;用 term/range 单独测试 Filter | 确认字段类型为数值/日期再用 range;字符串过滤改用 term/terms 或 keyword 字段 |
| Filter DSL 与 query 混用时结果数量异常 | 把本该用 filter 的条件写进 must,相关度导致部分结果被挤掉 | 去掉 filter 部分,仅保留 must 对比总命中数 | 将"纯条件"逻辑(状态、区间、标签)统一放到 bool.filter 中,只把真正需要算相关度的条件留在 must |
| sort 报错或排序不符合预期 | 排序字段为 text 类型,未使用 keyword 或数值字段 | GET index/_mapping 查看字段是否为 text 且无 .keyword | 对 text 字段改用 field.keyword 排序,或在 mapping 中增加 keyword 子字段;数值/日期字段用原字段排序 |
| from/size 分页到大页时变慢或超时 | 深分页,from 非常大,导致 ES 需要跳过大量文档 | 在大页场景下抓慢查询、查看 _search 耗时与节点 CPU | 考虑使用 search_after/scroll 方案替代 from/size 深分页,或限制最大页码与 size |
| highlight 没有任何高亮输出 | highlight fields 未匹配实际字段名,或字段未参与 query | 检查请求中的 highlight.fields 与 query 中使用的字段是否一致 | 确保高亮字段与 query 字段一致;必要时为字段开启合适的映射与分词配置 |
| highlight HTML 标签未生效或被转义 | 前端模板对返回的 HTML 做了转义 | 在浏览器开发者工具中查看原始 JSON 响应与前端渲染后的 DOM | 前端渲染时使用"信任 HTML"或危险 HTML 渲染方式(视框架而定),确保 /等标签不被二次转义 |
| _mget 返回部分文档 missing | _index 或 _id 填写错误,或指定索引下本身不存在该文档 | 检查 _mget 请求体中的 index 与 id;用单条 GET index/_doc/id 验证 | 保证索引名、id 与实际写入时一致,跨索引时注意每条 docs 明确 _index |
| _bulk 请求返回 400/格式错误 | 行间换行不规范、JSON 多加/少加花括号、使用了注释 | 对比官方示例,逐行检查 {"action":{}} 与 {"doc":{}} 是否一一对应 | 保证"动作行"和"数据行"严格成对且各占一行,去掉任何注释与多余空格/逗号 |
| _bulk 中只有部分操作成功 | bulk 中单条操作因映射冲突、版本冲突或验证失败 | 查看 bulk 响应中的 items 列表,逐条检查 error 字段 | 针对失败行单独重放或修正映射/文档结构;大批量导入前在小批数据上做预演 |
| 批量操作时 ES 节点负载飙升 | 单次 bulk 体积过大,全部进内存导致 GC 与 IO 压力过高 | 监控集群 JVM、CPU、IO,观察 bulk 请求时段负载变化 | 控制每次 bulk 的文档数与体积(如 1--5 万文档、约 5--15MB),按机器规格调整并做压测再放量 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解