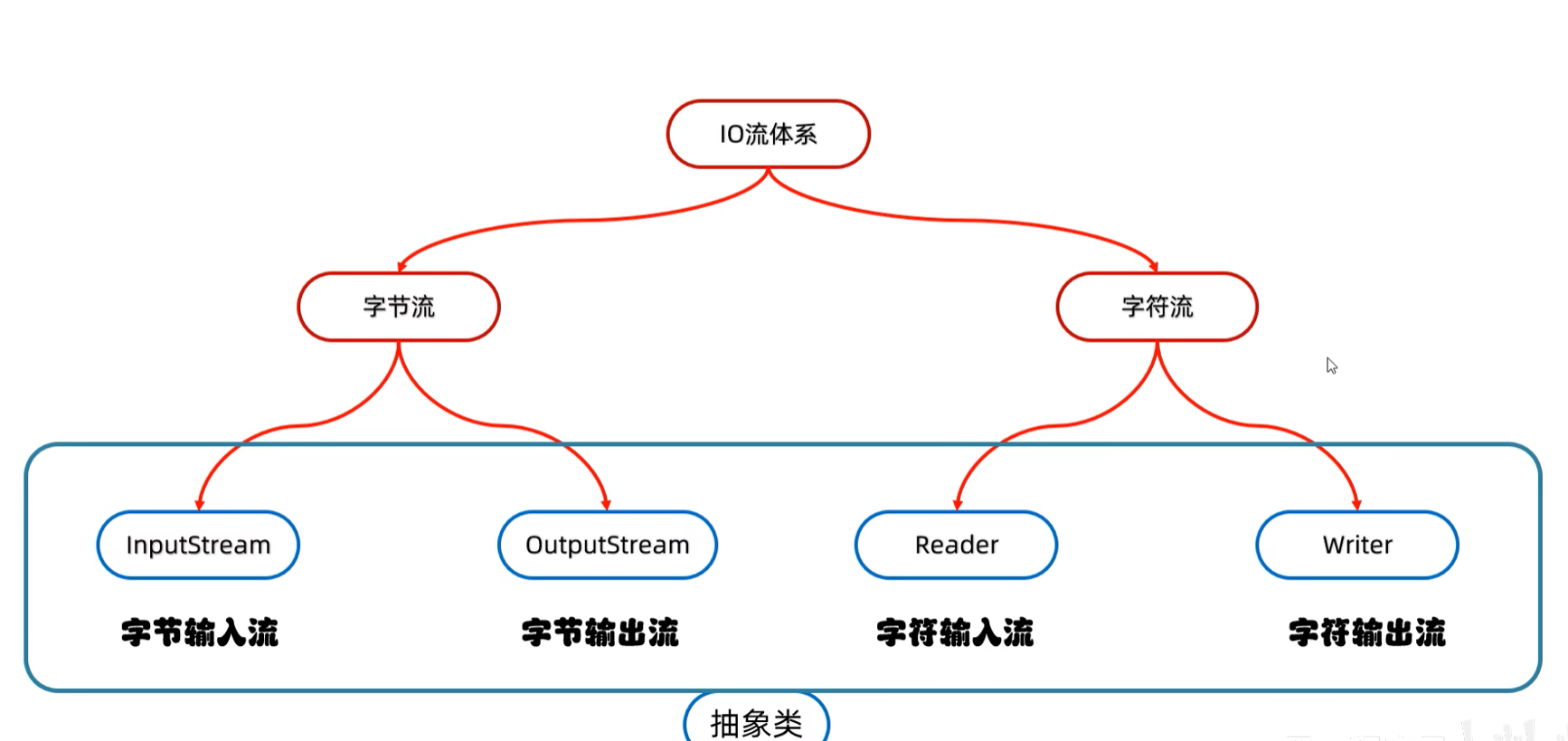
一、IO流的体系
1.1 字符集
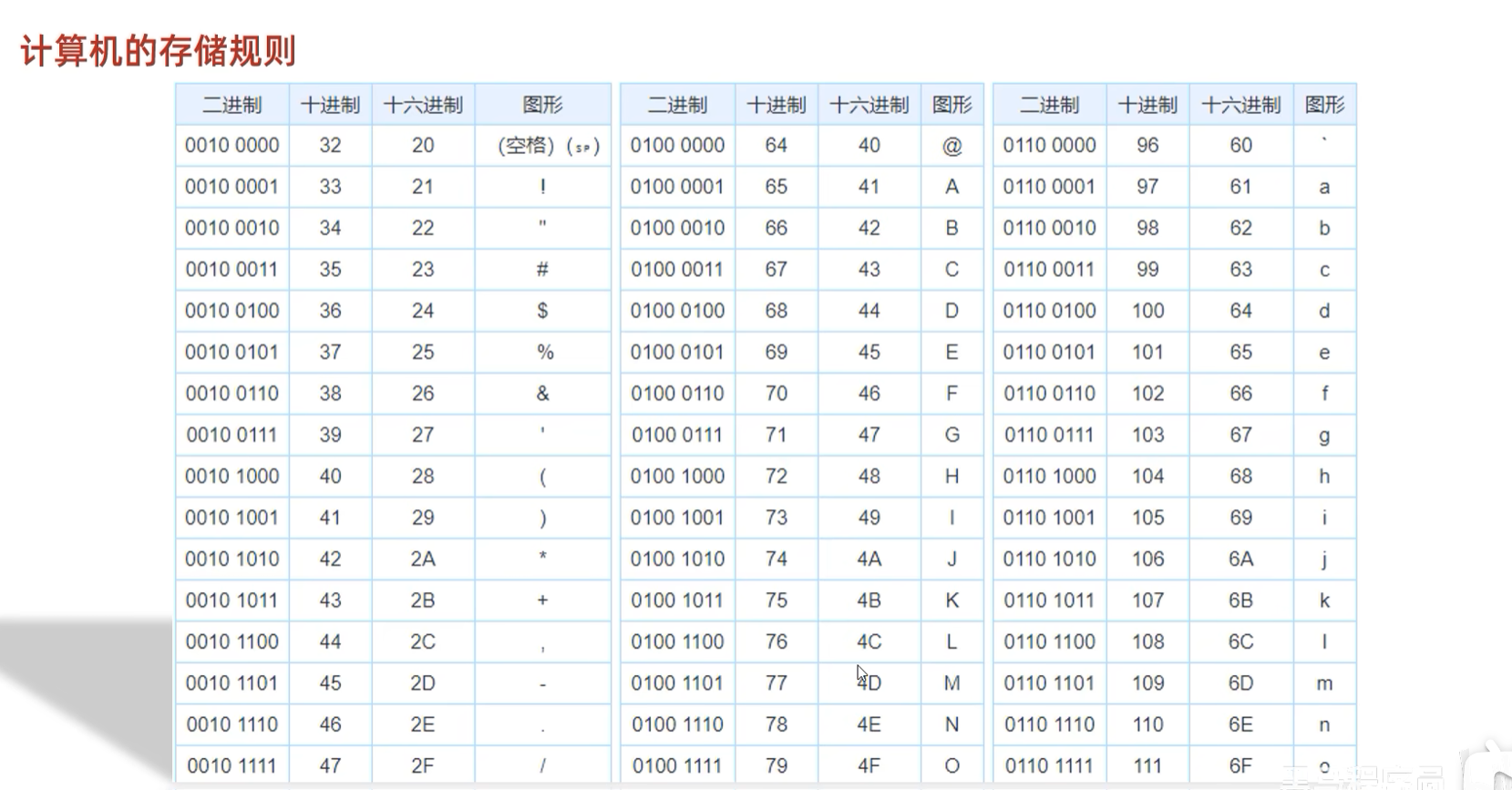
1.1.1 计算机的存储规则


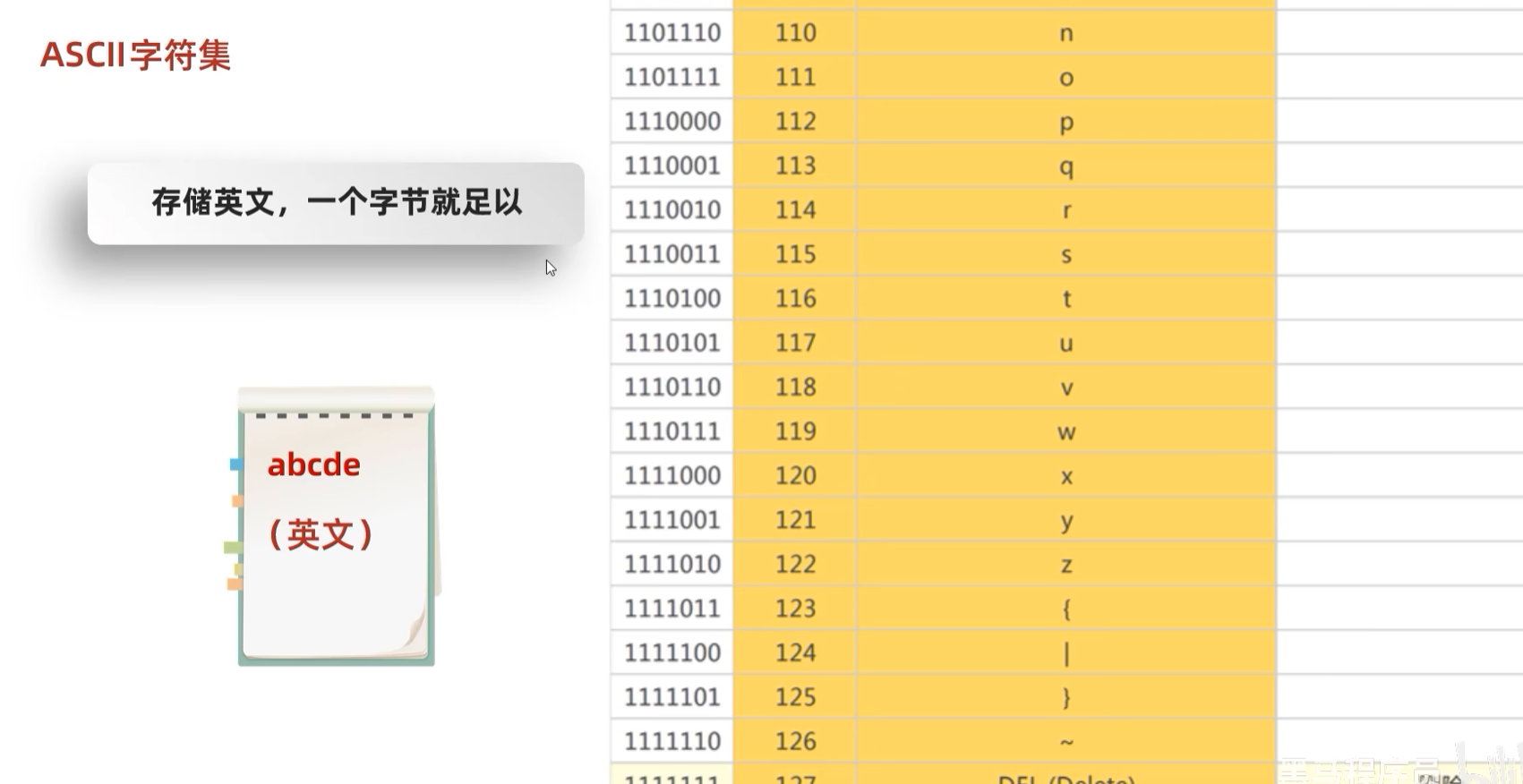
① ASCII字符集
ASCII码对应的最大数字是127,一共是0-127,128个字符。一个字节最多可以表示256的数据。所以可以得出一个结论:存储英文,一个字节足以。
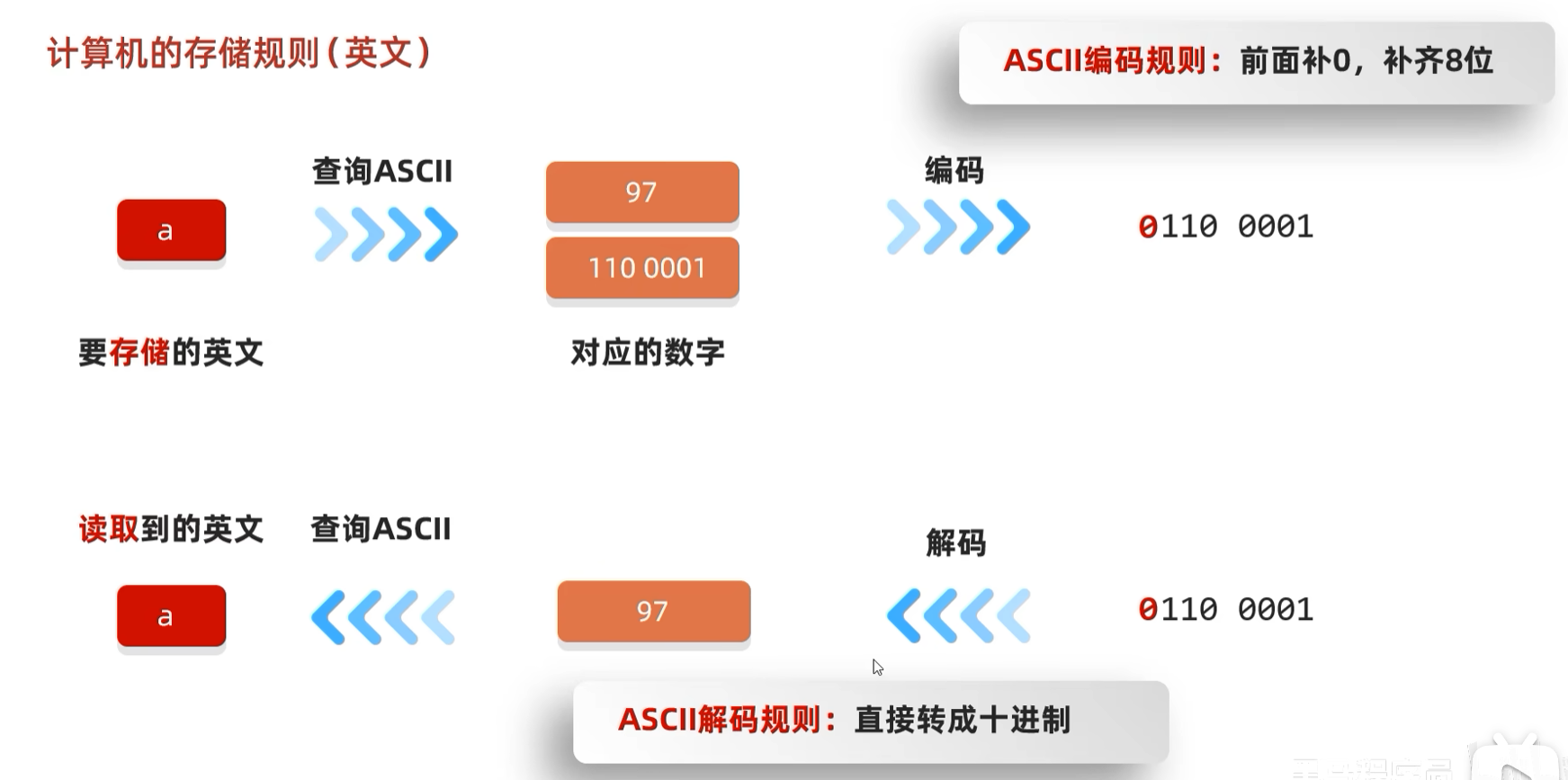
编码:把字符集当中查询到的数据,按照一定的规则进行计算,变成真实的能存储在硬盘当中的二进制数据。解码就是相反的过程。
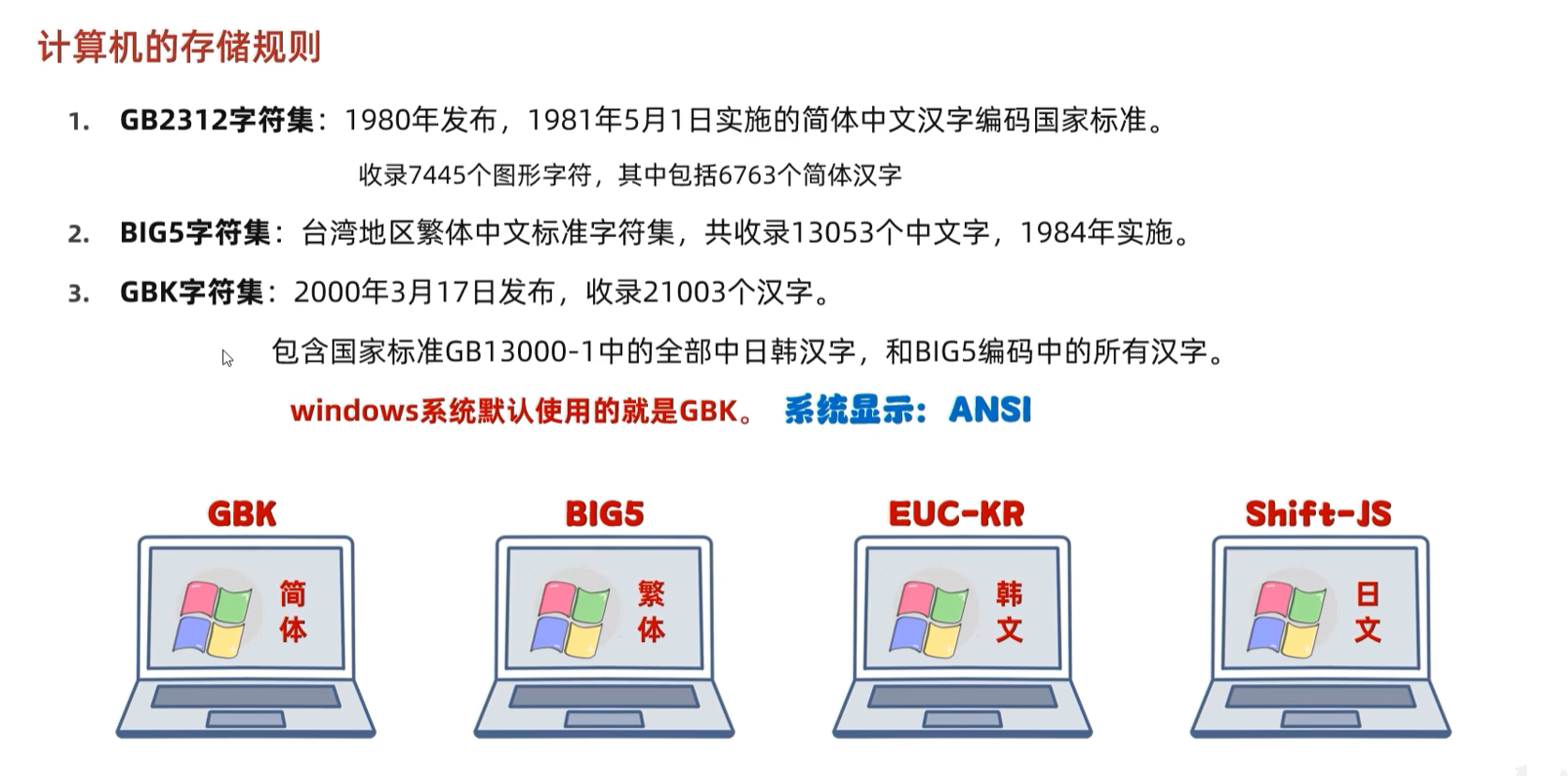

② GBK字符集
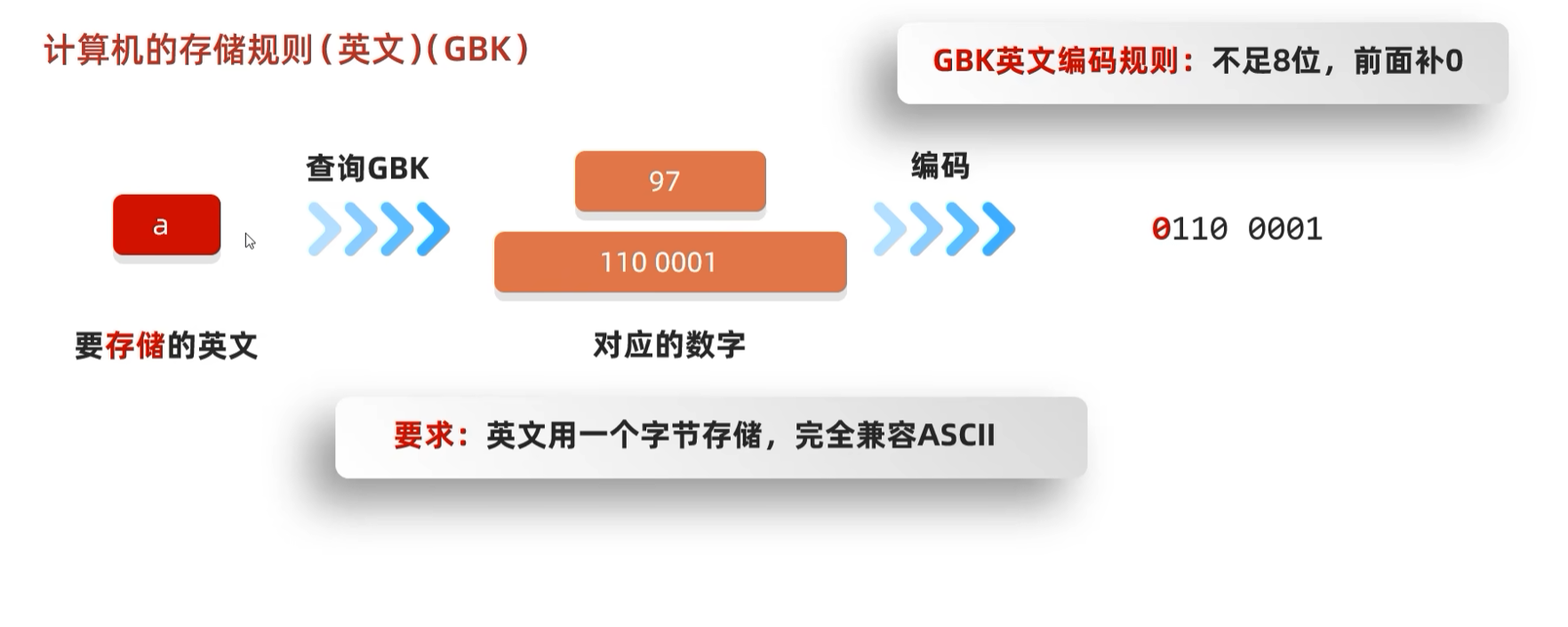

底层如何区分中英文:


③ Unicode字符集
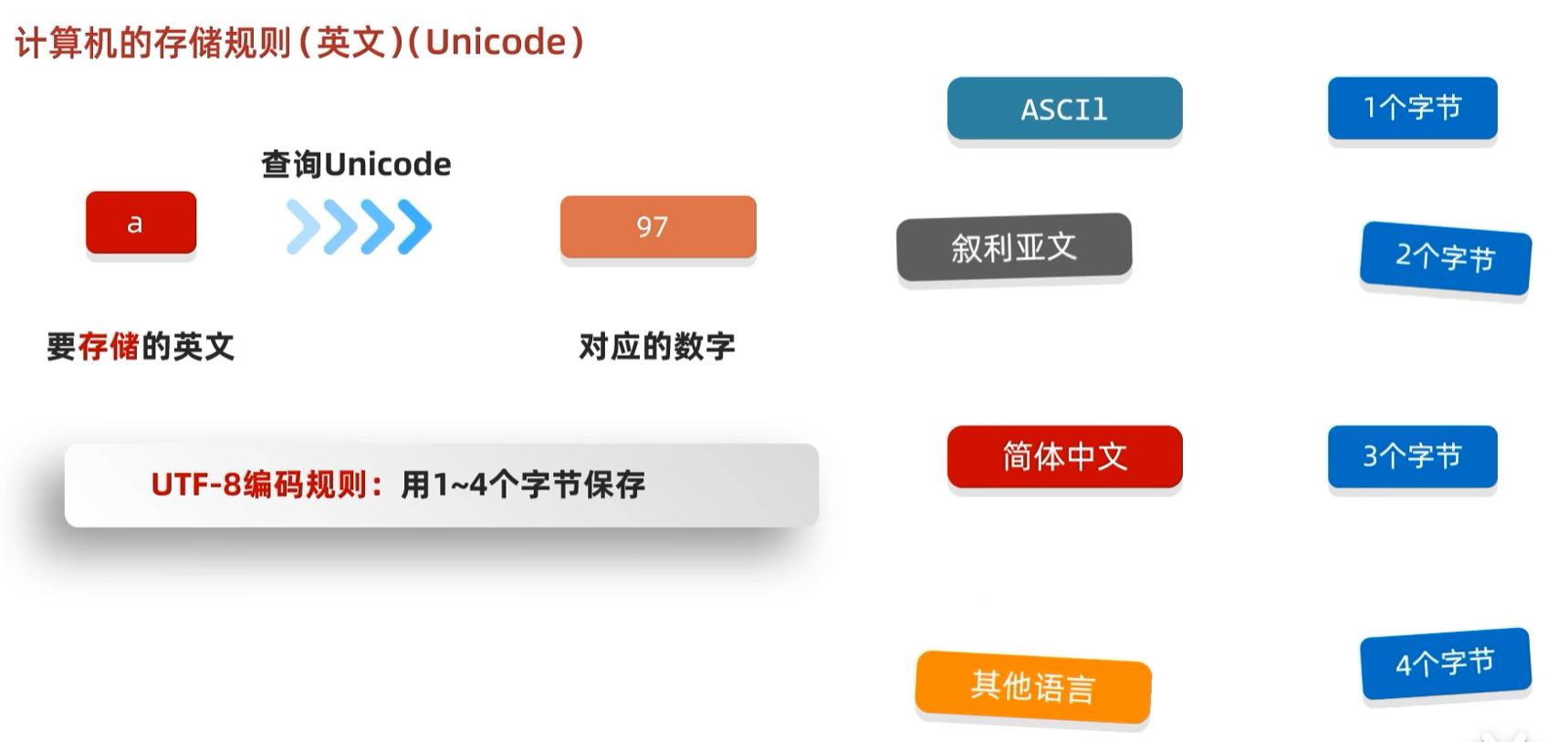
不管是一个字母还是别的字符,UTF-16统一用16个bit,而UTF-32是用32个bit。这在某些字符的存储上十分浪费空间。

后来出现的UTF-8就采用了分门处理的方式进行了优化。



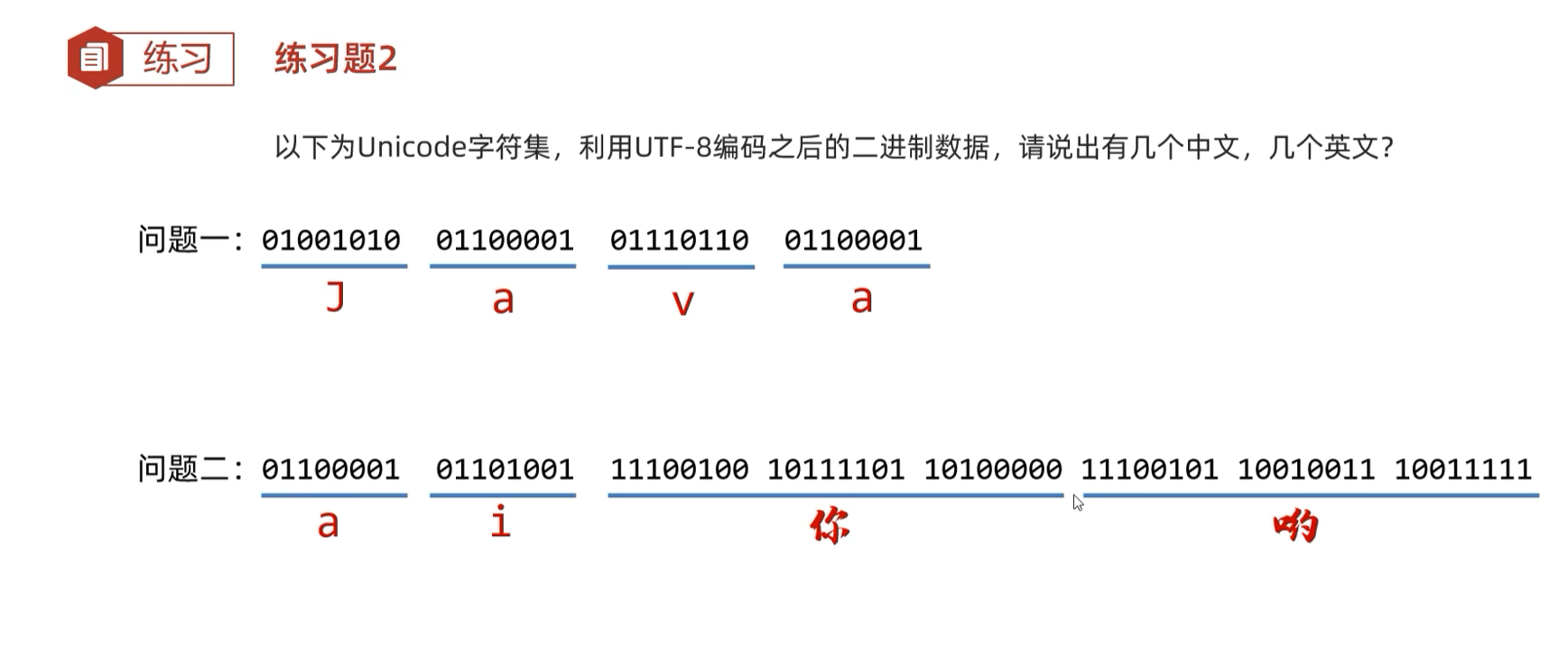
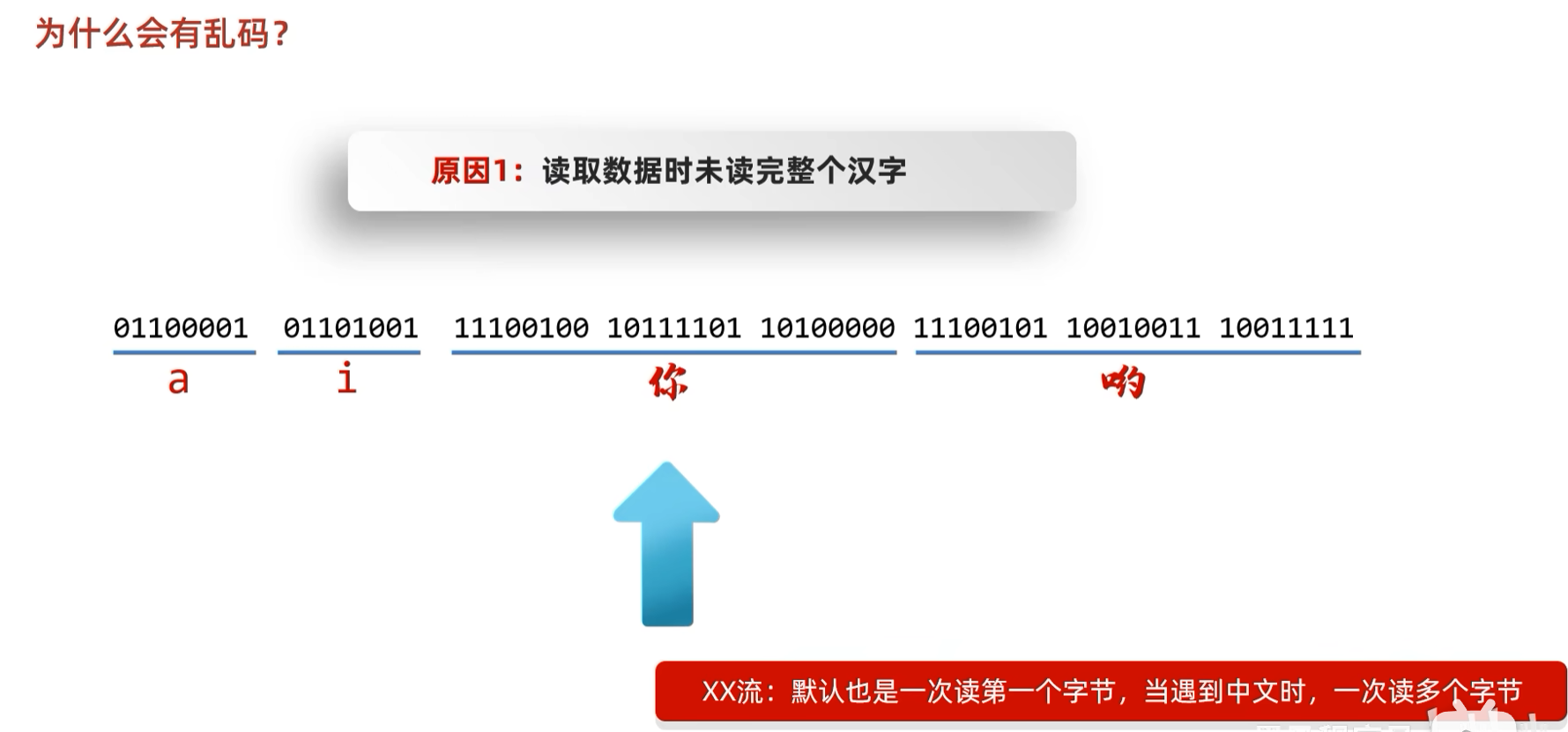
1.2.1 为什么会有乱码?
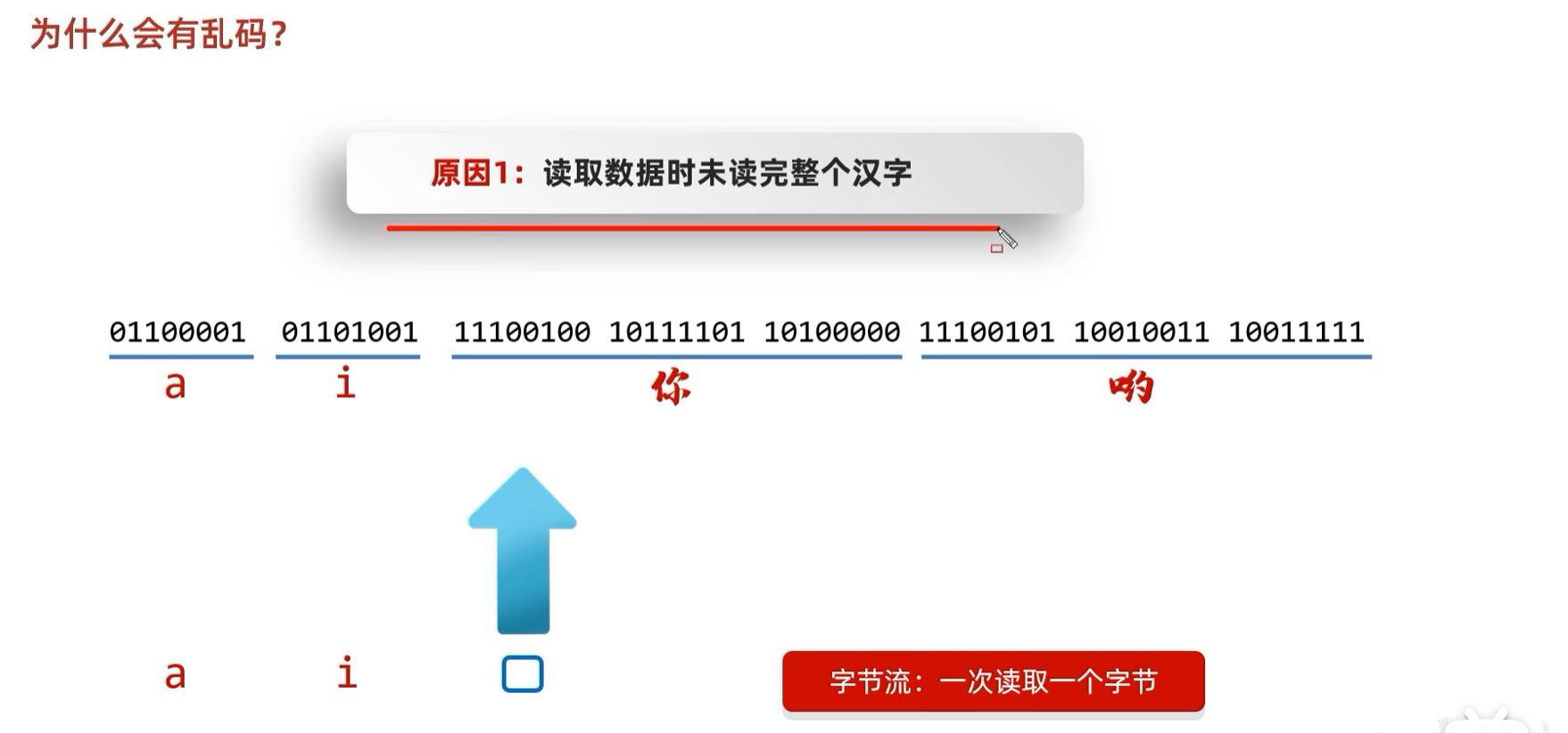
只读取了片段,解码成不符合字符集规则的数据出现乱码。
原因二:编码和解码的方式不一致。
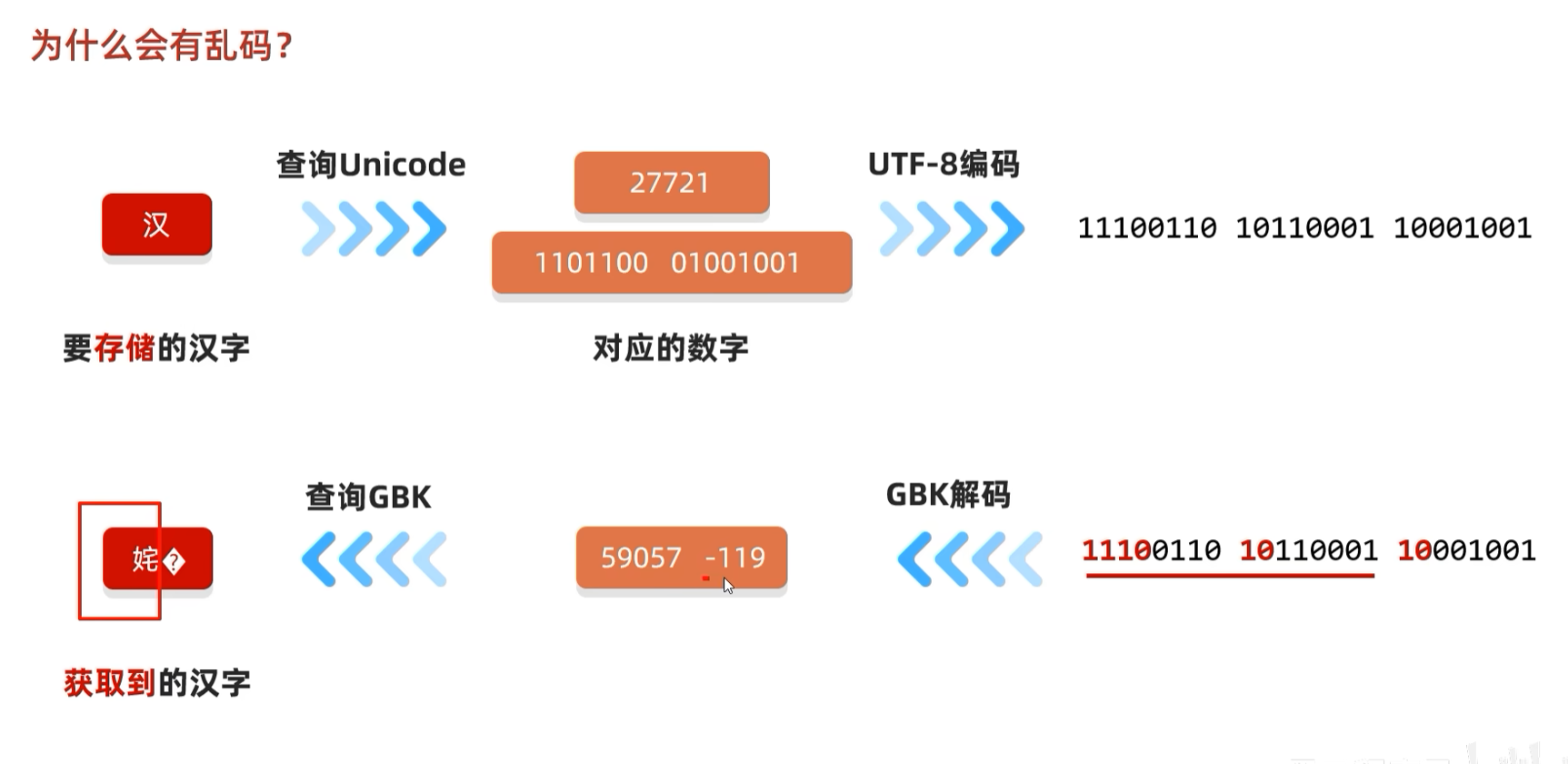

因为拷贝的时候,数据源的数据没有丢失,拷贝的一样,而且目的地编码方式跟数据源保持一致就不会出现乱码。

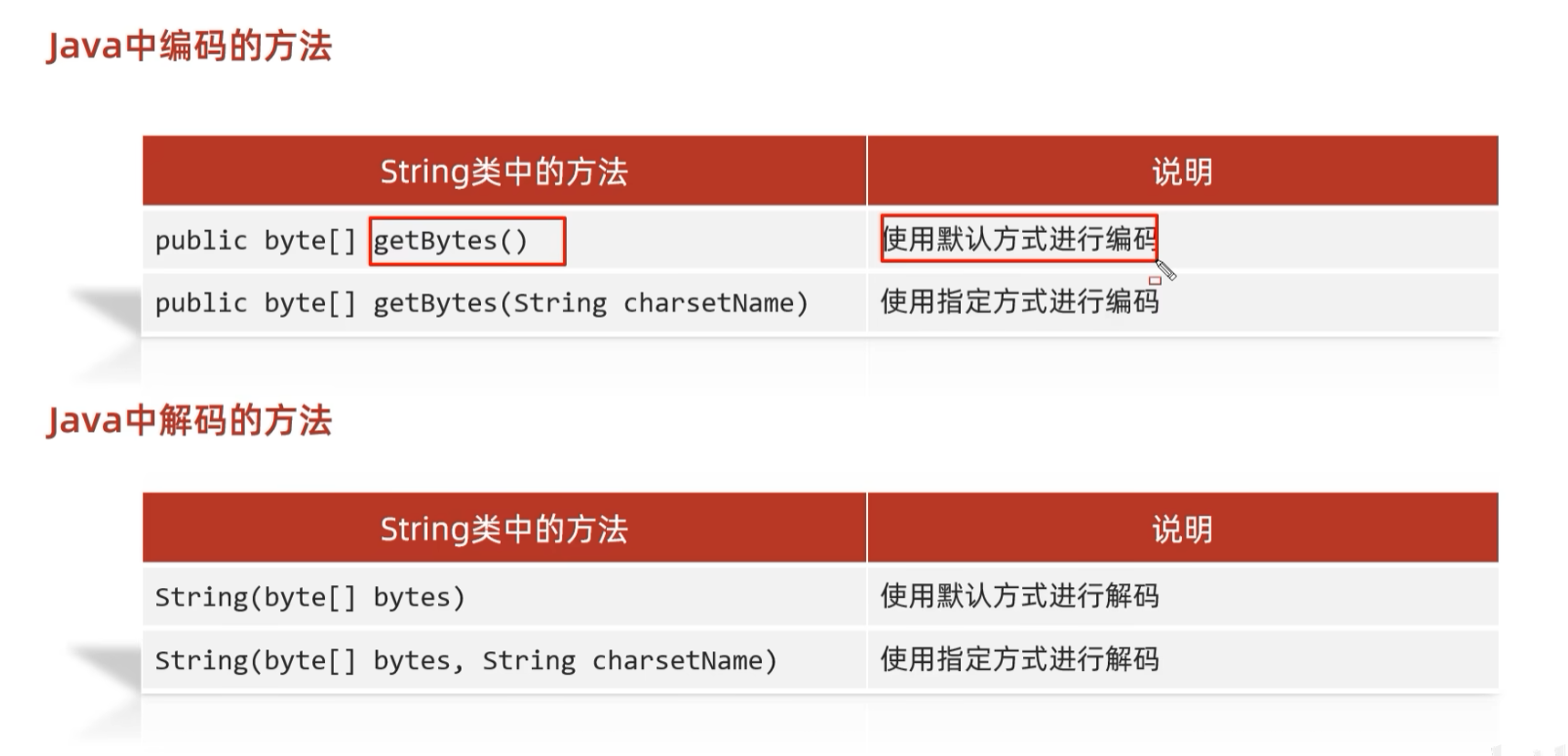
1.3.1 Java中编码和解码的代码实现
java
package com.lkbhua.IO;
import java.io.UnsupportedEncodingException;
import java.nio.charset.Charset;
import java.util.Arrays;
public class demo {
public static void main(String[] args) throws UnsupportedEncodingException {
/* Java中编码的方式:
public byte[] getBytes() 使用默认方式进行编码
public byte[] getBytes(String charsetName) 使用指定方式进行编码
Java中解码的方式:
String(byte[] bytes) 使用默认方式进行解码
String(byte[] bytes, String charsetName) 使用指定方式进行解码
*/
// 1、编码
String str = "Ai中国";
byte[] bytes = str.getBytes(); // GBK E: 1 C: 2
System.out.println(Arrays.toString(bytes));
// [65, 105, -42, -48, -71, -6]
// 2、指定编码
byte[] bytes1 = str.getBytes("UTF-8");
System.out.println(Arrays.toString(bytes1));
// [65, 105, -28, -72, -83, -27, -101, -67]
// 3、解码
String str1 = new String(bytes);
System.out.println(str1);
// Ai中国
// 4、指定解码
String str2 = new String(bytes1, "UTF-8");
System.out.println(str2);
// Ai中国
}
}1.2 字符流
对于原因二:编码和解码方式不统一的情况我们可以通过统一编码方式进行很好的解决。但是原因一怎么解决呢?字符流可以很好的解决。

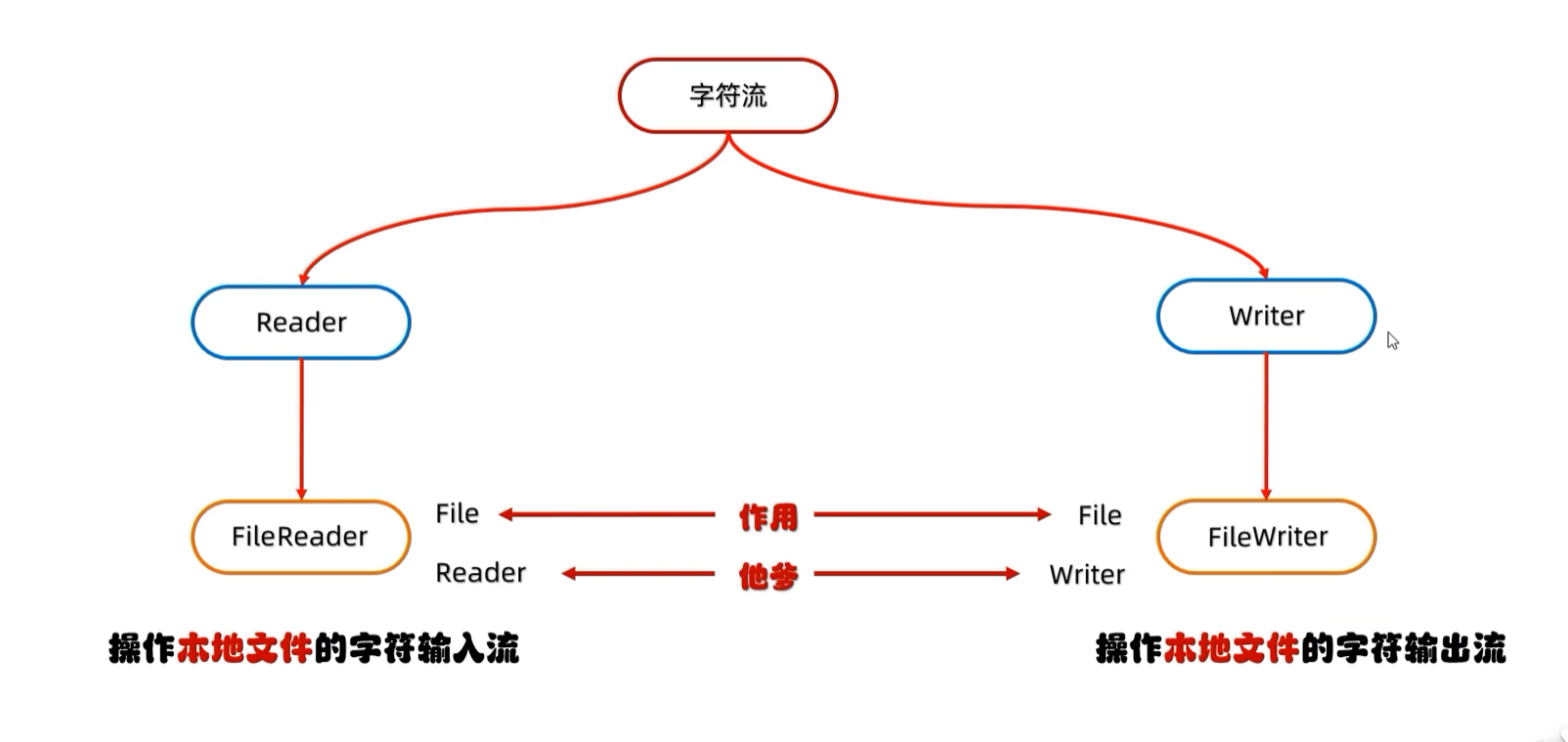
1.2.1 FileReader字符输入流



空参的read()方法:
java
package com.lkbhua.IO.FileReaderDemo;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class demo1 {
public static void main(String[] args) throws IOException {
/*
第一步: 创建对象
public FileReader(File file) 创建字符输入流关联本地文件
public FileReader(String fileName) 创建字符输入流关联本地文件
第二步: 读取数据
public int read() 读取数据,读到末尾返回-1
public int read(char[] cbuf) 读取多个数据,读到末尾返回-1
第三步: 释放资源
public void close() 释放资源
*/
// 1、创建对象并关联本地文件
FileReader fr = new FileReader("lkb04-File&IOCode\\a.txt");
// 2、读取数据 read()
// 细节1: 默认是一个字节一个字节读取,如果遇见中文就会读取多个(GBK:2,UTF-8:3)
// 细节2: 在读取之后,方法底层还会解码转成十进制。
// 最终将这个十进制作为返回值
// 这个十进制的数据也表示在字符集上的数字
// 比如是English: 0110 0001
// read方法读取进行解码: 97
// 比如是Chinese: 1100 1001 1000 1001
// read方法读取进行解码: 20989
int ch;
while((ch = fr.read()) != -1){
System.out.print((char)ch);
}
// 3、释放资源
fr.close();
}
}带参的read()方法:
java
package com.lkbhua.IO.FileReaderDemo;
import java.io.FileReader;
import java.io.IOException;
public class demo2 {
public static void main(String[] args) throws IOException {
/*
第一步: 创建对象
public FileReader(File file) 创建字符输入流关联本地文件
public FileReader(String fileName) 创建字符输入流关联本地文件
第二步: 读取数据
public int read() 读取数据,读到末尾返回-1
public int read(char[] cbuf) 读取多个数据,读到末尾返回-1
第三步: 释放资源
public void close() 释放资源
*/
// 1、创建对象
FileReader fr = new FileReader("lkb04-File&IOCode\\a.txt");
// 2、读取数据
// read(chars): 读取数据、解码、强壮三步合并了,把强转之后的字符放到数组当中
// 空参的read + 强转类型转换
char[] chars = new char[2];
int len;
while ((len = fr.read(chars)) != -1){
// 把数据中的字符串进行打印
System.out.print(new String(chars, 0, len));
}
// 3、释放资源
fr.close();
}
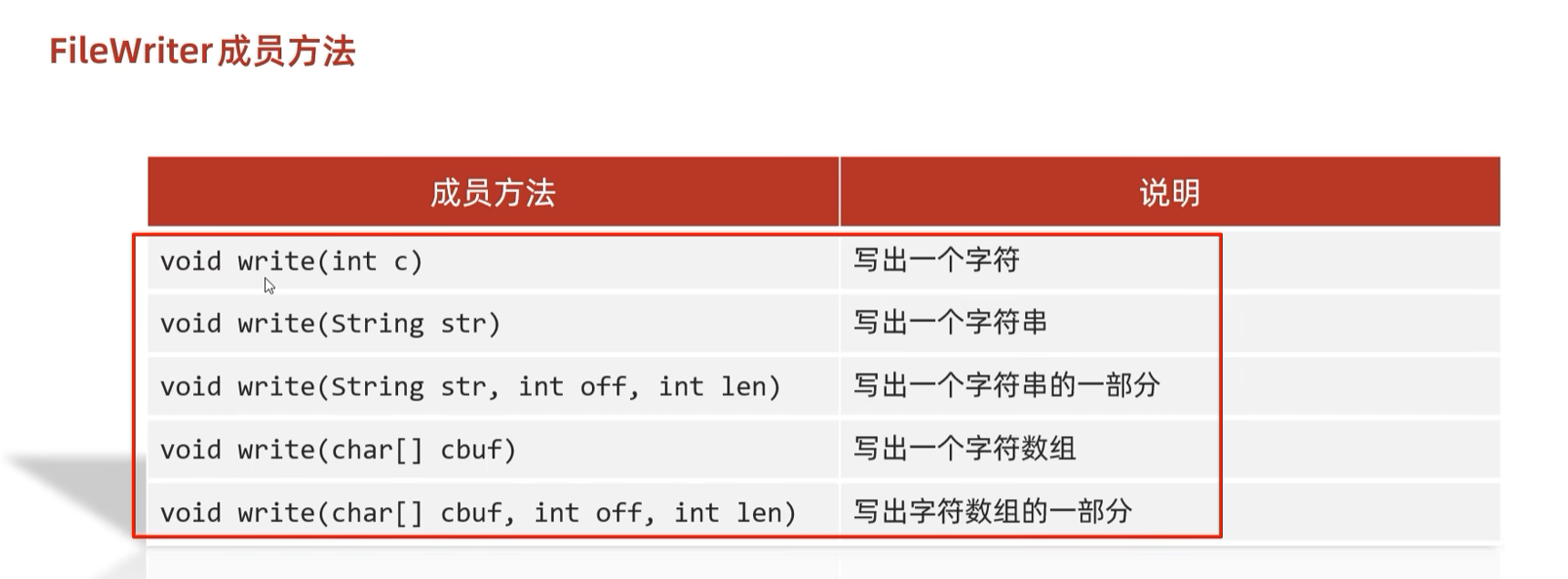
}1.2.2 FileWrtie字符输出流