VLA技术调研及学习
从一篇综述开始
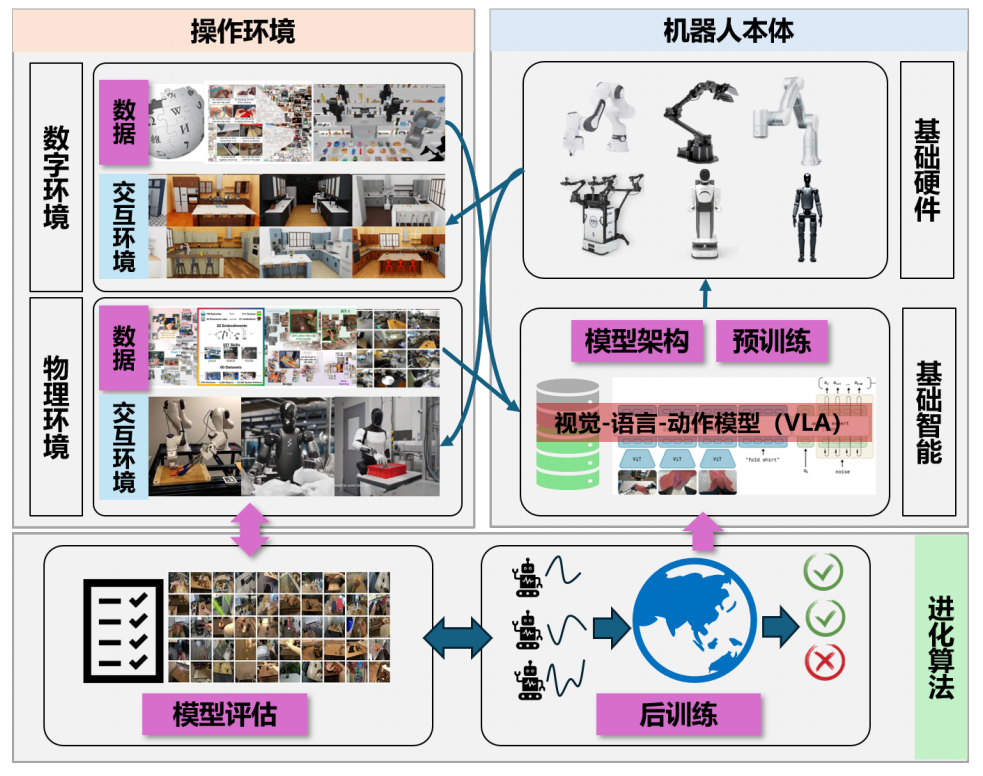
一、核心背景与 VLA 模型定位
具身智能强调智能体通过与物理环境交互实现学习,机器人操作是其典型应用场景。
传统机器人系统采用模块化设计,各模块独立工作,难以应对开放环境的多样化任务需求。
VLA 模型受大模型启发,将视觉、语言、动作深度融合,实现 "环境理解 - 物理执行" 的闭环,成为具身操作的核心基础智能。
二、VLA 模型发展历程
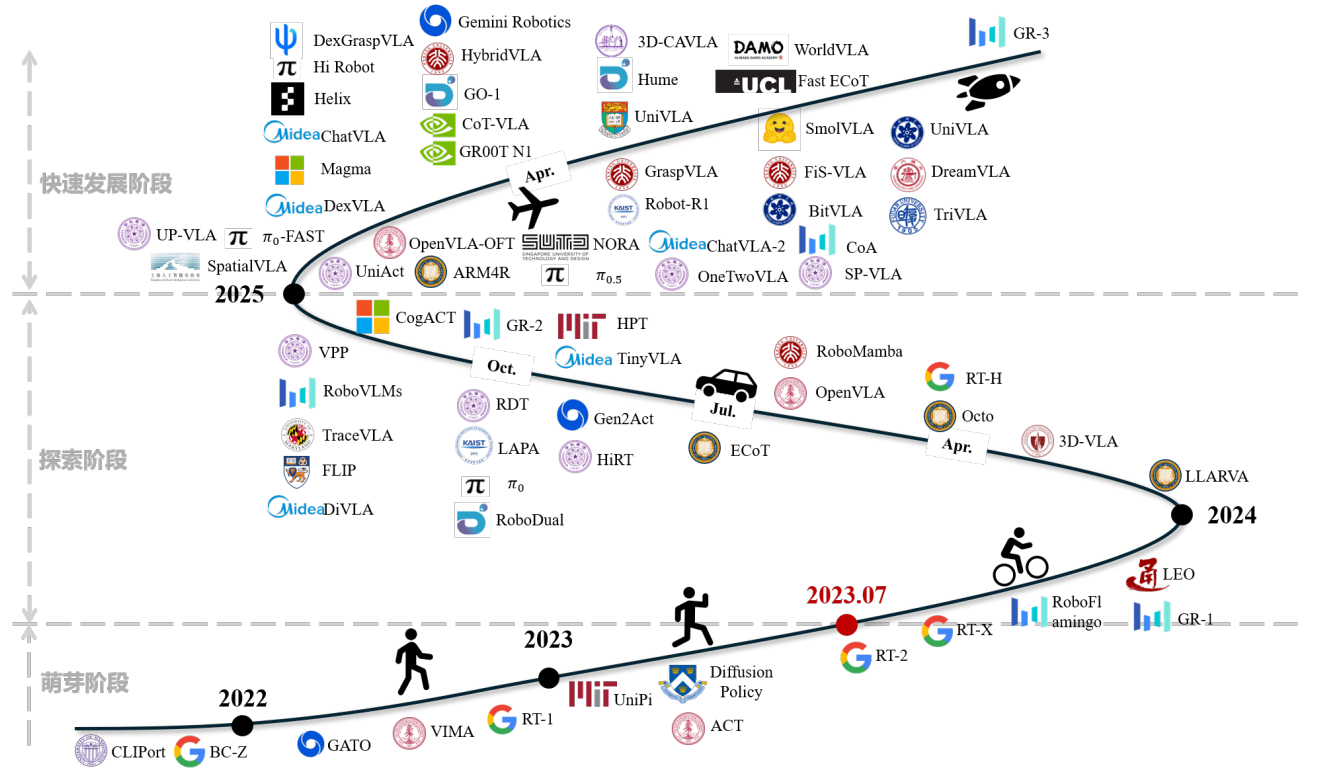
- 萌芽阶段:未明确 VLA 概念,通过语言辅助视觉模仿学习实现多任务操作,如 CLIPort 框架,但存 在泛化能力弱、网络容量有限等问题。
- 探索阶段:2023 年 7 月 VLA 概念正式提出,RT-2 等模型亮相,Transformer 成为骨干架构主流,OXE 等大规模数据集出现,同时开始探索继承 LLM/VLM 权重以提升泛化能力。
- 快速发展阶段:2024 年底至今,分层架构成为热点(如双层、三层系统),聚焦泛化能力提升,同时探索多模态数据融合、模型推理效率优化等方向。
三、VLA 模型核心技术模块
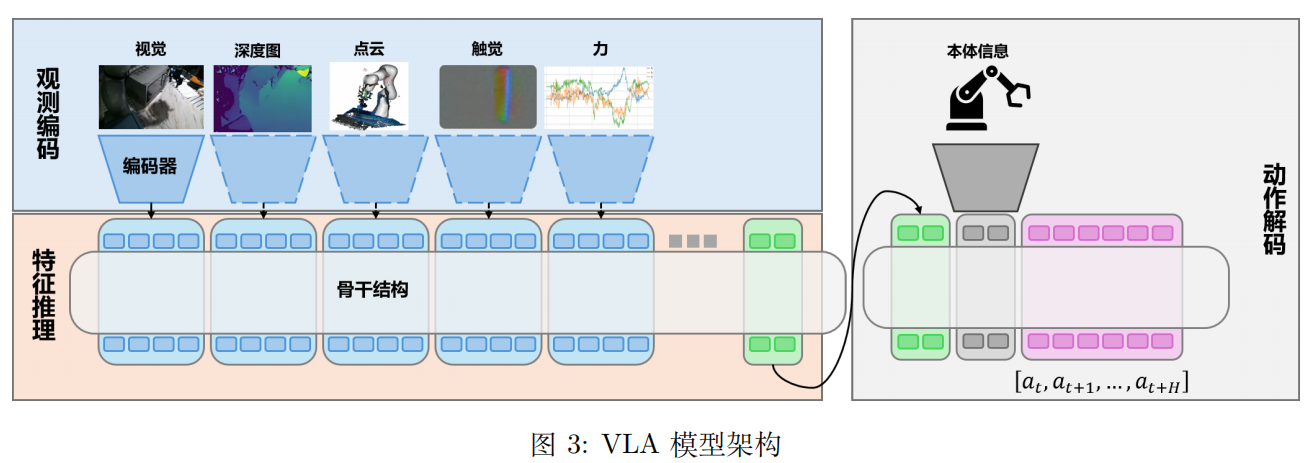
3.1 模型架构
基础结构分为观测编码、特征推理、动作解码三部分:观测编码将多模态输入(视觉、语言、触觉等)转化为特征令牌;特征推理通过 Transformer、DiT、MoE 等骨干网络建模依赖关系;动作解码输出离散或连续动作。
分层系统:拆解长时域任务理解与短时域动作生成,通过文本语言、动作轨迹、隐特征向量实现层间通信,平衡泛化性与实时性。
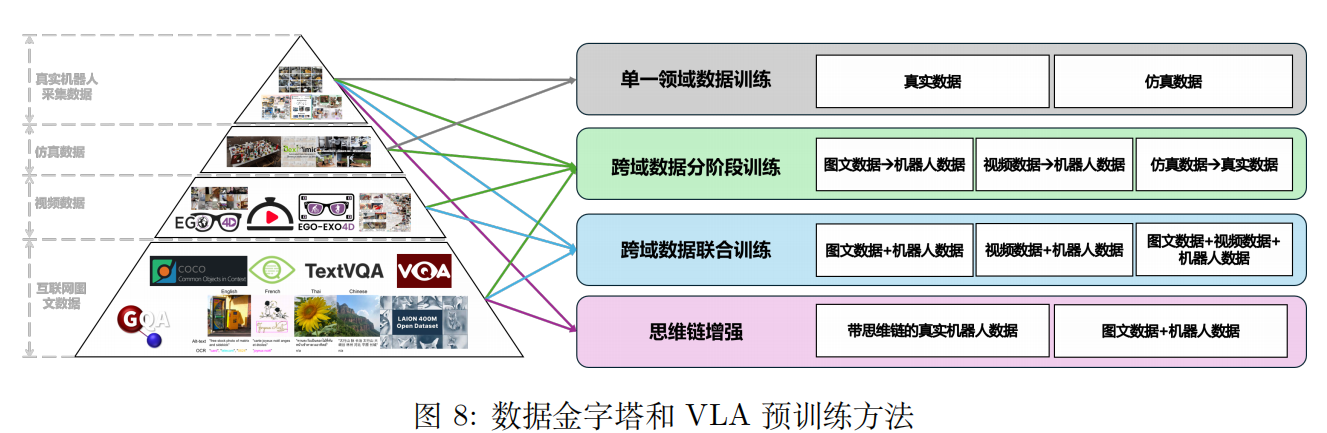
3.2 训练数据
数据类型包括互联网图文数据(如 COCO)、视频数据(如 Ego-4D)、仿真数据(如 RoboCasa)、真实机器人采集数据(如 DROID),构成 "数据金字塔"。
核心挑战:机器人轨迹数据规模与多样性不足,多模态数据融合难度大,仿真与真实环境数据存在分布差异。
3.3 训练方法
预训练方法:分为单一领域数据训练、跨域数据分阶段训练、跨域数据联合训练、思维链增强四类,其中跨域联合训练和思维链增强是提升泛化能力的关键方向。
后训练方法:包括监督微调(主流手段)、强化微调(潜力方向)、推理扩展(无需额外数据),核心目标是适配具体机器人与任务场景。
3.4 模型评估
评估方式分为真实环境评估(反映实际性能,成本高)、仿真器评估(可复现性强,如 LIBERO、SimplerEnv)、世界模型评估(新兴方向,依赖视频生成能力)。
评估核心指标包括任务成功率(分布内 / 分布外)、泛化能力、实时性等。
四、面临的挑战与未来方向
4.1 核心挑战
泛化能力不足:对视觉变化、机器人形态、跨任务场景的适应性有限。
精细操作性能差:依赖高质量遥操作数据,且缺乏力 / 触觉等多模态信息支撑。
实时推理难度大:模型参数量大,机器人端计算资源有限,难以满足动态环境响应需求。
4.2 未来趋势
模型架构:优化分层设计,探索多模态信息融合方案,提升跨形态泛化能力。
数据利用:扩大真实场景数据规模,优化仿真 - 真实数据迁移,完善多模态数据标准化。
训练优化:改进强化学习的奖励函数设计与样本效率,深化思维链与动作生成的耦合。
部署落地:探索 "端 - 云" 协同部署模式,优化模型精简与量化技术。
有关VLA的一些简单应用
为什么要了解VLA?
简单来说就是VLA是一套结合大模型的新技术,可以用它来做控制系统,值得去了解和学习。
但是呢,VLA的学习和了解涉及到大量的知识,深入学习和了解付出成本巨大,且VLA本身只是个概念,而且VLA的好坏完全取决于视频-语言模型的好坏,其次才是后面的动作控制。
所以呢,了解这个一方面是为了看一下本地部署的成熟方案是否合适一些项目的需求,另一方面是为了看一下VLA相关的一些简单应用有哪些,能不能本地部署看一下效果。
VLA与自动驾驶
自动驾驶系统的两个方向:
1.端到端模型 ,输入是摄像头、激光雷达、位置、车辆位置、导航等各种信息,输出是车辆的行驶轨迹
缺点:训练数据不足会导致一些极端情况或者偶尔前面有个人或者自行车经过,这个系统就会犯傻。
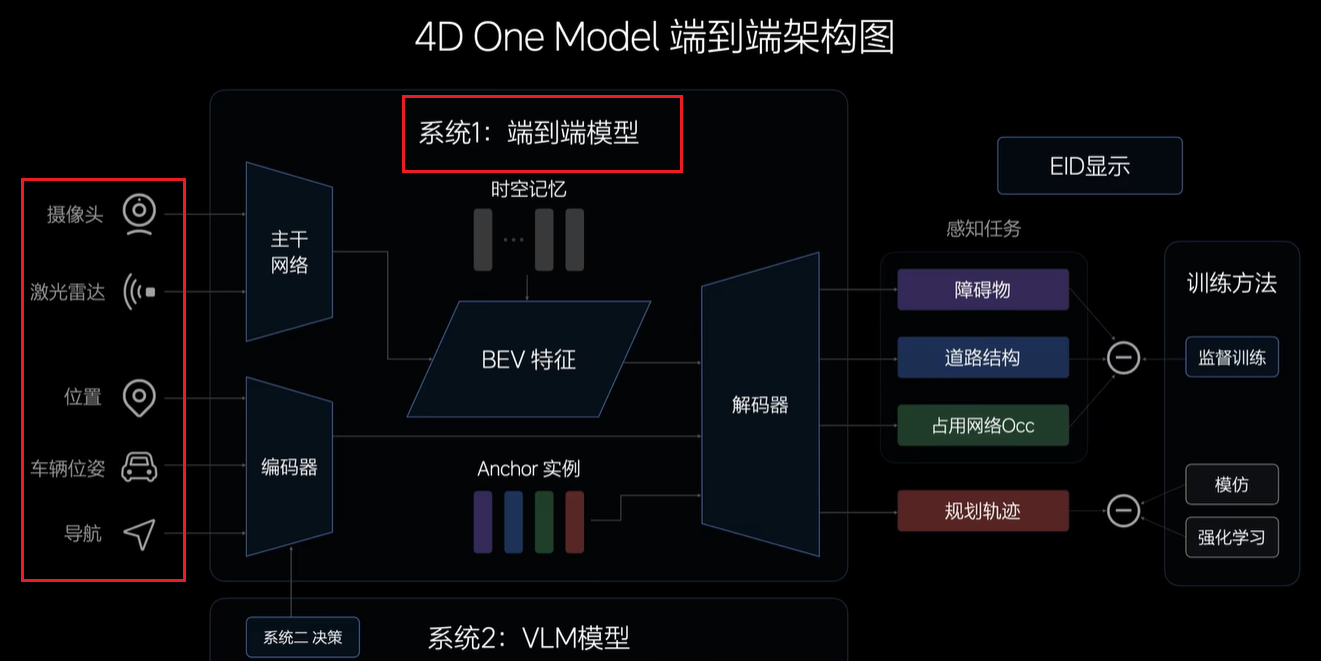
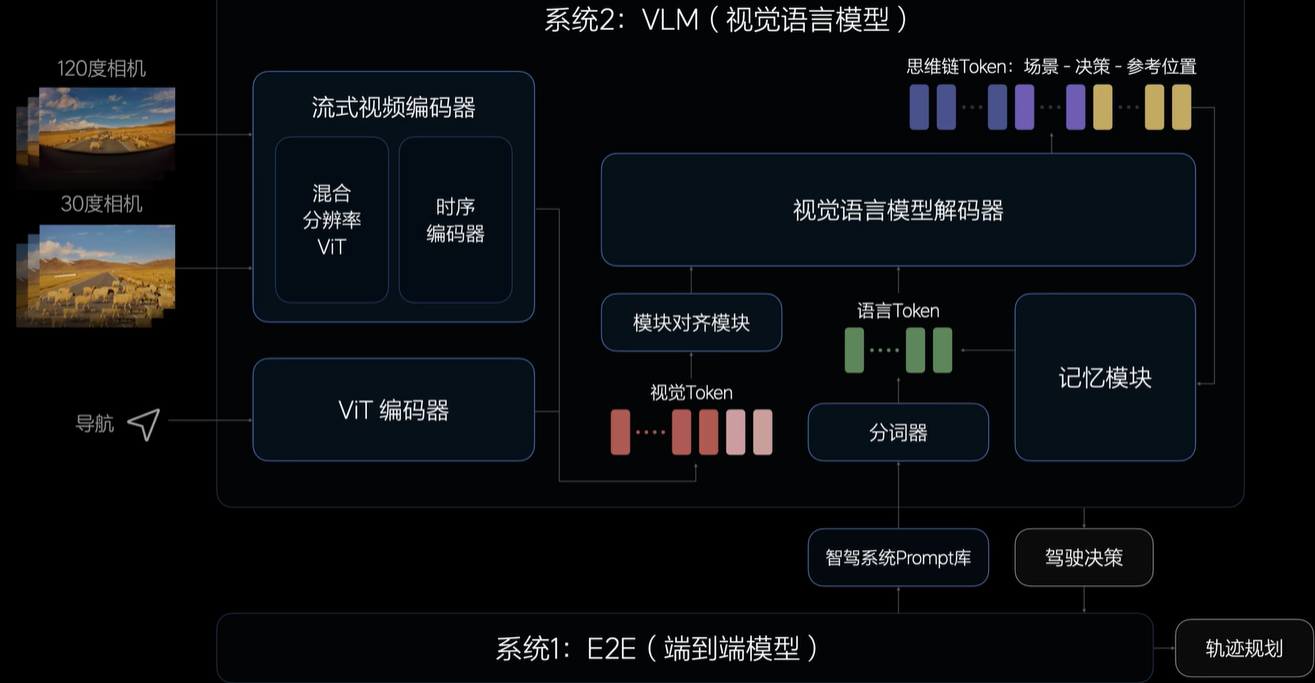
2.VLA
VLM(视觉语言模型)
VLA Vision Language-Action 视觉语言动作模型
缺点:同样十分明显,本地部署算力不足以支撑大语言模型,短时间内反应不足。
世界模型:World-Action-Model
端到端模型的延伸

VLA技术调研
作者的个人观点如下:

VLA视觉语言模型的精度有多大?精确到像素级别还是?
VLA对于特定场景的话需要微调模型,如何微调?
VLA模型的输入是视频或者图像,那么输出是文字?
Qwen3-VL
视频:视觉能力倍增!Qwen3-VL史诗级更新!
https://github.com/QwenLM/Qwen3-VL
VLM模型能力强大,尤其是对一些图片的理解,但对于一些特殊的场景,可能是没有对应场景数据的训练,所以实现的效果还是有所偏差。
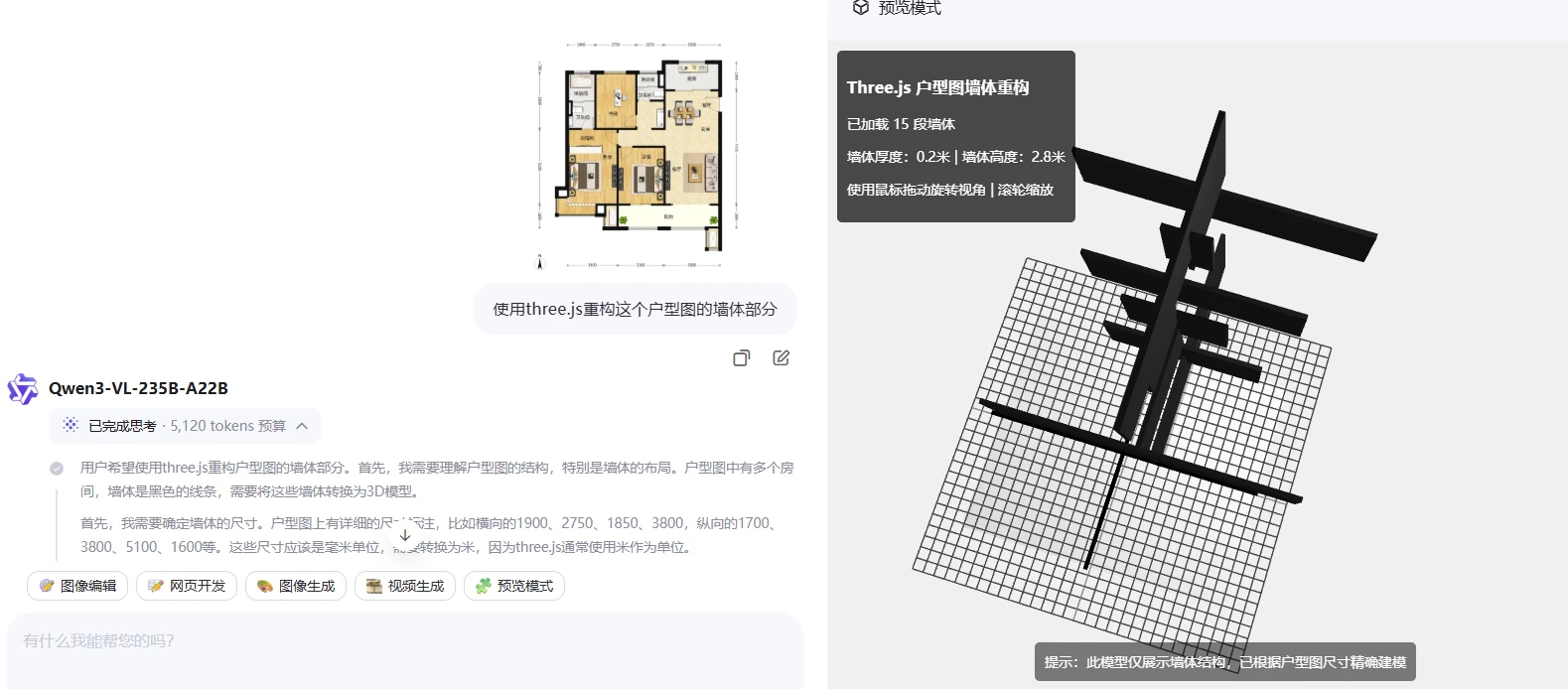
关于微调,关于实时性,关于本地部署
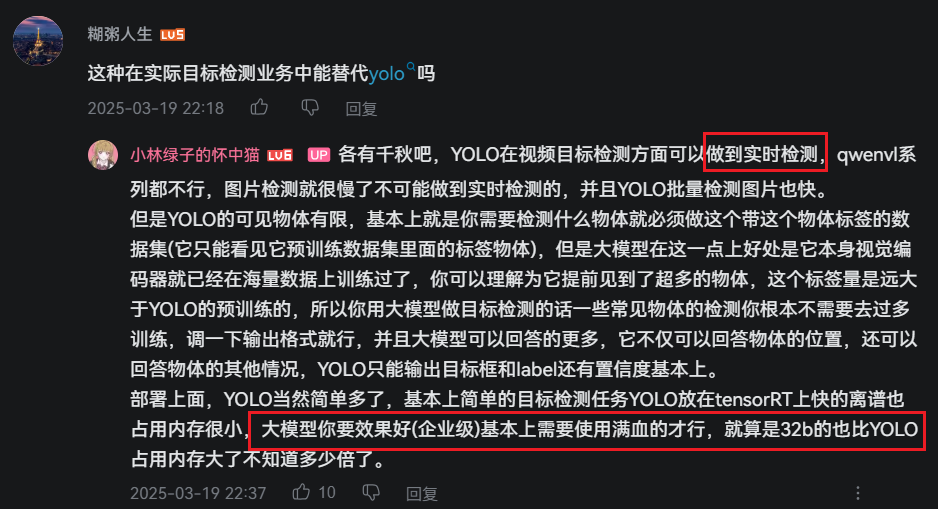
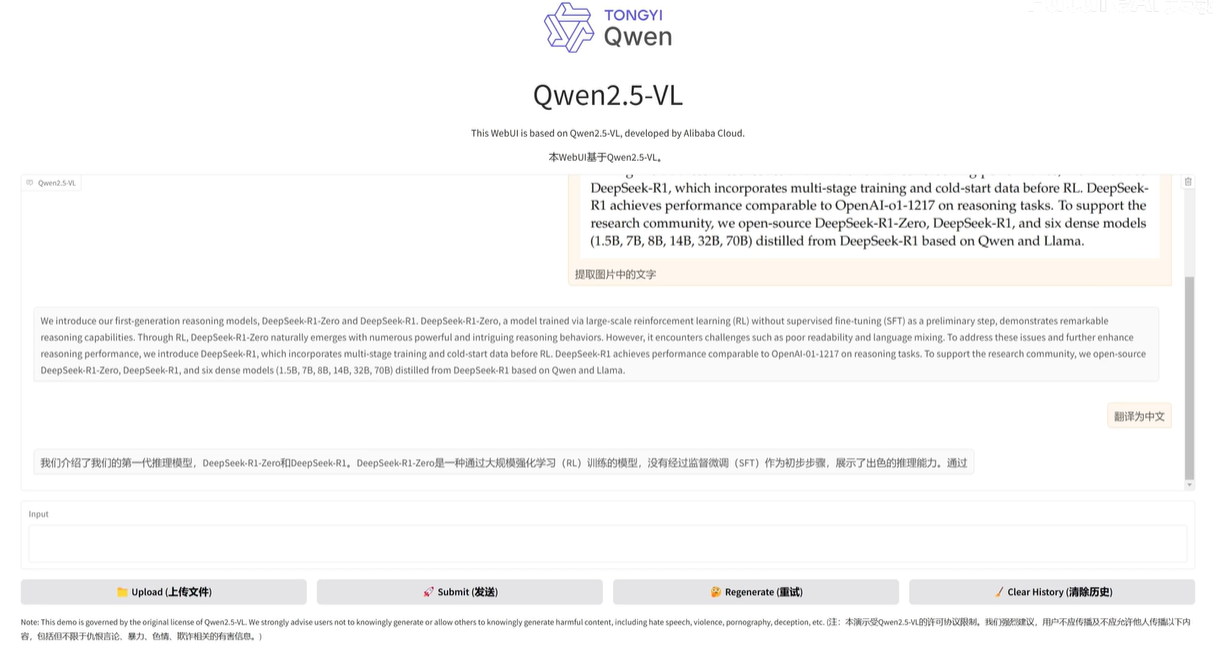
结论:微调也很麻烦,也有很多限制。

没有实时的图像输入,只能支持图片+语言然后得到的也是图片+语言。
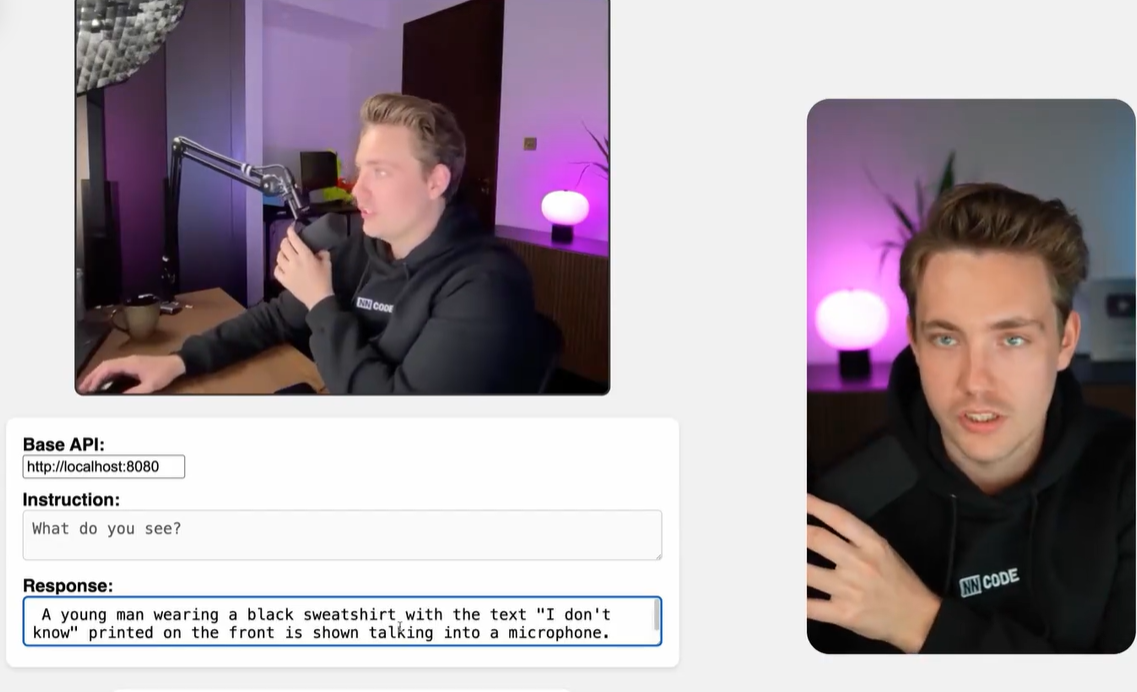
VLM貌似就是语言+图片然后输出语言描述,本质上就是改变了大模型的输入。我看这个视频里的实时性还好,能达到40ms?不过这种模型最好还是远程部署在服务器上比较合适,不适合本地部署,算力太低。
结论
- VLA本质上还是大语言模型,Language,本地部署依赖强大的算力,小算力只能得到一个阉割版的智能。
- 基于目前的项目需求来说,VLA的本地部署不太现实,做不到实时的推理,更何况还得进一步微调,对于小公司来说也不实用。
后记:如有侵权,请后台私信联系我,我会第一时间删除相关信息。