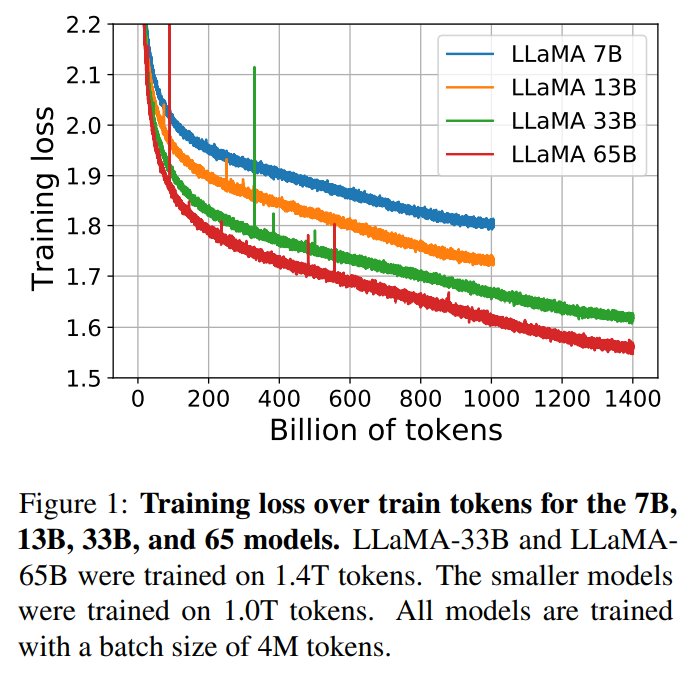
This paper is inspired by the Chinchilla scaling law. It found that given a fixed computing budget, the best performance is not generated by the larger models, but by the smaller models trained on more data . So it proposed a collection of models ranging from 7B to 65B. These smaller models outperforms other bigger models.
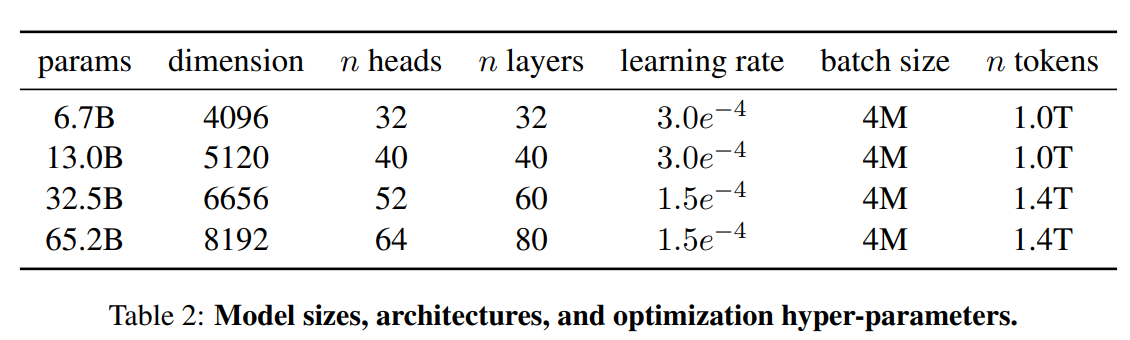
1. Architecture
It based on traditional transformer models, and leveraged some improvement proposed in the subquently large language models. The main change point is:
- Pre-normalization, which nomalized the input in the sub-layer, instead of the output.
- SwiGelu, instead of Relu.
- Rotary Embeddidngs.
2. Efficient Implementation
- The casual multihead attention. Which need me to explore the behind logic further.
- Reduce the amount of activations that are recomputed during the backward pass.
- Save the activation by manually implementing it, instead of using PyTorch Autograd in backward pass.
- Using model and sequence parallelism to reduce the memory usage.
- Using the overlay the computing and comunication bewteen different GPUs as much as possible.