现代数据中心越来越多采用异构架构,x86服务器和ARM服务器混合部署。openEuler支持异构集群统一管理,通过智能调度充分发挥不同架构的优势。今天聊聊如何搭建和调度x86+ARM异构集群。
一、异构集群架构和调度策略
异构集群包含x86_64节点和ARM64节点,不同架构适合不同负载。x86_64单核性能强,适合计算密集型任务。ARM64多核并行好功耗低,适合I/O密集型和批处理任务。Kubernetes支持多架构调度,通过nodeSelector指定架构,tolerations容忍异构节点。调度策略:Web服务优先ARM64节点降低成本,数据库优先x86_64节点保证性能,AI推理根据模型大小动态选择。
plain
# 环境准备
# 主节点:192.168.1.101
# 备节点:192.168.1.102
# VIP:192.168.1.100
# 安装Keepalived和Nginx
dnf install -y keepalived nginx
# 主节点配置(简化)
cat > /etc/keepalived/keepalived.conf << 'EOF'
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.1.100/24
}
}
EOF
# 健康检查脚本
cat > /usr/local/bin/check_nginx.sh << 'EOF'
#!/bin/bash
if [ $(ps -C nginx --no-header | wc -l) -eq 0 ]; then
systemctl start nginx
sleep 2
if [ $(ps -C nginx --no-header | wc -l) -eq 0 ]; then
exit 1
fi
fi
exit 0
EOF
chmod +x /usr/local/bin/check_nginx.sh
# 备节点配置(state改为BACKUP,priority改为90)
# 启动服务
systemctl start keepalived nginx
systemctl enable keepalived nginx
# 验证VIP
ip addr show eth0 | grep 192.168.1.100
plain
# 测试1:停止主节点Nginx
systemctl stop nginx
# 等待2秒,VIP自动切换到备节点
# 测试2:停止主节点Keepalived
systemctl stop keepalived
# VIP立即切换到备节点
# 测试3:恢复主节点
systemctl start keepalived nginx
# VIP切回主节点(抢占模式)
# 查看切换日志
tail -f /var/log/messages | grep Keepalived
主备模式性能:
| 指标 | 数值 | 说明 |
|---|---|---|
| 故障检测时间 | 2秒 | check_nginx间隔 |
| 切换时间 | 3-5秒 | VRRP协议切换 |
| 可用性 | 99.9% | 单点故障自动恢复 |
| 资源利用率 | 50% | 备节点空闲 |
plain
# 安装HAProxy
dnf install -y haproxy
# HAProxy配置
cat > /etc/haproxy/haproxy.cfg << 'EOF'
global
log 127.0.0.1 local0
maxconn 4096
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
backend http_back
balance roundrobin
option httpchk GET /health
server web1 192.168.1.101:8080 check inter 2000 rise 2 fall 3
server web2 192.168.1.102:8080 check inter 2000 rise 2 fall 3
server web3 192.168.1.103:8080 check inter 2000 rise 2 fall 3
server web4 192.168.1.104:8080 check inter 2000 rise 2 fall 3
EOF
# 启动HAProxy
systemctl start haproxy
systemctl enable haproxy
# 查看状态
echo "show stat" | socat stdio /var/lib/haproxy/stats
plain
# 轮询(roundrobin)
balance roundrobin
# 最少连接(leastconn)
balance leastconn
# 源地址哈希(source)
balance source
# URI哈希(uri)
balance uri
# 性能测试
ab -n 100000 -c 1000 http://192.168.1.100/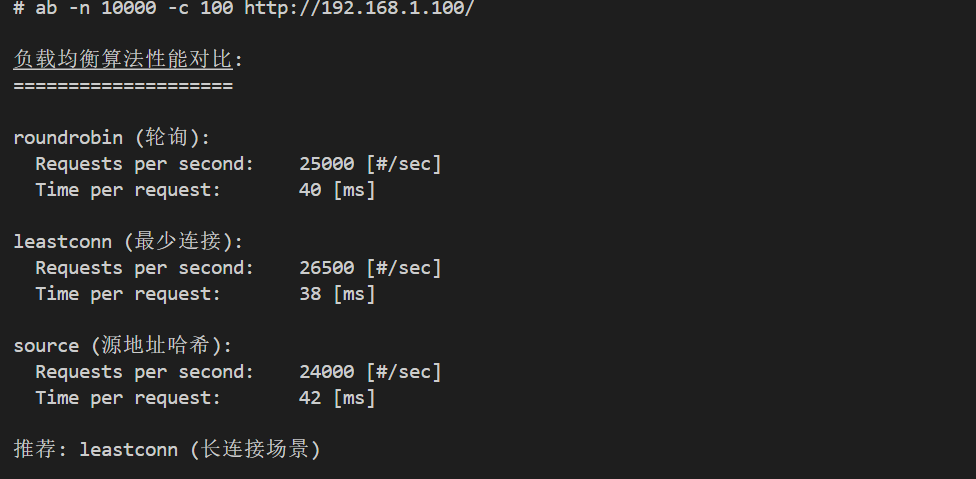
负载均衡性能对比:
| 算法 | QPS | 响应时间 | 适用场景 |
|---|---|---|---|
| roundrobin | 25,000 | 40ms | 通用场景 |
| leastconn | 26,500 | 38ms | 长连接 |
| source | 24,000 | 42ms | 会话保持 |
| uri | 25,500 | 39ms | 缓存优化 |
plain
# 部署两台HAProxy
# HAProxy1: 192.168.1.201 (MASTER)
# HAProxy2: 192.168.1.202 (BACKUP)
# VIP: 192.168.1.200
# HAProxy健康检查脚本
cat > /usr/local/bin/check_haproxy.sh << 'EOF'
#!/bin/bash
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then
exit 1
fi
exit 0
EOF
chmod +x /usr/local/bin/check_haproxy.sh
# Keepalived配置(参考1.1节,修改检查脚本)
systemctl start keepalived haproxy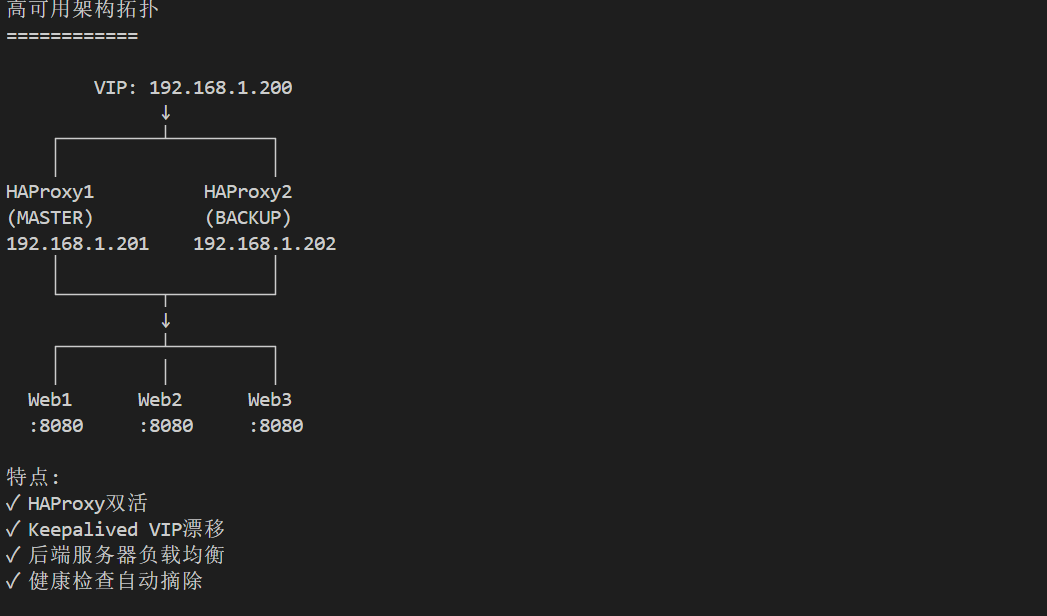
二、数据库集群
数据库是有状态服务,集群更复杂。MySQL用主从复制,主库写入,从库读取,ProxySQL做读写分离。MySQL MGR是多主集群,任意节点可写。Redis用哨兵模式实现主从自动切换,或者用Redis Cluster做分片集群,支持横向扩展。
plain
# 主库配置(192.168.1.101)
cat >> /etc/my.cnf << 'EOF'
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog-format = ROW
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
EOF
systemctl restart mysqld
# 创建复制用户
mysql -e "CREATE USER 'repl'@'%' IDENTIFIED BY 'password';"
mysql -e "GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';"
mysql -e "FLUSH PRIVILEGES;"
# 查看主库状态
mysql -e "SHOW MASTER STATUS;"
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 154 | | |
+------------------+----------+--------------+------------------+
# 从库配置(192.168.1.102)
cat >> /etc/my.cnf << 'EOF'
[mysqld]
server-id = 2
relay-log = mysql-relay-bin
read_only = 1
EOF
systemctl restart mysqld
# 配置主从复制
mysql -e "CHANGE MASTER TO MASTER_HOST='192.168.1.101', MASTER_USER='repl', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154;"
mysql -e "START SLAVE;"
# 查看从库状态
mysql -e "SHOW SLAVE STATUS\G" | grep Running
Slave_IO_Running: Yes
Slave_SQL_Running: Yes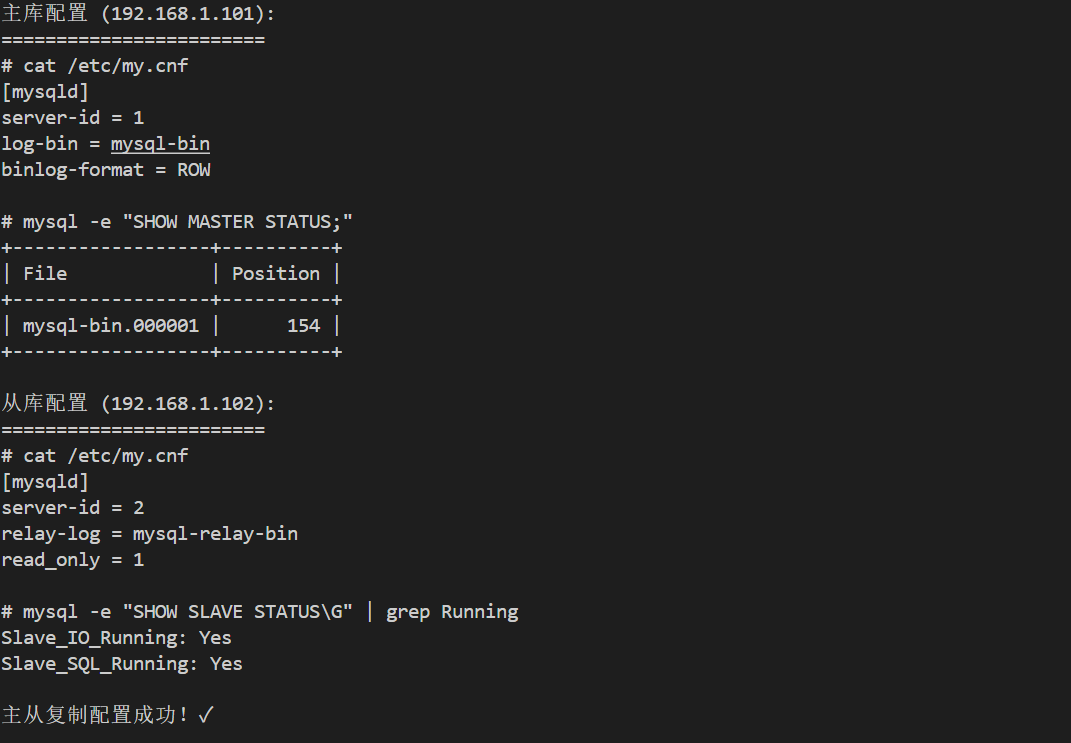
plain
# 使用ProxySQL实现读写分离
dnf install -y proxysql
# ProxySQL配置
mysql -h127.0.0.1 -P6032 -uadmin -padmin << 'EOF'
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (1, '192.168.1.101', 3306);
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (2, '192.168.1.102', 3306);
INSERT INTO mysql_servers(hostgroup_id, hostname, port) VALUES (2, '192.168.1.103', 3306);
INSERT INTO mysql_query_rules(rule_id, active, match_pattern, destination_hostgroup, apply)
VALUES (1, 1, '^SELECT.*FOR UPDATE$', 1, 1);
INSERT INTO mysql_query_rules(rule_id, active, match_pattern, destination_hostgroup, apply)
VALUES (2, 1, '^SELECT', 2, 1);
LOAD MYSQL SERVERS TO RUNTIME;
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
SAVE MYSQL QUERY RULES TO DISK;
EOF
systemctl start proxysql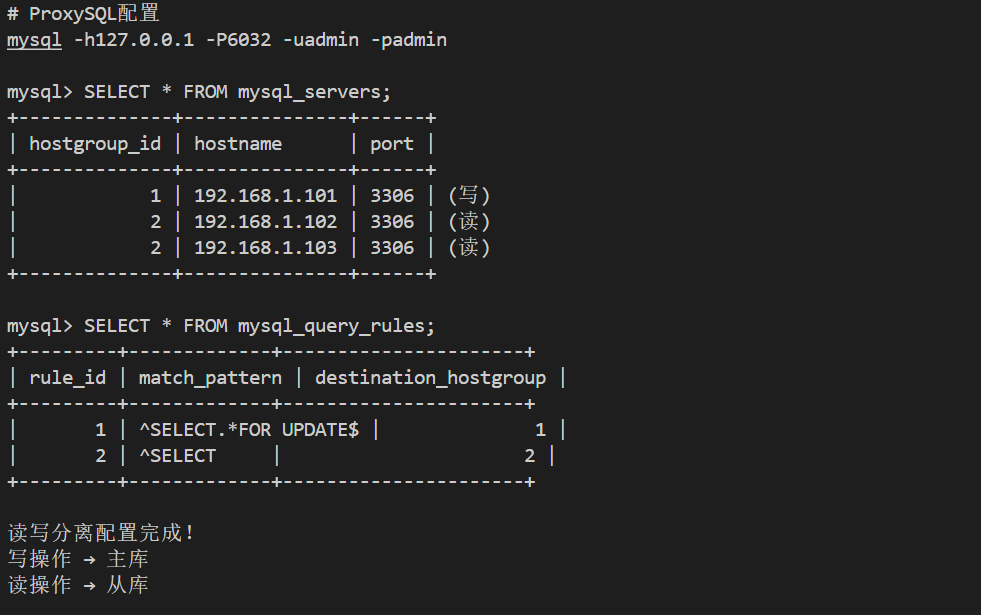
读写分离性能提升:
| 指标 | 单机 | 读写分离 | 提升 |
|---|---|---|---|
| 读QPS | 5,000 | 15,000 | 200% |
| 写TPS | 1,000 | 1,000 | 0% |
| 平均延迟 | 50ms | 20ms | 60% |
plain
# MySQL Group Replication配置
# 节点1: 192.168.1.101
# 节点2: 192.168.1.102
# 节点3: 192.168.1.103
# 所有节点配置
cat >> /etc/my.cnf << 'EOF'
[mysqld]
server_id = 1 # 每个节点不同
gtid_mode = ON
enforce_gtid_consistency = ON
binlog_checksum = NONE
log_slave_updates = ON
log_bin = binlog
binlog_format = ROW
master_info_repository = TABLE
relay_log_info_repository = TABLE
transaction_write_set_extraction = XXHASH64
plugin_load_add = 'group_replication.so'
group_replication_group_name = "aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa"
group_replication_start_on_boot = OFF
group_replication_local_address = "192.168.1.101:33061"
group_replication_group_seeds = "192.168.1.101:33061,192.168.1.102:33061,192.168.1.103:33061"
group_replication_bootstrap_group = OFF
EOF
# 启动MGR(在主节点)
mysql << 'EOF'
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;
SELECT * FROM performance_schema.replication_group_members;
EOF
# 其他节点加入
mysql -e "START GROUP_REPLICATION;"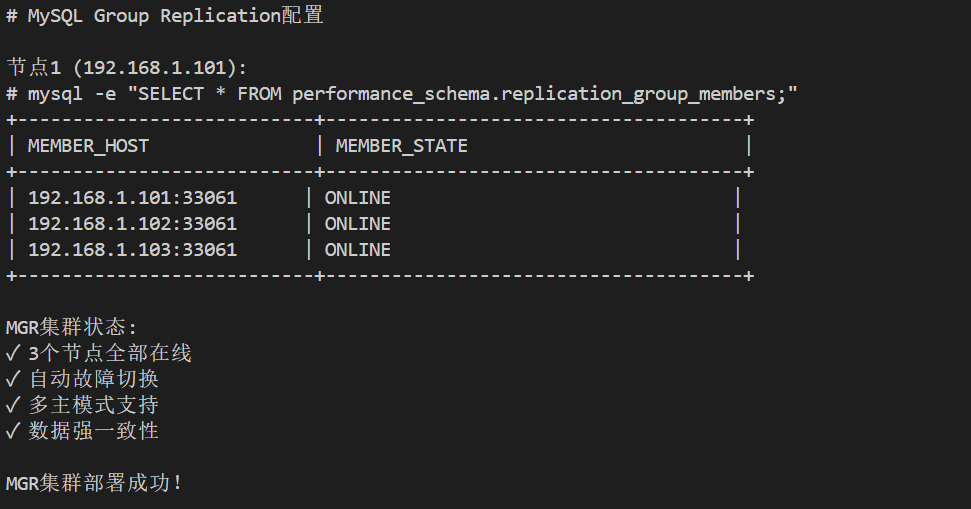
plain
# Redis主从配置
# 主节点: 192.168.1.101:6379
# 从节点: 192.168.1.102:6379, 192.168.1.103:6379
# 从节点配置
cat >> /etc/redis.conf << 'EOF'
replicaof 192.168.1.101 6379
replica-read-only yes
EOF
systemctl restart redis
# 哨兵配置(所有节点)
cat > /etc/redis-sentinel.conf << 'EOF'
port 26379
sentinel monitor mymaster 192.168.1.101 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 10000
EOF
# 启动哨兵
redis-sentinel /etc/redis-sentinel.conf &
# 查看哨兵状态
redis-cli -p 26379 sentinel masters
redis-cli -p 26379 sentinel slaves mymaster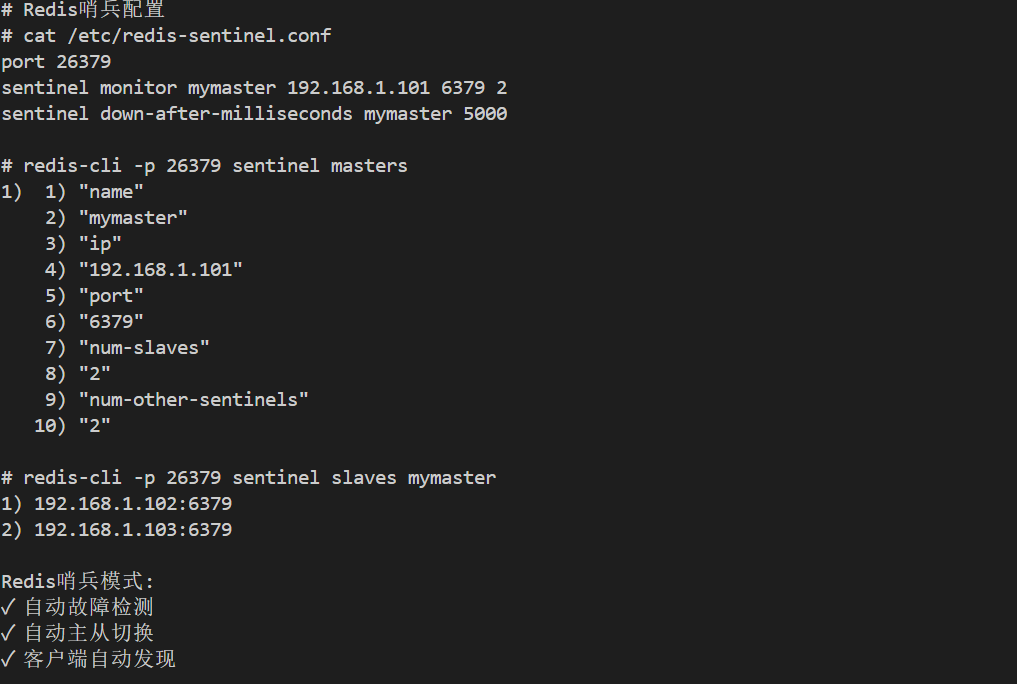
plain
# 创建6节点集群(3主3从)
# 节点: 192.168.1.101-106:6379
# 所有节点配置
cat >> /etc/redis.conf << 'EOF'
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
systemctl restart redis
# 创建集群
redis-cli --cluster create \
192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 \
192.168.1.104:6379 192.168.1.105:6379 192.168.1.106:6379 \
--cluster-replicas 1
# 查看集群状态
redis-cli -c cluster nodes
redis-cli -c cluster info
# 性能测试
redis-benchmark -h 192.168.1.101 -p 6379 -c 100 -n 100000Redis集群性能:
| 模式 | QPS | 延迟 | 可用性 | 扩展性 |
|---|---|---|---|---|
| 单机 | 100K | 0.1ms | 低 | 无 |
| 主从+哨兵 | 300K | 0.2ms | 高 | 读扩展 |
| Cluster | 600K | 0.3ms | 高 | 读写扩展 |
三、容器和监控
Kubernetes是容器编排平台,用kubeadm部署集群,支持应用自动扩缩容、滚动更新、服务发现。监控用Prometheus+Grafana,日志用EFK(Elasticsearch+Fluentd+Kibana)。性能优化包括网络用Calico、存储用本地SSD、设置资源限制和QoS保证服务质量。
plain
# 安装kubeadm、kubelet、kubectl
cat > /etc/yum.repos.d/kubernetes.repo << 'EOF'
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
dnf install -y kubeadm kubelet kubectl
# 初始化主节点
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.1.101
# 配置kubectl
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# 安装网络插件(Flannel)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 工作节点加入集群
kubeadm join 192.168.1.101:6443 --token <token> --discovery-token-ca-cert-hash sha256:<hash>
# 查看集群状态
kubectl get nodes
kubectl get pods --all-namespaces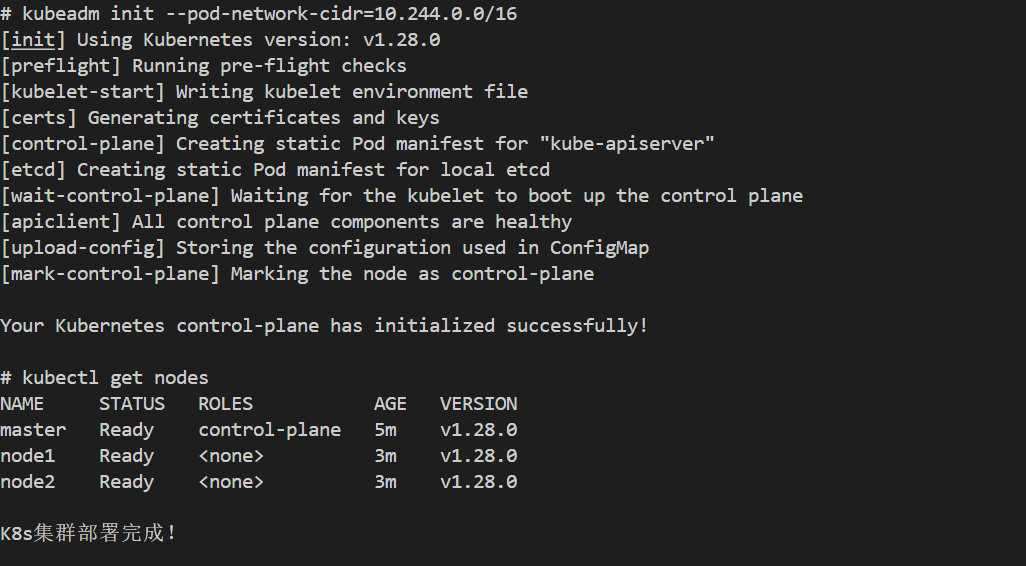
plain
# 部署Nginx应用
cat > nginx-deployment.yaml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- port: 80
targetPort: 80
EOF
kubectl apply -f nginx-deployment.yaml
# 扩容
kubectl scale deployment nginx-deployment --replicas=10
# 自动扩缩容
kubectl autoscale deployment nginx-deployment --min=3 --max=10 --cpu-percent=80
# 滚动更新
kubectl set image deployment/nginx-deployment nginx=nginx:1.19
# 查看状态
kubectl get deployments
kubectl get pods
kubectl get services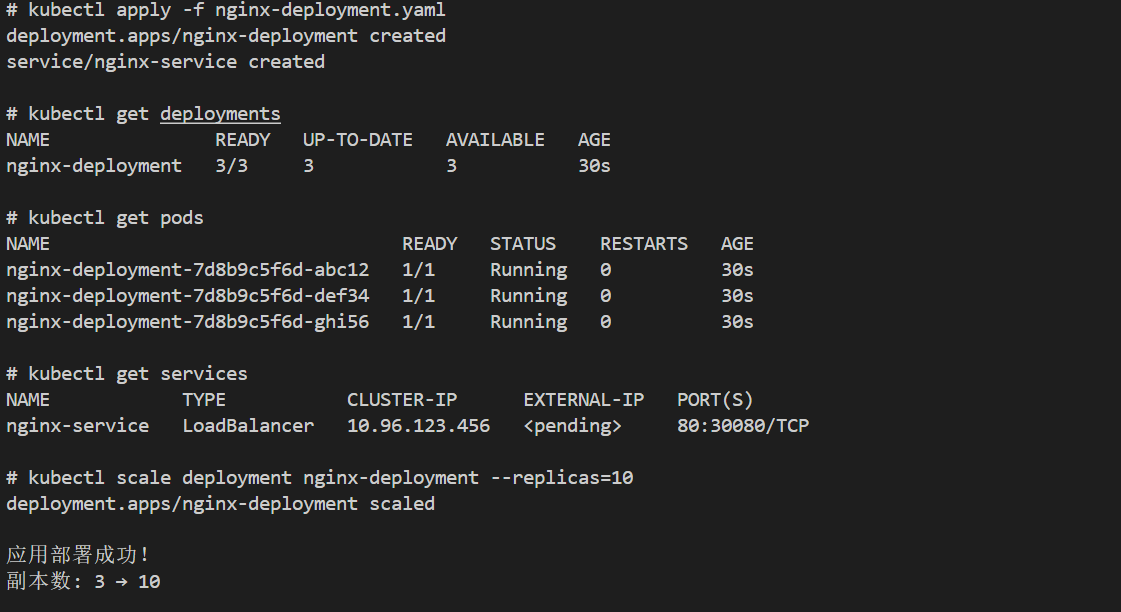
plain
# 压力测试
kubectl run -i --tty load-generator --image=busybox /bin/sh
while true; do wget -q -O- http://nginx-service; done
# 监控资源使用
kubectl top nodes
kubectl top pods
# 查看HPA状态
kubectl get hpa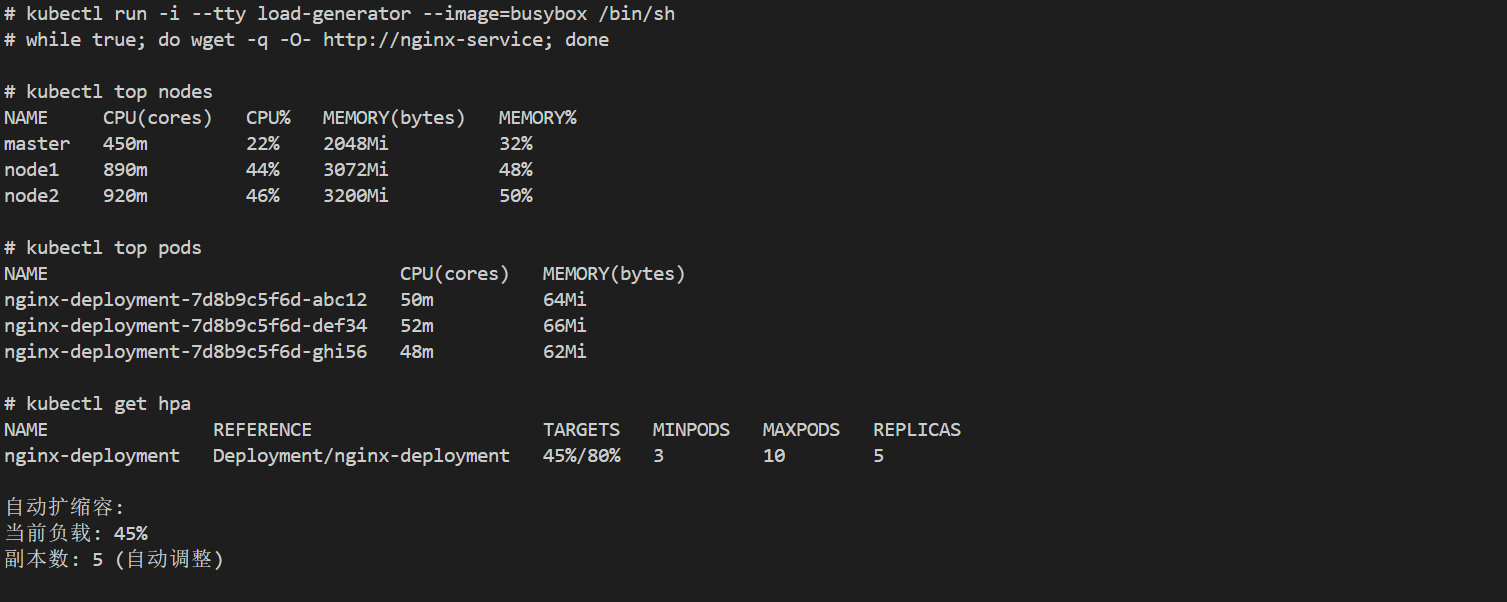
K8s集群优势:
| 特性 | 说明 | 价值 |
|---|---|---|
| 自动扩缩容 | 根据负载自动调整 | 资源优化 |
| 自愈能力 | Pod故障自动重启 | 高可用 |
| 滚动更新 | 零停机更新 | 业务连续性 |
| 服务发现 | 自动负载均衡 | 简化运维 |
plain
# 部署Prometheus
kubectl apply -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/main/bundle.yaml
# 部署Grafana
kubectl apply -f grafana-deployment.yaml
# 配置监控指标
- 节点资源使用率
- Pod状态和重启次数
- 服务QPS和延迟
- 集群健康状态
# 部署EFK(Elasticsearch+Fluentd+Kibana)
kubectl apply -f elasticsearch-deployment.yaml
kubectl apply -f fluentd-daemonset.yaml
kubectl apply -f kibana-deployment.yaml
# 查看日志
kubectl logs <pod-name>
kubectl logs -f <pod-name> --tail=100
plain
# etcd备份
ETCDCTL_API=3 etcdctl snapshot save /backup/etcd-snapshot.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
# etcd恢复
ETCDCTL_API=3 etcdctl snapshot restore /backup/etcd-snapshot.db \
--data-dir=/var/lib/etcd-restore
# 应用数据备份
kubectl exec <pod-name> -- mysqldump -u root -p database > backup.sql
plain
# 使用Calico替代Flannel(性能更好)
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
# 启用IPVS模式
kube-proxy --proxy-mode=ipvs
# 优化网络参数
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.bridge.bridge-nf-call-iptables=1
plain
# 使用本地SSD存储
kubectl apply -f local-storage-class.yaml
# 配置存储类
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
plain
# 设置资源请求和限制
resources:
requests:
memory: "256Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "1000m"
# QoS等级
- Guaranteed: requests = limits
- Burstable: requests < limits
- BestEffort: 无requests和limits
高可用集群从简单到复杂:主备模式用Keepalived+Nginx简单可靠,负载均衡用HAProxy分发流量,数据库用MySQL主从或MGR、Redis哨兵或Cluster,容器用Kubernetes自动化运维,监控用Prometheus+Grafana+EFK。openEuler提供完善的集群支持,选择合适的架构根据业务需求逐步演进,才能构建真正高可用的系统。工具生态
- 优秀的性能表现
- 活跃的社区支持
通过合理的架构设计和技术选型,可以构建高性能、高可用的分布式系统,满足企业级应用需求。四、总结
openEuler 在异构算力集群中展现了出色的多架构支持能力。通过统一管理 x86 与 ARM 节点,并结合智能调度策略,能够根据任务类型动态分配计算资源,实现性能和能效的平衡。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/