
论文标题:MedualTime: A Dual-Adapter Language Model for Medical Time Series-Text Multimodal Learning
论文链接:https://arxiv.org/abs/2406.06620
研究背景
我们之前解读过大语言模型和时间序列任务结合的文章,比如有北邮的ChatTime,清华的AutoTime,这类模型的核心想法是把预训练大语言的优势,移植到时间序列领域。这里涉及两个问题,一是模态对齐,不难理解,文本语言和时间序列数据也是不同维度的特征;二是谁主导谁的问题,这是本篇文章的讨论主题。
按作者的分析总结,已有的基于语言模型的时序-文本多模态研究工作,时序模态通常被视为主要模态,作者称之为:"时序优先"多模态模型,如下图所示。怎么理解呢,就是认为时间序列数据与任务决策的相关性更强,把时序作为主导,而文本模态作为辅助,比如:通过对比学习将文本知识投射到时序编码器;或者是通过文本提示词引导语言模型理解时序输入(目前多数是这种模式)。
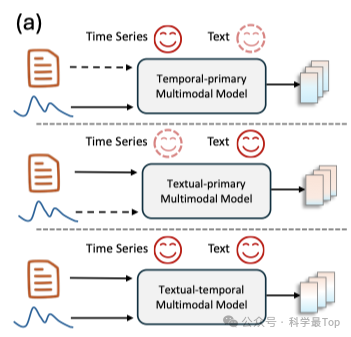
时序作为主导的问题在于,某些情况下文本模态包含的独特信息可能更丰富,因此将本文模态视为辅助模态可能引入偏差。为了解决以上问题,本文在医疗时序-文本数据集提出了一个MedualTime模型,该模型整合了"时序优先"和"文本优先"两种视角,充分利用了不同模态的互补优势。下面具体介绍MedualTime模型。
本文模型
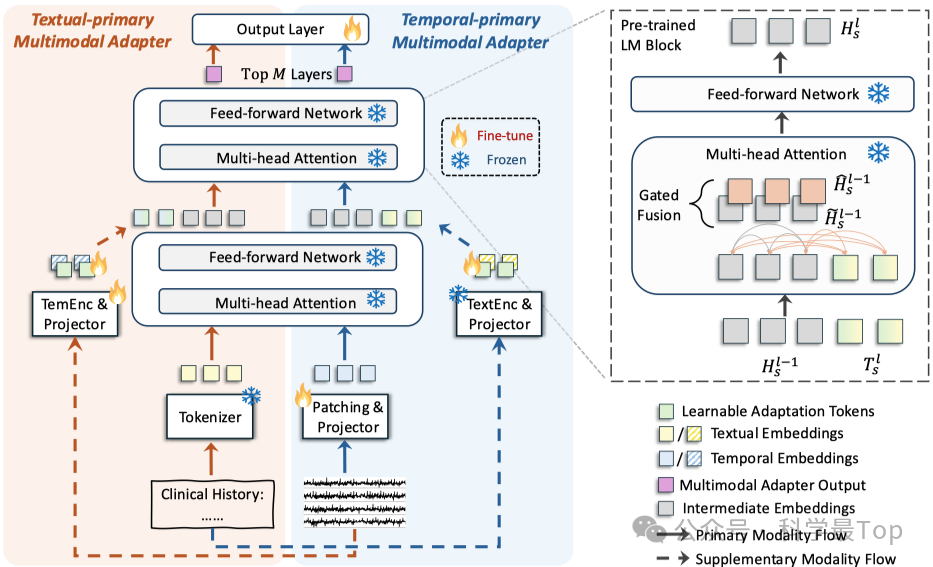
MedualTime 以 "共享骨干 + 双适配器" 为核心,结合图 2(b)可从整体框架、核心组件功能及模态融合逻辑三方面展开,具体如下:
从整体框架来看,模型以冻结的预训练语言模型(LM) 为共享骨干,该骨干包含多层 Transformer 块,双适配器(时序优先多模态适配器、文本优先多模态适配器)并行挂载于 LM 之上,且共用同一 LM 的参数(如注意力权重矩阵、前馈网络等),仅通过微调少量专属参数实现模态适配,借助共享 pipeline 实现双适配器嵌入空间的对齐。
在核心组件功能上,双适配器分别对应两种模态主导的建模逻辑。
-
时序优先适配器:主模态侧对时序数据采用 "补丁策略" 生成令牌,经投影器适配后输入 LM 前 L-M 层;辅助模态侧通过冻结语言模型(如 ClinicalBERT)提取文本嵌入并投影至 LM 空间;顶层 M 层注入结合文本向量的可学习适配令牌,以注意力键 / 值形式实现时序与文本融合;
-
文本优先适配器:主模态侧将文本经分词器生成嵌入并输入 LM 前 L-M 层;辅助模态侧通过可训练时序编码器(如轻量级 CNN)提取时序特征并投影;顶层 M 层注入结合时序向量的可学习适配令牌,完成文本与时序融合;
在模态融合逻辑上,将融合过程置于 LM 的顶层 M 层:通过在该层引入可学习适配令牌,让辅助模态信息以 "键 - 值对" 的形式参与主模态的注意力计算,而非直接混入输入,这种设计能更精准地捕捉两种模态的高层语义关联;同时,双适配器的 "主 - 辅" 模态角色可灵活切换,时序与文本均能作为主模态主导建模,另一模态则作为辅助增强,真正实现两种模态的平等对待与互补利用,契合 "文本 - 时序双主" 的学习范式。
实验分析
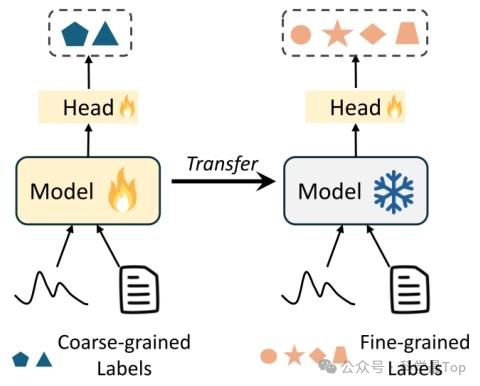
图3为少样本标签迁移(Few-shot Label Transfer)示意图,其设计针对医疗场景中粗粒度标签易获取、细粒度标签标注成本高的问题,展示了模型先在粗粒度标签数据上预训练,再冻结预训练参数、仅训练额外分类器以在少量细粒度标签数据上微调的任务逻辑,用于验证模型表征迁移能力;
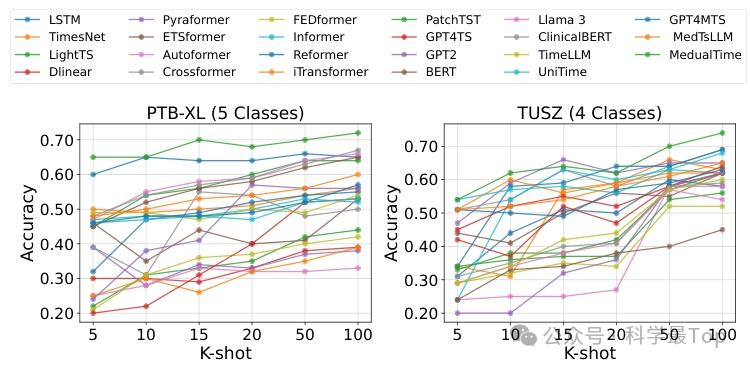
图4为少样本实验准确率结果图,而MedualTime(红色虚线标注)在两种数据集上均持续优于各类基线模型,即使样本极少时也保持较强分类性能,验证了其依托语言模型与多模态输入的出色迁移能力,能应对医疗场景细粒度标签稀缺问题。
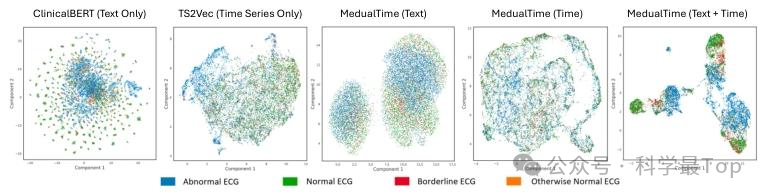
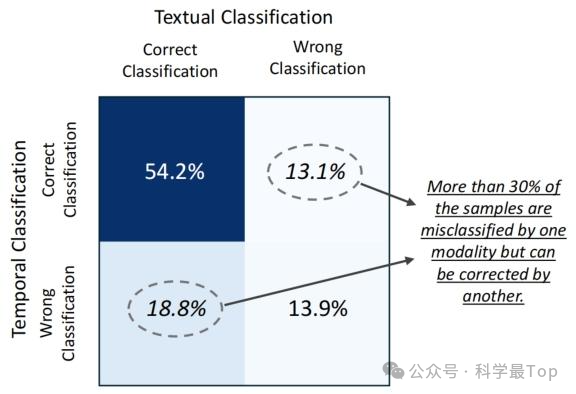
图 5 是 PTB-XL(4 类标签)数据集无监督学习的嵌入可视化(UMAP 降维至 2D,颜色区分标签):单模态模型 TS2Vec(时序)、ClinicalBERT(文本)无法有效区分 ECG 类别;MedualTime(Text)比 MedualTime(Time)区分效果更优,而 MedualTime(双适配器)类别区分最显著,验证其 "文本 - 时序双主" 建模优势。
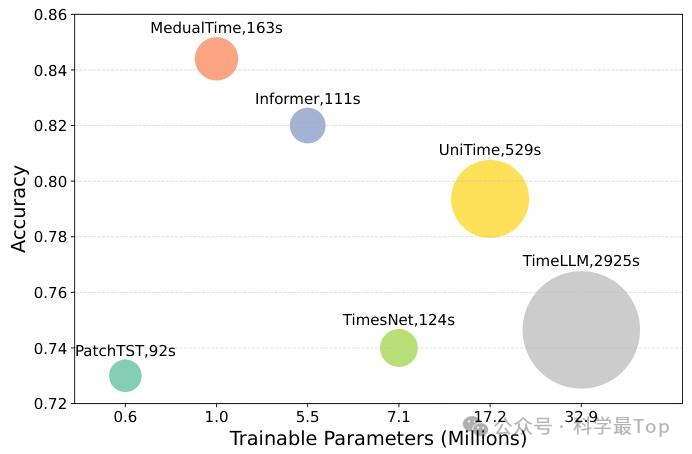
图 6 是 TUSZ(2 类标签)数据集模型效率对比(横轴为可训练参数 / 百万,纵轴为准确率,气泡大小代表每轮训练时间 / 秒):MedualTime 可训练参数约 100 万(少于 TimesNet 的 710 万),训练时间 163 秒(接近 TimesNet 的 124 秒),准确率约 0.84(高于 TimesNet 的 0.74),且优于 UniTime、TimeLLM 等模型,实现参数、时间、准确率的最优平衡。
结论
本文提出 "文本 - 时序双主" 多模态学习范式,设计了以共享冻结预训练语言模型为骨干、含 "时序优先" 与 "文本优先" 双适配器的 MedualTime 模型,通过在 LM 顶层注入可学习适配token实现高层模态融合,兼顾模态平等建模与高效计算。模型在 PTB-XL、TUSZ 等医疗数据集上,有监督学习平均提升 8% 准确率与 12% F1 分数,无监督学习平均提升 3% 准确率与 2% F1 分数,少样本标签迁移实验验证其出色迁移能力,且可训练参数仅约 100 万、训练效率接近轻量级模型,在性能、迁移性与效率上实现平衡,为医疗多模态学习提供有效解决方案。
**大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!**获取时序论文合集
