一、简介
SAM是Meta提出的一个分割一切的提示型模型,其在1100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化,突破了分割界限。本例程对SAM官方开源仓库的模型和算法进行移植,使之能在基于BM1684X芯片的嵌入式设备上进行高效推理测试。
1.特性
-
支持BM1684X平台全系列部署方案(x86 PCIe、SoC、riscv PCIe)
-
图像压缩(embedding)部分支持FP16 1batch(BM1684X)模型编译和推理
-
图像推理(mask_decoder)部分支持FP32 1batch、FP16 1batch(BM1684X)模型编译和推理
-
支持基于OpenCV的Python推理
-
支持单点和box输入的模型推理,并输出最高置信度mask或置信度前三的mask
-
支持图片测试
-
支持无需点框输入的自动图掩码生成
特别说明:
本例程已成功应用于ShiMetaPi基于BM1684X打造的算力盒子,实现了图像压缩(embedding)和图像推理(mask_decoder)两个bmodel的高效协同运行。图像推理部分最后一层resize未编入bmodel模型,这种设计在ShiMetaPi算力盒子的实际部署中展现了良好的灵活性和性能平衡,为边缘端分割任务提供了稳定可靠的解决方案。

2.工程目录
工程文件笔者对demo改动较多,建议直接拷贝笔者文件到/data目录下。
SAM
├─datasets ##weby以及python案例的图片保存
│ dog.jpg
│ groceries.jpg
│ truck.jpg
│
├─docs ##帮助文档
│ │ boxShare_PC_Wifi.md
│ │ sam.md
│ │
│ └─image ##文档中显示的图片
│ eth.png
│ ipv4.png
│ ping.png
│ regedit.png
│ result_0.jpg
│ result_auto.jpg
│ result_box_0.jpg
│ result_box_1.jpg
│ result_box_2.jpg
│ t2.png
│ t3.png
│ terminal.png
│ ui.png
│ uib.png
│ uip.png
│ wlan.png
│
├─models ##模型文件
│ └─BM1684X ##1684x的模型权重文件
│ ├─decode_bmodel
│ │ SAM-ViT-B_auto_multi_decoder_fp32_1b.bmodel
│ │ SAM-ViT-B_decoder_multi_mask_fp16_1b.bmodel
│ │ SAM-ViT-B_decoder_multi_mask_fp32_1b.bmodel
│ │ SAM-ViT-B_decoder_single_mask_fp16_1b.bmodel
│ │ SAM-ViT-B_decoder_single_mask_fp32_1b.bmodel
│ │
│ └─embedding_bmodel
│ SAM-ViT-B_embedding_fp16_1b.bmodel
│
├─python ##python脚本
│ amg.py
│ automatic_mask_generator.py
│ backend.py
│ predictor.py
│ sam_encoder.py
│ sam_model.py
│ sam_opencv.py
│ transforms.py
│
└─web_ui web例程文件
│ index.html
│
├─components
│ drawBox.png
│ firstPage.png
│ frontPage.png
│ singlePoint.png
│
├─css
│ styles.css
│
├─images
│ dog.jpg
│ groceries.jpg
│ truck.jpg
│
└─scripts
main.js二、运行步骤
**检查网网络环境:**因为后面的交互网页用到了固定IP,所以这里使用开发板通过网线共享电脑网络的方式进行,详细操作可以参考++联网文档++
1.环境准备
配置python环境
修改.bashrc文件,将sophon的python环境引入
sudo vim ~/.bashrc在文件末尾加上下面字段
export PYTHONPATH=$PYTHONPATH:/opt/sophon/libsophon-current/lib:/opt/sophon/sophon-opencv-latest/opencv-python/:wq保存退出后重新加载终端
source ~/.bashrc可echo $PYTHONPATH,检查是否是对应字段。
此外,运行环境还需要一下python库
pip3 install torch
##torchcision安装过慢,可指定清华源安装
pip3 install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install matplotlib
pip3 install flask flask-cors ##运行web交互案例所需,可选择性安装安装完毕可pip show 包名进行检查
2.python例程测试
2.1参数说明
python例程主要运行sam_opencv.py文件,参数说明如下:
usage: sam_opencv.py [--input_image INPUT_PATH] [--input_point INPOINT_POINT]
[--embedding_bmodel EMBEDDING_BMODEL] [--bmodel BMODEL]
[--auto bool][--dev_id DEV_ID]
--input_image: 测试图片路径,需输入图片路径;
--input_point: 输入点的坐标,输入格式为x,y;或者输入框坐标,格式为x1,y1,x2,y2
--embedding_bmodel 用于图像压缩(embedding)的bmodel路径;
--decode_bmodel: 用于推理(mask_decode)的bmodel路径;
--dev_id: 用于推理的tpu设备id;
--auto: 是否启用自动分割,为bool,默认为0不开启,1为开启;
'''以下为automatic masks generator的可调参数,可控制采样点的密度以及去除低质量或重复mask的阈值'''
--points_per_side: 沿图像一侧采样的点数。总点数为points_per_side2^2。默认值为32;
--points_per_batch: 设置模型同时检测的点数。数字越大可能速度越快,但会使用更多GPU内存。默认值为64;
--pred_iou_thresh: [0,1]中的过滤阈值,模型的预测mask质量。默认值为0.88;
--stability_score_thresh: [0,1] 中的过滤阈值(截止值变化时掩模的稳定性)用于对模型的mask预测进行二值化。默认值为0.95;
--stability_score_offset: 计算稳定性分数时,偏移截止值的量。默认值为1.0;
--box_nms_thresh: 用于过滤重复mask的非极大值抑制框IoU截止。默认值为0.7;
--crop_nms_thresh: 用于非极大值抑制的框IoU截止,以过滤不同对象之间的重复mask。默认值为0.7;
--crop_overlap_ratio: 设置物体重叠的程度。在第一个裁剪层中,裁剪将重叠图像长度的这一部分。物体较多的后几层会缩小这种重叠。默认值为512 / 1500;
--crop_n_points_downscale_factor: 在层n中采样的每侧的点数按比例缩小"crop_n_points_downscale_factorn"^n。默认值为1;
--min_mask_region_area: 如果>0,将应用后处理来移除面积小于"min_mask_region_area"的mask来中断开连接的区域和孔。需要opencv。默认为0;
--output_mode: mask输出方式。可以是binary_mask、uncompressed_rle或coco_rle ,coco_rle需要pycocotools。对于大分辨率,binary_mask可能会消耗大量内存。默认为'binary_mask';2.2测试图片
2.2.1点输入测试
cd /data/SAM
python3 python/sam_opencv.py --input_image datasets/truck.jpg --input_point 700,375 --embedding_bmodel models/BM1684X/embedding_bmodel/SAM-ViT-B_embedding_fp16_1b.bmodel --decode_bmodel models/BM1684X/decode_bmodel/SAM-ViT-B_decoder_single_mask_fp16_1b.bmodel --dev_id 0结果如下:
终端:
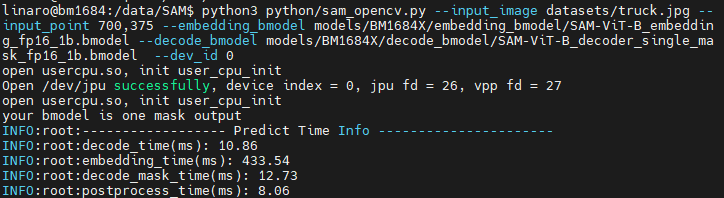
图片:图片位于SAM目录下的results/中



2.2.2box输入
python3 python/sam_opencv.py --input_image datasets/truck.jpg --input_point 100,300,1700,800 --embedding_bmodel models/BM1684X/embedding_bmodel/SAM-ViT-B_embedding_fp16_1b.bmodel --decode_bmodel models/BM1684X/decode_bmodel/SAM-ViT-B_decoder_multi_mask_fp16_1b.bmodel --dev_id 0效果以及位置与point中类似

2.2.3自动分割
若是要使用无需点和框输入的全自动掩码生成则需要设置输入参数auto为1,并设置--bmodel为auto的bmodel,操作如下:
python3 python/sam_opencv.py --input_image datasets/dog.jpg --embedding_bmodel models/BM1684X/embedding_bmodel/SAM-ViT-B_embedding_fp16_1b.bmodel --decode_bmodel models/BM1684X/decode_bmodel/SAM-ViT-B_auto_multi_decoder_fp32_1b.bmodel --dev_id 0 --auto 1 --pred_iou_thresh 0.86运行结束后,会将结果图保存在results/下,同时会打印推理时间等信息。

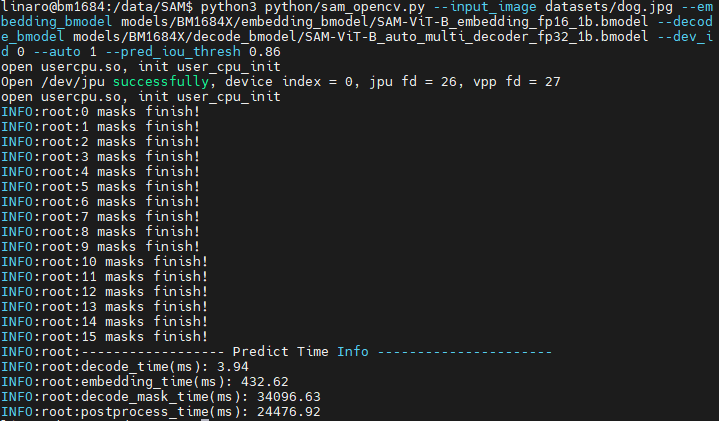
3.web例程
用于交互的图片文件存放于SAM/web_ui/images目录下,程序会自动读取目录下所有*.jpg的所有图片,并在前端页面下拉框中显示图片名。
3.1启动后端程序
后端程序位于SAM/python/中 ,脚本名字叫 backend.py。此web_ui的python例程不需要编译,可以直接运行
3.1.1参数说明
usage: backend.py [--embedding_bmodel EMBEDDING_BMODEL] [--bmodel BMODEL] [--dev_id DEV_ID]
--embedding_bmodel 用于图像压缩(embedding)的bmodel路径;
--bmodel: 用于推理(mask_decode)的bmodel路径;
--dev_id: 用于推理的tpu设备id;3.1.2运行示例
cd /data/SAM
python3 python/backend.py --embedding_bmodel models/BM1684X/embedding_bmodel/SAM-ViT-B_embedding_fp16_1b.bmodel --decode_bmodel models/BM1684X/decode_bmodel/SAM-ViT-B_decoder_single_mask_fp16_1b.bmodel --dev_id 0出现下面内容,说明后端已经启动
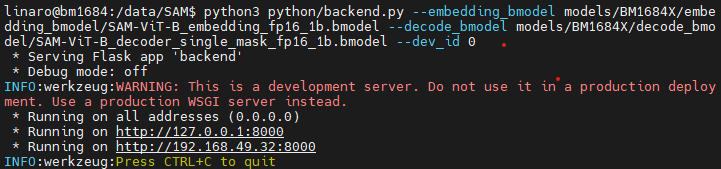
3.2启动前端服务
前端程序在/data/SAM/web_ui 里面,可以通过 python 启动。
保留后端session窗口,新开一个session窗口用于前端
cd /data/SAM/web_ui/
python3 -m http.server 8080打开PC端浏览器界面,在网址处输入192.168.49.32:8080,进入交互界面,点击选择要加载的图像...的下拉框,即可选择预存图像。选择Single Point进入点击模式,Draw BOX进入框选模式
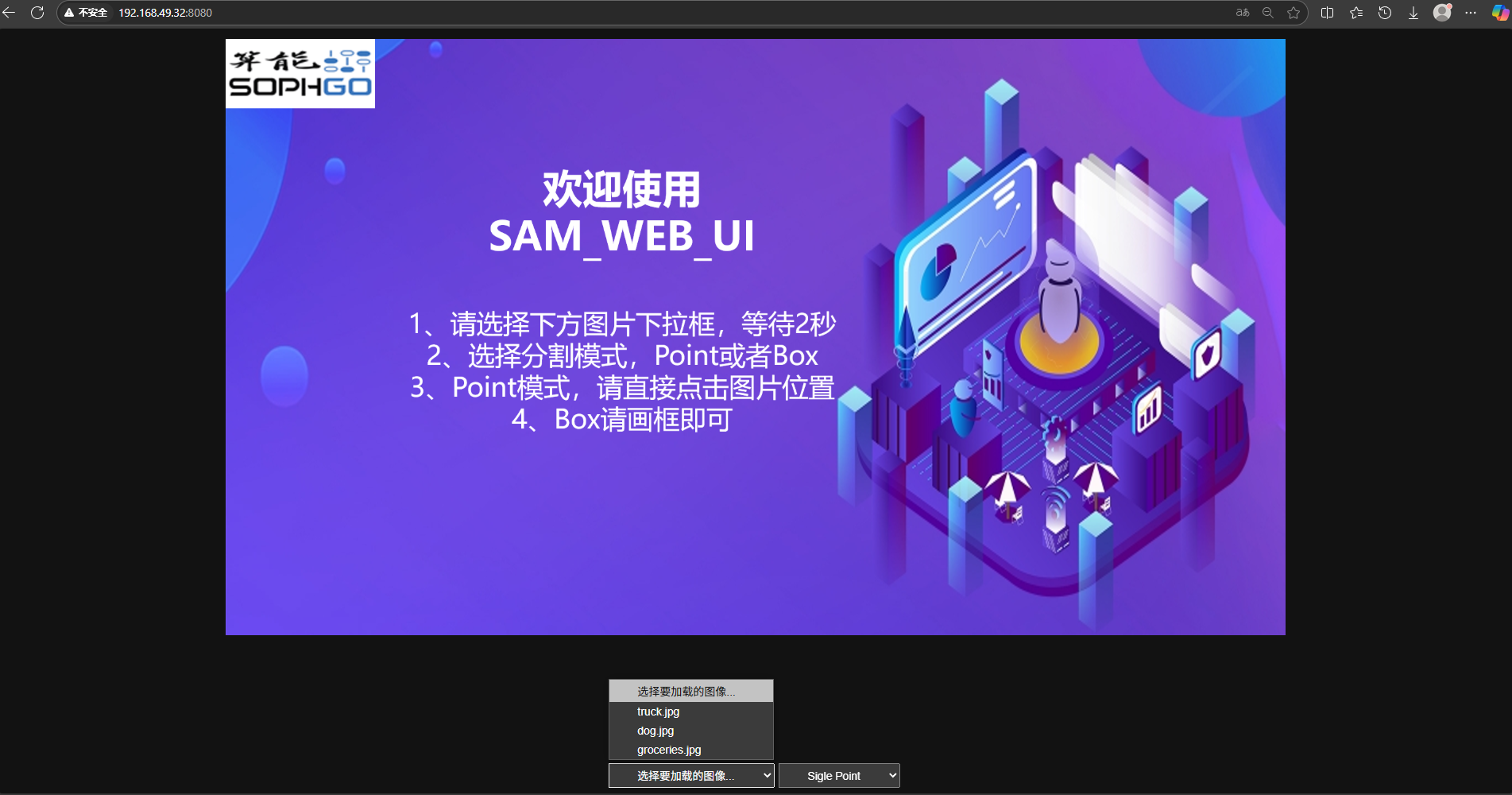
3.2.1点击模式
点击模式待图片加载成功,点击感兴趣区域即可,等待1-2S,页面绘制掩码结果。

3.2.2框选模式
点击模式待图片加载成功,点击鼠标拖动框选感兴趣区域即可,等待1-2S,页面绘制掩码结果。

PS:可在原来终端中检测后端和前端的运行状态,前端状态还可在浏览器开发者工具中检测。