文章目录
- ceph分布式存储
- [第 1 章 Ceph 分布式存储 介绍](#第 1 章 Ceph 分布式存储 介绍)
-
- 存储中用户角色
- [Ceph 介绍](#Ceph 介绍)
-
- [Ceph 简介](#Ceph 简介)
- [Ceph 技术优势](#Ceph 技术优势)
- [Ceph 使用场景](#Ceph 使用场景)
- [Ceph 历史](#Ceph 历史)
- [上游 Ceph 版本](#上游 Ceph 版本)
- [企业版 Ceph 存储](#企业版 Ceph 存储)
-
- [Ceph 存储](#Ceph 存储)
- [Ceph 架构介绍](#Ceph 架构介绍)
-
- Ceph集群架构简介
-
- Ceph访问方式-简介
- Ceph存储后端组件-简介
- Ceph访问方式-详细
-
- [Ceph原生API(librados)](#Ceph原生API(librados))
- [Ceph块设备(RBD、librbd)](#Ceph块设备(RBD、librbd))
- Ceph对象网关(RADOS网关、librgw)
- Ceph文件系统(CephFS、libcephfs)
- 存储访问方式选择
- Ceph后端存储组件-详细
-
- Ceph监视器(MON)
- Ceph对象存储设备(OSD)
- Ceph管理器(MGR)
- Ceph元数据服务器(MDS)
- [集群映射(Cluster Map)](#集群映射(Cluster Map))
- [第 2 章 Ceph 分布式存储 部署](#第 2 章 Ceph 分布式存储 部署)
-
- [Ceph 集群安装介绍](#Ceph 集群安装介绍)
-
- [Ceph 集群安装方式](#Ceph 集群安装方式)
- [Ceph 集群 最小硬件规格](#Ceph 集群 最小硬件规格)
- [Ceph 服务端口](#Ceph 服务端口)
- [Cephadm 简介](#Cephadm 简介)
- [Cephadm 与其他服务交互](#Cephadm 与其他服务交互)
- [Cephadm 管理接口](#Cephadm 管理接口)
-
- [Ceph CLI 接口](#Ceph CLI 接口)
- [Ceph Dashboard 接口](#Ceph Dashboard 接口)
- [Ceph 集群安装过程](#Ceph 集群安装过程)
- [Ceph 集群组件管理](#Ceph 集群组件管理)
- [第 3 章 Ceph 分布式存储 集群配置](#第 3 章 Ceph 分布式存储 集群配置)
-
- 管理集群配置
-
- [Ceph 集群配置概述](#Ceph 集群配置概述)
- 修改集群配置文件
- 使用集群配置数据库
-
- [ceph config ls](#ceph config ls)
- [ceph config help `<key>`](#ceph config help
<key>) - [ceph config dump](#ceph config dump)
- [ceph config show t y p e . type. type.id \`\
<key>]) - [ceph config show-with-defaults t y p e . type. type.id](#ceph config show-with-defaults t y p e . type. type.id)
- [ceph config get t y p e . type. type.id \`\
<key>]) - [ceph config set t y p e . type. type.id `<key> <value>`](#ceph config set t y p e . type. type.id
<key> <value>) - [ceph config rm t y p e . type. type.id \`\
<key>]) - [ceph config log `\
[<num:int>]) - [ceph config reset `\
[<num:int>])
- 集群引导选项
- 在运行时覆盖配置设置
-
- [ceph tell 命令](#ceph tell 命令)
- [ceph daemon 命令](#ceph daemon 命令)
- [Web UI 更改](#Web UI 更改)
- [配置集群监控器 Monitor](#配置集群监控器 Monitor)
- 配置集群网络-了解即可
- [第 4 章 Ceph 分布式存储 池管理](#第 4 章 Ceph 分布式存储 池管理)
- [第 5 章 Ceph 分布式存储 认证和授权管理](#第 5 章 Ceph 分布式存储 认证和授权管理)
- [第 6 章 Ceph 分布式存储 块存储管理](#第 6 章 Ceph 分布式存储 块存储管理)
-
- [管理 RADOS 块设备](#管理 RADOS 块设备)
-
- [RADOS 块设备](#RADOS 块设备)
- [创建 RBD 镜像](#创建 RBD 镜像)
- [访问 RADOS 块设备存储](#访问 RADOS 块设备存储)
-
- [使用内核RBD(KRBD)访问 Ceph 块存储](#使用内核RBD(KRBD)访问 Ceph 块存储)
-
- [映射 RBD 镜像](#映射 RBD 镜像)
- [持久映射 RBD 镜像](#持久映射 RBD 镜像)
- [使用 librbd 库访问 Ceph 块存储-配合虚拟化,不过多讲解](#使用 librbd 库访问 Ceph 块存储-配合虚拟化,不过多讲解)
-
- [使用 librbd 库访问 Ceph 块存储](#使用 librbd 库访问 Ceph 块存储)
- [RBD 缓存](#RBD 缓存)
- [RBD 缓存模式](#RBD 缓存模式)
- [RBD 缓存参数](#RBD 缓存参数)
- [RBD 镜像格式](#RBD 镜像格式)
-
- [RBD 镜像布局](#RBD 镜像布局)
- [RBD 镜像阶数](#RBD 镜像阶数)
- [RBD 镜像格式](#RBD 镜像格式)
- [使用 rbd 命令管理镜像](#使用 rbd 命令管理镜像)
- [管理 RADOS 块设备快照](#管理 RADOS 块设备快照)
-
- [RBD 镜像功能](#RBD 镜像功能)
- [RBD 快照](#RBD 快照)
- [RBD 克隆](#RBD 克隆)
- 挂载克隆镜像
- [导入和导出 RBD 镜像](#导入和导出 RBD 镜像)
-
- [导入和导出 RBD 镜像](#导入和导出 RBD 镜像)
-
- [导出 RBD 镜像](#导出 RBD 镜像)
- [导入 RBD 镜像](#导入 RBD 镜像)
- 管道导出和导入进程
- [导出和导入 RBD 镜像更改-不做,使用机会不大](#导出和导入 RBD 镜像更改-不做,使用机会不大)
-
- [导出 RBD 镜像更改](#导出 RBD 镜像更改)
- [比较 RBD 镜像更改](#比较 RBD 镜像更改)
- [导入 RBD 镜像更改](#导入 RBD 镜像更改)
- [配置 RBD Mirrors](#配置 RBD Mirrors)
- [第 7 章 Ceph 分布式存储 对象存储管理](#第 7 章 Ceph 分布式存储 对象存储管理)
-
- 对象存储介绍
- [RADOS 网关介绍](#RADOS 网关介绍)
-
- [RADOS 网关简介](#RADOS 网关简介)
- [RADOS 网关架构](#RADOS 网关架构)
- [RADOS 网关用例](#RADOS 网关用例)
- [RADOS 网关部署](#RADOS 网关部署)
-
- 创建对象存储域
- [RADOS 网关部署](#RADOS 网关部署)
-
- [RADOS 网关部署-命令行](#RADOS 网关部署-命令行)
- [# RADOS 网关部署-服务文件#跳过](# RADOS 网关部署-服务文件#跳过)
-
- [#RADOS 网关-部署](#RADOS 网关-部署)
- [#RADOS 网关-实例删除](#RADOS 网关-实例删除)
- [#RADOS 网关-实例添加](#RADOS 网关-实例添加)
- [#RADOS 网关-配置备份](#RADOS 网关-配置备份)
- [#RADOS 网关-配置恢复](#RADOS 网关-配置恢复)
- [#RADOS 网关删除-跳过](#RADOS 网关删除-跳过)
- #删除对象存储域
- 管理对象网关用户
- [使用 Amazon S3 API 访问对象存储](#使用 Amazon S3 API 访问对象存储)
- [使用 Swift API 访问对象存储-跳过](#使用 Swift API 访问对象存储-跳过)
- 管理多站点对象存储网关
- [第 8 章 Ceph 分布式存储 文件系统存储管理](#第 8 章 Ceph 分布式存储 文件系统存储管理)
-
- [介绍 CephFS](#介绍 CephFS)
- [部署 CephFS](#部署 CephFS)
-
- [手动部署 CephFS](#手动部署 CephFS)
-
- [创建 CephFS](#创建 CephFS)
- [删除 CephFS](#删除 CephFS)
- [卷部署 CephFS](#卷部署 CephFS)
-
- [创建 CephFS](#创建 CephFS)
- [删除 CephFS](#删除 CephFS)
- [挂载 CephFS 文件系统](#挂载 CephFS 文件系统)
- [挂载 CephFS 文件系统](#挂载 CephFS 文件系统)
-
- 环境准备
- [CephFS 挂载方式](#CephFS 挂载方式)
- [CephFS 挂载用户](#CephFS 挂载用户)
- [CephFS 客户端挂载准备](#CephFS 客户端挂载准备)
- [使用 Kernel 挂载 CephFS](#使用 Kernel 挂载 CephFS)
-
- [挂载 CephFS](#挂载 CephFS)
ceph分布式存储
第 1 章 Ceph 分布式存储 介绍
存储中用户角色
云存储用户角色
在一个比较大的云存储环境中,可能存在不同职责的存储用户。
存储管理员
存储管理员作为主要角色,执行以下任务:
- 安装、配置和维护 Ceph 存储集群。
- 对基础架构架构师进行有关 Ceph 功能和特性的培训。
- 告知用户有关 Ceph 数据表示和方法的信息,作为他们数据应用程序的选择。
- 提供弹性和恢复,例如复本、备份和灾难恢复方法。
- 通过基础架构即代码实现自动化和集成。
- 提供对数据分析和高级海量数据挖掘的访问。
存储操作员
- 存储操作员协助存储集群的日常操作,通常不如存储管理员经验丰富。
- 存储操作员主要使用 Ceph Dashboard GUI 来查看和响应集群警报和统计信息。
- 存储操作员还负责日常存储管理任务,例如更换故障存储设备。
其他存储相关的角色
其他直接使用 Ceph 的角色包括应用程序开发人员、项目经理和具有数据处理、数据仓库、大数据和类似应用程序需求的服务管理员。存储管理员经常与这些角色进行交流。定义这些关系有助于说明存储管理员职责,并阐明存储管理员范围的任务限制或边界。
- 云操作员,管理组织中的云资源,例如 OpenStack 或 OpenShift 基础设施。存储管理员与云操作员密切合作,维护 Ceph 集群。
- 自动化工程师,负责为常见的重复任务创建剧本。
- 应用程序开发人员(DevOps 开发人员),可以是原始代码开发人员、维护人员或其他负责应用程序正确部署和行为的云用户。存储管理员与应用程序开发人员协调以确保存储资源可用、设置配额并保护应用程序存储。
- 服务管理员,管理最终用户服务(不同于操作系统服务)。服务管理员具有与项目经理类似的角色,但针对的是现有的生产服务产品。
- 部署工程师(DevOps 工程师),在更大的环境中,专职人员与存储管理员和应用程序开发人员一起执行、管理和调整应用程序部署。
- 应用架构师,应用程序架构师可以在 Ceph 基础架构布局与资源可用性、扩展和延迟之间建立关联。这种架构专业知识可帮助存储管理员有效地设计复杂的应用程序部署。为了支持云用户及其应用程序,存储管理员必须了解资源可用性、扩展和延迟的这些相同方面。
- 基础架构架构师,存储管理员必须掌握存储集群的架构布局,才能管理资源位置、容量和延迟。 Ceph 集群部署和维护的基础架构架构师是存储管理员的主要信息来源。 基础架构架构师可能是云服务提供商员工或供应商解决方案架构师或顾问。
- 数据中心操作员,是较低 Ceph 存储基础设施层的角色,负责数据供应。数据中心操作员通常受雇于公共云服务提供商或私有数据中心云中组织的内部 IT 团队。
组织中用户角色
由于组织之间的人员配备、技能、安全性和规模不同,因此角色的实施通常不同。 尽管角色有时与个人相匹配,但用户通常会根据他们的工作职责承担多个角色。
- 在电信服务提供商和云服务提供商中,常见的角色是云操作员、存储操作员、基础架构架构师和云服务开发人员,通常只消费存储而不维护它们。
- 在银行、金融等需要安全、私有、专用基础架构的组织中,所有角色都由内部人员配备。 存储管理员、云操作员和基础架构架构师角色充当服务提供商并支持所有其他角色。
- 在大学和较小的实施中,技术支持人员可以承担所有角色。 一个人可能会承担存储管理员、基础架构架构师和云操作员角色。
Ceph 介绍
Ceph 简介
-
Ceph 是一款开源、分布式、软件定义存储 。
-
Ceph 具备极高的可用性、 扩展性和易用性, 用于存储海量数据。
-
Ceph 存储可部署在通用服务器上, 这些服务器的CPU可以是x86架构, 也可以是ARM架构。 Ceph 支持在同一集群内既有x86主机,又有ARM 主机。
软件定义 software-defined storage (SDS)
Ceph 技术优势
- 采用 RADOS 系统将所有数据作为对象, 存储在存储池中。
- 去中心化, 客户端可根据CRUSH算法自行计算出对象存储位置, 然后进行数据读写。
- 集群可自动进行扩展、 数据再平衡、 数据恢复等。
Ceph 使用场景
Ceph 历史
-
Ceph是圣克鲁兹加利福尼亚大学的 **Sage Weil 在2003年开发的,他的博士学位项目的一部分。**初始的项目原型是大约 40000 行 C++代码的 Ceph 文件系统,于 2006 年遵循 LGPL 协议(Lesser GUN Public License)开源。Ceph没有采用双重许可模式,也就不存在只针对企业版的特性。
-
2003-2007 年是Ceph的研究开发时期。在这期间,它的核心组件逐步形成,并且社区对项目的贡献开始逐渐变大。
-
2007年年末,Ceph已经越来越成熟,并开始等待孵化。
-
2012年4月,Sage Weil 在 DreamHost 的资助下成立了 Inktank 公司,主要目的是提供广泛的 Ceph 专业服务和技术支持。
-
2014年4月,Inktank 成为红帽大家庭的一员,Inktank Ceph Enterprise 也变为Ceph 存储。
-
此外,Ceph也与Linux内核、SUSE、OpenStack项目、CloudStack等项目进行了整合。一些公司将Ceph整合为存储设备产品的核心,如富士通的CD10000项目和SANDisk的InfiniFlash。
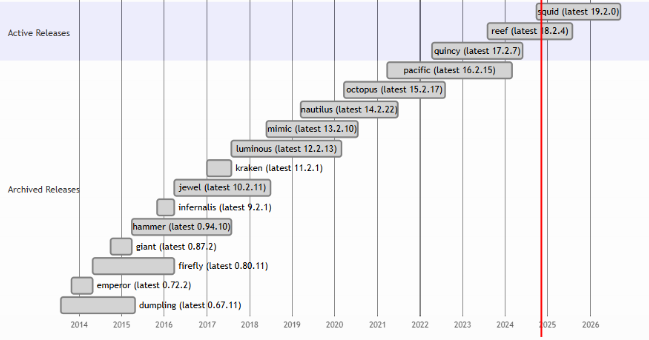
上游 Ceph 版本
参考链接: https://docs.ceph.com/en/latest/releases/
统计时间:2024-11
| Release code name | Version | LTS | Release date | Retirement date |
|---|---|---|---|---|
| Argonaut | 0.48.x | July 2012 | retired | |
| Bobtail | 0.56.x | January 2013 | retired | |
| Cuttlefish | 0.61.x | May 2013 | retired | |
| Dumpling | 0.67.x | Yes | August 2013 | May 2015 |
| Emperor | 0.72.x | November 2013 | May 2014 | |
| Firefly | 0.80.x | Yes | May 2014 | December 2015 |
| Giant | 0.87.x | October 2014 | May 2015 | |
| Hammer | 0.94.x | Yes | April 2015 | August 2017 |
| Infernalis | 9.2.x | November 2015 | April 2016 | |
| Jewel | 10.2.x | Yes | April 2016 | June 2018 |
| Kraken | 11.2.x | January 2017 | August 2017 | |
| Luminous | 12.2.x | Yes | August 2017 | January 2020 |
| Mimic | 13.2.x | Yes | June 2018 | April 2020 |
| nautilus | 14.2.x | Yes | March 2019 | June 2021 |
| octopus | 15.2.x | Yes | 2020-03-23 | 2022-06-01 |
| pacific | 16.2.x | Yes | 2021-03-31 | 2023-06-01 |
| Quincy | 17.2.x | Yes | 2022-04-19 | 2024-06-01 |
| Reef | 18.2.X | Yes | 2023-08-07 | 2025-08-01 |
| Squid | 19.2.X | Yes | 2024-09-26 | 2026-09-19 |
自Infernalis起,上游 Ceph 采用了新的版本号编号方案:每一稳定发行版主要版本号递增1。
- 2017年年底之前,上游CEPH项目每年发布两个稳定版本。
- 截止到Luminous版本,上游项目交替发布开发版本和长期稳定(LTS)版本。稳定版本发布后,将停止更新开发版本。红帽的RHCS产品与社区的LTS版本的CEPH生命周期一致。
- 从 Nautilus release (14.2.0)开始,每年 March 1st 发布一个稳定版本。稳定版本周期大概2年。
版本格式 x.y.z 说明:
-
x identifies the release cycle (e.g., 13 for Mimic).
-
y identifies the release type:
-
x.0.z - development releases (for early testers and the brave at heart)
-
x.1.z - release candidates (for test clusters, brave users)
-
x.2.z - stable/bugfix releases (for users)
-
-
z identifies the release number
企业版 Ceph 存储
Ceph 存储
-
Ceph 存储是一个企业级别的、软件定义的、支持数千客户端、存储容量 EB 级别的分布式数据对象存储,提供统一存储(对象、块和文件存储)。
-
**Ceph 存储与 Ceph 项目的关系,类似于RHEL与Fedora关系。**红帽定期将来自上游项目的最新变化整合到企业版、并提供专业支持。红帽对Ceph存储的改进也会以开源形式回馈到上游项目。
-
红帽为企业版Ceph 存储提供36个月支持,比上游支持长1年。
Ceph 架构介绍
Ceph集群架构简介
Ceph存储是一种分布式数据对象存储。这是一种企业级软件定义存储解决方案,可扩展至数以千计数据访问量在艾字节以上的客户端。Ceph旨在提供卓越的性能、可靠性和可扩展性。
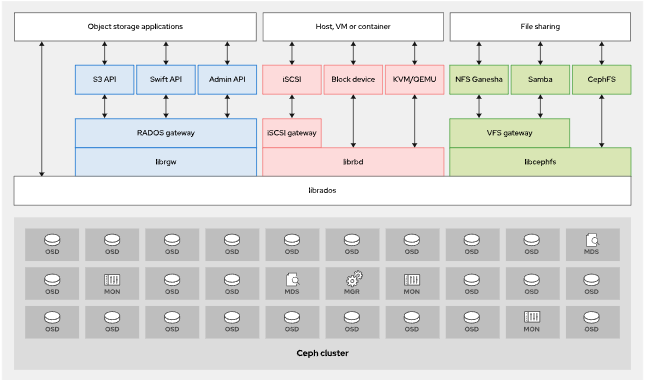
Ceph采用模块化分布式架构,包含下列元素:
- 对象存储后端,称为RADOS(可靠的自主分布式对象存储)
- 与RADOS交互的多种访问方式
RADOS是一种自我修复、自我管理、基于软件的对象存储。
Ceph访问方式-简介
Ceph提供以下访问Ceph集群的方法:
-
Ceph原生API(librados)
-
Ceph块设备(RBD、librbd),也称为 RADOS块设备(RBD)镜像
-
Ceph对象网关(RADOSGW、librgw)
-
Ceph文件系统(CephFS、libcephfs)
Ceph存储后端组件-简介
- **监控器(MON)**维护集群状态映射。它们可帮助其他守护进程互相协调。
- **对象存储设备(OSD)**存储数据并处理数据复制、恢复和重新平衡。
- **管理器(MGR)**通过基于浏览器的仪表板和RESTAPI,跟踪运行时指标并公开集群信息。
- **元数据服务器(MDS)**存储CephFS使用的元数据(而非对象存储或块存储),以便客户端能够高效运行 POSIX命令。
这些守护进程可以扩展,以满足所部署的存储集群的要求。
下图描述了Ceph集群的四种数据访问方法、支持访问方式的库,以及管理和存储数据的底层Ceph组件。
Ceph访问方式-详细
Ceph原生API(librados)
实施Ceph块设备、Ceph对象网关等其他Ceph接口的基础库为librados。librados库是原生C语言库,可以让应用直接与RADOS协作来访问Ceph集群存储的对象。也有类似的库适用于C++、Java、Python、Ruby、Erlang和 PHP。
为最大化性能,请编写软件以直接与librados配合使用。这种方式可以在改进Ceph环境中存储性能方面达到最佳效果。为了简化对Ceph存储的访问,您可以改为使用所提供的更高级访问方式,如ceph块设备、Ceph对象网关(RADOSGW)和CephFS。
Ceph块设备(RBD、librbd)
Ceph块设备(RADOS块设备或RBD)通过RBD镜像在Ceph集群内提供块存储。Ceph分散在集群不同的OSD中构成RBD镜像的个体对象。由于组成RBD的对象分布到不同的OSD,对块设备的访问自动并行处理。
RBD提供下列功能:
- Ceph集群中虚拟磁盘的存储
- Linux内核中的挂载支持
- QEMU、KVM和 OpenStack Cinder 的启动支持
Ceph对象网关(RADOS网关、librgw)
Ceph对象网关(RADOS网关、RADOSGW或RGW)是使用librados构建的对象存储接口。它使用这个库来与Ceph集群通信,并且直接写入到OSD进程。它通过RESTfulAPI为应用提供了网关,并且支持两种接口:Amazon S3和 OpenStack Swift。
Ceph对象网关提供扩展支持,它不限制部署的网关数量,而且支持标准的HTTP负载均衡器。Ceph对象网关包括以下用例:
- 镜像存储(例如,SmugMug和TumbIr)
- 备份服务
- 文件存储和共享(例如,Dropbox)
Ceph文件系统(CephFS、libcephfs)
Ceph文件系统(CephFS)是一种并行文件系统,提供可扩展的、单层级结构共享磁盘。红帽Ceph存储可为CephFS提供生产环境支持,包括快照支持。
Ceph元数据服务器(MDS)管理与CephFS中存储的文件相关联的元数据,包括文件访问、更改和修改时间戳。
存储访问方式选择
-
为了最大限度地提高性能,请编写用户的应用程序以直接使用 librados 。
-
如果想简化对Ceph存储的访问,也可以使用其他三种访问方式。
Ceph后端存储组件-详细
RADOS(Reliable ,Autonomic ,Distributed Object Store),即可靠的、自主的、分布式的对象存储,是Ceph存储系统的核心。Ceph的所有优秀特性都是由RADOS提供的 ,包括分布式对象存储、高可用性、高可靠性、没有单点故障、自我修复以及自我管理等。Ceph中的一切数据都以对象的形式存储,RADOS负责存储这些对象,而不考虑它们的数据类型。
Ceph监视器(MON)
- MON 必须就集群的状态达成共识 ,才能对外提供服务。
- Ceph 集群配置奇数个监视器,以确保监视器在对集群状态进行投票时可以建立法定人数。
- 要使 Ceph 存储集群正常运行和访问,必须有超过一半的已配置监视器正常工作。
- Ceph Monitor (MON) 是维护集群映射的守护进程。 集群映射是多个映射的集合,包含有关集群状态及其配置的信息。 Ceph 必须处理每个集群事件,更新相应的映射,并将更新后的映射复本到每个 MON 守护进程。
Ceph对象存储设备(OSD)
Ceph 对象存储设备 (OSD) 将存储设备连接到 Ceph 存储集群。 单个存储服务器可以运行多个 OSD 守护进程并为集群提供多个 OSD。
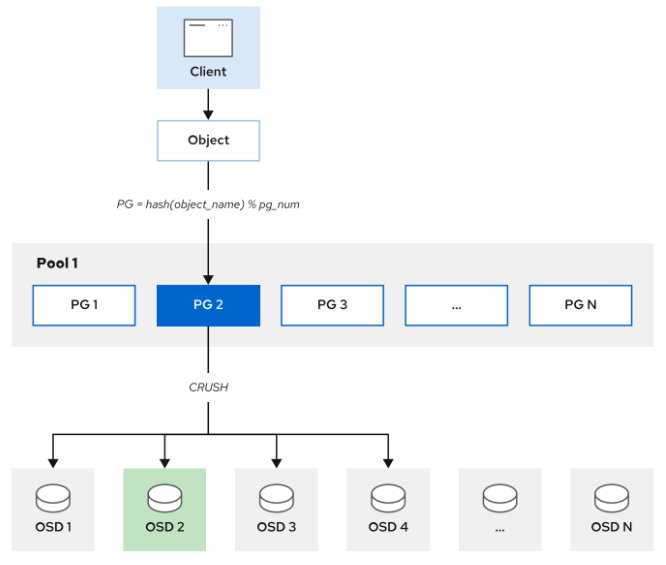
Ceph 客户端和 OSD 守护进程使用可扩展哈希下的受控复制 (CRUSH) 算法来高效地计算有关对象位置的信息,而不是依赖于中央查找表。
CRUSH映射
**CRUSH 将每个对象分配给一个放置组 (PG),也就是单个哈希存储桶, PG 将对象映射给多个OSD。**PG 是对象(应用层)和 OSD(物理层)之间的抽象层。 CRUSH 使用伪随机放置算法将对象分布在 PG 之间,并使用规则来确定 PG 到 OSD 的映射。 如果发生故障,Ceph 会将 PG 重新映射到不同的物理设备 (OSD) 并同步它们的内容以匹配配置的数据保护规则。
主要,次要OSD
与对象关联的多个OSD中,其中一个 OSD 是对象归置组的主 OSD,Ceph 客户端在读取或写入数据时总是联系主 OSD。 其他 OSD 是次要 OSD,在集群发生故障时确保数据的弹性可靠。
主要 OSD 功能:
- 服务所有 I/O 请求
- 复本和保护数据
- 检查数据一致性
- 重新平衡数据
- 恢复数据
次要 OSD 功能:
- 始终在主 OSD 的控制下行动
- 可以变为主 OSD
!WARNING
运行 OSD 的主机不得使用基于内核的客户端挂载 Ceph RBD 映像或 CephFS 文件系统。 由于内存死锁或之前会话上挂起的阻塞 I/O,挂载的资源可能会变得无响应。
**典型的Ceph集群部署方案:为每个物理磁盘创建一个OSD守护进程。**OSD也支持以更灵活的方式部署OSD守护进程,比如每个磁盘、每个主机或者每个RAID卷创建一个OSD守护进程。
**如下图:**Ceph集群包涵3个Monitor,多个OSD服务器。其中一个OSD服务器提供5个OSD,每个OSD守护进程对应一个存储设备。各个存储设备使用文件系统格式化,目前仅支持XFS文件系统。XFS文件系统上默认启用扩展属性,用于存储有关内部对象状态、快照元数据和Ceph RADOS网关ACL的信息。
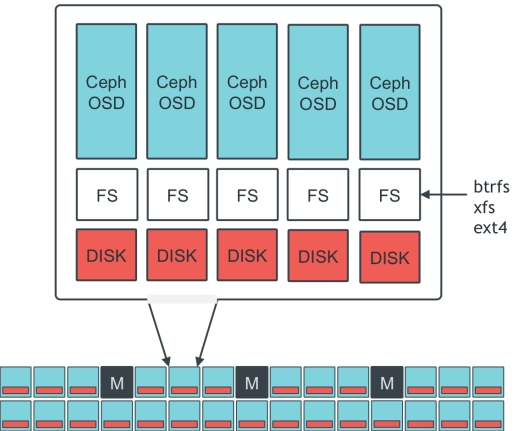
OSD日志 :每个OSD都有自己的OSD日志,OSD日志与文件系统日志无关,用于提升OSD操作写性能。**客户端的写请求常常是随机的,OSD进程按顺序将请求写入到日志。**这让主机文件系统有更多的时间来合并写操作,提高写效率,从而提高了性能。在所有OSD日志记录了写请求之后,CEPH集群通知客户端写入完成,然后将OSD日志的内容应用到后端文件系统。应用完成后,回收已经提交的日志请求,以回收日志存储设备上的空间。
-
当OSD或者存储服务器故障:如果日志未应用到文件系统,则根据日志将数据replay到文件系统;如果已经应用到后端文件系统,则根据复本恢复。
-
OSD日志最好配置为独立的、速度快的磁盘上,例如SSD,性能和写效率更好。
Ceph管理器(MGR)
- Ceph Manager(MGR)负责集群大部分数据统计。
- **如果集群中没有MGR,不会影响客户端I/O操作。**但是,将不能查询集群统计数据。为避免这种情形,建议为每个集群至少部署两个Ceph Managers,每个Managers运行在独立的失败域中。
- MGR 守护程序提供集中访问从集群收集的所有数据,并为存储管理员提供一个简单的 Web 仪表板。 MGR 守护进程还可以将状态信息导出到外部监控服务器,例如 Zabbix。
Ceph元数据服务器(MDS)
- Ceph 元数据服务器 (MDS) 管理 Ceph 文件系统 (CephFS) 元数据。
- MDS提供符合 POSIX 的共享文件系统元数据管理,包括所有权、时间戳和模式。
- MDS 使用 RADOS 存储元数据, 将文件 inode 映射到对象以及 Ceph 在树中存储数据的位置。
- 访问 CephFS 文件系统的客户端首先向 MDS 发送请求,MDS 提供客户端 获取文件内容所需的信息以便从正确的OSD获取文件内容。
集群映射(Cluster Map)
前面我们提到,MON维护集群映射。
Ceph 客户端和 OSD 通过集群映射确定数据存储位置。
五个映射表示集群拓扑,统称为集群映射。Ceph监控器守护进程维护集群映射。CephMON集群在监控器守护进程出现故障时确保高可用性。
集群映射有:
- 监视器映射(Monitor Map) , 包含集群的 fs id; 每个监视器(monitor)的位置、名称、地址和端口; 和地图时间戳。 fsid 是一个唯一的、自动生成的标识符 (UUID),用于标识 Ceph 集群。Ceph Monitor 守护进程维护集群映射。 使用 ceph mon dump 命令查看监视器图。
- OSD映射(OSD Map) , 包含集群的 fs id、池列表、复本大小、归置组编号、OSD 列表及其状态以及映射时间戳。 使用 ceph osd dump 命令查看 OSD 映射。
- 放置组映射(Placement Group Map) ,包含 PG 版本; 使用百分比; 每个归置组的详细信息,例如 PG ID、Up Set、Acting Set、PG 的状态、每个池的数据使用统计信息; 和地图时间戳。 使用 ceph pg dump 命令查看 PG Map 统计信息。
- CRUSH映射(CRUSH Map) , 包含存储设备列表、故障域层次结构(例如设备、主机、机架、行、房间)以及在存储数据时遍历层次结构的规则。 使用 ceph osd crush dump 命令查看 cursh Map 统计信息。
- 元数据服务器映射(MDS map) ,包含用于存储元数据的池、元数据服务器列表、元数据服务器状态和映射时间戳。 使用 ceph fs dump 命令查看 MDS 映射。
其他 map:
- Manager map ,包含 Manager 服务器列表、Manager 服务器状态和映射时间戳。 使用 ceph mgr dump 命令查看 MGR 映射。
- Service map ,包含RGW信息,如果集群中安装了RGW。 使用 ceph service dump 命令查看 rgw 统计信息。
第 2 章 Ceph 分布式存储 部署
Ceph 集群安装介绍
Ceph 集群安装方式
官方推荐部署方式:
- Cephadm:基于容器部署,支持 Octopus 及以后版本,部署完成后可通过命令行和图形界面进行ceph集群的管理。
- Rook:基于 kubernetes 部署,支持 Nautilus 及以后版本,部署完成后可通过命令行和图形界面进行ceph集群的管理,同时可通过 kubernetes 对组件所在 pod 进行管理。
其他部署方式:
- ceph-ansible,通过ansible进行ceph部署
- ceph-deploy,已经不再维护,不建议使用该方式部署
- DeepSea,通过salt进行ceph部署
- 手动部署
Ceph 集群 最小硬件规格
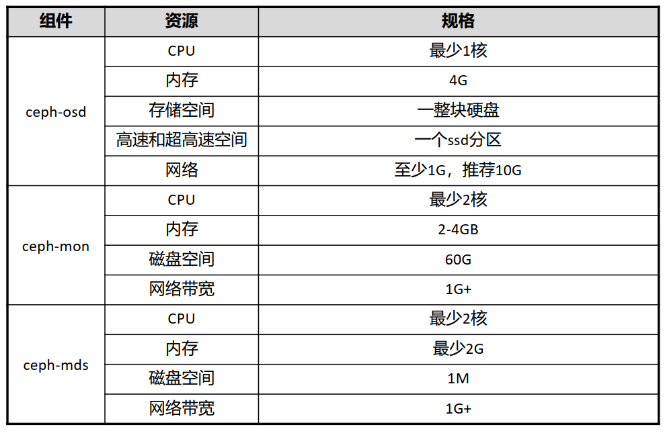
此处的最小硬件规格指的是在实际生产中的规格,实验手册中的规格会比此表中的规格小。
关于OSD的资源需注意:
- 每增加一个osd服务,就需要增加列出的资源。
- OSD的CPU资源最少是1核,后续根据带宽和IOPS进行调整,每200-500MB/s增加一核,或者每1000-3000IOPS增加一核。
- OSD的内存可以选择2G-4G,可以实现基本功能,但是会有卡顿。
Ceph 服务端口
| 服务 | 端口 | 描述 |
|---|---|---|
| MON | 6789、 3300 | 用于Ceph集群内部通信端口 |
| OSD | 6800-7300 | 每个osd占用四个端口,分别用于通过public网络与客户端和MON通信、 通过cluster网络或public网络与其他OSD数据通信、通过cluster网络或 public进行心跳数据包交换,其中用于心跳通信的端口需两个 |
| MDS | 6800-7300 | 用于与元数据服务器通信 |
| MGR | 8443 | 用于以SSL的方式登录ceph的图形化页面 |
| RESTful 管理模块 | 8003 | 用于以SSL的方式与RESTful管理模块通信 |
| Prometheus 管理模块 | 9283 | 用于与ceph的Prometheus插件通信 |
| Prometheus 告警管理 | 9093 | 用于与Prometheus的告警管理服务通信 |
| Prometheus 节点导出器 | 9100 | 用于与Prometheus节点导出器进程通信 |
| Grafana 服务器 | 3000 | 用于与Grafana服务通信 |
| RGW | 80 | 用于RADOSGW通信,如果client.rgw的配置为空, cephadm就使用默认 的80端口 |
| Ceph iSCSI 网关 | 9287 | 用于与ceph iSCSI网关通信 |
说明:
- 所有端口都是TCP协议。
- 在实验手册中,为了降低安装难度,直接关闭了firewalld及SELinux。
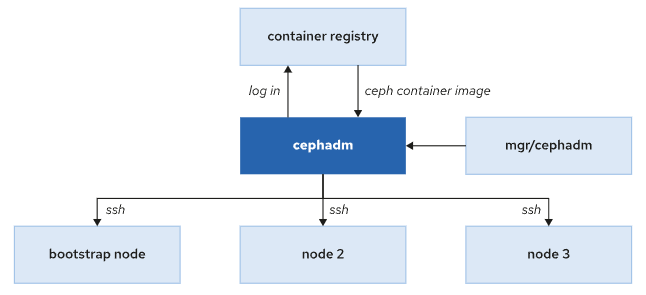
Cephadm 简介
-
Cephadm 是一个ceph全生命周期管理工具, 通过"引导( bootstrapping ) " 可创建一个包含一个MON和一个MGR的单节点集群, 后续可通过自带的编排接口进行集群的扩容、 主机添加、 服务部署。
-
Cephadm 使用容器部署 Ceph,大大降低了部署 Ceph 集群的复杂性和包依赖性。
-
cephadm 软件包安装在集群第一个节点中,该节点充当引导节点。Cephadm 是部署新集群时启动的第一个守护程序,同时也是管理器守护程序 (MGR) 中的一个模块。
Cephadm 与其他服务交互
-
Cephadm 登录容器注册表来拉取 Ceph 镜像并在使用该镜像的节点上部署服务。
-
Cephadm 使用 SSH 连接,向集群添加新主机、添加存储或监控这些主机。
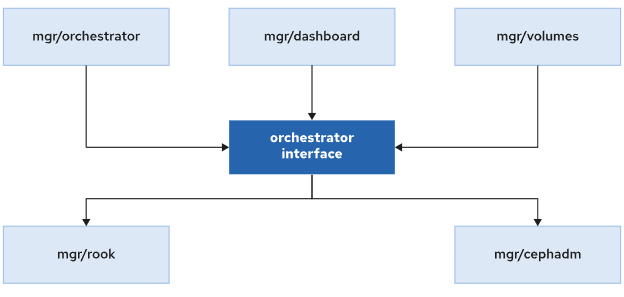
Cephadm 管理接口
Ceph 使用容器化部署,首先创建一个最小的集群,只有一个主机(引导节点)和两个守护进程(监视器和管理器守护进程)。
Ceph 提供两个管理接口:Ceph CLI 和 Dashboard GUI,用于配置 Ceph 守护进程和服务以及扩展或收缩集群。
cephadm 工具与 Ceph Manager 编排模块交互,Ceph Manager Orchestrator 再与其他组件交互:
Ceph CLI 接口
cephadm shell 命令启动一个容器化版本的 shell,容器中安装了所有必需的 Ceph 包。该命令应该只在引导节点中运行,因为在引导集群时只有该节点可以访问 /etc/ceph 中的管理密钥环。
实际情况,在集群中其他节点也可以执行,例如ceph1。
bash
[root@ceph1 ~]# cephadm shell
Inferring fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Using recent ceph image quay.io/ceph/ceph@sha256:f15b41add2c01a65229b0db515d2dd57925636ea39678ccc682a49e2e9713d98
[ceph: root@ceph1 /]# 还可以通过容器化的 shell 直接运行命令:cephadm shell -- command。
bash
[root@ceph1 ~]# cephadm shell -- ceph status
Inferring fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Using recent ceph image quay.io/ceph/ceph@sha256:f15b41add2c01a65229b0db515d2dd57925636ea39678ccc682a49e2e9713d98
cluster:
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1.dcr.cloud,ceph2,ceph3 (age 12m)
mgr: ceph2.oetbal(active, since 11m), standbys: ceph1.dcr.cloud.zoqmbt, ceph3.npaxvt
osd: 9 osds: 9 up (since 12m), 9 in (since 3w)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 1 active+clean为了操作方便,可以直接在物理主机执行ceph命令,需要安装ceph-common软件包。
bash
[root@ceph1 ~]# dnf install -y ceph-common
[root@ceph1 ~]# ceph statusCeph Dashboard 接口
Ceph Dashboard GUI 是一个基于 Web 的应用程序,用于监视和管理集群。 Ceph Dashboard GUI 得到了增强,可通过此界面执行许多集群任务,比 Ceph CLI 更直观的方式提供集群信息。
与 Ceph CLI 一样,Dashboard GUI Web 是 ceph-mgr 守护进程的一个模块。 默认情况下,Ceph 在创建集群时将 Dashboard GUI 部署在引导节点,并使用 TCP 端口 8443。
Ceph Dashboard GUI 提供以下功能:
- 用户和角色管理,用户可以创建具有多个权限和角色的不同用户帐户。
- 单点登录,仪表板 GUI 允许通过外部身份提供者进行身份验证。
- 审计,用户可以将仪表板配置为记录所有 REST API 请求。
- 安全,默认情况下,仪表板使用 SSL/TLS 来保护所有 HTTP 连接。
Ceph Dashboard GUI 还实现了集群管理和监控功能:
- 管理功能
- 使用 CRUSH 地图查看集群层次结构
- 启用、编辑和禁用管理器模块
- 创建、删除和管理 OSD
- 管理 iSCSI
- 管理池
- 监控功能
- 检查整体集群健康状况
- 查看集群中的主机及其服务
- 查看日志
- 查看集群警报
- 检查集群容量
下图显示了仪表板 GUI 的状态屏幕,可以快速查看一些重要的集群参数,例如集群状态、集群中的主机数量或 OSD 数量。
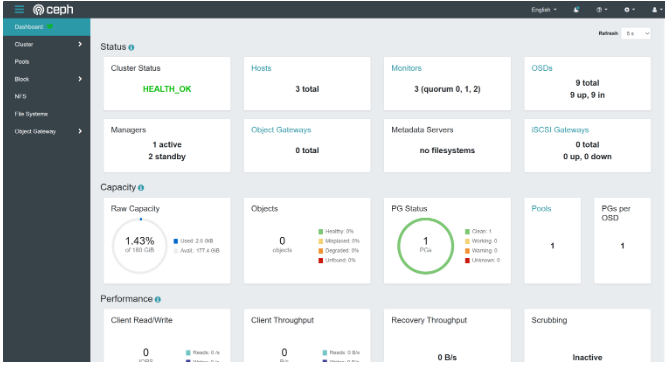
Ceph 集群安装过程
Ceph 集群环境说明
部署方法:cephadm
操作系统:Centos Stream 8(最小化安装)
硬件配置:2 cpu、4G memory、1个系统盘+3个20G数据盘
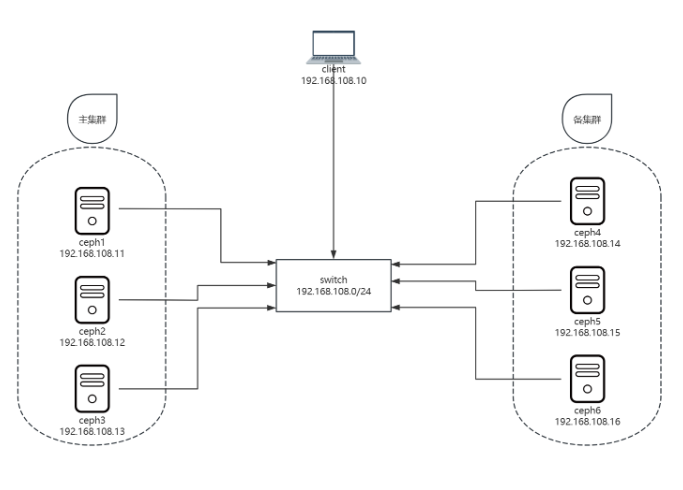
本教材共使用7台虚拟机:
- 客户端:client
- 主集群:ceph1、ceph2、ceph3
- 备集群:ceph4、ceph5、ceph6
| 主机名 | IP 地址 | 角色 |
|---|---|---|
| client.dcr.cloud | 192.168.108.10 | 客户端节点 |
| ceph1.dcr.cloud | 192.168.108.11 | 主集群-ceph 节点 |
| ceph2.dcr.cloud | 192.168.108.12 | 主集群-ceph 节点 |
| ceph3.dcr.cloud | 192.168.108.13 | 主集群-ceph 节点 |
| ceph4.dcr.cloud | 192.168.108.14 | 备集群-ceph 节点 |
| ceph5.dcr.cloud | 192.168.108.15 | 备集群-ceph 节点 |
| ceph6.dcr.cloud | 192.168.108.16 | 备集群-ceph 节点 |
网络拓扑如下图所示:
准备虚拟机模板
基于CentOS-Stream-8-template模板克隆出ceph-template
根据实验硬件要求,更改ceph-template硬件配置。
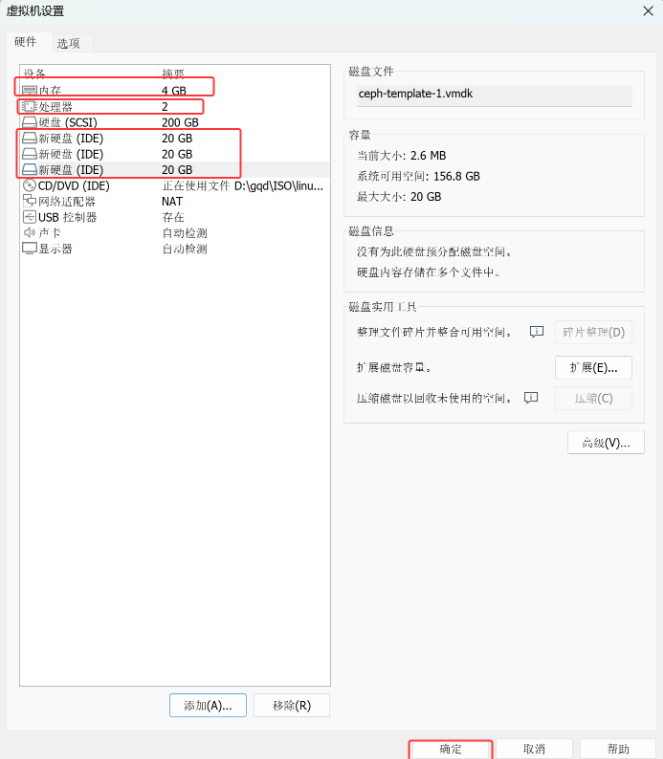
bash
# 1 配置主机名解析
[root@localhost ~]# cat >> /etc/hosts << EOF
###### ceph ######
192.168.108.10 client.dcr.cloud client
192.168.108.11 ceph1.dcr.cloud ceph1
192.168.108.12 ceph2.dcr.cloud ceph2
192.168.108.13 ceph3.dcr.cloud ceph3
192.168.108.14 ceph4.dcr.cloud ceph4
192.168.108.15 ceph5.dcr.cloud ceph5
192.168.108.16 ceph6.dcr.cloud ceph6
EOF
# 2 关闭 SELinux
[root@localhost ~]# sed -ri 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
# 3 关闭防火墙
[root@localhost ~]# systemctl disable firewalld --now
# 4 配置yum仓库
[root@localhost ~]# cat << 'EOF' > /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/centos-vault/8-stream/storage/x86_64/ceph-pacific
enabled=1
gpgcheck=0
EOF
# 5 安装基础软件包
[root@localhost ~]# dnf install -y bash-completion vim lrzsz unzip rsync sshpass tar
# 6 配置时间同步
[root@localhost ~]# dnf install -y chrony
[root@localhost ~]# systemctl enable chronyd --now
# 7 安装 cephadm
[root@localhost ~]# dnf install -y cephadm
[root@localhost ~]# cephadm --help
usage: cephadm [-h] [--image IMAGE] [--docker] [--data-dir DATA_DIR]
[--log-dir LOG_DIR] [--logrotate-dir LOGROTATE_DIR]
[--sysctl-dir SYSCTL_DIR] [--unit-dir UNIT_DIR] [--verbose]
[--timeout TIMEOUT] [--retry RETRY] [--env ENV]
[--no-container-init]
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rm-cluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,check-host,prepare-host,add-repo,rm-repo,install,registry-login,gather-facts,exporter,host-maintenance,disk-rescan}
...
Bootstrap Ceph daemons with systemd and containers.
positional arguments:
{version,pull,inspect-image,ls,list-networks,adopt,rm-daemon,rm-cluster,run,shell,enter,ceph-volume,zap-osds,unit,logs,bootstrap,deploy,check-host,prepare-host,add-repo,rm-repo,install,registry-login,gather-facts,exporter,host-maintenance,disk-rescan}
sub-command
version get ceph version from container
pull pull the default container image
inspect-image inspect local container image
ls list daemon instances on this host
......
# 安装 cephadm 的时候,会自动安装官方推荐的容器引擎 podman
[root@localhost ~]# rpm -q podman
podman-4.9.4-0.1.module_el8+971+3d3df00d.x86_64
# 8 提前下载镜像
[root@localhost ~]# podman pull quay.io/ceph/ceph:v16
[root@localhost ~]# podman pull quay.io/ceph/ceph-grafana:8.3.5
[root@localhost ~]# podman pull quay.io/prometheus/node-exporter:v1.3.1
[root@localhost ~]# podman pull quay.io/prometheus/alertmanager:v0.23.0
[root@localhost ~]# podman pull quay.io/prometheus/prometheus:v2.33.4
# 准备配置主机脚本
[root@localhost ~]# cat > /usr/local/bin/sethost <<'EOF'
#/bin/bash
hostnamectl set-hostname ceph$1.dcr.cloud
nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.108.1$1/24 ipv4.gateway 192.168.108.2 ipv4.dns 192.168.108.2
init 0
EOF
[root@localhost ~]# chmod +x /usr/local/bin/sethost关机虚拟机,并打快照。
准备集群节点
使用完全克隆方式,克隆出其他虚拟机,并配置主机名和IP地址。
bash
#ceph1到ceph6按以下修改
[root@localhost ~]# sethost 1 #ceph1用1,ceph2到ceph6分别为2-6
#client做以下修改
[root@localhost ~]# hostnamectl set-hostname client.dcr.cloud
[root@localhost ~]# nmcli connection modify ens160 ipv4.method manual ipv4.addresses 192.168.108.10/24 ipv4.gateway 192.168.108.2 ipv4.dns 192.168.108.2Ceph 集群初始化
Ceph 初始化
bash
[root@ceph1 ~]# cephadm bootstrap --mon-ip 192.168.108.11 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password dcr@123 --dashboard-password-noupdate选项说明:
- --mon-ip 192.168.108.11,指定 monitor ip。
- --allow-fqdn-hostname,指定允许使用长名称。当主机名是长名称时,初始化时必须使用该参数。
- --initial-dashboard-user admin,指定 Web UI 登录的管理员账户。
- --initial-dashboard-password dcr@123,指定 Web UI 登录的管理员账户对应密码。
- --dashboard-password-noupdate,指定不要更新 Web UI 登录密码。
输出信息如下:
yaml
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman (/usr/bin/podman) version 4.9.4 is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
Verifying IP 192.168.108.11 port 3300 ...
Verifying IP 192.168.108.11 port 6789 ...
Mon IP `192.168.108.11` is in CIDR network `192.168.108.0/24`
Mon IP `192.168.108.11` is in CIDR network `192.168.108.0/24`
Internal network (--cluster-network) has not been provided, OSD replication will default to the public_network
Pulling container image quay.io/ceph/ceph:v16...
Ceph version: ceph version 16.2.15 (618f440892089921c3e944a991122ddc44e60516) pacific (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting public_network to 192.168.108.0/24 in mon config section
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host ceph1.dcr.cloud...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph1.dcr.cloud:8443/
User: admin
Password: dcr@123
Enabling client.admin keyring and conf on hosts with "admin" label
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/en/pacific/mgr/telemetry/
Bootstrap complete.输出信息说明
Dashboard 登录信息
yaml
Ceph Dashboard is now available at:
URL: https://ceph1.dcr.cloud:8443/
User: admin
Password: dcr@123客户端访问方法
bash
Enabling client.admin keyring and conf on hosts with "admin" label
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell启用遥测
发送匿名数据给社区,以改善Ceph。
yaml
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on访问 dashboard
登录


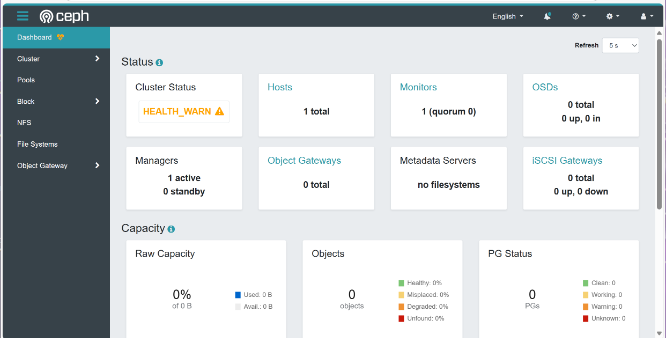
添加节点
添加节点过程:
- Ceph采用共享秘钥进行身份验证, 使用命令"ceph cephadm get-pub-key" 获取到主机接入集群时所需的ssh 公钥。
- 获取到公钥后, 使用该公钥实现对节点的免密ssh管理。
- 使用命令"ceph orch host add" 添加主机。
bash
# 为了配置方便,我们在ceph1上安装ceph客户端工具 ceph-common
[root@ceph1 ~]# dnf install -y ceph-common
# 获取集群公钥
[root@ceph1 ~]# ceph cephadm get-pub-key > ~/ceph.pub
# 推送公钥到其他节点
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph2.dcr.cloud
[root@ceph1 ~]# ssh-copy-id -f -i ~/ceph.pub root@ceph3.dcr.cloud
# 添加节点
[root@ceph1 ~]# ceph orch host add ceph2.dcr.cloud
Added host 'ceph2.dcr.cloud' with addr '192.168.108.12'
[root@ceph1 ~]# ceph orch host add ceph3.dcr.cloud
Added host 'ceph3.dcr.cloud' with addr '192.168.108.13'
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.dcr.cloud 192.168.108.11 _admin
ceph2.dcr.cloud 192.168.108.12
ceph3.dcr.cloud 192.168.108.13
3 hosts in cluster
# 等待自动部署服务到其他节点,部署完成后效果如下:
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 8m ago 9m count:1
crash 3/3 8m ago 9m *
grafana ?:3000 1/1 8m ago 9m count:1
mgr 2/2 8m ago 9m count:2
mon 3/5 8m ago 9m count:5
node-exporter ?:9100 3/3 8m ago 9m *
prometheus ?:9095 1/1 8m ago 9m count:1
# crash 3/3个
# mgr 2/2个
# mon 3/5个
# node-exporter 3/3个部署 mon 和 mgr
bash
# 禁用 mon 和 mgr 服务的自动扩展功能
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
[root@ceph1 ~]# ceph orch apply mgr --unmanaged=true
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 56s ago 12m count:1
crash 3/3 57s ago 12m *
grafana ?:3000 1/1 56s ago 12m count:1
mgr 2/2 57s ago 3s <unmanaged>
mon 3/5 57s ago 8s <unmanaged>
node-exporter ?:9100 3/3 57s ago 12m *
prometheus ?:9095 1/1 56s ago 12m count:1
# mon 和 mgr 的 PLACEMENT 状态为 <unmanaged>
# 配置主机标签,ceph2 和 ceph3 添加标签" _admin"
[root@ceph1 ~]# ceph orch host label add ceph2.dcr.cloud _admin
Added label _admin to host ceph2.dcr.cloud
[root@ceph1 ~]# ceph orch host label add ceph3.dcr.cloud _admin
Added label _admin to host ceph3.dcr.cloud
[root@ceph1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph1.dcr.cloud 192.168.108.11 _admin
ceph2.dcr.cloud 192.168.108.12 _admin
ceph3.dcr.cloud 192.168.108.13 _admin
3 hosts in cluster
# 将 mon 和 mgr 组件部署到具有_admin标签的节点上
[root@ceph1 ~]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
[root@ceph1 ~]# ceph orch apply mgr --placement="label:_admin"
Scheduled mgr update...
#观察现象
[root@ceph1 ~]# ceph orch ls | egrep 'mon|mgr'
mgr 3/3 2m ago 14s label:_admin
mon 3/3 2m ago 28s label:_admin
[root@ceph1 ~]# ceph orch ps | egrep 'mon|mgr'
部署 OSD
bash
# 将所有主机上闲置的硬盘添加为 OSD
[root@ceph1 ~]# ceph orch apply osd --all-available-devices
Scheduled osd.all-available-devices update...验证
查看集群中部署的服务
bash
[root@ceph1 ~]# ceph orch ls
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
alertmanager ?:9093,9094 1/1 3s ago 15m count:1
crash 3/3 4s ago 15m *
grafana ?:3000 1/1 3s ago 15m count:1
mgr 3/3 4s ago 2m label:_admin
mon 3/3 4s ago 2m label:_admin
node-exporter ?:9100 3/3 4s ago 15m *
osd.all-available-devices 9 4s ago 25s *
prometheus ?:9095 1/1 3s ago 15m count:1部分输出说明:
- RUNNING:服务的运行状态,前一个数字表示当前运行的服务数量,后一个数字表示系统根据策略或配置推荐的服务部署数量。
- PLACEMENT :为服务编排器部署服务时提供的参数,编排器可根据该参数判断服务所部署的节点,常见的 placement 包括:
- 具体节点名称,例如:
--placement=ceph2 - 标签,例如:
--placement="label:mylabel" - 数量,例如:
--placement="3 host1 host2 host3" unmanaged,表示服务不自动部署。通过设置--unmanaged为true打开该功能,设置为false关闭该功能>
- 具体节点名称,例如:
查看集群状态
bash
[root@ceph1 ~]# ceph -s
cluster:
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1.dcr.cloud,ceph2,ceph3 (age 6m)
mgr: ceph1.dcr.cloud.zoqmbt(active, since 15m), standbys: ceph2.oetbal, ceph3.npaxvt
osd: 9 osds: 9 up (since 30s), 9 in (since 45s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 1 active+clean命令
ceph -s对应的长命令为ceph --status。
输出包含:MON、 MGR及OSD的状态,包括数量、位置及运行时间。
集群的健康状态可分为:
- HEALTH_OK:表示健康状态良好
- HEALTH_WARN:表示集群存在告警,需进行排查处理后,可转为HEALTH_OK
- HEALTH_ERR:表示集群存在比较严重的错误,需要立即处理
查看集群 osd 结构
bash
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000查看集群组件
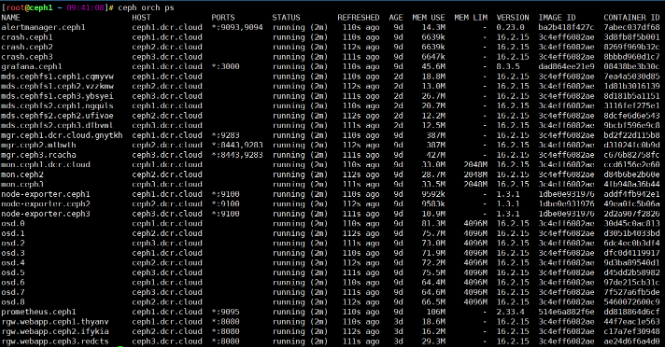
集群中运行的主要组件:
- mgr,ceph 管理程序
- monitor,ceph 监视器
- osd,ceph 对象存储进程
- rgw,ceph 对象存储网关
其他组件:
- crash,崩溃数据收集模块
- prometheus,监控组件
- grafana,监控数据展示dashboard
- alertmanager,prometheus告警组件
- node_exporter,prometheus节点数据收集组件
查询出服务的具体情况后, 可对指定服务进一步操作:
- 使用命令
ceph orch daemon start|stop|restart|redeploy|reconfig <service_name>对指定服务进行启动、停止、重启等操作。 - 使用命令
ceph orch daemon rm <service_name> [--force]可删除指定服务。
!TIP
这时关闭所有ceph存储节点。并打快照,便于后续做实验。
Ceph 集群组件管理
ceph orch 命令
ceph orch 命令与编排器模块交互,编排器模块是ceph-mgr的插件,与外部编排服务交互。
ceph orch 命令支持多个外部编排器:
- host:物理节点
- service type:服务类型,如nfs, mds, osd, mon, rgw, mgr, iscsi
- Service:逻辑服务
- Daemon:进程
cephadm使用的特殊标签:
- _no_schedule:不在此类标签的节点上部署或调度任何服务。
- _no_autotune_memory:不对此类标签的节点进行内存调优。
- _admin:自动将ceph.conf和ceph.client.admin.keyring发送到此类标签的节点上。
禁用服务自动扩展
Ceph 集群服务自动扩展功能,会自动部署ceph组件到存储节点。如果想手动管理 ceph 服务,则需要禁用 ceph 服务自动扩展功能。
bash
# 查看 mon 服务
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/3 90s ago 8m label:_admin
# 禁用 mon 服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=true
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/5 118s ago 4s <unmanaged>
# 启用 mon 服务自动扩展
[root@ceph1 ~]# ceph orch apply mon --unmanaged=false
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/5 2m ago 4s count:5
# 通过标签部署 mon 服务
[root@ceph1 ~]# ceph orch apply mon --placement="label:_admin"
Scheduled mon update...
[root@ceph1 ~]# ceph orch ls mon
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mon 3/3 3m ago 15s label:_admin删除服务
以 crash 服务为例。
bash
# 禁用服务自动扩展
[root@ceph1 ~]# ceph orch apply crash --unmanaged=true
[root@ceph1 ~]# ceph orch ls crash
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
crash 3/3 3m ago 5s <unmanaged>
# 查看服务中实例
[root@ceph1 ~]# ceph orch ps | grep crash
crash.ceph1 ceph1.dcr.cloud running (5m) 4m ago 24m 6639k - 16.2.15 3c4eff6082ae 5aea4634442b
crash.ceph2 ceph2.dcr.cloud running (5m) 4m ago 15m 6639k - 16.2.15 3c4eff6082ae 51d5f1e1d75c
crash.ceph3 ceph3.dcr.cloud running (4m) 4m ago 15m 6647k - 16.2.15 3c4eff6082ae 406b2a7b9d93
# 删除特定实例
[root@ceph1 ~]# ceph orch daemon rm crash.ceph1
Removed crash.ceph1 from host 'ceph1.dcr.cloud'
[root@ceph1 ~]# ceph orch ps | grep crash
crash.ceph2 ceph2.dcr.cloud running (9m) 8m ago 19m 6639k - 16.2.15 3c4eff6082ae 51d5f1e1d75c
crash.ceph3 ceph3.dcr.cloud running (8m) 8m ago 19m 6647k - 16.2.15 3c4eff6082ae 406b2a7b9d93
# 删除服务
[root@ceph1 ~]# ceph orch rm crash
Removed service crash
[root@ceph1 ~]# ceph orch ls crash #这里需要快点查看
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
crash 1/3 <deleting> 50s <unmanaged>
[root@ceph1 ~]# ceph orch ls crash
No services reported部署服务
使用 ceph 的编排器部署服务, 有两种方式:
-
apply 方式:定义了服务状态,由编排器根据参数自动寻找合适的节点进行服务部署。
语法:
ceph orch apply <service_type> [--placement=<placement_string>] [--unmanaged]例如:
ceph orch apply crash和ceph orch apply mon --placement="label:_admin"。 -
daemon add 方式:根据命令中的参数,直接进行服务部署。
语法:
ceph orch daemon add <daemon_type> <placement>
命令orch apply osd [--all-available-devices]将节点上的所有可用设备配置为OSD。
删除 OSD
确定 OSD 和设备关系
bash
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1 #主机ceph1下的硬盘
0 hdd 0.01949 osd.0 up 1.00000 1.00000 #看不出来osd.0对应哪块磁盘
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000
# 获取集群id
[root@ceph1 ~]# ceph -s | grep id
id: 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
# 登录到ceph1上确认osd.0使用的块设备
[root@ceph1 ~]# ls -l /var/lib/ceph/2faf683a-7cbf-11f0-b5ba-000c29e0ad0e/osd.0/block
lrwxrwxrwx 1 ceph ceph 93 Aug 19 14:01 /var/lib/ceph/2faf683a-7cbf-11f0-b5ba-000c29e0ad0e/osd.0/block -> /dev/ceph-c92942fb-f959-4255-b8e6-751fab70fa79/osd-block-2ed79b2f-d825-4829-b4b0-59879d2ad99c
# 59879d2ad99c是块设备名称最后一串字符
[root@ceph1 ~]# lsblk | grep -B1 59879d2ad99c
sdb 8:16 0 20G 0 disk
└─ceph--c92942fb--f959--4255--b8e6--751fab70fa79-osd--block--2ed79b2f--d825--4829--b4b0--59879d2ad99c 253:4 0 20G 0 lvm
# 确认osd.0对应sdb脚本实现
bash[root@ceph1 ~]# vim /usr/local/bin/show-osd-device
bashcluster_id=$(ceph -s|grep id |awk '{print $2}') cd /var/lib/ceph/${cluster_id} for osd in osd.* do device_id=$(ls -l $osd/block | awk -F '-' '{print $NF}') device=/dev/$(lsblk |grep -B1 ${device_id} |grep -v ${device_id} | awk '{print $1}') echo $osd : $device done
bash[root@ceph1 ~]# chmod +x /usr/local/bin/show-osd-device执行效果
bash[root@ceph1 ~]# show-osd-device osd.0 : /dev/sdb osd.3 : /dev/sdc osd.6 : /dev/sdd
使用编排删除(重点)
示例:删除 osd.0
bash
# 禁用 osd 服务自动扩展
[root@ceph1 ~ 09:48:09]# ceph orch apply osd --all-available-devices --unmanaged=true
[root@ceph1 ~ 09:48:09]# ceph orch ls osd
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
osd.all-available-devices 6 7m ago 6s <unmanaged>
# 删除 osd.0
[root@ceph1 ~ 09:49:46]# ceph orch osd rm 0
[root@ceph1 ~ 09:50:31]# ceph orch ls osd
osd.all-available-devices 8 3m ago 68s <unmanaged>
[root@ceph1 ~ 09:51:30]# lsblk | grep -A1 sdb
sdb 8:16 0 20G 0 disk
└─ceph--4c51a7f5--7bd6--493a--9100--21e42af14e0f-osd--block--3a562e7e--5c5a--4635--8043--b3504ab7be2a 253:4 0 20G 0 lvm
[root@ceph1 ~ 09:51:56]# ceph orch device ls
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph1.dcr.cloud /dev/sdb hdd VMware_Virtual_I_00000000000000000001 20.0G 5m ago Has a FileSystem, Insufficient space (<10 extents) on vgs, LVM detected
....
#查看磁盘发现数据没有被删除
# 删除device上数据
[root@ceph1 ~ 09:52:26]# ceph orch device zap ceph1.dcr.cloud /dev/sdb --force #看osd0管理的是/dev/sdb还是啥
zap successful for /dev/sdb on ceph1.dcr.cloud
# 确认结果
[root@ceph1 ~ 09:53:01]# lsblk | grep -A1 sdb
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
[root@ceph1 ~ 09:54:06]# ceph orch device ls | grep ceph1.*sdb
ceph1.dcr.cloud /dev/sdb hdd VMware_Virtual_I_00000000000000000001 20.0G Yes 77s ago
# 添加回来
[root@ceph1 ~ 09:54:21]# ceph orch apply osd --all-available-devices
[root@ceph1 ~ 09:56:06]# ceph orch ls osd
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
osd.all-available-devices 9 9m ago 24s * 注意删除osd顺序:
- 确认ceph节点对应哪个osd 并且osd于ceph节点中的磁盘如何对应
- 设置osd服务禁止自动扩展(防止删除后自动加回来)
- 删除osd(这里相当于解除osd 和磁盘之间的联系,但是磁盘里的数据并没有删除)
- zap 清空磁盘数据
手动删除过程
bash
# 停止 ceph1 中的 osd
[root@ceph1 ~]# ceph orch daemon stop osd.0
Scheduled to stop osd.0 on host 'ceph1.dcr.cloud'
[root@ceph1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host ceph1
0 hdd 0.01949 osd.0 down 1.00000 1.00000 #查看osd.0 down了
3 hdd 0.01949 osd.3 up 1.00000 1.00000
6 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host ceph2
2 hdd 0.01949 osd.2 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.05846 host ceph3
1 hdd 0.01949 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.00000
# 待 osd 停止后,删除 osd 进程
[root@ceph1 ~]# ceph orch daemon rm osd.0 --force #可以ps aux|grep osd.0观察
Removed osd.0 from host 'ceph1.dcr.cloud'
# 从 crush map 中剔除 osd
[root@ceph1 ~]# ceph osd out 0
marked out osd.0.
# 从 crush map 中删除 osd
[root@ceph1 ~]# ceph osd crush rm osd.0
removed item id 0 name 'osd.0' from crush map
# 执行下面的命令将会自动标记为out,并且从crush map中删除,最后删除osd相关文件。
[root@ceph1 ~]# ceph osd rm 0
removed osd.0
# 删除device上数据
[root@ceph1 ~]# ceph orch device zap ceph1.dcr.cloud /dev/sdb --force
zap successful for /dev/sdb on ceph1.dcr.cloud
# 确认结果
[root@ceph1 ~]# ceph orch device ls|grep 'ceph1.*sdb'
ceph1.dcr.cloud /dev/sdb hdd 20.0G Yes 10s ago
# 添加回来
[root@ceph1 ~]# ceph orch apply osd --all-available-devices删除主机
从集群中删除主机流程:
- 禁用集群所有服务自动扩展
- 查看待删除主机上当前运行的服务
- 停止待删除主机上的所有服务
- 删除主机上的所有服务
- 删除osd在CRUSH中的映射
- 擦除osd盘中的数据
- 从集群中删除主机
示例:删除 ceph2
首先,禁用集群中所有ceph服务自动扩展,进制自动部署osd。
bash
[root@ceph1 ~]# for service in $(ceph orch ls |grep -v -e NAME -e osd| awk '{print $1}');do ceph orch apply $service --unmanaged=true;done
[root@ceph1 ~]# ceph orch apply osd --all-available-devices --unmanaged=true其次,删除主机上运行的服务。
bash
# 查看ceph2上运行的daemon
[root@ceph1 ~]# ceph orch ps |grep ceph2 |awk '{print $1}'
crash.ceph2
mgr.ceph2.oetbal
mon.ceph2
node-exporter.ceph2
osd.2
osd.4
osd.7
# 删除相应 daemon
[root@ceph1 ~]# for daemon in $(ceph orch ps |grep ceph2 |awk '{print $1}');do ceph orch daemon rm $daemon --force;done
# 手动清理crush信息
[root@ceph1 ~]# ceph osd crush rm osd.2
[root@ceph1 ~]# ceph osd crush rm osd.4
[root@ceph1 ~]# ceph osd crush rm osd.7
[root@ceph1 ~]# ceph osd crush rm ceph2
[root@ceph1 ~]# ceph osd rm 2 4 7
# 清理磁盘数据
[root@ceph1 ~]# ceph orch device zap ceph2.dcr.cloud /dev/sdb --force
[root@ceph1 ~]# ceph orch device zap ceph2.dcr.cloud /dev/sdc --force
[root@ceph1 ~]# ceph orch device zap ceph2.dcr.cloud /dev/sdd --force然后,删除主机。
bash
[root@ceph1 ~]# ceph orch host rm ceph2
[root@ceph1 ~]# ceph orch host ls #查看现象ceph2被移除
HOST ADDR LABELS STATUS
ceph1.dcr.cloud 192.168.108.11 _admin
ceph3.dcr.cloud 192.168.108.13 _admin
2 hosts in cluster最后,删除ceph2中相应ceph遗留文件。
bash
[root@ceph2 ~]# rm -rf /var/lib/ceph
[root@ceph2 ~]# rm -rf /etc/ceph /etc/systemd/system/ceph*
[root@ceph2 ~]# rm -rf /var/log/ceph实验完成后,恢复环境。
恢复环境-还原快照
第 3 章 Ceph 分布式存储 集群配置
管理集群配置
Ceph 集群配置概述
Ceph 配置选项具有唯一名称,该名称由下划线连接的小写字符组成。有些配置选项会包含短划线(中横杠)或空格字符。推荐做法:使用下划线。
Ceph 守护进程会从以下某个来源访问其配置:
- 编译中的默认值
- 集中配置数据库
- 存储在本地主机上的配置文件
- 环境变量
- 命令行参数
- 运行时覆盖
当存在多个设置源时,配置生效原则:
- 较新设置将覆盖较早设置源中的设置。
- 配置文件会在启动时配置守护进程。
- 配置文件设置会覆盖存储在中央数据库中的设置。
- 监控器 (MON) 节点管理集中配置数据库。
生效过程:
- 启动时,Ceph 守护进程解析命令行选项、环境变量和本地集群配置文件提供的配置选项。
- 然后,守护进程会联系 MON 集群来检索存储在集中配置数据库中的配置选项。
注意:Ceph 存储优先使用集中配置数据库中配置,弃用 ceph.conf 集群配置文件。
修改集群配置文件
Ceph会去以下目录中查找集群相关配置文件:
- CEPH_CONF 环境变量中包含的路径
- -c path/path:由命令行参数"-c"指定的路径
- ./$cluster.conf
- ~/.ceph/$cluster.conf
- /etc/ceph/$cluster.conf,默认位置。
每个 Ceph 节点都会存储一个本地配置文件,默认位置是 /etc/ceph/ceph.conf。cephadm 工具会使用最小选项集创建初始 Ceph 配置文件。
配置文件采用 INI 文件格式,其中内容涵盖 Ceph 守护进程和客户端配置。每个部分都使用 [name] 标头定义的名称,以及一个或多个键值对参数。
ini
[name]
parameter1 = value1
parameter2 = value2使用井号 (#) 或分号 (😉 禁用设置或添加注释。
在引导集群时,可以借助集群配置文件,自定义引导集群。
示例:
bash
# cephadm bootstrap --config ceph-config.yaml配置部分
Ceph 使用所应用的守护进程或客户端的部分,将配置选项分组,确定是存储在配置文件中还是存储在配置数据库中。
- global 部分,存储所有守护进程(包括客户端)共有的一般配置,可为单个守护进程或客户端创建调用部分来覆盖 global 参数。
- mon 部分,存储监控器 (MON) 的配置。
- osd 部分,存储 OSD 守护进程的配置。
- mgr 部分,存储管理器 (MGR) 的配置。
- mds 部分,存储元数据服务器 (MDS) 的配置。
- client 部分,存储应用到所有 Ceph 客户客户端的配置。
良好的示例文件参见 /usr/share/doc/ceph/sample.ceph.conf,该文件由 ceph-common 软件包提供。
实例设置
实例设置适用于特定守护进程,名称格式为:[daemon-type.instance-ID]。
ini
[mon]
# Settings for all mon daemons
[mon.ceph1]
# Settings that apply to the specific MON daemon running on ceph1同样的名称还适用于 osd、mgr、mds 和 client 部分。
- OSD 守护进程的实例 ID 始终为数字,例如 osd.0。
- 客户端的实例 ID 是有效的用户名,例如 client.operator3。
元变量
元变量是由 Ceph 定义的变量。用户可使用它们来简化配置。
- $cluster ,Ceph 存储 5 集群的名称。默认集群名称为 ceph。
- $type ,守护进程类型,如监控器的值为 mon 。OSD 使用 osd ,元数据服务器使用 mds ,管理器使用 mgr ,客户端软件使用 client。
- i d ∗ ∗ ,守护进程实例 I D 。对于此变量, ∗ ∗ c e p h 1 ∗ ∗ 上监控器的值为 ∗ ∗ c e p h 1 ∗ ∗ 。 ∗ ∗ o s d . 1 ∗ ∗ 的 ∗ ∗ id**,守护进程实例 ID。对于此变量,**ceph1** 上监控器的值为 **ceph1**。**osd.1** 的 ** id∗∗,守护进程实例ID。对于此变量,∗∗ceph1∗∗上监控器的值为∗∗ceph1∗∗。∗∗osd.1∗∗的∗∗id 值为 1 ,客户端应用的值为用户名。
- n a m e ∗ ∗ ,守护进程名称和实例 I D 。此变量是 ∗ ∗ name**,守护进程名称和实例 ID。此变量是 ** name∗∗,守护进程名称和实例ID。此变量是∗∗type.$id 的简写。
- $host,运行守护进程的主机的名称。
bash
## Metavariables
# $cluster ; Expands to the Ceph Storage Cluster name. Useful
# ; when running multiple Ceph Storage Clusters
# ; on the same hardware.
# ; Example: /etc/ceph/$cluster.keyring
# ; (Default: ceph)
#
# $type ; Expands to one of mds, osd, or mon, depending on
# ; the type of the instant daemon.
# ; Example: /var/lib/ceph/$type
#
# $id ; Expands to the daemon identifier. For osd.0, this
# ; would be 0; for mds.a, it would be a.
# ; Example: /var/lib/ceph/$type/$cluster-$id
#
# $host ; Expands to the host name of the instant daemon.
#
# $name ; Expands to $type.$id.
# ; Example: /var/run/ceph/$cluster-$name.asok使用集群配置数据库
集群配置数据库由 MON 节点集中管理:
- 在守护进程启动之前,暂时更改设置。
- 在守护进程运行时,更改大部分设置。
- 将永久设置存储在数据库中。
Ceph集中配置数据库默认存放在 MON 节点 /var/lib/ceph/ f s i d / m o n . fsid/mon. fsid/mon.host/store.db中。
使用 ceph config 命令,查询和配置集中配置数据库。
ceph config ls
列出集群数据库中所有配置条目。
bash
[root@ceph1 ~ 11:18:23]# ceph config ls | head
host
fsid
public_addr
public_addrv
public_bind_addr
cluster_addr
public_network
public_network_interface
cluster_network
cluster_network_interface
[root@ceph1 ~ 11:19:51]# ceph config ls | wc -l
2077ceph config help <key>
查看集群数据库中特定配置帮助信息。 是 ceph config ls 命令列出的条目。
bash
[root@ceph1 ~ 11:17:32]# ceph config help host
host - local hostname
(str, basic)
Default:
Can update at runtime: false
Services: [common]
Tags: [network]
if blank, ceph assumes the short hostname (hostname -s)
[root@ceph1 ~ 11:17:57]# ceph config help fsid
fsid - cluster fsid (uuid)
(uuid, basic)
Default: 00000000-0000-0000-0000-000000000000
Can update at runtime: false
Services: [common]
Tags: [service]ceph config dump
显示集群配置数据库设置。
bash
[root@ceph1 ~ 11:19:43]# ceph config dump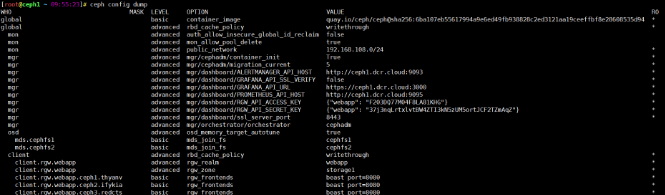
ceph config show t y p e . type. type.id ``
显示特定守护进程当前生效的设置,包含部分默认设置。
bash
[root@ceph1 ~]# ceph config show mon.ceph1.dcr.cloud
[root@ceph1 ~]# ceph config show mon.ceph1.dcr.cloud public_network
192.168.108.0/24
ceph config show-with-defaults t y p e . type. type.id
显示特定守护进程当前生效的设置,包含默认设置。
bash
[root@ceph1 ~ 11:35:57]# ceph config show-with-defaults mon.ceph1.dcr.cloud
NAME VALUE
admin_socket $run_dir/$cluster-$name.asok
admin_socket_mode
auth_allow_insecure_global_id_reclaim false
auth_client_required cephx, none
auth_cluster_required cephx
auth_debug false
auth_expose_insecure_global_id_reclaim true
auth_mon_ticket_ttl 259200.000000
auth_service_required cephx
auth_service_ticket_ttl 3600.000000
auth_supported
bdev_aio true
......ceph config get t y p e . type. type.id ``
获得集群数据库中特定配置设置。永久值
bash
[root@ceph1 ~ 11:37:12]# ceph config get mon.ceph1.dcr.cloud
WHO MASK LEVEL OPTION VALUE RO
mon advanced auth_allow_insecure_global_id_reclaim false
global basic container_image quay.io/ceph/ceph@sha256:6ba107eb55617994a9e6ed49fb938828c2ed3121aa19ceeffbf8e28608535d94 *
mon advanced public_network 192.168.108.0/24 *
[root@ceph1 ~]# ceph config get mon.ceph1.dcr.cloud public_network
192.168.108.0/24ceph config set t y p e . type. type.id <key> <value>
设置集群数据库中特定配置选项。
bash
# 设置特定类型所有实例
[root@ceph1 ~ 11:40:50]# ceph config set mon mon_allow_pool_delete false
# 设置特定类型特定实例
[root@ceph1 ~ 11:41:47]# ceph config set mon.ceph1.dcr.cloud mon_allow_pool_delete true
[root@ceph1 ~ 11:42:12]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
trueceph config rm t y p e . type. type.id ``
清除集群数据库中特定配置选项。--删除该参数还原默认配置的意思
bash
[root@ceph1 ~ 11:43:12]# ceph config rm mon.ceph1.dcr.cloud mon_allow_pool_delete
[root@ceph1 ~ 11:43:55]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
falseceph config log [<num:int>]
显示集群最近配置历史记录,默认显示10条,类似于linux中history命令。
bash
[root@ceph1 ~ 11:44:18]# ceph config log
--- 16 --- 2025-11-27T03:43:55.734360+0000 ---
- mon.ceph1.dcr.cloud/mon_allow_pool_delete = true
--- 15 --- 2025-11-27T03:42:12.086242+0000 ---
+ mon.ceph1.dcr.cloud/mon_allow_pool_delete = true
--- 14 --- 2025-11-27T03:41:47.272279+0000 ---
+ mon/mon_allow_pool_delete = false
--- 13 --- 2025-11-26T03:53:53.406125+0000 ---
....
# 只显示最近更改的两条记录
[root@ceph1 ~ 11:44:26]# ceph config log 2
--- 16 --- 2025-11-27T03:43:55.734360+0000 ---
- mon.ceph1.dcr.cloud/mon_allow_pool_delete = true
--- 15 --- 2025-11-27T03:42:12.086242+0000 ---
+ mon.ceph1.dcr.cloud/mon_allow_pool_delete = trueceph config reset [<num:int>]
回滚集群数据中特定配置为 num 指定的历史版本。
准备实验环境:
bash
[root@ceph1 ~ 11:46:28]# ceph config set mon.ceph1.dcr.cloud mon_allow_pool_delete true
[root@ceph1 ~ 11:46:47]# ceph config set mon.ceph1.dcr.cloud mon_allow_pool_delete false
[root@ceph1 ~ 11:46:55]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
false
#此刻为false
[root@ceph1 ~ 11:47:29]# ceph config log 3
--- 18 --- 2025-11-27T03:46:55.884288+0000 ---
- mon.ceph1.dcr.cloud/mon_allow_pool_delete = true
+ mon.ceph1.dcr.cloud/mon_allow_pool_delete = false
--- 17 --- 2025-11-27T03:46:47.684391+0000 ---
+ mon.ceph1.dcr.cloud/mon_allow_pool_delete = true
--- 16 --- 2025-11-27T03:43:55.734360+0000 ---
- mon.ceph1.dcr.cloud/mon_allow_pool_delete = true回滚配置到log 17的版本
bash
[root@ceph1 ~ 11:47:41]# ceph config reset 17
[root@ceph1 ~ 11:48:40]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
true
[root@ceph1 ~ 11:48:43]# ceph config log 1
--- 19 --- 2025-11-27T03:48:40.329760+0000 --- reset to 17 ---
- mon.ceph1.dcr.cloud/mon_allow_pool_delete = false
+ mon.ceph1.dcr.cloud/mon_allow_pool_delete = true集群引导选项
集群引导选项提供启动集群所需的信息。MON 读取 monmap 和 ceph.conf 文件,以确定如何与其他 MON 通信,并与其他 MON 并建立仲裁。
mon_ip 选项列出集群监控器。**此选项必不可少,并且不能存储在配置数据库中。**为避免使用集群配置文件,Ceph 集群支持使用 DNS 服务记录提供 mon_host 列表。
本地集群配置文件 ceph.conf 还可包含其他选项:
- mon_host_override,集群监视器的初始列表。
- mon_dns_serv_name,用于检查通过 DNS 识别的集群监控器的 DNS SRV 记录的名称。
- mon_data、osd_data 、mds_data 、mgr_data,定义守护进程的本地数据存储目录。
- keyring 、keyfile 和 key,使用监控器进行身份验证的身份验证凭据。
在运行时覆盖配置设置
Ceph支持在守护进程运行时,临时更改大部分配置选项。
ceph tell 命令
ceph tell $type.$id config 命令可临时覆盖配置选项,并要求所配置的MON和守护进程都在运行。
ceph tell $type.$id config show,获取守护进程的所有运行时设置。ceph tell $type.$id config get,获取守护进程的特定运行时设置。ceph tell $type.$id config set,设置守护进程的特定运行时设置。当守护进程重启时,这些临时设置将恢复为原始值。
示例:
bash
[root@ceph1 ~ 13:58:37]# ceph tell mon.ceph1.dcr.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "true"
}
[root@ceph1 ~ 14:00:40]# ceph tell mon.ceph1.dcr.cloud config set mon_allow_pool_delete false
{
"success": "mon_allow_pool_delete = 'false' "
}
# 临时更改的值已生效
[root@ceph1 ~ 14:01:08]# ceph tell mon.ceph1.dcr.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "false"
}
# 集群数据库中值仍然为true
[root@ceph1 ~ 14:01:21]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
true
# 重启守护进程,生效的值恢复为数据库中设置的值
[root@ceph1 ~ 14:02:06]# ceph orch daemon restart mon.ceph1.dcr.cloud
[root@ceph1 ~ 14:03:23]# ceph tell mon.ceph1.dcr.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "true"
}注意:使用此命令更改的设置在守护进程重启后会恢复为原始设置。
ceph tell $type.$id config 命令接受通配符,以获取或设置同一类型的所有守护进程的值。
bash
[root@ceph1 ~ 14:04:36]# ceph tell mon.* config get mon_allow_pool_delete
mon.ceph1.dcr.cloud: {
"mon_allow_pool_delete": "true"
}
mon.ceph2: {
"mon_allow_pool_delete": "false"
}
mon.ceph3: {
"mon_allow_pool_delete": "false"
}ceph daemon 命令
Ceph支持在集群特定节点上使用 ceph daemon $type.$id config 命令临时覆盖配置选项。该命令不需要连接 MON ,但要求对应的守护进程要运行,所以即使 MON 未运行,该命令仍可发挥作用,有助于故障排除。
-
ceph daemon $type.$id config show,获得特定守护进程运行时所有设置。bash# 在ceph1上只能查看和设置ceph1上运行的相关进程设置 [root@ceph1 ~ 14:04:43]# cephadm shell [ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config show | wc -l 1812 [ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config show { "name": "mon.ceph1.dcr.cloud", "cluster": "ceph", "admin_socket": "/var/run/ceph/ceph-mon.ceph1.dcr.cloud.asok", "admin_socket_mode": "", "auth_allow_insecure_global_id_reclaim": "false", "auth_client_required": "cephx, none", "auth_cluster_required": "cephx", "auth_debug": "false", "auth_expose_insecure_global_id_reclaim": "true", "auth_mon_ticket_ttl": "259200.000000", "auth_service_required": "cephx", ...... -
ceph daemon $type.$id config get,获得守护进程运行时特定设置。bash[ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config get mon_allow_pool_delete { "mon_allow_pool_delete": "true" } -
ceph daemon $type.$id config set,设置守护进程运行时特定设置。bash[ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config set mon_allow_pool_delete false { "success": "mon_allow_pool_delete = 'false' " } [ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config get mon_allow_pool_delete { "mon_allow_pool_delete": "false" }
注意:使用此命令更改的设置在守护进程重启后会恢复为原始设置。
bash
[ceph: root@ceph1 /]# ceph orch daemon restart mon.ceph1.dcr.cloud
Scheduled to restart mon.ceph1.dcr.cloud on host 'ceph1.dcr.cloud'
[ceph: root@ceph1 /]# ceph daemon mon.ceph1.dcr.cloud config get mon_allow_pool_delete
{
"mon_allow_pool_delete": "true"
}
[ceph: root@ceph1 /]# exit
exitWeb UI 更改
-
打开 Web 浏览器并导航到 https://ceph1.dcr.cloud:8443。必要时,接受证书警告。
输入用户名(admin)和密码(dcr@123) 登录。
-
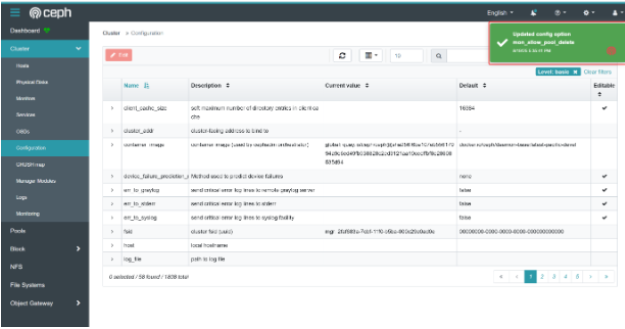
在 Ceph 控制面板 Web UI 中,单击 Cluster > Configuration 以显示 Configuration Settings 页面。
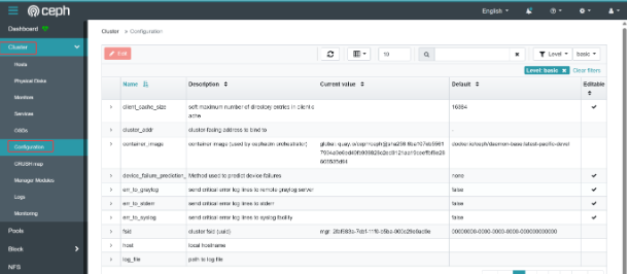
-
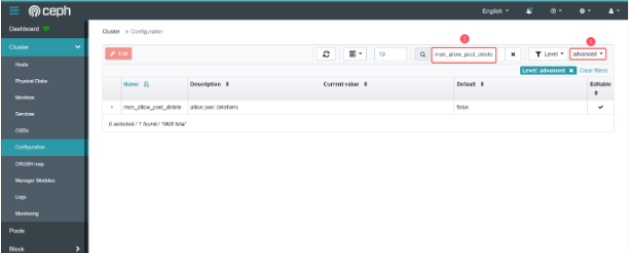
从 advanced 菜单中选择 advanced 选项,以查看高级配置选项。在搜索栏中键入mon_allow_pool_delete 来查找设置。
-
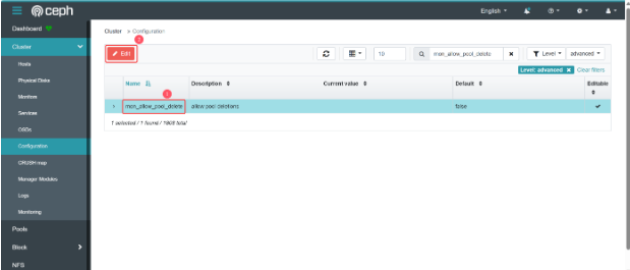
单击 mon_allow_pool_delete,然后单击 Edit。
-
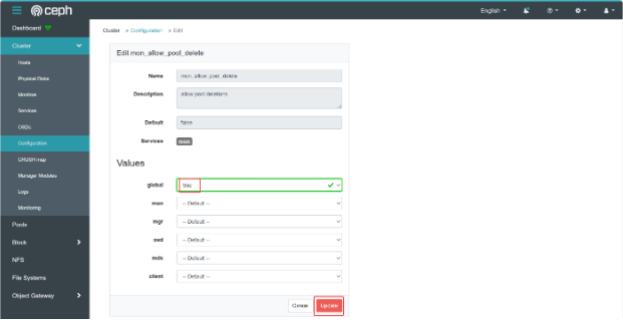
编辑 mon_allow_pool_delete 设置,将 global 值设置为 true,然后单击Update。
-
控制面板会显示一条消息,以确认新的设置。
配置集群监控器 Monitor
配置 Ceph 监控器
Ceph监控器(MON)存储和维护客户端用于查找MON和OSD节点的集群映射。Ceph客户端必须连接到MON以检索集群映射,然后才能读取或写入任何数据到OSD。因此,正确配置集群MON至关重要。
MON 采用 一种 Paxos 变体算法来选举领导者,在分布式计算机集之间达成一致。
各MON分别具有以下其中一个角色:
- Leader:第一个获得集群映射最新版本的 MON。
- Provider:拥有最新版本的集群映射,但不是 Leader 的 MON。
- Requester :没有最新版本的集群映射,必须先与 Provider 同步,然后才能重新加入仲裁的 MON。
**一旦有新的 MON 加入集群,便会进行同步。**每个 MON 都会定期检查相邻监控器是否已有更新版本的集群映射。如果相邻 MON 具有新版本的集群映射,则必须同步并获取相应集群映射。
**集群中的大多数 MON 必须处于运行状态,以建立仲裁。**例如,如果部署了五个 MON,则必须运行三个才能建立仲裁。**在生产 Ceph 集群中至少部署三个 MON 节点,以确保高可用性。**Ceph 支持在运行中的集群中添加或删除 MON。
集群配置文件 mon 块中 mon_host 定义 MON 主机 IP 地址(或 DNS 名称)和端口。cephadm 工具不会更新集群配置文件,可以通过第三方工具,例如rsync,让集群配置文件在集群节点之间保持同步的策略。
ini
[global]
fsid = 2faf683a-7cbf-11f0-b5ba-000c29e0ad0e
mon_host = [v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0] [v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0] [v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0]**重要:**在集群部署和运行期间,建议不要更改 MON 节点 IP 地址。
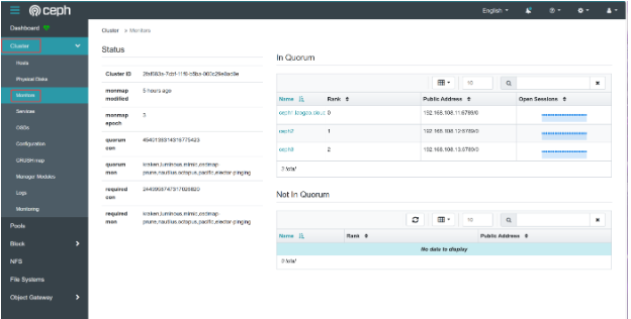
查看监控器仲裁
-
ceph status命令,检查 MON 仲裁状态。bash[root@ceph1 ~ 14:09:31]# ceph status | grep mon mon: 3 daemons, quorum ceph1.dcr.cloud,ceph2,ceph3 (age 66m) -
ceph mon stat命令,检查 MON 仲裁状态。bash[root@ceph1 ~ 15:16:40]# ceph mon stat e3: 3 mons at {ceph1.dcr.cloud=[v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0],ceph2=[v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0],ceph3=[v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0]} removed_ranks: {}, election epoch 72, leader 0 ceph1.dcr.cloud, quorum 0,1,2 ceph1.dcr.cloud,ceph2,ceph3 -
ceph quorum_status -f json-pretty命令,友好的 json 格式输出 MON 仲裁状态。bash[root@ceph1 ~ 15:19:02]# ceph quorum_status -f json-prettyjson{ "election_epoch": 72, "quorum": [ 0, 1, 2 ], "quorum_names": [ "ceph1.dcr.cloud", "ceph2", "ceph3" ], "quorum_leader_name": "ceph1.dcr.cloud", "quorum_age": 4168, "features": { "quorum_con": "4540138314316775423", "quorum_mon": [ "kraken", "luminous", "mimic", "osdmap-prune", "nautilus", "octopus", "pacific", "elector-pinging" ] }, "monmap": { "epoch": 3, "fsid": "58744eb6-ca7b-11f0-bfae-000c293dede4", "modified": "2025-11-26T06:34:15.902487Z", "created": "2025-11-26T03:52:43.457591Z", "min_mon_release": 16, "min_mon_release_name": "pacific", "election_strategy": 1, "disallowed_leaders: ": "", "stretch_mode": false, "tiebreaker_mon": "", "removed_ranks: ": "", "features": { "persistent": [ "kraken", "luminous", "mimic", "osdmap-prune", "nautilus", "octopus", "pacific", "elector-pinging" ], "optional": [] }, "mons": [ { "rank": 0, "name": "ceph1.dcr.cloud", "public_addrs": { "addrvec": [ { "type": "v2", "addr": "192.168.108.11:3300", "nonce": 0 }, { "type": "v1", "addr": "192.168.108.11:6789", "nonce": 0 } ] }, "addr": "192.168.108.11:6789/0", "public_addr": "192.168.108.11:6789/0", "priority": 0, "weight": 0, "crush_location": "{}" }, { "rank": 1, "name": "ceph2", "public_addrs": { "addrvec": [ { "type": "v2", "addr": "192.168.108.12:3300", "nonce": 0 }, { "type": "v1", "addr": "192.168.108.12:6789", "nonce": 0 } ] }, "addr": "192.168.108.12:6789/0", "public_addr": "192.168.108.12:6789/0", "priority": 0, "weight": 0, "crush_location": "{}" }, { "rank": 2, "name": "ceph3", "public_addrs": { "addrvec": [ { "type": "v2", "addr": "192.168.108.13:3300", "nonce": 0 }, { "type": "v1", "addr": "192.168.108.13:6789", "nonce": 0 } ] }, "addr": "192.168.108.13:6789/0", "public_addr": "192.168.108.13:6789/0", "priority": 0, "weight": 0, "crush_location": "{}" } ] } } -
控制面板中查看 MON 的状态:单击Cluster > Monitor。
分析监控器映射
Ceph 集群映射包含:
- MON 映射
- OSD 映射
- PG 映射
- MDS 映射
- CRUSH 映射
MON 映射包含:
- 集群 fsid(文件系统 ID),fsid 是一种自动生成的唯一标识符 (UUID),用于标识 Ceph 集群。
- 各个 MON 节点通信的名称、IP 地址和网络端口。
- 映射版本信息,如 epoch 和最近一次更改时间。MON 节点通过同步更改并就当前版本达成一致来维护映射。
查看当前的 MON 映射
bash
[root@ceph1 ~ 15:19:17]# ceph mon dump
epoch 3
fsid 58744eb6-ca7b-11f0-bfae-000c293dede4 #采集集群fsid
last_changed 2025-11-26T06:34:15.902487+0000
created 2025-11-26T03:52:43.457591+0000
min_mon_release 16 (pacific)
election_strategy: 1
0: [v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0] mon.ceph1.dcr.cloud
1: [v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0] mon.ceph2
2: [v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0] mon.ceph3
dumped monmap epoch 3管理集中配置数据库
MON 节点存储和维护集中配置数据库。数据库文件位于 MON 节点,默认位置是:
/var/lib/ceph/$fsid/mon.$host/store.db。
**注意:**不建议更改数据库的位置。
数据库文件会不断增大,改进措施:
-
运行
ceph tell mon.$id compact命令,整合数据库,以提高性能。bash[root@ceph1 ~ 15:22:47]# ceph config get mon.ceph1.dcr.cloud mon_compact_on_start false [root@ceph1 ~ 15:23:57]# ceph tell mon.ceph1.dcr.cloud compact compacted rocksdb in 0 seconds -
将
mon_compact_on_start配置选项为 TRUE ,以便在每次守护进程启动时压缩数据库。bash[root@ceph1 ~ 15:24:39]# ceph config set mon mon_compact_on_start true [root@ceph1 ~ 15:25:28]# ceph config get mon mon_compact_on_start true
设置以下数据库文件大小相关定义,以触发运行状况变化:
- mon_data_size_warn ,当配置数据库文件的大小超过此值时,集群运行状况更改为HEALTH_WARN 。默认值是15 (GB)。
- mon_data_avail_warn ,当包含配置数据库文件的文件系统剩余容量小于或等于此百分比时,将集群运行状况更改为 HEALTH_WARN 。默认值是30 (%)。
- mon_data_avail_crit ,当包含配置数据库的文件系统剩余容量小于或等于此百分比 时,将集群运行状况更改为 HEALTH_ERR 。默认值是5 (%)。
集群验证
Ceph 默认使用 Cephx 协议进行加密身份验证,同时使用共享密钥进行身份验证。默认情况下,Ceph 会启用 Cephx。如有必要,可以禁用 Cephx,但不建议这样做,因为这样会减弱集群的安全性。
使用 ceph config set 命令启用或禁用 Cephx 协议。
bash
[root@ceph1 ~ 15:26:07]# ceph config get mon auth_service_required
cephx
[root@ceph1 ~ 15:26:14]# ceph config get mon auth_client_required
cephx, none
[root@ceph1 ~ 15:26:22]# ceph config get mon auth_cluster_required
cephx参数说明:
- auth_service_required ,客户端与Ceph services之间通信认证。可用值
cephx和none。 - auth_cluster_required ,Ceph集群守护进程之间通信认证,例如
ceph-mon,ceph-osd,ceph-mds,ceph-mgr。可用值cephx和none。 - auth_client_required ,客户端与Ceph集群之间通信认证。可用值
cephx和none。
官方原话:If this configuration setting is enabled, then Ceph clients can access Ceph services only if those clients authenticate with the Ceph Storage Cluster. Valid settings are
cephxornone.
cephadm 工具创建 client.admin 用户,让用户能够运行管理命令并创建其他 Ceph 客户端用户帐户,用户密钥环存储在 /etc/ceph 目录中。
bash
[root@ceph1 ~ 15:26:32]# ls /etc/ceph/
ceph.client.admin.keyring ceph.conf ceph.pub rbdmap守护进程数据目录包含 Cephx 密钥环文件。对于 MON,密钥环文件是:
/var/lib/ceph/ f s i d / m o n . fsid/mon. fsid/mon.host/keyring。
bash
[root@ceph1 ~ 15:26:47]# ls /var/lib/ceph/58744eb6-ca7b-11f0-bfae-000c293dede4/mon.ceph1.dcr.cloud/keyring
/var/lib/ceph/58744eb6-ca7b-11f0-bfae-000c293dede4/mon.ceph1.dcr.cloud/keyring**密钥环文件以纯文本形式存储机密密钥。**务必使用合适的 Linux 文件权限来保护它们的安全。
使用ceph auth命令创建、查看和管理集群
使用 ceph-authtool 命令创建密钥环文件。
示例:为 MON 节点创建一个密钥环文件。
bash
[root@ceph1 ~ 15:28:57]# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
creating /tmp/ceph.mon.keyring
# --create-keyring /tmp/ceph.mon.keyring
创建一个新的密钥环文件(Keyring),路径为 /tmp/ceph.mon.keyring。
# --gen-key -n mon.
生成一个新密钥(--gen-key)。
-n mon. 指定密钥关联的实体名称(Entity Name),这里是 mon.(表示 Monitor 守护进程)。
注意:实体名称通常以守护进程类型开头(如 mon.、osd.),后接节点标识符(如 mon.a)。
# --cap mon 'allow *'
为该密钥分配权限(Capabilities):
mon 表示权限作用于 Monitor 服务。
'allow *' 授予 所有 Monitor 操作的完全权限(如访问集群状态、修改配置等)。cephadm 工具还会在**/etc/ceph目录中创建client.admin**用户,让您能够运行管理命令并创建其他Ceph客户端用户帐户。
配置集群网络-了解即可
配置公共网络和集群网络
public 网络是所有Ceph集群通信的默认网络。cephadm 工具假定第一个MON守护进程IP地址的网络是public 网络。新的MON守护进程部署在public网络中,除非您明确定义了不同的网络。
Ceph客户端通过集群的public 网络直接向OSD发送请求。OSD复制和恢复流量会使用public 网络,除非您为此配置了单独的cluster网络。
配置单独的cluster 网络可能会减少public网络的流量负载并与后端OSD运维流量进行客户端分流,从而提高集群的性能。
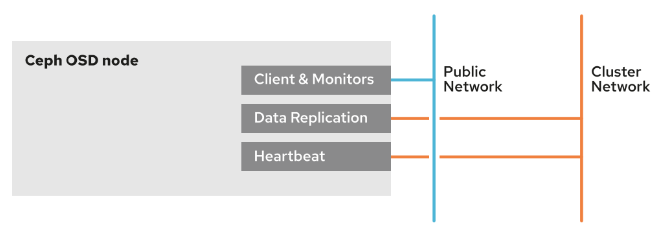
通过执行以下步骤,配置独立 cluster 网络的节点。
-
在每个集群节点上配置一个额外的网络接口。
-
在每个节点的新网络接口上配置适当的 cluster 网络 IP 地址。
-
cephadm bootstrap命令使用--cluster-network选项,在集群引导时定义 cluster网络。
Ceph 支持使用集群配置文件来设置 Public 网络和 Cluster 网络,还可以为每个网络配置多个子网,用逗号分隔。使用 CIDR 表示法表示子网,例如172.25.250.0/24。
ini
[global]
public_network = 192.168.108.0/24,192.168.109.0/24
cluster_network = 192.168.101.0/24!IMPORTANT
如果为一个网络配置多个子网,这些子网必须能够互相路由。
还可以使用 ceph config set 命令设置 Public 和 cluster 网络。
配置单个守护进程
MON 守护进程需绑定到特定的 IP 地址,但 MGR、OSD 和 MDS 守护进程可绑定至任何可用的 IP 地址。在Ceph 存储 5 中,cephadm 使用 Public 网络执行大部分服务。若要处理 cephadm 部署新守护进程的位置,需先定义服务要使用的特定子网。只有在同一子网中有 IP 地址的主机可用于部署该服务。
将 192.168.108.0/24 子网设置为 MON 守护进程公共网络:
bash
# ceph config set mon public_network 192.168.108.0/24以上命令相当于在集群配置文件中做如下设置:
ini
[mon]
public_network = 192.168.108.0/24使用 ceph orch daemon add 命令可将守护进程手动部署到特定子网或 IP 地址。
bash
# ceph orch daemon add mon cluster-host02:192.168.108.0/24
# ceph orch daemon rm mon.cluster-host01!TIP
建议使用服务规范文件来管理 Ceph 集群,不建议使用运行时
ceph orch daemon命令更改配置。
运行 IPv6
默认情况下,集群 ms_bind_ipv4 设置的值是 TRUE ,而 ms_bind_ipv6 设置的值是FALSE。
bash
# ceph config get mon.ceph1.dcr.cloud ms_bind_ipv4
true
# ceph config get mon.ceph1.dcr.cloud ms_bind_ipv6
false要将 Ceph 守护进程绑定至 IPv6 地址,需要:
-
将 ms_bind_ipv6 设置为 TRUE
-
将 ms_bind_ipv4 设置为 FALSE
同时绑定 public_network 和 cluster_network 为IPv6网络。
ini
[global]
public_network = <IPv6 public-network/netmask>
cluster_network = <IPv6 cluster-network/netmask>启用巨型帧
配置网络 MTU 来支持巨型帧是存储网络中的推荐做法,可以提升性能。在 cluster 网络接口上配置 MTU 值 9000,以支持巨型帧。
!IMPORTANT
通信路径中的所有节点和网络设备必须具有相同的MTU值。对于绑定网络接口,在绑定接口上设置MTU值,基础接口将继承相同的MTU值。
配置网络安全
配置独立的 cluster 网络可以提高集群的安全性和可用性:
- 防止数据在 Public 网络上泄露。
- 减少 Public 网络上的攻击面。
- 防止针对集群某些类型的拒绝服务 (DoS) 攻击。
- 防止 OSD 之间的流量中断。当 OSD 之间的流量中断时,客户端会无法读取和写入数据。
确保流量不在 cluster 和 Public 网络之间路由,以保护后端 cluster 网络。
配置防火墙规则
Ceph OSD 和 MDS 守护进程默认绑定到 6800 到 7300 之间的 TCP 端口。若要配置不同的范围,需更改 ms_bind_port_min 和 ms_bind_port_max 设置。
下表列出了Ceph 存储 5 的默认端口。
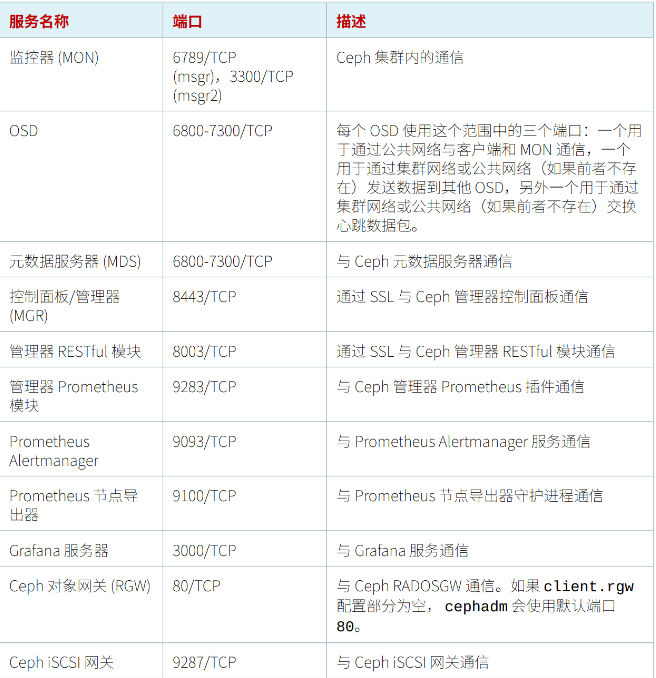
若要使用防火墙保护 MON 节点,需使用 Public 接口和 Public 网络 IP 地址来配置规则。
bash
# firewall-cmd --zone=Public --add-port=6789/tcp --add-port=3300/tcp
# firewall-cmd --zone=Public --add-port=6789/tcp --add-port=3300/tcp --permanent还可通过添加 ceph-mon 服务至防火墙规则来保护 MON 节点。
bash
# firewall-cmd --zone=Public --add-service=ceph-mon
# firewall-cmd --zone=Public --add-service=ceph-mon --permanent若要配置 cluster 网络,防火墙需要配置 Public 和 cluster 网络规则。客户端通过使用公共网络连接到 OSD,OSD 通过集群网络互相通信。
若要使用防火墙规则保护 OSD 节点,执行以下命令:
bash
# firewall-cmd --zone=<public-or-cluster> --add-port=6800-7300/tcp
# firewall-cmd --zone=<public-or-cluster> --add-port=6800-7300/tcp --permanent还可通过添加 ceph 服务至防火墙规则来保护 OSD 节点。
bash
# firewall-cmd --zone=<public-or-cluster> --add-service=ceph
# firewall-cmd --zone=<public-or-cluster> --add-service=ceph --permanent 第 4 章 Ceph 分布式存储 池管理
Ceph 数据组织结构
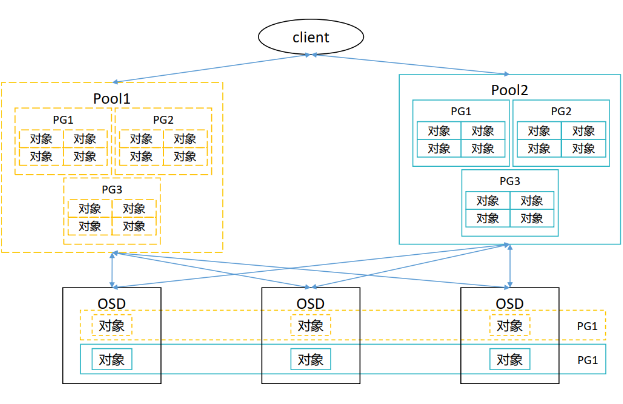
POOL
池是 Ceph 存储集群的逻辑分区,用于在通用名称标签下存储对象。 Ceph 为每个池分配特定数量放置组 (PG),用于对对象进行分组以进行存储。
每个池具有以下可调整属性:
- 池 ID
- 池名称
- PG 数量
- CRUSH 规则,用于确定此池的 PG 映射
- 保护类型(复本或擦除编码)
- 与保护类型相关的参数
- 影响集群行为的各种标志
Place Group
PG 全称为Placement group, 是构成pool的子集, 也是一系列对象的集合。一个PG仅能属于一个Pool。
Ceph 将每个 PG 映射到一组 OSD。属于同一个 PG 的所有对象都返回相同的哈希结果。
PG 数量会影响ceph的性能:
- 如果pg数量过多,数据移动时,每个PG维护的数据量过少, ceph占用大量的cpu 和内存计算,影响集群正常客户端使用。
- 如果pg数量过少,单个pg存储的数据就越多,移动pg会占用大量带宽,影响集群客户端使用
在以前版本中, PG的计算公式为:
- Ceph集群PG 总数 = (OSD 数 * 100) / 最大副本数
- 单个资源池PG总数 = (OSD 数 * 100) / 最大副本数 / 池数
以上公式中计算出的结果必须舍入到最接近2的N次幂的值。
一般情况下,PG数量设置遵循以下原则:
- 如果OSD少于5个时, PG 数量设置为128
- OSD数量大于5小于10时, PG数量设置为512
- OSD数量大于10小于50时, PG数量设置为4096
- 如果osd数量大于50,则需要借助工具进行计算,官方工具链接为: https://old.ceph.com/pgcalc/。
映射对象到OSD
客户端在进行数据读写时, 仅需向ceph提供资源池(pool)的名称和对象ID。一个完整的对象由三部分组成:对象ID、二进制数据、对象元数据。
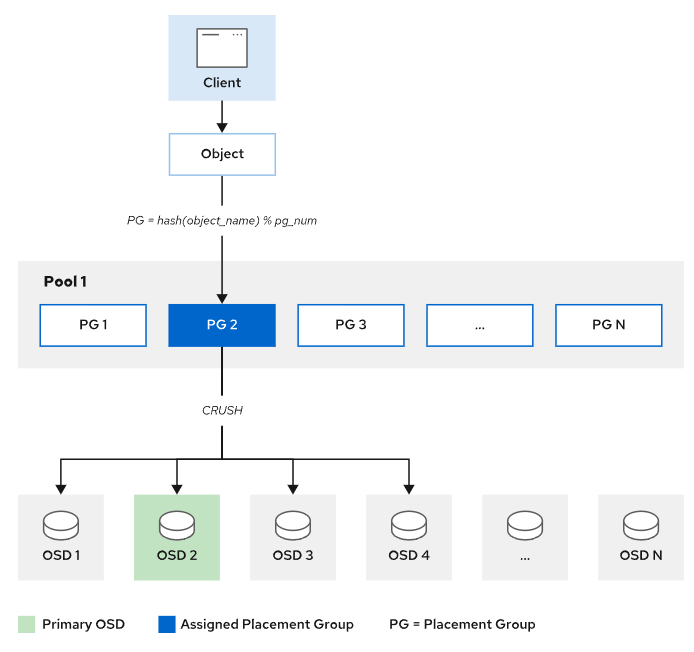
-
**Ceph 客户端从 MON 获取最新的集群映射复本。**集群映射向客户端提供有关集群中所有 MON、OSD 和 MDS 的信息,但不向客户提供对象的位置。
-
计算 PG ID。公式:PG ID=hash(Object ID)%(PG number)。
为了计算PG ID,Ceph需要知道对象存储池的名称和对象ID:根据池的名称获取池的PG数量,然后对Ceph对象 ID 做hash运算,最终计算出PG ID。
-
Ceph 使用 CRUSH 算法确定PG 负责哪些 OSDs (Acting Set)。 Acting Set 中的 OSD 在 Up Set 中。 Up Set 中的第一个 OSD 是对象归置组的当前主 OSD,Up Set 中的其他 OSD 是辅助 OSD。
-
Ceph 客户端直接跟主 OSD 通信以读写对象。
客户端访问ceph流程
- 客户端向MON集群发起连接请求。
- 客户端和MON建立连接后,它将索引最新版本的cluster map,从而获取到MON、 OSD和MDS的信息,但不包括对象的存储位置。
- client根据CRUSH算法计算出对象对应的PG和OSD。
- client根据上步中计算得出主OSD的位置,然后和其进行通信,完成对象的读写。
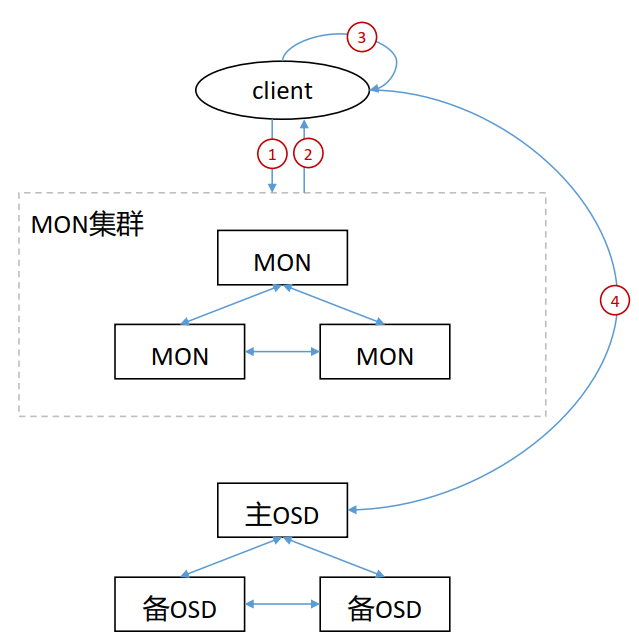
在 ceph 中,客户端自行计算对象存储位置的速度要比通过和ceph组件交互来查询对象存储位置快很多,因此,在数据读写时,都是客户端根据CRUSH完成对象的位置计算。
Ceph 数据读取流程
- 客户端通过MON获取到cluster map。
- client通过cluster map获取到主OSD节点信息,并向其发送读取请求。
- 主OSD将client请求的数据返回给client。
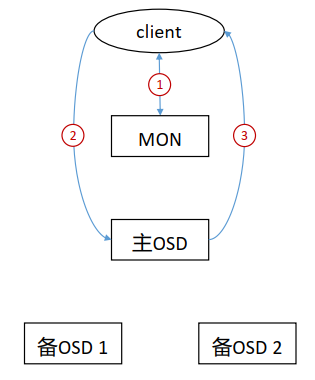
Ceph 数据写入流程
- 客户端通过 MON 获取到 cluster map。
- 客户端通过cluster map获取到主OSD节点信息,并向其发送写入请求。
- 主OSD收到写入请求后,将数据写入,并向两个备OSD发起数据写入指令。
- 两个备OSD将数据写入后返回确认到主OSD。
- 主OSD收到所有备OSD写入完成后的确认后,向客户端返回写入完成的确认。
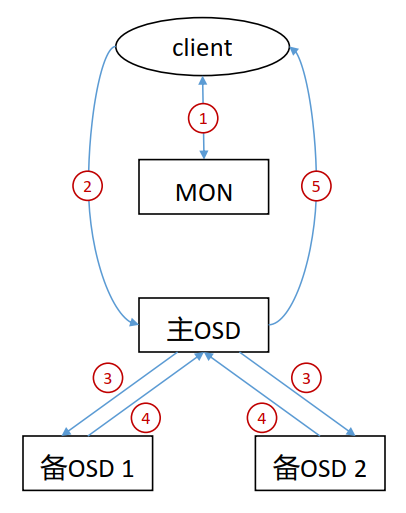
Ceph 采用数据强一致性来保证数据的同步。强一致性会导致数据写入有较大的延迟,因此ceph进行了优化,将数据的写入分两次进行:
- 第一次当所有数据都写入OSD节点的缓存后,向client发送一次确认, client就会认为数据写入完成,继续进行后面操作。
- 第二次当所有数据都从缓存写入到磁盘后,再向client发送一次确认, client就会认为数据彻底写入,从而根据需要删除对应的本地数据。
数据保护
Ceph 存储支持:复本池 和纠删码池。
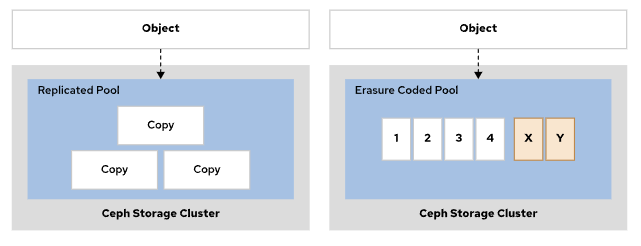
-
replicated pool(复本池),通过将各个对象复本到多个 OSD 来发挥作用。此池类型会创建多个对象复本,需要较多存储空间,但其通过冗余提高了读取操作的可用性。
-
Erasure code pool(纠删代码池),需要较少的存储空间和网络带宽,但因为要进行奇偶校验计算,所以会占用较多的 CPU处理时间。
注意:池一旦创建完成,池的类型便无法更改。
池类型选择:
- 对于不需要频繁访问且不需要低延迟的数据,推荐使用纠删代码池。
- 对于需要频繁访问并且要具备快速读取性能的数据,推荐使用复本池。
创建池
创建复本池
Ceph 为每个对象创建多个复本来保护复本池中的数据。Ceph 使用CRUSH 故障域来确定存储数据的操作集的主要 OSD。然后,主要 OSD 会查找池的当前复本数量,并计算要写入对象的次要 OSD。在主要 OSD 收到写入确认并完成数据写入后,主要 OSD 会向 Ceph 客户端确认写入操作已成功。如果一个或多个 OSD 出现故障,这一过程可保护对象中的数据。
创建复本池语法:
bash
ceph osd pool create pool-name pg-num pgp-num replicated crush-rule-name其中:
-
pool_name,指定新池的名称。
-
pg_num,指定池的放置组 (PG) 总数。
-
pgp_num,指定池的有效放置组数量。将它设置为与 pg_num 相等。该值可省略。
-
replicated ,指定池的类型为复本池;如果命令中未包含此参数,这是默认值。
-
crush-rule-name,指定池的 CRUSH 规则集的名称。
osd_pool_default_crush_replicated_ruleset 配置参数设置其默认值。
示例:
bash
[root@ceph1 ~ 09:26:38]# ceph osd pool create pool_web 32 32 replicated
pool 'pool_web' created
[root@ceph1 ~ 09:31:11]# ceph osd pool ls
device_health_metrics
pool_web创建纠删代码池
纠删代码池使用纠删代码保护对象数据。 在纠删代码池中存储的对象分割为多个数据区块,这些数据区块存储在不同的 OSD 中。编码块的数量是根据数据块计算的,并存储在不同的 OSD 中。当 OSD 出现故障时,可利用编码块重构对象数据。主要 OSD 接收写入操作,然后将载荷编码为 K+M 块,并将它们发给纠删代码池中的次要OSD。
以下概括了纠删代码池的工作方式:
-
每个对象的数据分割为 k 个数据区块,计算出 m 个编码区块。
-
对象存储在总共 k + m 个 OSD 中。
-
编码区块大小与数据区块大小相同。
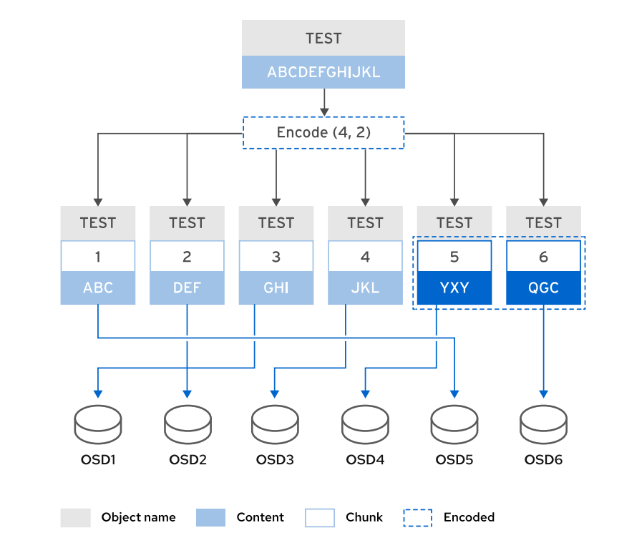
与复本相比,纠删代码使用存储容量的效率更高。复本池维护对象的 n 个复本,而纠删代码仅维护 k + m 个区块。
例如,具有 3 个复本的复本池要使用 3 倍存储空间。而 k=4 和 m=2 的纠删代码池仅要使用 1.5 倍存储空间。
支持以下 k+m 值,其对应的可用与原始比为:
- 4+2(比率为 1:1.5)
- 8+3(比率为 1:1.375)
- 8+4(比率为 1:1.5)
纠删代码池有效容量百分比:k / (k+m)。例如,如果用户有 64 个 OSD(每个 4 TB,总计 256 TB)并且 k=8 和 m=4,那么公式为 8 / (8+4) * 64 * 4 = 170.67。然后,将原始存储容量除以开销就能得出该比率。256 TB/170.67 TB 等于 1.5 比率。
创建纠删代码池语法:
bash
ceph osd pool create pool-name pg-num pgp-num erasure erasure-code-profile crush-rule-name- pool-name,指定新池的名称。
- pg-num,指定池的放置组 (PG) 总数。
- pgp-num,指定池的有效放置组数量。通常而言,这应当与 PG 总数相等。
- erasure,指定池的类型是纠删代码池。
- erasure-code-profile,指定池使用的纠删代码配置文件的名称。默认情况下,Ceph 使用 default 配置文件。
- crush-rule-name 是要用于这个池的 CRUSH 规则集的名称。如果不设置,Ceph 将使用纠删代码池配置文件中定义的规则集。
**纠删代码池无法使用对象映射功能。**对象映射是对象的一个索引,用于跟踪 rbd 对象的块会被分配到哪里,可用于提高大小调整、导出、扁平化和其他操作的性能。
示例:
bash
[root@ceph1 ~ 09:31:25]# ceph osd pool create pool_era 32 32 erasure
pool 'pool_era' created
[root@ceph1 ~ 09:32:07]# ceph osd pool ls
device_health_metrics
pool_web
pool_era查看默认纠删代码配置
bash
[root@ceph1 ~]# ceph osd erasure-code-profile ls
default
[root@ceph1 ~]# ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
technique=reed_sol_van管理纠删代码配置文件
纠删代码配置文件可配置纠删代码池用于存储对象的数据区块和编码区块的数量,以及要使用的纠删代码插件和算法。
创建纠删代码配置文件语法如下:
bash
ceph osd erasure-code-profile set profile-name arguments可用的参数如下:
- k,在不同 OSD 之间拆分的数据区块数量。默认值为 2。
- m,数据变得不可用之前可以出现故障的 OSD 数量。默认值为 1。
- directory,此可选参数是插件库的位置。默认值为 /usr/lib64/ceph/erasure-code。
- plugin,此可选参数定义要使用的纠删代码算法。
- crush-failure-domain,此可选参数定义 CRUSH 故障域,它控制区块放置。默认设置为 host,这样可确保对象的区块放置到不同主机的 OSD 上。如果设置为 osd,则对象的区块可以放置到同一主机的 OSD 上。如果主机出现故障,则该主机上的所有 OSD 都会出现故障。故障域可用于确保将区块放置到不同数据中心机架或其他定制的主机上的 OSD 上。
- crush-device-class,此可选参数选择仅将这一类别设备支持的 OSD 用于池。典型的类别可能包括 hdd、ssd 或nvme。
- crush-root,此可选参数设置 CRUSH 规则集的根节点。
- key=value,插件可以具有对该插件唯一的键值参数。
- technique,每个插件提供一组不同的技术来实施不同的算法。
示例:
bash
[root@ceph1 ~ 09:32:16]# ceph osd erasure-code-profile set ceph k=4 m=2列出现有的就删代码配置文件
bash
[root@ceph1 ~ 09:33:27]# ceph osd erasure-code-profile ls
ceph
defaultCeph 会在安装期间创建 default 配置文件。这个配置文件已配置为将对象分割为2个数据区块和2个编码区块。
查看现有配置文件的详细信息
bash
[root@ceph1 ~ 09:33:55]# ceph osd erasure-code-profile get ceph
crush-device-class=
crush-failure-domain=host
crush-root=default
jerasure-per-chunk-alignment=false
k=4
m=2
plugin=jerasure
technique=reed_sol_van
w=8删除现有的配置文件
bash
[root@ceph1 ~ 09:34:40]# ceph osd erasure-code-profile rm ceph
[root@ceph1 ~ 09:34:59]# ceph osd erasure-code-profile ls
default重要:现有纠删代码配置文件是无法修改或更改,只能创建新的配置文件。
查看 池 状态
使用 ceph osd pool ls 命令,可以列出池清单。
bash
[root@ceph1 ~ 09:35:02]# ceph osd pool ls
device_health_metrics
pool_web
pool_era使用 ceph osd pool ls detail 命令,可以列出池清单和池的详细配置。
bash
[root@ceph1 ~ 09:35:14]# ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 62 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr_devicehealth
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 69 flags hashpspool stripe_width 0
pool 3 'pool_era' erasure profile default size 4 min_size 3 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 73 flags hashpspool stripe_width 8192使用 ceph osd lspools 命令,也可以列出池清单。
bash
[root@ceph1 ~ 09:35:38]# ceph osd lspools
1 device_health_metrics
2 pool_web
3 pool_era使用 ceph osd pool stats 命令,可以列出池状态信息,池被哪些客户端使用。
bash
[root@ceph1 ~ 09:36:08]# ceph osd pool stats
pool device_health_metrics id 1
nothing is going on
pool pool_web id 2
nothing is going on
pool pool_era id 3
nothing is going on使用 ceph df 命令,可以查看池容量使用信息。
bash
[root@ceph1 ~ 09:36:24]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
TOTAL 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 8.5 KiB 3 25 KiB 0 56 GiB
pool_web 2 32 0 B 0 0 B 0 56 GiB
pool_era 3 32 0 B 0 0 B 0 84 GiB管理 池
管理 池 应用类型
使用 ceph osd pool application 命令,管理池 Ceph 应用类型。应用类型有cephfs(用于 Ceph 文件系统) 、rbd(Ceph 块设备)和 rgw(RADOS 网关)。
bash
[root@ceph1 ~ 09:59:07]# ceph osd pool application <tab><tab>
disable enable get rm set
# 启用池的类型为rbd
[root@ceph1 ~ 09:59:07]# ceph osd pool application enable pool_web rbd
enabled application 'rbd' on pool 'pool_web'
[root@ceph1 ~ 10:00:11]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 76 flags hashpspool stripe_width 0 `application rbd` <------ #看这的变化
# 使用set子命令,设置池的应用类型详细配置
[root@ceph1 ~ 10:00:32]# ceph osd pool application set pool_web rbd app1 apache
set application 'rbd' key 'app1' to 'apache' on pool 'pool_web'
# 这里添加的设置,app1=apache仅供参考,没有实际意义。
# 使用get子命令,查看池的应用类型详细配置
[root@ceph1 ~ 10:01:29]# ceph osd pool application get pool_web
{
"rbd": {
"app1": "apache"
}
}
# 使用rm子命令,删除池的应用类型详细配置
[root@ceph1 ~ 10:01:57]# ceph osd pool application rm pool_web rbd app1
removed application 'rbd' key 'app1' on pool 'pool_web'
[root@ceph1 ~ 10:02:36]# ceph osd pool application get pool_web
{
"rbd": {}
}
# 禁用池的类型
[root@ceph1 ~ 10:02:58]# ceph osd pool application disable pool_web rbd
Error EPERM: Are you SURE? Disabling an application within a pool might result in loss of application functionality; pass --yes-i-really-mean-it to proceed anyway
#需要加上--yes-i-really-mean-it
[root@ceph1 ~ 10:03:31]# ceph osd pool application disable pool_web rbd --yes-i-really-mean-it
disable application 'rbd' on pool 'pool_web'
[root@ceph1 ~ 10:03:49]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 79 flags hashpspool stripe_width 0管理 池 配额
使用 ceph osd pool get-quota 命令,获取池配额信息:池中能够存储的最大字节数或最大对象数量。
bash
[root@ceph1 ~ 10:04:15]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A使用 ceph osd pool set-quota 命令,可以设置池配额来限制池中能够存储的最大字节数或最大对象数量。
bash
[root@ceph1 ~ 10:43:06]# ceph osd pool set-quota pool_web max_objects 100000
set-quota max_objects = 100000 for pool pool_web
[root@ceph1 ~ 10:43:50]# ceph osd pool set-quota pool_web max_bytes 10G
set-quota max_bytes = 10737418240 for pool pool_web
[root@ceph1 ~ 10:44:21]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: 100k objects (current num objects: 0 objects)
max bytes : 10 GiB (current num bytes: 0 bytes)当池使用量达到池配额时,操作将被阻止。用户可通过将该值设置为 0 来删除配额。
bash
[root@ceph1 ~ 10:44:55]# ceph osd pool set-quota pool_web max_objects 0
set-quota max_objects = 0 for pool pool_web
[root@ceph1 ~ 10:45:55]# ceph osd pool set-quota pool_web max_bytes 0
set-quota max_bytes = 0 for pool pool_web
[root@ceph1 ~ 10:46:08]# ceph osd pool get-quota pool_web
quotas for pool 'pool_web':
max objects: N/A
max bytes : N/A管理 池 配置
查看池配置
使用 ceph osd pool get 命令,查看池配置。
bash
# 查看池所有配置
[root@ceph1 ~ 10:46:34]# ceph osd pool get pool_web all
size: 3 #副本数为3
min_size: 2
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false
# 查看池特定配置
[root@ceph1 ~ 10:47:02]# ceph osd pool get pool_web nodelete
nodelete: false
# 备用命令
[root@ceph1 ~ 10:47:40]# ceph osd pool get pool_web all | grep nodelete
nodelete: false设置池配置
使用 ceph osd pool set 命令,可以修改池配置选项。
bash
# 设置池不可删除
[root@ceph1 ~ 10:48:05]# ceph osd pool set pool_web nodelete true
set pool 2 nodelete to true
[root@ceph1 ~ 10:48:34]# ceph osd pool get pool_web nodelete
nodelete: true
# 将 nodelete 重新设置为 FALSE,即可允许删除池
[root@ceph1 ~ 10:48:55]# ceph osd pool set pool_web nodelete false
set pool 2 nodelete to false
[root@ceph1 ~ 10:49:09]# ceph osd pool get pool_web nodelete
nodelete: false管理 池 复本数
使用以下命令,更改池的复本数量。
bash
[root@ceph1 ~ 10:49:12]# ceph osd pool set pool_web size 2
set pool 2 size to 2 #2 size to 2???没变,别闹这里说的时pool2 的size 变成2,pool2是谁??
[root@ceph1 ~ 10:50:03]# ceph osd lspools
1 device_health_metrics
2 pool_web #是它
3 pool_era
[root@ceph1 ~ 10:49:48]# ceph osd pool get pool_web all
size: 2 #这里确实从之前的3变成了2
min_size: 1
pg_num: 32
pgp_num: 32
crush_rule: replicated_rule
hashpspool: true
nodelete: false
nopgchange: false
nosizechange: false
write_fadvise_dontneed: false
noscrub: false
nodeep-scrub: false
use_gmt_hitset: 1
fast_read: 0
pg_autoscale_mode: on
bulk: false池的默认复本数量由 osd_pool_default_size 配置参数定义,默认值为 3。
bash
[root@ceph1 ~ 10:50:24]# ceph config get mon osd_pool_default_size
3使用以下命令定义创建新池的默认复本数量。
bash
[root@ceph1 ~ 10:51:12]# ceph config set mon osd_pool_default_size 2
[root@ceph1 ~ 10:51:32]# ceph config get mon osd_pool_default_size
2osd_pool_default_min_size 参数定义集群必须提供多少个对象复本才能接受 I/O 请求。复本数为3的池,该值为2;复本数为2的池,该值为1。
使用以下命令定义池的最小复本数量。
bash
[root@ceph1 ~ 10:51:34]# ceph config get mon osd_pool_default_min_size
0 #参数值为0是特殊设置,意味着集群将自动使用存储池的size值作为最小副本数,举例说明:如果某存储池size=3,那么min_size会自动设为2(即size/2+1取整)
[root@ceph1 ~ 10:52:05]# ceph config set mon osd_pool_default_min_size 1
[root@ceph1 ~ 10:52:20]# ceph config get mon osd_pool_default_min_size
1管理 池 PG 数
使用以下命令,更改池 PG 数量。
bash
[root@ceph1 ~ 10:52:54]# ceph osd pool set pool_web pg_num 64
set pool 2 pg_num to 64
[root@ceph1 ~ 10:53:01]# ceph osd pool get pool_web all | grep pg_num
pg_num: 64**Ceph 存储默认在池上配置放置组自动扩展。**自动扩展允许集群计算放置组的数量,并且自动选择适当的 pg_num 值。
集群中的每个池都有一个 pg_autoscale_mode 选项,其值可以是 on、off 或 warn。
- on:启用自动调整池的 PG 数。
- off:禁用池的 PG 自动扩展。
- warn:在 PG 数需要调整时引发运行状况警报并将集群运行状况更改为 HEALTH_WARN。
集群配置放置组自动扩展,需要在 Ceph MGR 节点上启用 pg_autoscaler 模块,并将池的自动扩展模式设置为 on:
bash
[root@ceph1 ~ 10:54:11]# ceph mgr module enable pg_autoscaler
module 'pg_autoscaler' is already enabled (always-on)
[root@ceph1 ~ 10:59:40]# ceph osd pool set pool_web pg_autoscale_mode off #pool_web池pb_autoscale_mode设置为off
set pool 2 pg_autoscale_mode to off
[root@ceph1 ~ 11:00:47]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
device_health_metrics 8667 3.0 179.9G 0.0000 1.0 1 on False
pool_web 0 2.0 179.9G 0.0000 1.0 64 off False
pool_era 0 2.0 179.9G 0.0000 1.0 32 on False
[root@ceph1 ~ 11:01:07]# ceph osd pool set pool_web pg_autoscale_mode on
set pool 2 pg_autoscale_mode to on
[root@ceph1 ~ 11:01:20]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
device_health_metrics 8667 3.0 179.9G 0.0000 1.0 1 on False
pool_web 0 2.0 179.9G 0.0000 1.0 64 on False
pool_era 0 2.0 179.9G 0.0000 1.0 32 on False 可以在集群级别为新创建的池设置一些默认值:
- osd_pool_default_flag_nodelete,为池设置 nodelete 标志的默认值。将值设置为 TRUE 可以防止删除池。
- osd_pool_default_flag_nopgchange,为池设置 nopgchange 标志的默认值。将值设置为 TRUE 可以防止更改 pg_num 和pgp_num。
- osd_pool_default_flag_nosizechange,为池设置 nosizechange 标志的默认值。将值设置为 TRUE 可以防止更改池大小。
以上这些参数需要配置在ceph集群配置ceph.conf的global块中。
管理 池 中对象
Ceph使用 rados 命令管理池的对象。
bash
[root@ceph1 ~ 11:02:12]# rados -h
usage: rados [options] [commands]
POOL COMMANDS
lspools list pools
cppool <pool-name> <dest-pool> copy content of a pool
purge <pool-name> --yes-i-really-really-mean-it
remove all objects from pool <pool-name> without removing it
df show per-pool and total usage
ls list objects in pool
POOL SNAP COMMANDS
lssnap list snaps
mksnap <snap-name> create snap <snap-name>
rmsnap <snap-name> remove snap <snap-name>
OBJECT COMMANDS
get <obj-name> <outfile> fetch object
put <obj-name> <infile> [--offset offset]
write object with start offset (default:0)
append <obj-name> <infile> append object
truncate <obj-name> length truncate object
create <obj-name> create object
rm <obj-name> ... [--force-full] remove object(s), --force-full forces remove when cluster is full
cp <obj-name> [target-obj] copy object
listxattr <obj-name>
getxattr <obj-name> attr
setxattr <obj-name> attr val
rmxattr <obj-name> attr
stat <obj-name> stat the named object
stat2 <obj-name> stat2 the named object (with high precision time)
touch <obj-name> [timestamp] change the named object modification time
mapext <obj-name>
rollback <obj-name> <snap-name> roll back object to snap <snap-name>
listsnaps <obj-name> list the snapshots of this object
bench <seconds> write|seq|rand [-t concurrent_operations] [--no-cleanup] [--run-name run_name] [--no-hints] [--reuse-bench]
default is 16 concurrent IOs and 4 MB ops
default is to clean up after write benchmark
default run-name is 'benchmark_last_metadata'
cleanup [--run-name run_name] [--prefix prefix]
clean up a previous benchmark operation
default run-name is 'benchmark_last_metadata'
load-gen [options] generate load on the cluster
listomapkeys <obj-name> list the keys in the object map
listomapvals <obj-name> list the keys and vals in the object map
getomapval <obj-name> <key> [file] show the value for the specified key
in the object's object map
setomapval <obj-name> <key> <val | --input-file file>
rmomapkey <obj-name> <key>
clearomap <obj-name> [obj-name2 obj-name3...] clear all the omap keys for the specified objects
getomapheader <obj-name> [file]
setomapheader <obj-name> <val>
watch <obj-name> add watcher on this object
notify <obj-name> <message> notify watcher of this object with message
listwatchers <obj-name> list the watchers of this object
set-alloc-hint <obj-name> <expected-object-size> <expected-write-size>
set allocation hint for an object
set-redirect <object A> --target-pool <caspool> <target object A> [--with-reference]
set redirect target
set-chunk <object A> <offset> <length> --target-pool <caspool> <target object A> <taget-offset> [--with-reference]
convert an object to chunked object
tier-promote <obj-name> promote the object to the base tier
unset-manifest <obj-name> unset redirect or chunked object
tier-flush <obj-name> flush the chunked object
tier-evict <obj-name> evict the chunked object
IMPORT AND EXPORT
export [filename]
Serialize pool contents to a file or standard out.
import [--dry-run] [--no-overwrite] < filename | - >
Load pool contents from a file or standard in
ADVISORY LOCKS
lock list <obj-name>
List all advisory locks on an object
lock get <obj-name> <lock-name> [--lock-cookie locker-cookie] [--lock-tag locker-tag] [--lock-description locker-desc] [--lock-duration locker-dur] [--lock-type locker-type]
Try to acquire a lock
lock break <obj-name> <lock-name> <locker-name> [--lock-cookie locker-cookie]
Try to break a lock acquired by another client
lock info <obj-name> <lock-name>
Show lock information
options:
--lock-tag Lock tag, all locks operation should use
the same tag
--lock-cookie Locker cookie
--lock-description Description of lock
--lock-duration Lock duration (in seconds)
--lock-type Lock type (shared, exclusive)
SCRUB AND REPAIR:
list-inconsistent-pg <pool> list inconsistent PGs in given pool
list-inconsistent-obj <pgid> list inconsistent objects in given PG
list-inconsistent-snapset <pgid> list inconsistent snapsets in the given PG
CACHE POOLS: (for testing/development only)
cache-flush <obj-name> flush cache pool object (blocking)
cache-try-flush <obj-name> flush cache pool object (non-blocking)
cache-evict <obj-name> evict cache pool object
cache-flush-evict-all flush+evict all objects
cache-try-flush-evict-all try-flush+evict all objects
GLOBAL OPTIONS:
--object-locator object_locator
set object_locator for operation
-p pool
--pool=pool
select given pool by name
--target-pool=pool
select target pool by name
--pgid PG id
select given PG id
-f [--format plain|json|json-pretty]
--format=[--format plain|json|json-pretty]
-b op_size
set the block size for put/get ops and for write benchmarking
-O object_size
set the object size for put/get ops and for write benchmarking
--max-objects
set the max number of objects for write benchmarking
--obj-name-file file
use the content of the specified file in place of <obj-name>
-s name
--snap name
select given snap name for (read) IO
--input-file file
use the content of the specified file in place of <val>
--create
create the pool or directory that was specified
-N namespace
--namespace=namespace
specify the namespace to use for the object
--all
Use with ls to list objects in all namespaces
Put in CEPH_ARGS environment variable to make this the default
--default
Use with ls to list objects in default namespace
Takes precedence over --all in case --all is in environment
--target-locator
Use with cp to specify the locator of the new object
--target-nspace
Use with cp to specify the namespace of the new object
--striper
Use radostriper interface rather than pure rados
Available for stat, get, put, truncate, rm, ls and
all xattr related operations
BENCH OPTIONS:
-t N
--concurrent-ios=N
Set number of concurrent I/O operations
--show-time
prefix output with date/time
--no-verify
do not verify contents of read objects
--write-object
write contents to the objects
--write-omap
write contents to the omap
--write-xattr
write contents to the extended attributes
LOAD GEN OPTIONS:
--num-objects total number of objects
--min-object-size min object size
--max-object-size max object size
--min-op-len min io size of operations
--max-op-len max io size of operations
--max-ops max number of operations
--max-backlog max backlog size
--read-percent percent of operations that are read
--target-throughput target throughput (in bytes)
--run-length total time (in seconds)
--offset-align at what boundary to align random op offsets
CACHE POOLS OPTIONS:
--with-clones include clones when doing flush or evict
OMAP OPTIONS:
--omap-key-file file read the omap key from a file
GENERIC OPTIONS:
--conf/-c FILE read configuration from the given configuration file
--id ID set ID portion of my name
--name/-n TYPE.ID set name
--cluster NAME set cluster name (default: ceph)
--setuser USER set uid to user or uid (and gid to user's gid)
--setgroup GROUP set gid to group or gid
--version show version and quit这里我们主要讲解池中对象操作。
上传对象到池中
bash
[root@ceph1 ~ 11:20:59]# echo nihao > host1
[root@ceph1 ~ 11:21:25]# cat host1
nihao
[root@ceph1 ~ 11:21:31]# rados -p pool_web put hosts host1 #将host1文件上传到webapp池取名为hosts
[root@ceph1 ~ 11:22:31]# rados -p pool_web ls
hosts查看池中对象状态
bash
[root@ceph1 ~]# rados -p pool_web stat hosts
pool_web/hosts mtime 2025-08-21T09:52:43.000000+0800, size 8检索对象到本地
bash
[root@ceph1 ~ 11:22:43]# rados -p pool_web get hosts newhosts
[root@ceph1 ~ 11:23:28]# cat newhosts
nihao追加池中对象
bash
[root@ceph1 ~ 11:23:33]# echo hello >> host2
[root@ceph1 ~ 11:23:50]# rados append -p pool_web hosts host2
[root@ceph1 ~ 11:24:35]# rados -p pool_web ls
hosts
[root@ceph1 ~ 11:24:52]# rados get -p pool_web hosts newhosts
[root@ceph1 ~ 11:25:21]# cat newhosts
nihao
hello删除池中对象
bash
[root@ceph1 ~ 11:25:28]# rados put passwd /etc/passwd -p pool_web
[root@ceph1 ~ 11:26:01]# rados -p pool_web ls
passwd
hosts
[root@ceph1 ~ 11:26:18]# rados rm passwd -p pool_web
[root@ceph1 ~ 11:26:40]# rados -p pool_web ls
hosts管理 池 快照
使用 ceph osd pool mksnap 命令,创建池快照。
bash
[root@ceph1 ~ 11:26:41]# ceph osd pool <tab><tab>
application force-recovery rmsnap
autoscale-status get scrub
cancel-force-backfill get-quota set
cancel-force-recovery ls set-quota
create mksnap stats
deep-scrub rename unset
delete repair
force-backfill rm
[root@ceph1 ~ 11:26:41]# ceph osd pool mksnap pool_web snap1 #给池pool_web创建快照snap1
created pool pool_web snap snap1
[root@ceph1 ~ 11:39:14]# ceph osd pool ls detail
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 100 lfor 0/0/92 flags hashpspool,pool_snaps stripe_width 0
snap 1 'snap1' 2025-11-28T03:39:13.712713+0000 #多了snap1
[root@ceph1 ~ 11:39:30]# rados -p pool_web lssnap
1 snap1 2025.11.28 11:39:13
1 snaps使用 ceph osd pool rmsnap 命令,删除池快照。
bash
[root@ceph1 ~ 11:40:04]# ceph osd pool rmsnap pool_web snap1
removed pool pool_web snap snap1
[root@ceph1 ~ 11:40:37]# rados -p pool_web lssnap
0 snaps管理 池 快照中对象
对池某个快照中对象操作需要使用-s选项指定快照名称。
bash
[root@ceph1 ~ 11:41:30]# ceph osd pool mksnap pool_web snap1
created pool pool_web snap snap1
#查看快照记录
[root@ceph1 ~ 11:42:11]# ceph osd pool ls detail | grep pool_web
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 102 lfor 0/0/92 flags hashpspool,pool_snaps stripe_width 0
[root@ceph1 ~ 11:42:40]# ceph osd pool ls detail | grep -A1 pool_web
pool 2 'pool_web' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 64 pgp_num 64 autoscale_mode on last_change 102 lfor 0/0/92 flags hashpspool,pool_snaps stripe_width 0
snap 3 'snap1' 2025-11-28T03:42:11.562331+0000
[root@ceph1 ~ 11:43:01]# ceph osd pool ls detail | grep -A1 pool_web | grep -v pool_web
snap 3 'snap1' 2025-11-28T03:42:11.562331+0000
[root@ceph1 ~ 11:43:20]# rados -p pool_web lssnap
3 snap1 2025.11.28 11:42:11
1 snaps
[root@ceph1 ~ 11:43:48]# rados -p pool_web listsnaps hosts
hosts:
cloneid snaps size overlap
head - 12
#拍摄快照后,上传新的内容到hosts中
[root@ceph1 ~ 11:44:08]# echo hi > host3
[root@ceph1 ~ 11:44:51]# rados -p pool_web put hosts host3
[root@ceph1 ~ 11:45:26]# rados -p pool_web get hosts newhosts
[root@ceph1 ~ 11:45:50]# cat newhosts
hi
bash
# 查看快照中对象
[root@ceph1 ~ 11:45:54]# rados -p pool_web -s snap1 ls
selected snap 3 'snap1'
hosts
# 获取快照中对象
[root@ceph1 ~ 11:46:23]# rados -p pool_web -s snap1 get hosts f1
selected snap 3 'snap1'
[root@ceph1 ~ 11:53:14]# cat f1
nihao
hello #发现即使hosts文件拍摄快照后变了,从快照获取的依然没变
# 恢复对象内容为指定快照时内容
[root@ceph1 ~ 11:53:20]# rados -p pool_web rollback hosts snap1
rolled back pool pool_web to snapshot snap1
[root@ceph1 ~ 11:54:19]# rados -p pool_web get hosts f2
[root@ceph1 ~ 11:54:34]# cat f2
nihao
hello快照是只读文件系统,无法上传和删除快照中对象。
bash
[root@ceph1 ~ 11:54:39]# rados -p pool_web -s snap1 put passwd /etc/passwd
selected snap 3 'snap1'
error putting pool_web/passwd: (30) Read-only file system
[root@ceph1 ~ 11:55:28]# rados -p pool_web -s snap1 ls
selected snap 3 'snap1'
hosts
[root@ceph1 ~ 11:55:48]# rados -p pool_web -s snap1 rm hosts
selected snap 3 'snap1'
error removing pool_web>hosts: (30) Read-only file system
[root@ceph1 ~ 11:56:16]# rados -p pool_web -s snap1 ls
selected snap 3 'snap1'
hosts管理 池 命名空间
Ceph可以将整个池提供给特定应用。随着应用增加,池的数量也增加。
**建议每个 OSD 关联的PG数量为100-200。由于集群中 OSD 数量是有限的,所以PG的数量也是有限的。**创建的池越多,导致池能够分配的PG数量越少,每个PG 将会为更多的对象映射到OSD磁盘,进而导致每个 PG 的计算开销更高(负载更高),从而降低 OSD 性能。
使用命名空间,可以对池中对象进行逻辑分组,还可以限制用户只能存储或检索池中特定命名空间内的对象。借助命名空间,可以让多个应用使用同一个池,而且不必将整个池专用于各个应用,从而确保池的数量不会太多。
**命名空间目前仅支持直接使用 librados 的应用。**RBD 和 Ceph 对象网关客户端目前不支持此功能。
若要在命名空间内存储对象,客户端应用必须提供池和命名空间的名称。默认情况下,每个池包含一个具有空名称的命名空间,称为默认命名空间。
示例:
bash
[root@ceph1 ~ 13:56:10]# rados -p pool_web put -N myns1 hostname /etc/hostname
[root@ceph1 ~ 13:56:10]# rados ls -p pool_web
hosts
[root@ceph1 ~ 13:57:39]# rados -p pool_web -N myns1 ls
hostname #上传的hsotname1在namespace myns1中
[root@ceph1 ~ 13:59:24]# rados -p pool_web -N myns2 put newhostname /etc/hostname
[root@ceph1 ~ 13:59:46]# rados -p pool_web -N myns2 ls
newhostname
[root@ceph1 ~ 14:00:01]# rados -p pool_web ls --all
myns1 hostname
hosts
myns2 newhostname
[root@ceph1 ~ 14:01:11]# rados -p pool_web ls --all --format=json-pretty
[
{
"namespace": "myns1",
"name": "hostname"
},
{
"namespace": "",
"name": "hosts"
},
{
"namespace": "myns2",
"name": "newhostname"
}
]重命名池
使用 ceph osd pool rename 命令,重命名池。
bash
[root@ceph1 ~ 14:01:27]# ceph osd pool rename pool_web pool_apache
pool 'pool_web' renamed to 'pool_apache'
[root@ceph1 ~ 14:02:08]# ceph osd pool ls
device_health_metrics
pool_apache
pool_era**重命名池不会影响池中存储的数据。**如果用户重命名池,则会影响池级别的用户权限,则必须使用新的池名称来更新该用户的能力。
删除池
使用 ceph osd pool delete 命令,删除池。
bash
[root@ceph1 ~ 14:02:29]# ceph osd pool rm pool_apache
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool pool_apache. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it. #根据提示需要将pool name输入两次,跟上参数--yes-i-really-really-mean-it
[root@ceph1 ~ 14:02:55]# ceph osd pool rm pool_apache pool_apache --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool #提示需要先将mon_allow_pool_delete选项配置为true才能删除pool必须将集群级别 mon_allow_pool_delete 设置为 TRUE 才能删除池。
bash
[root@ceph1 ~ 14:04:54]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
false
[root@ceph1 ~ 14:05:30]# ceph config set mon.ceph1.dcr.cloud mon_allow_pool_delete true
[root@ceph1 ~ 14:05:44]# ceph config get mon.ceph1.dcr.cloud mon_allow_pool_delete
true
[root@ceph1 ~ 14:05:46]# ceph osd pool rm pool_apache pool_apache --yes-i-really-really-mean-it
pool 'pool_apache' removed重要:删除池会删除池中的所有数据,而且不可逆转。
还可以通过设置池 nodelete 属性为 yes,防止池被误删除。
bash
# ceph osd pool set pool_apache nodelete true第 5 章 Ceph 分布式存储 认证和授权管理
Ceph 集群身份验证
cephx 协议
Ceph 存储使用 cephx 协议管理集群认证。
Ceph 中用户帐户用途:
- Ceph 守护进程之间的内部通信。
- 客户通通过 librados 库访问集群。
- 集群管理。
账户名称
-
Ceph 守护进程使用的帐户与守护进程名称相匹配,例如 osd.1 或 mgr.ceph1,并在安装期间创建。
-
**使用 librados 的客户端应用所用帐户的名称具有 client. 前缀。**例如:
-
将 OpenStack 与 Ceph 集成时,常常会创建专用的 client.openstack 用户帐户。
-
对于 Ceph 对象网关,安装过程会创建专用的 client.rgw.hostname 用户帐户。
-
-
**安装程序会创建超级用户帐户 client.admin,该帐户具有访问所有内容及修改集群配置的能力。**运行ceph相关命令时,Ceph 默认使用 client.admin 帐户,除非用户通过 --name 或 --id 选项明确指定了其他用户名。
可以设置 CEPH_ARGS 环境变量来定义用户名称或用户 ID 等参数。
示例:
bash
# export CEPH_ARGS="--id dcr"**应用的最终用户不在 Ceph 集群中拥有帐户。**最终用户访问应用,然后由应用代表他们访问 Ceph。从 Ceph 角度来看,应用就是客户端。应用可能会通过其他机制提供自己的用户身份验证。
Ceph 对象网关有自己的用户数据库来验证 Amazon S3 或 Swift 用户的身份,Ceph 对象网关使用client.rgw.hostname 帐户来访问集群。
密钥环文件
Ceph 创建用户帐户时,为每个用户帐户生成密钥环文件,通过密钥环文件验证用户身份,必须将此文件复制到客户端系统或应用服务器上。
Ceph 根据 /etc/ceph/ceph.conf 配置文件中的 keyring 参数查找密钥环文件,默认值为/etc/ceph/ c l u s t e r . cluster. cluster.name.keyring。例如,对于 client.openstack 帐户,其密钥环文件为 /etc/ceph/ceph.client.openstack.keyring。
**密钥环文件以纯文本形式存储机密密钥,**因此需要使用适当的 Linux 文件权限来保护文件,仅允许授权的Linux 用户访问。仅将 Ceph 用户的密钥环文件部署到需要用它进行身份验证的系统上。
指定用户身份
ceph、rados 和 rbd 等命令行工具,通过 --id 和 --keyring 选项指定要使用的用户帐户和密钥环文件。未指定时,命令会以 client.admin 用户进行身份验证。
示例:ceph 命令会以 client.operator3 进行身份验证并列出可用池。
bash
# ceph --id operator3 osd lspools- 使用 --id 选项,不要添加 client. 前缀。
- 使用 --name 选项,需要 client. 前缀。
- 如果密钥环文件存储在默认的位置,则用户不需要 --keyring 选项。cephadm shell 会自动从 /etc/ceph/ 目录挂载密钥环。
Cephx 协议通信原理
**Cephx 协议使用共享机密密钥加密通信。**简要通信过程如下:
- 客户端向监控器请求会话密钥,同时传递共享秘钥给监视器。
- 监视器使用客户端的共享机密密钥加密会话密钥,再将会话密钥提供给客户端。
- 由客户端解密会话密钥,然后再从监控器请求票据,以便对集群守护进程进行身份验证。
Cephx 使用共享密钥进行身份验证, 客户端和MON群集都保存着共享秘钥副本。
Cephx 协议的认证流程:
-
client 向 MON 请求会话秘钥。
-
MON 创建会话秘钥,同时将产生的会话秘钥分享给 MDS 和 OSD。
-
MON 使用共享密钥加密会话密钥,并返回给 client。client 使用共享秘钥解密数据,获得会话密钥。
后续通信都使用会话秘钥进行加密和解密。
-
client 然后使用会话密钥加密会话,向 MON 请求票据数据。MON 使用会话密钥解密客户端请求,并创建 ticket,使用会话密钥加密返回给 client。client 使用会话密钥解密数据收到ticket。
-
client 使用ticket与MDS和OSD进行交互。由于client、MDS和OSD都拥有MON产生的秘钥,因此它们之间可以验证ticket是否合法。
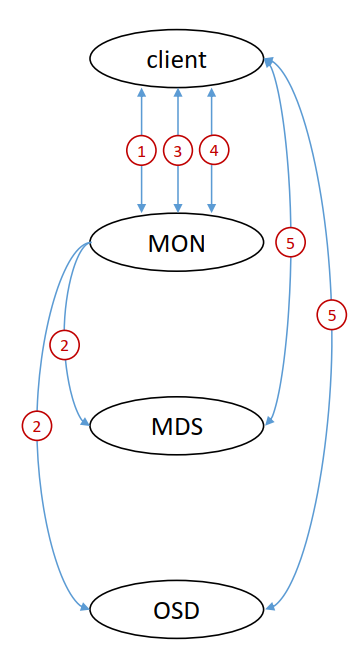
管理用户账户
查看用户账户
要列出现有用户帐户,可运行 ceph auth ls 或者 ceph auth list 命令。
bash
[root@ceph1 ~]# ceph auth list
osd.0
key: AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
......要获取特定帐户的详细信息,可使用 ceph auth get 命令。
bash
[root@ceph1 ~]# ceph auth get osd.0
[osd.0]
key = AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
exported keyring for osd.0要获取特定帐户的key内容,可使用命令:
- ceph auth get-key
- ceph auth print-key
- ceph auth print_key
bash
[root@ceph1 ~]# ceph auth get-key osd.0
AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
[root@ceph1 ~]# ceph auth print-key osd.0
AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
[root@ceph1 ~]# ceph auth print_key osd.0
AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==创建用户账户
要创建用户帐户,可使用命令:
- ceph auth add
- ceph auth get-or-create
- ceph auth get-or-create-key
bash
[root@ceph1 ~]# ceph auth add client.app1
added key for client.app1
[root@ceph1 ~]# ceph auth get-or-create client.app2
[client.app2]
key = AQC2vKZoZQzOCRAAWn6PfXhyMxh3/i4KTTvKQg==
[root@ceph1 ~]# ceph auth get-or-create-key client.app3
AQDFvKZoF8/iDxAAV7gMq2lnCQcLs9NAQGH5Kg==还可以在创建用户账户的时候,赋予用户账户权限。
赋予用户账户权限,稍后讲解。
bash
[root@ceph1 ~]# ceph auth add client.app4 mon 'allow r'
added key for client.app4删除用户账户
要创建用户帐户,可使用命令:
- ceph auth del
- ceph auth rm
bash
[root@ceph1 ~]# ceph auth del client.app3
updated
[root@ceph1 ~]# ceph auth rm client.app2
updated
[root@ceph1 ~]# ceph auth ls | grep client.app
installed auth entries:
client.app1
client.app4导出和导入用户账户
要导出特定帐户的详细信息,可使用命令:
- ceph auth export -o
- ceph auth get -o
bash
[root@ceph1 ~]# ceph auth export osd.0 -o ceph.osd.0.keyring.1
export auth(key=AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==)
[root@ceph1 ~]# cat ceph.osd.0.keyring.1
[osd.0]
key = AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"
[root@ceph1 ~]# ceph auth get osd.0 -o ceph.osd.0.keyring.2
exported keyring for osd.0
[root@ceph1 ~]# cat ceph.osd.0.keyring.2
[osd.0]
key = AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
caps mgr = "allow profile osd"
caps mon = "allow profile osd"
caps osd = "allow *"要导入特定帐户的详细信息,可使用 ceph auth import -i 命令。
bash
# 先导出client.app4然后删除client.app4
[root@ceph1 ~]# ceph auth export client.app4 -o ceph.client.app4.keyring
export auth(key=AQDnvKZoY7irCRAA5ap2HQ1nQ2ADHSJRJWtczw==)
[root@ceph1 ~]# ceph auth rm client.app4
updated
[root@ceph1 ~]# ceph auth get client.app4
Error ENOENT: failed to find client.app4 in keyring
# 将刚才删除的client.app4导入观察现象
[root@ceph1 ~]# ceph auth import -i ceph.client.app4.keyring
imported keyring
[root@ceph1 ~]# ceph auth get client.app4
[client.app4]
key = AQDnvKZoY7irCRAA5ap2HQ1nQ2ADHSJRJWtczw==
caps mon = "allow r"
exported keyring for client.app4ceph auth ls =ceph auth list
ceph auth add =ceph auth get-or-create=ceph auth get-or-create-key 注意:add添加用户不能直接生成keyring 需要额外利用export导出
ceph auth rm =ceph auth del
ceph auth export -o =ceph auth get -o
配置用户账户功能
用户账户功能
cephx 中的权限称为功能,使用功能来限制或提供对池中数据、池的命名空间或一组池的访问权限。功能还允许集群中的守护进程之间互相交互。通过守护进程类型(mon、osd、mgr 或 mds)来授予它们。
在 cephx 内,对于每个守护进程类型来说,都有多项功能可用:
- allow,在守护进程的访问权限之前设置。
- **r,授予读取访问权限。**每一用户帐户至少应在监控器上具有读取访问权限,以便能够检索 CRUSH 映射。
- **w,授予写入访问权限。**客户端需要写入访问权限以在 OSD 上存储和修改对象。对于管理器 (MGR),w 授予启用或禁用模块的权限。
- **x,授予执行扩展对象类的权限。**让用户能够调用类方法(即读取和写入)并对监控器执行身份验证操作。这使得客户端能够在对象上执行额外的操作,如使用 rados lock get 设置锁定或使用 rbd list 列出 RBD 镜像。
- **class-read ,让用户能够调用类读取方法。**x 的子集。通常用在 RBD 池中。
- **class-write,让用户能够调用类写入方法。**x 的子集。通常用在 RBD 池中。
- ***,授予完整访问权限。**授予用户对特定守护进程或池的读取、写入和执行权限,并允许用户执行管 理命令。
要赋予用户帐户功能,可运行 ceph auth caps 命令,运行该命令前确保用户账户已创建。
示例:
bash
[root@ceph1 ~]# ceph auth add client.dcr
added key for client.dcr
[root@ceph1 ~]# ceph auth caps client.dcr mon 'allow r' osd 'allow rw'
updated caps for client.dcr在创建用户账户时,直接赋予权限。
bash
[root@ceph1 ~]# ceph auth add client.dcr mon 'allow r' osd 'allow rw'用户账户功能配置文件
创建用户帐户时,可使用cephx 预定义的功能配置文件:
- 简化用户访问权限配置。
- 实现守护进程之间的内部通信。
- Ceph 会在内部定义这些文件,用户无法自行创建配置文件。
cephx 预定义的部分功能配置文件如下:
-
osd,授予用户作为 OSD 连接其他 OSD 或监控器的权限, 以便 OSD 能够 处理复制心跳流量和状态报告。
bash[root@ceph1 ~]# ceph auth get osd.1 [osd.1] key = AQA8EqRoxyM2OBAAQuVUxOvvVZL7Ydg4niwLPQ== caps mgr = "allow profile osd" caps mon = "allow profile osd" caps osd = "allow *" exported keyring for osd.1 -
bootstrap-osd,授予用户引导 OSD 的权限,以便他们在引导 OSD 时具有添加密钥的权限。
bash[root@ceph1 ~]# ceph auth get client.bootstrap-osd [client.bootstrap-osd] key = AQCgDqRoAD+sABAAP2icy5PAW2sgh8sU/An5Pw== caps mon = "allow profile bootstrap-osd" exported keyring for client.bootstrap-osd -
rbd,授予用户读写访问 Ceph 块设备的权限。
-
rbd-read-only,授予用户只读访问 Ceph 块设备的权限。
示例:
bash
[root@ceph1 ~]# ceph auth add client.forrbd mon 'profile rbd' osd 'profile rbd'
added key for client.forrbd
[root@ceph1 ~]# ceph auth get client.forrbd
[client.forrbd]
key = AQDLwqZo4W28KxAA8onfLsxAxUvYt2cKq+comQ==
caps mon = "profile rbd"
caps osd = "profile rbd"
exported keyring for client.forrbd限制访问范围
-
池,限制用户只能访问他们需要的池。
示例:
bash[root@ceph1 ~]# ceph auth get-or-create client.formyapp1 mon 'allow r' osd 'allow rw pool=myapp' [client.formyapp1] key = AQAMxqZodL12BhAA0IyPEV6SqT+9cLpr+k1DPw==如果在配置功能时不指定池,则 Ceph 会将它们设置到所有现有的池。
-
命名空间,限制用户帐户仅访问从属于特定命名空间中对象。
示例:
bash[root@ceph1 ~]# ceph auth get-or-create client.formyapp2 mon 'allow r' osd 'allow rw namespace=photos' [client.formyapp2] key = AQA6xqZolcVtBxAAMGJtK4hes9LLfuwaoTnMFA== -
池和命名空间,限制用户帐户仅访问特定池中特定命名空间中对象。
示例:
bash[root@ceph1 ~]# ceph auth get-or-create client.formyapp3 mon 'allow r' osd 'allow rw pool=myapp namespace=photos' [client.formyapp3] key = AQBmxqZo9uExExAAePkx63ERHvgGmMiEJd4GEg== -
对象名称前缀,限制用户帐户仅访问特定名称前缀的对象。
示例:
bash[root@ceph1 ~]# ceph auth get-or-create client.formyapp4 mon 'allow r' osd 'allow rw object_prefix pref' [client.formyapp4] key = AQCYxqZorsmOHxAAlQMGO+Ouv719SN1/BLpy8w== -
文件路径,限制用户帐户仅访问 Ceph 文件系统 (CephFS) 中特定目录。
示例:
bash# ceph fs authorize cephfs client.webdesigner /webcontent rw -
monitor 命令,限制用户帐户只能使用一组特定的命令。
示例:
bash[root@ceph1 ~]# ceph auth get-or-create client.operator1 mon 'allow r, allow command "auth get-or-create", allow command "auth list"' [client.operator1] key = AQDdxqZotZpCFRAAI1DFw519uGF/EbAF2KB6GQ==
实践1:创建一个可执行ceph auth list的用户,并使用该用户执行该命令
bash
[root@ceph1 ~]# ceph auth get-or-create client.dcr mon 'allow r,allow command "auth list"'
[client.dcr]
key = AQCn56Zo8hxHFxAA1GnGWHE9RRGe6TnglJIoVg==
[root@ceph1 ~]# ceph auth get client.dcr -o /etc/ceph/ceph.client.dcr.keyring
exported keyring for client.dcr
[root@ceph1 ~]# ceph auth ls --id dcr #执行等同于auth list的auth ls都不行
Error EACCES: access denied
[root@ceph1 ~]# ceph auth list --id dcr
osd.0
key: AQA8EqRojLYOOBAAVprA9Rs0Gkg4zK0dKZUUrA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
......实践2:通过client管理ceph
client:
bash
[root@client ~ 16:08:11]# vim /etc/yum.repos.d/ceph.repo
[root@client ~ 16:16:37]# cat /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=https://mirrors.aliyun.com/centos-vault/8-stream/storage/x86_64/ceph-pacific
enabled=1
gpgcheck=0
#设置仓库
[root@client ~ 16:12:22]# mkdir /etc/ceph
[root@client ~ 16:13:05]# yum install -y ceph-common
#客户端无法查看集群状态
[root@client ~ 16:13:43]# ceph -s
Error initializing cluster client: ObjectNotFound('RADOS object not found (error calling conf_read_file)',)ceph1:
bash
[root@ceph1 ~ 16:05:41]# cat /etc/ceph/ceph.conf
# minimal ceph.conf for 58744eb6-ca7b-11f0-bfae-000c293dede4
[global]
fsid = 58744eb6-ca7b-11f0-bfae-000c293dede4
mon_host = [v2:192.168.108.11:3300/0,v1:192.168.108.11:6789/0] [v2:192.168.108.12:3300/0,v1:192.168.108.12:6789/0] [v2:192.168.108.13:3300/0,v1:192.168.108.13:6789/0]
[root@ceph1 ~ 16:14:19]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQCKeSZpZj3sIxAAqEz7kMVlJCdlKHAz4/7Jaw==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
# 将/etc/ceph/ceph.client.admin.keyring拷贝到client
[root@ceph1 ~ 16:14:42]# scp /etc/ceph/ceph.client.admin.keyring root@client:/etc/ceph/
# 将/etc/ceph.conf拷贝到cleint
[root@ceph1 ~ 16:15:44]# scp /etc/ceph/ceph.conf root@client:/etc/cephclient:
bash
[root@client ~ 16:16:21]# ceph -s
cluster:
id: 58744eb6-ca7b-11f0-bfae-000c293dede4
health: HEALTH_WARN
Degraded data redundancy: 32 pgs undersized
services:
mon: 3 daemons, quorum ceph1.dcr.cloud,ceph2,ceph3 (age 2h)
mgr: ceph3.rcacha(active, since 2h), standbys: ceph2.mtbwth, ceph1.dcr.cloud.gnytkh
osd: 9 osds: 9 up (since 2h), 9 in (since 2d)
data:
pools: 2 pools, 33 pgs
objects: 3 objects, 0 B
usage: 2.6 GiB used, 177 GiB / 180 GiB avail
pgs: 32 active+undersized
1 active+clean第 6 章 Ceph 分布式存储 块存储管理
管理 RADOS 块设备
RADOS 块设备
块设备是服务器、笔记本电脑和其他计算系统上最为常见的长期存储设备。**它们以固定大小的块存储数据。**块设备包括基于旋转磁盘的硬盘驱动器,以及基于非易失性存储器的固态驱动器。若要使用存储,用户要使用文件系统格式化块设备,并将它挂载到 Linux 文件系统层次结构中。
Ceph 存储集群的RADOS 块设备 (RBD) 功能 提供虚拟块设备,并以RBD 镜像形式存储在Ceph 存储集群的池中。
创建 RBD 镜像
存储管理员使用 rbd 命令来创建、列出、检索信息、调整大小和删除块设备镜像。
-
创建 rbd 池 。使用 ceph osd pool create 命令来创建用于存储 RBD 镜像池,并使用 rbd pool init 命令进行初始化池。
bash[root@ceph1 ~ 10:01:55]# ceph osd pool create images_pool pool 'images_pool' created [root@ceph1 ~ 10:02:35]# rbd pool init images_pool #等同于ceph osd pool application enable images_pool rbd [root@ceph1 ~ 10:02:35]# ceph osd pool ls detail | grep images_pool #看现象 pool 2 'images_pool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 41 flags hashpspool,selfmanaged_snaps stripe_width 0 `application rbd` -
创建专用用户。虽然 Ceph 管理员可以访问这个池,但建议使用受限制的 Cephx 用户访问 rbd 池,仅向该受限用户授予所需 RBD 池的读写权限,而非整个集群的访问权限。
bash[root@ceph1 ~]# ceph auth get-or-create client.rbd mon 'profile rbd' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd.keyring -
创建 RBD 镜像。
bash[root@ceph1 ~]# rbd create images_pool/webapp1 --size 1G # 查看池中镜像清单 [root@ceph1 ~]# rbd ls images_pool webapp1 # 查看池整体情况 [root@ceph1 ~]# rbd pool stats images_pool Total Images: 1 Total Snapshots: 0 Provisioned Size: 1 GiB如果用户不指定池名称,此命令会使用默认的池名称,默认的池名称由 rbd_default_pool 参数指定。使用 ceph config set osd rbd_default_pool value 设置此参数。
访问 RADOS 块设备存储
访问 RADOS 块设备存储方法:
- 使用 KRBD, 客户端 krbd 模块将 RBD 镜像映射为 Linux 块设备。
- 使用 librbd 库,将 RBD 存储提供给 KVM 虚拟机和 OpenStack 云实例。这些客户端使得裸机恢复服务器或虚拟机像普通的块存储一样使用 RBD镜像。在 OpenStack 环境中,OpenStack 将这些 RBD 镜像连接并映射到 Linux 服务器,在那里它们可以充当引导设备。
Ceph 存储将虚拟设块设备使用的实际存储分散在集群中,以利用 IP网络提供高性能访问。
使用内核RBD(KRBD)访问 Ceph 块存储
映射 RBD 镜像
Ceph 客户端可以使用原生 Linux 内核模块 (krbd) 挂载 RBD 镜像。这个模块使用 /dev/rbd0 之类的名称将 RBD 镜像映射到 Linux 块设备。
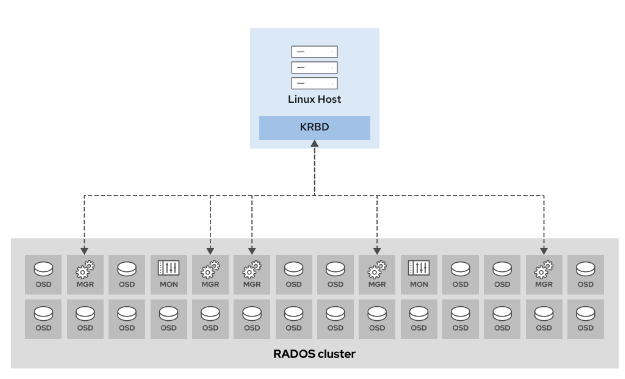
示例:将 images_pool 池中的 webapp1 镜像映射为client上 /dev/rbd0 设备。
bash
#client上操作:
[root@client ~]# dnf install -y ceph-common
#ceph1上操作:
[root@ceph1 ~]# scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.rbd.keyring root@client:/etc/ceph
# 在客户端 client 上操作
[root@client ~]# rbd --id rbd ls images_pool
webapp1
# 为了简化命令参数,定义CEPH_ARGS环境变量,确保ceph相关命令使用该环境变量提供的默认值。
[root@client ~]# export CEPH_ARGS='--id=rbd'
[root@client ~]# rbd ls images_pool
webapp1
# 使用 krbd 内核模块来映射镜像
[root@client ~]# rbd device map images_pool/webapp1 #或者使用rbd map images_pool/webapp1映射镜像
/dev/rbd0
[root@client ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 200G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 199G 0 part
├─cs-root 253:0 0 70G 0 lvm /
├─cs-swap 253:1 0 3.9G 0 lvm [SWAP]
└─cs-home 253:2 0 125.1G 0 lvm /home
sr0 11:0 1 12.8G 0 rom
rbd0 252:0 0 1G 0 disk #多了个rbd0设备Ceph 客户端系统可以像其他块设备一样使用映射的块设备,例如使用文件系统进行格式化、挂载和卸载。
bash
# 列出计算机中映射的 RBD 镜像
[root@client ~]# rbd showmapped
id pool namespace image snap device
0 images_pool webapp1 - /dev/rbd0
# 或者
[root@client ~]# rbd device list #等于rbd device ls
id pool namespace image snap device
0 images_pool webapp1 - /dev/rbd0
# 格式化和挂载
[root@client ~]# lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 1G 0 disk
[root@client ~]# mkfs.xfs /dev/rbd0
[root@client ~]# mkdir -p /webapp/webapp1
[root@client ~]# mount /dev/rbd0 /webapp/webapp1/
[root@client ~]# lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 1G 0 disk /webapp/webapp1 #已经挂载
[root@client ~]# echo Hello World > /webapp/webapp1/index.html
[root@client ~]# cat /webapp/webapp1/index.html
Hello World
[root@client ~]# df /webapp/webapp1/
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/rbd0 1038336 40504 997832 4% /webapp/webapp1
[root@client ~]# rbd status images_pool/webapp1 #看看谁在用
Watchers:
watcher=192.168.108.10:0/1267779106 client.44650 cookie=18446462598732840961取消映射 RBD 镜像,使用以下命令:
bash
# 先卸载改设备
[root@client ~]# umount /webapp/webapp1
# 取消映射
[root@client ~]# rbd unmap /dev/rbd0 # rbd unmap images_pool/webapp1也可以
# 或者
[root@client ~]# rbd device unmap /dev/rbd0
[root@client ~]# rbd device ls #查看现象注意:rbd map 和 rbd unmap 命令需要 root 特权。
**==注意:==两个客户端可以同时将同一个 RBD 镜像映射为块设备。**但如果块设备含有普通的单挂载文件系统,则建议每次将数据块设备连接到一个客户端。如果将含有普通文件系统的 RADOS 块设备同时挂载到两个或多个客户端上,可能会造成文件系统损坏和数据丢失。
持久映射 RBD 镜像
**rbdmap 服务可在系统启动自动映射 RBD 镜像到系统。**此服务在 /etc/ceph/rbdmap 文件中查找已映射的镜像及其凭据。当 系统识别到 RBD 镜像时,读取 /etc/fstab 文件中记录,并挂载镜像。
下列步骤对 rbdmap 进行配置,以持久映射已包含文件系统的 RBD 镜像:
-
在 /etc/ceph/rbdmap RBD 映射文件内创建一个单行条目。此条目必须指定 RBD 池和镜像的名称。还必须引用 Cephx 用户,该用户具有镜像的读写权限并且具有相应的密钥环文件。确保客户端系统上存在 Cephx 用户的密钥环文件。
bash[root@client ~]# vim /etc/ceph/rbdmap # RbdDevice Parameters #poolname/imagename id=client,keyring=/etc/ceph/ceph.client.keyring images_pool/webapp1 id=rbd,keyring=/etc/ceph/ceph.client.rbd.keyring -
在客户端系统上的 /etc/fstab 文件中为 RBD 创建一个条目。
块设备的名称:/dev/rbd/pool_name/image_name,指定 _netdev 挂载选项,等待 rbdmap 服务映射镜像后,再挂载文件系统。
bash[root@client ~]# vim /etc/fstab ...... /dev/rbd/images_pool/webapp1 /webapp/webapp1 xfs _netdev 0 0 -
确认块设备映射正常工作。使用 rbdmap map 和 rbdmap unmap 命令来挂载和卸载镜像。
-
启用 rbdmap systemd 服务。
bash[root@client ~]# systemctl enable rbdmap.service -
重启系统验证。
bash
[root@client ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 200G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 199G 0 part
├─cs-root 253:0 0 70G 0 lvm /
├─cs-swap 253:1 0 3.9G 0 lvm [SWAP]
└─cs-home 253:2 0 125.1G 0 lvm /home
sr0 11:0 1 12.8G 0 rom
rbd0 252:0 0 1G 0 disk /webapp/webapp1 #开机自动挂载如需更多信息,请参见 rbdmap(8)。
使用 librbd 库访问 Ceph 块存储-配合虚拟化,不过多讲解
使用 librbd 库访问 Ceph 块存储
librbd 库为用户空间应用提供对 RBD 镜像的直接访问。它继承 librados 的功能,将数据块映射到 Ceph 对象存储中的对象,并且实施相关的功能来访问 RBD 镜像和创建快照与克隆。
**OpenStack 和 libvirt 等云和虚拟化解决方案使用 librbd 将 RBD 镜像作为块设备提供给它们管理的云实例和虚拟机。**例如,RBD 镜像可以存储 QEMU 虚拟机镜像。
- 使用 RBD 克隆功能时,虚拟化容器可以在不复制引导镜像的情况下引导虚拟机。
- 使用写时复制 (COW) 机制,在将数据写入到克隆中的未分配对象时,会将数据从父级复制到克隆。
- 使用读时复制 (COR) 机制,在从克隆中的未分配对象读取数据时,会将数据从父级复制到克隆。
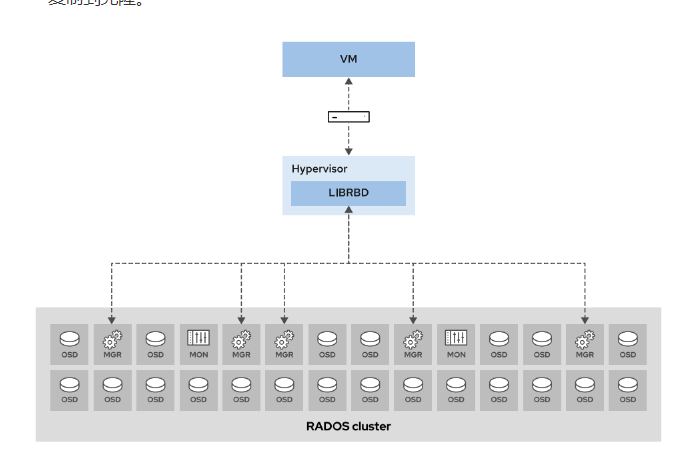
RBD 缓存
Ceph 块设备是在用户空间实施(如 librbd),无法利用 Linux 页面缓存。Ceph 块设备会使用Linux系统自己的内存中缓存 ,称为 RBD 缓存。RBD 缓存的行为与 Linux 页面缓存相似。操作系统实施阻碍机制或清空请求时,Ceph 会将所有脏数据写入到 OSD。这意味着,在虚拟机正确发送清空时(例如,Linux 内核 >= 2.6.32),使用回写缓存与使用物理硬盘缓存一样安全。缓存采用"最早使用"(LRU) 算法,而且在回写模式中,它可以联合毗邻的请求来获得更佳的吞吐量。
**RBD 缓存对客户端而言是本地的,因为它使用发起 I/O 请求的计算机上的 RAM。**例如,如果用户的OpenStack 平台安装中有 Nova 计算节点,并且它们将 librbd 用于其虚拟机,则发起 I/O 请求的 OpenStack 客户端会将本地 RAM 用于其 RBD 缓存。
RBD 缓存模式
- 未启用缓存,读取和写入前往 Ceph 对象存储。数据在写入所有相关的 OSD 日志和写入 OSD 设备完成后,Ceph 集群确认写入。
- 回写缓存(write-back) ,需要考量两个值:未清空缓存字节数 U 和最大脏缓存字节数 M。如果 U < M,则此时缓存写入完成即确认写入完成,否则在数据写回到磁盘后确认,直到 U < M 为止。
- 直写缓存(Write-through) ,将最大脏字节数设置为 0,以强制使用直写模式。数据首先写入缓存,然后再写入所有相关的 OSD 日志和写入 OSD 设备完成后,Ceph 集群确认写入。使用直写模式,以最大程度降低服务器故障时数据丢失或文件系统损坏的风险,提供很好的读IO 。
RBD 缓存参数
-
rbd_cache,定义是否启用 RBD 缓存,可用值 true 和 false,默认值true。
-
rbd_cache_policy,定义 RBD 缓存模式,可用值:
- writearound,默认值,写入数据时不经过缓存直接写入后端硬盘。
- writeback,回写。
- writethrough,直写。
-
rbd_cache_size,定义每个 RBD 镜像的缓存大小,以字节为单位。默认值 32 MB。
-
rbd_cache_max_dirty,定义每个 RBD 镜像允许的最大脏字节数。默认值 24 MB。
-
rbd_cache_target_dirty,定义每个 RBD 镜像开始抢先清空的脏字节数。默认值 16 MB。
-
rbd_cache_max_dirty_age,定义清空前的最大页面期限,以秒为单位。默认值 1。
-
rbd_cache_writethrough_until_flush,定义启动直写模式,直至执行第一次清空,可用值 true 和 false,默认值TRUE。
示例:查看并设置以上参数。
bash
[root@ceph1 ~]# ceph config ls | grep rbd_cache
rbd_cache
rbd_cache_policy
rbd_cache_writethrough_until_flush
rbd_cache_size
rbd_cache_max_dirty
rbd_cache_target_dirty
rbd_cache_max_dirty_age
rbd_cache_max_dirty_object
rbd_cache_block_writes_upfront
[root@ceph1 ~]# for arg in $(ceph config ls|grep rbd_cache)
do
echo -n "$arg: "
ceph config get client $arg
done
rbd_cache: true
rbd_cache_policy: writearound
rbd_cache_writethrough_until_flush: true
rbd_cache_size: 33554432
rbd_cache_max_dirty: 25165824
rbd_cache_target_dirty: 16777216
rbd_cache_max_dirty_age: 1.000000
rbd_cache_max_dirty_object: 0
rbd_cache_block_writes_upfront: false
# 设置客户端
[root@ceph1 ~]# ceph config set client rbd_cache_policy writethrough
[root@ceph1 ~]# ceph config get client rbd_cache_policy
writethrough
# 设置全局
[root@ceph1 ~]# ceph config set global rbd_cache_policy writethroughRBD 镜像格式
RBD 镜像布局
RBD 镜像中的所有对象的名称以各个 RBD 块名称前缀字段中包含的值为开头,可使用rbd info 命令来显示。此前缀后是句点 (.),后跟对象编号。对象编号字段的值是 12 个字符的十六进制数字。
bash
[root@client ~]# rbd info images_pool/webapp1 --id rbd
rbd image 'webapp1':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: acb9415d427f
block_name_prefix: rbd_data.acb9415d427f
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Aug 21 21:06:45 2025
access_timestamp: Thu Aug 21 21:06:45 2025
modify_timestamp: Thu Aug 21 21:06:45 2025Ceph 块设备允许将数据分条存储在Ceph 存储集群中的多个对象存储设备 (OSD) 上。
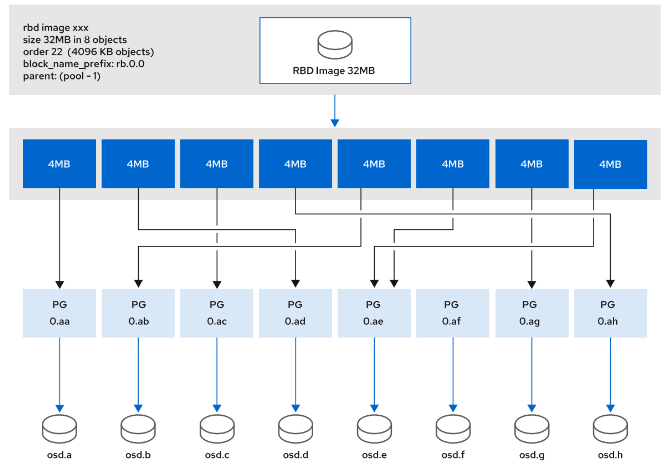
RBD 镜像阶数
**镜像阶数是用于定义 RBD 镜像的对象大小。**镜像阶数基于 <<(按位左移)C 运算符来定义二进制偏移值。此运算符按照右侧运算对象来偏移左侧运算对象。
例如,1 << 2 = 4。十进制 1 在二进制中是 1,因此 1 << 2 = 4 运算的结果是二进制的 100,也就是十进制的 4。
镜像阶数的值必须在12 到 25 之间,其中 12 = 4 KiB,13 = 8 KiB,以此类推。例如,镜像阶数默认为 22,生成 4 MiB 对象。用户可使用 rbd create 命令的 --order 选项来覆盖默认值。
**用户也可通过 --object-size 选项指定对象的大小。**此参数必须指定介于 4096 字节 (4 KiB) 和33,554,432 字节 (32 MiB) 之间的对象大小,以字节、K 或 M 表示(例如,4096、8 K 或 4 M)。
bash
[root@client ~]# rbd help create
usage: rbd create [--pool <pool>] [--namespace <namespace>] [--image <image>]
[--image-format <image-format>] [--new-format]
[--order <order>] [--object-size <object-size>]
[--image-feature <image-feature>] [--image-shared]
[--stripe-unit <stripe-unit>]
[--stripe-count <stripe-count>] [--data-pool <data-pool>]
[--mirror-image-mode <mirror-image-mode>]
[--journal-splay-width <journal-splay-width>]
[--journal-object-size <journal-object-size>]
[--journal-pool <journal-pool>]
[--thick-provision] --size <size> [--no-progress]
<image-spec>
Create an empty image.
Positional arguments
<image-spec> image specification
(example: [<pool-name>/[<namespace>/]]<image-name>)
......RBD 镜像格式
与每个 RBD 镜像关联的参数有三个:
- image_format,RBD 镜像格式版本。默认值为 2,即最新的版本。版本 1 已弃用,而且不支持克隆和镜像等功能。
- stripe_unit,一个对象中存储的连续字节数(默认为 object_size)。
- stripe_count,一个条带跨越的 RBD 镜像对象数量(默认为 1)。
对于 RBD 格式 2 镜像,用户可以更改以上各个参数的值。设置必须与下列等式一致:
stripe_unit * stripe_count = object_size例如: stripe_unit = 1048576, stripe_count = 8 for default 8 MiB objects
bash
[root@client ~]# rbd create --stripe-unit=1M --stripe-count=8 --size 1G images_pool/webapp2 --id rbd
[root@client ~]# rbd info images_pool/webapp2 --id rbd
rbd image 'webapp2':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: ada41793809a
block_name_prefix: rbd_data.ada41793809a
format: 2
features: layering, striping, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Aug 21 23:07:26 2025
access_timestamp: Thu Aug 21 23:07:26 2025
modify_timestamp: Thu Aug 21 23:07:26 2025
stripe unit: 1 MiB
stripe count: 8使用 rbd 命令管理镜像
status
用于查看哪些客户端在使用该镜像。
bash
[root@client ~]# rbd status images_pool/webapp1 --id rbd
Watchers:
watcher=192.168.108.10:0/2614504094 client.44320 cookie=18446462598732840961
[root@client ~]# rbd status images_pool/webapp2 --id rbd
Watchers: nonedu
用于查看镜像大小使用情况。
bash
[root@client ~]# rbd du images_pool/webapp1 --id rbd
NAME PROVISIONED USED
webapp1 1 GiB 36 MiBresize
用于扩展和缩减镜像。
bash
# 扩展未在使用的镜像
[root@client ~]# rbd resize images_pool/webapp2 --size 2G --id rbd
Resizing image: 100% complete...done.
[root@client ~]# rbd du images_pool/webapp2
NAME PROVISIONED USED
webapp2 2 GiB 0 B
# 扩展正在使用的镜像
[root@client ~]# rbd resize images_pool/webapp1 --size 2G --id rbd
Resizing image: 100% complete...done.
[root@client ~]# lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 2G 0 disk /webapp/webapp1
[root@client ~]# df -h /dev/rbd0
Filesystem Size Used Avail Use% Mounted on
/dev/rbd0 1014M 40M 975M 4% /webapp/webapp1
[root@client ~]# xfs_growfs /webapp/webapp1/
[root@client ~]# df -h /webapp/webapp1/
Filesystem Size Used Avail Use% Mounted on
/dev/rbd0 2.0G 48M 2.0G 3% /webapp/webapp1
# 缩减镜像
[root@client ~]# rbd resize images_pool/webapp2 --size 1G --id rbd
rbd: shrinking an image is only allowed with the --allow-shrink flag
[root@client ~]# rbd resize images_pool/webapp2 --size 1G --allow-shrink --id rbd
Resizing image: 100% complete...done.
[root@client ~]# rbd du images_pool/webapp2 --id rbd
NAME PROVISIONED USED
webapp2 1 GiB 0 B
# 缩减正在使用的镜像(xfs文件系统不支持缩减)rename 和 mv
用于重命名镜像,该操作不支持跨池。
bash
# 创建新池
[root@ceph1 ~]# ceph osd pool create images_pool_2 32 32
pool 'images_pool_2' created
[root@ceph1 ~]# rbd pool init images_pool_2
# 重命名
[root@ceph1 ~]# rbd rename images_pool/webapp2 images_pool/webapp02
[root@ceph1 ~]# rbd ls images_pool
webapp02
webapp1
[root@ceph1 ~]# rbd mv images_pool/webapp02 images_pool/webapp2
[root@ceph1 ~]# rbd ls images_pool
webapp1
webapp2
# 跨池重命名
[root@ceph1 ~]# rbd rename images_pool/webapp2 images_pool_2/webapp02
rbd: mv/rename across pools not supported #不支持
source pool: images_pool dest pool: images_pool_2cp
用于复制镜像。
bash
#实验前观察
[root@client ~]# ceph osd lspools
1 device_health_metrics
2 images_pool
3 images_pool_2
[root@client ~]#
[root@client ~]# rbd ls images_pool
webapp1
webapp2
[root@client ~]# rbd ls images_pool_2
[root@ceph1 ~]# rbd cp images_pool/webapp2 images_pool_2/webapp2 #打这条命令之前可以先rbd ls -p images_pool_2查看下
Image copy: 100% complete...done.
[root@ceph1 ~]# rbd ls -p images_pool
webapp1
webapp2
[root@ceph1 ~]# rbd ls -p images_pool_2
webapp2 #原来images_pool_2是没有image的,通过copy产生trash
使用垃圾箱管理镜像。
bash
# 将镜像放入垃圾箱
[root@ceph1 ~]# rbd ls images_pool #先查看下images_pool
webapp1
webapp2
[root@ceph1 ~]# rbd trash mv images_pool/webapp2
[root@ceph1 ~]# rbd ls images_pool #再验证
webapp1
[root@ceph1 ~]# rbd trash ls images_pool
ada41793809a webapp2
# 恢复垃圾箱中镜像,必须使用id
[root@ceph1 ~]# rbd trash restore -p images_pool ada41793809a
[root@ceph1 ~]# rbd ls images_pool
webapp1
webapp2
[root@client ~]# rbd trash ls images_pool
# 删除垃圾箱中镜像
[root@ceph1 ~]# rbd trash mv images_pool/webapp2
[root@ceph1 ~]# rbd trash ls images_pool
ada41793809a webapp2
[root@ceph1 ~]# rbd trash rm -p images_pool ada41793809a #将回收站中的webapp2删除
Removing image: 100% complete...done.
[root@ceph1 ~]# rbd trash ls images_pool
[root@ceph1 ~]# rbd ls images_pool
webapp1rm
用于删除镜像。
bash
[root@ceph1 ~]# rbd rm images_pool_2/webapp2
Removing image: 100% complete...done.
[root@ceph1 ~]# rbd ls images_pool_2管理 RADOS 块设备快照
RBD 镜像功能
使用 格式 2 的RBD 镜像支持若干可选功能:
- layering,镜像分层功能,该功能支持快照和克隆。
- striping,提高性能的分条 v2 功能,由 librbd 提供支持。
- exclusive-lock,独占锁定功能。
- object-map,对象映射功能(依赖 exclusive-lock)。
- fast-diff,快速 diff 命令功能(依赖 object-map 和 exclusive-lock)。
- deep-flatten,扁平化 RBD 镜像的所有快照。
- journaling,日志功能(依赖 exclusive-lock)。
- data-pool,EC 数据池功能。
在RBD的features中,源代码定义如下
bash
#define RBD_FEATURE_LAYERING (1ULL<<0)
#define RBD_FEATURE_STRIPINGV2 (1ULL<<1)
#define RBD_FEATURE_EXCLUSIVE_LOCK (1ULL<<2)
#define RBD_FEATURE_OBJECT_MAP (1ULL<<3)
#define RBD_FEATURE_FAST_DIFF (1ULL<<4)
#define RBD_FEATURE_DEEP_FLATTEN (1ULL<<5)
#define RBD_FEATURE_JOURNALING (1ULL<<6)
#define RBD_FEATURE_DATA_POOL (1ULL<<7)
(1ULL<<0) 2^0=1
(1ULL<<1) 2^1=2
(1ULL<<2) 2^2=4
(1ULL<<3) 2^3=8
(1ULL<<4) 2^4=16
(1ULL<<5) 2^5=32
(1ULL<<6) 2^6=64
(1ULL<<7) 2^7=128集群中 RBD 镜像默认启用功能:
layering, exclusive-lock, object-map, fast-diff, deep-flatten
bash
[root@ceph1 ~]# ceph config get client rbd_default_features
layering,exclusive-lock,object-map,fast-diff,deep-flatten-
使用命令 ceph config set client rbd_default_features value 命令设置镜像默认功能。
-
/etc/ceph/ceph.conf 的 client 中 rbd_default_features 参数定义镜像支持的功能。
-
命令行创建image时候,可以通过 --image-feature feature-name 指定镜像功能。
禁用 object-map 功能
bash
[root@ceph1 ~]# rbd feature disable images_pool/webapp1 object-map启用 object-map 功能
bash
[root@ceph1 ~]# rbd feature enable images_pool/webapp1 object-map有些功能是永久性的,不能直接禁用和启用,例如 layering。
bash
[root@ceph1 ~]# rbd feature disable images_pool/webapp1 layering
rbd: failed to update image features: (22) Invalid argument
2025-08-22T17:31:15.602+0800 7ff4768033c0 -1 librbd::Operations: cannot update immutable featuresRBD 快照
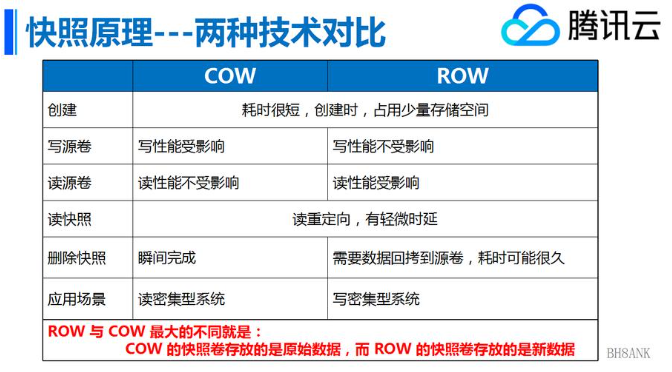
RBD 快照使用 COW 技术 ,实现最大程度减少维护快照所需的存储空间。在将写入 I/O 请求应用到 RBD 快照镜像前,集群会将原始数据复制到 I/O 操作所影响对象的 PG 中的另一区域。快照在创建时不会占用存储空间,随着所包含对象的变化而增大。RBD 镜像支持增量快照。

快照 COW 技术在对象级别上运行,不受对 RBD 镜像发出的写入 I/O 请求大小的限制。如果用户在有快照的 RBD 镜像中写入一个字节,则 Ceph 会将整个受影响的对象从 RBD 镜像复制到快照区域。
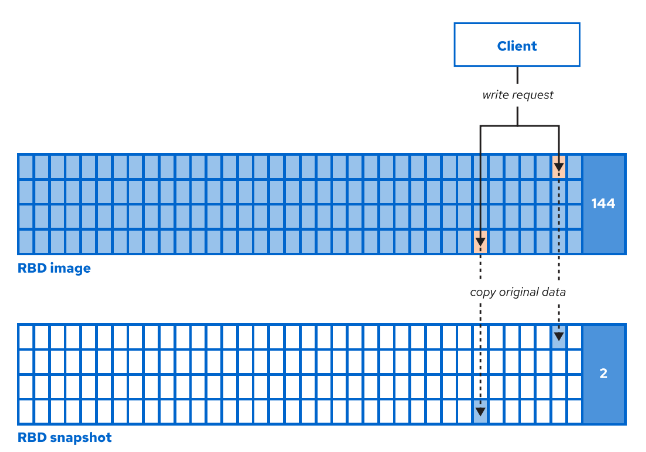
注意: 在拍摄快照前,一定要完成以下任一操作:
- 卸载文件系统。
- 使用 fsfreeze命令冻结文件系统,只允许读操作。
使用 rbd snap create 命令,创建 Ceph 块设备的快照。
bash
# 重新创建一个镜像
[root@client ~]# export CEPH_ARGS='--id=rbd'
[root@client ~]# rbd create images_pool/webapp --size 2G
[root@client ~]# rbd map images_pool/webapp
/dev/rbd1
[root@client ~]# mkfs.xfs /dev/rbd/images_pool/webapp
[root@client ~]# mkdir /webapp/webapp
[root@client ~]# mount /dev/rbd/images_pool/webapp /webapp/webapp
[root@client ~]# echo Hello World > /webapp/webapp/index.html
[root@client ~]# cat /webapp/webapp/index.html
Hello World
# 卸载文件系统
[root@client ~]# umount /webapp/webapp
# 拍摄快照
[root@client ~]# rbd snap create images_pool/webapp@snap1
Creating snap: 100% complete...done.
[root@client ~]# rbd snap ls images_pool/webapp
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 snap1 2 GiB Fri Aug 22 17:52:20 2025
# 挂载文件系统,并写入新数据
[root@client ~]# mount /dev/rbd/images_pool/webapp /webapp/webapp
[root@client ~]# echo Hello dcr > /webapp/webapp/index.html
[root@client ~]# cat /webapp/webapp/index.html
Hello dcr使用 rbd snap ls 命令,列出块设备快照。
bash
[root@client ~]# rbd snap ls images_pool/webapp
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 snap1 2 GiB Fri Aug 22 17:52:20 2025RBD 快照是创建于特定时间的 RBD 镜像的只读副本。
重要提示:镜像快照和镜像具有相同的文件系统,同一客户端不允许挂载具有相同UUID的文件系统。
bash
#将/webapp/webapp里的index.html删除,通过挂载/webapp/webapp@snap1找回来
[root@client ~]# rm /webapp/webapp/index.html
# 在挂载快照前,需要卸载原始镜像
[root@client ~]# umount /dev/rbd/images_pool/webapp
[root@client ~]# mkdir /webapp/webapp-snap1
[root@client ~]# rbd map images_pool/webapp@snap1
/dev/rbd2
[root@client ~]# mount /dev/rbd/images_pool/webapp@snap1 /webapp/webapp-snap1
mount: /webapp/webapp1-snap1: WARNING: device write-protected, mounted read-only.
[root@client ~]# cat /webapp/webapp-snap1/index.html #将快照里的文件复制出来,实现数据找回
Hello World使用 rbd snap rollback 命令,回滚块设备快照,并用快照中的数据覆盖镜像的当前版本。
实践效果,回滚失败。
bash
# 回滚快照失败
[root@client ~]# rbd snap rollback images_pool/webapp@snap1
Rolling back to snapshot: 0% complete...failed.
rbd: rollback failed: (30) Read-only file system
# 后续我们使用克隆实现恢复使用 rbd snap rm 命令,删除 Ceph 块设备的快照。
bash
[root@client ~]# umount /dev/rbd/images_pool/webapp@snap1
[root@client ~]# rbd unmap images_pool/webapp@snap1
[root@client ~]# rbd snap rm images_pool/webapp@snap1
Removing snap: 100% complete...done.
[root@client ~]# rbd snap ls images_pool/webapp使用 rbd snap purge 命令,删除镜像所有快照。
bash
u[root@client ~]# rbd snap create images_pool/webapp@snap1
[root@client ~]# rbd snap create images_pool/webapp@snap2
[root@client ~]# rbd snap ls images_pool/webapp
SNAPID NAME SIZE PROTECTED TIMESTAMP
6 snap1 2 GiB Fri Aug 22 18:07:20 2025
7 snap2 2 GiB Fri Aug 22 18:07:22 2025
[root@client ~]# rbd snap purge images_pool/webapp
Removing all snapshots: 100% complete...done.
[root@client ~]# rbd snap ls images_pool/webapp提示:镜像存在快照时,将无法删除 RBD 镜像。
RBD 克隆
RBD 克隆是 RBD 镜像的可读写副本,它使用受保护的 RBD 快照克隆。RBD 克隆也可以被扁平化,转换为独立于来源的 RBD 镜像。
克隆过程有三个步骤:
-
创建快照
bash[root@client ~]# rbd snap create images_pool/webapp@snap1 [root@client ~]# rbd snap ls images_pool/webapp SNAPID NAME SIZE PROTECTED TIMESTAMP 10 snap1 2 GiB Fri Aug 22 18:10:18 2025 #看PROTECTED列默认未保护 -
保护快照以免被删除
bash[root@client ~]# rbd snap protect images_pool/webapp@snap1 [root@client ~]# rbd snap ls images_pool/webapp SNAPID NAME SIZE PROTECTED TIMESTAMP 10 snap1 2 GiB yes Fri Aug 22 18:10:18 2025 -
使用受保护的快照创建克隆
bash[root@client ~]# rbd clone images_pool/webapp@snap1 images_pool/webapp-clone-1 [root@client ~]# rbd map images_pool/webapp-clone-1 /dev/rbd3 [root@client ~]# mkdir /webapp/webapp-clone-1 [root@client ~]# umount /webapp/webapp # 挂载clone前确保镜像和快照不要挂载 # 挂载clone前确保镜像和快照不要挂载 [root@client ~]# mount /dev/rbd/images_pool/webapp-clone-1 /webapp/webapp-clone-1 [root@client ~]# df /webapp/webapp-clone-1/ Filesystem 1K-blocks Used Available Use% Mounted on /dev/rbd2 2086912 47864 2039048 3% /webapp/webapp-clone-1新创建的克隆可以像常规 RBD 镜像一样运作,克隆支持 COW 和 COR技术,默认只支持 COW。COW 会将父快照数据复制到克隆中,然后将写入 I/O 请求应用到克隆。
bash[root@ceph1 ~]# ceph config get client rbd_clone_copy_on_read false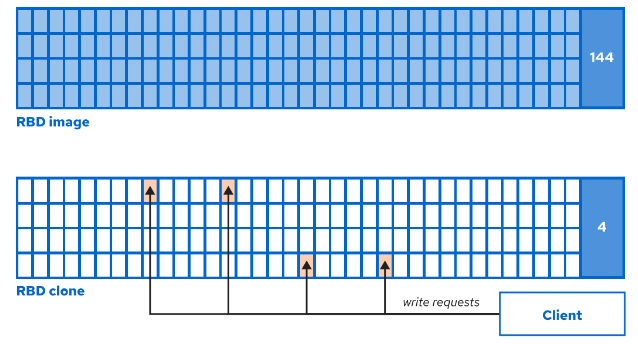
RBD 克隆未启用 COR 功能时,父 RBD 快照和克隆相同的数据会直接从父快照读取。相对于客户端而言,父快照的 OSD 具有较高的延迟,这种操作会提高读取的代价。
**如果用户启用了 COR,并且克隆中尚未存在数据,则 Ceph 会在处理读取 I/O 请求前先从父快照复制数据到克隆。**通过为客户端或全局设置运行 ceph config set client rbd_clone_copy_on_read true 命令或 ceph ceph config set global rbd_clone_copy_on_read true 命令来激活 COR 功能。原始数据不会被覆盖。
bash
# ceph config set client rbd_clone_copy_on_read true
# ceph config get client rbd_clone_copy_on_read
true如果不对 RBD 克隆启用 COR,则克隆无法满足的每个读取操作都会对克隆的父级发出 I/O 请求。
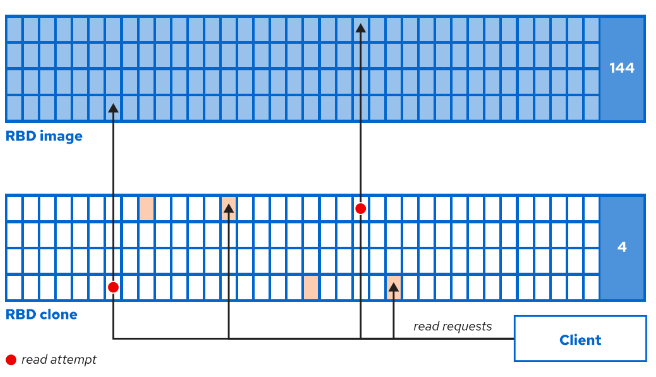
克隆 COW 和 COR 步骤在对象级别上运行,不受 I/O 请求大小的限制。要读取或写入 RBD 克隆的单个字节,Ceph 会将整个对象从父镜像或快照复制到克隆。
查看基于特定快照的克隆列表
bash
[root@client ~]# rbd clone images_pool/webapp@snap1 images_pool/webapp-clone-2
[root@client ~]# rbd children images_pool/webapp@snap1
images_pool/webapp-clone-1
images_pool/webapp-clone-2扁平化克隆,Ceph 会将所有缺失的数据从父级复制到克隆,然后移除对父级的引用。克隆会变成独立的 RBD 镜像,不再是受保护快照的子级。
bash
[root@client ~]# rbd flatten images_pool/webapp-clone-1
Image flatten: 100% complete...done.
[root@client ~]# rbd children images_pool/webapp@snap1
images_pool/webapp-clone-2挂载克隆镜像
通过镜像快照克隆出来的镜像,具有原镜像相同的文件系统,而同一客户端不允许挂载具有相同UUID的文件系统。怎么处理?
答案:修改文件系统UUID。
假设客户端将克隆出来的镜像映射为/dev/rbd3设备。操作如下:
bash
[root@client ~]# rbd map images_pool/webapp-clone-2
/dev/rbd4
blkid | grep rbd #看UUID
# 生成新的 UUID
[root@client ~]# uuidgen
e0e005e5-c8a0-4102-a266-3964c7069e18
# 修改 ext4 文件系统 UUID
[root@client ~]# tune2fs -U e0e005e5-c8a0-4102-a266-3964c7069e18 /dev/rbd4
# 修改 xfs 文件系统 UUID
[root@client ~]# xfs_admin -U e0e005e5-c8a0-4102-a266-3964c7069e18 /dev/rbd4
Clearing log and setting UUID
writing all SBs
new UUID = e0e005e5-c8a0-4102-a266-3964c7069e18
# 挂载测试
[root@client ~]# mkdir /webapp/webapp-clone-2
[root@client ~]# mount /dev/rbd4 /webapp/webapp-clone-2/
#查看现象
[root@client ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 200G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 199G 0 part
├─cs-root 253:0 0 70G 0 lvm /
├─cs-swap 253:1 0 3.9G 0 lvm [SWAP]
└─cs-home 253:2 0 125.1G 0 lvm /home
sr0 11:0 1 12.8G 0 rom
rbd0 252:0 0 2G 0 disk /webapp/webapp1
rbd1 252:16 0 2G 0 disk
rbd2 252:32 0 2G 1 disk
rbd3 252:48 0 2G 0 disk /webapp/webapp-clone-1
rbd4 252:64 0 2G 0 disk /webapp/webapp-clone-2 #挂载上了
[root@client ~]# 导入和导出 RBD 镜像
导入和导出 RBD 镜像
利用 RBD 导出与导入机制,用户可以在同一集群中,也可以使用另一独立集群维护拥有完整功能和可访问性的 RBD 镜像操作副本。
用户可以将这些副本用于各种不同的用例,包括:
- 利用实际的数据卷测试新版本
- 利用实际的数据卷运行质量保障流程
- 实施业务连续性方案
- 将备份进程从生产块设备分离
导出 RBD 镜像
Ceph 存储提供 rbd export 命令来将 RBD 镜像导出到文件。此命令可以将 RBD 镜像或 RBD镜像快照导出到指定的目标文件。
rbd export 命令的语法如下:
rbd export [--export-format {1|2}] (image-spec | snap-spec) [dest-path]--export-format 选项可指定导出数据的格式,允许用户将较早的 RBD 格式 1 镜像转换为较新的格式 2 镜像。
示例:
bash
[root@ceph1 ~]# rbd export images_pool/webapp webapp.img
Exporting image: 100% complete...done.导入 RBD 镜像
Ceph 存储提供 rbd import 命令来从文件导入 RBD 镜像。此命令会新建一个镜像,并从指定的源路径导入数据。
rbd import 命令的语法如下:
rbd import [--export-format {1|2}] [--image-format format-id] [--object-size size-in-B/K/M] [--stripe-unit size-in-B/K/M --stripe-count num] [--image-feature feature-name]... [--image-shared] src-path [image-spec]-
--export-format 选项指定待导入数据的格式,必须确保 rbd export 和 rbd import 命令使用的--export-format 参数值一致。
-
在导入格式 2 的导出数据时,使用 --stripeunit、--stripe-count、--object-size 和 --image-feature 选项可创建新的 RBD 格式 2镜像。
**示例1:**同一集群导入
bash
[root@ceph1 ~]# rbd import webapp.img images_pool/webapp-backup
Importing image: 100% complete...done.
[root@ceph1 ~]# rbd ls images_pool
webapp
webapp-backup
webapp-clone-1
webapp-clone-2
webapp1
[root@ceph1 ~]# rbd info images_pool/webapp-backup
rbd image 'webapp-backup':
size 2 GiB in 512 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: afec7a78062a
block_name_prefix: rbd_data.afec7a78062a
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Fri Aug 22 19:18:19 2025
access_timestamp: Fri Aug 22 19:18:19 2025
modify_timestamp: Fri Aug 22 19:18:19 2025**示例2:**不同集群导入
bash
[root@ceph1 ~]# scp webapp.img root@ceph4:
[root@ceph4 ~]# ceph osd pool create images_pool 32
[root@ceph4 ~]# rbd pool init images_pool
[root@ceph4 ~]# rbd ls images_pool #查看
[root@ceph4 ~]# rbd import webapp.img images_pool/webapp-backup
Importing image: 100% complete...done.
[root@ceph4 ~]# rbd ls images_pool #导入后再查看
webapp-backup管道导出和导入进程
将短划线 (-) 字符指定为导出操作的目标文件会导致输出转到标准输出 (stdout)。用户还可使用短划线字符 (-) 将 stdout 或标准输入 (stdin) 指定为导出目标或导入来源。
用户可以将这两个命令传送到一个命令中。
bash
# 同一集群导出和导入
[root@ceph1 ~]# rbd export images_pool/webapp - | rbd import - images_pool/webapp-backup2
Exporting image: 100% complete...done.
Importing image: 100% complete...done.
# 不同集群导出和导入
[root@ceph1 ~]# rbd export images_pool/webapp - | ssh root@ceph4 rbd import - images_pool/webapp-backup2
root@ceph4's password: plete...
Exporting image: 100% complete...done.
Importing image: 100% complete...done.导出和导入 RBD 镜像更改-不做,使用机会不大
RADOS 块设备功能支持导出和导入整个 RBD 镜像,也可以仅导出和导入两个时间点之间的 RBD 镜像变化。
导出 RBD 镜像更改
Ceph 存储提供 rbd export-diff 命令来导出在两个时间点之间对 RBD 镜像的变更。
bash
[root@ceph1 ~]# rbd help export-diff
usage: rbd export-diff [--pool <pool>] [--namespace <namespace>]
[--image <image>] [--snap <snap>] [--path <path>]
[--from-snap <from-snap>] [--whole-object]
[--no-progress]
<source-image-or-snap-spec> <path-name>
......起始时间可以是:
- RBD 镜像的创建日期和时间,不使用 --from-snap 选项。
- RBD 镜像的快照,通过 --from-snap snapname 选项获取。
也就是:
- 如果不指定快照,命令将导出自 RBD镜像创建之后的所有更改,这与常规的 RBD 镜像导出操作相同。
- 如果用户指定起始点快照,命令将导出用户创建该快照后的更改。
终止时间可以是:
- RBD 镜像的当前内容,如 poolname/imagename。
- RBD 镜像的快照,如 poolname/imagename@snapname。
实验环境:
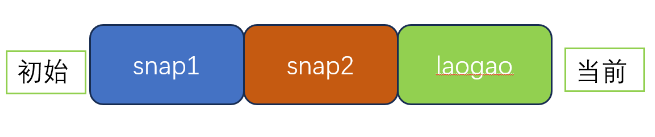
环境准备:
bash
[root@ceph1 ~]# ceph osd pool create rbd 32
[root@ceph1 ~]# rbd pool init rbd
[root@ceph1 ~]# rbd create data -s 1G
[root@ceph1 ~]# rbd map data
[root@ceph1 ~]# mkfs.xfs /dev/rbd0
[root@ceph1 ~]# mkdir -p /mnt/data
# 第一次快照内容
[root@ceph1 ~]# mount /dev/rbd0 /mnt/data
[root@ceph1 ~]# echo snap1 > /mnt/data/snap1
[root@ceph1 ~]# umount /mnt/data
[root@ceph1 ~]# rbd snap create data@snap1
# 第二次快照内容
[root@ceph1 ~]# mount /dev/rbd0 /mnt/data
[root@ceph1 ~]# echo snap2 > /mnt/data/snap2
[root@ceph1 ~]# umount /mnt/data
[root@ceph1 ~]# rbd snap create rbd/data@snap2
# 当前内容
[root@ceph1 ~]# mount /dev/rbd0 /mnt/data
[root@ceph1 ~]# echo dcr > /mnt/data/dcr
[root@ceph1 ~]# umount /dev/rbd0
[root@ceph1 ~]# rbd unmap /dev/rbd0实践部分:
bash
# 导出镜像完整变化
[root@ceph1 ~]# rbd export-diff rbd/data begin-end.data
# 导出创建之初到snap1之间变化
[root@ceph1 ~]# rbd export-diff rbd/data@snap1 begin-snap1.data
# 导出snap1到snap2之间变化
[root@ceph1 ~]# rbd export-diff --from-snap snap1 rbd/data@snap2 snap1-snap2.data
# 导出snap1到当前镜像之间变化
[root@ceph1 ~]# rbd export-diff --from-snap snap1 rbd/data snap1-end.data比较 RBD 镜像更改
Ceph 存储提供 rbd diff 命令来比较两个时间点之间对 RBD 镜像的变更。
bash
[root@ceph1 ~]# rbd help diff
usage: rbd diff [--pool <pool>] [--namespace <namespace>] [--image <image>]
[--snap <snap>] [--from-snap <from-snap>] [--whole-object]
[--format <format>] [--pretty-format]
<image-or-snap-spec>
Print extents that differ since a previous snap, or image creation.
Positional arguments
<image-or-snap-spec> image or snapshot specification
(example:
[<pool-name>/[<namespace>/]]<image-name>[@<snap-name>])
......示例:
bash
[root@ceph1 ~]# rbd diff rbd/data@snap1 >diff-s1
[root@ceph1 ~]# rbd diff rbd/data@snap2 >diff-s2
[root@ceph1 ~]# rbd diff rbd/data >diff-all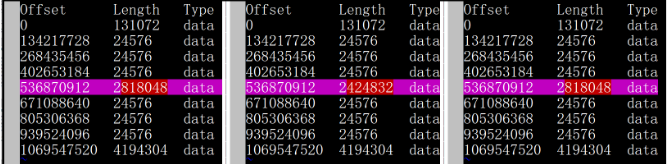
导入 RBD 镜像更改
Ceph 存储提供 rbd import-diff 命令来导入在两个时间点之间对 RBD 镜像的变更。
bash
[root@ceph1 ~]# rbd help import-diff
usage: rbd import-diff [--path <path>] [--pool <pool>]
[--namespace <namespace>] [--image <image>]
[--sparse-size <sparse-size>] [--no-progress]
<path-name> <image-spec>
......import-diff 操作执行下列有效性检查:
- 如果export-diff指定了起始快照,在目标镜像必须存在相同快照。
- 如果export-diff指定了结束快照,导出成功后,会创建同样的快照。
示例:
-
导入准备:删除所有快照
bash[root@ceph1 ~]# rbd snap purge data -
导入第一个快照
bash# 导入第一个快照 [root@ceph1 ~]# rbd import-diff begin-snap1.data rbd/data Importing image diff: 100% complete...done. [root@ceph1 ~]# rbd snap ls rbd/data SNAPID NAME SIZE PROTECTED TIMESTAMP 8 snap1 1 GiB Fri Aug 22 20:42:23 2025 # 验证第一个快照中内容 [root@ceph1 ~]# rbd map data@snap1 /dev/rbd0 [root@ceph1 ~]# mount /dev/rbd0 /mnt/data mount: /mnt/data: WARNING: device write-protected, mounted read-only. [root@ceph1 ~]# ls /mnt/data/ snap1 [root@ceph1 ~]# cat /mnt/data/snap1 snap1 [root@ceph1 ~]# umount /mnt/data -
导入第二个快照
bash# 导入第二个快照 [root@ceph1 ~]# rbd import-diff snap1-snap2.data rbd/data Importing image diff: 100% complete...done. [root@ceph1 ~]# rbd snap ls data SNAPID NAME SIZE PROTECTED TIMESTAMP 8 snap1 1 GiB Fri Aug 22 20:42:23 2025 9 snap2 1 GiB Fri Aug 22 20:43:30 2025 # 验证第二个快照中内容 [root@ceph1 ~]# rbd map data@snap2 /dev/rbd1 [root@ceph1 ~]# mount /dev/rbd1 /mnt/data mount: /mnt/data: WARNING: device write-protected, mounted read-only. [root@ceph1 ~]# ls /mnt/data/ snap1 snap2 [root@ceph1 ~]# grep . /mnt/data/* /mnt/data/snap1:snap1 /mnt/data/snap2:snap2 [root@ceph1 ~]# umount /mnt/data -
导入第一个快照到最后内容
bash# 导入第一个快照到最后内容 [root@ceph1 ~]# rbd import-diff snap1-end.data rbd/data Importing image diff: 100% complete...done. [root@ceph1 ~]# rbd snap ls data SNAPID NAME SIZE PROTECTED TIMESTAMP 8 snap1 1 GiB Fri Aug 22 20:42:23 2025 9 snap2 1 GiB Fri Aug 22 20:43:30 2025 # 验证当前内容 [root@ceph1 ~]# rbd map data /dev/rbd2 [root@ceph1 ~]# mount /dev/rbd2 /mnt/data/ [root@ceph1 ~]# ls /mnt/data/ dcr snap1 snap2 [root@ceph1 ~]# grep . /mnt/data/* /mnt/data/dcr:dcr /mnt/data/snap1:snap1 /mnt/data/snap2:snap2 [root@ceph1 ~]# umount /mnt/data
配置 RBD Mirrors
RBD Mirrors 介绍
Ceph 存储支持在两个存储集群之间进行 RBD 镜像同步,将 RBD 镜像从一个Ceph 存储集群自动复制到另一个远程集群。如果包含主要 RBD 镜像的集群变得不可用,则可以从远程集群故障转移到次要 RBD 镜像,并重启使用它的应用。
受支持的镜像配置
RBD 镜像功能支持两种配置:
- 单向镜像(主动-被动),在单向模式中,一个集群的 RBD 镜像可以读写模式访问,远程集群中包含镜像。镜像代理在远程集群上运行。这种模式可以支持配置多个次要集群。
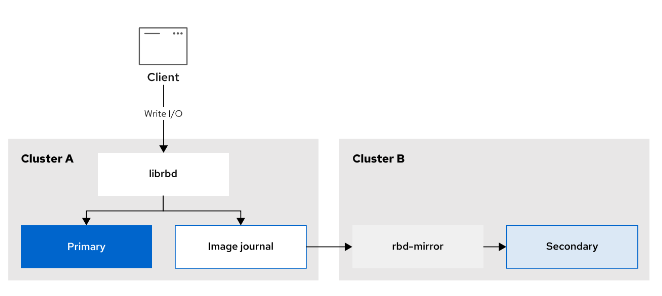
-
双向镜像(主动-主动),在双向模式中,Ceph 使来源与目标对(主要与次要)保持同步。此模式允许在两个集群之间进行复制,用户也必须在每个集群上配置镜像代理。
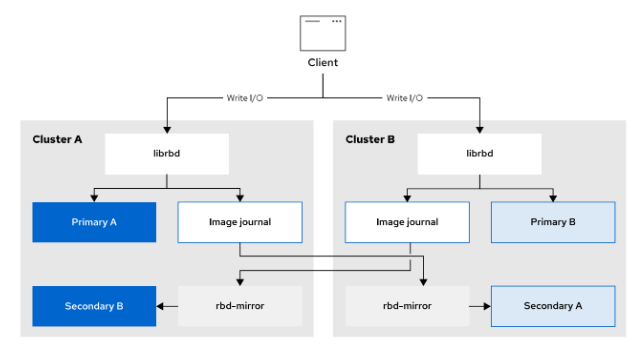
受支持的镜像模式
RBD 镜像功能支持两种模式:
- 池模式,Ceph 自动为被镜像池中的每一个 RBD 镜像启用镜像功能。当用户在来源集群上的池中创建镜像时,Ceph 会在远程集群中创建次要镜像。
- 镜像模式,Ceph 选择性地为被镜像池中的个别 RBD 镜像启用镜像功能。在这种模式中,用户必须显式选择要在两个集群之间复制的 RBD 镜像。
RBD 镜像的镜像状态
在两个Ceph 存储集群之间异步镜像,通过以下模式实现:
- 基于日志的镜像,此模式通过 RBD 日志镜像功能来确保两个Ceph 存储集群之间的时间点和崩溃一致性复制。对 RBD 镜像的每一次写入首先要记录到相关日志中,然后再修改实际镜像。远程集群从此日志中读取,并将更新内容重播到其镜像的本地副本。
- 基于快照的镜像,基于快照的镜像使用定期调度或手动创建的 RBD 镜像快照,在两个Ceph 存储集群之间复制崩溃一致性 RBD 镜像。远程集群确定两个镜像快照之间的数据或元数据更新,并将增量复制到镜像的本地副本。**RBD fast-diff 镜像功能可快速确定更新的数据块,而无需扫描完整的RBD 镜像。**在故障转移场景中,必须先同步两个快照之间的完整增量,然后才能使用。任何部分应用的增量集都会在故障转移时回滚。
RBD Mirrors 配置
存储管理员可通过在ceph存储集群之间镜像数据镜像来提高冗余度,防止数据丢失,如防范站点故障。
要实现 RBD 镜像功能,必须启用 rbd-mirror 守护进程来发现其对等集群,以及使用专用用户帐户注册对等集群。使用 rbd mirror pool peer bootstrap create 命令来自动执行此过程。
rbd-mirror 守护进程的每个实例都必须同时连接到本地和远程 Ceph 集群。此外,两个数据中心之间的网络必须有足够的带宽来处理镜像工作负载。
RBD Mirrors 过程
rbd-mirror 守护进程不要求源集群和目标集群具有唯一的内部名称;两者都可以而且应当自称为 ceph。rbd mirror pool peer bootstrap 命令会利用 --site-name 选项来描述 rbdmirror 守护进程使用的集群。
下表概述了在 prod 和 backup 两个集群之间配置镜像功能所需的步骤:
-
在 prod 和 backup 两个集群中创建一个同名池。
-
在启用 exclusive-lock 和 journaling 功能的情况下,创建或修改 RBD 镜像。
-
在池上启用池模式镜像功能。
-
在 prod 集群中,引导存储集群对等体并保存引导令牌。
-
部署 rbd-mirror 守护进程。
- 对于单向复制,rbd-mirror 守护进程仅在 backup 集群上运行。
- 对于双向复制,rbd-mirror 守护进程会在两个集群上运行。
单向-池模式-配置
在本例中,用户将看到使用 prod 和 backup 集群配置单向镜像所需的分步说明。
- ceph1 所在集群为 prod 集群
- ceph4 所在集群为 backup 集群
简要配置过程如下:
- 确保双集群状态是
HEALTH_OK。 - 双集群同时创建并初始化池。
- prod 集群创建镜像。
- prod 集群启用池模式镜像功能。
- prod 集群创建引导 token并同步到 backup 集群。
- backup 集群部署 rbd-mirror进程,并使用单向(
rx-only)导入 prod 集群token。 - 验证池和镜像状态。
具体配置过程如下:
-
确保双集群状态是
HEALTH_OK。bash[root@ceph1 ~]# ceph health HEALTH_OK [root@ceph4 ~]# ceph health HEALTH_OK -
双集群同时创建并初始化池。
bash# 主集群 [root@ceph1 ~]# ceph osd pool create rbd 32 32 [root@ceph1 ~]# rbd pool init rbd # 备集群 [root@ceph4 ~]# ceph osd pool create rbd 32 32 [root@ceph4 ~]# rbd pool init rbd -
prod 集群创建镜像。
bash[root@ceph1 ~]# rbd create image1 --size 1024 --pool rbd --image-feature=layering,exclusive-lock,journaling #创建image1并开启特性layering, exclusive-lock, journaling [root@ceph1 ~]# rbd ls image1 [root@ceph1 ~]# rbd info image1 rbd image 'image1': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: acaadb9409a3 block_name_prefix: rbd_data.acaadb9409a3 format: 2 features: layering, exclusive-lock, journaling #layering, exclusive-lock, journaling功能已经开启 op_features: flags: create_timestamp: Fri Aug 22 20:55:23 2025 access_timestamp: Fri Aug 22 20:55:23 2025 modify_timestamp: Fri Aug 22 20:55:23 2025 journal: acaadb9409a3 mirroring state: disabled #mirror没开启 -
prod 集群启用池模式镜像功能。
bash[root@ceph1 ~]# rbd mirror pool enable rbd pool #rbd池开启mirror功能,池级别 [root@ceph1 ~]# rbd info image1 rbd image 'image1': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: acaadb9409a3 block_name_prefix: rbd_data.acaadb9409a3 format: 2 features: layering, exclusive-lock, journaling op_features: flags: create_timestamp: Fri Aug 22 20:55:23 2025 access_timestamp: Fri Aug 22 20:55:23 2025 modify_timestamp: Fri Aug 22 20:55:23 2025 journal: acaadb9409a3 mirroring state: enabled #mirror开启 mirroring mode: journal #镜像模式:日志 mirroring global id: df19e4c3-cdd8-4b9f-89c5-f980d5b46c31 mirroring primary: true #主端 -
prod 集群创建引导token,并同步到 backup 集群。
bash[root@ceph1 ~]# rbd mirror pool peer bootstrap create --site-name prod rbd > bootstrap_token_prod [root@ceph1 ~]# rsync -a bootstrap_token_prod root@ceph4: -
backup 集群部署rbd-mirror进程,并导入prod 集群token。
bash[root@ceph4 ~]# ceph orch apply rbd-mirror --placement=ceph4.dcr.cloud Scheduled rbd-mirror update... [root@ceph4 ~]# ceph orch ls rbd-mirror NAME PORTS RUNNING REFRESHED AGE PLACEMENT rbd-mirror 1/1 54s ago 56s ceph4.dcr.cloud [root@ceph4 ~]# rbd mirror pool peer bootstrap import --site-name backup --direction rx-only rbd bootstrap_token_prod -
验证 backup 集群池和镜像的同步状态。
bash[root@ceph4 ~]# rbd mirror pool info rbd Mode: pool Site Name: backup Peer Sites: UUID: be8faee1-d28c-45dd-95d9-9b37099f4c58 Name: prod Direction: rx-only Client: client.rbd-mirror-peer [root@ceph4 ~]# rbd mirror pool status health: OK daemon health: OK image health: OK images: 1 total 1 replaying [root@ceph4 ~]# rbd ls image1 [root@ceph4 ~]# rbd info image1 rbd image 'image1': size 1 GiB in 256 objects order 22 (4 MiB objects) snapshot_count: 0 id: acc0c87c8d2f block_name_prefix: rbd_data.acc0c87c8d2f format: 2 features: layering, exclusive-lock, journaling op_features: flags: create_timestamp: Fri Aug 22 20:58:56 2025 access_timestamp: Fri Aug 22 20:58:56 2025 modify_timestamp: Fri Aug 22 20:58:56 2025 journal: acc0c87c8d2f mirroring state: enabled mirroring mode: journal mirroring global id: df19e4c3-cdd8-4b9f-89c5-f980d5b46c31 mirroring primary: false #mirror从 # 验证镜像同步状态 [root@ceph4 ~]# rbd mirror image status image1 image1: global_id: df19e4c3-cdd8-4b9f-89c5-f980d5b46c31 state: up+replaying description: replaying, {"bytes_per_second":17.5,"entries_behind_primary":0,"entries_per_second":0.2,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} service: ceph4.ddmzxf on ceph4.dcr.cloud last_update: 2025-08-22 20:59:22 -
验证 prod 集群池和镜像的同步状态。
bash[root@ceph1 ~]# rbd mirror pool info rbd Mode: pool Site Name: prod Peer Sites: UUID: 2e835b66-1a98-4f2a-a10c-8b6b8af39f54 Name: backup Mirror UUID: 9f354662-3968-4bc3-b809-4d7659f8bc9a Direction: tx-only # 主集群无法看到备用集群的集群状态和rbd-mirror进程状态 [root@ceph1 ~]# rbd mirror pool status health: UNKNOWN daemon health: UNKNOWN image health: OK images: 1 total 1 replaying [root@ceph1 ~]# rbd mirror image status image1 image1: global_id: df19e4c3-cdd8-4b9f-89c5-f980d5b46c31**注意:**在单向模式中,主集群无法看到备用集群的集群状态和rbd-mirror进程状态。备集群中的 RBD 镜像代理会更新状态信息。
清理配置过程如下:
-
删除镜像:优先从创建节点删除。如果同步服务已经终止,则需要强制禁用镜像同步,然后再删除。
bash[root@ceph1 ~]# rbd rm image1 -
删除同步对端
bash# 先在 backup 集群执行 [root@ceph4 ~]# rbd mirror pool peer remove rbd be8faee1-d28c-45dd-95d9-9b37099f4c58 #通过rbd mirror pool info rbd获取对方UUID # 然后在 prod 集群执行 [root@ceph1 ~]# rbd mirror pool peer remove rbd 2e835b66-1a98-4f2a-a10c-8b6b8af39f54 -
禁用池同步
bash[root@ceph1 ~]# rbd mirror pool disable rbd # 如果池中存在同步的镜像,则需要先禁用镜像同步,在禁用池同步 [root@ceph4 ~]# rbd mirror image disable image1 --force [root@ceph4 ~]# rbd mirror pool disable rbd -
删除池
bash[root@ceph1 ~]# ceph config set mon mon_allow_pool_delete true [root@ceph1 ~]# ceph osd pool rm rbd rbd --yes-i-really-really-mean-it [root@ceph4 ~]# ceph config set mon mon_allow_pool_delete true [root@ceph4 ~]# ceph osd pool rm rbd rbd --yes-i-really-really-mean-it -
删除同步进程 rbd-mirror
bash# 禁止自动管理 [root@ceph4 ~]# ceph orch apply rbd-mirror --unmanaged Scheduled rbd-mirror update... # 获取rbd-mirror进程的id [root@ceph4 ~]# systemctl list-units|grep -o ' \brbd-mirror[^ ]* ' rbd-mirror.ceph4.ddmzxf # 删除rbd-mirror进程 [root@ceph4 ~]# ceph orch daemon rm rbd-mirror.ceph4.ddmzxf或者直接删除rbd-mirror服务
bash[root@ceph4 ~]# ceph orch rm rbd-mirror
双向-池模式-配置
全新的双向池模式同步,简要配置过程如下:
- 确保双集群状态是
HEALTH_OK。 - 双集群同时创建并初始化池。
- prod 集群创建镜像。
- prod 集群启用池模式镜像功能。
- prod 集群创建引导 token并同步到 backup 集群。
- backup 集群部署 rbd-mirror进程,并使用双向(
rx-tx)导入 prod 集群token。 - prod 集群部署 rbd-mirror进程。
- 验证池和镜像状态。
基于现有的单向池模式同步更改为双向池模式同步,简要配置过程如下:
- backup 集群创建镜像。
- prod 集群删除原先自动创建的
tx-only对端。 - backup 集群删除原先单方向同步,并使用双向(
rx-tx)导入 prod 集群token。 - prod 集群部署rbd-mirror进程。
- 验证池和镜像状态。
本次演示基于全新的双向同步操作。
具体配置过程如下:
-
确保双集群状态是
HEALTH_OK。bash[root@ceph1 ~]# ceph health HEALTH_OK [root@ceph4 ~]# ceph health HEALTH_OK -
双集群同时创建并初始化池。
bash# 主集群 [root@ceph1 ~]# ceph osd pool create rbd 32 32 [root@ceph1 ~]# rbd pool init rbd # 备集群 [root@ceph4 ~]# ceph osd pool create rbd 32 32 [root@ceph4 ~]# rbd pool init rbd -
prod 集群创建镜像image1、prod 集群创建镜像image2。
bash[root@ceph1 ~]# rbd create image1 --size 1024 --pool rbd --image-feature=layering,exclusive-lock,journaling #ceph1上创建image1 [root@ceph4 ~]# rbd create image2 --size 1024 --pool rbd --image-feature=layering,exclusive-lock,journaling #ceph2上创建image2 -
双集群启用池模式镜像功能。
bash[root@ceph1 ~]# rbd mirror pool enable rbd pool [root@ceph4 ~]# rbd mirror pool enable rbd pool -
prod 集群创建引导 token并同步到 backup 集群。
bash[root@ceph1 ~]# rbd mirror pool peer bootstrap create --site-name prod rbd > bootstrap_token_prod [root@ceph1 ~]# rsync -a bootstrap_token_prod root@ceph4: -
backup 集群部署 rbd-mirror 进程,并使用双向(
rx-tx)导入 prod 集群token。bash[root@ceph4 ~]# ceph orch apply rbd-mirror --placement=ceph4.dcr.cloud Scheduled rbd-mirror update... [root@ceph4 ~]# ceph orch ls rbd-mirror NAME RUNNING REFRESHED AGE PLACEMENT rbd-mirror 1/1 4s ago 16s ceph4.dcr.cloud [root@ceph4 ~]# rbd mirror pool peer bootstrap import --site-name backup --direction rx-tx rbd bootstrap_token_prod -
验证两个集群中池同步状态。
bash# 双集群池的同步状态 [root@ceph4 ~]# rbd mirror pool status health: WARNING daemon health: OK image health: WARNING images: 2 total 2 unknown [root@ceph1 ~]# rbd mirror pool status health: UNKNOWN daemon health: UNKNOWN image health: OK images: 1 total 1 replaying # 双集群池的同步方向是双向 [root@ceph4 ~]# rbd mirror pool info rbd Mode: pool Site Name: backup Peer Sites: UUID: 8f595ed3-49b7-4806-9060-40c8b4849762 Name: prod Mirror UUID: Direction: rx-tx Client: client.rbd-mirror-peer [root@ceph1 ~]# rbd mirror pool info rbd Mode: pool Site Name: prod Peer Sites: UUID: faa7b6b6-b748-4efa-b31e-91c2eb38d689 Name: backup Mirror UUID: 8cdf8c6c-3bd3-47bd-bb45-1bb8239a5e82 Direction: rx-tx Client: client.rbd-mirror-peer -
验证两个集群镜像同步状态。
双集群image1状态
bash[root@ceph1 ~]# rbd mirror image status image1 image1: global_id: bfde0b15-681e-45fc-9ad0-9ceb74f8b585 state: down+unknown description: status not found last_update: peer_sites: name: backup state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} last_update: 2025-08-23 17:18:22 [root@ceph4 ~]# rbd mirror image status image1 image1: global_id: bfde0b15-681e-45fc-9ad0-9ceb74f8b585 state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} service: ceph4.jitnqq on ceph4.dcr.cloud last_update: 2025-08-23 17:17:22双集群image2状态
bash[root@ceph4 ~]# rbd mirror image status image2 image2: global_id: b517e528-89f6-4246-a87d-777942b13649 state: up+stopped description: local image is primary service: ceph4.jitnqq on ceph4.dcr.cloud last_update: 2025-08-23 17:19:52 # prod 集群没有rbd-mirror进程,未同步过来 [root@ceph1 ~]# rbd mirror image status image2 rbd: error opening image image2: (2) No such file or directory -
prod 集群部署rbd-mirror进程。
bash[root@ceph1 ~]# ceph orch apply rbd-mirror --placement=ceph1.dcr.cloud Scheduled rbd-mirror update... [root@ceph1 ~]# ceph orch ls rbd-mirror NAME PORTS RUNNING REFRESHED AGE PLACEMENT rbd-mirror 1/1 9s ago 12s ceph1.dcr.cloud -
验证两个集群池同步状态。
bash[root@ceph1 ~]# rbd mirror pool status health: OK daemon health: OK image health: OK images: 2 total 2 replaying [root@ceph4 ~]# rbd mirror pool status health: OK daemon health: OK image health: OK images: 2 total 2 replaying -
验证集群中镜像同步状态。
bash[root@ceph1 ~]# rbd mirror image status image1 image1: global_id: bfde0b15-681e-45fc-9ad0-9ceb74f8b585 state: up+stopped description: local image is primary service: ceph1.umpyob on ceph1.dcr.cloud last_update: 2025-08-23 17:29:28 peer_sites: name: backup state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} last_update: 2025-08-23 17:29:22 [root@ceph1 ~]# rbd mirror image status image2 image2: global_id: b517e528-89f6-4246-a87d-777942b13649 state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} service: ceph1.umpyob on ceph1.dcr.cloud last_update: 2025-08-23 17:29:58 peer_sites: name: backup state: up+stopped description: local image is primary last_update: 2025-08-23 17:29:52 [root@ceph4 ~]# rbd mirror image status image1 image1: global_id: bfde0b15-681e-45fc-9ad0-9ceb74f8b585 state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} service: ceph4.jitnqq on ceph4.dcr.cloud last_update: 2025-08-23 17:30:22 peer_sites: name: prod state: up+stopped description: local image is primary last_update: 2025-08-23 17:30:28 [root@ceph4 ~]# rbd mirror image status image2 image2: global_id: b517e528-89f6-4246-a87d-777942b13649 state: up+stopped description: local image is primary service: ceph4.jitnqq on ceph4.dcr.cloud last_update: 2025-08-23 17:30:22 peer_sites: name: prod state: up+replaying description: replaying, {"bytes_per_second":0.0,"entries_behind_primary":0,"entries_per_second":0.0,"non_primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1},"primary_position":{"entry_tid":3,"object_number":3,"tag_tid":1}} last_update: 2025-08-23 17:30:28在双向模式中:
- prod集群看到自己创建的镜像同步状态:本地是
up+stopped,对端是up+replaying。 - prod集群看到同步过来的镜像同步状态:本地是
up+replaying,对端是up+stopped。
- prod集群看到自己创建的镜像同步状态:本地是
清理配置过程如下:
-
删除镜像:优先从创建节点删除。如果同步服务已经终止,则需要强制禁用镜像同步,然后再删除。
bash[root@ceph1 ~]# rbd rm image1 [root@ceph4 ~]# rbd rm image2 -
删除同步对端
bash# 先在 prod 集群执行 [root@ceph1 ~]# rbd mirror pool peer remove rbd faa7b6b6-b748-4efa-b31e-91c2eb38d689 # 然后在 backup 集群执行 [root@ceph4 ~]# rbd mirror pool peer remove rbd 8f595ed3-49b7-4806-9060-40c8b4849762如果删除同步后,系统还会自动创建单方向同步,需要再次删除。
bash[root@ceph4 ~]# rbd mirror pool info rbd Mode: pool Site Name: backup Peer Sites: UUID: 7a9afa38-6c8a-4b0d-ac1a-ec33e670439c Name: prod Mirror UUID: 19c8d1c0-e541-4064-a328-2cab9291bdaf Direction: tx-only [root@ceph4 ~]# rbd mirror pool peer remove rbd 7a9afa38-6c8a-4b0d-ac1a-ec33e670439c # R1相同 -
禁用池同步
bash[root@ceph1 ~]# rbd mirror pool disable rbd [root@ceph4 ~]# rbd mirror pool disable rbd # 如果池中存在同步的镜像,则需要先强制禁用镜像同步 [root@ceph4 ~]# rbd mirror image disable image1 --force -
删除池
bash[root@ceph1 ~]# ceph config set mon mon_allow_pool_delete true [root@ceph1 ~]# ceph osd pool rm rbd rbd --yes-i-really-really-mean-it [root@ceph4 ~]# ceph config set mon mon_allow_pool_delete true [root@ceph4 ~]# ceph osd pool rm rbd rbd --yes-i-really-really-mean-it -
删除同步进程 rbd-mirror
bash# backup 集群操作 [root@ceph4 ~]# ceph orch apply rbd-mirror --unmanaged [root@ceph4 ~]# systemctl list-units|grep -o ' \brbd-mirror[^ ]* ' rbd-mirror.ceph4.jitnqq [root@ceph4 ~]# ceph orch daemon rm rbd-mirror.ceph4.jitnqq Removed rbd-mirror.ceph4.jitnqq from host 'ceph4.dcr.cloud' # prod 集群操作 [root@ceph1 ~]# ceph orch apply rbd-mirror --unmanaged [root@ceph1 ~]# systemctl list-units|grep -o ' \brbd-mirror[^ ]* ' rbd-mirror.ceph1.umpyob [root@ceph1 ~]# ceph orch daemon rm rbd-mirror.ceph1.umpyob Removed rbd-mirror.ceph1.umpyob from host 'ceph1.dcr.cloud'
第 7 章 Ceph 分布式存储 对象存储管理
对象存储介绍
对象存储简介
对象存储是一个基于对象的存储服务, 提供海量、 安全、 高可靠、 低成本的数据存储能力。
对象存储将数据存储为离散项,每一项也是一个对象。每个对象都具有唯一的对象ID (也称对象密钥),用户可在不了解对象位置的情况下,通过对象ID进行存储或检索。
对象存储中的对象实际是一个文件数据与其相关属性信息的集合体, 包括三个部分:
- Key:键值,即对象的名称,为经过 UTF-8 编码的长度大于0且不超过1024的字符序列。一个桶里的每个对象必须拥有唯一的对象键值。
- Metadata:元数据,即对象的描述信息,包括系统元数据和用户元数据,这些元数据以键值对(Key-Value)的形式被上传到对象存储中。元数据由对象存储产生,在处理对象数据时使用,包括Date, Content-length,Last-modify, ETag等。
- Data:数据,即文件的数据内容。
对象存储在扁平的命名空间中 ,称为桶,是对象存储存储对象的容器。 桶中的所有对象都处于同一逻辑层级, 去除了文件系统中的多层级树形目录结构。每个桶都有自己的存储类别、 访问权限、 所属区域等属性, 用户可以在不同区域创建不同存储类别和访问权限的桶, 并配置更多高级属性来满足不同场景的存储诉求。
对象存储特征
- 接入灵活:支持多种形态客户端,如通过用对象存储接口、 RESTful接口、 SDK等。
- 访问协议简单:使用http或https协议访问。
- 访问网络不受限:通过互联网或局域网都进行访问。
- 结构扁平化:对象直接存放在桶中,无目录结构。
RADOS 网关介绍
RADOS 网关简介
-
RADOS GateWay,也称对象网关 (RGW),**为客户端提供标准对象存储 API 来访问 Ceph 集群。**Ceph 存储支持 Amazon S3(简单存储服务)和 OpenStack Swift(OpenStack 对象存储)两种常用的对象 API。Amazon S3 将对象存储的扁平命名空间称为存储桶,而 OpenStack Swift 则将其称为容器。
-
守护进程 radosgw 在 librados 库的基础上构建,提供基于 Beast HTTP、WebSocket 和网络协议库的 Web 服务接口,作为处理 API 请求的前端。
-
radosgw 是Ceph 存储的客户端,用于访问对象存储中对象。
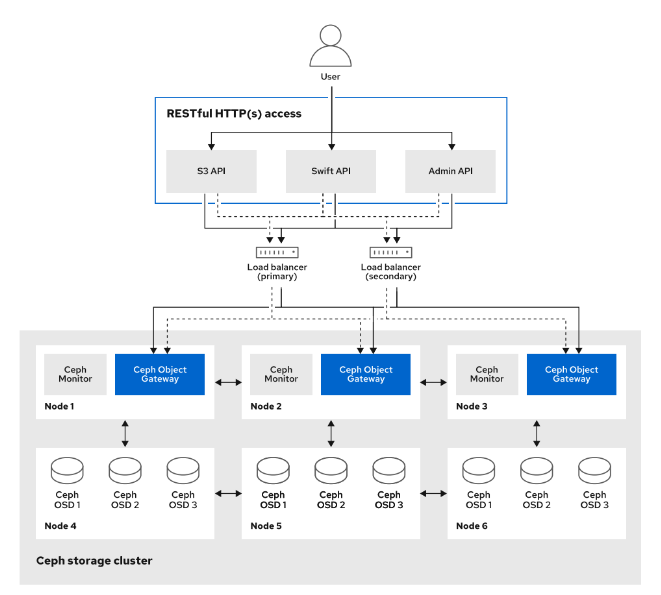
RADOS 网关中用户只能访问网关,不能像cephx 用户一样直接访问存储集群。提交 Amazon S3 或 OpenStack Swift API 请求时,RADOS 网关客户端会使用这些网关用户帐户进行身份验证。网关用户通过 RADOS 网关完成身份验证后,网关会使用 cephx 凭据向存储集群进行身份验证,以处理对象请求。也可通过集成基于 LDAP 的外部身份验证服务来管理网关用户。
RADOS 网关会为默认区域创建多个池:
- .rgw.root,存储信息记录。
- .default.rgw.control,控制池。
- .default.rgw.meta,存储 user_keys 和其他关键元数据。
- .default.rgw.log,包含所有存储桶/容器和对象操作(如创建、读取和删除)的日志。
- .default.rgw.buckets.index,存储存储桶的索引。
- .default.rgw.buckets.data,存储存储桶数据。
- .default.rgw.buckets.non-ec,用于对象元数据上传。
用户也可以手动创建这些池。建议这些池名称以区域名称为前缀,例如区域名称是 us-east-1,则池名称可以是 .us-east-1.rgw.buckets.data。
RADOS 网关架构
Ceph RADOS 网关支持多站点部署:在多个 Ceph 存储集群之间自动复制对象数据。常见的用例是在地理上分隔的集群之间进行主动/主动复制,以便于灾难恢复。
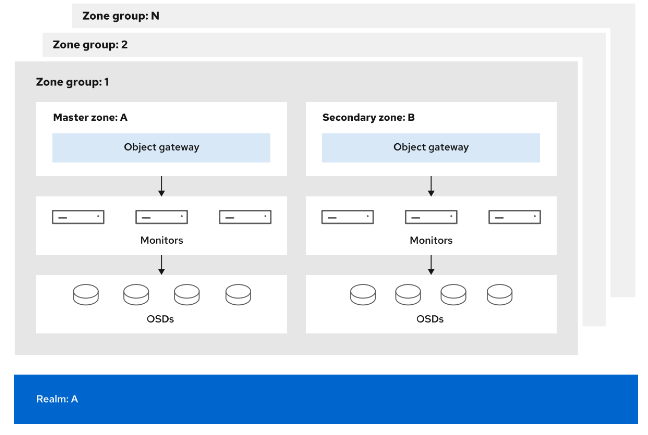
-
区域(zone),每个区域会关联一个或多个 RADOS 网关,这些网关关联Ceph 存储。
-
区域组(zone group ),区域组是由一个或多个区域的集合。存储在区域组中某个区域中的数据会被复制到该区域组中的所有其他区域。每个区域组中会有一个区域为该组的主区域 ,该组中的其他区域为次要区域。
-
域 (realm) ,代表所有对象和存储桶的全局命名空间。域中含有一个或多个区域组,各自包含一个或多个区域。域中会指定一个区域组为主区域组 ,其他都是次要区域组。域 (realm) 中的所有 RADOS 网关都从位于主区域组中主区域中的 RADOS 网关拉取配置。因为主区域组中的主区域负责处理所有元数据更新,所以创建用户等操作都必须在主区域进行。
每个域有关联的期间 (period),每个期间有关联的时期 (epoch)。
- 期间 (period),用于跟踪特定时间域、区域组和区域的配置状态。每个期间有一个唯一 ID,包含域配置,并且知道前一个期间的 ID。
- 时期 (epoch),用于跟踪特定域期间的配置版本号。
更新规则:
- 更新主区域的配置时,RADOS 网关服务使用当前时间更新期间。这个新期间会变成域的当前期间,该期间的时期值会增加一。
- 至于其他配置更改,只有时期会递增,期间不会变化。
RADOS 网关用例
Ceph 对象存储因其高扩展性、高可靠性和灵活性,适用于多种场景,包括大规模数据存储、云服务、备份归档、大数据分析、多媒体存储、容器存储、灾难恢复、混合云、科学计算和物联网数据存储等。
以下是常见的使用场景及原因:
- 大规模数据存储
- 场景: 适用于需要存储海量非结构化数据的场景,如视频、图片、日志等。
- 原因: Ceph 对象存储能轻松扩展到 PB 甚至 EB 级别,适合处理大规模数据。
- 云存储服务
- 场景: 用于公有云或私有云中的对象存储服务。
- 原因: Ceph 兼容 S3 和 Swift API,便于与现有云平台集成,提供高可用性和持久性。
- 备份和归档
- 场景: 用于长期数据备份和归档。
- 原因: Ceph 提供高可靠性和低成本存储,支持数据压缩和加密,适合长期保存。
- 大数据分析
- 场景: 存储大数据分析中的原始数据或中间结果。
- 原因: Ceph 的高吞吐量和低延迟特性,适合大数据应用的读写需求。
- 多媒体内容存储与分发
- 场景: 用于存储和分发视频、音频等多媒体内容。
- 原因: Ceph 的高并发读写能力,适合内容分发网络(CDN)的需求。
- 容器存储
- 场景: 为 Kubernetes 等容器平台提供持久化存储。
- 原因: Ceph 支持 RBD 和 CephFS,适合容器环境中的动态存储需求。
- 灾难恢复
- 场景: 用于跨地域的数据复制和灾难恢复。
- 原因: Ceph 支持多站点复制,确保数据在灾难发生时的高可用性。
- 混合云存储
- 场景: 在混合云环境中统一管理数据。
- 原因: Ceph 可在私有云和公有云之间无缝迁移数据,提供一致的存储体验。
- 科学计算与高性能计算(HPC)
- 场景: 存储科学计算和 HPC 中的大量数据。
- 原因: Ceph 的高吞吐量和并行访问能力,适合科学计算中的大规模数据处理。
- 物联网(IoT)数据存储
- 场景: 存储物联网设备生成的海量数据。
- 原因: Ceph 的高扩展性和高可靠性,适合处理物联网设备产生的大量数据。
RADOS 网关部署
Ceph 使用 Ceph 编排器来部署 (或删除) RADOS 网关服务 ,用于管理单个集群或多个集群。使用集中式配置数据库中的 client.rgw.* 部分来定义新 RADOS 网关守护进程的参数和特征。
对象存储网关部署流程:
- 创建对象存储域
- 创建对象网关
创建对象存储域
示例:
bash
# 创建 realm
[root@ceph1 ~]# radosgw-admin realm create --rgw-realm=webapp --default
[root@ceph1 ~]# radosgw-admin realm list
{
"default_info": "527e3bea-d51d-462e-92d7-79aaf422a89c",
"realms": [
"webapp"
]
}
# 创建 zonegroup,并将其设置为 master
[root@ceph1 ~]# radosgw-admin zonegroup create --rgw-realm=webapp --rgw-zonegroup=video --master --default
[root@ceph1 ~]# radosgw-admin zonegroup list
{
"default_info": "0fdaf584-33ee-4be7-978c-fb2771181aee",
"zonegroups": [
"video"
]
}
# 创建 zone,并将其设置为 master
[root@ceph1 ~]# radosgw-admin zone create --rgw-realm=webapp --rgw-zonegroup=video --rgw-zone=storage1 --master --default
[root@ceph1 ~]# radosgw-admin zone list
{
"default_info": "76366a48-2ab8-4830-9cf7-f9b2fe432c5a",
"zones": [
"storage1"
]
}
# 提交配置
[root@ceph1 ~]# radosgw-admin period update --rgw-realm=webapp --commitRADOS 网关部署
RADOS 网关部署-命令行
bash
# 创建 rgw,并和已创建的 realm webapp 进行关联,数量为 3
[root@ceph1 ~]# ceph orch apply rgw webapp --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud" --realm=webapp --zone=storage1 --port=8080
# 查看服务
[root@ceph1 ~]# ceph orch ls rgw
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
rgw.webapp ?:8080 3/3 40s ago 45s ceph1.dcr.cloud;ceph2.dcr.cloud;ceph3.dcr.cloud;count:3
# 查看进程
[root@ceph1 ~]# ceph orch ps --daemon-type rgw| awk '{print $1,$4}'
NAME STATUS
rgw.webapp.ceph1.luxaau running
rgw.webapp.ceph2.hrdzlb running
rgw.webapp.ceph3.pyfond running验证对象存储是否可以访问
yaml
[root@ceph1 ~]# curl http://ceph1.dcr.cloud:8080
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
[root@ceph1 ~]# curl http://ceph2.dcr.cloud:8080
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
[root@ceph1 ~]# curl http://ceph3.dcr.cloud:8080
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult># RADOS 网关部署-服务文件#跳过
#RADOS 网关-部署
以下示例 YAML 文件中,Ceph 编排器会将 rgw.webapp RADOS 网关服务和3个守护进程部署到单个集群中,并会通过端口 8080 提供该服务。
bash
[root@ceph1 ~]# vim rgw_service.yaml
yaml
service_type: rgw
service_id: webapp
service_name: rgw.webapp
placement:
count: 3
hosts:
- ceph1.dcr.cloud
- ceph2.dcr.cloud
- ceph3.dcr.cloud
spec:
rgw_frontend_port: 8080服务规范文件说明:
- **count 参数用于设定创建的 RGW 实例数量。**如果在一个主机上创建多个实例,Ceph 编排器会将第一个实例的端口设置为指定的 rgw_frontend_port 或 port 值。对于每个后续实例,端口值加 1。例如:ceph1.dcr.cloud 服务器运行两个 RGW 实例,一个使用端口 8080,另一个使用端口 8081。
- 每个实例都启用自己的唯一端口进行访问,并对请求创建相同的响应。通过部署提供单一服务 IP 地址和端口的负载平衡器服务,为 RADOS 网关配置高可用性。
应用部署:
bash
[root@ceph1 ~]# ceph orch apply -i rgw_service.yaml
Scheduled rgw.webapp update...**有些参数(如 RGW 实例使用的网络或 ssl 证书内容)只能使用服务规格文件来定义。**在服务规范文件中,域、区域和端口的参数名称与 CLI 使用的参数名称不同。
#RADOS 网关-实例删除
bash
# 更改 rgw.webapp 服务实例为2
[root@ceph1 ~]# vim rgw_service.yaml
yaml
service_type: rgw
service_id: webapp
service_name: rgw.webapp
placement:
count: 2
hosts:
- ceph1.dcr.cloud
- ceph2.dcr.cloud
spec:
rgw_frontend_port: 8080
bash
[root@ceph1 ~]# ceph orch apply -i rgw_service.yaml #RADOS 网关-实例添加
bash
# 更改 rgw.webapp 服务实例为3
[root@ceph1 ~]# vim rgw_service.yaml
yaml
service_type: rgw
service_id: webapp
service_name: rgw.webapp
placement:
count: 3
hosts:
- ceph1.dcr.cloud
- ceph2.dcr.cloud
- ceph3.dcr.cloud
spec:
rgw_frontend_port: 8080
bash
[root@ceph1 ~]# ceph orch apply -i rgw_service.yaml #RADOS 网关-配置备份
bash
# 查看当前 RADOS 网关配置
[root@ceph1 ~]# ceph orch ls rgw --format yaml
service_type: rgw
service_id: webapp
service_name: rgw.webapp
placement:
count: 3
hosts:
- ceph1.dcr.cloud
- ceph2.dcr.cloud
- ceph3.dcr.cloud
spec:
rgw_frontend_port: 8080
status:
created: '2023-09-20T03:07:39.524771Z'
running: 0
size: 3
events:
- 2023-09-20T03:01:03.668554Z service:rgw.webapp [INFO] "service was created"
# 备份生成的文件
[root@ceph1 ~]# ceph orch ls rgw --format yaml -o rgw_service.yaml#RADOS 网关-配置恢复
bash
# 删除status之后所有行记录
[root@ceph1 ~]# sed '/^status/,$d' rgw_service.yaml
yaml
service_type: rgw
service_id: webapp
service_name: rgw.webapp
placement:
count: 3
hosts:
- ceph1.dcr.cloud
- ceph2.dcr.cloud
- ceph3.dcr.cloud
spec:
rgw_frontend_port: 8080
bash
[root@ceph1 ~]# ceph orch apply -i rgw_service.yaml#RADOS 网关删除-跳过
删除 RADOS 网关服务,将删除 RADOS 网关对应所有进程。
bash
[root@ceph1 ~]# ceph orch rm rgw.webapp注意:删除RADOS 网关,并不会删除池中数据。
#删除对象存储域
yaml
# 删除 zone
[root@ceph1 ~]# radosgw-admin zone delete --rgw-zone=storage
# 删除 zonegroup
[root@ceph1 ~]# radosgw-admin zonegroup delete --rgw-zonegroup=video
# 删除 realm
[root@ceph1 ~]# radosgw-admin realm delete --rgw-realm=webapp管理对象网关用户
创建用户
使用 radosgw-admin user create 命令来创建 RADOS 网关用户。
- 必选选项 --uid 和 --display-name ,指定唯一的帐户名和人性化显示名。
- 可选选项 --access-key 和 --secret,指定自定义 AWS 帐户和机密密钥。
示例:
bash
[root@ceph1 ~]# radosgw-admin user create --uid="operator" --display-name="S3 Operator" --email="operator@example.com" --access-key="12345" --secret-key="67890"
{
"user_id": "operator",
"display_name": "S3 Operator",
"email": "operator@example.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "operator",
"access_key": "12345",
"secret_key": "67890"
}
],
......
[root@ceph1 ~]# radosgw-admin user list
[
"operator",
"dashboard"
]
[root@ceph1 ~]# radosgw-admin user info --uid=operator
{
"user_id": "operator",
"display_name": "S3 Operator",
"email": "operator@example.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "operator",
"access_key": "12345",
"secret_key": "67890"
}
],
......如果未指定访问密钥和机密密钥,则自动生成,并显示在输出中。
bash
[root@ceph1 ~]# radosgw-admin user create --uid=s3user --display-name="Amazon S3 API user"
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3user",
"access_key": "ZQI72JZZDTA8BRCQOLGK",
"secret_key": "BN6lMGhqacV61Fx2iEHww9N0ySI3Vvo6jMwCJnxX"
}
],
......**注意:**radosgw-admin 命令自动生成的访问密钥和机密密钥可能包含 JSON 转义字符(\)。客户端可能无法正确处理此字符。建议重新生成或手动指定密钥以避免此问题。
重新生成密钥
仅重新生成现有用户的机密密钥。
bash
[root@ceph1 ~]# radosgw-admin key create --uid=s3user --access-key="ZQI72JZZDTA8BRCQOLGK" --gen-secret
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3user",
"access_key": "ZQI72JZZDTA8BRCQOLGK",
"secret_key": "TJCcwo8rspE4xYyLAZHz4vapWA42YGB8hhrlPUnl"
}
],
......添加用户访问密钥
若要为现有用户添加访问密钥,请使用 --gen-access-key 选项。创建额外的密钥可以方便地授予同一用户对需要不同或唯一密钥的多个应用的访问权限。
bash
[root@ceph1 ~]# radosgw-admin key create --uid=s3user --gen-access-key
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3user",
"access_key": "6WBR1FL8CBFX26KVRPPA",
"secret_key": "UsytqYCeSudSqHKWwVVYZGFDdcS24lPpkXBrD42G"
},
{
"user": "s3user",
"access_key": "ZQI72JZZDTA8BRCQOLGK",
"secret_key": "TJCcwo8rspE4xYyLAZHz4vapWA42YGB8hhrlPUnl"
}
],
......删除用户密钥
要从用户删除访问密钥和相关的机密密钥,请使用 radosgw-admin key rm --access-key 命令。此操作非常适用于删除单个应用访问权限,并且不会影响使用其他密钥的访问权限。
bash
[root@ceph1 ~]# radosgw-admin key rm --uid=s3user --access-key=6WBR1FL8CBFX26KVRPPA
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3user",
"access_key": "ZQI72JZZDTA8BRCQOLGK",
"secret_key": "TJCcwo8rspE4xYyLAZHz4vapWA42YGB8hhrlPUnl"
}
],
......临时禁用对象网关用户
使用 radosgw-admin user suspend 命令可临时禁用 RADOS 网关用户,用户的子用户也会暂停,无法与 RADOS 网关服务交互。
bash
root@ceph1 ~]# radosgw-admin user suspend --uid=s3user
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 1, <----看着变成了1
....注意:suspended的值为1。
临时启用对象网关用户
使用 radosgw-admin user enable 命令可启用 RADOS 网关用户。
bash
root@ceph1 ~]# radosgw-admin user enable --uid=s3user
{
"user_id": "s3user",
"display_name": "Amazon S3 API user",
"email": "",
"suspended": 0,
....注意:suspended的值为0。
修改用户信息
用户可修改用户信息,如电子邮件、显示名、密钥和访问控制级别。
bash
[root@ceph1 ~]# radosgw-admin user modify --uid=s3user --access=full--access 选项用于控制子用户访问权限,控制级别有:read、write、 readwrite 和 full。full 访问级别包括 readwrite 级别和访问控制管理功能。
删除用户
若要移除用户,同时删除其对象和存储桶,需使用 --purge-data 选项。
bash
[root@ceph1 ~]# radosgw-admin user list
[
"operator",
"dashboard",
"s3user"
]
[root@ceph1 ~]# radosgw-admin user rm --uid=s3user --purge-data
[root@ceph1 ~]# radosgw-admin user list
[
"operator",
"dashboard"
]
[root@ceph1 ~]# 使用 Amazon S3 API 访问对象存储
Amazon S3 API 介绍
在混合云环境中,用户希望应用可以通过相同的 API 无缝混用私有企业、公共云资源和存储位置。Ceph 存储支持使用 Amazon S3 API 接口管理对象存储资源。
Amazon S3 API 称命名空间为存储桶,用于存储对象。要使用 Amazon S3 API 管理对象和存储桶,应用需通过 RADOS 网关用户进行身份验证。每个用户都有一个识别用户的 access key 和一个对用户进行身份验证的 secret key。
使用 Amazon S3 API 时,需考虑对象和元数据的大小限制:
- 对象大小介于 0B 和 5 TB 之间。
- 单次上传操作的最大大小为 5GB。
- 使用分段上传功能可上传 100MB 以上的对象。
- 单个 HTTP 请求中的元数据大小最大为 16,000 字节。
安装 Amazon S3 API 客户端
Amazon S3 API 客户端有多个,例如 awscli、cloudberry、cyberduck 和 curl。
**这里我们讲解 aws 工具。**aws工具由awscli 软件包提供。
以下演示通过pip方式安装。
bash
# 准备 aliyun 源 pip 仓库
[root@client ~]# mkdir .pip
[root@client ~]# cat > .pip/pip.conf << 'EOF'
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
EOF
# 安装软件包
[root@client ~]# pip3 install awscli使用 Amazon S3 API 客户端
aws 命令帮助信息
bash
[root@client ~]# aws
Note: AWS CLI version 2, the latest major version of the AWS CLI, is now stable and recommended for general use. For more information, see the AWS CLI version 2 installation instructions at: https://docs.aws.amazon.com/cli/latest/userguide/install-cliv2.html
usage: aws [options] <command> <subcommand> [<subcommand> ...] [parameters]
To see help text, you can run:
aws help
aws <command> help
aws <command> <subcommand> help
aws: error: the following arguments are required: command配置 AWS CLI 凭据
配置 AWS CLI 工具默认凭据:使用 operator 用户,输入 12345 作为访问密钥,67890 作为机密密钥。
bash
[root@client ~]# aws configure
AWS Access Key ID [None]: 12345
AWS Secret Access Key [None]: 67890
Default region name [None]: `回车`
Default output format [None]: `回车`配置信息保存在~/.aws目录。
bash
[root@client ~]# ls .aws
config credentials
[root@client ~]# cat .aws/config
[default]
[root@client ~]# cat .aws/credentials
[default]
aws_access_key_id = 12345
aws_secret_access_key = 67890注意:aws 命令默认使用 default 中凭据。
如果想配置多个凭据,配置如下:#跳过
bash
[root@client ~]# aws configure --profile=ceph
AWS Access Key ID [None]: 12345
AWS Secret Access Key [None]: 67890
Default region name [None]:
Default output format [None]:
[root@client ~]# cat .aws/config
[default]
[profile ceph]
[root@client ~]# cat .aws/credentials
[default]
aws_access_key_id = 12345
aws_secret_access_key = 67890
[ceph]
aws_access_key_id = 12345
aws_secret_access_key = 67890配置参考:https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html
使用参数 endpoint_url配置服务器位置。
示例:
创建存储桶
环境准备:
client:
bash
[root@client ~]# scp 192.168.108.11:/etc/hosts /etc/hosts可以通过选项 --profile 指定凭据,--endpoint 指定服务器位置。
bash
[root@client ~]# aws --endpoint=http://ceph1.dcr.cloud:8080 s3 mb s3://webapp
make_bucket: webapp查看存储桶清单
示例:
bash
[root@client ~]# aws --endpoint=http://ceph1.dcr.cloud:8080 s3 ls
2025-08-25 17:14:05 webappradosgw-admin 命令也支持存储桶操作,例如使用 radosgw-admin bucket list 或 radosgw-admin bucket rm 命令。
bash
[root@ceph1 ~]# radosgw-admin buckets list
[
"webapp"
]上传对象到存储桶
cp 子命令支持三种复制方向:
<LocalPath> <S3Uri>,将本地文件上传到对象存储中。<S3Uri> <LocalPath>,下载对象存储中对象到本地。<S3Uri> <S3Uri>,将对象存储中对象复制到对象存储中。
示例:
bash
[root@client ~]# echo Hello World > Welcome-pub.html
[root@client ~]# echo Hello dcr > Welcome-pri.html
[root@client ~]# aws --endpoint=http://ceph1.dcr.cloud:8080 s3 cp Welcome-pub.html s3://webapp/ --acl=public-read-write
upload: ./Welcome-pub.html to s3://webapp/Welcome-pub.html
[root@client ~]# aws s3 cp Welcome-pri.html s3://webapp --endpoint=http://ceph1.dcr.cloud:8080
upload: ./Welcome-pri.html to s3://webapp/Welcome-pri.html查看存储桶中对象
bash
[root@client ~]# aws s3 ls s3://webapp --endpoint=http://ceph1.dcr.cloud:8080
2025-08-25 17:23:35 13 Welcome-pri.html
2025-08-25 17:22:18 12 Welcome-pub.html下载存储桶中对象
bash
# 下载单个
[root@client ~]# aws s3 cp s3://webapp/Welcome-pri.html /tmp --endpoint=http://ceph1.dcr.cloud:8080
download: s3://webapp/Welcome-pri.html to ../tmp/Welcome-pri.html
[root@client ~]# ls /tmp/Welcome-pri.html
/tmp/Welcome-pri.html
# 使用选项 --recursive 递归下载bucket中所有对象
[root@client ~]# aws s3 cp s3://webapp /tmp --recursive --endpoint=http://ceph1.dcr.cloud:8080
download: s3://webapp/Welcome-pri.html to ../tmp/Welcome-pri.html
download: s3://webapp/Welcome-pub.html to ../tmp/Welcome-pub.html
# 使用wget或者curl下载
[root@client ~]# wget http://ceph1.dcr.cloud:8080/webapp/Welcome-pub.html # Welcome-pub.html可以正常下载
[root@client ~]# wget http://ceph1.dcr.cloud:8080/webapp/Welcome-pri.html # Welcome-pri.html不可以下载,因为权限不允许
--2025-08-25 17:36:59-- http://ceph1.dcr.cloud:8080/webapp/Welcome-pri.html
Resolving ceph1.dcr.cloud (ceph1.dcr.cloud)... 192.168.108.11
Connecting to ceph1.dcr.cloud (ceph1.dcr.cloud)|192.168.108.11|:8080... connected.
HTTP request sent, awaiting response... 403 Forbidden
2025-08-25 17:36:59 ERROR 403: Forbidden.删除存储桶中对象
bash
[root@client ~]# aws s3 rm s3://webapp/Welcome-pri.html --endpoint=http://ceph1.dcr.cloud:8080
delete: s3://webapp/Welcome-pri.html
[root@client ~]# aws s3 ls s3://webapp --endpoint=http://ceph1.dcr.cloud:8080
2025-08-25 17:22:18 12 Welcome-pub.html删除存储桶
bash
# 非空的存储桶不能删除
[root@client ~]# aws s3 rb s3://webapp --endpoint=http://ceph1.dcr.cloud:8080
remove_bucket failed: s3://webapp argument of type 'NoneType' is not iterable
# 清空存储桶,再次删除
[root@client ~]# aws s3 rm s3://webapp --recursive --include "Welcome-*" --endpoint=http://ceph1.dcr.cloud:8080
delete: s3://webapp/Welcome-pub.html
[root@client ~]# aws s3 rb s3://webapp --endpoint=http://ceph1.dcr.cloud:8080
remove_bucket: webapp用户配额管理
设置配额可限制用户或存储桶可消耗的存储量。
user 级别
--quota-scope 选项设置为 user 来应用用户配额。
启用用户配额
示例:operator用户的配额设置为最多 1024 个对象。
bash
[root@ceph1 ~]# radosgw-admin quota enable --quota-scope=user --uid=operator
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=user --uid=operator --max-objects=1024
# 查看用户配额
[root@ceph1 ~]# radosgw-admin user info --uid=operator
{
"user_id": "operator",
"display_name": "S3 Operator",
"email": "operator@example.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "operator",
"access_key": "12345",
"secret_key": "67890"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 1024
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
# 查看空间使用情况
[root@ceph1 ~]# radosgw-admin user stats --uid=operator
{
"stats": {
"size": 0,
"size_actual": 0,
"size_kb": 0,
"size_kb_actual": 0,
"num_objects": 0
},
"last_stats_sync": "0.000000",
"last_stats_update": "2025-08-25T09:44:36.609841Z"
}禁用用户配额
示例:禁用operator用户配额。
bash
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=user --uid=operator --max-objects=-1
[root@ceph1 ~]# radosgw-admin quota disable --quota-scope=user --uid=operator
[root@ceph1 ~]# radosgw-admin user info --uid=operator
{
"user_id": "operator",
"display_name": "S3 Operator",
"email": "operator@example.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "operator",
"access_key": "12345",
"secret_key": "67890"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}bucket 级别
--quota-scope 选项设置为 bucket 来应用存储桶配额。
启用 bucket 配额
示例:webapp 存储桶被设置为最多 1024 个对象。
bash
[root@client ~]# aws --endpoint=http://ceph1.dcr.cloud:8080 s3 mb s3://webapp
make_bucket: webapp
[root@ceph1 ~]# radosgw-admin quota enable --quota-scope=bucket --bucket=webapp
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=bucket --bucket=webapp --max-objects=1024
# 查看 bucket 配额
[root@ceph1 ~]# radosgw-admin bucket stats --bucket=webapp
{
"bucket": "webapp",
"num_shards": 11,
"tenant": "",
"zonegroup": "0fdaf584-33ee-4be7-978c-fb2771181aee",
"placement_rule": "default-placement",
"explicit_placement": {
"data_pool": "",
"data_extra_pool": "",
"index_pool": ""
},
"id": "76366a48-2ab8-4830-9cf7-f9b2fe432c5a.44325.2",
"marker": "76366a48-2ab8-4830-9cf7-f9b2fe432c5a.44325.2",
"index_type": "Normal",
"owner": "operator",
"ver": "0#1,1#1,2#1,3#1,4#1,5#1,6#1,7#1,8#1,9#1,10#1",
"master_ver": "0#0,1#0,2#0,3#0,4#0,5#0,6#0,7#0,8#0,9#0,10#0",
"mtime": "2025-08-25T10:12:11.164221Z",
"creation_time": "2025-08-25T10:09:12.571418Z",
"max_marker": "0#,1#,2#,3#,4#,5#,6#,7#,8#,9#,10#",
"usage": {},
"bucket_quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 1024 #webapp 存储桶被设置为最多 1024 个对象。
}
}禁用 bucket 配额
示例:
bash
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=bucket --bucket=webapp --max-objects=-1
[root@ceph1 ~]# radosgw-admin quota disable --quota-scope=bucket --bucket=webapp
# 查看配额和使用情况
[root@ceph1 ~]# radosgw-admin bucket stats --bucket=webapp
{
"bucket": "webapp",
"num_shards": 11,
"tenant": "",
"zonegroup": "0fdaf584-33ee-4be7-978c-fb2771181aee",
"placement_rule": "default-placement",
"explicit_placement": {
"data_pool": "",
"data_extra_pool": "",
"index_pool": ""
},
"id": "76366a48-2ab8-4830-9cf7-f9b2fe432c5a.44325.2",
"marker": "76366a48-2ab8-4830-9cf7-f9b2fe432c5a.44325.2",
"index_type": "Normal",
"owner": "operator",
"ver": "0#1,1#1,2#1,3#1,4#1,5#1,6#1,7#1,8#1,9#1,10#1",
"master_ver": "0#0,1#0,2#0,3#0,4#0,5#0,6#0,7#0,8#0,9#0,10#0",
"mtime": "2025-08-25T10:13:42.983364Z",
"creation_time": "2025-08-25T10:09:12.571418Z",
"max_marker": "0#,1#,2#,3#,4#,5#,6#,7#,8#,9#,10#",
"usage": {},
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1 #取消了配额
}
}global 级别
全局配额会影响集群中的所有存储桶和所有用户。
针对所有用户的配额:
bash
[root@ceph1 ~]# radosgw-admin global quota set --quota-scope user --max-objects 2048
Global quota changes saved. Use 'period update' to apply them to the staging period, and 'period commit' to commit the new period.
{
"user quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}
[root@ceph1 ~]# radosgw-admin global quota enable --quota-scope user
Global quota changes saved. Use 'period update' to apply them to the staging period, and 'period commit' to commit the new period.
{
"user quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}
# 查看配额
[root@ceph1 ~]# radosgw-admin global quota get --quota-scope user
{
"user quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}针对所有bucket配额:
bash
[root@ceph1 ~]# radosgw-admin global quota set --quota-scope bucket --max-objects 2048
Global quota changes saved. Use 'period update' to apply them to the staging period, and 'period commit' to commit the new period.
{
"bucket quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}
[root@ceph1 ~]# radosgw-admin global quota enable --quota-scope bucket
Global quota changes saved. Use 'period update' to apply them to the staging period, and 'period commit' to commit the new period.
{
"bucket quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}
# 查看配额
[root@ceph1 ~]# radosgw-admin global quota get --quota-scope bucket
{
"bucket quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 2048
}
}要在区域和期间配置中实施全局配额:
- 使用 radosgw-admin period update --commit 命令来提交更改来实施配额。
- 重启 RGW 实例来实施配额。
查看配额使用情况
存储管理员通过监控使用情况统计信息来确定存储消耗或用户带宽使用情况。监控还有助于查找不活动的应用或不当的用户配额。
显示用户在特定日期之间的使用情况统计信息。
bash
[root@ceph1 ~]# radosgw-admin usage show --uid=operator --start-date='2023-09-21T07:01:52' --end-date='2023-09-21T07:01:53'
{
"entries": [],
"summary": []
}查看所有用户的统计信息。这些总体统计数据有助于了解对象存储模式,并规划新实例的部署以扩展 RADOS 网关服务。
bash
[root@ceph1 ~]# radosgw-admin usage show --show-log-entries=false
{
"summary": []
}使用 Swift API 访问对象存储-跳过
Swift API 介绍
用户还可以通过 OpenStack Swift API 访问 Ceph 存储集群中对象。
OpenStack Swift API 的用户模型与 Amazon S3 API 的不同。
- **Amazon S3 API 授权和身份验证模型是单层设计。**一个用户帐户可能有多个访问密钥和机密,供该用户提供不同类型的访问。
- **OpenStack Swift API 是多层级设计,专为容纳租户和指定用户而构建。**Swift 租户拥有由服务使用的存储及其容器。Swift 用户分配给服务,配置不同的访问权限级别访问存储。
为了容纳 OpenStack Swift API 身份验证和授权模型,RADOS 网关使用子用户。Swift API tenant:user 模型以 user:subuser 形式映射到 RADOS 网关的身份验证系统。
- Swift API 租户 作为 RADOS 网关用户进行处理。
- Swift API 用户 作为 RADOS 网关子用户进行处理。
若要访问Swift API ,需要创建一个 Swift 用户,然后为该 Swift 用户创建一个子用户,该子用户与 RADOS 网关用户和访问密钥相关联。
还原快照做如下操作:
bash
radosgw-admin realm create --rgw-realm=webapp --default
radosgw-admin zonegroup create --rgw-realm=webapp --rgw-zonegroup=video --master --default
radosgw-admin zone create --rgw-realm=webapp --rgw-zonegroup=video --rgw-zone=storage --master --default
ceph orch apply rgw webapp --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud" --realm=webapp --zone=storage --port=8080
radosgw-admin user create --uid="operator" --display-name="swift Operator" --email="operator@example.com" --access_key="12345" --secret="67890"管理对象网关子用户
创建子用户
bash
# 这里创建 operator 子用户 operator:swift
[root@ceph1 ~]# radosgw-admin subuser create --uid=operator --subuser=operator:swift --access=full --secret=opswift
{
"user_id": "operator",
"display_name": "swift Operator",
"email": "operator@example.com",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "operator:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "operator",
"access_key": "12345",
"secret_key": "67890"
}
],
"swift_keys": [
{
"user": "operator:swift",
"secret_key": "opswift"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}- --access 选项,指定用户的权限(读取、写入、读写、完全)。
- --uid 选项,指定现有的已关联 RADOS 网关用户。
- --subuser=username:swift 选项,指定现有的已关联 RADOS 网关用户的子用户。
创建子用户 key
bash
[root@ceph1 ~]# radosgw-admin key create --uid=operator --subuser=operator:swift --key-type=swift --gen-secret--key-type 选项接受 swift 或 s3 值。如果要手动指定访问密钥,请使用 --access-key 选项;如果要手动指定机密密钥,请使用 --secret-key 选项。也可以使用 --gen-accesskey 选项仅生成随机访问密钥,或使用 --gen-secret 选项仅生成随机机密。
修改子用户
使用 radosgw-admin subuser modify 命令可修改子用户,例如访问级别、secret等。
bash
[root@ceph1 ~]# radosgw-admin subuser modify --uid=operator --subuser=operator:swift --secret=opswift --access=full删除子用户key
要删除子用户密钥,请使用 radosgw-admin key rm 命令。
bash
[root@ceph1 ~]# radosgw-admin key rm --subuser=operator:swift删除子用户
使用 radosgw-admin subuser rm 命令删除子用户。--purge-data 选项可清除与子用户关联的所有数据,--purge-keys 选项可清除所有子用户密钥。
bash
[root@ceph1 ~]# radosgw-admin subuser rm --subuser=operator:swift准备实验子用户
bash
# 创建用户 swift
[root@ceph1 ~]# radosgw-admin user create --uid=swift --display-name=swift
# 创建子账号 swift_rgw
[root@ceph1 ~]# radosgw-admin subuser create --uid=swift --subuser=swift:swift_rgw --access=full
# 创建的子账号 swift 类型 key
[root@ceph1 ~]# radosgw-admin key create --subuser=swift:swift_rgw --key-type=swift --gen-secret
{
"user_id": "swift",
"display_name": "swift",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "swift:swift_rgw",
"permissions": "full-control"
}
],
"keys": [
{
"user": "swift",
"access_key": "BXK4ZTZLO2A5W2380V8Y",
"secret_key": "ygZS3CTL1x3ja4UJMlY4M6Zb8abOQFZ3A9FOgQcM"
}
],
"swift_keys": [
{
"user": "swift:swift_rgw",
"secret_key": "9KPxNkJSvGP1i5LDs9QV4elDCoHTAjdsPJoszDWj"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
# 配置完成后,记录下生成的 Key,后续会使用该值进行认证。
# "user": "swift:swift_rgw",
# "secret_key": "9KPxNkJSvGP1i5LDs9QV4elDCoHTAjdsPJoszDWj"安装 swift 客户端
bash
# 准备 aliyun 源 pip 仓库
[root@client ~]# mkdir .pip
[root@client ~]# cat > .pip/pip.conf << 'EOF'
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
EOF
# 安装软件包
[root@client ~]# pip3 install python-swiftclient
# 确认swift版本
[root@client ~]# swift --version
python-swiftclient 4.7.0配置用户凭据
Swift 客户端与 RADOS 网关通信时,RADOS 网关同时充当数据服务器和 Swift 身份验证守护进程(使用 /auth URL 路径)。
使用环境变量提供凭据
RADOS 网关支持 Internal Swift(版本 1.0)和 OpenStack Keystone(版本2.0)身份验证:
- 如果使用的是 Auth 版本 1.0,则请使用 ST_AUTH、ST_USER 和 ST_KEY 环境变量。
- 如果使用的是 Auth 版本 2.0,则请使用OS_AUTH_URL、OS_USERNAME、OS_PASSWORD、OS_TENANT_NAME 和OS_TENANT_ID 环境变量。
bash
[root@client ~]# vim swift.rc
export ST_AUTH=http://ceph1.dcr.cloud:8080/auth/1.0
export ST_USER=swift:swift_rgw
export ST_KEY=9KPxNkJSvGP1i5LDs9QV4elDCoHTAjdsPJoszDWj #用前面的值替代
[root@client ~]# source swift.rc
[root@client ~]# swift list使用选项提供凭据
用户认证选项:
- -A 选项,指定Swift 认证 URL。
- -U 选项,指定Swift 子用户。
- -K 选项,指定Swift 子用户对应的机密。
示例:
bash
[root@client ~]# swift -A http://ceph1.dcr.cloud:8080/auth/1.0 -U "swift:swift_rgw" -K 9KPxNkJSvGP1i5LDs9QV4elDCoHTAjdsPJoszDWj list管理对象
swift 命令帮助信息
bash
[root@client ~]# swift --help
usage: swift [--version] [--help] [--os-help] [--snet] [--verbose]
[--debug] [--info] [--quiet] [--auth <auth_url>]
[--auth-version <auth_version> |
--os-identity-api-version <auth_version> ]
[--user <username>]
[--key <api_key>] [--retries <num_retries>]
[--os-username <auth-user-name>]
[--os-password <auth-password>]
[--os-user-id <auth-user-id>]
[--os-user-domain-id <auth-user-domain-id>]
[--os-user-domain-name <auth-user-domain-name>]
[--os-tenant-id <auth-tenant-id>]
[--os-tenant-name <auth-tenant-name>]
[--os-project-id <auth-project-id>]
[--os-project-name <auth-project-name>]
[--os-project-domain-id <auth-project-domain-id>]
[--os-project-domain-name <auth-project-domain-name>]
[--os-auth-url <auth-url>]
[--os-auth-token <auth-token>]
[--os-auth-type <os-auth-type>]
[--os-application-credential-id
<auth-application-credential-id>]
[--os-application-credential-secret
<auth-application-credential-secret>]
[--os-storage-url <storage-url>]
[--os-region-name <region-name>]
[--os-service-type <service-type>]
[--os-endpoint-type <endpoint-type>]
[--os-cacert <ca-certificate>]
[--insecure]
[--os-cert <client-certificate-file>]
[--os-key <client-certificate-key-file>]
[--no-ssl-compression]
[--force-auth-retry]
<subcommand> [--help] [<subcommand options>]
Command-line interface to the OpenStack Swift API.
Positional arguments:
<subcommand>
delete Delete a container or objects within a container.
download Download objects from containers.
list Lists the containers for the account or the objects
for a container.
post Updates meta information for the account, container,
or object; creates containers if not present.
copy Copies object, optionally adds meta
stat Displays information for the account, container,
or object.
upload Uploads files or directories to the given container.
capabilities List cluster capabilities.
tempurl Create a temporary URL.
auth Display auth related environment variables.
bash_completion Outputs option and flag cli data ready for
bash_completion.
Examples:
swift download --help
swift -A https://api.example.com/v1.0 \
-U user -K api_key stat -v
swift --os-auth-url https://api.example.com/v2.0 \
--os-tenant-name tenant \
--os-username user --os-password password list
swift --os-auth-url https://api.example.com/v3 --auth-version 3\
--os-project-name project1 --os-project-domain-name domain1 \
--os-username user --os-user-domain-name domain1 \
--os-password password list
swift --os-auth-url https://api.example.com/v3 --auth-version 3\
--os-project-id 0123456789abcdef0123456789abcdef \
--os-user-id abcdef0123456789abcdef0123456789 \
--os-password password list
swift --os-auth-url https://api.example.com/v3 --auth-version 3\
--os-application-credential-id d78683c92f0e4f9b9b02a2e208039412 \
--os-application-credential-secret APPLICATION_CREDENTIAL_SECRET \
--os-auth-type v3applicationcredential list
swift --os-auth-token 6ee5eb33efad4e45ab46806eac010566 \
--os-storage-url https://10.1.5.2:8080/v1/AUTH_ced809b6a4baea7aeab61a \
list
swift list --lh
optional arguments:
--version show program's version number and exit
-h, --help
--os-help Show OpenStack authentication options.
-s, --snet Use SERVICENET internal network.
-v, --verbose Print more info.
--debug Show the curl commands and results of all http queries
regardless of result status.
--info Show the curl commands and results of all http queries
which return an error.
-q, --quiet Suppress status output.
-A=AUTH, --auth=AUTH URL for obtaining an auth token.
-V=AUTH_VERSION, --auth-version=AUTH_VERSION, --os-identity-api-version=AUTH_VERSION
Specify a version for authentication. Defaults to
env[ST_AUTH_VERSION], env[OS_AUTH_VERSION],
env[OS_IDENTITY_API_VERSION] or 1.0.
-U=USER, --user=USER User name for obtaining an auth token.
-K=KEY, --key=KEY Key for obtaining an auth token.
-T=TIMEOUT, --timeout=TIMEOUT
Timeout in seconds to wait for response.
-R=RETRIES, --retries=RETRIES
The number of times to retry a failed connection.
--insecure Allow swiftclient to access servers without having to
verify the SSL certificate. Defaults to
env[SWIFTCLIENT_INSECURE] (set to 'true' to enable).
--no-ssl-compression This option is deprecated and not used anymore. SSL
compression should be disabled by default by the
system SSL library.
--force-auth-retry Force a re-auth attempt on any error other than 401
unauthorized
--prompt Prompt user to enter a password which overrides any
password supplied via --key, --os-password or
environment variables.子命令帮助信息
bash
[root@client ~]# swift upload --help
Usage: swift upload [--changed] [--skip-identical] [--segment-size <size>]
[--segment-container <container>] [--leave-segments]
[--object-threads <thread>] [--segment-threads <threads>]
[--meta <name:value>] [--header <header>] [--use-slo]
[--use-dlo] [--ignore-checksum] [--skip-container-put]
[--object-name <object-name>]
<container> <file_or_directory> [<file_or_directory>] [...]
Uploads specified files and directories to the given container.
Positional arguments:
<container> Name of container to upload to.
<file_or_directory> Name of file or directory to upload. Specify multiple
times for multiple uploads. If "-" is specified, reads
content from standard input (--object-name is required
in this case).
Optional arguments:
-c, --changed Only upload files that have changed since the last
upload.
--skip-identical Skip uploading files that are identical on both sides.
-S, --segment-size <size>
Upload files in segments no larger than <size> (in
Bytes) and then create a "manifest" file that will
download all the segments as if it were the original
file.
--segment-container <container>
Upload the segments into the specified container. If
not specified, the segments will be uploaded to a
<container>_segments container to not pollute the
main <container> listings.
--leave-segments Indicates that you want the older segments of manifest
objects left alone (in the case of overwrites).
--object-threads <threads>
Number of threads to use for uploading full objects.
Default is 10.
--segment-threads <threads>
Number of threads to use for uploading object segments.
Default is 10.
-m, --meta <name:value>
Sets a meta data item. This option may be repeated.
Example: -m Color:Blue -m Size:Large
-H, --header <header:value>
Adds a customized request header. This option may be
repeated. Example: -H "content-type:text/plain"
-H "Content-Length: 4000".
--use-slo When used in conjunction with --segment-size it will
create a Static Large Object. Deprecated; this is now
the default behavior when the cluster supports it.
--use-dlo When used in conjunction with --segment-size it will
create a Dynamic Large Object. May be useful with old
swift clusters.
--ignore-checksum Turn off checksum validation for uploads.
--skip-container-put Assume all necessary containers already exist; don't
automatically try to create them.
--object-name <object-name>
Upload file and name object to <object-name> or upload
dir and use <object-name> as object prefix instead of
folder name.查看存储状态
bash
[root@client ~]# swift stat
Account: v1
Containers: 0
Objects: 0
Bytes: 0
Objects in policy "default-placement-bytes": 0
Bytes in policy "default-placement-bytes": 0
Containers in policy "default-placement": 0
Objects in policy "default-placement": 0
Bytes in policy "default-placement": 0
X-Timestamp: 1756120916.52301
X-Account-Bytes-Used-Actual: 0
X-Trans-Id: tx000000bdae1b6eec631b5-0068ac4754-ad01-storage
X-Openstack-Request-Id: tx000000bdae1b6eec631b5-0068ac4754-ad01-storage
Accept-Ranges: bytes
Content-Type: text/plain; charset=utf-8
Connection: Keep-Alive查看认证信息
bash
[root@client ~]# swift auth
export OS_STORAGE_URL=http://ceph1.dcr.cloud:8080/swift/v1
export OS_AUTH_TOKEN=AUTH_rgwtk0f00000073776966743a73776966745f7267771c03132ca7ff9f23e498ad685aaedc2332323e8a316edd865b5d15be670fb35bf3a00a8c创建容器
bash
[root@client ~]# swift post --help
Usage: swift post [--read-acl <acl>] [--write-acl <acl>] [--sync-to <sync-to>]
[--sync-key <sync-key>] [--meta <name:value>]
[--header <header>]
[<container> [<object>]]
Updates meta information for the account, container, or object.
If the container is not found, it will be created automatically.
Positional arguments:
[<container>] Name of container to post to.
[<object>] Name of object to post.
Optional arguments:
-r, --read-acl <acl> Read ACL for containers. Quick summary of ACL syntax:
.r:*, .r:-.example.com, .r:www.example.com,
account1 (v1.0 identity API only),
account1:*, account2:user2 (v2.0+ identity API).
-w, --write-acl <acl> Write ACL for containers. Quick summary of ACL syntax:
account1 (v1.0 identity API only),
account1:*, account2:user2 (v2.0+ identity API).
-t, --sync-to <sync-to>
Sync To for containers, for multi-cluster replication.
-k, --sync-key <sync-key>
Sync Key for containers, for multi-cluster replication.
-m, --meta <name:value>
Sets a meta data item. This option may be repeated.
Example: -m Color:Blue -m Size:Large
-H, --header <header:value>
Adds a customized request header.
This option may be repeated. Example
-H "content-type:text/plain" -H "Content-Length: 4000"
[root@client ~]# swift post webapp查看容器清单
bash
[root@client ~]# swift list --help
Usage: swift list [--long] [--lh] [--totals] [--prefix <prefix>]
[--delimiter <delimiter>] [--header <header:value>]
[--versions] [<container>]
Lists the containers for the account or the objects for a container.
Positional arguments:
[<container>] Name of container to list object in.
[root@client ~]# swift list
webapp上传对象到容器
bash
[root@client ~]# swift upload --help
Usage: swift upload [--changed] [--skip-identical] [--segment-size <size>]
[--segment-container <container>] [--leave-segments]
[--object-threads <thread>] [--segment-threads <threads>]
[--meta <name:value>] [--header <header>] [--use-slo]
[--use-dlo] [--ignore-checksum] [--skip-container-put]
[--object-name <object-name>]
<container> <file_or_directory> [<file_or_directory>] [...]
Uploads specified files and directories to the given container.
Positional arguments:
<container> Name of container to upload to.
<file_or_directory> Name of file or directory to upload. Specify multiple
times for multiple uploads. If "-" is specified, reads
content from standard input (--object-name is required
in this case).
[root@client ~]# echo Hello World > Welcome.html
[root@client ~]# echo Test> test.html
[root@client ~]# swift upload webapp Welcome.html
Welcome.html用户可使用 --object-name 选项来定义对象名称。
如果使用绝对路径来定义文件位置,对象名称将包含文件路径,包括斜杠字符 /。例如,以下命令将会上传 /etc/hosts 文件到 services 存储桶。
bash
[root@client ~]# swift upload webapp /etc/hostname
etc/hostname查看容器中对象清单
bash
[root@client ~]# swift list webapp
Welcome.html
etc/hostname下载容器中对象
bash
[root@client ~]# swift download --help
Usage: swift download [--all] [--marker <marker>] [--prefix <prefix>]
[--output <out_file>] [--output-dir <out_directory>]
[--object-threads <threads>] [--ignore-checksum]
[--container-threads <threads>] [--no-download]
[--skip-identical] [--remove-prefix]
[--version-id <version_id>]
[--header <header:value>] [--no-shuffle]
[<container> [<object>] [...]]
# 下载容器中所有对象
[root@client ~]# swift download webapp
etc/hostname [auth 0.005s, headers 0.009s, total 0.010s, 0.004 MB/s]
Welcome.html [auth 0.005s, headers 0.010s, total 0.010s, 0.002 MB/s]
# 下载容器中单个对象
[root@client ~]# swift download webapp Welcome.html
Welcome.html [auth 0.004s, headers 0.008s, total 0.009s, 0.003 MB/s]删除容器中对象
bash
[root@client ~]# swift delete --help
Usage: swift delete [--all] [--leave-segments]
[--object-threads <threads>]
[--container-threads <threads>]
[--header <header:value>]
[--prefix <prefix>]
[--versions]
[<container> [<object>] [--version-id <version_id>] [...]]
Delete a container or objects within a container.
Positional arguments:
[<container>] Name of container to delete from.
[<object>] Name of object to delete. Specify multiple times
for multiple objects.
[root@client ~]# swift delete webapp etc/hostname
etc/hostname删除容器
删除容器,将删除容器中所有对象和容器本身。
bash
[root@client ~]# swift delete webapp
Welcome.html
webapp桶配额限制
环境准备
bash
[root@client ~]# swift post dbapp
[root@client ~]# swift upload --object-name hosts-1 dbapp /etc/hosts针对用户进行配额限制
bash
# 对用户 swift 的配额限制
[root@ceph1 ~]# radosgw-admin quota enable --quota-scope=user --uid=swift
# 将用户 swift 可上传的对象数量设置为不超过 3
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=user --uid=swift --max-objects=3
# 查看用户配额信息
[root@ceph1 ~]# radosgw-admin user info --uid=swift
......
"user_quota": {
"enabled": true,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": 3
},
......
# 上传对象测试:当上传第4个对象时,客户端会收到报错。
[root@client ~]# swift upload --object-name hosts-2 dbapp /etc/hosts
[root@client ~]# swift upload --object-name hosts-3 dbapp /etc/hosts
[root@client ~]# swift upload --object-name hosts-4 dbapp /etc/hosts
Object PUT failed: http://ceph1.dcr.cloud:8080/swift/v1/dbapp/hosts-4 413 Request Entity Too Large b'QuotaExceeded' (txn: tx00000f89584465dec20ff-006603ab85-acdb-webapp)
Consider using the --segment-size option to chunk the object
# 将" --max-objects"设置为-1,取消对象数量配额的限制
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=user --uid=swift --max-objects=-1
# 在客户端重新上传对象,则会顺利上传完成
[root@client ~]# swift upload --object-name hosts-4 dbapp /etc/hosts思考:除了设置对象数量外,是否还有其他的配额限制方式?
回答:有,除了对象数量,还可以最大上传的容量进行限制。
针对桶进行配额限制
bash
# 启用对桶 dbapp 的配额限制
[root@ceph1 ~]# radosgw-admin quota enable --quota-scope=bucket --bucket=dbapp
# 将桶 dbapp 的最大容量设置为 10M:
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=bucket --bucket=dbapp --max-size=10M
# 查看配额信息
[root@ceph1 ~]# radosgw-admin bucket stats
......
"bucket_quota": {
"enabled": true,
"check_on_raw": true,
"max_size": 10485760,
"max_size_kb": 10240,
"max_objects": -1
}
......
# 在客户端创建一个 6M 的文件 file,进行测试,具体命令为:
[root@client ~]# dd if=/dev/zero of=file bs=1M count=6
# 将文件 file 上传到容器(桶) dbapp 中,当上传第二个时,系统会返回报错
[root@client ~]# swift upload --object-name file-1 dbapp file
file-1
[root@client ~]# swift upload --object-name file-2 dbapp file
Object PUT failed: http://ceph1.dcr.cloud:8080/swift/v1/dbapp/file-2 413 Request Entity Too Large b'QuotaExceeded' (txn: tx000008b826fc312e77202-006603acbd-acdb-webapp)
Consider using the --segment-size option to chunk the object
# 将"--max-size"设置为-1,取消对象容量配额的限制
[root@ceph1 ~]# radosgw-admin quota set --quota-scope=bucket --bucket=dbapp --max-size=-1
# 在客户端重新上传对象,则会顺利上传完成
[root@client ~]# swift upload --object-name file-2 dbapp file管理多站点对象存储网关
Ceph RADOS 网关支持多站点部署,实现在多个Ceph 存储集群之间自动复制对象数据。常见的用例是在地理上分隔的集群之间进行主动/主动复制,以便于灾难恢复。
多站点架构选择
- multi zone,域(realm)中具有一个区域组(zonegroup)和多个区域(zone)。每个区域由一个或多个 RADOS 网关以及关联一个独立的Ceph 存储集群。一个区域中存储的数据复制到该区域组中所有区域。如果有一个 zone 遭遇到灾难性故障,这可用于进行灾难恢复。
- multi zonegroup,域(realm)中有多个区域组,每个区域组具有一个或多个区域。用户可使用多区域组来管理一个地区中一个或多个区域内 RADOS 网关的地理位置。
- multi realm,配置使得同一硬件可用于支持不同区域组和区域之间通用的多个对象命名空间。
最小的 RADOS 网关多站点部署:
- 需要两个Ceph 存储集群,每个集群具有一个 RADOS 网关。
- 它们存在于同一域中,分配到相同的主区域组。
- 一个 RADOS 网关与该区域组中的主区域关联。另一个与该区域组中的独立次要区域关联。
多站点网关同步流程
RADOS 网关在所有主要区域组和次要区域组集合之间同步元数据和数据操作。
- **元数据操作与存储桶相关:**创建、删除、启用和禁用版本控制,以及管理用户。元主 (meta master) 位于主区域组中的主区域,负责管理元数据更新。
- 数据操作与对象相关。
多站点之间数据同步流程:
- 多站点初始配置后,RADOS 网关会在主区域和次要区域之间执行一次初始的完整同步。随后的更新是增量更新。
- **当 RADOS 网关将数据写入区域组中任何区域时,它会在其他区域组的所有区域之间同步这一数据。**当 RADOS 网关同步数据时,所有活跃的网关会更新数据日志并通知其他网关。
- 当 RADOS 网关因为存储桶或用户操作而同步元数据时,主网关会更新元数据日志并通知其他RADOS 网关。
多站点架构配置流程
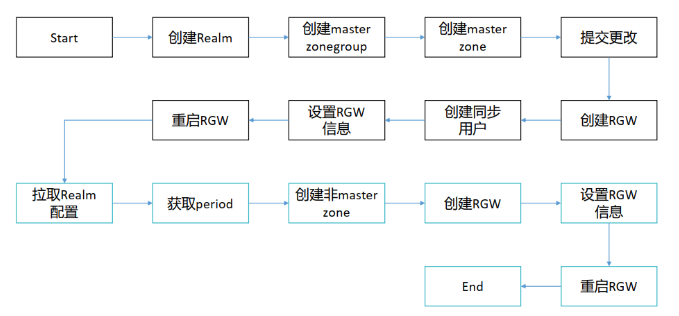
部署多站点 RGW-实践
多站点架构如下图所示:
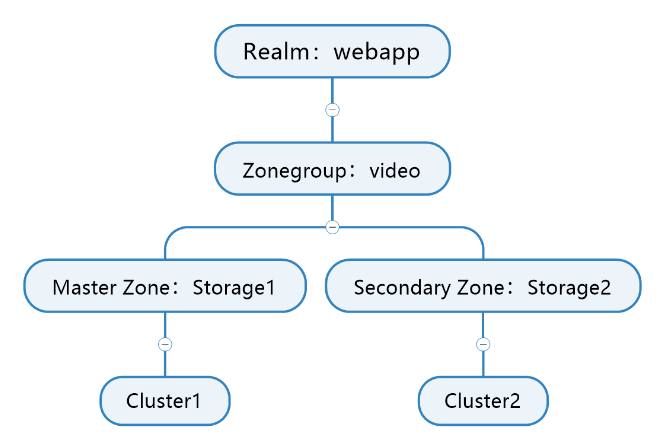
环境准备
部署好主集群和备集群。
配置主集群
bash
# 创建存储域
[root@ceph1 ~]# radosgw-admin realm create --rgw-realm=webapp --default
[root@ceph1 ~]# radosgw-admin zonegroup create --rgw-realm=webapp --rgw-zonegroup=video --master --default
[root@ceph1 ~]# radosgw-admin zone create --rgw-realm=webapp --rgw-zonegroup=video --rgw-zone=storage1 --master --default
[root@ceph1 ~]# radosgw-admin period update --rgw-realm=webapp --commit
# 创建 rgw 服务,这里创建3个(创建一个也够了)
[root@ceph1 ~]# ceph orch apply rgw webapp --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud" --realm=webapp --zone=storage1 --port=8080
# 创建用于同步数据的系统用户:
[root@ceph1 ~]# radosgw-admin user create --uid=system-user --display-name=system-user --access-key=dcr@123 --secret=Huawei12#$ --system
# 将创建好的系统用户绑定给 master zone
[root@ceph1 ~]# radosgw-admin zone modify --rgw-realm=webapp --rgw-zonegroup=video --rgw-zone=storage1 --endpoints 'http://ceph1.dcr.cloud:8080,http://ceph2.dcr.cloud:8080,http://ceph3.dcr.cloud:8080' --access-key=dcr@123 --secret=Huawei12#$ --master --default
# 配置 RGW
[root@ceph1 ~]# ceph auth ls 2>/dev/null |grep 'rgw.*ceph'
client.rgw.webapp.ceph1.qqepfc
client.rgw.webapp.ceph2.iculct
client.rgw.webapp.ceph3.xbrkun
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph1.qqepfc rgw_realm webapp
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph1.qqepfc rgw_zonegroup video
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph1.qqepfc rgw_zone storage1
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph2.iculct rgw_realm webapp
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph2.iculct rgw_zonegroup video
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph2.iculct rgw_zone storage1
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph3.xbrkun rgw_realm webapp
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph3.xbrkun rgw_zonegroup video
[root@ceph1 ~]# ceph config set client.rgw.webapp.ceph3.xbrkun rgw_zone storage1
# 提交配置
[root@ceph1 ~]# radosgw-admin period update --commit
# 重启 RGW 服务
[root@ceph1 ~]# ceph orch restart rgw.webapp配置备集群
bash
# 拉取主分区 realm 的配置信息:
[root@ceph4 ~]# radosgw-admin realm pull --url=http://ceph1.dcr.cloud:8080 --access-key=dcr@123 --secret=Huawei12#$
# 查看是否获取到 realm 和 zonegroup 的信息:
[root@ceph4 ~]# radosgw-admin realm list
[root@ceph4 ~]# radosgw-admin zonegroup list
# 获取 period 信息
[root@ceph4 ~]# radosgw-admin period pull --url=http://ceph1.dcr.cloud:8080 --access-key=dcr@123 --secret=Huawei12#$
# 检查是否获取
[root@ceph4 ~]# radosgw-admin period list
{
"periods": [
"df0d2416-7ee9-465c-a1e5-cebd19b7b468"
]
}
# 创建非 master zone
[root@ceph4 ~]# radosgw-admin zone create --rgw-zonegroup=video --rgw-zone=storage2 --endpoints "http://ceph4.dcr.cloud:8080, http://ceph5.dcr.cloud:8080, http://ceph6.dcr.cloud:8080" --access-key=dcr@123 --secret=Huawei12#$
# 创建 RGW
[root@ceph4 ~]# ceph orch apply rgw webapp --placement="3 ceph4.dcr.cloud ceph5.dcr.cloud ceph6.dcr.cloud" --realm=webapp --zone=storage2 --port=8080
# 设置 RGW 信息
[root@ceph4 ~]# ceph auth ls 2>/dev/null|grep 'rgw.*ceph'
client.rgw.webapp.ceph4.quzfrg
client.rgw.webapp.ceph5.catzsj
client.rgw.webapp.ceph6.aszklt
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph4.quzfrg rgw_realm webapp
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph4.quzfrg rgw_zonegroup video
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph4.quzfrg rgw_zone storage2
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph5.catzsj rgw_realm webapp
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph5.catzsj rgw_zonegroup video
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph5.catzsj rgw_zone storage2
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph6.aszklt rgw_realm webapp
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph6.aszklt rgw_zonegroup video
[root@ceph4 ~]# ceph config set client.rgw.webapp.ceph6.aszklt rgw_zone storage2
# 更新 realm
[root@ceph4 ~]# radosgw-admin period update --rgw-realm=webapp --commit
# 重启 RGW 服务
[root@ceph4 ~]# ceph orch restart rgw.webapp测试
bash
# 查看同步状态
[root@ceph4 ~]# radosgw-admin sync status
realm f1ea35c6-c4b5-46b4-9e4b-62e2c6301217 (webapp)
zonegroup c4f0f536-6651-43f0-b1f3-a1fbaf55775d (video)
zone 9d1339a8-6570-4ad6-88de-172cf3899332 (storage2)
metadata sync syncing
full sync: 0/64 shards
incremental sync: 64/64 shards
metadata is caught up with master
data sync source: 9366405a-6d9b-4897-97d0-9e139304fe64 (storage1)
syncing
full sync: 0/128 shards
incremental sync: 128/128 shards
data is caught up with source
# 对象同步测试---有问题
[root@client ~]# source swift.rc
[root@client ~]# swift post dbapp
[root@client ~]# swift upload --object-name hosts-from-primary dbapp /etc/hosts
# 查看备集群对象(需要稍微等待几秒)
[root@client ~]# source swift-slave.rc
[root@client ~]# swift list dbapp
hosts-from-primary管理区域故障转移
在多站点部署中,主区域不可用时,次要区域可以继续为读取和写入请求服务。
不过,因为主区域不可用,所以用户无法创建新的存储桶和用户。如果主区域没有立即恢复,则需要对其中一个次要区域升级,以替代主区域。
具体过程如下:
-
将主区域指定为次要区域。
bash[root@ceph4 ~]# radosgw-admin zone modify --master --rgw-zone=storage2 -
更新主区域组端点。
bash[root@ceph4 ~]# radosgw-admin zonegroup modify --rgw-zonegroup=video \ --endpoints=http://ceph4.dcr.cloud:8080 -
提交更改。
bash[root@ceph4 ~]# radosgw-admin period update --commit [root@ceph4 ~]# radosgw-admin sync status realm f1ea35c6-c4b5-46b4-9e4b-62e2c6301217 (webapp) zonegroup c4f0f536-6651-43f0-b1f3-a1fbaf55775d (video) zone 9d1339a8-6570-4ad6-88de-172cf3899332 (storage2) metadata sync no sync (zone is master) data sync source: 9366405a-6d9b-4897-97d0-9e139304fe64 (storage1) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with source
radosgw-admin 命令
realm 子命令
bash
realm create create a new realm
realm rm remove a realm
realm get show realm info
realm get-default get default realm name
realm list list realms
realm list-periods list all realm periods
realm rename rename a realm
realm set set realm info (requires infile)
realm default set realm as default
realm pull pull a realm and its current periodzonegroup 子命令
zonegroup add add a zone to a zonegroup
zonegroup create create a new zone group info
zonegroup default set default zone group
zonegroup delete delete a zone group info
zonegroup get show zone group info
zonegroup modify modify an existing zonegroup
zonegroup set set zone group info (requires infile)
zonegroup rm remove a zone from a zonegroup
zonegroup rename rename a zone group
zonegroup list list all zone groups set on this cluster
zonegroup placement list list zonegroup's placement targets
zonegroup placement get get a placement target of a specific zonegroup
zonegroup placement add add a placement target id to a zonegroup
zonegroup placement modify modify a placement target of a specific zonegroup
zonegroup placement rm remove a placement target from a zonegroup
zonegroup placement default set a zonegroup's default placement targetzone 子命令
zone create create a new zone
zone rm remove a zone
zone get show zone cluster params
zone modify modify an existing zone
zone set set zone cluster params (requires infile)
zone list list all zones set on this cluster
zone rename rename a zone
zone placement list list zone's placement targets
zone placement get get a zone placement target
zone placement add add a zone placement target
zone placement modify modify a zone placement target
zone placement rm remove a zone placement targetperiod 子命令
period rm remove a period
period get get period info
period get-current get current period info
period pull pull a period
period push push a period
period list list all periods
period update update the staging period
period commit commit the staging period常用选项
bash
--uid=<id> user id
--new-uid=<id> new user id
--subuser=<name> subuser name
--email=<email> user's email address
--display-name=<name> user's display name
--system set the system flag on the user
--access-key=<key> S3 access key
--secret/--secret-key=<key> specify secret key
--gen-access-key generate random access key (for S3)
--gen-secret generate random secret key
--key-type=<type> key type, options are: swift, s3
--bucket=<bucket> Specify the bucket name.
--bucket-id=<bucket-id> bucket id
--bucket-new-name=<bucket>
for bucket link: optional new name
--pool=<pool> Specify the pool name.
--object=<object> object name
--period=<id> period id
--url=<url> url for pushing/pulling period/realm
--epoch=<number> period epoch
--commit commit the period during 'period update'
--default set entity (realm, zonegroup, zone) as default
--master set as master
--master-zone=<id> master zone id
--rgw-realm=<name> realm name
--realm-id=<id> realm id
--realm-new-name=<name> realm new name
--rgw-zonegroup=<name> zonegroup name
--zonegroup-id=<id> zonegroup id
--zonegroup-new-name=<name>
zonegroup new name
--endpoints=<list> zone endpoints
--rgw-zone=<name> name of zone in which radosgw is running
--zone-id=<id> zone id
--zone-new-name=<name> zone new name
--source-zone specify the source zone (for data sync)第 8 章 Ceph 分布式存储 文件系统存储管理
介绍 CephFS
介绍 CephFS
-
Ceph 文件系统 (CephFS) ,构建在 Ceph 存储之上,是一种兼容 POSIX 的文件系统。
-
与 RBD 和 RGW 类似,CephFS 也会作为 librados 的原生接口来实施。
-
Ceph 支持在一个集群中运行多个活动 MDS,以提高元数据性能。为保持高可用性,还可配置备用 MDS,以便在任何活动 MDS 出现故障时,接管其任务。
-
Ceph 支持在一个集群中部署多个活动的 CephFS 文件系统。部署多个 CephFS 文件系统需要运行多个 MDS 守护进程。
不同存储方式对比
- **基于文件的存储:**可以像传统文件系统一样整理用户的数据,并带有目录树层次结构。数据会保存在文件中,文件会有一个名称并包含相关元数据,如修改时间戳、所有者和访问权限。
- 基于块的存储:提供像磁盘一样运作的存储卷,整理到大小相等的区块中。通常而言,基于块的存储卷要么通过文件系统进行格式化,要么是像数据库一样可直接读写的应用。
- **基于对象的存储:**支持将任意数据和元数据作为一个标有唯一标识符的单元存储在扁平存储池中。用户会使用 API 来存储和检索数据,而不会作为块或在文件系统层次结构中访问数据。
元数据服务器
元数据服务器 (MDS) 负责:
- 管理目录层次结构和文件元数据(如所有者、时间戳和权限模式等),提供 CephFS 客户端访问 RADOS 对象所需的信息。
- 访问客户端缓存,并维护客户端缓存一致性。
MDS 以两种运行模式:
- 活动 MDS, 负责管理 CephFS 文件系统上的元数据。
- 备用 MDS, 充当备份,并会在活动 MDS 无响应时切换到活动模式。
CephFS 文件系统至少需要一个活跃的 MDS 服务,最好再部署一个备用 MDS 以确保可用性。
MDS 配置选项:
-
MDS 等级,设置集群中活动 MDS 守护进程的最大数量,由 max_mds 定义。MDS 守护进程在启动时没有等级,MON 守护进程负责为它们分配1个等级,也就是集群中只有一个活动 MDS。
-
卷、子卷和子卷组:
-
CephFS 卷,对应一个 CephFS 文件系统。
-
**CephFS 子卷,对应 CephFS 文件系统子目录。**在创建子卷时,用户可指定更细致的权限管理,如子卷的 UID、GID、文件模式、大小和子卷组。
-
CephFS 子卷组,对应一组子卷。
-
-
**文件系统关联性,将用户的 CephFS 文件系统配置为首选某一个 MDS。**例如,用户可配置为首选在速度更快的服务器上运行的 MDS。文件系统关联性通过 mds_join_fs 选项进行配置。
-
MDS 缓存大小限制 ,通过 mds_cache_memory_limit 选项限制最大内存,mds_cache_size 选项定义最大索引节点数,以限制 MDS 缓存的大小。
-
**配额,配置用户的 CephFS 文件系统,以限制使用配额存储的字节数或文件数。**FUSE 和Kernel 客户端都支持在挂载 CephFS 文件系统时检查配额。这些客户端还负责在用户达到配额限值时,停止向 CephFS 文件系统写入数据。使用 setfattr 命令的 ceph.quota.max_bytes 和ceph.quota.max_files 选项可设置限值。
客户端访问 CephFS 过程
- CephFS 客户端首先会联系 MON 进行身份验证并检索集群映射。
- 完成上一步后,客户端从集群映射中获取到活动 MDS信息。
- 客户端向活动 MDS 索取文件元数据。
- 然后客户端直接与 OSD 通信,使用元数据来访问文件或目录。
部署 CephFS
部署 CephFS 方法:
- 手动部署,步骤多,可以控制每个步骤。
- 卷部署,步骤少,简单方便,无法控制每个步骤。
手动部署 CephFS
部署 CephFS 流程:
- 创建所需池
- 创建 CephFS 文件系统
- 部署 MDS 守护进程
创建 CephFS
要创建 CephFS 文件系统,首先至少要创建两个池,一个用于存储 CephFS 数据,另一个用于存储 CephFS 元数据。这两个池的默认名称分别为 cephfs_data 和 cephfs_meta。
bash
[root@ceph1 ~]# ceph osd pool create cephfs.cephfs1.data.1
[root@ceph1 ~]# ceph osd pool create cephfs.cephfs1.meta元数据池用于存储文件的位置信息,所以为此池设置更高的复本级别,以避免出现数据错误,导致数据无法访问。CephFS 默认使用复制数据池,也支持使用纠删代码数据池。
bash
[root@ceph1 ~]# ceph osd pool set cephfs.cephfs1.meta size 3使用 ceph fs new 命令来创建文件系统:
bash
[root@ceph1 ~]# ceph fs new cephfs1 cephfs.cephfs1.meta cephfs.cephfs1.data.1要将现有池添加为 CephFS 文件系统中的数据池,请使用 ceph fs add_data_pool。
bash
[root@ceph1 ~]# ceph osd pool create cephfs.cephfs1.data.2
[root@ceph1 ~]# ceph fs add_data_pool cephfs1 cephfs.cephfs1.data.2部署 MDS 服务
bash
[root@ceph1 ~]# ceph orch apply mds cephfs1 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"验证 MDS 服务部署
bash
# 查看文件系统清单
[root@ceph1 ~]# ceph fs ls
name: cephfs1, metadata pool: cephfs.cephfs1.meta, data pools: [cephfs.cephfs1.data.1 cephfs.cephfs1.data.2 ]
# 查看文件系统状态
[root@ceph1 ~]# ceph fs status
cephfs1 - 0 clients
=======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active cephfs1.ceph1.hazpoq Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
cephfs.cephfs1.meta metadata 96.0k 56.1G
cephfs.cephfs1.data.1 data 0 56.1G
cephfs.cephfs1.data.2 data 0 56.1G
STANDBY MDS
cephfs1.ceph3.kjpzae
cephfs1.ceph2.fdudvc
MDS version: ceph version 16.2.15 (618f440892089921c3e944a991122ddc44e60516) pacific (stable)
# 查看池空间使用状态
[root@ceph1 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
TOTAL 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 56 GiB
cephfs.cephfs1.data.1 3 32 0 B 0 0 B 0 56 GiB
cephfs.cephfs1.meta 4 32 2.3 KiB 22 96 KiB 0 56 GiB
cephfs.cephfs1.data.2 5 32 0 B 0 0 B 0 56 GiB
# 查看mds服务状态
[root@ceph1 ~]# ceph mds stat
cephfs1:1 {0=cephfs1.ceph1.hazpoq=up:active} 2 up:standby
# 查看mds服务守护进程
[root@ceph1 ~]# ceph orch ls mds
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mds.cephfs1 3/3 6m ago 6m ceph1.dcr.cloud;ceph2.dcr.cloud;ceph3.dcr.cloud;count:3删除 CephFS
删除流程如下:
- 删除服务
- 删除文件系统
- 删除池
删除过程如下:
bash
# 删除服务
[root@ceph1 ~]# ceph orch rm mds.cephfs1
Removed service mds.cephfs1
# 如果需要删除 CephFS,请先备份所有数据,
# 因为删除 CephFS 文件系统会破坏该文件系统上存储的所有数据。
# 要删除 CephFS,首先要将其标记为 down
[root@ceph1 ~]# ceph fs set cephfs1 down true
cephfs1 marked down.
# 然后删除 CephFS
[root@ceph1 ~]# ceph fs rm cephfs1 --yes-i-really-mean-it
# 删除池
[root@ceph1 ~]# ceph config set mon mon_allow_pool_delete true
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.meta cephfs.cephfs1.meta --yes-i-really-really-mean-it
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.data.1 cephfs.cephfs1.data.1 --yes-i-really-really-mean-it
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.data.2 cephfs.cephfs1.data.2 --yes-i-really-really-mean-it卷部署 CephFS
创建 CephFS
bash
# 部署三个实例
[root@ceph1 ~]# ceph fs volume create cephfs2 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"
# 查看文件系统清单
[root@ceph1 ~]# ceph fs ls
name: cephfs2, metadata pool: cephfs.cephfs2.meta, data pools: [cephfs.cephfs2.data ]
# 查看mds服务状态
[root@ceph1 ~]# ceph mds stat
cephfs2:1 {0=cephfs2.ceph3.irxxar=up:active} 2 up:standby
# 查看mds服务守护进程
[root@ceph1 ~]# ceph orch ls mds
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mds.cephfs2 3/3 58s ago 62s ceph1.dcr.cloud;ceph2.dcr.cloud;ceph3.dcr.cloud;count:3删除 CephFS
bash
[root@ceph1 ~]# ceph fs volume ls
[
{
"name": "cephfs2"
}
]
[root@ceph1 ~]# ceph fs volume rm cephfs2 --yes-i-really-mean-it
metadata pool: cephfs.cephfs2.meta data pool: ['cephfs.cephfs2.data'] removed
[root@ceph1 ~]# ceph fs ls
No filesystems enabled挂载 CephFS 文件系统
环境准备
创建 cephfs1 和 cephfs2。
bash
[root@ceph1 ~]# ceph fs volume create cephfs1 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"
[root@ceph1 ~]# ceph fs volume create cephfs2 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"CephFS 挂载方式
用户可使用以下方式挂载 CephFS 文件系统:
- Kernel 挂载,要求 Linux 内核版本达到 4 或以上,从 RHEL 8 开始可用。对于之前的内核版本,请改用FUSE 客户端。
- FUSE 挂载。
这两个挂载方式各有优势和劣势:
- Kernel 挂载,不支持配额,但速度可能较快。
- FUSE 挂载,支持配额和 ACL。 ACL 功能需要在挂载时明确指定该功能以启用。
CephFS 挂载用户
通过 ceph fs authorize 命令,可为 CephFS 文件系统中的不同用户和文件夹提供精细的访问控制。
CephFS 文件系统支持不同访问选项:
- **r:对指定文件夹的读取权限。**如果未指定其他限制,则会向子文件夹授予读取权限。
- **w:对指定文件夹的写入权限。**如果未指定其他限制,则会向子文件夹授予写入权限。
- p:除了 r 和 w 功能外,客户端还需要 p 选项才能使用布局或配额。
- s:除了 r 和 w 功能外,客户端还需要 s 选项才能创建快照。
示例1:允许用户对 / 文件夹具备读取、写入、配额和快照权限,并保存用户凭据。
bash
[root@ceph1 ~]# ceph fs authorize cephfs1 client.cephfs1-all-user / rwps > /etc/ceph/ceph.client.cephfs1-all-user.keyring示例2:允许用户读取 root 文件夹,并提供对 /dir2 文件夹的读取、写入,并保存用户凭据。
bash
[root@ceph1 ~]# ceph fs authorize cephfs1 client.cephfs1-restrict-user / r /dir2 rw > /etc/ceph/ceph.client.cephfs1-restrict-user.keyringCephFS 客户端挂载准备
要挂载基于 CephFS 的文件系统,请验证客户端主机是否满足以下条件:
-
安装 ceph-common 软件包。对于 FUSE 客户端,还要安装 ceph-fuse 软件包。
bash[root@client ~]# dnf install -y ceph-common -
复制 Ceph 配置文件到客户端。
bash[root@ceph1 ~]# scp /etc/ceph/ceph.conf root@client:/etc/ceph/ceph.conf -
将用户keyring复制到客户端主机上的 /etc/ceph 文件夹。
bash[root@ceph1 ~]# scp /etc/ceph/ceph.client.{cephfs1-all-user,cephfs1-restrict-user}.keyring root@client:/etc/ceph/
为了方便管理集群,我们将admin凭据复制到client。
bash
[root@ceph1 ~]# scp /etc/ceph/ceph.client.admin.keyring root@client:/etc/ceph/使用 Kernel 挂载 CephFS
挂载 CephFS
使用 mount.ceph 命令挂载文件系统:
bash
# mount.ceph [src] [mount-point] [-n] [-v] [-o ceph-options]
# 或者
# mount -t ceph [src] [mount-point] [-n] [-v] [-o ceph-options]用户可以指定逗号分隔的多个 MON 来挂载设备。标准端口 (6789) 为默认值,用户也可在各个MON 名称的后面添加冒号和非标准端口号。建议指定多个 MON,以防文件系统挂载时有些 MON 处于脱机状态。
bash
[root@client ~]# mount.ceph
usage: mount.ceph [src] [mount-point] [-n] [-v] [-o ceph-options]
options:
-h: Print this help
-n: Do not update /etc/mtab
-v: Verbose
ceph-options: refer to mount.ceph(8)使用 CephFS Kernel 客户端时,可用选项有:
- fs=fs-name,指定要挂载的 CephFS 文件系统名称。未提供值时,它会使用默认文件系统。
- name=name,指定Cephx 客户端 ID。默认为 guest。
- secret=secret_value,指定客户端的机密密钥的值。
- secretfile=secret_key_file,指定包含此客户端机密密钥的文件的路径。
- rsize=bytes,指定最大读取大小,以字节为单位。
- wsize=bytes,指定最大写入大小,以字节为单位。默认为不写入。
示例1:使用不受限账户挂载 cephfs 文件系统。
bash
[root@client ~]# mkdir /mnt/cephfs1
[root@client ~]# mount.ceph ceph1.dcr.cloud:/ /mnt/cephfs1 -o name=cephfs1-all-user,fs=cephfs1
[root@client ~]# df -h /mnt/cephfs1
Filesystem Size Used Avail Use% Mounted on
192.168.108.11:/ 57G 0 57G 0% /mnt/cephfs1
[root@client ~]# mkdir /mnt/cephfs1/{dir1,dir2}
[root@client ~]# echo Hello World > /mnt/cephfs1/dir1/welcome.txt
[root@client ~]# dd if=/dev/zero of=/mnt/cephfs1/dir1/file-100M bs=1M count=100
[root@client ~]# tree /mnt/cephfs1
/mnt/cephfs1
├── dir1
│ ├── file-100M
│ └── welcome.txt
└── dir2
2 directories, 2 files
# 3副本池,创建100M文件,文件系统空间减少100M
[root@client ~]# df -h /mnt/cephfs1
Filesystem Size Used Avail Use% Mounted on
192.168.108.11:/ 57G 100M 56G 1% /mnt/cephfs1
# 3副本池,创建100M文件,cephfs.cephfs_data 池系统空间使用300M
[root@client ~]# ceph fs status
cephfs1 - 1 clients
=======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active cephfs1.ceph1.hpwqgm Reqs: 0 /s 14 17 14 5
POOL TYPE USED AVAIL
cephfs.cephfs1.meta metadata 192k 55.9G
cephfs.cephfs1.data data 300M 55.9G
cephfs2 - 0 clients
=======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active cephfs2.ceph3.nwbhbl Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
cephfs.cephfs2.meta metadata 96.0k 55.9G
cephfs.cephfs2.data data 0 55.9G
STANDBY MDS
cephfs1.ceph2.notedt
cephfs1.ceph3.qxjqfe
cephfs2.ceph2.hjrvmu
cephfs2.ceph1.yursdd
MDS version: ceph version 16.2.15 (618f440892089921c3e944a991122ddc44e60516) pacific (stable)
# 卸载文件系统
[root@client ~]# umount /mnt/cephfs1示例2:使用受限账户挂载 cephfs 文件系统。
bash
# 挂载
[root@client ~]# mount.ceph ceph1.dcr.cloud:/ /mnt/cephfs1 -o name=cephfs1-restrict-user,fs=cephfs1
# 验证权限
[root@client ~]# touch /mnt/cephfs1/dir1/cephfs1-restrict-user-file1
touch: cannot touch '/mnt/cephfs1/dir1/cephfs1-restrict-user-file1': Permission denied
[root@client ~]# touch /mnt/cephfs1/dir2/cephfs1-restrict-user-file1
[root@client ~]# tree /mnt/cephfs1/
/mnt/cephfs1/
├── dir1
│ ├── file-100M
│ └── welcome.txt
└── dir2
└── cephfs1-restrict-user-file1
2 directories, 3 files
# 卸载文件系统
[root@client ~]# umount /mnt/cephfs1挂载特定子目录
通过 CephFS Kernel 客户端,用户可从 CephFS 文件系统挂载特定子目录。
本例从 CephFS 文件系统的 root 中挂载了名为 /dir2 的目录:
bash
[root@client ~]# mount -t ceph ceph1.dcr.cloud:/dir2 /mnt/cephfs1 -o name=cephfs1-restrict-user,fs=cephfs1
[root@client ~]# touch /mnt/cephfs1/cephfs1-restrict-user-file2
态
[root@ceph1 ~]# ceph fs status
cephfs1 - 0 clients
=======
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active cephfs1.ceph1.hazpoq Reqs: 0 /s 10 13 12 0
POOL TYPE USED AVAIL
cephfs.cephfs1.meta metadata 96.0k 56.1G
cephfs.cephfs1.data.1 data 0 56.1G
cephfs.cephfs1.data.2 data 0 56.1G
STANDBY MDS
cephfs1.ceph3.kjpzae
cephfs1.ceph2.fdudvc
MDS version: ceph version 16.2.15 (618f440892089921c3e944a991122ddc44e60516) pacific (stable)
# 查看池空间使用状态
[root@ceph1 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
TOTAL 180 GiB 177 GiB 2.6 GiB 2.6 GiB 1.42
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 56 GiB
cephfs.cephfs1.data.1 3 32 0 B 0 0 B 0 56 GiB
cephfs.cephfs1.meta 4 32 2.3 KiB 22 96 KiB 0 56 GiB
cephfs.cephfs1.data.2 5 32 0 B 0 0 B 0 56 GiB
# 查看mds服务状态
[root@ceph1 ~]# ceph mds stat
cephfs1:1 {0=cephfs1.ceph1.hazpoq=up:active} 2 up:standby
# 查看mds服务守护进程
[root@ceph1 ~]# ceph orch ls mds
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mds.cephfs1 3/3 6m ago 6m ceph1.dcr.cloud;ceph2.dcr.cloud;ceph3.dcr.cloud;count:3删除 CephFS
删除流程如下:
- 删除服务
- 删除文件系统
- 删除池
删除过程如下:
bash
# 删除服务
[root@ceph1 ~]# ceph orch rm mds.cephfs1
Removed service mds.cephfs1
# 如果需要删除 CephFS,请先备份所有数据,
# 因为删除 CephFS 文件系统会破坏该文件系统上存储的所有数据。
# 要删除 CephFS,首先要将其标记为 down
[root@ceph1 ~]# ceph fs set cephfs1 down true
cephfs1 marked down.
# 然后删除 CephFS
[root@ceph1 ~]# ceph fs rm cephfs1 --yes-i-really-mean-it
# 删除池
[root@ceph1 ~]# ceph config set mon mon_allow_pool_delete true
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.meta cephfs.cephfs1.meta --yes-i-really-really-mean-it
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.data.1 cephfs.cephfs1.data.1 --yes-i-really-really-mean-it
[root@ceph1 ~]# ceph osd pool rm cephfs.cephfs1.data.2 cephfs.cephfs1.data.2 --yes-i-really-really-mean-it卷部署 CephFS
创建 CephFS
bash
# 部署三个实例
[root@ceph1 ~]# ceph fs volume create cephfs2 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"
# 查看文件系统清单
[root@ceph1 ~]# ceph fs ls
name: cephfs2, metadata pool: cephfs.cephfs2.meta, data pools: [cephfs.cephfs2.data ]
# 查看mds服务状态
[root@ceph1 ~]# ceph mds stat
cephfs2:1 {0=cephfs2.ceph3.irxxar=up:active} 2 up:standby
# 查看mds服务守护进程
[root@ceph1 ~]# ceph orch ls mds
NAME PORTS RUNNING REFRESHED AGE PLACEMENT
mds.cephfs2 3/3 58s ago 62s ceph1.dcr.cloud;ceph2.dcr.cloud;ceph3.dcr.cloud;count:3删除 CephFS
bash
[root@ceph1 ~]# ceph fs volume ls
[
{
"name": "cephfs2"
}
]
[root@ceph1 ~]# ceph fs volume rm cephfs2 --yes-i-really-mean-it
metadata pool: cephfs.cephfs2.meta data pool: ['cephfs.cephfs2.data'] removed
[root@ceph1 ~]# ceph fs ls
No filesystems enabled挂载 CephFS 文件系统
环境准备
创建 cephfs1 和 cephfs2。
bash
[root@ceph1 ~]# ceph fs volume create cephfs1 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"
[root@ceph1 ~]# ceph fs volume create cephfs2 --placement="3 ceph1.dcr.cloud ceph2.dcr.cloud ceph3.dcr.cloud"CephFS 挂载方式
用户可使用以下方式挂载 CephFS 文件系统:
- Kernel 挂载,要求 Linux 内核版本达到 4 或以上,从 RHEL 8 开始可用。对于之前的内核版本,请改用FUSE 客户端。
- FUSE 挂载。
这两个挂载方式各有优势和劣势:
- Kernel 挂载,不支持配额,但速度可能较快。
- FUSE 挂载,支持配额和 ACL。 ACL 功能需要在挂载时明确指定该功能以启用。
CephFS 挂载用户
通过 ceph fs authorize 命令,可为 CephFS 文件系统中的不同用户和文件夹提供精细的访问控制。
CephFS 文件系统支持不同访问选项:
- **r:对指定文件夹的读取权限。**如果未指定其他限制,则会向子文件夹授予读取权限。
- **w:对指定文件夹的写入权限。**如果未指定其他限制,则会向子文件夹授予写入权限。
- p:除了 r 和 w 功能外,客户端还需要 p 选项才能使用布局或配额。
- s:除了 r 和 w 功能外,客户端还需要 s 选项才能创建快照。
示例1:允许用户对 / 文件夹具备读取、写入、配额和快照权限,并保存用户凭据。
bash
[root@ceph1 ~]# ceph fs authorize cephfs1 client.cephfs1-all-user / rwps > /etc/ceph/ceph.client.cephfs1-all-user.keyring示例2:允许用户读取 root 文件夹,并提供对 /dir2 文件夹的读取、写入,并保存用户凭据。
bash
[root@ceph1 ~]# ceph fs authorize cephfs1 client.cephfs1-restrict-user / r /dir2 rw > /etc/ceph/ceph.client.cephfs1-restrict-user.keyringCephFS 客户端挂载准备
要挂载基于 CephFS 的文件系统,请验证客户端主机是否满足以下条件:
-
安装 ceph-common 软件包。对于 FUSE 客户端,还要安装 ceph-fuse 软- 件包。
bash[root@client ~]# dnf install -y ceph-common -
复制 Ceph 配置文件到客户端。
bash[root@ceph1 ~]# scp /etc/ceph/ceph.conf root@client:/etc/ceph/ceph.conf -
将用户keyring复制到客户端主机上的 /etc/ceph 文件夹。
bash[root@ceph1 ~]# scp /etc/ceph/ceph.client.{cephfs1-all-user,cephfs1-restrict-user}.keyring root@client:/etc/ceph/
为了方便管理集群,我们将admin凭据复制到client。
bash
[root@ceph1 ~]# scp /etc/ceph/ceph.client.admin.keyring root@client:/etc/ceph/使用 Kernel 挂载 CephFS
挂载 CephFS
使用 mount.ceph 命令挂载文件系统:
bash
# mount.ceph [src] [mount-point] [-n] [-v] [-o ceph-options]
# 或者
# mount -t ceph [src] [mount-point] [-n] [-v] [-o ceph-options]用户可以指定逗号分隔的多个 MON 来挂载设备。标准端口 (6789) 为默认值,用户也可在各个MON 名称的后面添加冒号和非标准端口号。建议指定多个 MON,以防文件系统挂载时有些 MON 处于脱机状态。
bash
[root@client ~]# mount.ceph
usage: mount.ceph [src] [mount-point] [-n] [-v] [-o ceph-options]
options:
-h: Print this help
-n: Do not update /etc/mtab
-v: Verbose
ceph-options: refer to mount.ceph(8)使用 CephFS Kernel 客户端时,可用选项有:
- fs=fs-name,指定要挂载的 CephFS 文件系统名称。未提供值时,它会使用默认文件系统。
- name=name,指定Cephx 客户端 ID。默认为 guest。
- secret=secret_value,指定客户端的机密密钥的值。
- secretfile=secret_key_file,指定包含此客户端机密密钥的文件的