摘要
https://arxiv.org/pdf/2509.25164
本研究对Ultralytics YOLO26进行了全面分析,重点阐述了其在实时边缘目标检测方面的关键架构增强和性能基准测试。YOLO26于2025年9月发布,是YOLO家族中最新、最先进的成员,专为在边缘和低功耗设备上提供高效、准确且易于部署的解决方案而构建。本文依次详细介绍了YOLO26的架构创新,包括移除分布焦点损失(DFL)、采用端到端无NMS推理、集成渐进式损失平衡(ProgLoss)与小目标感知标签分配(STAL),以及引入用于稳定收敛的MuSGD优化器。除架构外,本研究将YOLO26定位为一个多任务框架,支持目标检测、实例分割、姿态/关键点估计、旋转目标检测和分类。我们展示了YOLO26在NVIDIA Jetson Nano和Orin等边缘设备上的性能基准,并将其结果与YOLOv8、YOLOv11、YOLOv12、YOLOv13以及基于Transformer的检测器进行比较。本文进一步探讨了实时部署路径、灵活的导出选项(ONNX、TensorRT、CoreML、TFLite)以及INT8/FP16量化。文中强调了YOLO26在机器人、制造和物联网等领域的实际用例,以展示其跨行业适应性。最后,讨论了关于部署效率和更广泛影响的见解,并概述了YOLO26及YOLO系列的未来发展方向。
关键词 YOLO26· 边缘AI· 多任务目标检测· 无NMS推理· 小目标识别· You Only Look Once· 目标检测· MuSGD优化器
1 引言
目标检测已成为计算机视觉中最关键的任务之一,使机器能够定位和分类图像或视频流中的多个目标1, 2。从自动驾驶和机器人到监控、医学影像、农业和智能制造,实时目标检测算法是人工智能(AI)应用的支柱3, 4。在这些算法中,You Only Look Once(YOLO)系列已成为最具影响力的实时目标检测模型系列,将准确性与前所未有的推理速度相结合5, 6, 7, 7。自2016年提出以来,YOLO经历了多次架构修订,每一次都解决了前代模型的局限性,同时集成了神经网络设计、损失函数和部署效率方面的尖端进展5。YOLO26于2025年9月发布,代表了这一演进轨迹的最新里程碑,引入了架构简化、新颖的优化器以及为低功耗设备设计的增强的边缘部署能力。
表1详细比较了从YOLOv1到YOLOv13以及YOLO26的各个YOLO模型,突出了它们的发布年份、关键架构创新、性能增强和开发框架。
YOLO框架由Joseph Redmon及其同事于2016年首次提出,标志着目标检测领域的范式转变8。与传统的两阶段检测器(如R-CNN18和Faster R-CNN19)将区域提议与分类分开不同,YOLO将检测公式化为一个单一的回归问题20。通过在一个前向传播过程中直接预测边界框和类别概率,YOLO在保持具有竞争力的准确性的同时实现了实时速度21, 20。这种效率使得YOLOv1在延迟是关键因素的应用中极具吸引力,包括机器人、自主导航和实时视频分析。后续版本YOLOv2(2017)9和YOLOv3(2018)10在保持实时性能的同时显著提高了准确性。YOLOv2引入了批量归一化、锚框和多尺度训练,从而提高了对不同尺寸目标的鲁棒性。YOLOv3采用了基于Darknet-53的更深架构以及多尺度特征图以改善小目标检测。这些增强功能使YOLOv3在随后的几年中成为学术界和工业应用的事实标准22, 5, 23。
随着对更高准确性的需求不断增长,特别是在航空影像、农业和医学分析等具有挑战性的领域,YOLO模型发展出更多先进的架构。YOLOv4(2020)11引入了跨阶段部分网络(CSPNet)、改进的激活函数(如Mish)以及先进训练策略,包括马赛克数据增强和CIoU损失。YOLOv5(Ultralytics, 2020)虽然非官方,但因其PyTorch实现、广泛的社区支持以及在多样化平台上的简化部署而获得了极大的普及。YOLOv5还带来了模块化特性,使其更容易适应分割、分类和边缘应用。进一步的发展包括YOLOv612和YOLOv713(2022),它们集成了先进的优化技术、参数高效模块和受Transformer启发的模块。这些迭代将YOLO推向了最先进的(SoTA)准确性基准,同时保持了对实时推理的关注。至此,YOLO生态系统已牢固确立了其在目标检测研究和部署领域的领先系列模型地位。
Ultralytics作为现代YOLO版本的主要维护者,通过YOLOv8(2023)24重新定义了该框架。YOLOv8采用了解耦的检测头、无锚框预测和改进的训练策略,从而在准确性和部署灵活性方面实现了实质性提升25。由于其简洁的Python API、与TensorRT、CoreML和ONNX的兼容性,以及针对速度与准确性权衡优化的变体(nano、small、medium、large和extra-large)的可用性,它在工业界被广泛采用。YOLOv914、YOLOv1015和YOLO11相继快速发布,每一次迭代都在推动架构和性能的边界。YOLOv9引入了GELAN(广义高效层聚合网络)和渐进式蒸馏,将效率与更高的表征能力相结合。YOLOv10通过混合任务对齐分配专注于平衡准确性和推理延迟。YOLOv11进一步完善了Ultralytics的愿景,在GPU上提供了更高的效率,同时保持了强大的小目标性能5。这些模型共同巩固了Ultralytics在生产适用于现代部署流程的、即用型YOLO版本方面的声誉。
继YOLO11之后,替代版本YOLOv1216和YOLOv1317引入了以注意力为中心的设计和先进的架构组件,旨在最大化跨不同数据集的准确性。这些模型探索了多头自注意力、改进的多尺度融合和更强的训练正则化策略。虽然它们提供了强大的基准,但仍然依赖非极大值抑制(NMS)和分布焦点损失(DFL),这引入了延迟开销和导出挑战,特别是对于低功耗设备。基于NMS的后处理和复杂损失公式的局限性推动了YOLO26(Ultralytics YOLO26官方来源)的开发。2025年9月,在伦敦举行的YOLO Vision 2025活动上,Ultralytics发布了YOLO26,作为专为边缘计算、机器人和移动AI优化的下一代模型。
YOLO26围绕三个指导原则构建:简洁性、效率和创新。图1概述将这些设计选择与其支持的五个任务(目标检测、实例分割、姿态/关键点检测、旋转目标检测和分类)并列展示。在推理路径上,YOLO26消除了NMS,产生原生的端到端预测,消除了主要的后处理瓶颈,减少了延迟方差,并简化了跨部署的阈值调整。在回归方面,它移除了DFL,将分布式的边界框解码转变为更轻量、硬件友好的公式,从而干净地导出到ONNX、TensorRT、CoreML和TFLite------这对于边缘和移动端部署流程是一个实用的胜利。这些变化共同产生了一个更简洁的计算图、更快的冷启动和更少的运行时依赖,这对于CPU受限和嵌入式场景尤其有益。训练稳定性和小目标保真度通过ProgLoss(渐进式损失平衡)和STAL(小目标感知标签分配)来解决。ProgLoss自适应地重新加权各目标损失,以防止在训练后期简单样本主导学习过程,而STAL则优先为微小或被遮挡的实例分配标签,提高了在航空、机器人、智能摄像头等常见于杂乱、树叶或运动模糊条件下的召回率。优化由MuSGD驱动,这是一种混合优化器,融合了SGD的泛化能力与受Muon风格方法启发的动量/曲率行为,实现了更快、更平滑的收敛和跨尺度更可靠的平台期。
如图1再次强调,功能上,YOLO26的五个能力共享统一的骨干/颈部和简化的头:
- 目标检测:无锚框、无NMS的边界框和分数
- 实例分割:耦合到共享特征的轻量级掩码分支
- 姿态/关键点检测:用于人体或部位关键点的紧凑关键点头
- 旋转目标检测:用于倾斜物体和细长目标的旋转边界框
- 分类:用于纯识别任务的单标签逻辑输出
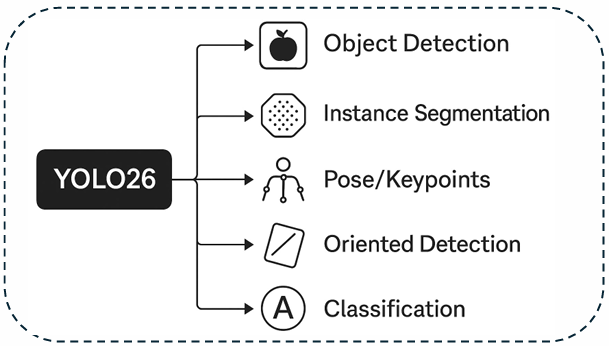
图1:YOLO26统一架构支持五个关键视觉任务:目标检测、实例分割、姿态/关键点检测、旋转目标检测和分类。
这种整合设计允许进行多任务训练或特定任务的微调,而无需进行架构上的修改,同时简化的导出保持了跨加速器的可移植性。总之,YOLO26通过将端到端推理和无DFL回归与ProgLoss、STAL和MuSGD相结合,推进了YOLO系列的发展,产生了一个部署更快、训练更稳定、能力更广泛的模型,如图1视觉总结所示。
2 YOLO26的架构增强
YOLO26的架构遵循一个经过精简和高效的流程,专为跨边缘和服务器平台的实时目标检测而构建。如图2所示,该过程始于以图像或视频流形式的输入数据,这些数据首先经过预处理操作,包括调整大小和归一化到适合模型推理的标准尺寸。然后,数据被送入骨干特征提取阶段,一个紧凑而强大的卷积网络在此捕获视觉模式的层次化表征。为了增强跨尺度的鲁棒性,该架构生成多尺度特征图(图2),为大小目标保留语义丰富性。这些特征图随后在一个轻量级的特征融合颈部进行合并,信息以计算高效的方式进行整合。特定于检测的处理发生在直接回归头中,与先前的YOLO版本不同,它直接输出边界框和类别概率,而不依赖于非极大值抑制(NMS)。这种端到端的无NMS推理(图2)消除了后处理开销并加速了部署。训练稳定性和准确性通过ProgLoss平衡和STAL分配模块得到加强,确保损失项的公平加权并改进小目标的检测。模型优化由MuSGD优化器引导,结合了SGD和Muon的优势,实现更快、更可靠的收敛。部署效率通过量化得到进一步增强,支持FP16和INT8精度,从而能够在CPU、NPU和GPU上实现加速,同时精度损失最小。最后,该流程最终生成输出预测,包括边界框和类别分配,可以可视化叠加在输入图像上。总的来说,YOLO26的架构展示了一种精心平衡的设计理念,同时提升了准确性、稳定性和部署简便性。
YOLO26引入了几个关键的架构创新,使其区别于前几代YOLO模型。这些增强不仅提高了训练稳定性和推理效率,而且从根本上重塑了实时边缘设备的部署流程。在本节中,我们描述了YOLO26的四个主要贡献:(i)移除分布焦点损失(DFL),(ii)引入端到端无NMS推理,(iii)包括渐进式损失平衡(ProgLoss)和小目标感知标签分配(STAL)在内的新颖损失函数策略,以及(iv)开发用于稳定高效收敛的MuSGD优化器。我们将详细讨论每一项架构增强,并通过对比分析突出它们相较于YOLOv8、YOLOv11、YOLOv12和YOLOv13等早期YOLO版本的优势。
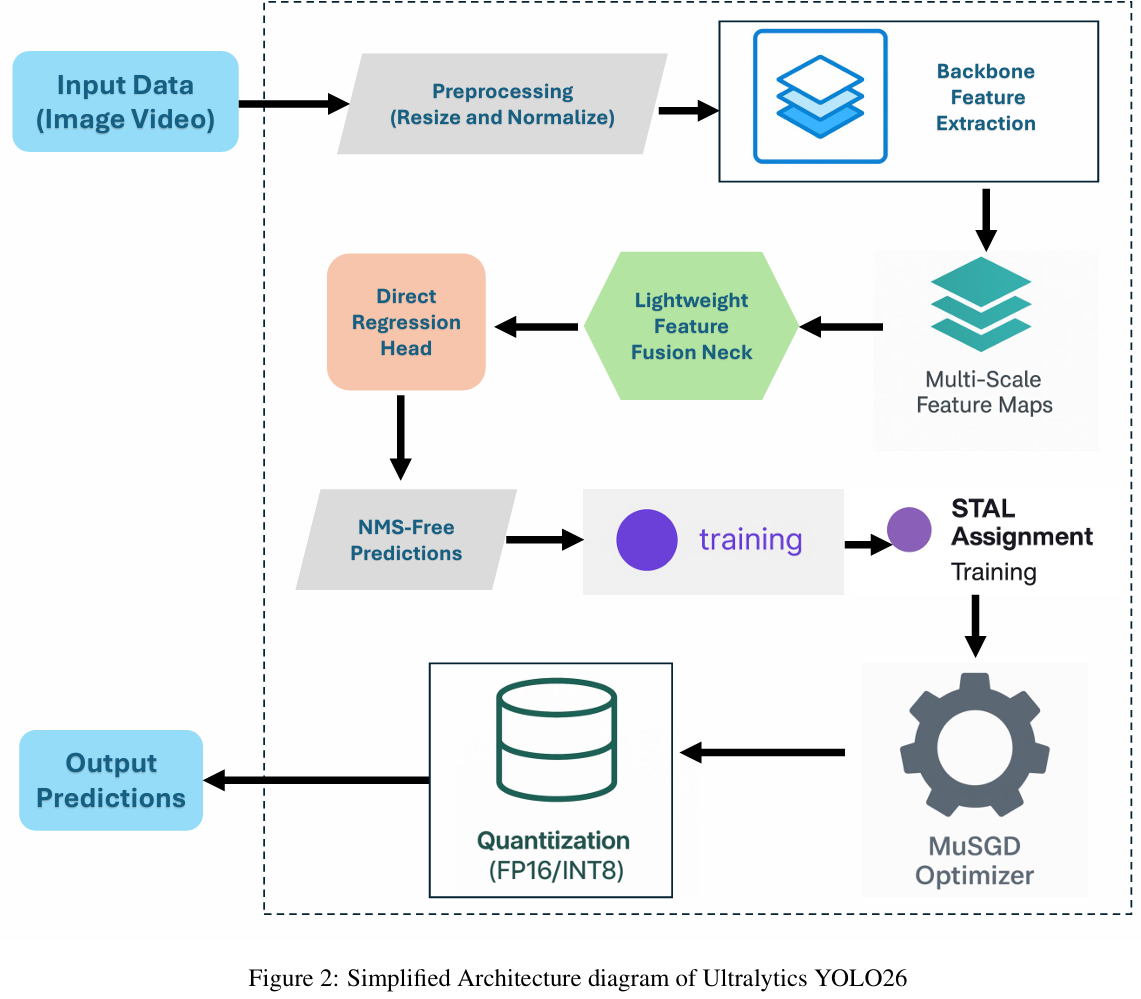
图2:Ultralytics YOLO26的简化架构图
2.1 移除分布焦点损失(DFL)
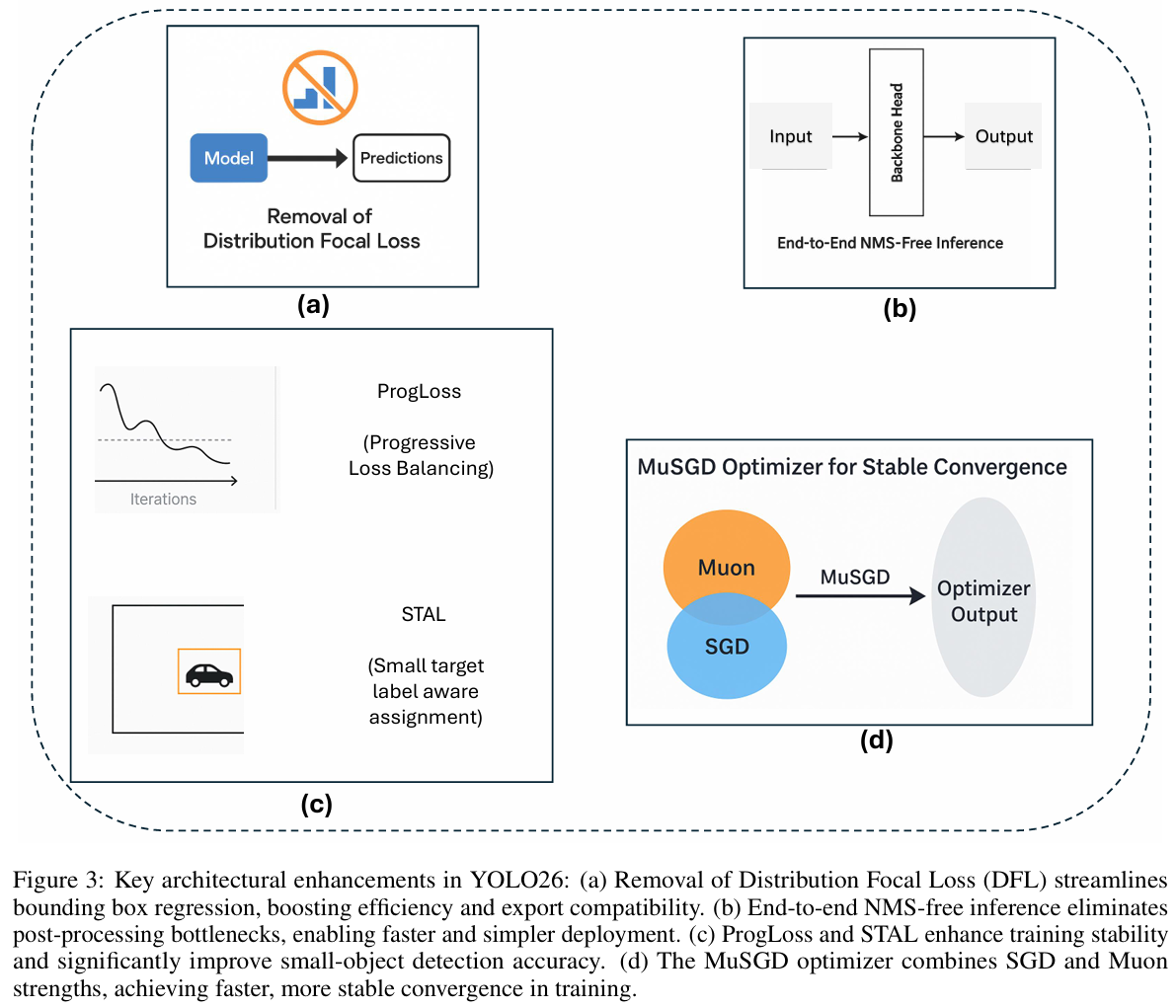
YOLO26中最显著的架构简化之一是移除了分布焦点损失(DFL)模块(图3a),该模块曾出现在YOLOv8和YOLOv11等先前的YOLO版本中。DFL最初旨在通过预测边界框坐标的概率分布来改进边界框回归,从而允许更精确的目标定位。虽然该策略在早期模型中显示出准确性的提升,但它也引入了不小的计算开销和导出困难。在实践中,DFL在推理和模型导出时需要特殊处理,这使针对ONNX、CoreML、TensorRT或TFLite等硬件加速器的部署流程复杂化。
通过消除DFL,YOLO26简化了模型架构,使边界框预测成为一个更直接的回归任务,同时不牺牲性能。对比分析表明,当与ProgLoss和STAL等其他创新结合时,YOLO26实现了与基于DFL的YOLO模型相当或更优的准确性。此外,移除DFL显著降低了推理延迟并提高了跨平台兼容性。这使得YOLO26更适合边缘AI场景,在这些场景中,轻量级和硬件友好的模型至关重要。
相比之下,YOLOv12和YOLOv13等模型在其架构中保留了DFL,这限制了它们在受限设备上的适用性,尽管在GPU资源丰富的环境中具有强大的准确性基准。因此,YOLO26标志着朝着使最先进的目标检测性能与移动、嵌入式和工业应用的实际需求相协调的决定性一步。
2.2 端到端无NMS推理
YOLO26的另一个突破性特性是其原生支持无需非极大值抑制(NMS)的端到端推理(参见图3b)。传统的YOLO模型,包括从YOLOv8到YOLOv13,都严重依赖NMS作为后处理步骤,通过只保留置信度最高的边界框来过滤掉重复的预测。虽然有效,但NMS给流程增加了额外的延迟,并且需要手动调整超参数,如交并比(IoU)阈值。这种对手工后处理步骤的依赖在部署流程中引入了脆弱性,特别是对于边缘设备和延迟敏感的应用。
YOLO26从根本上重新设计了预测头,以产生直接的、非冗余的边界框预测,而无需NMS。这种端到端设计不仅降低了推理复杂度,还消除了对人工调整阈值的依赖,从而简化了集成到生产系统中的过程。对比基准测试表明,YOLO26实现了比YOLOv11和YOLOv12更快的推理速度,其中nano模型的CPU推理时间减少了高达43%。这使得YOLO26对移动设备、无人机和嵌入式机器人平台特别有利,在这些平台上,毫秒级的延迟可能产生重大的操作影响。
除了速度之外,无NMS方法还提高了可重复性和部署可移植性,因为模型不再需要大量的后处理代码。虽然其他先进的检测器(如RT-DETR和Sparse R-CNN)已经尝试了无NMS推理,但YOLO26代表了第一个采用这种范式同时保持YOLO标志性的速度与准确性平衡的YOLO版本。与仍然依赖NMS的YOLOv13相比,YOLO26的端到端流程作为实时检测的前瞻性架构脱颖而出。
2.3 ProgLoss与STAL:增强的训练稳定性和小目标检测
训练稳定性和小目标识别仍然是目标检测中持续存在的挑战。YOLO26通过集成两种新颖的策略来解决这些问题:渐进式损失平衡(ProgLoss)和小目标感知标签分配(STAL),如图3c所示。
ProgLoss在训练期间动态调整不同损失分量的权重,确保模型不会过度拟合主导目标类别,同时对稀有或小类别表现不佳。这种渐进式重新平衡提高了泛化能力,并防止了在训练后期阶段的不稳定性。另一方面,STAL明确优先为小目标分配标签,这些小目标由于其有限的像素表示和容易被遮挡而特别难以检测。ProgLoss和STAL共同为YOLO26在包含小目标或被遮挡目标的数据集(如COCO和无人机影像基准)上提供了实质性的准确性提升。
相比之下,早期模型如YOLOv8和YOLOv11没有纳入此类针对性机制,通常需要数据集特定的增强或外部训练技巧来实现可接受的小目标性能。YOLOv12和YOLOv13试图通过基于注意力的模块和增强的多尺度特征融合来解决这一差距;然而,这些解决方案增加了架构复杂性和推理成本。YOLO26以更轻量级的方法实现了相似或更优的改进,从而加强了其对于边缘AI应用的适用性。通过集成ProgLoss和STAL,YOLO26在保持YOLO家族效率和可移植性的同时,确立了自身作为鲁棒的小目标检测器的地位。
2.4 用于稳定收敛的MuSGD优化器
YOLO26的最后一个创新是引入了MuSGD优化器(图3d),它结合了随机梯度下降(SGD)的优势与最近提出的Muon优化器(一种受大型语言模型训练中使用的优化策略启发的技术)的优势。MuSGD利用了SGD的鲁棒性和泛化能力,同时融合了Muon的自适应特性,从而能够在不同数据集上实现更快的收敛和更稳定的优化。
这种混合优化器反映了现代深度学习的一个重要趋势:自然语言处理(NLP)和计算机视觉之间进展的交叉融合。通过借鉴LLM训练实践(例如,Moonshot AI的Kimi K2),YOLO26受益于先前在YOLO系列中未探索过的稳定性增强。实证结果表明,MuSGD使YOLO26能够以更少的训练周期达到具有竞争力的准确性,从而减少了训练时间和计算成本。
先前的YOLO版本,包括从YOLOv8到YOLOv13,依赖于标准的SGD或AdamW变体。虽然有效,但这些优化器需要进行大量的超参数调整,并且有时表现出不稳定的收敛,特别是在具有高变异性的数据集上。相比之下,MuSGD在保持YOLO轻量级训练理念的同时提高了可靠性。对于实践者来说,这意味着更短的开发周期、更少的训练重启次数以及跨部署场景更可预测的性能。通过集成MuSGD,YOLO26不仅将自己定位为一个推理优化的模型,而且还是一个对研究人员和行业实践者友好的、便于训练的架构。
3 基准测试与比较分析
针对YOLO26,我们进行了一系列严格的基准测试,以评估其性能,并与YOLO前代模型以及替代的最先进架构进行比较。图4呈现了这一评估的综合视图,绘制了在NVIDIA T4 GPU上使用TensorRT FP16优化时的COCO mAP(50--95)与延迟(每张图像毫秒数)的关系。包含竞争架构,如YOLOv10、RT-DETR、RT-DETRv2、RT-DETRv3和DEIM,提供了近期实时检测进展的全面概览。从图中可以看出,YOLO26展示了一个独特的位置:它保持了与RT-DETRv3等基于Transformer模型相媲美的高精度水平,同时在推理速度方面显著优于它们。例如,YOLO26-m和YOLO26-l分别实现了高于51%和53%的竞争性mAP分数,但延迟显著降低,这突显了其无NMS架构和轻量级回归头的优势。
这种准确性与速度之间的平衡对于边缘部署尤其重要,因为在边缘部署中,保持实时吞吐量与确保可靠的检测质量同样重要。与YOLOv10相比,YOLO26在不同的模型规模上持续实现了更低的延迟,在CPU受限的推理中观察到高达43%的加速,同时通过其ProgLoss和STAL机制保持或提高了准确性。与严重依赖Transformer编码器和解码器的DEIM和RT-DETR系列相比,YOLO26简化的骨干网络和MuSGD驱动的训练流程实现了更快的收敛和更精简的推理,同时不影响小目标识别能力。
图4中的图表清楚地说明了这些区别:虽然RT-DETRv3在大规模准确性基准测试中表现出色,但其延迟曲线仍然不如YOLO26有利,这强化了YOLO26以边缘为中心的设计理念。此外,基准测试分析强调了YOLO26在平衡准确性-延迟曲线方面的鲁棒性,使其成为适用于高吞吐量服务器应用和资源受限设备的多功能检测器。这一比较证据证实了YOLO26不仅仅是渐进式的更新,而是YOLO系列中的范式转变,成功弥合了早期YOLO模型效率至上的理念与基于Transformer的检测器准确性驱动的导向之间的差距。最终,基准测试结果表明,YOLO26提供了引人注目的部署优势,特别是在对延迟有严格要求、需要可靠性能的实际环境中。
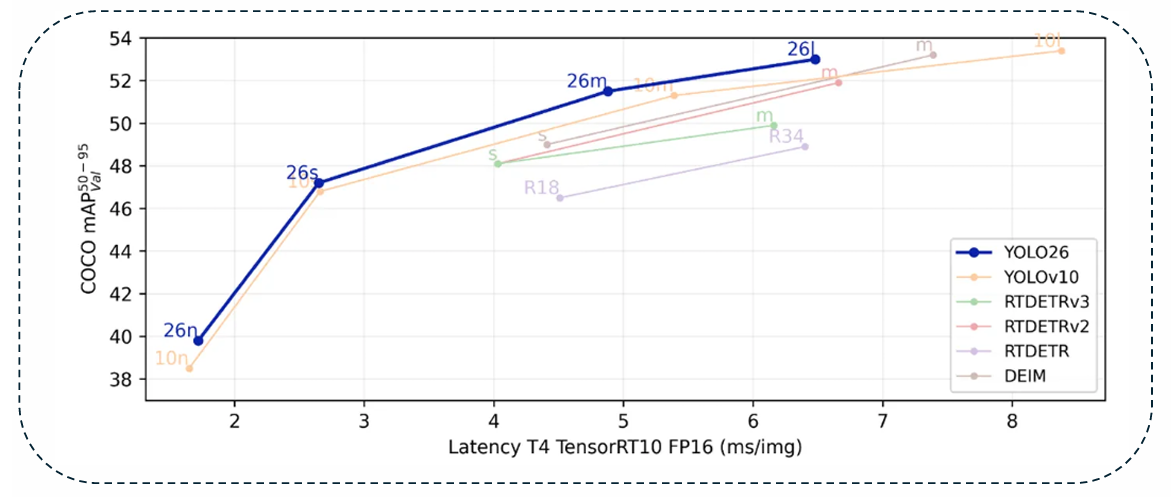
图4:YOLO26与YOLOv10、RT-DETR、RT-DETRv2、RT-DETRv3和DEIM在COCO数据集上的性能基准测试。该图显示了在NVIDIA T4 GPU上使用TensorRT FP16推理测得的COCO mAP(50--95)与延迟(每张图像毫秒数)的关系。YOLO26展示了准确性与效率之间的卓越平衡,实现了具有竞争力的检测性能,同时显著降低了延迟,从而突出了其在实时边缘和资源受限部署中的适用性。
4 使用Ultralytics YOLO26进行实时部署
在过去十年中,目标检测模型的发展不仅体现在准确性的提高上,还体现在部署复杂性的增长上26, 27, 28。早期检测器如R-CNN及其更快变体(Fast R-CNN、Faster R-CNN)实现了令人印象深刻的检测质量,但计算成本高昂,需要多个阶段进行区域提议和分类29, 30, 31。这限制了它们在实时和嵌入式应用中的使用。YOLO家族的出现改变了这一格局,它将检测重新定义为一个单一的回归问题,使得在商用GPU上实现实时性能成为可能32。然而,随着YOLO系列从YOLOv1发展到YOLOv13,准确性的提升常常以增加额外的架构组件为代价,例如分布焦点损失(DFL)、复杂的后处理步骤(如非极大值抑制(NMS))以及日益沉重的骨干网络,这些都在部署过程中引入了摩擦。YOLO26通过精简架构和导出路径来直接解决这一长期存在的挑战,从而降低跨不同硬件和软件生态系统的部署障碍。
4.1 灵活的导出与集成路径
YOLO26的一个关键优势是其能够无缝集成到现有的生产流程中。Ultralytics维护一个积极开发的Python包,为训练、验证和导出提供统一支持,降低了寻求采用YOLO26的实践者的技术门槛。与早期需要为硬件加速进行大量自定义转换脚本的YOLO模型不同33, 34, 35,YOLO26原生支持广泛的导出格式。这些格式包括用于最大GPU加速的TensorRT、用于广泛跨平台兼容性的ONNX、用于原生iOS集成的CoreML、用于Android和边缘设备的TFLite,以及用于在英特尔硬件上优化性能的OpenVINO。这些导出选项的广度使得研究人员、工程师和开发人员能够将模型从原型设计阶段推进到生产阶段,而不会遇到早期版本中常见的兼容性瓶颈。
历史上,YOLOv3到YOLOv7在导出时通常需要人工干预,特别是在针对NVIDIA TensorRT或Apple CoreML等专用推理引擎时36, 37。类似地,基于Transformer的检测器(如DETR及其后续版本)在转换到PyTorch环境之外时面临挑战,因为它们依赖于动态注意力机制。相比之下,YOLO26通过移除DFL和采用无NMS预测头而简化的架构,确保了跨平台的兼容性,同时不牺牲准确性。这使得YOLO26成为迄今为止部署最友好的检测器之一,强化了其作为边缘优先模型的身份。
4.2 量化与资源受限设备
除了导出灵活性之外,现实世界部署的真正挑战在于确保在计算资源有限的设备上的效率27, 38。边缘设备,如智能手机、无人机和嵌入式视觉系统,通常缺乏独立的GPU,并且必须平衡内存、功耗和延迟约束39, 40。量化是减少模型大小和计算负载的广泛采用的策略,然而许多复杂的检测器在进行激进的量化时会出现显著的准确性下降。YOLO26在设计时就考虑到了这一限制。
得益于其简化的架构和简化的边界框回归流程,YOLO26在半精度(FP16)和整数(INT8)量化方案下都表现出一致的准确性。FP16量化利用GPU对混合精度算术的原生支持,以更少的内存占用实现更快的推理。INT8量化将模型权重压缩为8位整数,在保持具有竞争力的准确性的同时,显著减少了模型大小和能耗。基准实验证实,YOLO26在这些量化水平下保持稳定性,在相同条件下优于YOLOv11和YOLOv12。这使得YOLO26特别适合部署在紧凑的硬件上,如NVIDIA Jetson Orin、Qualcomm Snapdragon AI加速器,甚至是为智能摄像头提供动力的基于ARM的CPU。
相比之下,基于Transformer的检测器(如RT-DETRv3)在INT8量化下表现出性能的急剧下降41,这主要是由于注意力机制对精度降低的敏感性。同样,YOLOv12和YOLOv13虽然在GPU服务器上提供了强大的准确性,但在低功耗设备上一旦量化后,难以保持有竞争力的性能。因此,YOLO26为目标检测中的量化感知设计建立了新的基准,证明了架构简洁性可以直接转化为部署鲁棒性。
4.3 跨行业应用:从机器人到制造
这些部署增强的实际影响可以通过跨行业应用得到最好的说明。在机器人领域,实时感知对于导航、操纵和安全的人机协作至关重要42, 43。通过提供无NMS预测和一致的低延迟推理,YOLO26使机器人系统能够更快、更可靠地解释其环境。例如,配备YOLO26的机械臂可以在动态条件下以更高的精度识别和抓取物体,而移动机器人则受益于在杂乱空间中改进的障碍物识别能力。与YOLOv8或YOLOv11相比,YOLO26提供了更低的推理延迟,这在高速场景中可能是安全操作与碰撞之间的区别。
在制造业中,YOLO26对于自动缺陷检测和质量保证具有重要影响。传统的手动检查不仅劳动密集,而且容易出错。先前的YOLO版本,特别是YOLOv8,已经在智能工厂中得到部署;然而,导出的复杂性和NMS的延迟开销有时限制了大规模的推广。YOLO26通过提供通过OpenVINO或TensorRT的轻量级部署选项来减轻这些障碍,允许制造商将实时缺陷检测系统直接集成到生产线上。早期基准测试表明,基于YOLO26的缺陷检测流程与YOLOv12和基于Transformer的替代方案(如DEIM)相比,实现了更高的吞吐量和更低的运营成本。
4.4 来自YOLO26部署的广泛见解
总而言之,YOLO26的部署特性强调了目标检测演变中的一个中心主题:架构效率与准确性同等重要。虽然过去五年见证了从基于卷积的YOLO变体到基于Transformer的检测器(如DETR和RT-DETR)日益复杂的模型的兴起,但实验室性能与生产就绪性之间的差距常常限制了它们的影响力。YOLO26通过简化架构、扩展导出兼容性并确保量化下的弹性,弥合了这一差距,从而将尖端准确性与实际部署需求相结合。
对于构建移动应用程序的开发人员,YOLO26通过CoreML和TFLite实现无缝集成,确保模型在iOS和Android平台上本地运行。对于在云或本地服务器上部署视觉AI的企业,TensorRT和ONNX导出提供了可扩展的加速选项。对于工业和边缘用户,OpenVINO和INT8量化保证了即使在资源紧张的限制下性能也能保持一致。从这个意义上说,YOLO26不仅是目标检测研究的一个进步,也是民主化部署的一个重要里程碑。
5 结论与未来方向
总之,YOLO26代表了YOLO目标检测系列中的一个重大飞跃,将架构创新与务实的部署焦点相结合。该模型通过移除分布焦点损失(DFL)模块并消除对非极大值抑制的需求来简化其设计。通过移除DFL,YOLO26简化了边界框回归并避免了导出复杂化,从而拓宽了与各种硬件的兼容性。同样,其端到端、无NMS的推理使网络能够直接输出最终检测结果,而无需后处理步骤。这不仅减少了延迟,还简化了部署流程,使YOLO26成为早期YOLO理念的自然演进。在训练方面,YOLO26引入了渐进式损失平衡(ProgLoss)和小目标感知标签分配(STAL),它们共同稳定了学习过程,并提升了在具有挑战性的小目标上的准确性。此外,新颖的MuSGD优化器结合了SGD和Muon的特性,加速了收敛并提高了训练稳定性。这些增强功能协同工作,提供了一个不仅在实践中更准确、更鲁棒,而且明显更快、更轻量的检测器。
基准比较凸显了YOLO26相对于其YOLO前代模型和当代模型的强大性能。先前的YOLO版本(如YOLO11)以更高的效率超越了早期版本,而YOLO12通过集成注意力机制进一步扩展了准确性。YOLO13增加了基于超图的改进以实现额外的提升。YOLO26相对于基于Transformer的竞争对手,在很大程度上缩小了差距。其原生的无NMS设计反映了受Transformer启发的检测器的端到端方法,但具有YOLO标志性的效率。YOLO26在提供具有竞争力的准确性的同时,显著提升了在常见硬件上的吞吐量并最小化了复杂性。实际上,YOLO26的设计使其在CPU上的推理速度比以前的YOLO版本快高达43%,使其成为资源受限环境中最实用的实时检测器之一。这种性能与效率的和谐平衡使得YOLO26不仅在基准排行榜上表现出色,而且在速度、内存和能耗至关重要的实际现场部署中也表现出色。
YOLO26的一个主要贡献是其对部署优势的强调。该模型的架构被特意优化以用于实际应用:通过省略DFL和NMS,YOLO26避免了在专用硬件加速器上难以实现的操作,从而提高了跨设备的兼容性。该网络可以导出为多种格式,包括ONNX、TensorRT、CoreML、TFLite和OpenVINO,确保开发人员可以同样轻松地将其集成到移动应用程序、嵌入式系统或云服务中。至关重要的是,YOLO26还支持鲁棒的量化:得益于其简化的架构能够容忍低比特宽度推理,它可以使用INT8量化或半精度FP16进行部署,而对准确性的影响最小。这意味着模型可以被压缩和加速,同时仍能提供可靠的检测性能。这些特性转化为实际的边缘性能提升:从无人机到智能摄像头,YOLO26可以在CPU和小型设备上实时运行,而以前的YOLO模型在这些设备上运行困难。所有这些改进都展示了一个贯穿始终的主题:YOLO26弥合了尖端研究思想与可部署AI解决方案之间的差距。这种方法强调了YOLO26作为学术创新与工业应用之间桥梁的作用,将最新的视觉进展直接带给实践者。
5.1 未来方向
展望未来,YOLO和目标检测研究的轨迹指出了几个有希望的方向。一个明确的途径是将多个视觉任务统一到更全面的模型中。YOLO26已经在一个框架中支持目标检测、实例分割、姿态估计、旋转边界框和分类,反映了向多任务通用性发展的趋势。未来的YOLO迭代可能会通过融入开放词汇表和基础模型能力来进一步推动这一点。这可能意味着利用强大的视觉-语言模型,使检测器能够以零样本方式识别任意的目标类别,而不受限于固定的标签集。通过基于基础模型和大规模预训练进行构建,下一代的YOLO可以作为一个通用的视觉AI,无缝处理检测、分割,甚至对上下文中的新目标进行描述。
另一个关键的演进可能在于目标检测领域的半监督和自监督学习44, 45, 46, 47。最先进的检测器仍然严重依赖大型标记数据集,但研究正在迅速推进利用未标记或部分标记数据进行训练的方法。教师-学生训练48, 49, 50、伪标签51, 52和自监督特征学习53等技术可以集成到YOLO训练流程中,以减少对大量人工标注的需求。未来的YOLO可能会自动利用大量未标注的图像或视频来提高识别的鲁棒性。通过这样做,模型可以持续改进其检测能力,而无需成比例地增加标记数据,使其更能适应新领域或罕见目标类别。
在架构方面,我们预计在目标检测器中会继续融合Transformer和CNN设计原则。近期YOLO模型的成功表明,将注意力和全局推理注入YOLO类架构中可以带来准确性收益54, 55。未来的YOLO架构可能会采用混合设计,将卷积骨干网络(用于高效的局部特征提取)与基于Transformer的模块或解码器(用于捕获长距离依赖关系和上下文)相结合。这种混合方法可以通过建模纯CNN或朴素自注意力可能错过的关系,来改进模型对复杂场景的理解,例如在拥挤或高度上下文依赖的环境中。我们期望下一代检测器能够智能地融合这些技术,实现丰富的特征表征和低延迟。简而言之,"基于CNN的"和"基于Transformer的"检测器之间的界限将继续模糊,汲取两者的优势以应对多样化的检测挑战。
最后,由于部署仍然是一个首要关注点,未来的研究可能会强调边缘感知的训练和优化。这意味着从训练阶段开始,模型开发将越来越多地考虑硬件约束,而不是仅仅作为事后的想法。诸如量化感知训练(在训练期间使用模拟低精度算术)之类的技术可以确保即使在量化为INT8以实现快速推理后,网络仍然保持准确。我们还可能看到神经架构搜索和自动化模型压缩在构建YOLO模型时成为标准,从而使每个新版本都是与特定目标平台协同设计的。此外,将部署反馈(例如设备上的延迟测量或能耗)纳入训练循环是一个新兴的想法。例如,一个边缘优化的YOLO可以根据运行时约束动态调整其深度或分辨率,或者从更大的模型蒸馏到更小的模型,同时性能损失最小。通过在训练中考虑这些因素,所产生的检测器将在实践中实现准确性与效率之间更优的权衡。随着目标检测器进入物联网、AR/VR和自主系统,在这些领域中,在有限硬件上的实时性能是无可非议的,这种对高效AI的关注至关重要。
注意:本研究将在不久的将来通过基准测试YOLO26与YOLOv13、YOLOv12和YOLOv11的性能进行实验评估。将使用机器视觉摄像头在农业环境中收集一个包含10,000多个手动标记的目标的自定义数据集。模型将在相同条件下进行训练,结果将以精确率、召回率、准确率、F1分数、mAP、推理速度和前/后处理时间的形式报告。此外,在NVIDIA Jetson上的边缘计算实验将评估实时检测能力,为YOLO26在资源受限的农业应用中的实际部署提供见解。
6 致谢
本工作部分得到了美国国家科学基金会(NSF)和美国农业部(USDA)国家粮食与农业研究所(NIFA)通过"农业人工智能(AI)研究所"计划的支持,资助号为AWD003473和AWD004595,以及USDA-NIFA登录号1029004,项目名为"使用软机械臂进行机器人疏花"。额外支持来自USDA-NIFA资助号2024-67022-41788,登录号1031712,项目名为"扩大UCF人工智能研究至新型农业工程应用(PARTNER)"。
参考文献
1 Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, and Xindong Wu. Object detection with deep learning: A review. IEEE transactions on neural networks and learning systems, 30(11):3212--3232, 2019.
2 Zhengxia Zou, Keyan Chen, Zhenwei Shi, Yuhong Guo, and Jieping Ye. Object detection in 20 years: A survey. Proceedings of the IEEE, 111(3):257--276, 2023.
3 Chhavi Rana et al. Artificial intelligence based object detection and traffic prediction by autonomous vehicles---a review. Expert Systems with Applications, 255:124664, 2024.
4 Zohaib Khan, Yue Shen, and Hui Liu. Object detection in agriculture: A comprehensive review of methods, applications, challenges, and future directions. Agriculture, 15(13):1351, 2025.
5 Ranjan Sapkota, Marco Flores-Calero, Rizwan Qureshi, Chetan Badgujar, Upesh Nepal, Alwin Poulose, Peter Zeno, Uday Bhanu Prakash Vaddevolu, Sheheryar Khan, Maged Shoman, et al. Yolo advances to its genesis: a decadal and comprehensive review of the you only look once (yolo) series. Artificial Intelligence Review, 58(9):274, 2025.
6 Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, and Manoj Karkee. Rf-detr object detection vs yolov12: A study of transformer-based and cnn-based architectures for single-class and multi-class greenfruit detection in complex orchard environments under label ambiguity. arXiv preprint arXiv:2504.13099, 2025.
7 Ranjan Sapkota, Awood Ahmed, and Manoj Karkee. Comparative analysis of yolov8 and mask r-cnn for instance segmentation in complex orchard environments. Artificial Intelligence in Agriculture, 13:84-99, 2024.
8 Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779-788, 2016.
9 Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263--7271, 2017.
10 Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
11 Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
12 Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976, 2022.
13 Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7464--7475, 2023.
14 Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. Yolov9: Learning what you want to learn using programmable gradient information. In European conference on computer vision, pages 1--21. Springer, 2024.
15 Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, et al. Yolov10: Real-time end-to-end object detection. Advances in Neural Information Processing Systems, 37:107984--108011, 2024.
16 Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors. arXiv preprint arXiv:2502.12524, 2025.
17 Mengqi Lei, Siqi Li, Yihong Wu, Han Hu, You Zhou, Xinhu Zheng, Guiguang Ding, Shaoyi Du, Zongze Wu, and Yue Gao. Yolov13: Real-time object detection with hypergraph-enhanced adaptive visual perception. arXiv preprint arXiv:2506.17733, 2025.
18 Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961--2969, 2017.
19 Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence, 39(6):1137--1149, 2016.
20 Tausif Diwan, G Anirudh, and Jitendra V Tembhurne. Object detection using yolo: challenges, architectural successors, datasets and applications. Multimedia Tools and Applications, 82(6):9243--9275, 2023.
21 Momina Liaqat Ali and Zhou Zhang. The yolo framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers, 13(12):336, 2024.
22 Kyriakos D Apostolidis and George A Papakostas. Delving into yolo object detection models: Insights into adversarial robustness. Electronics, 14(8):1624, 2025.
23 Enerst Edozie, Aliyu Nuhu Shuaibu, Ukagwu Kelechi John, and Bashir Olaniyi Sadiq. Comprehensive review of recent developments in visual object detection based on deep learning. Artificial Intelligence Review, 58(9):277, 2025.
24 Mupparaju Sohan, Thotakura Sai Ram, and Ch Venkata Rami Reddy. A review on yolov8 and its advancements. In International Conference on Data Intelligence and Cognitive Informatics, pages 529--545. Springer, 2024.
25 J Javaria Farooq, Muhammad Muaz, Khurram Khan Jadoon, Nayyer Aafaq, and Muhammad Khizer Ali Khan. An improved yolov8 for foreign object debris detection with optimized architecture for small objects. Multimedia Tools and Applications, 83(21):60921-60947, 2024.
26 Maria Trigka and Elias Dritsas. A comprehensive survey of machine learning techniques and models for object detection. Sensors, 25(1):214, 2025.
27 Md Tanzib Hosain, Asif Zaman, Mushfiqur Rahman Abir, Shanjida Akter, Sawon Mursalin, and Shadman Sakeeb Khan. Synchronizing object detection: Applications, advancements and existing challenges. IEEE access, 12:54129--54167, 2024.
28 Ambati Pravallika, Mohammad Farukh Hashmi, and Aditya Gupta. Deep learning frontiers in 3d object detection: a comprehensive review for autonomous driving. IEEE Access, 2024.
29 Jiawei Tian, Seungho Lee, and Kyungtae Kang. Faster r-cnn in healthcare and disease detection: A comprehensive review. In 2025 International Conference on Electronics, Information, and Communication (ICEIC), pages 1--6. IEEE, 2025.
30 Peng Fu and Jiyang Wang. Lithology identification based on improved faster r-cnn. Minerals, 14(9):954, 2024.
31 Samiyaa Yaseen Mohammed. Architecture review: Two-stage and one-stage object detection. Franklin Open, page 100322, 2025.
32 Richard Johnson. YOLO Object Detection Explained: Definitive Reference for Developers and Engineers. HiTeX Press, 2025.
33 Daniel Pestana, Pedro R Miranda, João D Lopes, Rui P Duarte, Mário P Véstias, Horacio C Neto, and José T De Sousa. A full featured configurable accelerator for object detection with yolo. IEEE Access, 9:75864--75877, 2021.
34 Duy Thanh Nguyen, Tuan Nghia Nguyen, Hyun Kim, and Hyuk-Jae Lee. A high-throughput and power-efficient fpga implementation of yolo cnn for object detection. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 27(8):1861--1873, 2019.
35 Caiwen Ding, Shuo Wang, Ning Liu, Kaidi Xu, Yanzhi Wang, and Yun Liang. Req-yolo: A resource-aware, efficient quantization framework for object detection on fpgas. In proceedings of the 2019 ACM/SIGDA international symposium on field-programmable gate arrays, pages 33--42, 2019.
36 Patricia Citranegara Kusuma and Benfano Soewito. Multi-object detection using yolov7 object detection algorithm on mobile device. Journal of Applied Engineering and Technological Science (JAETS), 5(1):305--320, 2023.
37 Nico Surantha and Nana Sutisna. Key considerations for real-time object recognition on edge computing devices. Applied Sciences, 15(13):7533, 2025.
38 Kareemah Abdulhaq and Abdussalam Ali Ahmed. Real-time object detection and recognition in embedded systems using open-source computer vision frameworks. Int. J. Electr. Eng. and Sustain., pages 103--118, 2025.
39 Sabir Hossain and Deok-Jin Lee. Deep learning based real-time multiple-object detection and tracking on aerial imagery via a flying robot with gpu-based embedded devices. Sensors, 19(15):3371, 2019.
40 Arief Setyanto, Theopilus Bayu Sasongko, Muhammad Ainul Fikri, and In Kee Kim. Near-edge computing aware object detection: A review. IEEE Access, 12:2989-3011, 2023.
41 Shuo Wang, Chunlong Xia, Feng Lv, and Yifeng Shi. Rt-detrv3: Real-time end-to-end object detection with hierarchical dense positive supervision. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1628-1636. IEEE, 2025.
42 Andrea Bonci, Pangcheng David Cen Cheng, Marina Indri, Giacomo Nabissi, and Fiorella Sibona. Human-robot perception in industrial environments: A survey. Sensors, 21(5):1571, 2021.
43 Ranjan Sapkota and Manoj Karkee. Object detection with multimodal large vision-language models: An in-depth review. Information Fusion, 126:103575, 2026.
44 Peng Tang, Chetan Ramaiah, Yan Wang, Ran Xu, and Caiming Xiong. Proposal learning for semi-supervised object detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2291--2301, 2021.
45 Kihyuk Sohn, Zizhao Zhang, Chun-Liang Li, Han Zhang, Chen-Yu Lee, and Tomas Pfister. A simple semi-supervised learning framework for object detection. arXiv preprint arXiv:2005.04757, 2020.
46 Gabriel Huang, Issam Laradji, David Vazquez, Simon Lacoste-Julien, and Pau Rodriguez. A survey of self-supervised and few-shot object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4071--4089, 2022.
47 Veenu Rani, Syed Tufael Nabi, Munish Kumar, Ajay Mittal, and Krishan Kumar. Self-supervised learning: A succinct review. Archives of Computational Methods in Engineering, 30(4):2761--2775, 2023.
48 Yu-Jhe Li, Xiaoliang Dai, Chih-Yao Ma, Yen-Cheng Liu, Kan Chen, Bichen Wu, Zijian He, Kris Kitani, and Peter Vajda. Cross-domain adaptive teacher for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7581--7590, 2022.
49 Mengde Xu, Zheng Zhang, Han Hu, Jianfeng Wang, Lijuan Wang, Fangyun Wei, Xiang Bai, and Zicheng Liu. End-to-end semi-supervised object detection with soft teacher. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3060-3069, 2021.
50 Peng Mi, Jianghang Lin, Yiyi Zhou, Yunhang Shen, Gen Luo, Xiaoshuai Sun, Liujuan Cao, Rongrong Fu, Qiang Xu, and Rongrong Ji. Active teacher for semi-supervised object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14482--14491, 2022.
51 Gang Li, Xiang Li, Yujie Wang, Yichao Wu, Ding Liang, and Shanshan Zhang. Pseco: Pseudo labeling and consistency training for semi-supervised object detection. In European Conference on Computer Vision, pages 457--472. Springer, 2022.
52 Benjamin Caine, Rebecca Roelofs, Vijay Vasudevan, Jiquan Ngiam, Yuning Chai, Zhifeng Chen, and Jonathon Shlens. Pseudo-labeling for scalable 3d object detection. arXiv preprint arXiv:2103.02093, 2021.
53 Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. IEEE transactions on pattern analysis and machine intelligence, 43(11):4037--4058, 2020.
54 Ming Kang, Chee-Ming Ting, Fung Fung Ting, and Raphael C-W Phan. Asf-yolo: A novel yolo model with attentional scale sequence fusion for cell instance segmentation. Image and Vision Computing, 147:105057, 2024.
55 Ajantha Vijayakumar and Subramaniyaswamy Vairavasundaram. Yolo-based object detection models: A review and its applications. Multimedia Tools and Applications, 83(35):83535--83574, 2024.