继前分享的锂电池数据
精品数据分享 | 锂电池数据集(一)新能源汽车大规模锂离子电池数据集
精品数据分享 | 锂电池数据集(二)Nature子刊论文公开锂离子电池数据
精品数据分享 | 锂电池数据集(三)西安交通大学(XJTU)电池数据集
精品数据分享 | 锂电池数据集(四)PINN+锂离子电池退化稳定性建模和预测
精品数据分享 | 锂电池数据集(五)麻省理工-斯坦福-丰田研究中心电池数据集
本期继续分享一篇 一区TOP 论文:基于深度迁移学习的锂离子电池实时个性化健康状态预测,划重点-数据集开源, 代码开源 !
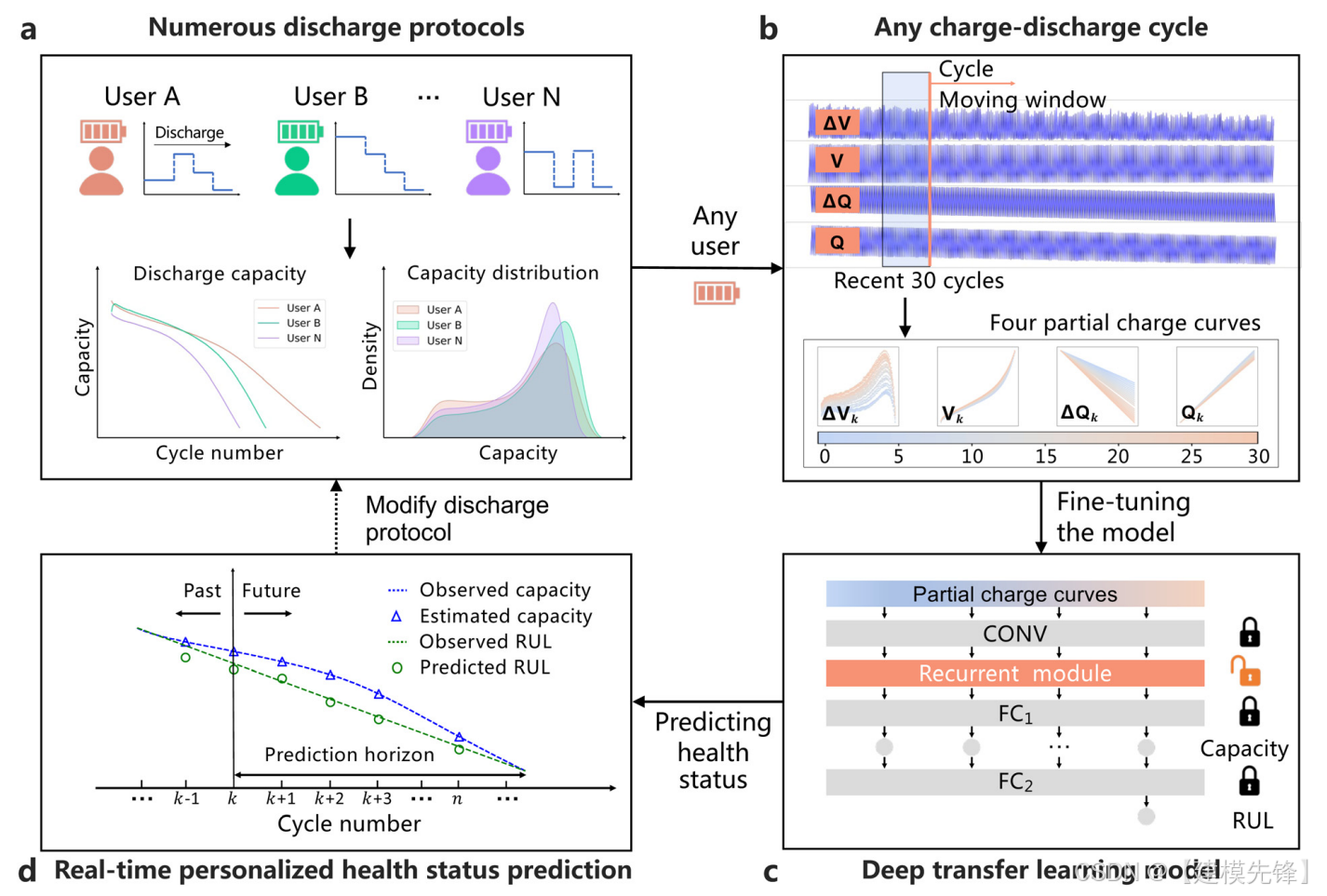
论文题目:《Real-time personalized health status prediction of lithium-ion batteries using deep transfer learning》
论文链接:
https://pubs.rsc.org/en/content/articlelanding/2022/ee/d2ee01676a
数据集链接:
https://data.mendeley.com/datasets/nsc7hnsg4s/2
论文代码:
https://zenodo.org/records/6827566
如果您使用此数据集,请引用作者论文:
Huazhong Artificial Intelligence Lab (HAIL). (2022). HAIRLAB/Health_status_prediction: (v0.0.5). Zenodo. https://doi.org/10.5281/zenodo.6827566
注意:如果下载不了,后台回复"深度迁移",可获取我们已经打包好的论文、数据集和代码!
1 摘要
实时、个性化的锂离子电池健康管理有利于提高终端用户的安全性。然而,由于使用兴趣的多样性、动态的操作模式和有限的历史数据,对电池健康状态的个性化预测仍然具有挑战性。我们生成了一个由超过140000次充放电循环的77个商业电池(77个放电协议)组成的综合数据集,并开发了一个迁移学习框架,以实现在任何充放电循环中对看不见的电池放电协议的实时个性化健康状态预测。该方法在容量估计和剩余使用寿命预测中的平均测试误差分别为0.176%和8.72%。此外,建议的框架可以利用来自另外两个著名的电池数据集的知识,分别具有不同的充电配置和不同的电池化学成分,以可靠地估计我们的电池的容量(0.328%/0.193%)和预测RUL(9.80%/9.90%)。这项研究允许最终用户定制电池消耗计划,并激励制造商改进电池设计。
2 前言
锂离子电池经历了50多年的革命,近年来已成功应用于手机、笔记本电脑、电动汽车等。锂离子电池的充电方案优化已经引起了大量的研究。相比之下,由于人与人之间的使用偏好,锂离子电池的放电方案的研究较少。针对个性化放电协议的电池健康状态(即容量和剩余使用寿命)的实时预测将为最终用户提供安全和预定的使用场景,并加强电池健康管理。此外,电池健康状态预测技术可以进一步促进电池自修复材料的开发和回收技术,并指导下一代电池生产。例如,最终用户可以在高功率放电协议后估计电池的当前健康状态,并根据当前估计制定新的使用计划以延长电池RUL。同样,制造商可以测试电池在经历极端放电后的实时性能,以改进电池的设计。与此同时,回收商可以评估电池的当前健康状况,以确定它们是否最适合再利用(如果是,适用于哪些应用)、再制造或回收。因此,定制个性化的电池健康管理是能源技术领域对最终用户、制造商和回收商的迫切要求。
开发可靠的实时个性化健康状态预测策略面临两个重大挑战:放电方案和实时要求的可变性。首先,由于使用的可变性很高,以及不同的电池化学成分和环境温度,历史数据库中很少存在相同的放电方案和退化模式。因此,如果通过其他历史协议直接预测新放电协议的健康状态,则存在偏差的可能性。以前的研究集中于通过从早期循环电池数据中提取共同的高性能特征来执行一般预测,或者提出使用每个电池至少25%的退化数据的逐例预测。一方面,由于忽略了每个电池的个性化退化模式,使用共同特征的一般预测方法产生了可以想象的预测误差。另一方面,逐例预测方法在数据量和预测精度之间存在矛盾。其次,健康状态预测要求是实时的,这样终端用户就可以持续了解当前的电池健康状况,并可以相应地安排维护或更换。以前的研究主要集中在预测预定周期(S)的电池健康状态,这与实时性要求不匹配。
迁移学习的最新研究目的是通过迁移不同但相关学习者的知识来提高特定学习者的学习成绩。作为迁移学习的一个重要分支,深度迁移学习不需要人工特征工程。深度迁移学习方法已成功地应用于各种应用,如医疗诊断、化学、自然语言处理和智能制造。越来越多的深度迁移学习技术被用于锂离子电池的健康状态预测。然而,这些研究需要至少50%的目标电池的先前退化数据才能从历史数据库中执行曲线匹配,而没有考虑随着电池退化而进行实时预测的必要性。对于广泛的使用模式,仍然存在相当大的机会来填补深度迁移学习和实时个性化健康状态预测之间的空白。
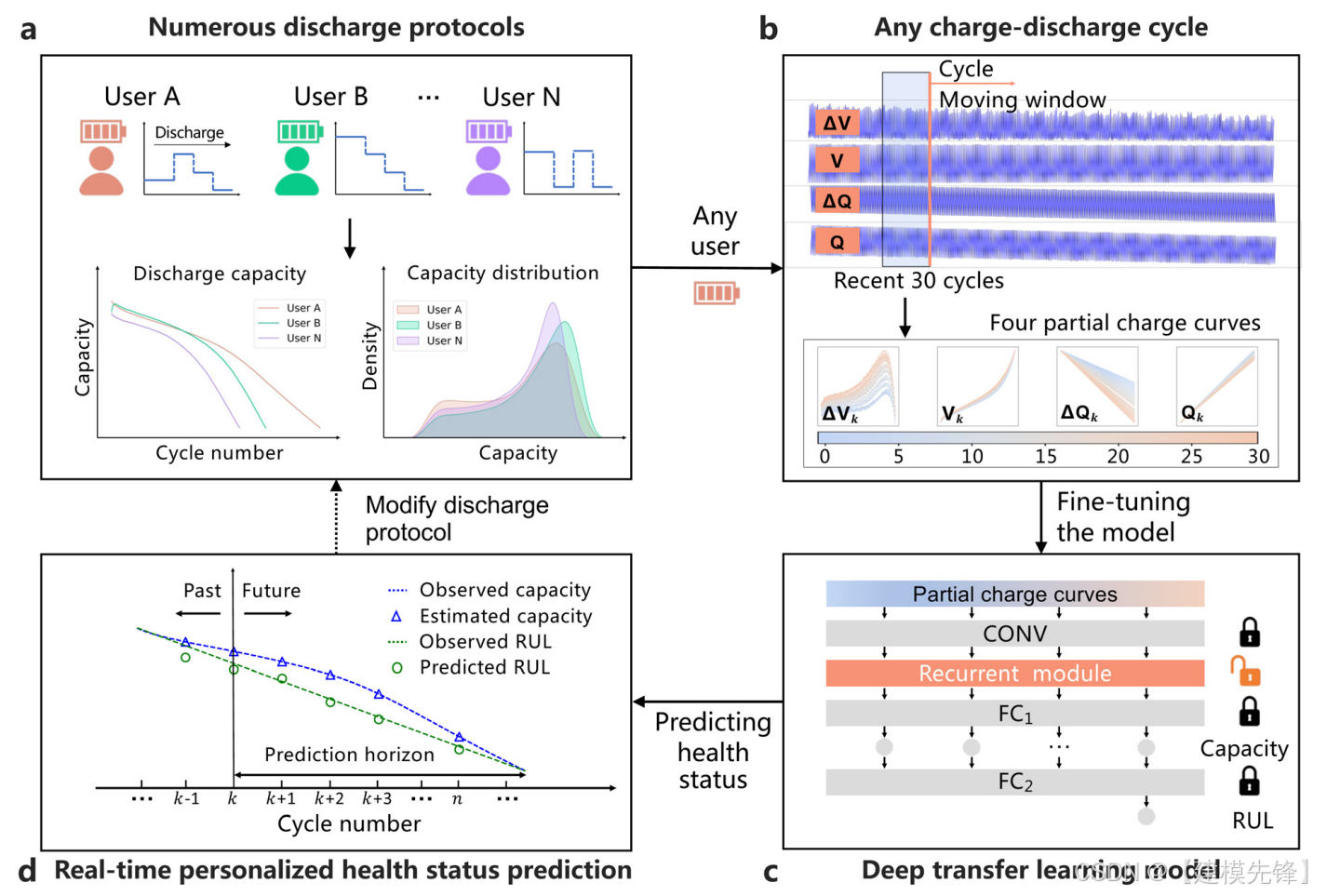 图1
图1
在这项工作中,我们设计了一个可转移的深度网络来实现个性化和实时的锂离子电池健康状态预测,使用最近30个循环在任何感兴趣的周期的部分循环数据(图1)。为此,我们构建了一个包含77个锂离子电池的实验平台,电池的循环寿命从1100到2700次不等。电池经历不同的多级放电方案以近似使用可变性,从而总共获得146122个充放电循环。在所有充放电循环中,容量估计和RUL预测的平均测试误差分别为0.176%和8.72%。此外,我们还执行了另外两项任务,通过从另外两个数据集中转移退化知识来预测数据集中测试电池的健康状态,这两个数据集中分别具有不同的充放电条件和不同的电池化学成分。在接下来的两个任务中,容量估计和RUL预测的平均测试误差分别为0.328%(0.193%)和9.80%(9.9%)。这些结果说明了深度迁移学习框架根据个性化使用模式进行健康状态预测的有效性和泛化能力。
3 实验数据
我们开发了一个电池退化实验(图2)。S1ESI†),具有77个单元(LFP/石墨A123 APR18650M1A,1.1ah额定容量和3.3V额定电压;请参见方法部分的更多详细信息),考虑77种不同的多级放电协议,但具有相同的快速充电协议(图1)。S2和表S1,ESI†)在两个恒温室中)。图2a示出了作为循环次数的函数的放电容量,其中曲线的颜色由电池的循环寿命定标,范围从1100到2700个循环(平均值为1898,标准偏差为387)。该数据集共包含146 122个放电循环,是目前作者所知的考虑各种放电方案的最大数据集。图2B显示了所有77节电池的循环寿命和初始容量的联合分布,其中观察到的循环寿命和初始放电容量的分布都接近正态分布,标准偏差很大,颜色由数量密度进行标度。为便于验证,电池分为两部分:55个训练电池(55个放电方案)和22个测试电池(22个放电方案,见ESI†表S1)。
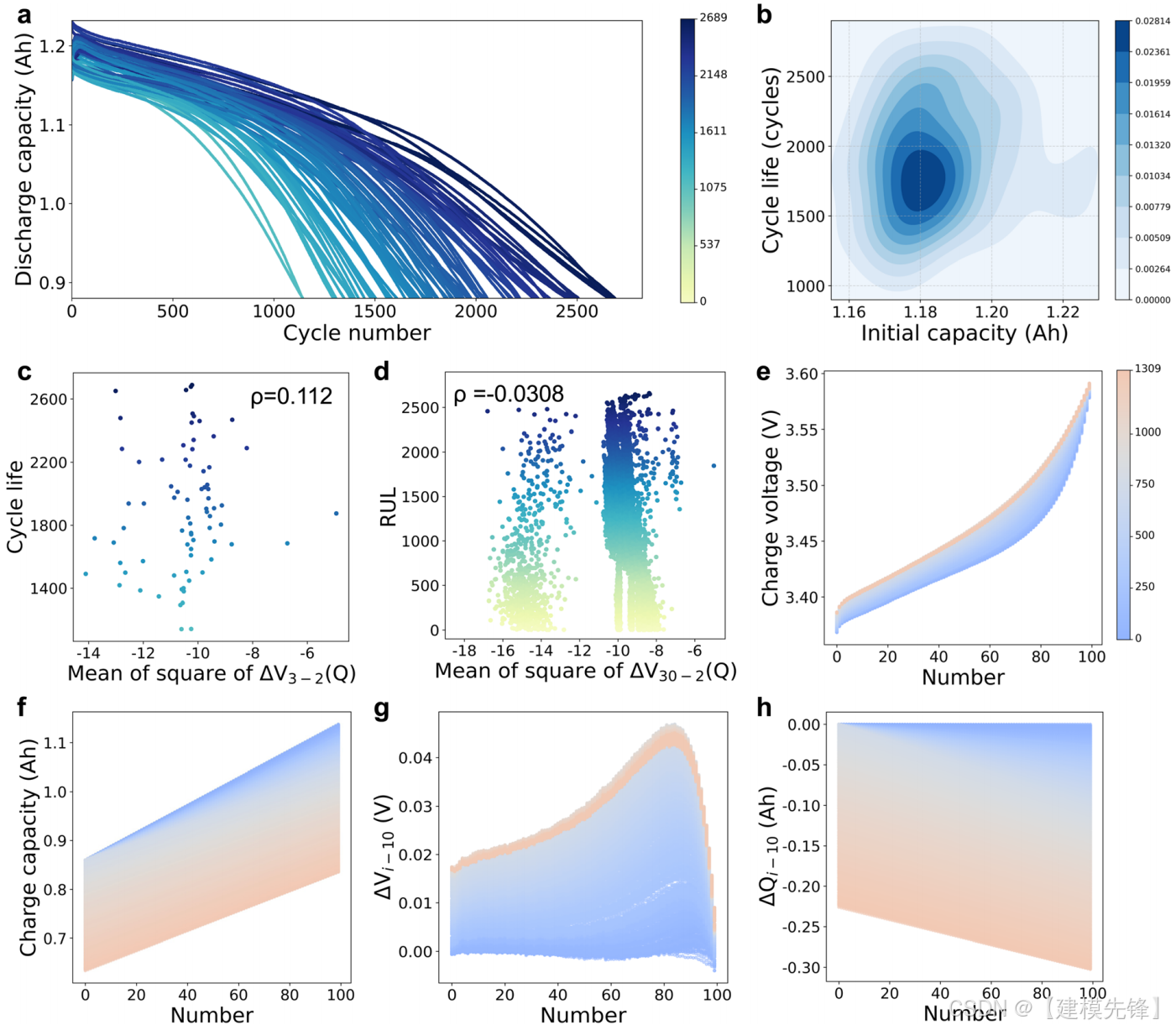
图2
我们还使用了另外两个众所周知的公共数据集,它们包含来自我们的数据集的不同充放电配置、环境温度和电池化学成分。其中,第一个公开数据集包括100多个LFP/石墨单元(见图3)。S3A,esi†用于退化曲线),包括72种不同的充电协议,但相同的放电协议,其重点是我们的数据集中反映的放电以外的电荷变化。Preger等人开发的第二个公共数据集49包含22个锂锰钴氧化物(NMC)/石墨电池(见图2)。S3b,ESI†用于降解曲线),其中NMC/石墨电池在三个环境温度(15 1C、25 1C和35 1C)下使用相同的充电方案进行循环,但使用四种不同的单级放电方案(0.5C、1C、2C和3C)。可以发现,第二个公共数据集和我们的数据集具有不同的电池化学成分、循环环境温度和放电配置。有关这两个公共数据集的更多详细信息,请参阅方法部分。在这项工作中,当训练数据有限时,研究跨场景和跨化学的电池健康状态预测。具体地说,这两个公共数据集用于训练两个深度模型,然后将它们分别应用于我们的测试单元,以进行实时的个性化健康状态预测。
4 深度迁移学习方法
我们开发了一种深度迁移学习方法,通过利用来自其他不同但相关的电池退化数据的知识,执行实时的个性化电池健康状态预测。深度迁移学习模型首先使用训练细胞的多周期感觉数据进行预训练,并将在线传输到任何测试方案的任何充放电周期。我们选择深度迁移学习模型,不需要高性能手工制作的功能,这些功能很难满足所有充放电循环和放电协议。此外,深度迁移学习模型通过动态微调特定的网络层来灵活地快速适应新的工作条件。
为了减少对电池充电范围的依赖,将常用充电范围从80%SOC到前3.6V的部分充电数据作为深度学习模型的输入,该模型可以自动从充电数据中提取有价值的特征,而不需要复杂的特征工程。在充电过程中采用了四条部分特征曲线,即充电电压曲线(V,图2E)、充电容量曲线(Q,图2F)、每个循环与第10个循环之间的充电电压曲线之差(DVI 10=Vi V10,图2G)以及每个循环与第10个循环之间的充电容量曲线之差(Dqi 10=Q10,图2H)。将四条特征曲线作为时间的函数进行拟合,并将其线性内插到固定长度100,以方便模型操作。在四条特征曲线中,Dqi 10的灵感来自于Severson等人,他们证明了一个高性能的特征(DQ100 10(V)的对数方差,即第100次循环和第10次循环的放电容量曲线的差值)与电池循环寿命有很强的相关性(相关系数的绝对值为0.92)。
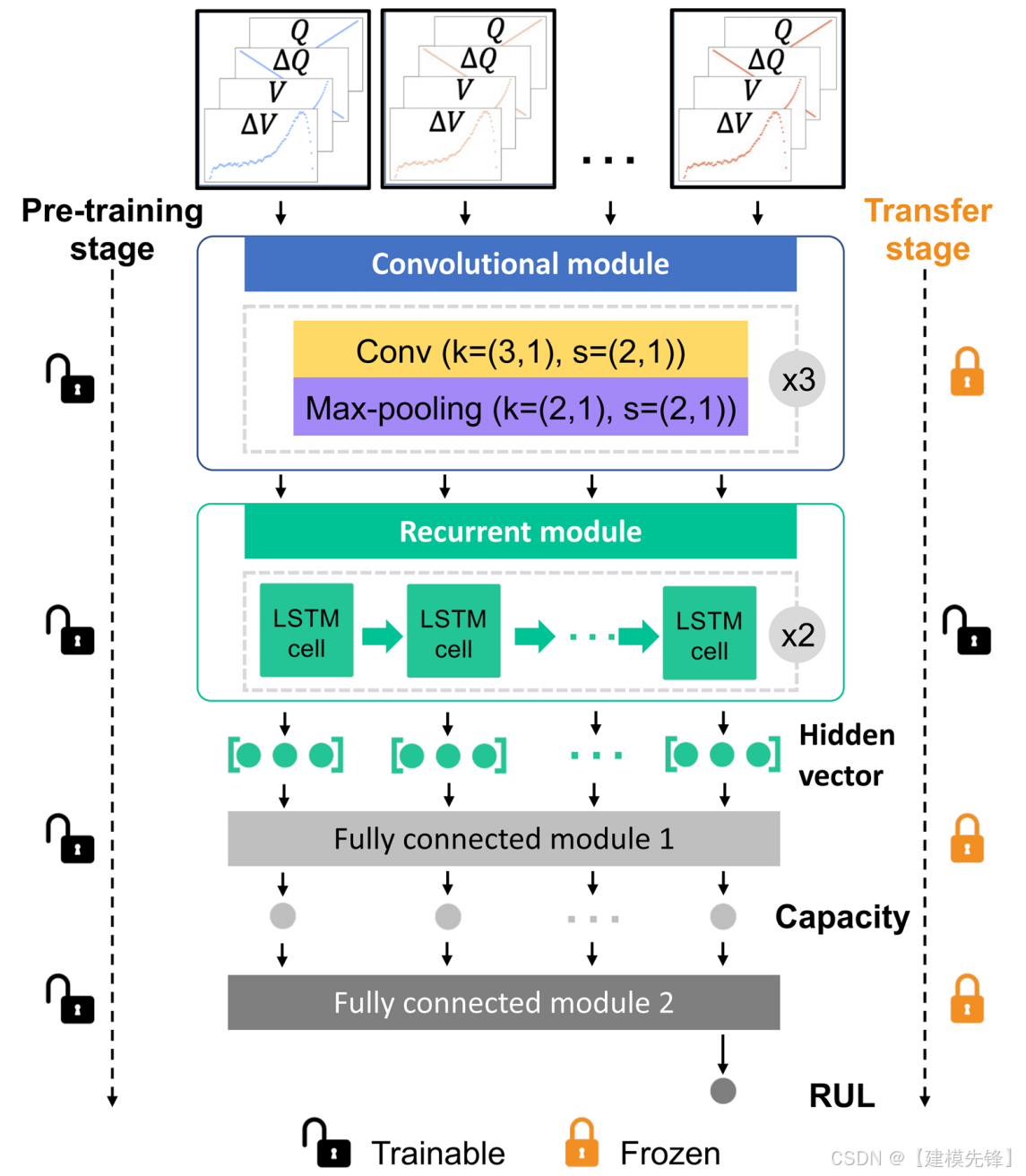
图3
如图3所示,我们设计了一个深度学习模型,该模型由一个卷积模块、一个递归模块和两个全连通模块组成。其中,卷积模块作为特征提取模块,从四条特征曲线中自动提取有价值的周期内特征,递归模块作为编码器进行学习循环到循环的知识。此外,还设计了两个全连接模块,分别用于容量估计和RUL预测。在迁移学习模型中,设计了两个阶段:模型预训练阶段和模型迁移阶段。在模型预训练阶段,使用输入特征曲线对深度学习模型进行预训练,并对每个细胞有数千次充放电循环的训练细胞的健康状态进行标记。然后,模型传递阶段通过输入最近10个充放电周期(重采样后)的特征曲线,实现对任意新放电方案的任意周期的实时个性化健康状态预测。特别是,前9个循环中的输入特性曲线和标记的放电容量被用来通过冻结其他模块来在线微调循环模块(见注S1,ESI†)。然后利用微调模型对当前充放电循环下的容量和RUL分别进行了在线估计和预测。在方法一节中描述了更多的计算细节。利用所提出的深度迁移学习模型,任何具有个性化放电模式的终端用户都可以获得电池健康任何充放电周期的状态,并相应地制定新的使用计划。
基于提出的深度迁移学习方法和三个数据集,我们研究了三个不同的任务,通过转移来自以下三个不同任务的退化知识:(1)训练数据集中具有不同放电协议的55个细胞(表示为任务A);(2)第一个公共数据集中具有不同充放电配置的细胞(表示为任务B);以及(3)第二个公共数据集中具有不同电池化学成分(表示为任务C)的细胞(表示为NMC/石墨)。在所有情况下,22个看不见的放电方案都取自我们的数据集。采用均方根误差(RMSE,见公式(4))、决定系数(R2,见公式(5))和平均绝对百分比误差(MAPE,见公式(6))三个评价指标来评价电池健康状态的预测性能。
5 结果和讨论
5.1 深度迁移学习模型的性能研究
我们首先寻求基于其他终端用户提供的历史数据为每个新的终端用户定制个性化的电池健康状态预测,其中终端用户的电池具有相同的化学成分,但不同的使用协议。为此,我们基于我们的LFP/石墨电池数据集和提出的深度迁移学习方法,研究了放电协议中电池健康状态预测的任务(任务A)。为了对新的放电方案进行任意充放电周期的电池健康状态预测,我们通过调用其他55个测试协议的健康状态知识,分别预测了22个有代表性的测试协议的所有充放电周期的电池健康状态。最后,给出了测试协议的容量估计和RUL预测结果:
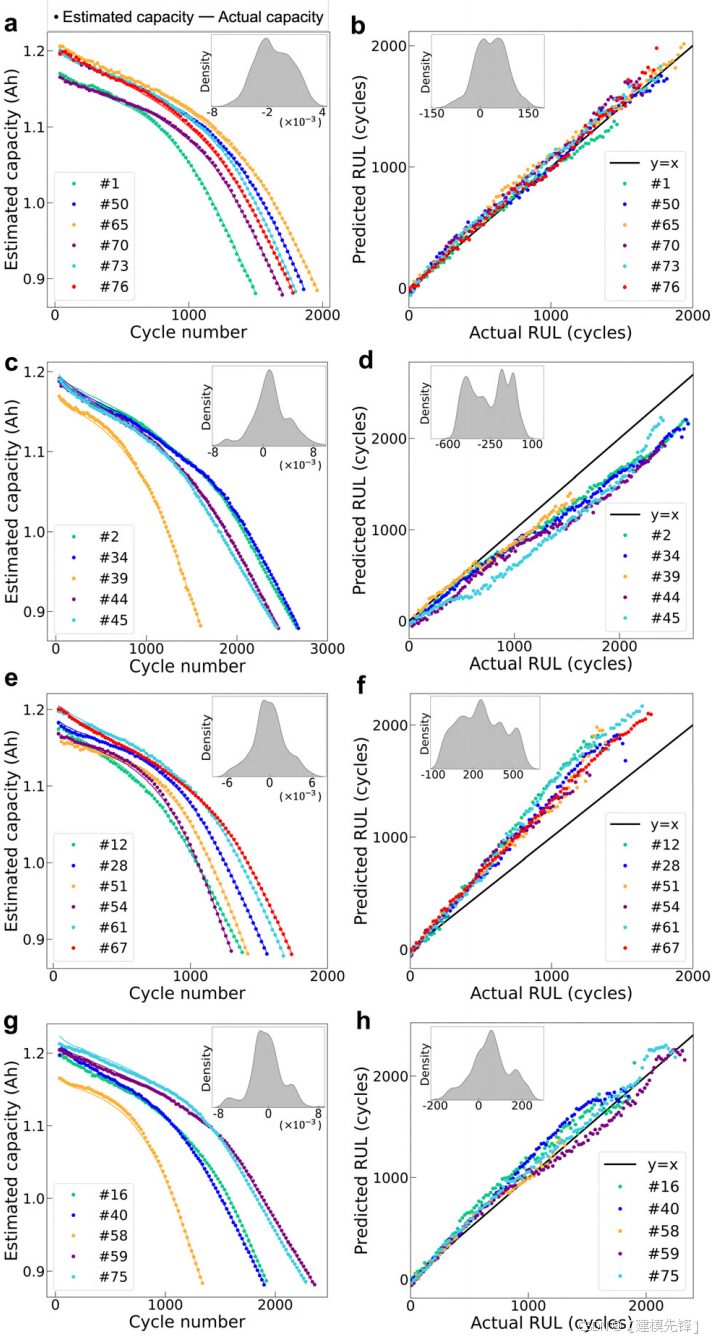
图4
(1) 容量估算。图4的左栏显示了测试协议的估计容量和实际容量与周期数的关系,其中估计容量与每个测试协议的观测容量具有几乎相同的轨迹。更具体地说,我们的模型实现了总体均方根为2.57 mA h,MAPE为0.176%,R2为0.999(参见表1中的任务A),其中大多数相对误差都在4 mA h,4 mA h(图4)的小间隔内,表明我们的模型可以准确地估计每个充放电周期的电池容量。结果还表明,当前充放电循环的电池退化程度与之前的充放电循环高度相关。为了进一步评估模型的性能,我们将提出的模型的估计结果与基准模型,即没有模型迁移阶段的深度学习模型(相同的网络结构图)进行了比较。3),其中容量估计的基准模型的均方根误差为3.24 mA h(表S3和图3)。S6a任务A,ESI†),表明基准模型在容量估计方面也有相当的性能,而所提出的模型中的模型转移阶段可以大幅提高估计精度。
表1
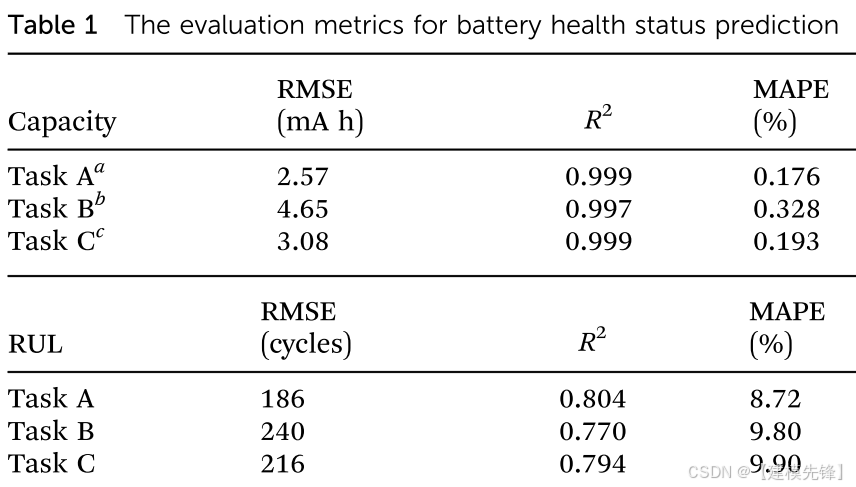
(2)RUL预测。图4中右栏显示了测试协议的预测RUL与实际RUL,其中每个图中打包的协议是根据预测RUL和实际RUL之间的相对误差界来呈现的。不出所料,在电池老化初期,预测误差较大,但随着电池老化的进行,预测误差逐渐减小,这有助于为最终用户提供可靠的RUL,特别是在电池接近故障的情况下,最终用户可以相应地快速修改电池使用计划,以避免安全事故。此外,我们发现,对于循环寿命在平均循环寿命(1898个循环)左右的细胞,预测的RUL与实际RUL(图4B)具有显著的高一致性,这与大部分具有类似循环寿命的训练细胞是一致的。表1(见任务A)显示了RUL预测的评估指标,其中所提出的模型的总体均方根误差为186个周期,MAPE为8.72%,R2为0.804,显示了所提出的模型的有效性。为了对所提出的模型进行基准测试,我们将我们的预测结果与两个基准模型进行了比较,即具有两个周期手工特征的弹性网50(见注S2,esi†)和不具有模型转移阶段的深度学习模型(与图3相同的网络结构),其中两个基准模型分别获得了434个周期和192个周期的均方根误差(参见表S4和图3)。S6B任务A,esi†)。结果表明,所提出的模型明显优于具有双周期手工特征的弹性网络的基准模型,其中双周期手工特征是根据先前的文献6,27开发的用于馈送线性模型的双周期手工特征,在跨越不同放电协议的所有充放电循环中与RUL的相关性较差(图2)。S4和S5,esi†)。相比之下,我们提出的模型从多周期原始循环数据中获取关键知识,不依赖于高性能的手工制作的特征,并且可以很容易地扩展到各种电池使用条件。同时,与没有模型迁移阶段的深度学习模型相比,该模型具有更好的性能,表明模型迁移能够通过使预先训练的深度学习模型适应个性化的电池使用条件来提高RUL预测精度。此外,转移阶段和健康状况预测过程的时间成本分别为1.7%S和2.4103%S。结果表明,在任何充放电循环下,总的预测时间都明显小于放电时间,证明了该方法的实用性。
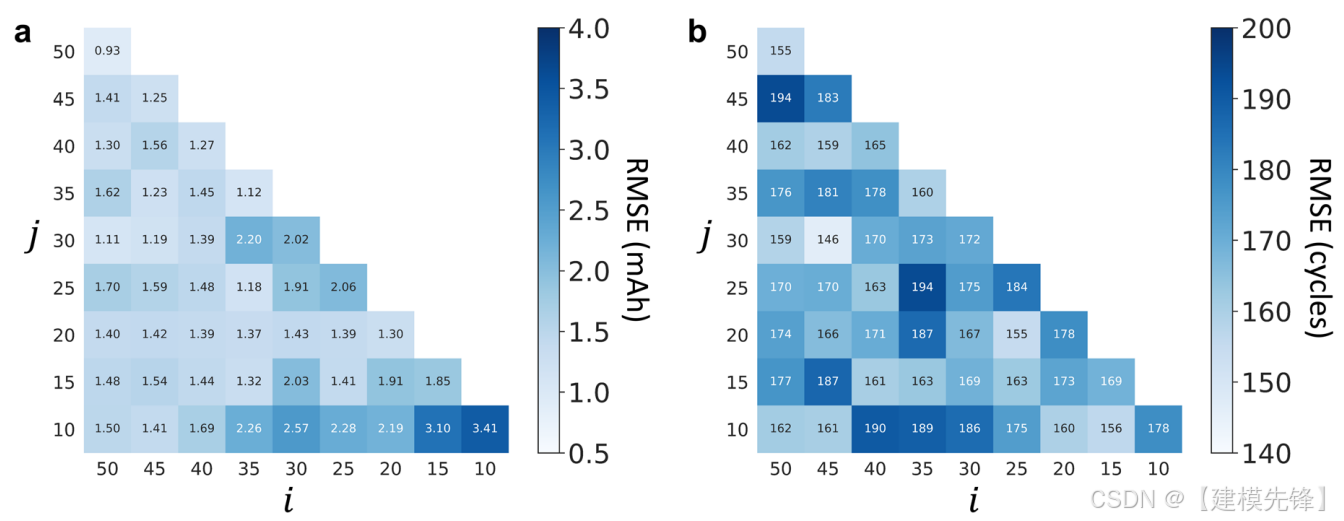
图5
需要注意的是,使用最近30个周期的循环数据和3个周期的采样率,通过考虑较少的输入周期数、较小的计算成本和较小的预测误差来执行健康状态预测。为了研究该模型在不同输入周期数下的可行性和稳健性,我们进行了额外的分析,以比较稀疏采样后不同输入周期数下的测试性能。图5显示了使用不同数量的稀疏输入周期进行容量估计和RUL预测时的预测误差,结果表明,我们在本工作中选择的输入周期数是一般的,但不是最优的,并且所提出的模型在较少的输入周期数下也是可行的(例如,i=20和j=10对于容量估计和RUL预测分别获得2.19 mAh和160个周期的均方根误差模型对输入周期数和采样率不敏感(容量估计平均1.65 mA h,标准差0.50 mA h;RUL预测平均171个周期,标准差11个周期),证明了所提出的深度迁移学习模型的稳健性。
总而言之,上述结果说明了我们的方法对看不见的放电协议的预测能力,展示了为每个最终用户定制个性化电池健康管理的高度灵活性和有效性。
5.2 通过传递来自具有不同充放电配置的电池的退化知识来实现性能
然后,我们试图通过概括训练电池的操作条件来研究为每个最终用户定制个性化电池健康状态预测的可能性。在这种情况下,我们假设数据库没有或很少有其他最终用户提供的训练细胞的历史数据,其中由于过度拟合现象,不足的训练数据无法训练可靠的深度学习模型。51为此,我们在两个不同的数据集之间开发了个性化电池健康状态预测的任务(任务B),包括一个公共数据集27和我们的数据集,这两个数据集具有相同的化学成分(LFP/石墨),但充放电协议不同。具体地说,我们试图通过转移公共数据集中电池的退化知识,分别预测相同22个代表性测试协议在所有充放电周期中的电池健康状态。表1(见任务B)显示了测试协议的评估指标,其中我们的模型在容量估计和RUL预测方面的总体均方根误差为4.65 mA h(240个周期),平均均方误差为0.328%(9.8%),R2为0.997(0.77)。此外,我们将我们的模型的性能与没有模型转移阶段(RMSE分别为85.3 mA h和760个周期的RMSE)的深度学习模型进行了基准比较,以进行容量估计和RUL预测,参见表S5、S6和图3。S6任务B,ESIRUL)和具有双周期手工制作特征的弹性网络(用于RUL预测的607周期的均方根误差,参见表S6和图†。S6B任务B,ESI†),表明我们的方法的性能明显优于基准模型,模型转移阶段能够大幅提高预测精度。值得注意的是,与任务A相比,我们模型的预测误差略高,这归因于两个数据集之间的充放电配置和电池测试平台非常不同。然而,我们的模型仍然获得了令人满意的结果(图3)。S7-S10,esi†)用于个性化电池健康状态预测,即使训练单元和测试单元来自跨场景数据集。上述结果进一步强调了我们的方法用于个性化电池健康状态预测的能力。
5.3 通过传递来自不同化学 成分的细胞的知识来实现性能
我们进一步询问,我们的模型是否能够基于训练具有不同电池化学成分的电池来为每个最终用户定制个性化的电池健康状态预测。为此,我们通过转移另一个公共数据集中NMC/石墨电池的降解知识,为我们数据集中的LFP/石墨电池设计了一个个性化健康状态预测任务(任务C)。49值得注意的是,NMC/石墨数据集和我们的LFP/石墨数据集的标称容量、标称电压、环境温度和充放电配置不同,导致电池退化轨迹显著不同,其中LFP/石墨电池和NMC/石墨电池的老化速度分别增加和降低(见图2A和图2)。S3b,esi†)。尽管跨化学健康状况预测任务似乎具有挑战性,但我们的模型在容量估计和RUL预测方面分别实现了3.08 mA h(216个周期)、0.193%(9.9%)和0.999(0.794)的总体均方根误差(RMSE)(参见图1)。S11-S14,esi†)。此外,我们的方法也显著优于基准模型,即没有模型转移阶段的深度学习模型(容量估计和RUL预测的均方根误差分别为92.4 mA h和832个周期,参见表S7和表S8和图3)。S6任务C,ESIRUL)和具有两个周期手工制作特征的弹性网络(749个周期的均方根误差用于RUL预测,参见表S8和图)。S6B任务C,esi†),从而突出了所提出的方法用于跨化学电池健康状态预测任务的可行性。此外,该任务的预测误差略高于任务A,这表明我们的方法不受电池化学物质的严重限制。上述结果进一步证明了深度迁移学习方法的有效性和普适性,即使在具有挑战性的跨化学条件下也是如此。
值得一提的是,模型传递阶段对循环模块进行微调,以适应个性化的电池使用条件。一个看似自然的问题是,我们是否可以在模型转移阶段微调卷积模块。为了进一步评估我们提出的传输策略,我们在模型传输阶段通过微调卷积模块而不是递归模块来研究个性化电池健康状态预测的性能(参见表S9,esi†)。这三个任务的结果一致地表明,微调卷积模块在容量估计和RUL预测方面都会导致性能下降,表明循环间知识与电池健康状态密切相关,并且递归模块在微调模型后可以有效地学习新的循环间知识。
上述结果表明了所提出的方法用于LFP/石墨电池的能力。除了LFP/石墨电池,我们的方法还可以应用于NMC/石墨电池。49为此,我们通过分别从NMC/石墨电池和LFP/石墨电池传递降解知识,进行了两个额外的实验,用于NMC/石墨电池的个性化健康状态预测。一方面,我们使用交叉验证策略对NMC/石墨电池的四种放电方案(0.5C、1C、2C和3C的恒流放电率)的健康状态进行预测,其中一个方案用于验证,另外三个方案用于每次预训练深度模型。我们实现了12.7 mA h的总体RMSE和98个周期分别用于容量估计和RUL预测(图2)。S15,esi†)。另一方面,我们还通过传递来自我们数据集中55个训练LFP/石墨电池的降解知识来预测相同四种放电方案的NMC/石墨电池的健康状态。容量估计和RUL预测的总均方根误差分别为19.38 mA/h和103个循环(图2)。S16,esi†)。结果进一步显示了我们的方法对NMC/石墨化学而不是LFP/石墨化学的个性化电池健康状态预测的有效性。
6 结论
总之,我们使用开发的深度迁移学习方法成功地为每个放电协议定制了个性化的电池健康状态预测。这种方法使用来自具有完全不同的使用方案、充放电配置和电池化学的电池的循环知识,在各种未见的使用方案上实现了令人满意的有效性、通用性和灵活性。使用该方法,电池管理系统可以快速适应新的运行条件并预测每个使用偏好的电池健康状态,从而最终用户可以立即采取行动确保安全或制定新的使用计划来延长电池的RUL。这种方法可以扩展到其他放电场景,如恒流放电和随机放电,以及快速充电场景,如多步充电、脉冲充电和恒功率充电。此外,拟议的办法还可以扩展到准固态电池、固态电池和后锂离子电池(例如,锂硫电池、钠离子电池等)。
虽然该方法在这项工作中取得了令人满意的效果,但仍存在一些局限性。首先,当固定电荷范围内的循环数据可用时,该方法有效,但没有研究接近实际应用的随机电荷过程(随机电荷范围)。然后,该方法需要最近30个周期来预测细胞的健康状态,结果是前几个周期的健康状态无法预测。此外,我们的方法依赖于最近几个周期的周期数据的质量,其中一些奇异的测量数据肯定会影响预测结果。此外,我们的工作简化了实际应用中的操作条件,在实际应用中,我们的数据集中没有包括更实际的操作场景,如不同的温度、放电深度和放电功率,因此仍需进一步研究。然而,这种方法在各种使用场景中获得了相当大的普适性,并有可能扩展到实际应用中。
7 代码、数据整理如下:
点击下方卡片获取代码!