什么?部署大模型要多少显存你都不知道?

引言:
虽然大模型出来有段时间了,但是依然有很多的开发者不知道如何下手去部署一个自己的本地模型,
甚至不知道,自己本地的资源适合部署什么模型 ,什么模型需要多少资源。今天我们就来讲讲这个常规的基础问题。
作者 : 吴佳浩
最后更新: 2025-12-6
一个常见的误区:
很多人在部署大语言模型时,会有这样的直觉认知:
"我下载的模型文件是 19GB,那我需要 20GB 显存就够了吧?"
错! 这是一个看似合理但实际上会让你踩坑的理解。本文将深入剖析大模型部署时的显存占用机制,帮助你准确估算所需硬件资源。
第一部分:显存占用的完整图景
1.1 显存都被谁占用了?
当你运行一个大语言模型时,显存不仅仅存储模型权重,还包含多个关键组件:
1.2 核心公式推导
基础公式(无上下文)
bash
显存需求 = 模型文件大小 × 1.2 + 框架开销(1-2 GB)这里的 1.2 倍系数 来自:
- CUDA 框架初始化开销(5-10%)
- 推理时临时张量缓存(5-10%)
- 内存对齐和碎片(5-10%)
完整公式(考虑上下文)
bash
显存需求 = 模型文件大小 × 1.2 + KV Cache + 预留缓冲(3-5 GB)第二部分:量化技术的影响
2.1 量化精度与文件大小
2.2 量化后的显存占用实测
以 Qwen3-Coder-30B 为例(实际测试数据):
| 量化方式 | 模型文件大小 | 基础显存占用 | 加载后实际占用 | 差值 |
|---|---|---|---|---|
| FP16 | 61 GB | 61 GB | 65-68 GB | +4-7 GB |
| Q8_0 | 32 GB | 32 GB | 35-37 GB | +3-5 GB |
| Q5_K_M | 24 GB | 24 GB | 27-29 GB | +3-5 GB |
| Q4_K_M | 19 GB | 19 GB | 22-24 GB | +3-5 GB |
观察规律 : 无论哪种量化方式,实际显存都会比文件大小多出 3-7 GB
第三部分:KV Cache ------ 隐形的显存杀手
3.1 什么是 KV Cache?
在 Transformer 架构中,注意力机制需要存储每个 token 的 Key 和 Value 向量,这些缓存随上下文长度线性增长。
KV Cache 计算公式:
bash
KV Cache(GB) ≈ 2 × 层数 × 隐藏层维度 × 序列长度 × 每参数字节数 / 10^9以 Qwen3-30B 为例(48 层,4096 隐藏维度,FP16):
bash
KV Cache = 2 × 48 × 4096 × seq_len × 2 / 10^9
≈ 0.0008 × seq_len GB3.2 上下文长度的惊人影响
3.3 实测案例对比
场景 1: 日常对话(4K 上下文)
bash
# RTX 4090 (24GB) 运行 Qwen3-30B Q4_K_M
输入: "写一个 Python 排序算法"
上下文长度: ~500 tokens
显存占用: 21 GB
结论: 完全 OK场景 2: 长代码文件(64K 上下文)
bash
# 同样的显卡和模型
输入: 粘贴一个 5000 行的 JavaScript 项目
上下文长度: ~40K tokens
显存占用: 28 GB
结论: OOM 崩溃!第四部分:实用显存估算方法
4.1 三步快速估算法
4.2 不同场景的显存需求表
| 使用场景 | 模型量化 | 模型大小 | 安全显存配置 | 推荐显卡 |
|---|---|---|---|---|
| 轻量对话 | Q4_K_M | 7B | 8 GB | RTX 3060 12GB |
| 代码补全 | Q4_K_M | 14B | 14 GB | RTX 4060 Ti 16GB |
| 通用助手 | Q5_K_M | 30B | 32 GB | RTX 4090 24GB × 2 |
| 长文档分析 | Q4_K_M | 30B | 40 GB | A100 40GB |
| 超长上下文 | FP16 | 30B | 80+ GB | A100 80GB |
第五部分:真实部署案例分析
案例 1: RTX 4090 的极限挑战
硬件 : RTX 4090 (24GB VRAM) 目标: 运行 Qwen3-Coder-30B
方案 A: Q4_K_M 量化(失败)
bash
模型文件: 19 GB
基础占用: 19 × 1.2 = 22.8 GB
预留缓冲: 3 GB
总需求: 25.8 GB
结果: 短对话 OK,长代码 OOM方案 B: 降至 14B 模型(成功)
bash
模型文件: Qwen3-Coder-14B Q4_K_M = 8.5 GB
基础占用: 8.5 × 1.2 = 10.2 GB
预留缓冲: 5 GB
总需求: 15.2 GB
结果: 32K 上下文流畅运行案例 2: 多卡部署策略
硬件 : 2 × RTX 3090 (24GB × 2 = 48GB) 目标: 运行 Llama 3.1 70B
问题点深度解析
上图中虽然表面上看起来可行,但实际上仍然会 OOM。根本原因有三个:
原因 1: 张量并行需要复制部分模型结构
Tensor Parallelism(张量并行)会将权重分片到各卡,但许多 LayerNorm、Embedding、Router、Position Encoding 等模块无法完全切分,会在各卡上重复存在。
结果: 每张卡会多占 1-2 GB。
原因 2: KV Cache 不是均分,而是每张卡都要维护一份
Attention 的 KV Cache 和上下文有关,而不是模型权重。多卡推理时每张 GPU 都要维护完整 KV Cache。
也就是说:
- 你不是把 KV Cache 分到不同卡
- 而是每张卡都要占用 5GB
原因 3: 显存碎片化与 CUDA allocator 开销(1-3 GB)
llama.cpp、vLLM、TransformerEngine 都有自己的显存池化策略,会产生 5-10% 开销。当显存占用到 90% 以上时,碎片化会导致直接 OOM。
实际显存占用分析
| 项目 | 每张 GPU 实际占用 |
|---|---|
| Q4_K_M 权重分片 | 约 21 GB |
| 重复权重/结构 | +1.5 GB |
| KV Cache(32K) | +5 GB |
| 框架/allocator | +1.5 GB |
| 合计 | 约 29 GB |
结论: 你只有 24GB,所以必定 OOM。
正确解决方案
要运行 70B 模型,多卡只是一部分,你还需要:
方案 A: 使用 4 卡(推荐)
bash
4 × 24GB = 96GB 总显存Tensor Parallelism 切分更细:
| 项目 | 显存占用 |
|---|---|
| 权重分片 | 10-11 GB |
| 重复结构 | 1 GB |
| KV Cache | 5 GB |
| 框架开销 | 1 GB |
| 总计 | 约 18GB(完全够) |
结论: 4 卡 3090 可以运行 70B(Q4_K_M),独立显卡党最低门槛: 4 × 24GB
方案 B: 使用 2 × A100 40GB
- 70B FP16 肯定不行
- Q4_K_M 权重 42GB,每卡分到 21GB
- 40GB 显存足够容纳 KV Cache + 框架开销
结论: 两张 A100 40GB 能运行 70B(Q4_K_M)
方案 C(错误): 2 × RTX 4090(24GB × 2)
和 3090 相同显存,无法解决 KV Cache 重复问题:
bash
21GB(权重分片) + 5GB(KV) + 1.5GB(重复结构) + 1.5GB(allocator)
≈ 29GB > 24GB → OOM结论: 双卡 24GB 系统永远无法运行 70B 大模型(超过 30K 上下文)。
第六部分:显存需求终极参考表
6.1 单卡显存部署极限
| 模型大小 | Q4_K_M 占用 | 能否单卡部署? | 推荐显卡 |
|---|---|---|---|
| 7B | 约 4GB | 完全可以 | 8GB+(3060/4060) |
| 14B | 约 8.5GB | 完全可以 | 16GB(4060Ti/4070) |
| 30B | 约 19GB | 勉强可以 | 24GB(4090/5090) |
| 33B | 约 21GB | 较困难 | 24GB(4090/5090) |
| 70B | 约 42GB | 必须多卡 | 必须多卡或 A100 |
6.2 多卡运行 70B 的显存要求
| GPU 组合 | Q4_K_M(42GB) | 能否运行? | 原因 |
|---|---|---|---|
| 2 × 24GB | 理论 48GB | 不够 | KV Cache 重复占用 |
| 2 × 48GB(A6000) | 理论 96GB | 足够 | 每卡 26-29GB |
| 2 × 40GB(A100) | 理论 80GB | 足够 | 每卡 25-27GB |
| 4 × 24GB | 理论 96GB | 足够 | 切分更细,每卡约 18GB |
6.3 不同上下文长度的显存规划
| 上下文长度 | 30B 模型(Q4) | 70B 模型(Q4) | 推荐配置 |
|---|---|---|---|
| 4K | 22 GB | 需多卡 | 单卡 24GB / 多卡 |
| 32K | 28 GB | 需多卡 | 单卡 32GB / 多卡 40GB |
| 128K | 45+ GB | 需多卡 | A100 40GB+ |
| 256K | 70+ GB | 需多卡 | A100 80GB / H100 |
第七部分:本文终极总结
部署大模型显存需求,你必须记住这 5 条
1. 显存不等于模型文件大小,永远要乘 1.2-1.3
模型文件 19GB,不等于显存 19GB。
原因:
- CUDA 运行时开销
- 临时张量
- Memory alignment
- 框架开销
2. KV Cache 是大模型 OOM 的最大元凶
上下文长度越大,显存爆炸越快:
| 上下文 | KV Cache |
|---|---|
| 4K | 0.8 GB |
| 32K | 6 GB |
| 128K | 25 GB |
| 256K | 50 GB |
3. 单卡 24GB 的极限就是 30B(量化)
30B 是独显党的天花板,这是非常现实的限制。
4. 70B 模型永远需要至少 2 卡(40GB+)或 4 卡(24GB+)
否则 KV Cache 会导致 OOM。
5. 想跑长上下文(大于 128K),必须使用 A100 / H100
消费级显卡连 64K 上下文都吃力。
第八部分:优化技巧与最佳实践
8.1 降低显存占用的五大技巧
-
选择合适的量化方式
bash精度要求不高 → Q4_K_M(最省显存) 需要高精度 → Q5_K_M 或 Q8_0 研究用途 → FP16(完整精度) -
动态 KV Cache 管理
- 使用 PagedAttention(vLLM)
- Sliding Window Attention(只保留最近 N 个 tokens)
- 分块处理长文档
-
批处理大小控制
python# 单次推理 batch_size = 1 # 显存占用最小 # 批量推理 batch_size = 4 # 显存占用 × 4,但吞吐量 × 3.5 -
Offloading 策略
bash模型层分配: - GPU: 前 30 层(高频计算) - CPU: 后 18 层(低频计算) 显存节省: 30-40% 速度损失: 15-25% -
使用专业推理框架
- vLLM: 最佳吞吐量,支持 PagedAttention
- llama.cpp: 最低显存占用,支持 CPU offload
- TensorRT-LLM: 最快推理速度(NVIDIA 优化)
8.2 显存不足时的应急方案
第九部分:常见问题 FAQ
Q1: 为什么我的显存占用比预期高?
可能原因:
- 推理框架预分配了额外缓冲区
- 多个进程同时使用 GPU
- 显存碎片化(长时间运行后)
解决方法:
bash
# 查看实际占用
nvidia-smi
# 清理 GPU 缓存(PyTorch)
torch.cuda.empty_cache()
# 限制框架最大显存使用
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:512Q2: INT4 量化会损失多少精度?
实测对比(C-Eval 基准):
| 模型 | FP16 | Q8_0 | Q5_K_M | Q4_K_M |
|---|---|---|---|---|
| Qwen-7B | 62.3% | 62.1% | 61.8% | 60.9% |
| Llama-13B | 51.2% | 51.0% | 50.5% | 49.2% |
结论: Q4_K_M 对中文模型影响 < 2%,英文模型 < 3%
Q3: 如何监控实时显存占用?
工具推荐:
bash
# 方法1: nvidia-smi 实时监控
watch -n 1 nvidia-smi
# 方法2: nvtop(更友好的界面)
sudo apt install nvtop
nvtop
# 方法3: Python 脚本
import torch
print(f"已用: {torch.cuda.memory_allocated()/1e9:.2f} GB")
print(f"预留: {torch.cuda.memory_reserved()/1e9:.2f} GB")最终结论:显存估算的黄金法则
记住这三个关键点
- 基础需求: 模型文件大小 × 1.2
- 上下文影响: 长文档场景 +8-30 GB
- 安全余量: 总是预留 20% 以上缓冲
最终公式
bash
所需显存 = 模型大小 × 1.2 + KV Cache(上下文相关) + 3-5 GB 余量选型建议
现在,当有人问你"部署大模型需要多少显存"时,你就可以自信地回答了!
GPU显存计算器
如果你不想动脑筋去算 ,去找需要用什么样的设备,巧了刚好我做了一个大模型GPU计算器 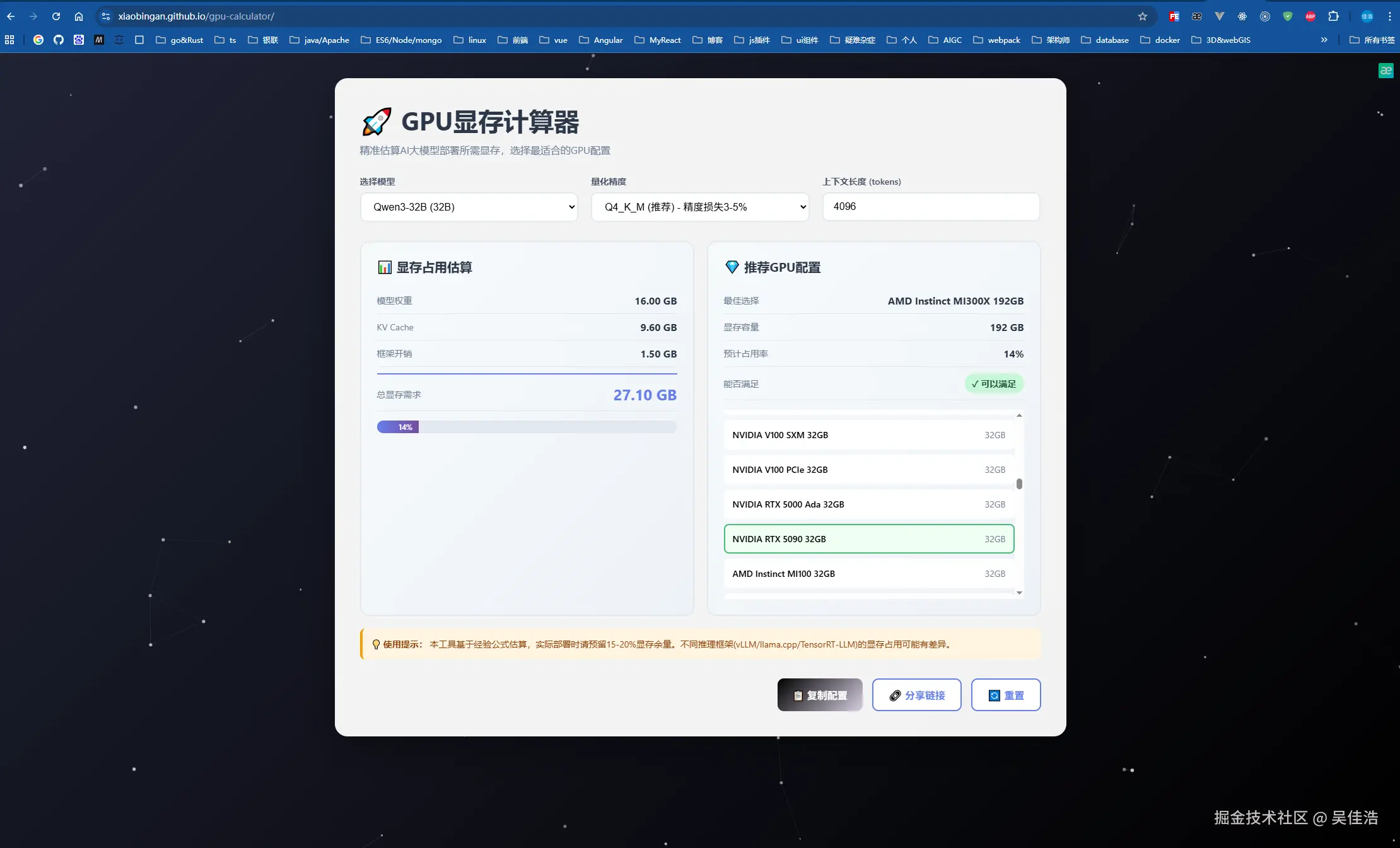
点击这里试试看你的设备能部署多大的模型吧👉👉👉GPU显存计算器
参考资源: