数据库介绍
数据库定义
数据库是建立在文件系统之上的电子化数据仓库,提供了高效的数据组织、存储和管理方案。与传统文件存储相比,数据库能实现数据的快速检索、多用户共享和数据一致性维护,是各类应用程序(如网站、管理系统、APP)不可或缺的底层支撑。
关系型数据库特点
关系型数据库基于关系模型构建,核心是存储实体与实体之间的关联关系(如用户与订单、部门与员工),采用二维表格结构组织数据,数据完整性和一致性有完善的保障机制,是目前应用最广泛的数据库类型。
主流数据库对比

MySQL 环境配置与基础操作
(一)核心配置文件
MySQL 安装目录下的my.ini文件是关键配置文件,其中:
basedir:指定 MySQL 安装路径;datadir:指定数据文件的存储位置,直接影响数据读写性能。
(二)MySQL 服务连接与验证
- 登录测试 :打开 CMD 窗口,切换至 MySQL 的 bin 目录,输入命令**
mysql -u root -p**,回车后输入密码即可登录 MySQL 服务器。 - 版本与用户验证:登录后可通过以下命令确认环境信息:
sql
-- 查看MySQL版本
select version();
-- 查看当前登录用户
select user();(三)密码修改流程
当需要重置 root 密码时,按以下步骤操作:
-
通过
services.msc打开服务窗口,停止 MySQL 服务; -
在 CMD 中执行
mysqld --skip-grant-tables,启动免认证的 MySQL 服务; -
新打开 CMD 窗口,输入
mysql -u root -p,无需密码直接登录; -
执行以下命令修改密码:
sql-- 切换至mysql系统数据库 use mysql; -- 更新root用户密码(此处密码设为root,可自定义) update user set authentication_string=password('root') WHERE user='root'; -
关闭所有 CMD 窗口,在任务管理器中结束
mysqld进程,重启 MySQL 服务即可生效。
(四)数据库备份与恢复
1. 数据备份
通过mysqldump工具备份指定数据库的所有数据,命令格式如下(需在 CMD 环境执行,非 MySQL 登录状态):
mysqldump -u 用户名 -p 数据库名 > 备份文件名.sql
执行后输入密码,即可将数据库数据导出为 SQL 脚本文件。
2. 数据恢复
恢复数据前需先创建空数据库并切换至该数据库,恢复命令如下:
mysql -u 用户名 -p 数据库名 < 备份文件名.sql
注意事项:
- 命令需在 CMD 环境执行,无需登录 MySQL;
- 备份与恢复命令中
>和<方向不可混淆; - 恢复时确保目标数据库已创建,且与备份数据的表结构兼容。
SQL 语言介绍
(一)SQL 语言特性
SQL(结构化查询语言)是一种非过程性编程语言,核心特点是每条语句独立执行并返回结果,无需依赖其他语句的执行顺序。与 Oracle 专属的 PL/SQL(过程性语言)不同,SQL 具有跨数据库通用性,是操作关系型数据库的标准语言。
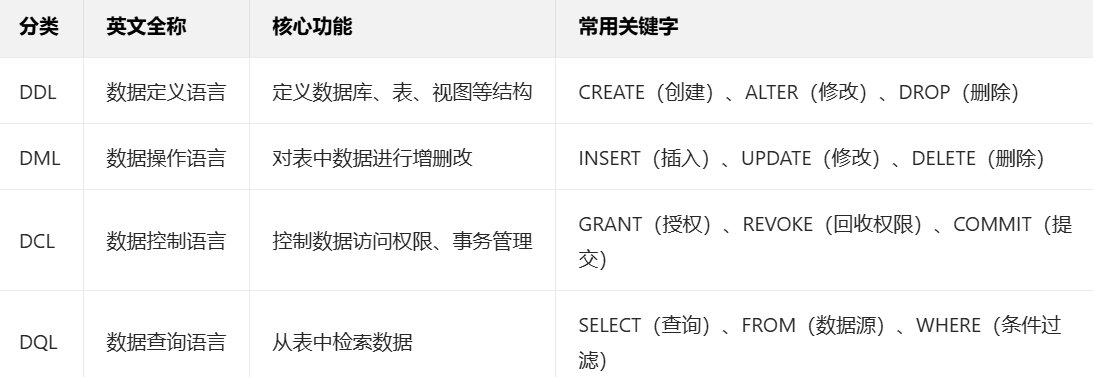
(二)SQL 语言分类
SQL 按功能可分为四大类,涵盖数据库操作的全流程:
数据库核心操作(CURD)
(一)数据库级操作
MySQL 服务器中可包含多个数据库,每个数据库独立存储表结构与数据,核心操作如下:
1. 创建数据库
- 基础语法:
create database 数据库名称; - 指定字符集与排序规则(推荐 utf8/utf8mb4):
create database 数据库名称 character set utf8 collate utf8_general_ci;
2. 查看与切换数据库
sql
-- 查看所有数据库
show databases;
-- 切换至指定数据库(后续操作针对该数据库)
use 数据库名称;
-- 查看当前使用的数据库
select database();
-- 查看数据库创建语句(含字符集等配置)
show create database 数据库名称;3. 修改与删除数据库
sql
-- 修改数据库字符集
alter database 数据库名称 character set 'gbk' collate 'gbk_chinese_ci';
-- 删除数据库(谨慎操作,数据不可恢复)
drop database 数据库名称;(二)表结构操作
表是数据库存储数据的基本单元,由字段(列)和数据(行)组成,字段需指定数据类型与约束条件。
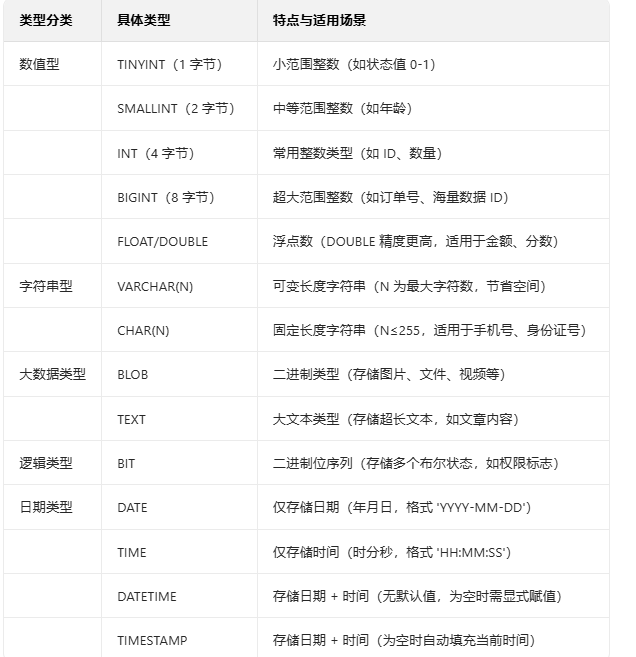
1. 数据类型详解
MySQL 支持多种数据类型,适配不同场景的数据存储需求:
2. 表约束(保证数据完整性)
约束是对字段的规则限制,常见约束如下:
- 主键约束(primary key):唯一标识表中每条记录,非空且唯一,一个表仅能有一个主键;
- 唯一约束(unique):字段值唯一,允许为空;
- 非空约束(not null):字段必须填写数据,不可为空。
3. 表结构核心操作
sql
-- 1. 创建表(示例:创建学生表stu)
create table stu(
id int primary key, -- 主键ID
name varchar(30) not null, -- 学生姓名(非空)
math int, -- 数学成绩
english int, -- 英语成绩
chinese int, -- 语文成绩
create_time datetime -- 创建时间
);
-- 2. 查看表结构
desc 表名;
-- 查看表创建语句
show create table 表名;
-- 查看当前数据库所有表
show tables;
-- 3. 修改表结构
alter table 表名 add 新字段 类型(长度) 约束; -- 添加字段
alter table 表名 drop 字段名; -- 删除字段
alter table 表名 modify 字段名 新类型(长度) 新约束; -- 修改字段类型/约束
alter table 表名 change 旧字段名 新字段名 类型(长度) 约束; -- 修改字段名
rename table 表名 to 新表名; -- 修改表名
alter table 表名 character set utf8; -- 修改表字符集
-- 4. 删除表(谨慎操作)
drop table 表名;(三)数据操作(增删改查)
1. 插入数据(INSERT)
sql
-- 指定字段插入(推荐,顺序可自定义)
insert into stu (id, name, math, english, chinese) values (1, '聪聪', 95, 92, 98);
-- 全字段插入(需按表字段顺序赋值)
insert into stu values (2, '明明', 88, 85, 90, '2025-09-13 10:00:00');注意:字符串和日期类型数据需用单引号包裹,数据类型需与字段类型一致。
2. 修改数据(UPDATE)
sql
-- 修改符合条件的记录(推荐添加WHERE条件)
update stu set math=90, english=88 where name='明明';
-- 无WHERE条件时,将修改表中所有记录(谨慎使用)
update stu set create_time='2025-09-13 10:00:00';3. 删除数据(DELETE)
sql
-- 删除符合条件的记录
delete from stu where id=2;
-- 删除表中所有数据(保留表结构)
delete from stu;
-- 清空表数据(先删表再重建,效率更高,不可恢复)
truncate table stu;对比说明:
- DELETE:逐行删除,支持 WHERE 条件,可通过事务回滚恢复数据;
- TRUNCATE:直接重建表结构,不记录日志,效率高于 DELETE,数据不可恢复;
- DROP TABLE:删除表结构及所有数据,完全不可恢复。
4. 查询数据(SELECT)
查询是 SQL 最核心的功能,支持简单查询、条件过滤、排序、聚合等复杂操作:
(1)基础查询
sql
-- 查询表中所有字段所有数据
select * from stu;
-- 查询指定字段数据
select name, math, chinese from stu;(2)去重与合并查询
sql
-- 去除重复记录(如查询所有不重复的数学成绩)
select distinct math from stu;
-- 合并两个查询结果(字段数与类型需一致,自动去重)
select name, math from stu where math>90 union select name, math from stu where chinese>90;
-- 合并结果并保留重复记录
select name, math from stu where math>90 union all select name, math from stu where chinese>90;(3)运算与别名
sql
-- 成绩加分(数学+10分,英语+10分)
select name, (math+10) as 数学加分, (english+10) as 英语加分 from stu;
-- 计算总分并指定别名
select name, (math+english+chinese) as 总分 from stu;(4)条件过滤(WHERE)
支持比较运算、范围查询、模糊查询等多种条件:
sql
-- 比较运算(查询英语成绩>90分的学生)
select name, english from stu where english>90;
-- 范围查询(数学成绩在78、88、99中的学生)
select * from stu where math in (78,88,99);
-- 模糊查询(姓名包含"张"字的学生,%表示任意字符)
select * from stu where name like '%张%';
-- 多条件组合(总分>200且数学>80)
select name, (math+english+chinese) as 总分 from stu where (math+english+chinese)>200 and math>80;(5)NULL 值处理
sql
-- 判断字段是否为空(返回1表示为空,0表示非空)
select name, isnull(chinese) as 语文成绩是否为空 from stu;
-- 空值替换(语文成绩为空时显示0)
select name, ifnull(chinese, 0) as 语文成绩 from stu;
-- 两值相等返回NULL(数学与英语成绩相同时返回NULL)
select name, nullif(math, english) as 数学英语是否不等 from stu;(6)排序(ORDER BY)
sql
-- 按总分降序排列(DESC降序,ASC升序,默认ASC)
select name, (math+english+chinese) as 总分 from stu order by 总分 desc;
-- 多字段排序(先按数学降序,再按英语升序)
select name, math, english from stu order by math desc, english asc;(7)聚合函数与分组查询(GROUP BY/HAVING)
聚合函数用于统计分析,分组查询按指定维度聚合数据:
sql
-- 聚合函数(统计学生总数、数学平均分、最高分)
select count(*) as 学生总数, avg(math) as 数学平均分, max(math) as 数学最高分 from stu;
-- 分组查询(按班级分组,统计每个班级的总分平均值)
select class_id, avg(math+english+chinese) as 班级平均分 from stu group by class_id;
-- 过滤分组结果(班级平均分>180)
select class_id, avg(math+english+chinese) as 班级平均分 from stu group by class_id having 班级平均分>180;查询语句执行顺序:SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
(四)多表查询
当数据分散在多个关联表中时,需通过多表查询获取整合数据,核心依赖外键建立表间关联。
1. 内连接(INNER JOIN)
仅查询两表中满足关联条件的数据,是最常用的多表查询方式:
sql
-- 显式内连接(推荐,逻辑清晰)
select d.dname, e.ename, e.sal from dept d inner join emp e on d.did = e.dno;
-- 隐式内连接(简化写法,通过WHERE指定关联条件)
select d.dname, e.ename, e.sal from dept d, emp e where d.did = e.dno;注:d和e分别是表dept和emp的别名,用于简化代码。
2. 外连接
保留一张表的全部数据,关联另一张表的匹配数据,未匹配的数据显示为 NULL:
sql
-- 左外连接(保留左表dept的所有数据,关联emp的匹配数据)
select d.dname, e.ename from dept d left outer join emp e on d.did = e.dno;
-- 右外连接(保留右表emp的所有数据,关联dept的匹配数据)
select d.dname, e.ename from dept d right outer join emp e on d.did = e.dno;3. 子查询(嵌套查询)
子查询是嵌套在其他 SQL 语句中的查询,内层查询结果作为外层查询的条件或数据源:
sql
-- 示例:查询数学成绩高于平均分的学生
select name, math from stu where math > (select avg(math) from stu);子查询可灵活实现复杂逻辑,但需注意性能优化,避免多层嵌套导致查询效率下降。
补充说明
- SQL 语法规范:SQL 关键字不区分大小写;语句结束需加英文分号(除备份 / 恢复等 CMD 命令外);
- 字符集设置:为避免中文乱码,建议数据库、表、字段统一使用 utf8 字符集;
- 安全风险:WHERE 子句中 AND 优先级高于 OR,可能导致 SQL 注入漏洞,开发中需使用参数化查询替代字符串拼接;
- 性能优化:查询大数据量时,合理使用索引(通过 CREATE INDEX 创建);避免 SELECT *,仅查询需要的字段;分组查询和子查询需控制数据量。