前言
在多模态大模型(MLLM)爆发的浪潮中,上海人工智能实验室(OpenGVLab) 推出的 InternVideo(书生·多模态视频) 系列一直是视频理解领域的标杆。
从 InternVideo 1 的双流互补 ,到 InternVideo 2 的统一扩展 ,再到 InternVideo 2.5 的精细化交互 ,这一系列的演进完美诠释了视频理解技术的发展路径:从"看懂动作"到"理解语义",最终迈向"像人一样交流"。
本文将深入剖析这三个版本的核心原理,对比它们的技术差异与改进点。
一、 InternVideo 1.0:动作与语义的互补融合
发布时间 :2022年
核心关键词:双流架构、互补学习
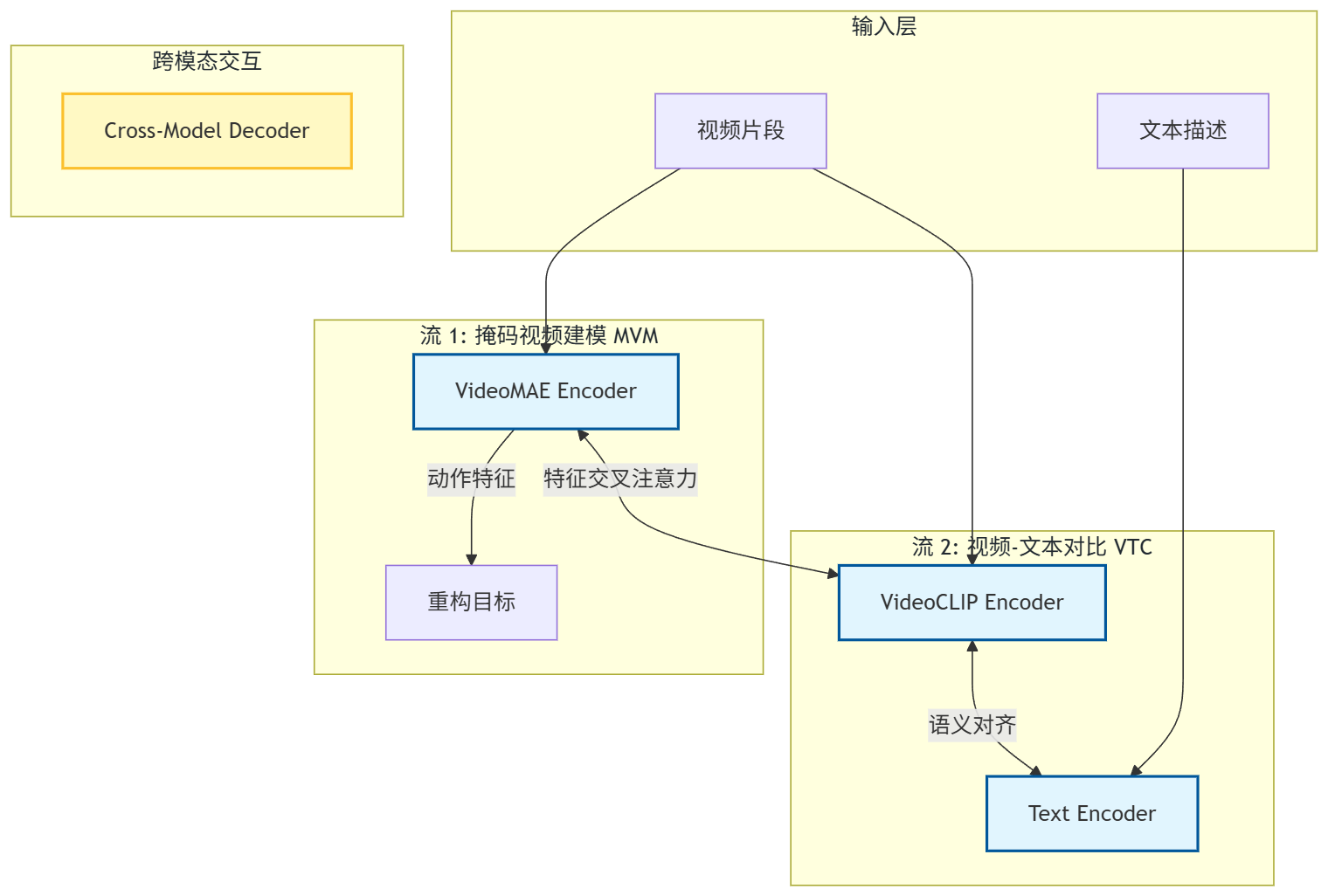
1.1 核心痛点
在 InternVideo 1.0 时代,视频领域存在两条割裂的路线:
- 生成式/重构路线(如 VideoMAE) :通过掩码重构学习视频,动作理解能力极强,但缺乏语义标签,不知道"狗"是"狗"。
- 对比式路线(如 VideoCLIP) :通过图文对比学习,语义对齐能力强,但往往忽略了细粒度的时序动作信息。
1.2 解决方案
InternVideo 1.0 提出了一种通用视频基础模型(General Video Foundation Model),其核心思想是**"我全都要"**。它采用了双流架构,分别利用掩码建模和对比学习,并通过交互机制融合两者。
1.3 架构图 (Mermaid)
1.4 关键改进
相比于单流模型,InternVideo 1.0 证明了重构任务和对比任务是互补的。它通过 Cross-Model Attention 让两个分支交换信息,既保留了 VideoMAE 的动作捕捉能力,又获得了 CLIP 的语义泛化能力。
二、 InternVideo 2.0:统一骨干与渐进式扩展
发布时间 :2024年 (CVPR 2024)
核心关键词:统一 ViT、渐进式训练、Scaling Law
2.1 相对 v1.0 的痛点与改进
InternVideo 1.0 的双流架构虽然有效,但存在明显问题:
- 计算冗余:需要维护两个庞大的 Encoder,推理慢,显存占用高。
- 扩展困难:双流结构难以验证 Scaling Law(缩放定律),难以做成超大模型。
InternVideo 2.0 的改进核心在于"统一(Unified)" 。它废弃了双流设计,使用一个单一的 Vision Transformer (ViT) 同时完成重构和对比任务,并将参数量扩展到了 6B。
2.2 核心原理:渐进式训练 (Progressive Training)
如何让一个模型同时学好"动作"和"语义"?InternVideo 2 提出了分阶段训练策略:
- 阶段一 (MVM):无监督掩码重构,让 ViT 学会看世界(理解时空动态)。
- 阶段二 (VTC):多模态对比学习,让 ViT 学会懂语言(语义对齐)。
- 阶段三 (SFT):指令微调,适配下游任务。
2.3 架构图 (Mermaid)
多任务头 Multi-Heads 统一骨干网络 Unified Backbone 输入层 Inputs 可见特征 全局特征 轻量解码器 Decoder 重构损失 MVM 文本编码器 Text Encoder 对比损失 VTC 时空掩码 Masking InternVideo2 ViT 6B
3D Patch Embedding Video/Audio Text
2.4 关键突破
- Scaling:验证了视频模型在数据量和参数量上的 Scaling Law,证明了大力出奇迹。
- Audio融合:引入音频模态,利用音频辅助视频理解。
- 性能霸榜:在 Kinetics-400 等多个榜单上取得了 SOTA。
三、 InternVideo 2.5:迈向精细化交互与长时序
发布时间 :2024年下半年 (InternVL 2.5 家族)
核心关键词:动态高分辨率、长上下文、LLM 驱动
3.1 相对 v2.0 的痛点与改进
InternVideo 2.0 虽然在分类和检索任务上很强,但在多轮对话(Chat)和细节理解上存在瓶颈:
- 分辨率限制:2.0 通常将视频压缩到 224x224,导致无法识别视频中的字幕(OCR)或微小物体。
- 交互能力:2.0 更多是判别式模型,缺乏强大的逻辑推理和文本生成能力。
InternVideo 2.5 的本质是"InternVL 2.5 的视频模式" 。它采用了 ViT + MLP + LLM 的范式,彻底解决了细节丢失问题。
3.2 核心原理:动态高分辨率 (Dynamic High-Resolution)
这是 v2.5 最革命性的改进。它不再粗暴缩放视频,而是:
- 全局缩略图:提供宏观视角。
- 局部切片:根据视频帧的宽高比,将其切分为多个高分辨率块(如 448x448),保留极致细节。
- LLM 基座:使用 InternLM 2.5,支持超长上下文,可以处理几十甚至上百帧的高清切片 Token。
3.3 架构图 (Mermaid)
- 推理生成 3. 压缩映射 2. 视觉编码 1. 动态输入 Resize Crop Visual Tokens 用户提问 InternLM 2.5 Chat
Long Context 文本回答 Pixel Shuffle 下采样 MLP 投影层 InternViT 共享权重 多尺度特征 宽高比分析 原始视频帧 全局缩略图 局部高清切片
3.4 关键突破
- OCR 能力质变:得益于动态切片,能够精准识别视频中的文字、车牌、手机屏幕内容。
- 长视频理解:利用 LLM 的长上下文能力,能够理解几分钟长的视频逻辑。
- 通用性:同一个模型架构同时处理图像和视频,实现了 Image-Video 的大一统。
四、 总结:三代版本的演进对比
| 特性 | InternVideo 1.0 | InternVideo 2.0 | InternVideo 2.5 |
|---|---|---|---|
| 核心架构 | 双流架构 (VideoMAE + VideoCLIP) | 统一 ViT (Unified Backbone) | ViT + LLM (InternVL 架构) |
| 主要任务 | 动作识别、视频检索 | 零样本分类、检索、动作理解 | 多模态对话、推理、OCR |
| 输入分辨率 | 固定 (224x224) | 固定 (224x224) | 动态高分辨率 (448+) |
| 训练范式 | 交互式学习 | 渐进式训练 (MAE -> CLIP) | SFT (视觉 Token -> LLM) |
| 对细节的理解 | 弱 (模糊) | 一般 (关注动作轮廓) | 极强 (像素级感知) |
| 交互能力 | 无 (仅输出标签/分数) | 弱 (需外挂 LLM) | 强 (原生 Chat) |
结语
从 InternVideo 1 到 2.5 的演进,实际上是 AI 视频理解技术从**"专用小模型"向"通用大模型"**转变的缩影。
- 如果你关注传统的动作识别精度,InternVideo 2.0 是很好的选择;
- 如果你需要构建 AI 视频助手、分析监控画面细节或进行视频内容问答,InternVideo 2.5 则是目前的 SOTA 之选。
希望这篇深度解析能帮助您更好地理解 InternVideo 系列的技术脉络!