文章目录
-
- [一、背景 --- 为什么要有多种"列表(List)"编码](#一、背景 — 为什么要有多种“列表(List)”编码)
- [二、ziplist ------ 压缩列表(compact list)](#二、ziplist —— 压缩列表(compact list))
-
- [2.1 ziplist 是什么](#2.1 ziplist 是什么)
- [2.2 ziplist 的适用条件(默认策略)](#2.2 ziplist 的适用条件(默认策略))
- [2.3 ziplist 的优点与缺点](#2.3 ziplist 的优点与缺点)
- [三、quicklist ------ 快速列表(QuickList)](#三、quicklist —— 快速列表(QuickList))
-
- [3.1 quicklist 是什么](#3.1 quicklist 是什么)
- [3.2 quicklist 的结构与配置参数](#3.2 quicklist 的结构与配置参数)
- [3.3 quicklist 的优点](#3.3 quicklist 的优点)
- [3.4 quicklist 的限制与注意事项](#3.4 quicklist 的限制与注意事项)
- [四、ziplist vs quicklist ------ 对比总结](#四、ziplist vs quicklist —— 对比总结)
一、背景 --- 为什么要有多种"列表(List)"编码
- 在内存数据库 Redis 中,列表(List)是常用数据类型之一,用于实现队列、堆栈、消息队列、任务队列等场景。
- 不同场景对内存使用与访问效率有不同要求:少量元素 → 希望节省内存;大量元素或频繁插入/删除 → 需要高性能操作。
- 因此Redis 设计者提供了不同的"编码方式"(encoding)来存储 List 对象,以兼顾 空间效率 与 操作效率。
在历史发展中,Redis 对 List 的编码方式经历了如下阶段:
- 早期:使用 双向链表(linkedlist) 或 压缩列表(ziplist),两种可选。
- 从 Redis 3.2 版本起,引入 quicklist,作为新的默认结构,取代了 ziplist + linkedlist 的混合策略。
下面分别介绍 ziplist 和 quicklist 的结构与特性,然后比较优缺点。
二、ziplist ------ 压缩列表(compact list)
2.1 ziplist 是什么
- ziplist 是 Redis 提供的一种"紧凑型列表结构(compact list)"。它将多个 list 元素连续地存放在一块 连续内存(contiguous memory block) 中。
- 每个 entry(元素)包含必要的 metadata(如前一个 entry 长度、当前 entry 长度、数据内容等),因此 ziplist 可以存放不同长度的数据项(字符串、整数等),而不需要为每个元素单独分配内存。
- 因为内存连续、元素紧凑,ziplist 在内存占用上非常高效 --- 对于存储少量、短字符串/整数列表时,能节省大量内存。
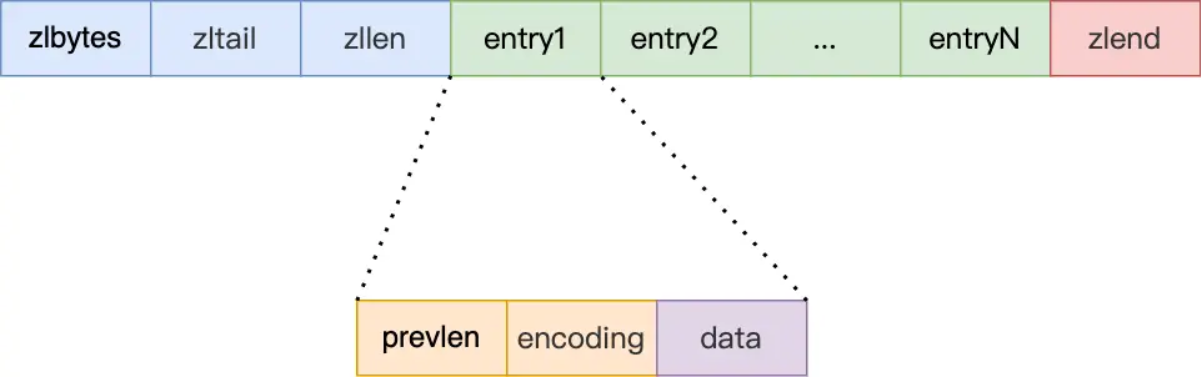
ziplist结构如图所示,参考Redis面试题:
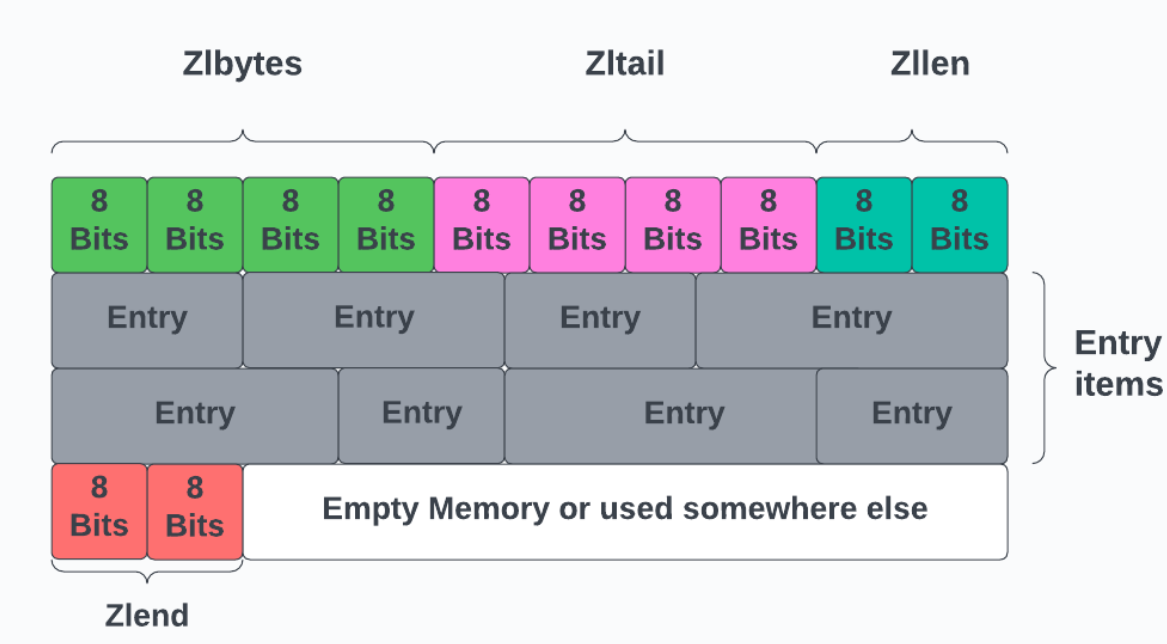
下边的图也可加深理解
ziplist的各字段含义如下。
- zlbytes:压缩列表的字节长度,占4B,因此压缩列表最长 2³²‑1B。
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4B。
- zllen:压缩列表的元素数目,占2B;当压缩列表的元素数目超过65535(2¹⁶‑1)时,zllen 无法存储,此时必须遍历整个压缩列表才能获取元素数目。
- entry1、entr2y:压缩列表存储的若干个元素,可以是字节数组或者整数,长度不限;
- zlend:压缩列表的结尾,占1B,固定为0xFF。
对于每一个entry元素来讲
entry 结构包含三个字段:
- prelen
- 记录前一个元素的长度,用于从后向前遍历。
- 前一个元素长度 < 254B → 占 1B。
- 前一个元素长度 ≥ 254B → 占 5B(首字节为 0xFE,后 4B 为实际长度)。
- encoding
- 表示 data 的数据类型(整数或字节数组)。
- 长度可变(1B、2B 或 5B),通过开头的比特区分。
- 同时可包含字节数组的长度信息(如 6bit、14bit 或 32bit 表示长度)。
以下是encoding字段的元素编码
| 编码 (encoding) 标识 / 类型 | encoding长度 | 说明 / 含义 (简要) |
|---|---|---|
00pppppp |
1B | 表示一个 string,长度 ≤ 63 字节。 |
01pppppp + qqqqqqqq |
2B | 表示一个 string,长度 ≤ 2¹⁴‑1字节。 |
10000000 + 4 bytes length |
5B | 表示一个较长 string(长度 ≤ 2³²‑1字节)。 |
11000000 |
1B | 表示一个 int16_t(16-bit 整数)元素。 |
11010000 |
1B | 表示一个 int32_t(32-bit 整数)元素。 |
11100000 |
1B | 表示一个 24-bit 整数编码(special 24-bit 整数)。 |
11111110 |
1B | 表示一个 int8_t(8-bit 整数)元素。 |
1111xxxx |
1B | xxxx表示范围为 0--12 的整数 。 |
- data
- 实际存储的数据,可以是整数或字节数组,长度由 encoding 决定。
2.2 ziplist 的适用条件(默认策略)
在 Redis 配置文件(或编译时默认)中,对于 LIST、HASH、ZSET 等类型,会设置参数来决定是否使用 ziplist,例如:
list-max-ziplist-entries:限制 ziplist 中元素(entry)个数list-max-ziplist-value:限制每个 entry 的最大字节数(value 大小)
当元素数量或元素大小超过这些限制时,Redis 会放弃 ziplist 编码,转为其他更适合的编码方式(在老版本可能是 linkedlist,现在是 quicklist)。
2.3 ziplist 的优点与缺点
优点:
- 内存利用率高 --- 非常节省内存空间,适合存储少量、小数据。
- 内存连续,有利于 CPU 缓存和遍历效率。
缺点 / 缺陷:
- 对修改操作(插入 / 删除 / 更新)不友好 --- 因为要保持连续内存,一旦中间插入或删除,就可能触发内存重新分配和数据搬移(realloc + memcpy),代价高昂。这里会涉及连锁更新问题。
- 当元素较多或较大时,ziplist 会非常臃肿或重复 realloc,性能和稳定性都不理想。
- 因此,ziplist 更适合"短小、稳定、不频繁变更"的列表数据,不适合大数据量或高频写入场景。
三、quicklist ------ 快速列表(QuickList)
3.1 quicklist 是什么
- quicklist 是从 Redis 3.2 开始引入的 List 编码方式,用于替代早期的 ziplist /adlist 编码。
- 它本质上是 双向链表 + 压缩子列表 的混合结构:一个 quicklist 是一个双向链表,而链表的每个节点(
quicklistNode)内部持有一个 ziplist来存储一段连续的元素。 - 这样的设计兼顾了链表和 ziplist 各自的优点。
3.2 quicklist 的结构与配置参数
quicklist 的主要结构由 quicklist 和 quicklistNode 两个 C 结构体定义,在 Redis 源码中(例如 quicklist.h / quicklist.c)可以查看。
结构图可参考Redis从入门到精通之底层数据结构快表 - QuickList详解-阿里云开发者社区,如下图
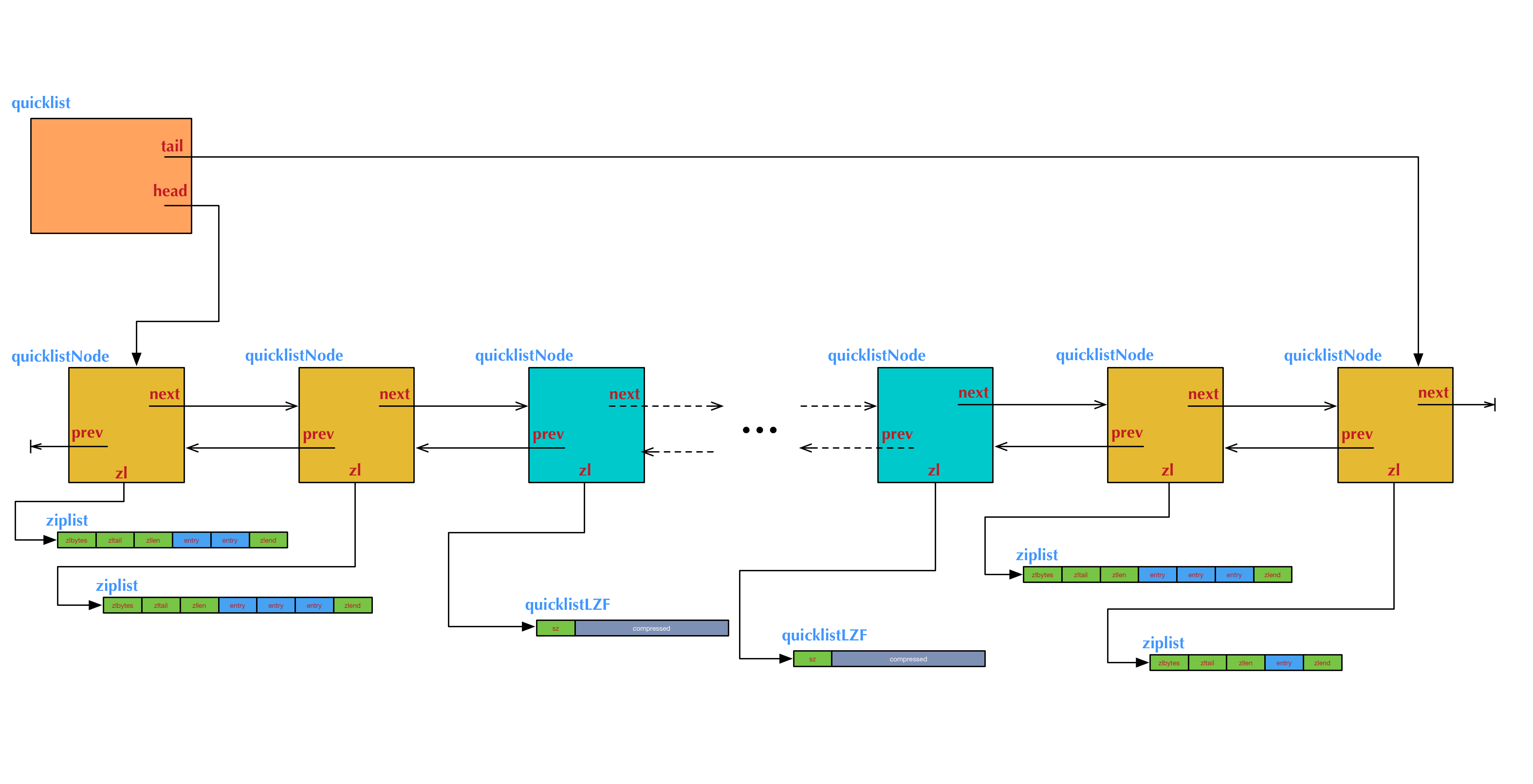
在quicklist中,关键字段包括:
head/tail:指向链表头尾节点。count:List 中所有元素entry的总数。len:quicklistNode 节点数量。fill:用于控制每个 ziplist 容量上限entry 数量 或 字节大小,通过list-max-ziplist-size配置项设定。compress:用于控制压缩深度,即链表两端多少个节点不压缩,中间节点可被压缩以节省内存,通过list-compress-depth配置项控制。- 每个 quicklistNode 包含指向内部 ziplist(或 listpack)的指针
zl,大小sz,元素计数count等信息。
⚠️ 注意:在 Redis 最新版本中(例如 7.x),listpack 已经逐步取代 ziplist 作为内部压缩子列表结构,但 quicklist 的设计思想不变 ------ 分段 + 链表 + 压缩子列表。
3.3 quicklist 的优点
- 兼顾空间与效率:通过将列表拆成多个小段(ziplist),既避免了大型链表带来的内存碎片和高 overhead,也避免了大型 ziplist 带来的频繁 realloc 问题。
- 快速头尾操作(push/pop):因为 quicklist 是链表结构,在头尾插入删除是 O(1) 操作,非常高效,适合队列/栈等操作频繁场景。
- 压缩可选:中间节点可以压缩(LZF 等算法/listpack 压缩),节省内存;而头尾保留原始以保证访问性能。
- 灵活适应不同场景:既适合存储小量短元素,也适合存储大量元素或长列表。
3.4 quicklist 的限制与注意事项
- 如果配置不当(ziplist 内部过大、压缩设置不合理),可能出现性能开销过重,或内存碎片/压缩开销问题。
- quicklist 内部实现比简单链表或数组复杂,对于某些极端访问模式(大量随机访问中间、频繁跨节点访问)可能不如纯数组或其他结构高效。
quicklist 的两种极端情况如下:
1. 当 ziplist 节点过多时,quicklist 退化为双向链表。最极端的情况是每个 ziplist 节点只包含一个 entry,即一个元素对应一个节点。 2. 当 ziplist 节点过少时,quicklist 退化为 ziplist。最极端的情况是整个 quicklist 中只含有一个 ziplist 节点。
- 对于非常频繁的随机访问或修改,可能需要谨慎评估是否适合使用列表结构。
四、ziplist vs quicklist ------ 对比总结
| 特性 / 维度 | ziplist | quicklist |
|---|---|---|
| 内存布局 | 连续内存 block(compact) | 链表 + 多个 ziplist/listpack segments |
| 内存开销 | 低,连续、紧凑 | 较高(链表+子列表)但比纯链表低 |
| 适合场景 | 元素少、数据小、读不频繁修改 | 元素多、队列 / 栈 / 批量 push/pop / 变长频繁 |
| 插入/删除性能 | 中间插入删除开销大(可能 memcpy) | 头尾 O(1),节点级调整,较稳定 |
| 内存碎片 | 几乎无 | 较少(链表 + 子列表) |
| 压缩 / 节省空间 | 默认紧凑 | 可配置压缩,兼顾效率 |
| Redis 中默认支持 | 早期版本 | Redis 3.2+ 默认 |
Redis 之所以在内存数据库 / 缓存系统中表现出色,很大程度上是因为它为不同场景提供了优化良好的底层数据结构。ziplist 与 quicklist 是 Redis List 类型在历史与现在对空间与时间折中的经典设计。
- ziplist:为"少量、小数据、节省内存"而生。
- quicklist:为"高性能、灵活、适应大/变动列表"而设计。
参考资料
Redis 源码解析 7:五大数据类型之列表 - 小新是也 - 博客园