目录
[2.list 双链表 底层实现](#2.list 双链表 底层实现)
[2.0 定义结点为什么是结构体模板,不是类模板?](#2.0 定义结点为什么是结构体模板,不是类模板?)
[2.1.1 默认构造的封装------方便其他构造调用](#2.1.1 默认构造的封装——方便其他构造调用)
[2.1.0 n 个 val 的 构造](#2.1.0 n 个 val 的 构造)
[2.2 pusn_back 尾插](#2.2 pusn_back 尾插)
[2.3 迭代器(重要)](#2.3 迭代器(重要))
[2.3.0 vector 和 list 的迭代器比较](#2.3.0 vector 和 list 的迭代器比较)
[2.3.1迭代器:内存 和 类型 的奥妙](#2.3.1迭代器:内存 和 类型 的奥妙)
[2.4insert erase 以及 复用 (迭代器失效)](#2.4insert erase 以及 复用 (迭代器失效))
[2.4.2 insert , erase (处理迭代器失效)](#2.4.2 insert , erase (处理迭代器失效))
[2.4.2 迭代器返回类型 详解](#2.4.2 迭代器返回类型 详解)
[2.4.3 头插头删,尾插尾删的复用](#2.4.3 头插头删,尾插尾删的复用)
[2.6析构函数 和 clear (仔细看区别)](#2.6析构函数 和 clear (仔细看区别))
[2.7基于迭代器的 构造函数](#2.7基于迭代器的 构造函数)
[2.7.2 迭代器区间构造](#2.7.2 迭代器区间构造)
[2.8 拷贝构造 传统,现代](#2.8 拷贝构造 传统,现代)
[2.9 operator= 赋值运算符重载 传统,现代](#2.9 operator= 赋值运算符重载 传统,现代)
[2.10 swap](#2.10 swap)
[2.11const_iterator cosnt 迭代器](#2.11const_iterator cosnt 迭代器)
[2.11 const 迭代器 和 普通迭代器 的核心差异 :T& 和const T&](#2.11 const 迭代器 和 普通迭代器 的核心差异 :T& 和const T&)
[2.11.1 const 迭代器 传统方法](#2.11.1 const 迭代器 传统方法)
[2.11.2 const 迭代器 利用模板实现------避免冗余](#2.11.2 const 迭代器 利用模板实现——避免冗余)
[2.12 迭代器 重载 - > (第三个模板参数)](#2.12 迭代器 重载 - > (第三个模板参数))
[2.12.1 Ptr参数:实现 T* 和 const T* 重载- >](#2.12.1 Ptr参数:实现 T* 和 const T* 重载- >)
1.list部分源码解析
同样,现在我们是读不懂大部分源码的。还是跳着看,看看部分模块功能,重要的底层变量,不去深究
根据我们看vector源码的理解,list头文件而是其他头文件的封装,重要的是 list.h ,那我们直接打开看看

打开来就看到了一个结构体模板,显然这是节点 ,定义的是双向链表next,prev ,__list_node 但节点类型为什么是void*? 一起往下看

再往下,就是迭代器,看他的迭代器模板参数 , 有3个参数,究竟是为什么?后面再说,链表迭代器很复杂,暂时跳过。看不懂


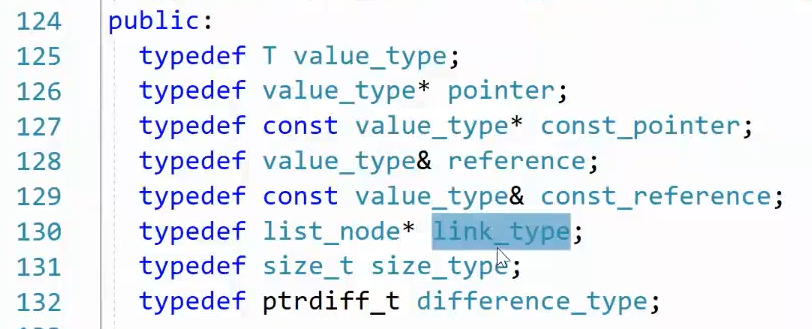
再往下看,找到了链表的核心成员,节点 node,类型是 list_node* ,被 typedef为了 link_type,那它到底是什么?我们去看一下它的构造

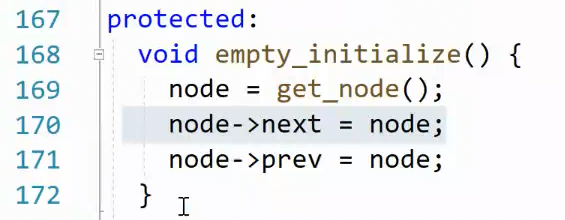

找到了它的构造函数,构造函数里封装"空初始化函数",转到定义,发现它是创建哨兵位头节点 的,因为next和prev都指向node
那为什么是get_node,不是直接new一段空间? 因为它的内存都是内存池来的,我们的new是直接在堆空间获取内存。
内存池的空间也是堆空间。区别是 new是 动态分配,内存池是 预分配 ,内存池更高效。
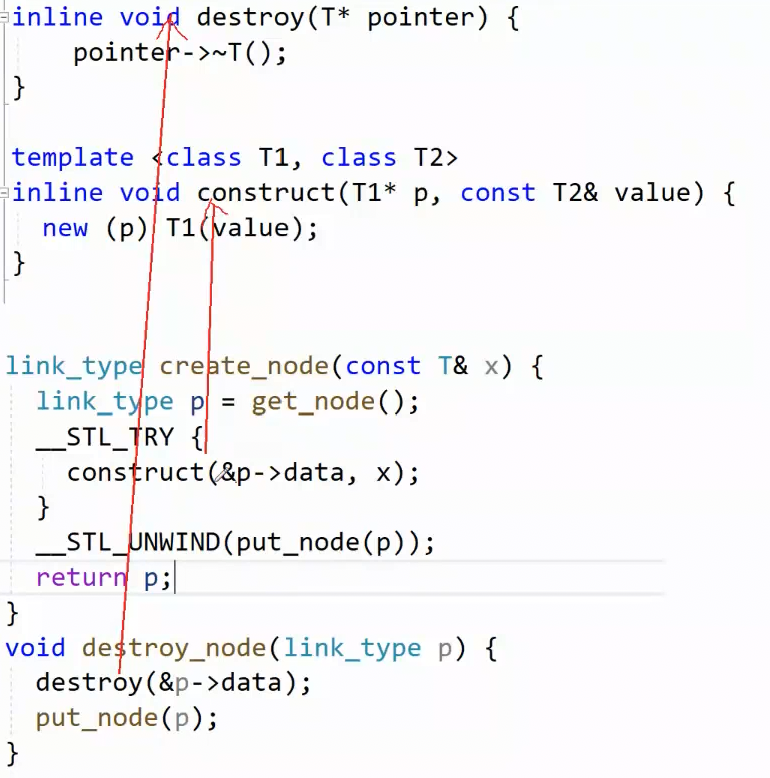
往下看发现了create_node 函数,创建节点 ,其中调用了consturct,construct是用定位new对已有空间显式调用构造完成初始化
因为内存池申请的空间是未初始化的内存空间 ,不是像new,new是开空间加构造。 但是内存池申请空间更高效,所以这样。
所以用内存池申请,释放空间 ,就得显式调用它的析构,构造函数,

这一部分是插入和删除,虽然有助于了解底层,不过都涉及迭代器,链表迭代器比较难,那就不去了解了,我们确认链表底层,一步步来实现
2.list 双链表 底层实现
基于源码,我们首先来设计一下链表底层:
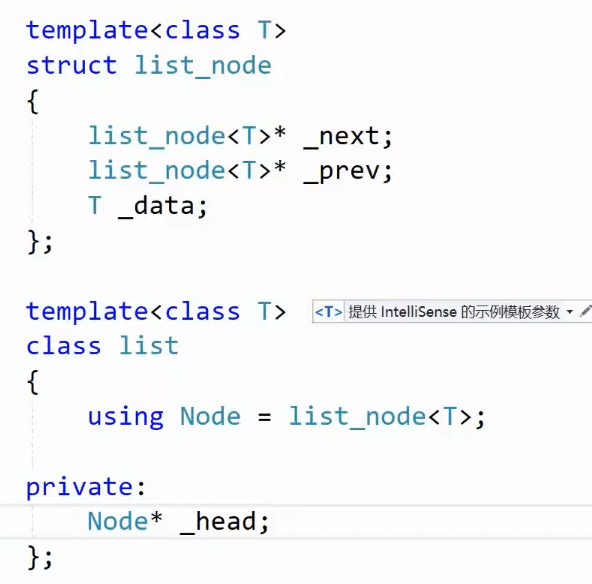
补充:结构体也是类,需要写构造函数,不然插入新节点会出错(默认构造下,指针是(随机内存地址)野指针,_data是随机值),无法构造新节点。

源码中,节点类型是void* ,不过我们不使用void*,我们按照之前数据结构学的来定义。因为void*设计的不好。后面具体说
2.0 定义结点为什么是结构体模板,不是类模板?
为什么用struct结构体? 一个类,如果我们不期望它的成员被访问限定符限定的时候,我们用结构体struct。 因为结构体默认public , 也可以用class加public ,不过习惯上喜欢定义为sturct,方便。结点作为list的子结构,默认就是要被list访问和使用 ,因此结点不能设为私有成员
编译器设为公有不怕被其他人随意访问吗?不怕,因为底层都是有层层封装,从外壳层角度,结点底层变量名是不可猜的,因为随机性很强。也没人闲的去翻源码来使用,没有意义。
2.1构造函数
我们就不使用内存池了,太繁琐,没学过。 用new:

2.1.1 默认构造的封装------方便其他构造调用
也可以封装一下这个构造,因为链表底层很多构造,那每个涉及构造的函数都得重复一遍创建哨兵位节点的操作,干脆封装起来:


2.1.0 n 个 val 的 构造

重载两个,一个int,一个size_t,因为会和 迭代器区间构造函数模板 冲突
2.2 pusn_back 尾插
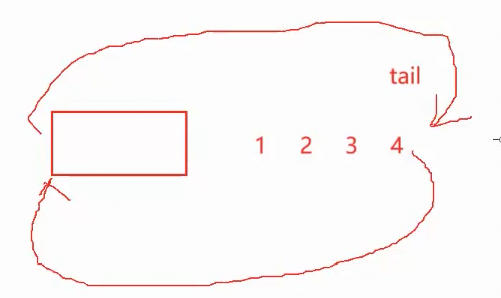
思路:尾插需要找到最后一个节点tail,如图,那 tail 就是_head->prev ,然后只需要改变一下节点指向,就完成了

并且这里的尾插不需要考虑为空 的情况,因为哨兵位头节点的存在 ,空也可以直接在** 哨兵位上正常尾插** ,十分方便
2.3 迭代器(重要)
2.3.0 vector 和 list 的迭代器比较

这是vector的迭代器,vector底层空间连续,它的指针功能刚好符合迭代器需求,这就是**"天赋"** ,所以vector的迭代器十分简单,指针就行。
迭代器是行为类似指针的东西,不一定是指针,但可以是指针
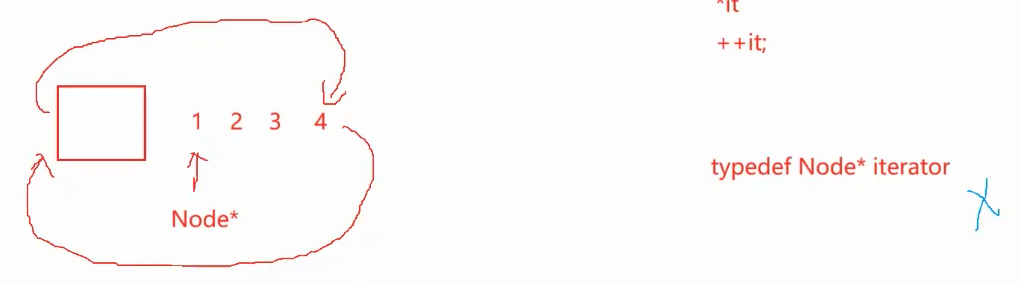
这是链表,那链表可以用节点的指针作为迭代器吗? 不能。 首先,*it得到的是节点,不是节点数据_data ,其次,节点的地址是不连续的,你不能保证下一个节点的地址一定比前面的大,那++it 也实现不了。链表没有vector的"天赋" ,那就需要**"努力",** 怎么努力?
2.3.0迭代器的本质

其实迭代器就是一种封装 ,只要外层行为像是指针 就行,底层可以不是指针 ,我们可以重载运算符 ,重载 * ,++ , ->让迭代器像指针
那我们就像源码那样,把迭代器封装成类,自己努力,实现指针行为
2.3.0迭代器的实现
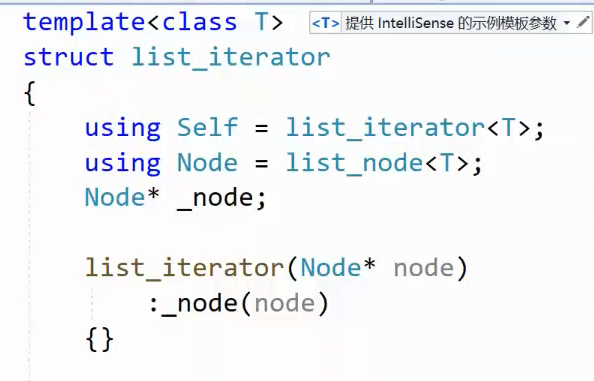

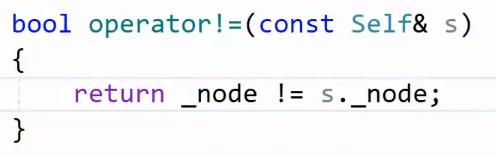
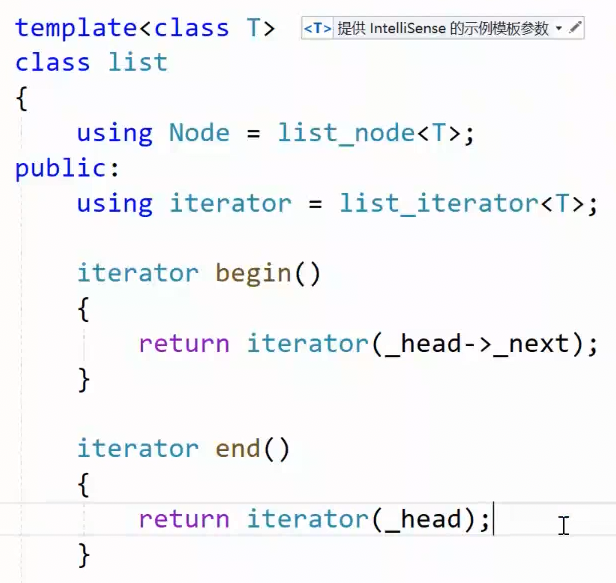


实现const 迭代器后 补充:

begin ,end接口返回值是迭代器类型,这种写法是:显式构造迭代器匿名对象,初始化为对应节点指针返回。
也可以是直接返回指针,由迭代器的构造函数,单参数构造函数的隐式类型转换,转换为迭代器类型
封装一个iterator类模板,重载指针相关功能,然后在list中封装为iterator ,然后提供相关迭代器接口**:begin,end**
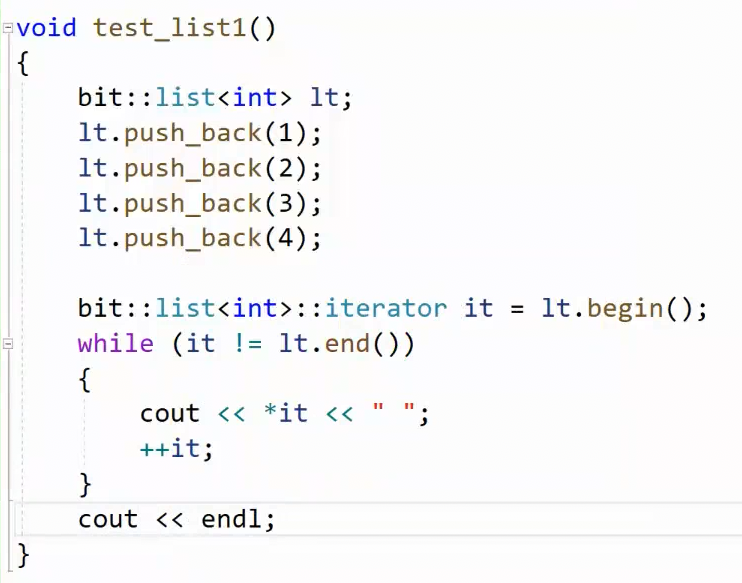

测试,迭代器功能正常,基础迭代器就完成了
2.3.1迭代器:内存 和 类型 的奥妙

32位下, it1 是4字节, it2 也是4字节,迭代器只是封装了一个Node*指针。甚至他们指向同一个节点,只是因为类型不同(自定义类型),它就调用自定义类型自己的重载函数,导致他们行为完全不同。 内存一样,数据一样,只是因为类型不一样,编译的结果就完全不同。
2.3.2迭代器是否需要实现析构?
不需要,节点归链表管,迭代器负责迭代,如果迭代完,把节点析构了,那就麻烦了
节点属于链表,不归迭代器管理。
2.4insert erase 以及 复用 (迭代器失效)

源码中push_bakc,push_front都是复用insert的,理论上也确实。那我们先实现insert
2.4.1源码节点类型void*的弊端
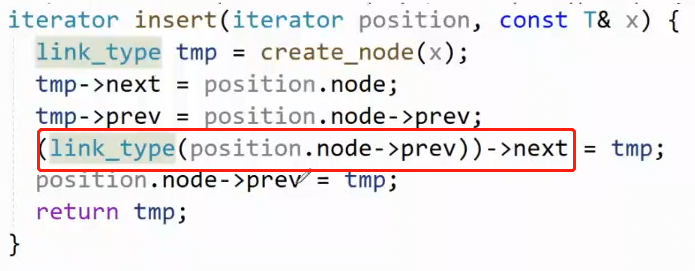
如图,insert的逻辑不难,就是在pos和pos前一个位置插入一个节点, 但是源码的这一句,因为void*要强制转换为link_type类型(list_node*),导致弯弯绕绕的,很麻烦,可读性不高
2.4.2 insert , erase (处理迭代器失效)

这样就好看多了,把cur位置和prev位置标出来,3个位置节点方向换一下,轻轻松松。

2.4.2 迭代器返回类型 详解
返回值:注释的写法是:返回的是迭代器类型,所以显式构造一个匿名对象,初始化为next指针
当前写法: 直接返回next指针,通过迭代器的构造,和 单参数构造函数的隐式类型转换,转换为迭代器类型
erase 同样也是简简单单,细节是 处理迭代器失效
2.4.3 头插头删,尾插尾删的复用

复用 ,在insert 和 erase 的基础上 ,关键在于找对头和尾节点。
2.5size()
求size,有两种办法,第一种,用范围for循环遍历,计数器记住size数量:
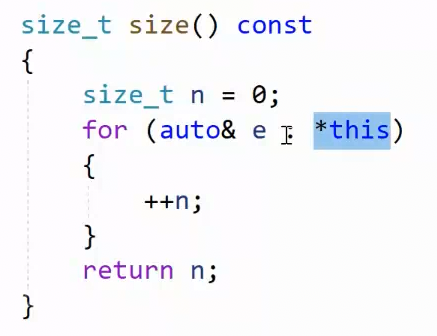
不过,现在还没实现const 迭代器 ,运行不了。这个方法效率很低,O(N)

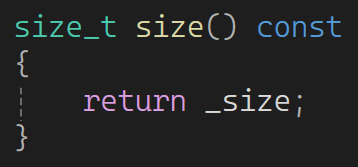
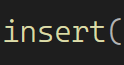
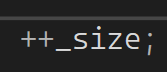
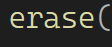

第二种方法,新增加一个成员_size ,然后插入删除时对应size++或者size-- ,效率极高,O(1)
2.6析构函数 和 clear (仔细看区别)
析构函数:销毁所有节点,包括销毁哨兵位头节点 clear:销毁所有节点,除了哨兵位头节点 析构包含clear
鉴于这个包含关系 ,我们对clear封装,在析构调用clear

2.7基于迭代器的 构造函数
2.7.1initializer_list构造
initializer_list 支持迭代器,范围for ,那initializer_list构造:(记住要先调用empty_init(),得有哨兵位头节点才能谈构造)

2.7.2 迭代器区间构造
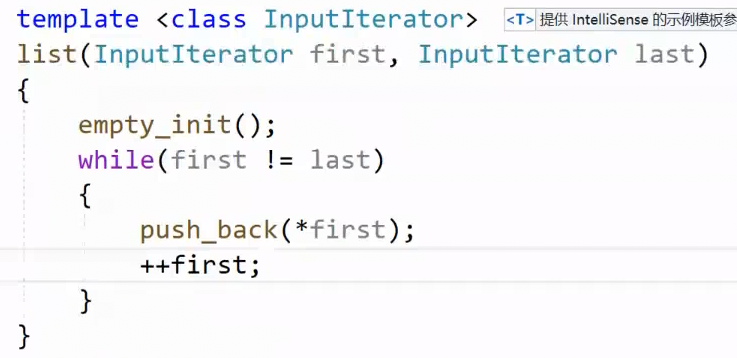
2.8 拷贝构造 传统,现代
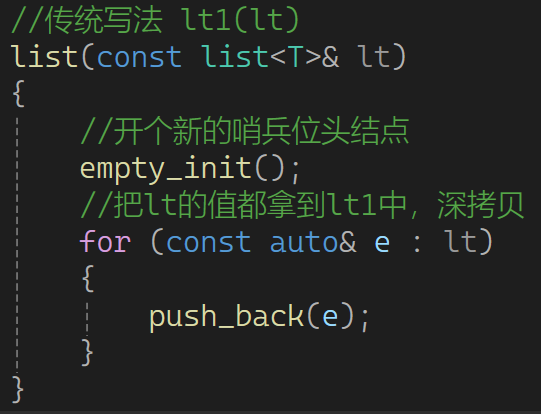
这是拷贝构造函数的传统写法,代码量很少。 所以现代写法占不到什么便宜:

现代写法,代码量差不多,
2.9 operator= 赋值运算符重载 传统,现代
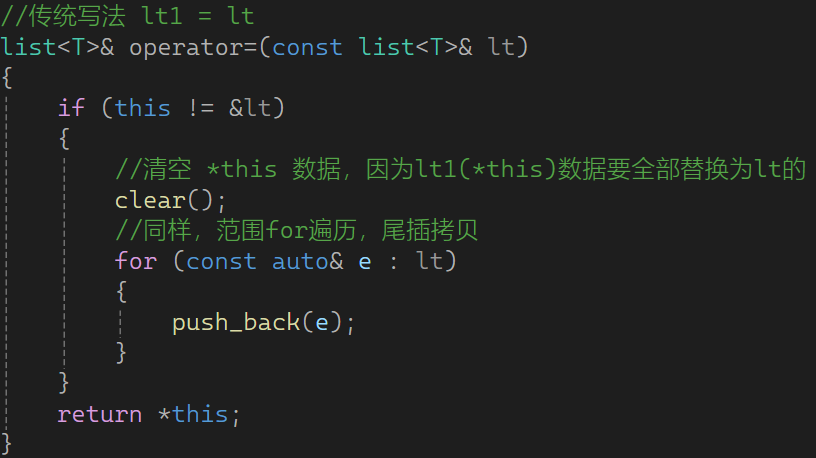
赋值重载 的 传统写法
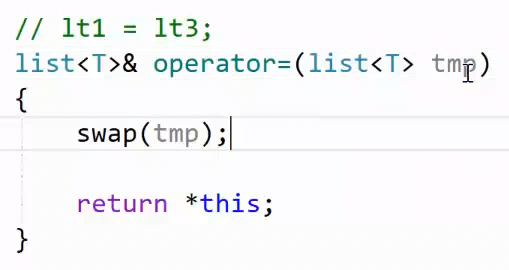
现代写法
2.10 swap

交换底层数据资源就行,不需要深拷贝。
2.11const_iterator cosnt 迭代器
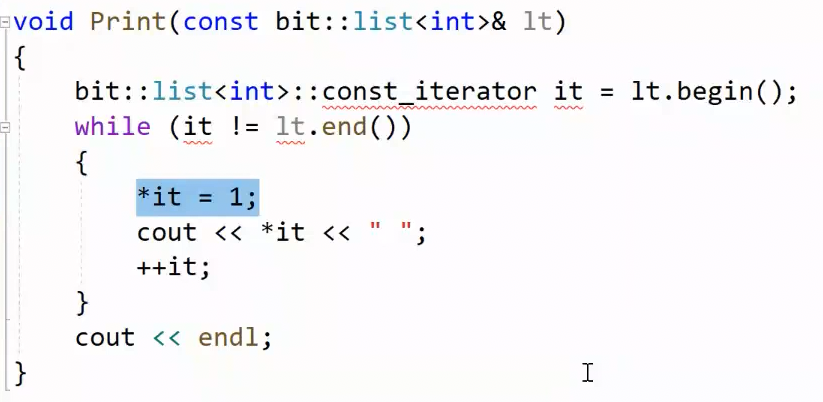
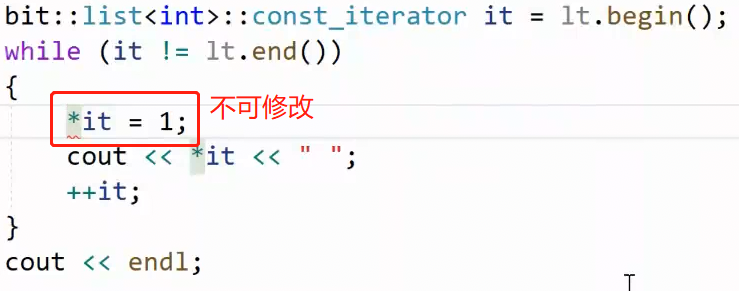
const_iterator 很重要,它要保护迭代器指向的内容(_data)不被修改,但是图中显然能修改*it,而且也没有const_iterator,那现在我们要实现它:
2.11 const 迭代器 和 普通迭代器 的核心差异 :T& 和const T&
const_iterator怎么保护迭代器指向内容不被修改?模拟指针行为,那就是让*it 不能被修改:

*it返回类型是T& ,能被修改,只需要改成 const T& ,const 迭代器就完成了 ,这就是const迭代器和普通迭代器的差异
那么传统方法就是,重新实现一个类模板,把名字改为const_iterator ,然后其他不变,单独把T& 改成 const T&
2.11.1 const 迭代器 传统方法

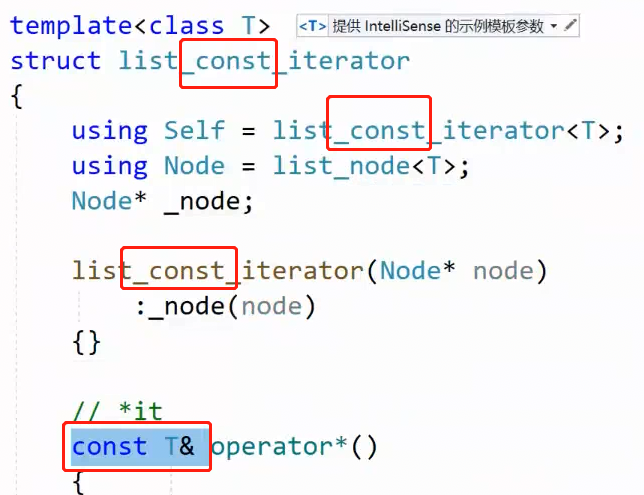

改几个名字,然后其他的全部不变 ,封装成另一个类 const_iterator,在list中重命名一下。
虽然能解决问题,但是两个迭代器代码重合度很高,太浪费了 。 看看源码是怎么写的:
2.11.2 const 迭代器 利用模板实现------避免冗余
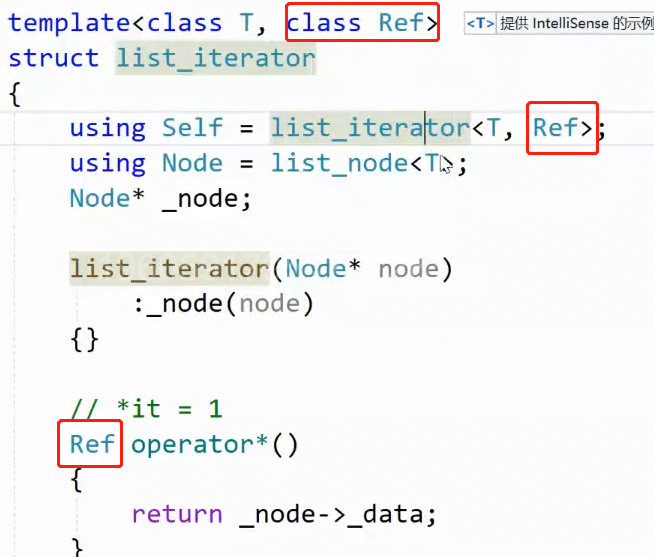

源码在模板参数列表新增了一个参数(左图):Ref (reference,引用),然后list中重命名改成了两个参数,一个是T&,一个是const T&(右图)
把原本的T& 改成了 Ref ,调用const迭代器,Ref就是const T& ,调用普通迭代器,Ref就是T&,完美地解决了代码重合度高的问题。
前者是自己实现两个类, 后者是实现一个双参数类模板,根据模板参数,编译器实例化两个不同的类
2.12 迭代器 重载 - > (第三个模板参数)
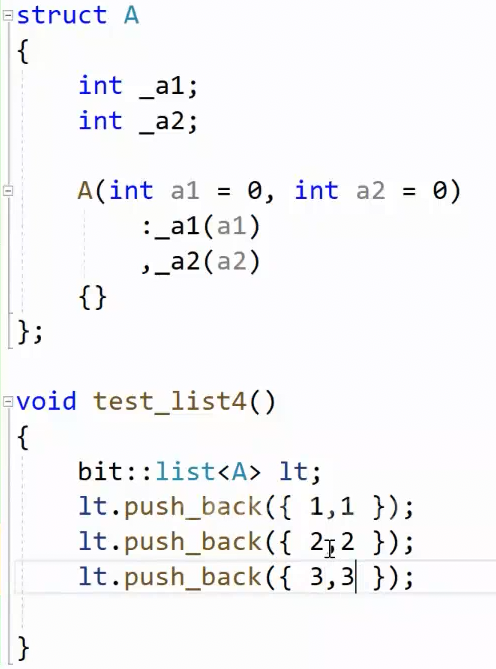
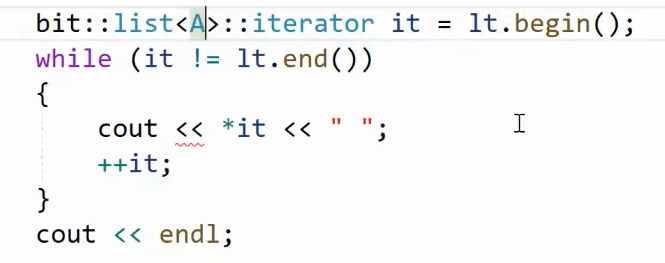
原因:模拟指针行为
迭代器还有缺陷,没有实现 - > 右图的 << 失效了,原因是A对象没有支持 << 输出
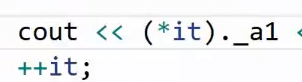
*it 返回当前节点数据_data,的引用,也就是对象A(节点存储A),所以通过这样的方式我们就能访问了 A 对象的成员了。
但是迭代器模仿指针的行为,指针能用箭头 - > 访问 ,所以我们需要重载 - >
实现原理:


返回 T指针 T* ,也就是A*,返回对象的指针,就可以使用- >访问A的成员
为什么一个->可以访问A的成员?:可读性的省略
为什么一个箭头 - > 就能访问A的成员? 原生写法应该是这样:it.operator->()->_a1 通过调用operator-> 获取 A*, 然后A*利用 -> 访问成员
然后隐式调用operator->() 的话就是 :it->->_a1
真的是这样吗? 看看结果:

结果是**->-> 不能用** ,但是it.operator->()->_a1 可以 原因是:作者认为两个箭头可读性不强。为了可读性,省略了一个箭头(operator->()这个箭头)
于是就有了上面的写法:it->_a1
2.12.1 Ptr参数:实现 T* 和 const T* 重载- >
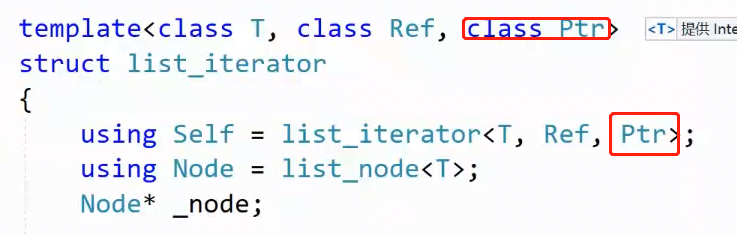


和上面实现const 迭代器 的 第二个参数 的原理一样。
感谢支持
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=7424iazrz5r