在 《前端玩转 AI 应用开发|30行代码实现聊天机器人🤖》中,我们实现了一个基础的聊天应用。然而,该方案存在明显的体验缺陷:由于采用同步等待模式,前端必须等到 AI 模型完整生成并返回全部内容后,才能将结果显示给用户。这在生成长文本时,会带来显著的延迟与卡顿感。
究其根源,这种请求-等待-响应的交互方式并不符合 AI 模型的流式生成特性。模型输出本质上是连续、逐词(Token)产生的,而我们此前采用的默认调用方式,会等待所有内容生成完毕后才一次性返回,导致用户在等待期间完全无法感知生成进度。
为解决这一问题,本文将系统介绍如何在前端实现流式响应。我们将通过建立持久连接,使前端能够实时接收并渲染模型返回的每一个数据片段,从而实现回答的逐词(Token)输出效果。这将从根本上消除不必要的等待,显著提升应用的实时交互体验与响应感知。
下面,我们将从技术原理到代码实现,逐步完成这一优化。
核心技术:Server-Sent Events
什么是 SSE?
Server-Sent Events (SSE) 是一种基于 HTTP 的服务器推送技术,允许服务器主动向客户端发送数据流。其核心机制在于:服务器通过声明 Content-Type: text/event-stream,告知客户端响应为一个持续的数据流。连接将保持打开状态,使服务器可连续发送数据片段,实现实时信息推送。
SSE 的优势
在需要服务器向客户端持续推送数据的场景中,WebSocket 虽是全双工通信的通用方案,但 SSE 在单向数据流场景中具备显著优势:
- 协议轻量:基于标准 HTTP,无需额外协议升级,兼容性与部署成本更低。
- 内置重连:支持自动断线重连与消息追踪,简化客户端容错逻辑。
- 文本友好:原生支持 UTF-8 文本流,与 AI 响应等文本场景高度契合。
- 开发简洁 :浏览器端使用标准
EventSourceAPI,接入成本低。
在 AI 回复流式输出这类以服务器推送为主的场景中,SSE 以简洁的实现提供了高效、可靠的解决方案。
服务器如何流式返回数据?
服务器在返回 SSE 数据时,必须满足两个基本要求:内容必须使用 UTF-8 编码 ,且响应头中的 Content-Type 必须设置为 text/event-stream。
data
SSE 数据由遵循特定格式的文本块构成,每个消息以两个换行符 \n\n 结尾。以下是一个标准的多消息响应示例:
text
data: This is the first message.\n\n
data: This is the second message, it
data: has two lines.\n\n
data: This is the third message.\n\n在实际应用中,为了传递结构化数据,我们通常会在 data 字段中嵌入 JSON 字符串。这也是当前端与 AI 服务交互时的常见做法,如下图所示:
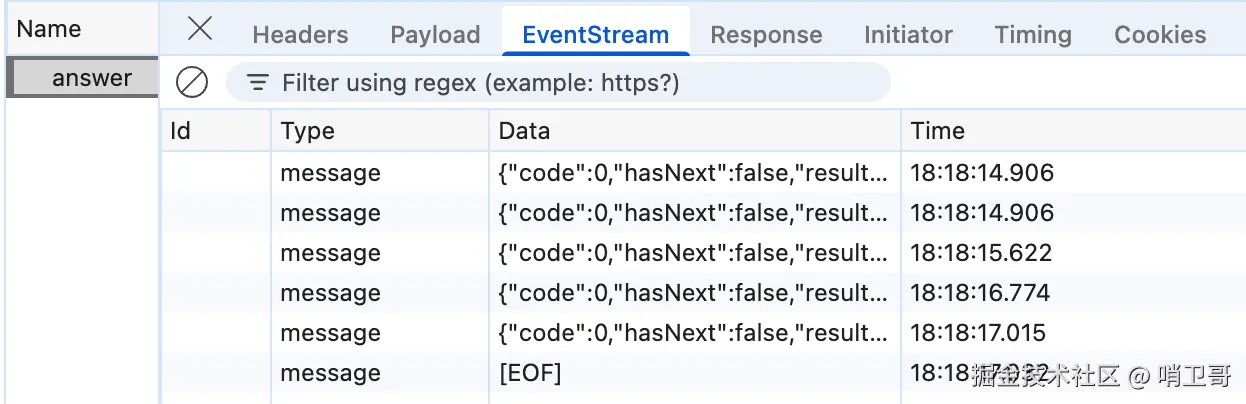
除了核心的 data 字段,SSE 还支持以下关键字段以增强功能:
event
用于定义事件类型。浏览器端可通过 addEventListener() 监听特定事件。若未指定,则默认为 message 事件。
示例:服务器发送自定义 add 事件
text
event: add
data: 113411\n\n客户端可针对此事件进行监听与处理:
javascript
const source = new EventSource(url); // 下文会介绍 EventSource
source.addEventListener('add', addHandler, false);id
用于指定消息的事件 ID,其主要作用是实现断线重连同步。
示例:
text
id: message1
data: This is a message\n\n当连接意外中断时,浏览器会在重新建立的请求头中自动携带 Last-Event-ID: message1,服务器可据此判断断连位置,并发送后续消息,从而保证消息流的连续性。
Demo: Node.js 实现 SSE
理解协议最好的方式就是亲手实现它。下面,我们将创建一个最简单的 SSE 服务器,它会每秒向客户端推送一次当前时间。
第一步:创建并启动服务端
- 将以下代码保存为
server.js。 - 在终端运行
node server.js。
js
const http = require('http');
// 创建 HTTP 服务器
http
.createServer((req, res) => {
const url = req.url;
// SSE 流式响应端点
if (url === '/stream') {
// 设置 SSE 响应头
res.writeHead(200, {
'Content-Type': 'text/event-stream', // SSE 的 MIME 类型
'Cache-Control': 'no-cache', // 禁止缓存
Connection: 'keep-alive', // 保持长连接
'Access-Control-Allow-Origin': '*', // 允许跨域(生产环境建议指定具体域名)
});
// SSE 格式:retry 指定重连间隔(毫秒)
res.write('retry: 10000\n');
// 发送自定义事件名称的消息
res.write('event: connecttime\n');
res.write(`data: ${new Date().toISOString()}\n\n`);
// 发送默认事件的消息(客户端通过 onmessage 接收)
res.write(`data: ${new Date().toISOString()}\n\n`);
// 每秒向客户端推送当前时间
const interval = setInterval(() => {
res.write(`data: ${new Date().toISOString()}\n\n`);
}, 1000);
// 监听客户端断开连接事件,清理定时器
req.socket.on('close', () => {
clearInterval(interval);
});
}
})
.listen(8844, '127.0.0.1');第二步:在浏览器中验证
服务启动后,点击这个 在线测试页面,你会看到页面上开始每秒打印出服务器推送的时间。
第三步:观察与理解
此时,打开浏览器的 开发者工具(F12) ,切换到 网络(Network) 面板。刷新测试页,你应该能看到一个对 stream 的请求,其类型为 eventsource。

点击该请求,查看详细内容。在 "事件流(EventStream)" 或 "响应(Response)" 标签页中(取决于浏览器),你将看到持续流入的、格式规整的 SSE 数据:
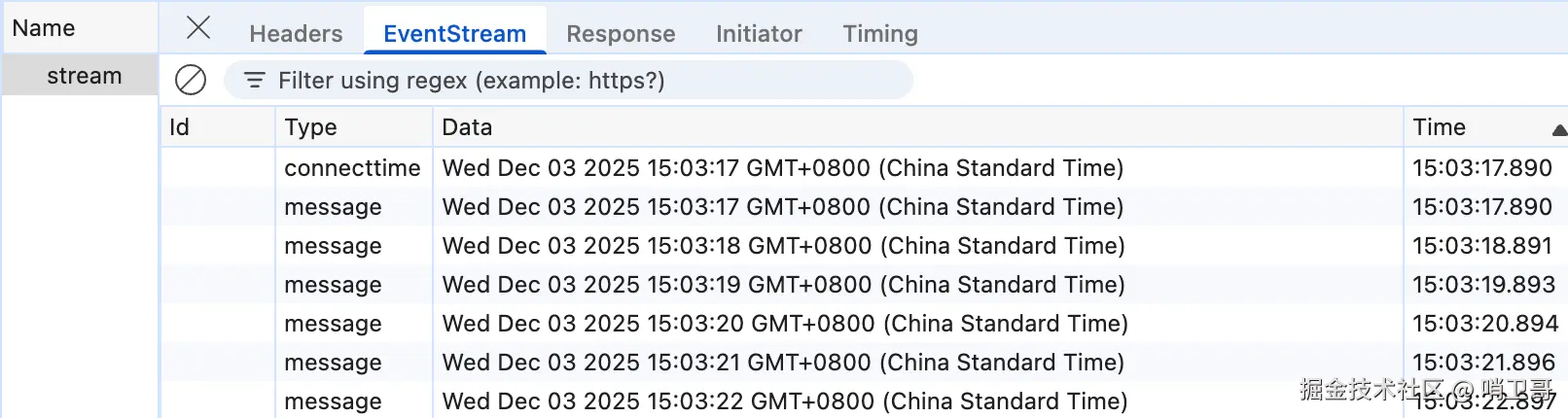
请注意观察:
- 连接建立时,服务器先发送了一个
connecttime事件(事件类型event: connecttime)。 - 随后,服务器以默认的
message事件 (未显式指定event:字段)持续每秒推送一条时间戳数据。
通过亲手运行和观察,不仅验证了 SSE 协议的格式规范,也直观地理解了事件类型(event)和数据块(data)是如何在流中组织和传输的。这正是我们前端接收并处理 AI 流式响应的基础。接下来,我们就来看看前端如何建立并处理这样的 SSE 连接。
前端如何建立 SSE 连接?
在理解了服务端的实现后,我们来看前端如何接收并处理 SSE 数据流。浏览器为此提供了原生的 EventSource接口,它是与服务器发送事件通信的标准方式。
创建连接:EventSource 构造函数
要建立 SSE 连接,只需创建一个 EventSource 实例,传入服务器端点的 URL:
js
const eventSource = new EventSource('http://127.0.0.1:8844/stream');这本质上是一个 HTTP GET 请求,与我们熟悉的 fetch 或 XMLHttpRequest 没有太大区别。
上面的url可以与当前网址同域,也可以跨域。跨域时,可以指定第二个参数,打开withCredentials属性,表示是否一起发送 Cookie。
js
var source = new EventSource(url, { withCredentials: true });EventSource 实例属性和方法
js
console.log(eventSource.readyState); // 1 (连接已建立)
// 对应的常量值
EventSource.CONNECTING === 0; // 连接中或重连中
EventSource.OPEN === 1; // 连接已打开
EventSource.CLOSED === 2; // 连接已关闭这个属性是只读的,你可以通过监听状态变化来优化用户体验,比如在连接建立时显示"已连接",在重连时显示"重新连接中..."。
当不再需要接收服务器推送时,可以主动关闭连接:
js
// 关闭SSE连接
eventSource.close();
// 关闭后,readyState会变为2
console.log(eventSource.readyState); // 2 (EventSource.CLOSED)这在组件卸载、页面跳转或用户主动停止接收时非常有用。
EventSource 事件
js
// 1. 连接成功建立时触发
eventSource.onopen = (event) => {
console.log('连接已建立', event);
};
// 2. 接收到默认消息(未指定event类型的消息)时触发
eventSource.onmessage = (event) => {
console.log('收到消息:', event.data);
// 在我们的Demo中,这里会每秒打印一次时间戳
};
// 3. 发生错误时触发(包括连接错误、解析错误等)
eventSource.onerror = (error) => {
console.error('SSE连接错误:', error);
// 注意:浏览器会自动尝试重连,无需手动处理
};除了默认的 message 事件,我们还可以监听服务器发送的自定义事件:
js
// 监听我们Demo中发送的'connecttime'事件
eventSource.addEventListener('connecttime', (event) => {
console.log('连接时间:', event.data);
// 输出:"连接时间: 连接建立于 2024-01-15T10:30:00.000Z"
});EventSource 的局限性
尽管 EventSource 简单易用,但它有一些限制:
- 仅支持 GET 请求:无法使用 POST 或其他方法,参数长度有限
- 无法自定义请求头 :这意味着无法携带标准的
Authorization: Bearer <token>等认证信息,限制了其在需要鉴权的API场景中的应用 - 自动重连机制不可配置:虽然方便,但有时需要更精细的控制
对于需要更多控制权的场景(如需要发送认证头、使用POST方法等),我们可以使用 fetch() API 配合流式处理来接收 SSE,这也是现代 AI 应用中更常见的做法。接下来,我们将深入探讨这种方法。
处理数据流:JS 中的流式处理能力
💡 前置知识提示:本节将介绍流式处理所需的 JavaScript 基础。如果你已熟悉迭代器、生成器和 TextDecoder,可快速浏览或跳过。
严格来说,下面这些JS API本身并非专为"流式处理"而生,但它们组合起来构成了处理流数据的强大能力。
我们可以将其视为一个处理管道:首先需要理解数据流的基础协议 (迭代器/生成器);然后掌握浏览器中网络数据流 的具体实现(ReadableStream)及其消费语法 (for await...of);最后,还需要一个工具将原始的二进制流转换为我们需要的文本(TextDecoder)。
下面,我们就按照这个管道的顺序,逐一拆解。
数据流的基础:迭代器与生成器
在理解 JavaScript 中的流式处理之前,我们需要先掌握两个基础概念:迭代器(Iterator) 和生成器(Generator) 。它们是 ES6 引入的现代化数据处理机制,构成了流式处理的底层基础。
什么是迭代器?
迭代器是一个实现了 Iterator 接口 的对象。该接口要求对象必须提供 next() 方法,每次调用返回一个包含两个属性的对象:
value:迭代序列中的下一个值done:布尔值,表示序列是否结束
js
// 简单的迭代器示例
const simpleIterator = {
data: [1, 2, 3],
index: 0,
next() {
if (this.index < this.data.length) {
return { value: this.data[this.index++], done: false };
}
return { value: undefined, done: true };
}
};
console.log(simpleIterator.next()); // { value: 1, done: false }
console.log(simpleIterator.next()); // { value: 2, done: false }
console.log(simpleIterator.next()); // { value: 3, done: false }
console.log(simpleIterator.next()); // { value: undefined, done: true }异步迭代器:处理异步数据流
当数据是异步产生时(如网络请求、定时器),我们需要异步迭代器。它与普通迭代器类似,但有两点关键区别:
- 对象需要实现
[Symbol.asyncIterator]()方法而非[Symbol.iterator]() next()方法返回一个 Promise,而不是直接返回{value, done}
js
// 异步迭代器示例
const asyncIterator = {
data: [1, 2, 3],
index: 0,
[Symbol.asyncIterator]() {
return {
next: () => {
if (this.index < this.data.length) {
// 返回Promise,模拟异步获取数据
return new Promise(resolve => {
setTimeout(() => {
resolve({ value: this.data[this.index++], done: false });
}, 100);
});
}
return Promise.resolve({ value: undefined, done: true });
}
};
}
};关键点 :异步迭代器的 next() 返回的是 Promise<{value, done}>,这使得它能够被 for await...of 循环消费。这正是我们后续处理网络流(如SSE响应)所依赖的底层协议。
可迭代对象
任何实现了 [Symbol.iterator]() 方法的对象都是可迭代对象。这个方法必须返回一个迭代器。
这里的 Symbol.iterator 是 ES6 引入的一个特殊 Symbol,用于定义对象的默认迭代器。[Symbol.iterator] 使用了计算属性名语法,而 [Symbol.iterator]() 是 ES6 中函数属性的简写形式。
js
const iterableObject = {
values: ['a', 'b', 'c'],
[Symbol.iterator]() {
let index = 0;
return {
next: () => {
if (index < this.values.length) {
return { value: this.values[index++], done: false };
}
return { value: undefined, done: true };
}
};
}
};
// 使用 for...of 遍历可迭代对象
for (const value of iterableObject) {
console.log(value); // 依次输出: 'a', 'b', 'c'
}for...of 循环就是基于这个协议工作的:它会自动调用对象的 [Symbol.iterator]() 方法获取迭代器,然后反复调用 next() 直到 done 为 true。
生成器:惰性数据源
生成器是 ES6 引入的特殊函数,使用 function* 声明。它返回一个生成器对象,该对象同时符合可迭代对象和迭代器的协议。
js
function* numberGenerator() {
yield 1;
yield 2;
yield 3;
}
const generator = numberGenerator();
console.log(generator.next()); // { value: 1, done: false }
console.log(generator.next()); // { value: 2, done: false }
console.log(generator.next()); // { value: 3, done: false }
console.log(generator.next()); // { value: undefined, done: true }
// 生成器对象也是可迭代的
for (const num of numberGenerator()) {
console.log(num); // 依次输出: 1, 2, 3
}生成器的 yield 关键字具有暂停和恢复 执行的能力。每次调用 next(),函数会执行到下一个 yield 并暂停,直到再次被调用。这实现了惰性求值(Lazy Evaluation) ------数据只在需要时才产生。
js
function* lazySequence() {
console.log('开始生成数据');
yield '第一个数据';
console.log('继续生成...');
yield '第二个数据';
console.log('最后生成...');
yield '第三个数据';
}
const lazyGen = lazySequence();
// 注意观察控制台输出时机
console.log('准备获取数据');
const first = lazyGen.next(); // 输出: "开始生成数据"
console.log(first.value); // "第一个数据"
console.log('做一些其他事情');
const second = lazyGen.next(); // 输出: "继续生成..."
console.log(second.value); // "第二个数据"网络数据流:ReadableStream 的两种消费方式
当使用 fetch() 发起网络请求时,响应对象的 body 属性是一个 ReadableStream(可读流)。这个流实现了异步迭代器协议,因此我们可以用两种方式消费它:
js
// 发起请求,获取响应
const response = await fetch('/api/stream');
// 获取响应体的流
const stream = response.body;方式一:使用 getReader() 手动读取
这是最基础的方式,提供了完全的控制权:
js
// 获取流读取器
const reader = stream.getReader();
// 典型的数据读取模式
while (true) {
const { done, value } = await reader.read();
if (done) {
// 流已结束
break;
}
// value 是一个 Uint8Array(字节数组)
console.log('收到数据块:', value);
}getReader()返回一个 ReadableStreamDefaultReader 对象- reader.read() 返回
Promise<{done, value}> value是Uint8Array类型,包含原始字节数据- 需要手动管理循环和资源释放
方式二:使用 for await...of 自动迭代
更现代、简洁的方式是直接使用 for await...of 循环遍历 ReadableStream 本身,因为流对象已经实现了异步迭代器协议。
js
// 直接使用 for await...of 遍历 ReadableStream
for await (const chunk of stream) {
// chunk 同样是 Uint8Array 数据块
console.log('收到数据块:', chunk);
}for await...of 是基于异步迭代器协议的语法糖。当用于遍历 ReadableStream 时,它会在内部自动创建读取器、调用 read() 方法,并在循环结束时妥善处理资源的释放。
这种"来一块,处理一块"的消费模式,与异步生成器的工作方式如出一辙。我们可以用一个异步生成器来模拟 AI 的流式响应:
js
// 模拟 AI 流式响应:每秒生成一个 token
async function* mockAIStream() {
const tokens = ["思考", "中", ",", "这", "是", "一个", "流式", "响应"];
for (const token of tokens) {
await new Promise(resolve => setTimeout(resolve, 100)); // 模拟 AI 处理延迟
yield token; // 每次只生成一个 token
}
}
// 消费流式数据:来一点,处理一点
async function processStream() {
for await (const token of mockAIStream()) {
console.log(`收到: ${token}`);
// 这里可以实时渲染到页面,实现"逐词(Token)打印"效果
}
}
// 在控制台执行 processStream() 试试解析二进制流:TextDecoder
网络传输的本质是二进制数据。当我们需要将这些字节转换为字符串时,会遇到一个关键问题:数据块(chunk)的边界,可能与字符的编码边界不一致。
JavaScript 的 TextDecoder 就是为解决此问题而生。它能将字节流按指定编码(如 UTF-8)解码为字符串。
为什么普通的解码会出问题?
以中文字符"你"为例。在 UTF-8 编码中,它由 三个字节 构成,对应的十六进制值是 [0xE4, 0xBD, 0xA0]。
想象一下网络传输场景:服务器发出这个字符的字节,但可能因为网络分包,前两个字节 [0xE4, 0xBD] 到达了第一个数据块,而最后一个字节 [0xA0] 落在了第二个数据块。
如果对第一个块单独进行解码,由于缺少构成一个完整字符的必要字节,解码器要么输出乱码(�),要么直接抛出错误。这显然不是我们想要的。
解决方案:流式解码(Stream Decoding)
TextDecoder.decode() 方法的第二个参数有一个关键的 stream 选项。当设置为 true 时,解码器会进入"流模式":
- 它会记住(缓冲)当前不完整的字节序列,而不是强行解码。
- 等待后续数据块到来,与缓冲的字节拼凑成一个完整的字符后,再一并输出。
这样,无论网络如何分割数据,我们都能在应用层获得完整、正确的字符串。
js
const decoder = new TextDecoder('utf-8');
// 模拟被分割到两个网络数据块中的字符
const chunk1 = new Uint8Array([0xe4, 0xbd]); // 这是"你"字的前2/3
const chunk2 = new Uint8Array([0xa0, 0xe5, 0xa5, 0xbd]); // 这是"你"的最后1/3,以及整个"好"字
// 处理第一块:告知解码器"数据还没完,先存着"
let part1 = decoder.decode(chunk1, { stream: true });
console.log(part1); // 输出:"" (空字符串,解码器在等待)
// 处理第二块(也是最后一块):告知解码器"数据到结尾了,把攒着的都解出来"
let part2 = decoder.decode(chunk2, { stream: false });
console.log(part2); // 输出:"你好" (两个完整字符被正确解码)至此,我们已经掌握了流式处理的完整技术链条:从迭代器/生成器 这一底层概念,到ReadableStream 和for await...of这对获取与消费网络流的黄金组合,再到正确解码二进制数据的TextDecoder。
在下一节的实战中,我们将把这些知识组合起来,真正实现一个能够"逐词(Token)打印"的流式AI聊天应用。
实战:构建完整的流式聊天响应
初始代码
让我们基于上一章 《前端玩转 AI 应用开发|30行代码实现聊天机器人🤖》 中的代码进行优化,实现流式输出:
js
import readline from 'readline';
const API_KEY = process.env.API_KEY;
const messages = [
{
role: 'system',
content:
'你是一个前端高手,能帮我解答前端开发中遇到的问题。我希望你的回答精简干练有技术范',
},
];
// 主对话循环
while (true) {
// 用户输入
const input = await new Promise((resolve) => {
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
rl.question('用户: ', (msg) => {
resolve(msg);
rl.close();
});
});
messages.push({ role: 'user', content: input });
// 调用AI助手
const res = await fetch(
'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${API_KEY}`, // 使用API_KEY进行授权
},
body: JSON.stringify({ model: 'qwen-plus', messages }),
}
);
// 解析AI助手的回复
const reply = (await res.json()).choices[0].message.content;
messages.push({ role: 'assistant', content: reply });
console.log('AI助手:', reply + '\n');
}代码分为三个主要模块:
- 用户输入 :通过
readline获取用户问题 - 调用AI助手:向 API 发送请求
- 解析回复:等待完整响应并解析结果
显然,要实现流式输出的核心工作集中在 第三部分 。我们需要将同步的 res.json() 解析改为异步的流式处理,让 AI 的回答能够"逐词(Token)"实时显示。这正是我们将要进行的改造。
启用流式响应并观察原始数据
首先,我们需要在请求中启用流式响应。将 stream: true 添加到请求体中:
js
// 调用AI助手
const res = await fetch(
'https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${API_KEY}`,
},
body: JSON.stringify({
model: 'qwen-plus',
messages,
stream: true, // 启用流式响应
}),
}
);现在 API 将以 SSE 格式返回数据流,而不是一次性返回完整 JSON。为了理解数据格式,我们首先观察原始数据:
js
// 解析AI助手的回复
console.log('AI助手: ');
// 获取响应体的 reader,用于读取流数据
const reader = res.body.getReader();
// 循环读取数据块
while (true) {
// 读取下一个数据块
const { done, value } = await reader.read();
// 如果流结束,退出循环
if (done) {
break;
}
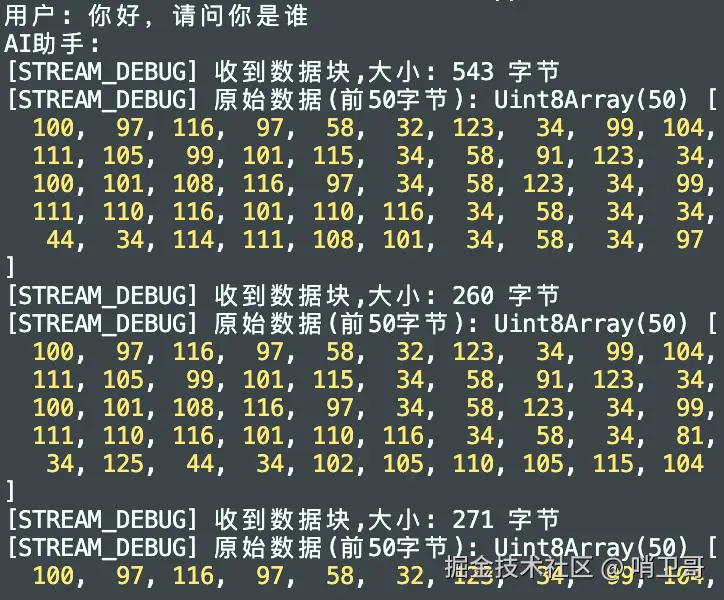
// 打印原始二进制数据块信息
console.log(`[STREAM_DEBUG] 收到数据块,大小: ${value.length} 字节`);
console.log(`[STREAM_DEBUG] 原始数据(前50字节):`, value.slice(0, 50));
}运行代码后,可以看到类似下图的二进制数据返回:
使用 TextDecoder 解码二进制数据为文本
现在我们使用上一章学到的 TextDecoder,将二进制数据转换为可读的文本:
js
console.log('AI助手: ');
// 创建 TextDecoder 用于解码二进制数据
const decoder = new TextDecoder('utf-8');
// 获取响应体的 reader,用于读取流数据
const reader = res.body.getReader();
// 循环读取数据块
while (true) {
const { done, value } = await reader.read();
if (done) {
break;
}
// 关键步骤:使用 TextDecoder 解码二进制数据为文本
// stream: true 表示这是流式解码,会保留不完整的字符等待下一块数据
const text = decoder.decode(value, { stream: true });
console.log('[STREAM_DEBUG] 解码后的文本:');
console.log(text);
console.log('[STREAM_DEBUG] ===== 数据块结束 =====\n');
}对比第一步和第二步的输出,你会发现:
- 第一步 :看到的是
Uint8Array(50) [100, 97, 116, 97, ...]这样的数字 - 第二步 :看到的是
data: {...}这样可读的文本

解析 SSE 格式,提取 AI 回复内容
现在我们已经拿到了可读的文本流。从上面的截图可以看到,每个数据块(chunk)都包含若干行完整、独立的 SSE 消息,每行都以 data: 开头。
我们的任务变得非常清晰 :从解码后的文本中,准确拆出每一行 data: 消息,并提取其 JSON 中包含的 AI 回复片段(Token)。
js
// 解析AI助手的回复
console.log('AI助手: ');
const decoder = new TextDecoder('utf-8');
const reader = res.body.getReader();
// 循环读取数据块
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 解码二进制数据为文本
const text = decoder.decode(value, { stream: true });
// 第三步:解析 SSE 格式数据
// SSE 消息以换行符分隔,按行处理
const lines = text.split('\n').filter((line) => line.trim());
for (const line of lines) {
// 提取 data: 开头的内容
if (line.startsWith('data: ')) {
const data = line.slice(6); // 去掉 "data: " 前缀
// 打印提取出的数据
console.log(data);
}
}
}这段代码执行后,我们将看到如下图所示的输出------干净、完整的 JSON 字符串。这些 JSON 对象包含了 AI 返回的每个文本片段,是我们实现逐字输出的关键数据源:

使用 for await...of 简化流处理并实现逐 token 输出
经过前三步的分解,我们对流式处理的每个环节都有了清晰理解。现在,让我们将这些知识整合起来,用更现代的 for await...of 语法重构代码,并最终实现 AI 回复的"逐词"实时输出。
对比之前的 while 循环,for await...of 让流式处理代码更加简洁直观:
js
// 解析AI助手的回复
process.stdout.write('AI助手: ');
// 创建 TextDecoder 用于解码二进制数据
const decoder = new TextDecoder('utf-8');
// 用于累积完整回复
let reply = '';
// 使用 for await...of 遍历流数据 (更简洁的写法)
for await (const chunk of res.body) {
// 解码二进制数据为文本
const text = decoder.decode(chunk, { stream: true });
// 解析 SSE 格式并提取 AI 回复内容
const lines = text.split('\n').filter((line) => line.trim());
for (const line of lines) {
// 提取 data: 开头的内容
if (line.startsWith('data: ')) {
const data = line.slice(6); // 去掉 "data: " 前缀
// 处理结束标记
if (data === '[DONE]') {
continue;
}
// 解析 JSON 数据
try {
const json = JSON.parse(data);
// 提取 AI 返回的文本片段 (token)
const token = json.choices[0]?.delta?.content || '';
// 实现逐字输出效果
process.stdout.write(token);
// 累积完整回复
reply += token;
} catch (error) {
console.error('\nJSON 解析错误:', error.message);
}
}
}
}
// 输出换行,结束本次回复
process.stdout.write('\n\n');实现逐字输出效果后,AI的回复将像下图一样实时呈现,大幅提升了交互体验:

参考链接
- 服务器发送事件 - HTML标准
- Server-Sent Events 教程 - 阮一峰的网络日志
- MDN Web Docs
- 《JavaScript高级程序设计》