0.YOLO简介
YOLO(You only look once),是ultralytics公司发布的一个计算机视觉检测框架。
与目前流行的视觉大模型(VLM)相比,YOLO具有识别快,占用资源低的特点,在目标追踪等场景中具有广泛的应用。
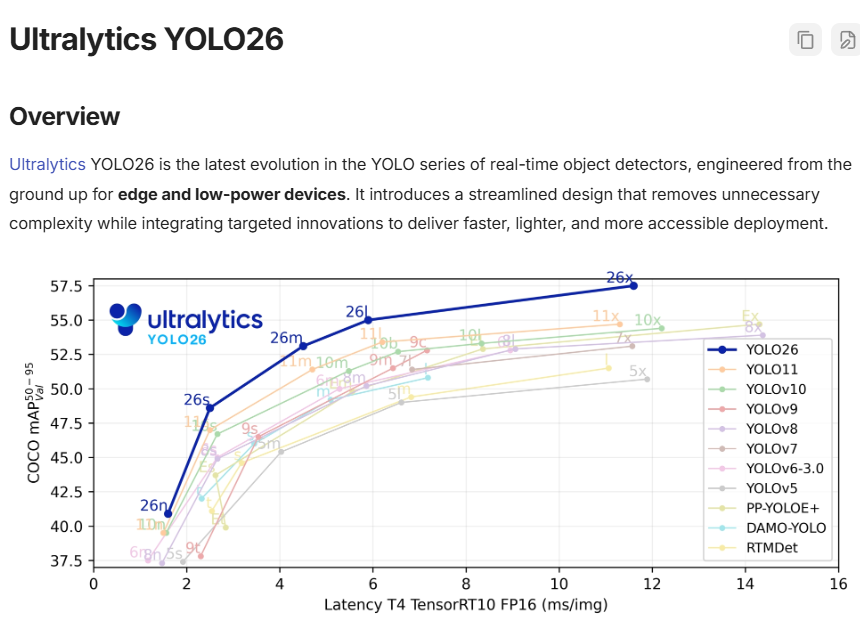
截止目前的YOLO最新版本为YOLO26,在yolo26版本中可以很方便的在边缘低功耗上设备都能运行。
通过本文,将学会如何使用YOLO进行数据的训练与识别,并最终实现一个车牌检测的小示例。最终示例效果如下:

1. YOLO模型的选择
根据任务类型,YOLO分为以下几种任务类型:
- real-time detection,实时检测。
- segmentation,实例分割。
- classification,分类。
- pose estimation,姿态估计。
- oriented object detection,旋转检测 。
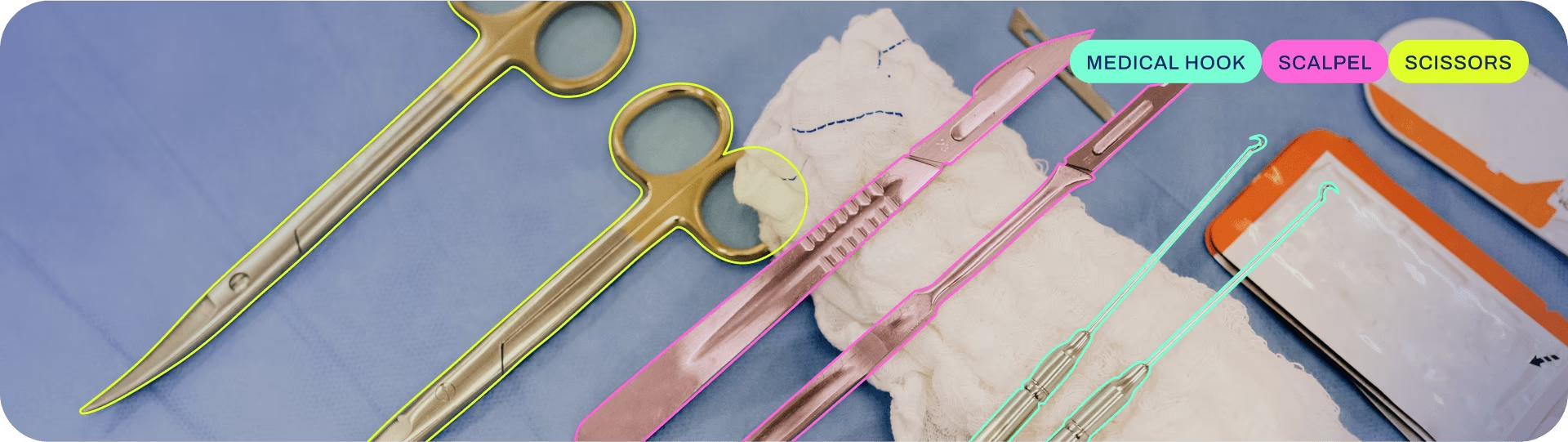
下图依次为每个任务类型对应的图片示例:




又根据yolo的模型文件大小,分为n、s、m、l、x后缀,如:
- yolo26n.pt,Nano。极致轻量化。参数最少,推理速度最快,适合手机、嵌入式开发板,如树莓派。
- yolo26s.pt,Small。 速度与精度的平衡点。适合一般的实时视频流处理。
- yolo26m.pt,Medium。 针对中等复杂场景,性能更稳健,适合一般的 PC 端或边缘计算盒子。
- yolo26l.pt,Large。高精度型号。适合对准确率要求极高、硬件资源(显存)充足的场景。
- yolo26x.pt,Extra Large。精度上限,参数量最大,通常用于学术竞赛或离线高精度分析。
在模型的选择时,我们可以根据任务与设备类型,选择一个最适合的模型。任务的耗时可参考YOLO的官方说明:performance-metrics。
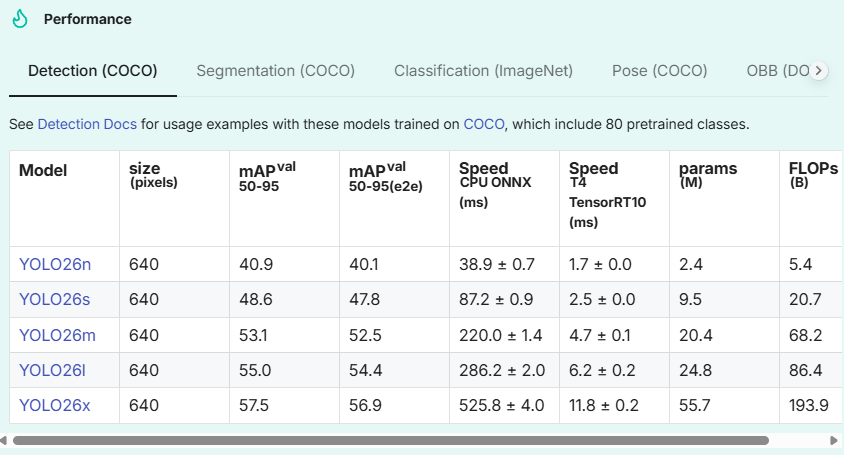
以上图中的YOLO26n ,640像素图像 为例,Speed CPU ONNX 代表yolo26n模型在cpu 上的推理速度为38ms 左右,在Speed T4 TensorRT10 (类似RTX 2060 显卡)中的推理速度为1.7ms。所以,YOLO在GPU显卡上会快得多。
2.YOLO预训练模型检测
前面提到的YOLO官方模型是通用模型,即预训练模型(Pretrained Models),直接使用预训练模型也可以进行识别。这里先做个演示。
参考YOLO官方的Conda Quickstart Guide可以快速体验一下YOLO预训练模型的识别效果。
执行以下命令安装yolo所需依赖包:
conda create --name ultralytics-env python=3.11 -y
conda activate ultralytics-env
conda install -c conda-forge ultralyticsconda推荐使用Miniconda ,下载地址为:https://www.anaconda.com/docs/getting-started/miniconda/main。
如果有显卡,可以再执行以下命令安装cuda,我这里没有GPU就不执行了(可选)
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
再准备好对应的图片和预训练模型,运行以下代码:
python
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
results = model("images/1.png")
results[0].show()上面的yolo26n.pt 从此路径下载:https://docs.ultralytics.com/tasks/detect/#models
项目结构截图如下:
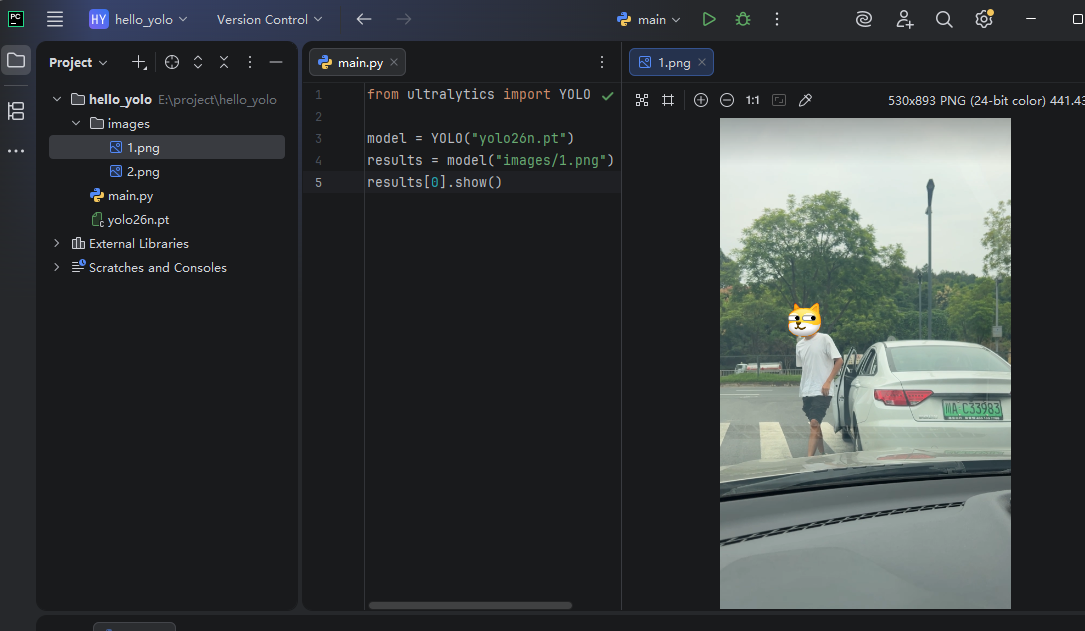
运行结果为:
image 1/1 E:\project\hello_yolo\images\1.png: 640x384 1 person, 2 cars, 55.4ms
Speed: 2.2ms preprocess, 55.4ms inference, 0.3ms postprocess per image at shape (1, 3, 640, 384)

从运行结果可以看出,YOLO的预训练模型对于人、车 这些信息的识别 是可以办到的,但我的需求是要识别出更细致的 信息------如车牌 ,这时单靠预训练模型就力不从心了。
YOLO预训练模型支持的类别清单见此链接:https://docs.ultralytics.com/datasets/detect/coco/#dataset-yaml,共80种。
TIPS:如果上面的安装方式报错,也可使用pip的方式安装YOLO,详细命令为:
conda deactivate
conda remove --name ultralytics-env --all -y
conda create --name ultralytics-env python=3.11 -y
conda activate ultralytics-env
# 如果没显卡(CPU版):
conda install pytorch torchvision torchaudio cpuonly -c pytorch -y
pip install ultralytics
# (可选)配置代理加速
conda config --set proxy_servers.http http://127.0.0.1:7078
conda config --set proxy_servers.https http://127.0.0.1:7078
# (可选)检查是否配置成功
conda config --show proxy_servers另外,也可以使用yolo源码的方式进行安装。命令如下:
python
pip install git+https://github.com/ultralytics/ultralytics.git
# 无法访问github可以以下命令替换:
pip install git+https://gitee.com/monkeycc/ultralytics.git3.YOLO数据标注与训练
为了让YOLO能识别出图片中的车牌,我可以对YOLO的模型进行训练,以满足我们期望的特定场景。
对YOLO模型的训练,一般在基础预训练模型的基础上进行。
3.1 数据标注
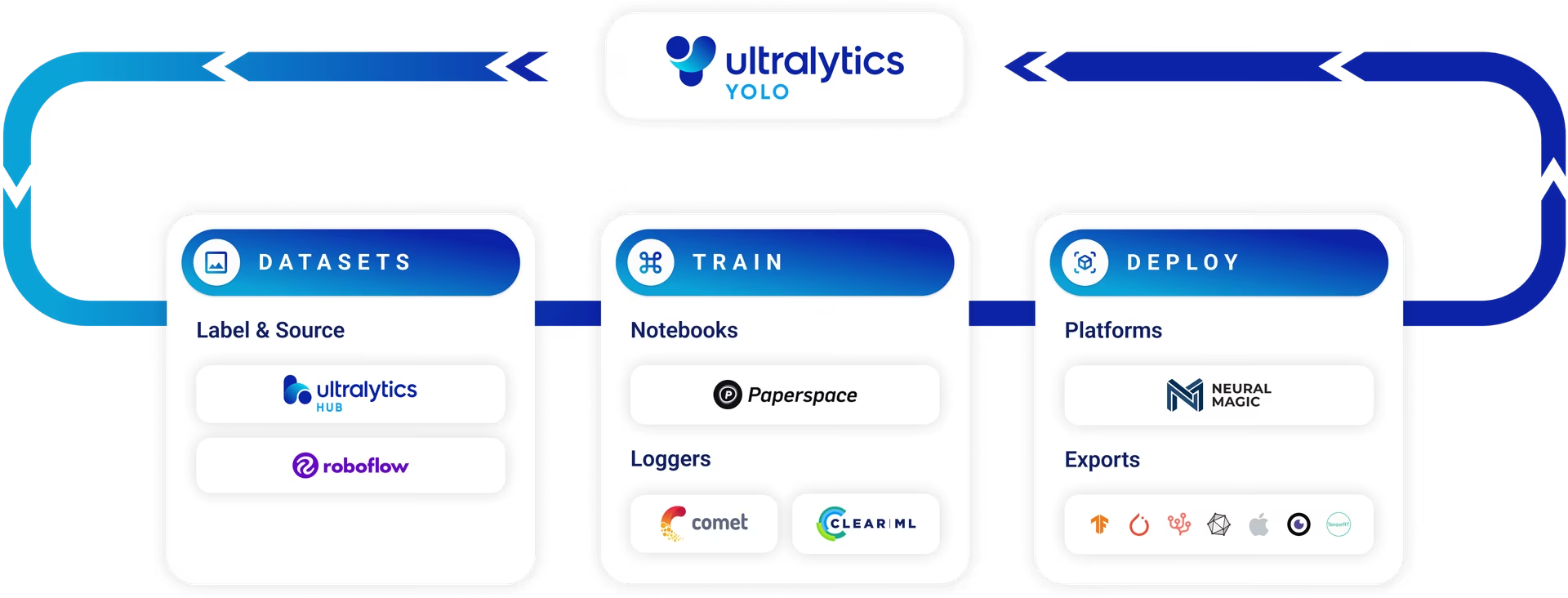
在训练模型前,我们需要提前准备好已标注好的数据集,以能让YOLO在训练的过程中能评估模型的质量。
数据标注这个过程是一个烦琐且枯燥的过程,它的过程就是使用诸如Label Studio、CVAT、Labelme、LabelImg、makesense之类的数据标注工具对原始图片进行拖拽选中目标区域图像并打好标签。YOLO官方的标注示例如下图:
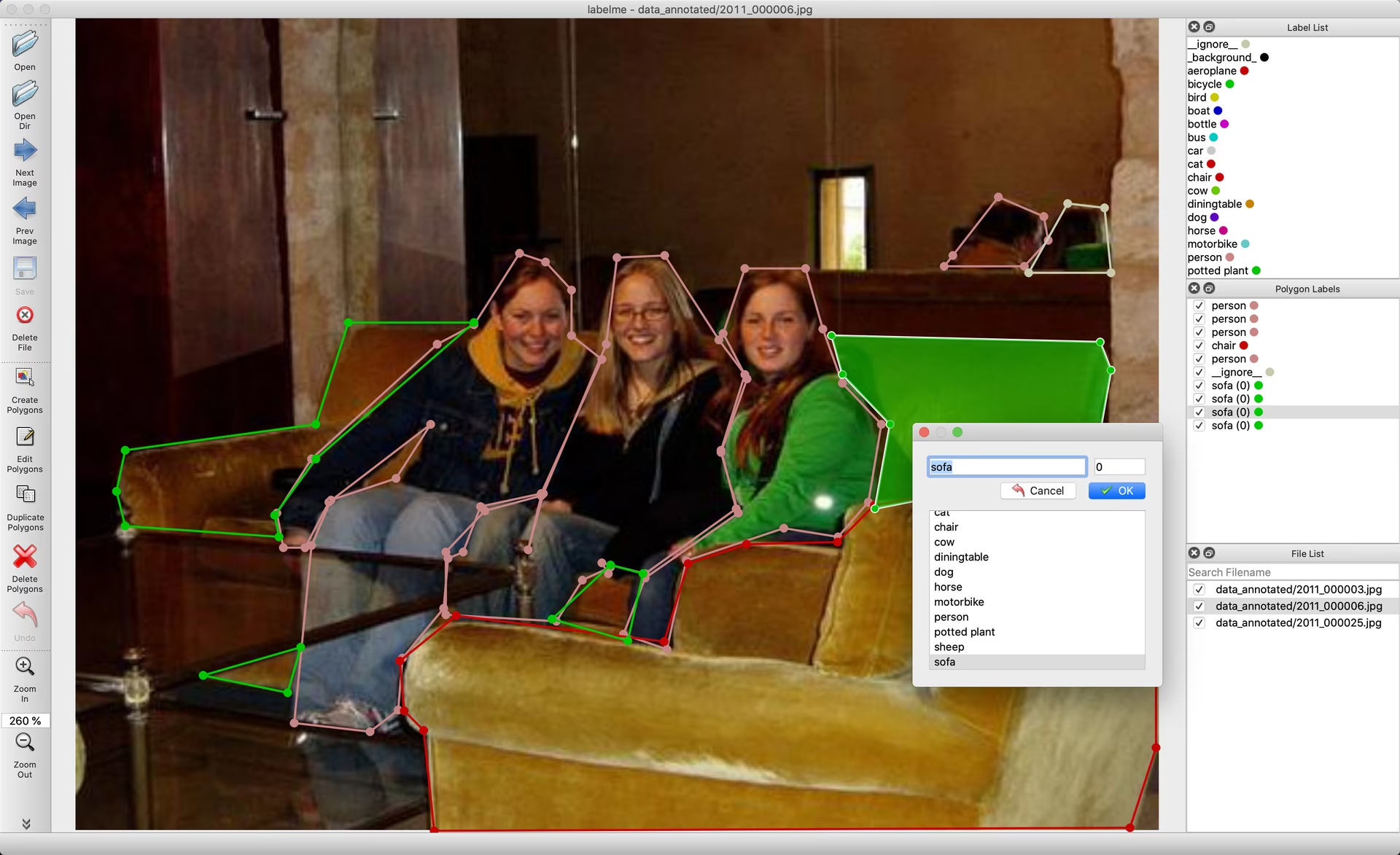
除了使用自行标注的数据集进行标注外,我们也可以使用已经标注好的数据集 直接拿来用。比如本文的要做车牌识别所使用到的数据集为CCPD (Chinese City Parking Dataset)中的车牌图片,地址为:https://github.com/detectRecog/CCPD。
以其中的绿牌车数据集为例,其中包括train、val、test 这3个目录,分别与训练、验证、预测这3个阶段所使用到的数据集对应。
- Train mode: Fine-tune your model on custom or preloaded datasets.
- Val mode: A post-training checkpoint to validate model performance.
- Predict mode: Unleash the predictive power of your model on real-world data.

随机打开数据集中的一个任意文件,以文件名04-90_267-158&448_542&553-541&553_162&551_158&448_542&450-0_1_3_24_27_33_30_24-99-116.jpg 为例,文件名解释如下:
这个长字符串被连字符 - 划分为 7 个功能区:
04:面积比
90_267:水平与垂直角度
158&448_542&553:外接矩形框坐标
541&553_162&551_158&448_542&450:四个顶点精确坐标
0_1_3_24_27_33_30_24:车牌号码索引
99:亮度值
116:模糊度示例:

CCPD字符字典:
provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W',
'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']3.2 车牌检测-模型训练
当我们准备好了训练使用的数据集后,我们就可以进行训练了。
但由于我们这里使用的数据集为CCPD格式的数据集,我们需要将它转为YOLO支持的数据集格式。转换的过程我们可以自己编写对应的程序去处理,也可以直接使用roboflow其他用户处理好的直接下载。
为了方便,我们也直接在roboflow 中搜索ccpd和yolo一键下载 对应的数据集。如:https://universe.roboflow.com/search?q=ccpd+yolo
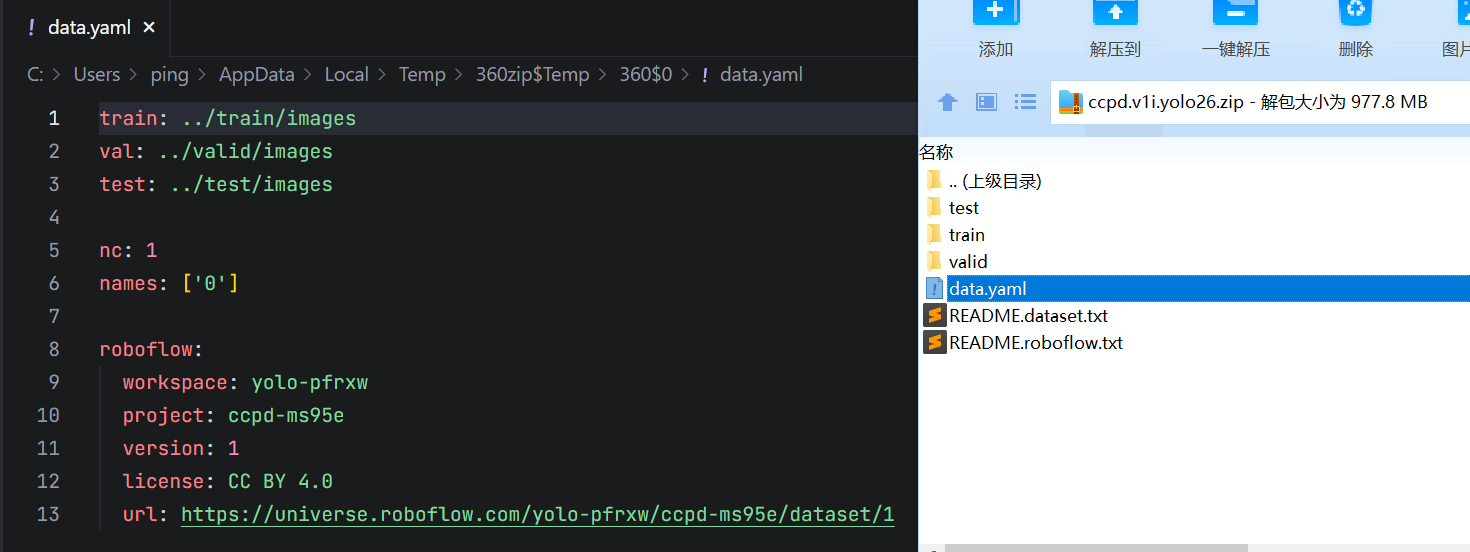
目前在roboflow上只搜到了绿牌没有蓝牌,我这里因为要同时训练蓝牌和绿牌,就自己写了一个脚本自动下载合并数据集。数据集我已经上传到了openxlab(下载速度非常快,自测下载速度可达50M/s+)
- https://openxlab.org.cn/datasets/puhaiyang/CCPD2019
- https://openxlab.org.cn/datasets/puhaiyang/CCPD2020
为了省事,也可以用我写好的脚本,一键下载这两个数据集,再执行一键转换yolo数据集脚本。源码分别为:
- https://github.com/puhaiyang/OpenTrafficFlow/blob/main/download_ccpd.py (一键下载)
- https://github.com/puhaiyang/OpenTrafficFlow/blob/main/convert_all_ccpd_to_yolo.py (一键转换为yolo数据集)
训练代码:
from ultralytics import YOLO
# 加载预训练的 YOLO26 模型
# 你可以使用 yolo26n.pt / yolo26s.pt / yolo26m.pt 等不同规模
model = YOLO("yolo26n.pt") # 推荐从预训练权重开始微调
# 开始训练
results = model.train(
data="YOLO_Data/data.yaml", # 指向你写的 data.yaml
epochs=100, # 训练轮数,根据数据集大小调整
imgsz=640, # 输入图像尺寸
batch=16, # 批大小,可按 GPU 显存调整
device=0, # GPU编号(0表示第一张GPU), 若无GPU可写 "cpu"
project="runs/train", # 输出训练结果路径
name="yolo26_ccpd", # experiment名字
save=True # 保存模型
)
print("训练完成,最佳权重保存在 runs/train/yolo26_ccpd/weights/best.pt")3.3 车牌检测(定位)-训练过程
如果没有显卡,可以找一个显卡租赁平台租。我试过autoDL,这上面显卡类型比较全;也试过智川云的,有4090显卡,价格相比autodl便宜下载速度也很快,值得推荐。
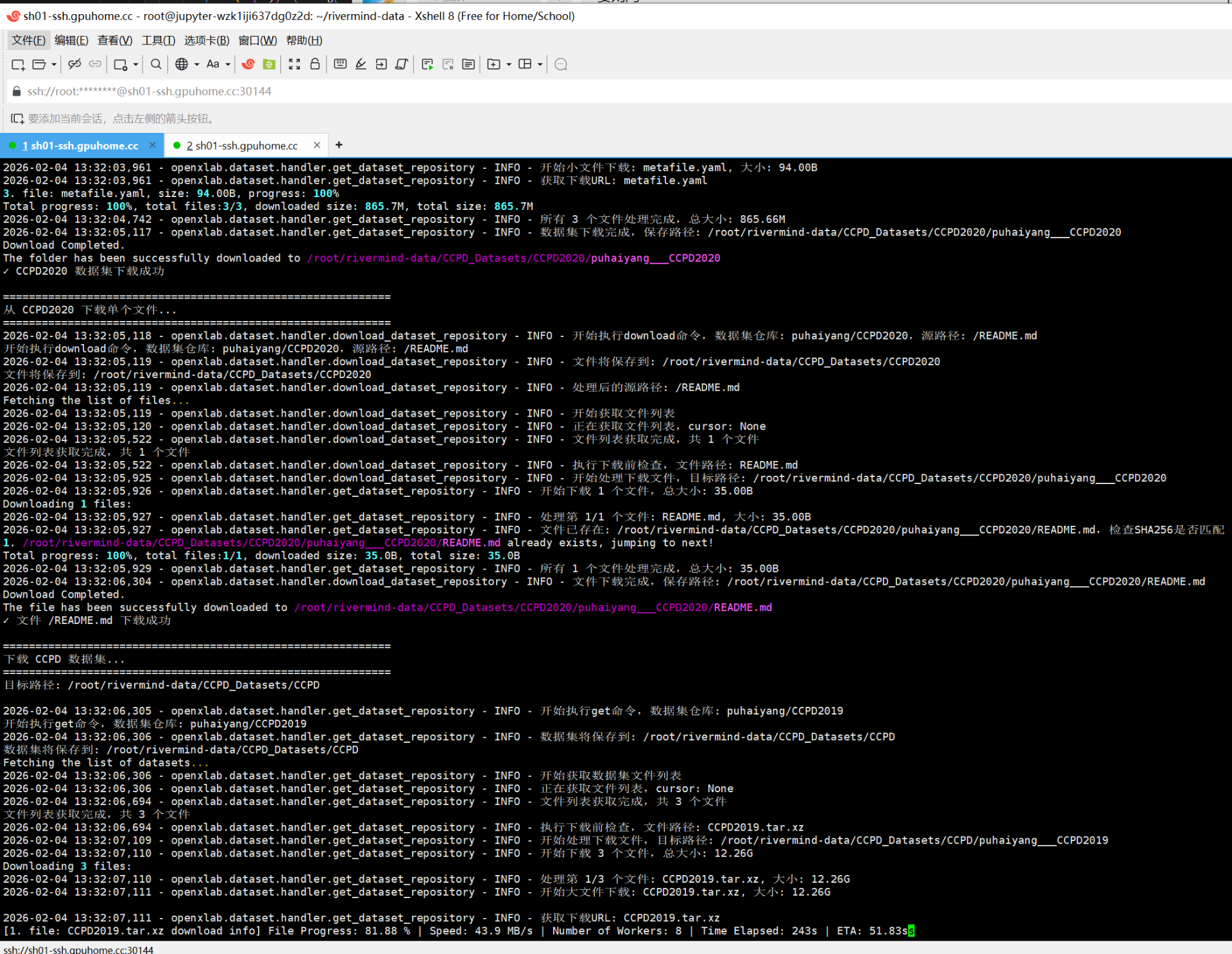
训练过程中的截图(python train_26.py):
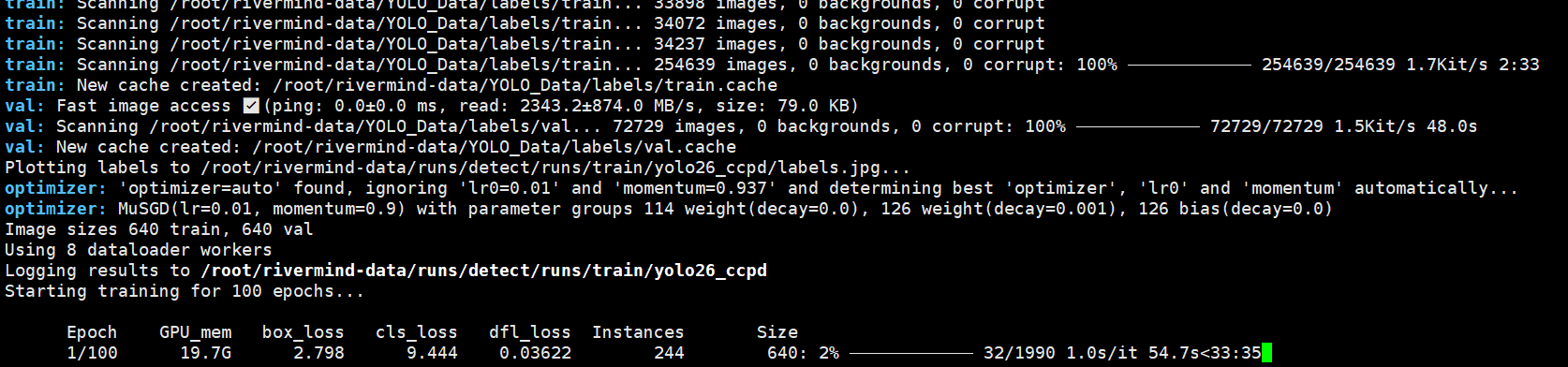
在训练过程中yolo会生成最佳模型best.pt文件,这也是我们所需要得到的最终训练模型文件。
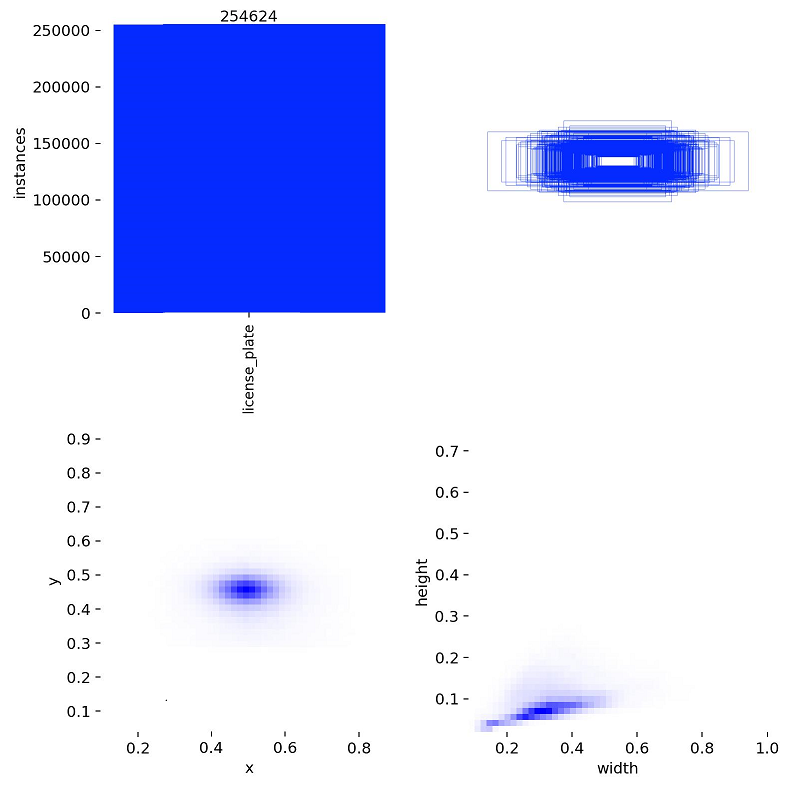
我所使用的训练数据集标注 情况如下图:
以下是我在训练过程中yolo输出的部分训练变化数据:
| epoch | time | train/box_loss | train/cls_loss | train/dfl_loss | metrics/precision(B) | metrics/recall(B) | metrics/mAP50(B) | metrics/mAP50-95(B) | val/box_loss | val/cls_loss | val/dfl_loss |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1988.13 | 0.98098 | 1.20015 | 0.00575 | 0.9819 | 0.98156 | 0.99312 | 0.77792 | 0.84797 | 0.25015 | 0.00769 |
| 2 | 4545.04 | 0.93797 | 0.31494 | 0.00536 | 0.98921 | 0.99071 | 0.99403 | 0.80339 | 0.80841 | 0.22492 | 0.00732 |
| 3 | 7072.12 | 0.96023 | 0.29772 | 0.00548 | 0.98729 | 0.99099 | 0.99337 | 0.79922 | 0.8047 | 0.21976 | 0.0073 |
| 4 | 9623.21 | 0.95604 | 0.29308 | 0.00546 | 0.99422 | 0.99672 | 0.99393 | 0.82567 | 0.77478 | 0.20147 | 0.00697 |
| 5 | 12198 | 0.93325 | 0.28156 | 0.00529 | 0.99549 | 0.99641 | 0.99376 | 0.83084 | 0.75486 | 0.19771 | 0.0068 |
| 6 | 14781.7 | 0.92261 | 0.27651 | 0.00522 | 0.9946 | 0.99653 | 0.99396 | 0.83288 | 0.74802 | 0.20033 | 0.00675 |
| 7 | 17256.4 | 0.91907 | 0.277 | 0.00521 | 0.99666 | 0.99725 | 0.99404 | 0.8354 | 0.74308 | 0.19344 | 0.00667 |
| 8 | 19737.5 | 0.91502 | 0.27464 | 0.00517 | 0.99634 | 0.99761 | 0.99386 | 0.83733 | 0.74054 | 0.19333 | 0.00664 |
| 9 | 22317.7 | 0.91304 | 0.27156 | 0.00516 | 0.99485 | 0.99591 | 0.99408 | 0.83451 | 0.73948 | 0.20596 | 0.00663 |
| 10 | 24825.8 | 0.91299 | 0.27033 | 0.00514 | 0.99292 | 0.99551 | 0.99405 | 0.8341 | 0.73839 | 0.21757 | 0.00662 |
| 11 | 27393.8 | 0.91151 | 0.26998 | 0.00513 | 0.99495 | 0.99622 | 0.99409 | 0.83632 | 0.73551 | 0.21048 | 0.0066 |
在训练过程中,我们可以使用watch -n 1 nvidia-smi命令对显卡数据监控,示例:
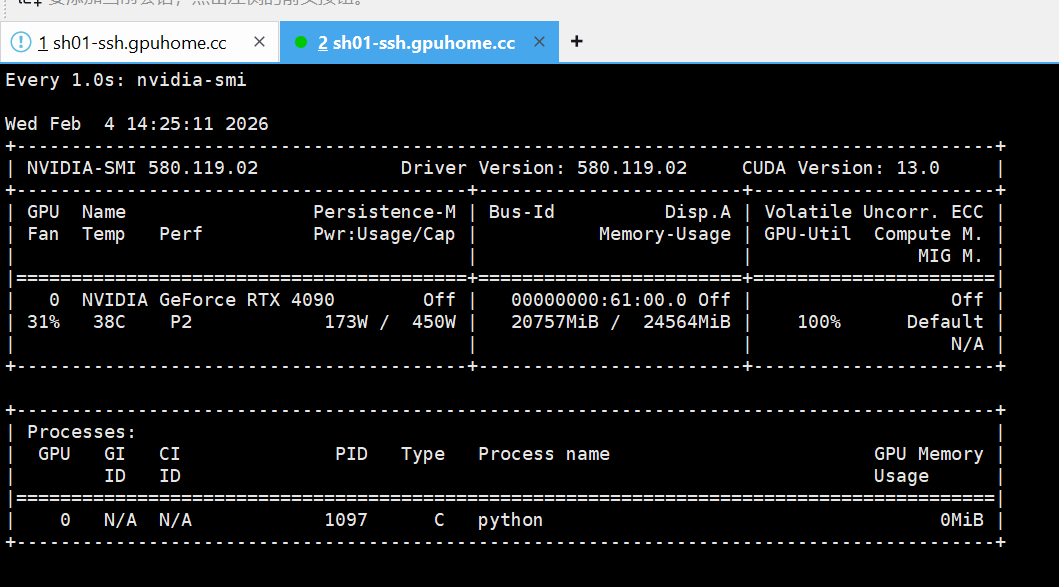
TIPS:如果租的是5090显卡,需要安装pytorch124及以上的版本
4. 车牌号识别
当完成YOLO的训练后,我们写段代码尝试验证一下:
python
from ultralytics import YOLO
model = YOLO("weights/best.pt")
# 将图片路径放在一个列表中
source = ["test_images/1.jpg"]
# 一次性传入列表
results = model(source)
# 遍历结果并显示
for r in results:
r.show()运行结果为:

从运行结果我们可以看出,它成功对车牌的位置进行定位,但还没有对车牌的内容提取成功。
这时,根据需求我们就可以使用各种
- OCR工具,如Tesseract OCR
- OCR模型,如GLM-OCR
- 视觉大模型(VLM),如Qwen-VL
- 自定义神经网络(如LRPNet)
从精确度 与识别速度 两个角度,推荐使用LPRNet,开源地址为:https://github.com/sirius-ai/LPRNet_Pytorch
为了方便理解,使用netron.app渲染一下LPRNet网络架构。图片有点长:
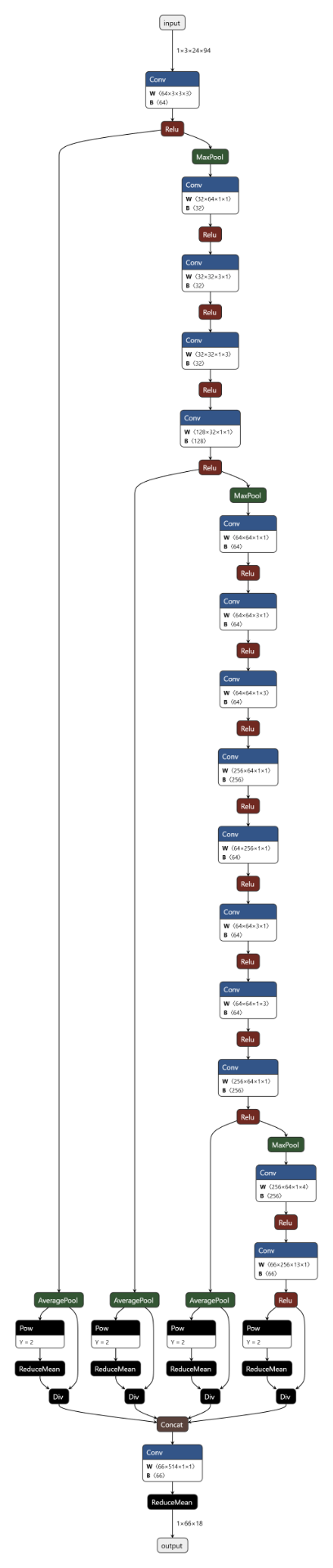
不理解也没关系,在LPRNet的官网中也已经预训练好了一个LPRNet的模型,我们可以拿来直接用:https://github.com/sirius-ai/LPRNet_Pytorch/blob/master/weights/Final_LPRNet_model.pth
再将我们前面训练好的YOLO26的模型和LPRNet的模型结合一下,实现车牌的定位与车牌号识别,代码见我的github仓库:https://github.com/puhaiyang/OpenTrafficFlow/blob/main/yolo_final_test.py
测试效果截图:
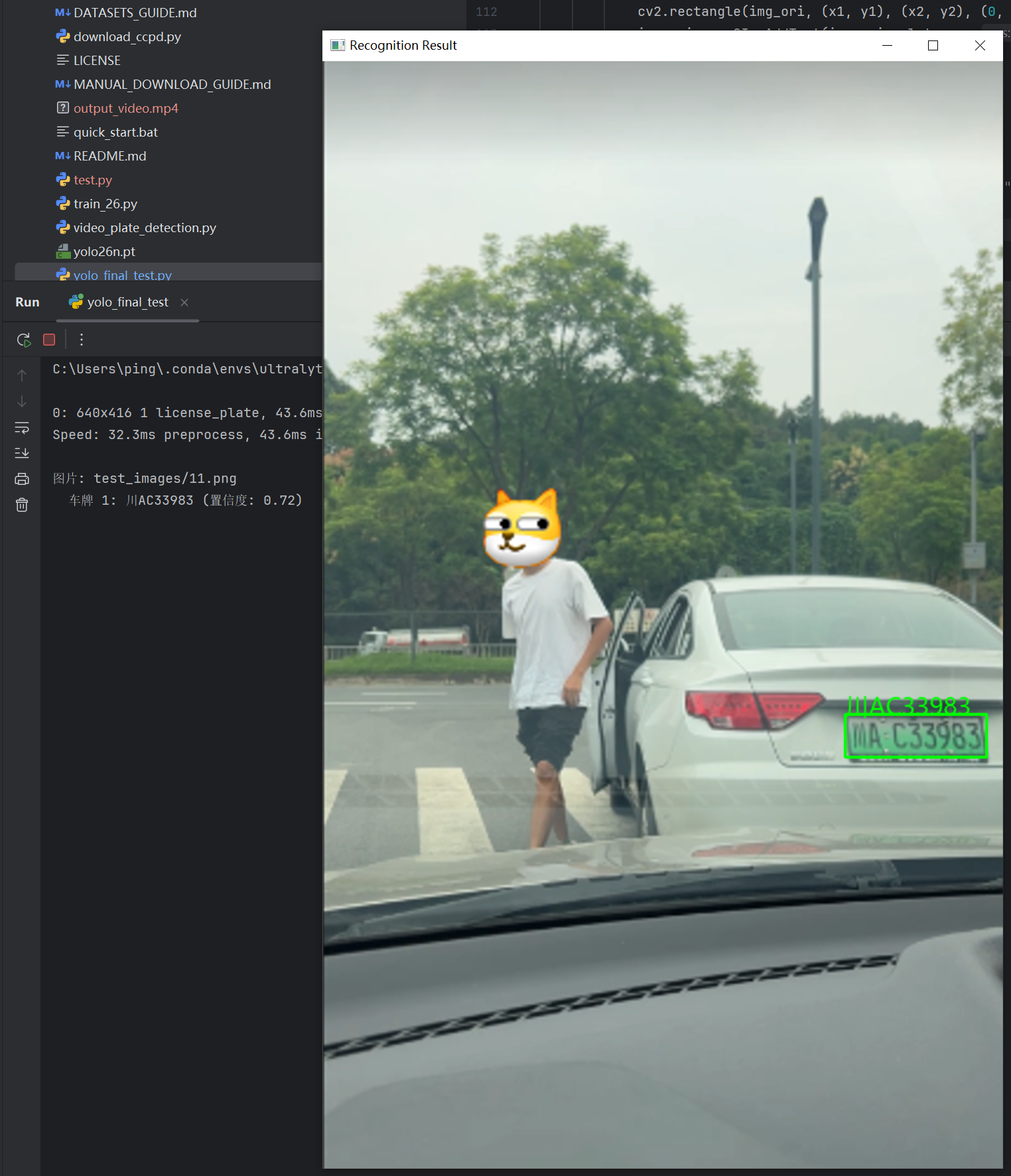
车牌定位并识别成功!
5. 总结
通过本文,我们了解了YOLO进行目标检测的主要流程,包括对数据标注、数据集训练、模型使用都有了一定的掌握。
在使用过程中如果发现车牌定位 与识别还不够精准,可根据具体的情况进行进一步处理,如:
- 图像预处理
- 车牌定位YOLO模型再训练
- LPRNet模型再训练
其他可用开源数据集:
在本文中所有涉及到的数据集和训练好的模型文件,都已经上传到了我的github中。