备注 :回顾看过的论文与之前总结的内容,对目前这个系列做个小小的汇总。虽然LLM现在更新层出不穷+各种paper漫天飞舞,不过目前回顾看的各种结构改变并不是特别大,掌握基础的不变的才可以能更好的适应变化。(注:笔者水平有限,若有描述不当之处,欢迎大家留言。后期会继续更新LLM系列,文生图系列,VLM系列,agent系列等。如果看完有收获,可以【点赞】【收藏】【加粉】)
小结的结构:
一 基础知识:attention的细节和归一化,激活函数的函数等。
二 LLM分类:不同的LLM结构和原因分析
三 架构: 不同的架构比较,如使用的编码方式,归一化方法,激活函数等
四 训练方式: 汇总训练LLM的训练时数据的来源与预训练方法,后训练方法
五 评估方法: 评估的数据
一 基础知识(掌握可以跳过)
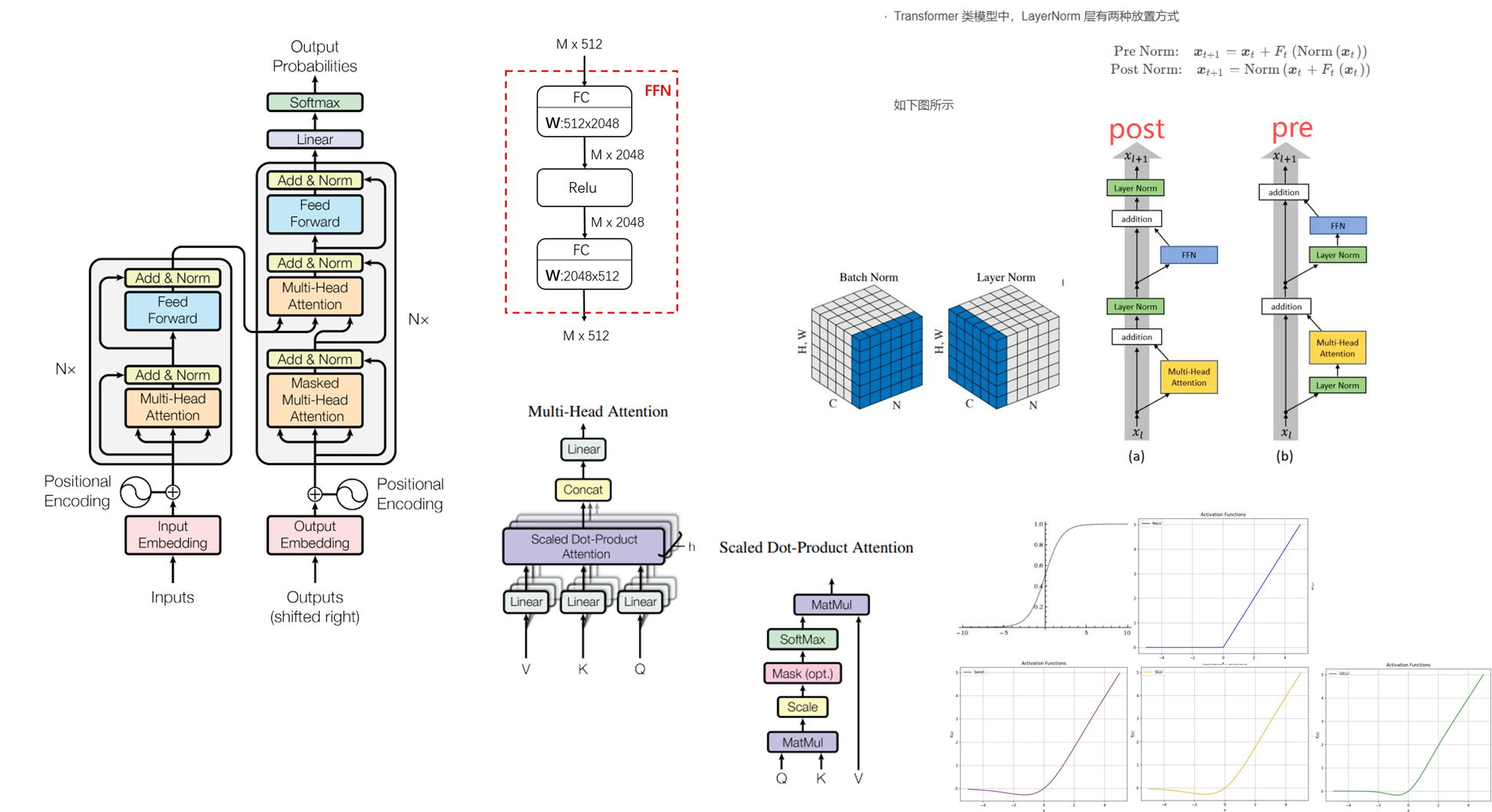
1.1 Transformer中-记忆的来源
Transformer【1】架构是由多个encoder+decoder的堆叠构成,每个encoder是由多头自注意力机制+FFN构成,decoer是有多头自注意力机制+多头交叉注意力机制+FFN构成。
记忆的来源主要是网络提供非线性,对数据进行拟合【2】【3】。 Attention 是对短期的信息进行提取,而 FFN 则对整个训练样本提取和学习:
Attention更多是对信息的记忆和提取 ,关注那些重要进行记忆。另外多头注意力机制(MHA)的主要非线性来自于 操作。如果仅看 MHA 模块,其非线性是比 FFN 弱很多的,但它不是严格线性的。
FFN 是一个 Key-Value 记忆网络,第一层线性变换是 Key Memory,第二层线性变换是 Value Memory。FFN 学到的记忆有一定的可解释性,比如低层的 Key 记住了一些通用 pattern (比如以某某结尾),而高层的 Key 则记住了一些语义上的 Pattern (比如句子的分类)。Value Memory 根据 Key Memory 记住的 Pattern,来预测输出词的分布。skip connection 将每层 FFN 的结果进行细化。

1.2 模型的归一化函数
Batch Normalization(BN):沿batch方向上,对 **(N、H、W)**做归一化,保留通道C的维度
公式:
-
优点:适用于CNN
-
缺点:对较小的batch size效果不好,不适用于RNN。每次计算均值和方差是在一个batch上如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
Layer Normalization (LN):沿Channel方向上,对 **(C、H、W)**做归一化,保留通道N的维度
公式:
-
优点:适用序列模型,不同的输入样本有不同的均值和方差,可以更快、更好地达到最优效果,如:RNN,LLM
-
缺点:不适应输入变化很大的数据,大Batch较差
RMSNorm:提出的动机是LN运算量比较大,为 LayerNorm 的一个简单变体。
公式:
小结:
TransformerLN BN :因为 transformer 模型是基于相似度的,把序列中的每个 token 的特征向量进行归一化有利于模型学习语义,第一步调整均值方差时 ,相当于对把各个 token 的特征向量缩放到统一的尺度,第二步施加
BN :因为 transformer 模型是基于相似度的,把序列中的每个 token 的特征向量进行归一化有利于模型学习语义,第一步调整均值方差时 ,相当于对把各个 token 的特征向量缩放到统一的尺度,第二步施加 时,相当于对所有 token 的特征向量进行了统一的 transfer,这不会破坏 token 特征向量间的相对角度,因此不会破坏学到的语义信息。与之相对的,BN 沿着特征维度进行归一化,这时对序列中各个 token 施加的 transfer 是不同的,破坏了 token 特征向量间的相对角度关系
RMSNormLayerNorm:的主要区别在于RMSNorm不需要同时计算均值和方差 两个统计量,而只需要计算均方根 一个统计量**,性能和 LayerNorm 相当,可以节省7%到64%的运算。**
python
import torch
import torch.nn as nn
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
"""
LlamaRMSNorm is equivalent to T5LayerNorm
"""
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)1.3 模型的激活函数
Sigmoid: 公式
拓展:Swish;SiLu;
优点:把输入的连续实值变换为0和1之间的输出,适合做概率值的处理
缺点:梯度消失; 不是零中心化; 运算量大
ReLU: 公式
拓展:LeakyReLU;PReLU;RReLU;ELU;SELU
优点:计算高效, ReLU的计算量小,收敛速度很快**;缓解梯度消失问题:** 在正区间(x>0) 解决了梯度消失问题,对梯度消失问题的缓解效果更好;稀疏激活性: 当输入是负数时,ReLU输出为零,这意味着神经元可以学习对于某些输入忽略不计的特征,从而使模型更加稀疏,提高了模型的表示能力。
缺点:死亡ReLU问题: 当输入为负数时,ReLU的导数为零,这意味着在训练过程中,某些神经元可能永远不会被激活,导致这些神经元对于所有输入都无法学习;不是零中心化: ReLU的输出范围是[0, 正无穷),因此不是零中心化的
Swish: 公式
优点:当 x>0时,不存在梯度消失的情况;当 x<0时,神经元也不会像 ReLU 一样出现死亡的情况;swish处处可导,连续光滑,容易训练;swish并非一个单调的函数
缺点:计算量大
SiLu: 公式
优点:平滑性与非单调性;缓解梯度消失与神经元死亡;
缺点:计算成本略高于 ReLU(需计算 Sigmoid);输出非零中心化,需配合 BatchNorm 使用
GeLu: 公式
优点:平滑性与自适应性;能避免梯度消失问题;
缺点: GELU的计算代价相对较高
python
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Define the activation functions
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def relu(x):
return np.maximum(0, x)
def swish(x, beta=1):
return x * sigmoid(beta * x)
def silu(x):
return swish(x, beta=1) # SiLU is Swish with beta=1
def gelu(x):
return x * norm.cdf(x)
# Define the derivatives
def sigmoid_derivative(x):
s = sigmoid(x)
return s * (1 - s)
def relu_derivative(x):
return np.where(x > 0, 1, 0)
def swish_derivative(x, beta=1):
s = sigmoid(beta * x)
return s + beta * x * s * (1 - s)
def silu_derivative(x):
return swish_derivative(x, beta=1)
def gelu_derivative(x):
return norm.cdf(x) + x * norm.pdf(x)1.4 切词tokenizer
Tokenizer 目标是解决词汇表大小、稀有词问题(OOV, Out-Of-Vocabulary)和文本通用性之间的平衡。
基于词的切分 (Word-based Tokenization):将文本按完整词汇单元切分,通常以空格 和标点为主要分隔符。
方法: 依赖特定语言的分词工具或词典(例如英文的空格切分,中文的 Jieba 等)。
**优点:**语义清晰,Token 直接对应词汇。
**缺点:**词汇表爆炸且存在OOV(无法处理新词或生僻词)。
基于字的切分 (Character-based Tokenization):将文本拆分为最小单位------字符或字。
**优点:**无 OOV 问题,词汇表极小。
**缺点:**序列长度爆炸,Token 缺乏独立语义,计算效率极低。
基于词的切分 (Word-based Tokenization):将词汇分解为有意义的子单元 (Subword),如 dogs --->[dog, ##s]
方法:基于统计频率或概率模型进行切分;BPE (Byte Pair Encoding) / BBPE (Byte-level BPE, 用于 GPT-2/3);WordPiece (用于 BERT);Unigram (用于 T5 等)
**优点:**效率与语义的良好折衷(词汇表适中)。
解决了 OOV 问题(稀有词会被分解为已知子词/字符)。
提升泛化能力(能识别词根和词缀)。
**缺点:**切分边界模糊,子词语义不如完整词汇清晰。
1.5 位置编码
位置编码 (Positional Encoding):是自然语言处理中用来表示词语在句子中位置信息的一种方法。因为像Transformer这样的模型不会自动捕捉词的顺序,所以需要通过位置编码给每个词加上一个独特的标记,帮助模型理解词语的相对位置和上下文关系。【6】备注:之前已经讲解汇总过,为了保持汇总的简要。在此不展开讲解,可进入对应链接详细查看

1.6 Attention模块
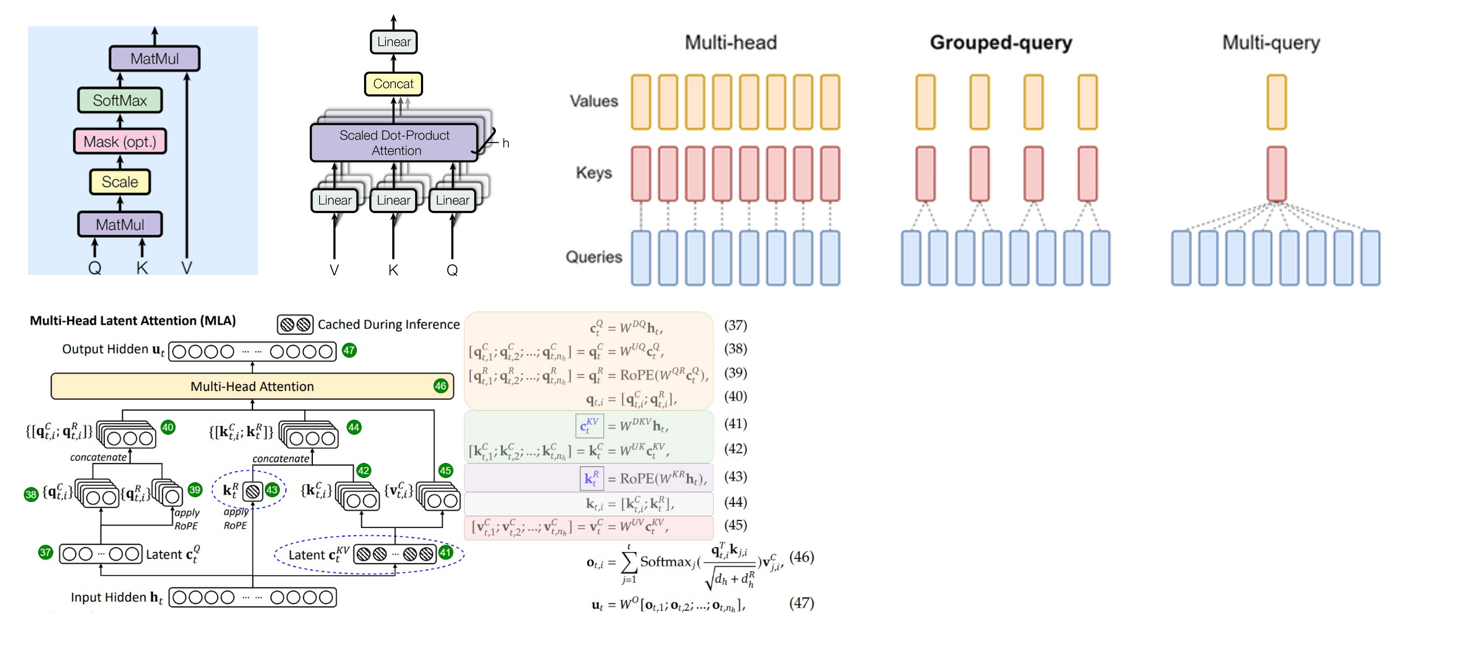
自注意力机制:
原理: 输入序列 X 经过线性变换生成 Q(查询)、K(键)、V(值) 三个向量组。通过计算 Q 和 K 的点积(经 \\sqrt{d_k} 缩放),确定注意力权重,然后对 V 进行加权求和得到输出。
优点: 全局依赖捕获,并行化。
缺点: 计算复杂度高
因果注意力机制:
原理: 在计算某个位置t的注意力时,模型只能关注到位置 及之前(t,t-1,...,1)的信息,而不能看到位置 t之后的信息。这通过在 Attention Score 矩阵上应用掩码 (Mask) 来实现。
优点: 保证生成任务的合理性,是所有自回归语言模型(如 GPT 系列)进行文本生成的基础
缺点: 信息的流动是单向的,无法利用未来的上下文信息。
交叉注意力机制:
原理: 关注于两个不同序列之间的关系。Query (Q) 来自目标序列(如解码器),而 Key (K) 和 Value (V) 来自源序列(如编码器)。
优点: 信息融合:允许解码器在生成输出时,从编码器的隐藏表示中选择性地提取信息,是 Seq2Seq 任务(如翻译)的核心
缺点: 需要两个独立的输入序列。计算量高于自注意力机制。
多头注意力机制:
原理: 每个注意力头有独立的 Q/KN 矩阵,允许模型从不同角度学习特征。
优点: 模型容量大,性能强。
缺点: 计算和内存开销高。
多查询注意力:
原理: 所有注意力头共享同一个K和 V,仅 Q 独立。
优点: 显著减少参数量和计算量,适合推理加速。
缺点: 可能损失模型容量。
分组注意力:
原理: 将头分成 G组,组内共享K和 V,Q 独立。。
优点: 平衡 MHA 和 MQA,灵活调节计算效率。
关系: MHA 可以看作是组数等于查询头数的 GQA,而 MQA 则是组数为 1 的 GQA。
MLA:
原理: 使用 状态空间模型 (SSM) 机制替代或补充 Transformer 的注意力机制。它不计算全序列的点积,而是通过线性递归或卷积来处理序列信息,具有与序列长度线性相关的计算复杂度。。
优点:效率高:处理长序列时计算复杂度为 O(N)(N为序列长度),远低于 MHA 的 O(N^2)。内存高效。
缺点: 在某些复杂的长程依赖和通用推理任务中,理论上性能可能不如全 Attention 机制。
1.7 优化器
优化器 是在深度学习反向传播过程中,指引损失函数的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数值不断逼近全局最小。
SGD:
Adam:
Adamw:
Muon:
MuonClip:
1.8 损失函数
todo
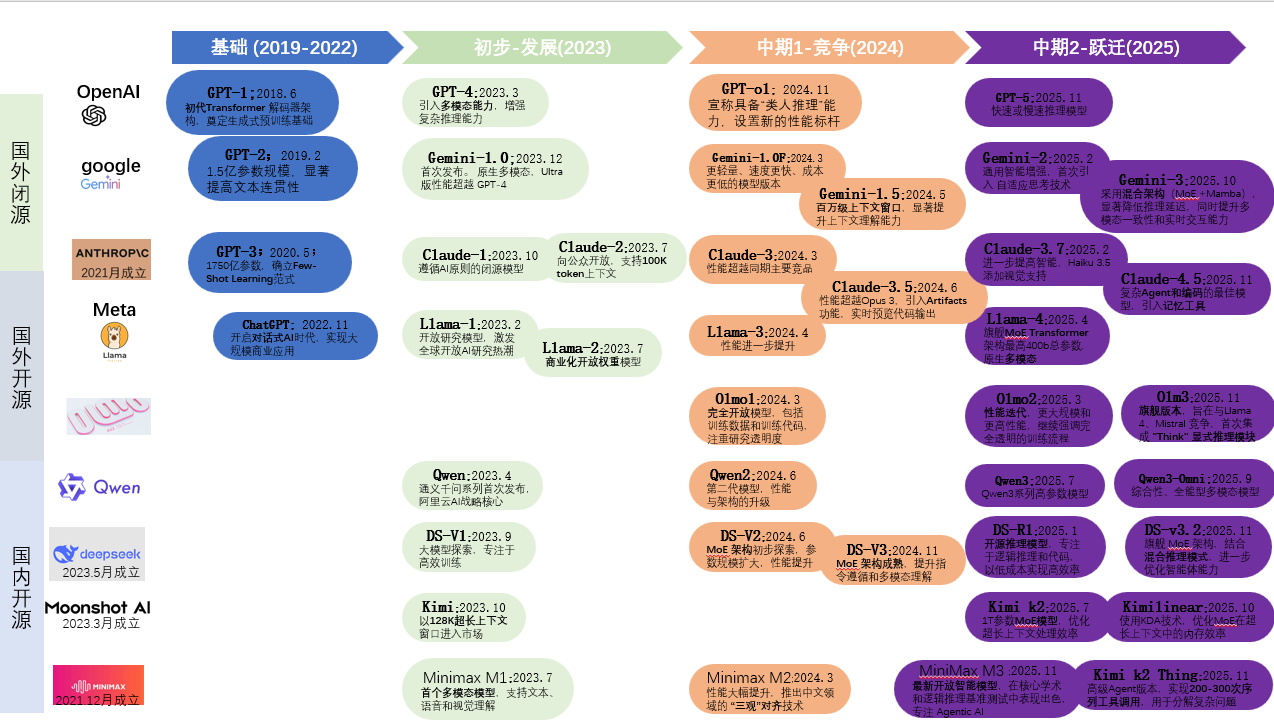
二 LLM分类
**7**备注:之前已经讲解汇总过,为了保持汇总的简要。在此不展开讲解,可进入对应链接详细查看;

下面为平时看到的LLM 文献+资料按照时间进行汇总(仅代表自己认为重要llm)
三 LLM架构
主要对之前的【8】【9】中汇总的架构进行对比分析,给出异同点。从经典的Transformer架构入手,分别对经典的架构按图拆解。
通过章节一中的基础,可以看到除attention外就是对归一化函数,激活函数与PE的不同使用。
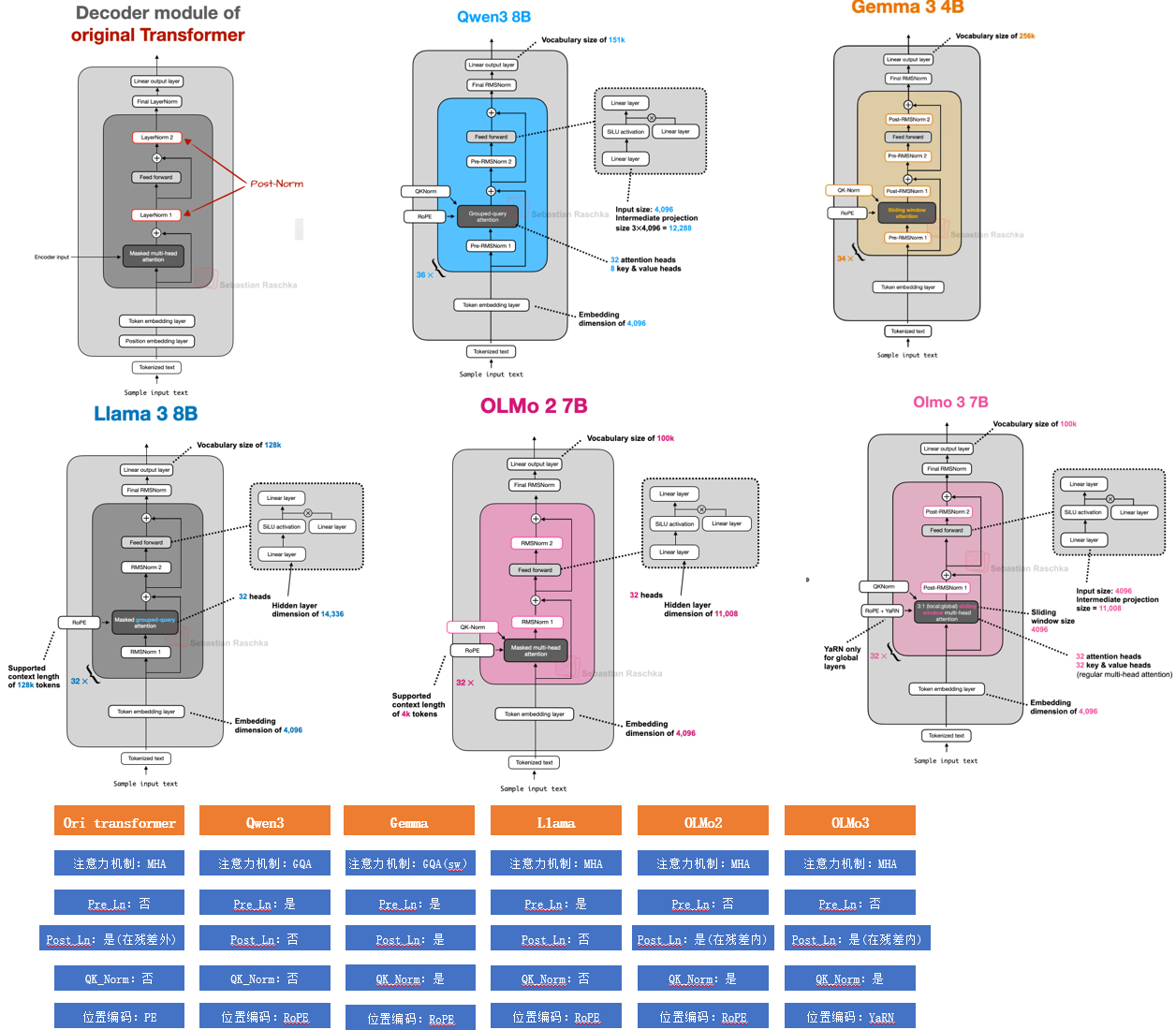 LLM 10b以下dense对比
LLM 10b以下dense对比 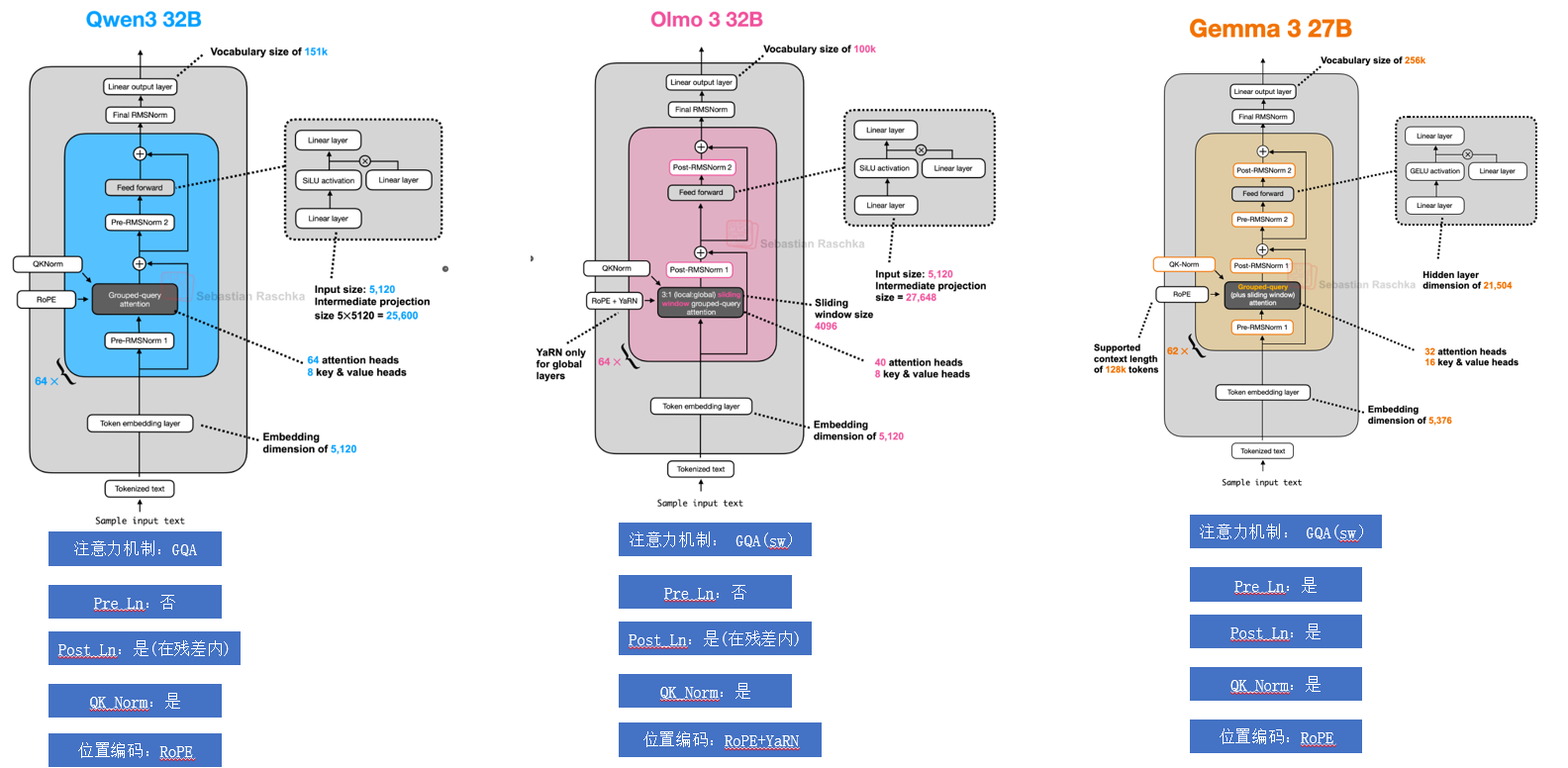 LLM 30b左右dense对比
LLM 30b左右dense对比 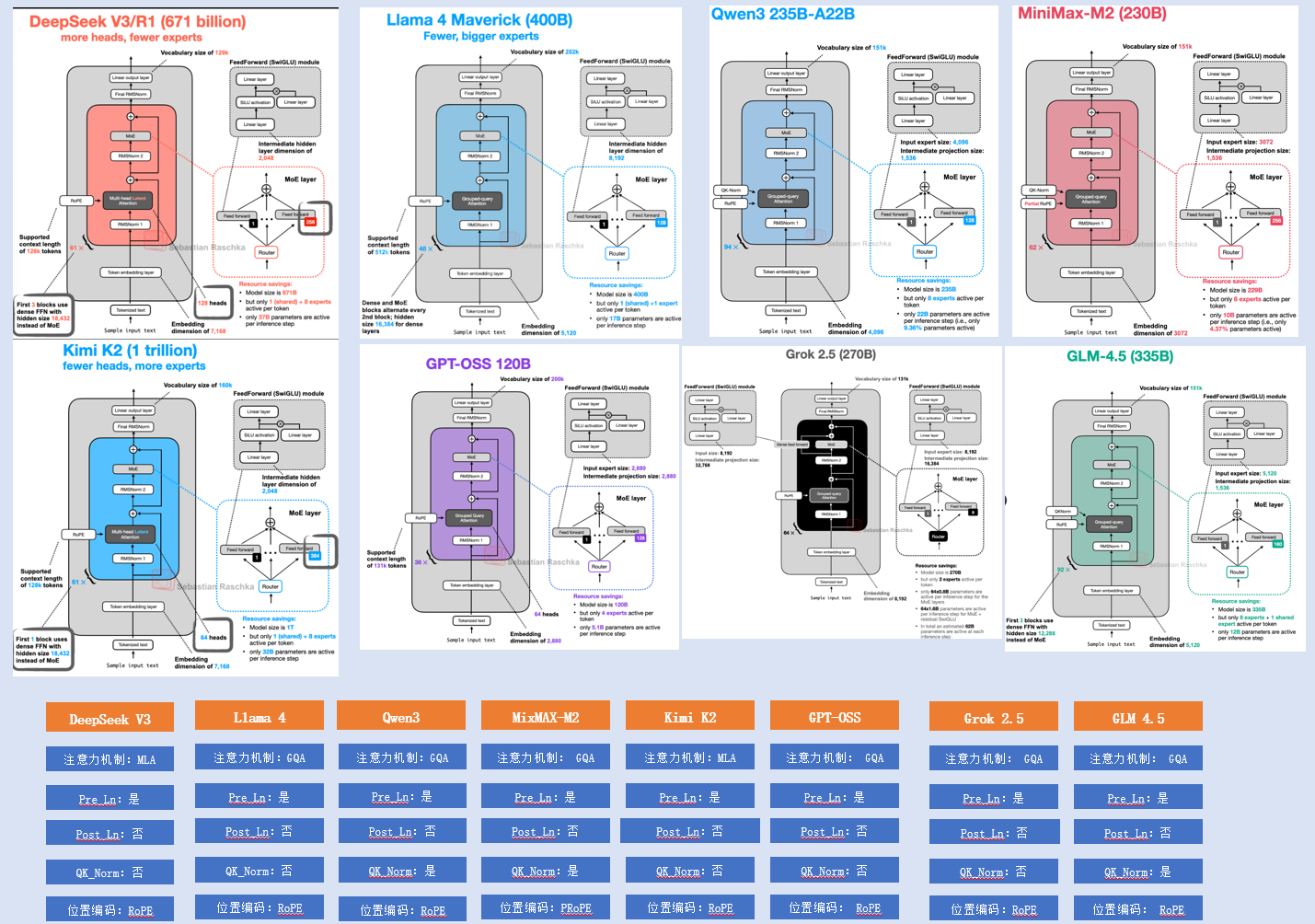 LLM 100b以上MOE架构
LLM 100b以上MOE架构 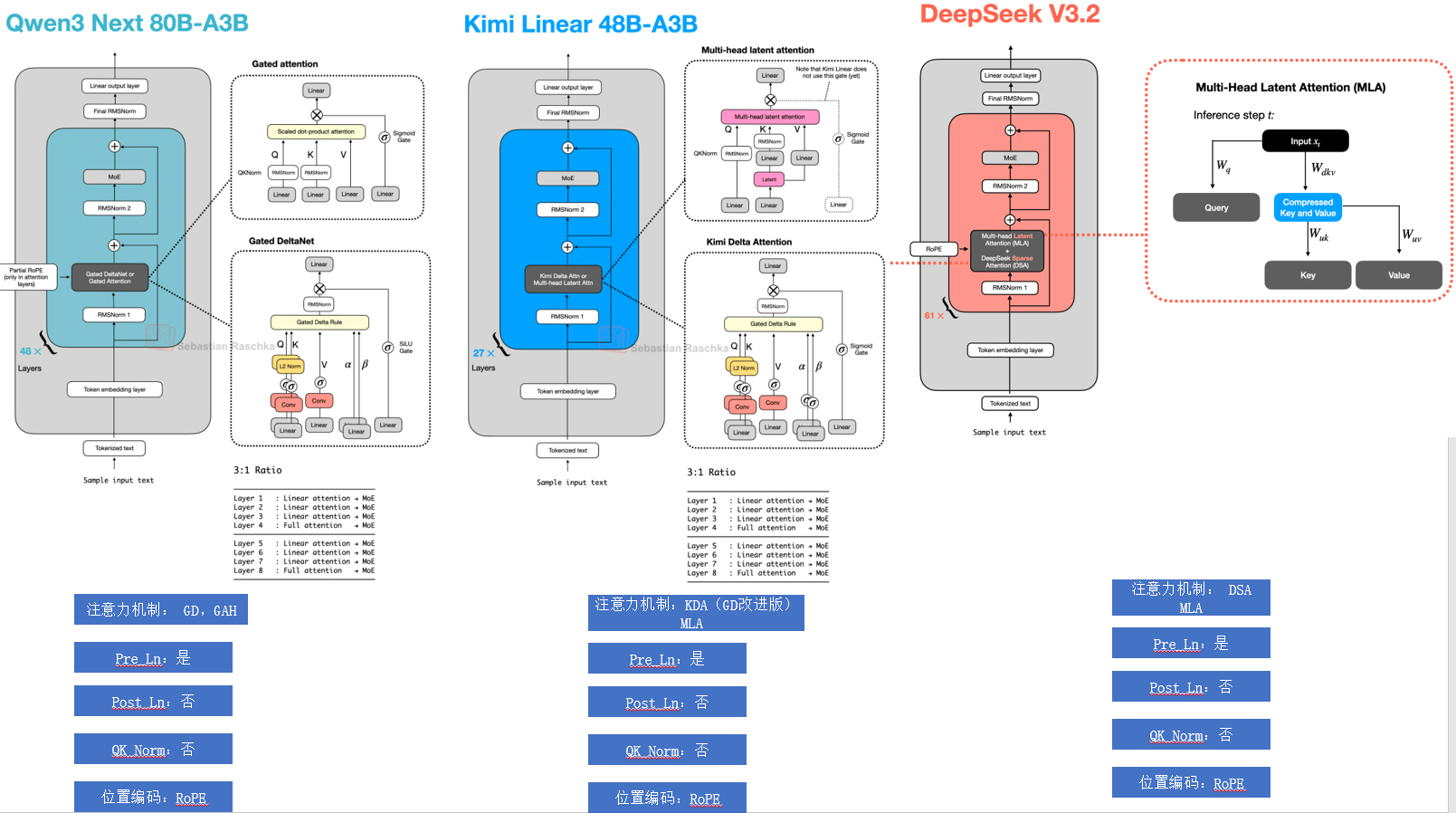 LLM 混合注意力+MOE架构
LLM 混合注意力+MOE架构
四 训练方法
todo
五 评估数据集
todo
参考资料
1 Attention Is All You Need :https://arxiv.org/abs/1706.03762
2 Transformer Feed-Forward Layers Are Key-Value Memories:https://arxiv.org/pdf/2012.14913
3 End-To-End Memory Networks :https://arxiv.org/pdf/1503.08895
4 归一化方法 :https://www.cnblogs.com/lxp-never/p/11566064.html#blogTitle0
5 激活函数:https://zhuanlan.zhihu.com/p/659413142
6 位置编码:https://blog.csdn.net/qq_29296685/article/details/153988822
7 LLM分类:https://blog.csdn.net/qq_29296685/article/details/154721668
8 大模型14个经典架构 : https://blog.csdn.net/qq_29296685/article/details/154976250
9 GPT-2 到 gpt-oss: https://blog.csdn.net/qq_29296685/article/details/155424773