在AI浏览器概述:Atlas、Comet、Fellou、BrowserOS里介绍过几款AI浏览器,以及传统浏览器(外加AI聊天能力)。
本文试图深入理解几款可用于实现浏览器自动化的框架/项目。
Puppeteer
官网,开源(GitHub,93K Star,9.3K Fork)Node库,提供高级API基于CDP协议控制Chromium或Chrome。默认以headless模式运行,可通过修改配置文件运行有头模式。官方文档,。
功能列表:
- 生成页面截图、PDF;
- 抓取SPA(单页应用)并生成预渲染内容,即服务器端渲染SSR;
- 自动提交表单,进行UI测试,键盘输入等;
- 捕获网站Timeline Trace,用于分析性能问题;
- 测试浏览器扩展;
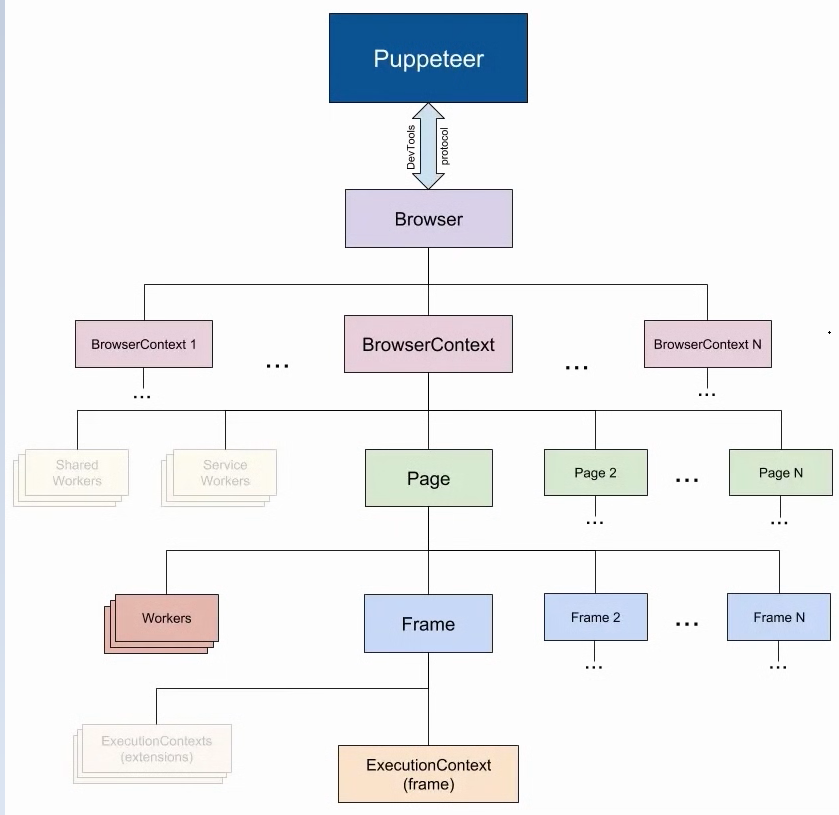
概念:
- BrowserFetcher:可用来下载和管理不同版本Chromium;
- Browser:Puppeteer连接到Chromium实例创建Browser对象,两种方法:
puppeteer.launch或puppeteer.connect。创建实例后,在页面操作完毕时,需要手动把实例关闭,否则实例会越来越多导致内存泄漏; - BrowserContext:最基本的执行环境,不同浏览器上下文的环境中,不会共享Cookies和Cache;
- Page:一个Browser实例可以有多个Page实例;
- Worker:
实战
安装:
bash
# 会自动会下载最新版本Chromium
npm i puppeteer
# 或
yarn add puppeteer
# 不下载Chromium
npm i puppeteer-coreChromium默认下载到用户缓存目录:
示例:
js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();然后在命令行执行node example.js即可在当前目录生成example.png文件。
如果不想又安装一个Chrome/Chromium,即执行命令行npm i puppeteer-core,上述代码修改2行即可:
js
const puppeteer = require('puppeteer-core');
const browser = await puppeteer.launch({executablePath: 'C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe'});Page作为核心对象,其他方法:
page.pdf({path: 'hn.pdf', format: 'A4'});:生成PDFpage.evaluate:执行脚本
页面设置API:
page.setViewport(viewport):设置页面大小page.cookies(...urls?):返回指定页面Cookies,默认返回当前页面page.setCookie(...cookies):设置Cookiespage.deleteCookie(...cookies):删除Cookiespage.setExtraHTTPHeaders(headers):设置为当前页面的所有请求带上自定义请求头page.setUserAgent(userAgent):设置用户代理page.setGeolocation(options):设置当前页面的访问地理位置page.setJavaScriptEnabled(enabled):设置是否禁用页面JSpage.setRequestInterception(value):设置请求拦截器page.setCacheEnabled(enabled?):设置是否开启请求缓存,默认开启page.setOfflineMode(enabled):设置是否开启离线模式
执行等待API:
page.waitForNavigation(options?):等待页面跳转后等待跳转完成条件成立,默认load事件触发时page.waitForXPath(xpath, options?):等待xpath解析的页面元素出现在页面中page.waitForSelector(selector, options?):等待选择器解析的页面元素出现在页面中。和上面方法的出现是指在dom中可检索到便触发,可额外配置成dom中不为display:none或visibility:hidde样式触发,但是无法控制成元素出现在窗口范围内触发page.waitForFunction(pageFunction, options?, ...args?):等待放到页面上下文执行的方法返回真值page.waitForRequest(urlOrPredicate, options):等待页面上发起的请求满足判断条件并返回真值page.waitForResponse(urlOrPredicate, options):等待页面上接收的请求响应满足判断条件并返回真值page.waitFor(selectorOrFunctionOrTimeout, options?, ...args?):可充当page.waitForXPath、page.waitForSelector、page.waitForFunction和延时效果用
Playwright
官网,微软开源(GitHub,77.3K Star,4.6K Fork),用于Web自动化和端到端(End-to-End,E2E)测试的开源框架。支持多种浏览器(Chromium、Firefox和WebKit)和多种编程语言(JS/TS、Python、Java和.NET),对单页应用(SPA)、动态加载、iframe、多标签页都能稳定处理,旨在提供可靠、快速且功能丰富的自动化测试解决方案。
应用场景:
- E2E测试:可模拟真实用户的使用场景,测试网站从头到尾的整个流程是否正常工作;
- Web爬虫和数据抓取:从网页上自动化地获取数据,可渲染JS动态加载内容,比传统爬虫工具更强大;
- 网页自动化:任何重复性网页操作,如自动签到、批量下载文件、填写报告等,都可以用Playwright来自动化;
- 生成截图和PDF:网页截图、网页内容保存为PDF文件。
官方提供VS Code插件。
三个核心概念/对象:
- Browser:浏览器,自动化过程起点。启动Browser示例,在其内部创建多个独立会话;
- BrowserContext:浏览器上下文,独立的浏览器会话。完全隔离页面、本地存储、cookies等数据;
- Page:页面,代表浏览器上下文中的标签页或窗口。所有操作,如点击、输入、导航、截图等,都是在Page对象上执行的。
一个Browser可包含多个BrowserContext,一个BrowserContext可包含多个Page;通常只需一个Browser和一个BrowserContext。多BrowserContext实例用于数据隔离场景,同时运行多个互不影响的任务,类似隐身模式。
| 对比项 | Selenium | Playwright |
|---|---|---|
| 开源时间 | 2004年,历史悠久 | 2020年,后起之秀 |
| 浏览器支持 | Chrome、IE等 | Chromium,Firefox,WebKit(现代浏览器全覆盖) |
| API设计 | 早期接口多,稍显复杂 | API简洁现代,学习成本低 |
| 执行速度 | 较慢,常遇到等待问题 | 更快,更少超时 |
| 特殊功能 | 较强大,生态成熟 | 原生支持截图、录制视频、Mock网络请求 |
安装:npm init playwright@latest
常用命令行:
bash
npx playwright test # 运行全部测试
npx playwright test login.spec.js # 测试指定文件
npx playwright codegen # 启动录制工具,自动生成脚本
npx playwright show-report # 打开测试报告示例
js
await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
await page.reload({ waitUntil: 'networkidle' });
await page.goBack();
await page.goForward();
await page.waitForLoadState('load'); // 页面和资源全部加载完
await page.waitForSelector('#main-content'); // 等待元素出现
// 文件上传
await page.setInputFiles('input[type="file"]', 'avatar.png');
const upload = page.locator('input[type=file]');
await upload.setInputFiles(['1.png', '2.png']);
// 下载文件
await page.goto('https://the-internet.herokuapp.com/download');
const [download] = await Promise.all([
page.waitForEvent('download'),
page.click('a[href="some-file.txt"]'),
]);
await download.saveAs('downloads/some-file.txt');
console.log('下载完成:', await download.suggestedFilename());
await page.screenshot({ path: 'home.png', fullPage: true });
await page.video()?.saveAs('test.mp4'); // 需开启video记录才可用Skyvern
官网,开源(GitHub,19.6K Star,1.7K Fork)浏览器自动化工具,基于Gemini等多模态大模型来识别理解页面上的元素。官方文档。
整个系统分为三个主要模块:
- Planner:规划器,负责将上述复杂的宏观指令拆解成一步步可执行的子步骤;
- Task:任务执行器,负责具体执行Planner分配的某一个步骤;
- Validator:验证器,反馈机制,用于确认任务是否真的完成,防止AI在网页加载失败或操作失误时继续盲目执行。
功能
- 认证和安全:支持多种登录方式,包括基于二维码的双因素认证、短信和邮箱验证码等,还能对接主流密码管理器;
- 实时查看过程:可以实时看到浏览器在做什么,每个操作都有对应的截图记录,有利于调试;
- 数据提取:严格按照指定的格式提取网页数据,支持JSON、CSV等多种格式输出。
实战
在线体验,需科学上网,然后使用Google授权登录:
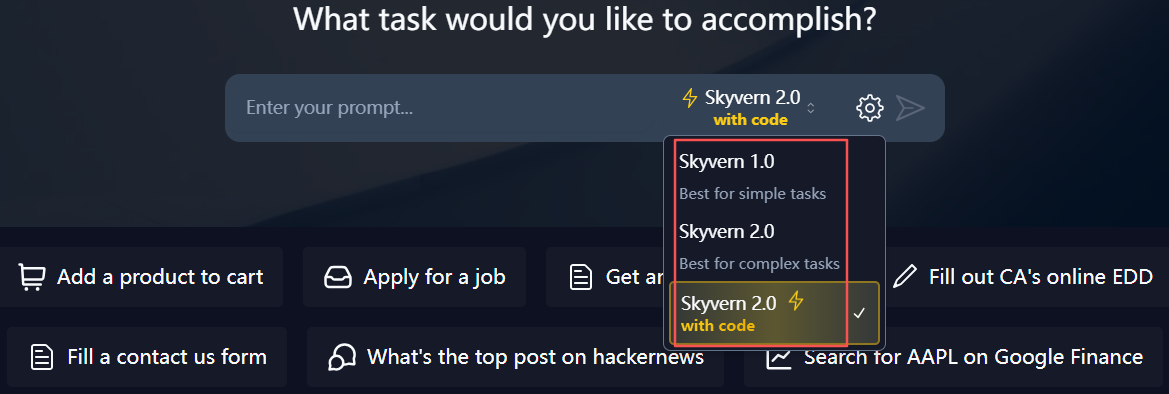
如上图,提供3种模型,分别用于不同场景任务。
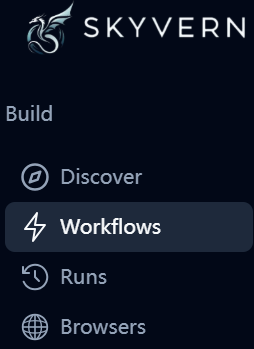
提供几种场景下的自动化Agent:
提供云服务版本和开源自部署两种方式,自部署又提供多种方式:
pip:- Docker Compose
本地部署:
bash
pip install skyvern
skyvern quickstart
skyvern run all浏览器访问http://localhost:8080体验。
基于Docker Compose:
bash
git clone https://github.com/Skyvern-AI/skyvern.git
cd skyvern
./run_skyvern.sh init
docker compose up -d集成Python SDK:
py
from skyvern import Skyvern
skyvern = Skyvern(api_key="你的_SKYVERN_API_KEY")
# 注:如果是本地部署,需配置 base_url 指向本地服务
# 下达任务
task = await skyvern.run_task(
prompt="去Hacker News网站找到今天热度最高的帖子,并返回标题和链接"
)
print(task)StageHand
官网,开源(GitHub,19.1K Star,1.2K Fork)AI驱动的浏览器自动化框架,基于Playwright开发,计算机使用模型、
功能特性:
- AI驱动操作,基于自然语言指令,提供丰富的操作支持(点击、输入、提取、导航等)
- 基于Playwright的可靠架构
- 支持多种AI模型(OpenAI、Anthropic等computer use模型)
- 基于代码与自然语言结合的灵活性
- 统一的页面操作接口,快速能够切换各种操作模式
- 动作预览功能
- 缓存重复操作
- 数据提取工具
- 一行代码集成能力
实战
npx create-browser-app
bash
git clone https://github.com/browserbase/stagehand.git
cd stagehand
pnpm install
pnpm playwright install示例
ts
import { Stagehand } from "@browserbasehq/stagehand";
const stagehand = new Stagehand({
apiKey: process.env.OPENAI_API_KEY,
});
await stagehand.init();
// 使用Playwright函数
const page = stagehand.page;
await page.goto("https://github.com/browserbase");
// 使用AI执行操作
await page.act("click on the stagehand repo");
// 使用计算机使用代理
const agent = stagehand.agent({
provider: "openai",
model: "computer-use-preview",
});
await agent.execute("Get to the latest PR");
// 提取页面数据
const { author, title } = await page.extract({
instruction: "extract the author and title of the PR",
schema: z.object({
author: z.string().describe("The username of the PR author"),
title: z.string().describe("The title of the PR"),
}),
});Nanobrowser
官网,一款运行于浏览器中的开源(GitHub,9.6K Star,960 Fork)Web自动化AI工具,安装使用简单,无需代码基础。通过简单的自然语言描述,将指令传入给智能体,进行计划、执行、校验最终给出答案,整个过程无需人工干预。
功能
- 多智能体协同:内置多个智能体共同协同,包括计划模块、执行模块、校验模块,共同来完成复杂任务
- 交互式侧面板:采用侧边栏进行交互,方便打开和关闭。可以实时查看每一步任务,节点更新的状态
- 自动执行任务:通过自然语言描述,将指令传递给智能体,自动进行计划、执行、校验结果,最终给出一个答案
- 已完成任务继续执行:支持已完成的任务,继续对话,更深入的执行任务,进行解答
- 存档历史记录:支持已经完成的任务,会进行存档,方便后续查找
- 支持多种大模型:支持OpenAI、Ollama等
应用场景:
- 重复表单:
- 数据采集:日常重复搜索关键词,采集数据
- 自动化流程:日常重复的工作流
实战
安装:
- Chrome App市场搜索
- GitHub Release页面下载压缩包
如果安装失败:
切换代理区域解决。

打开设置
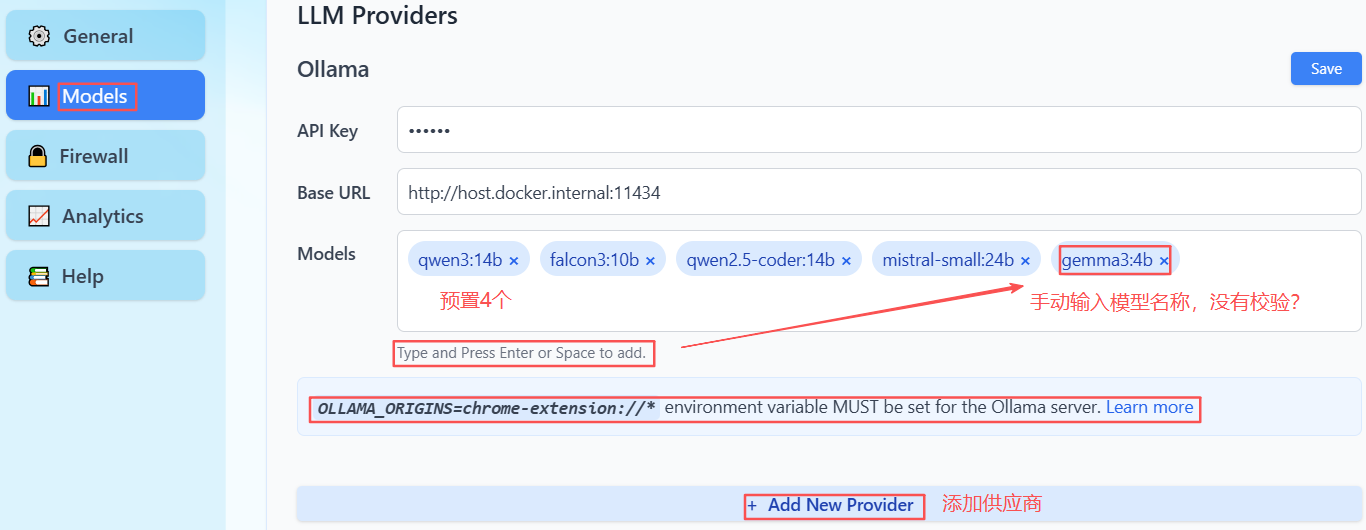
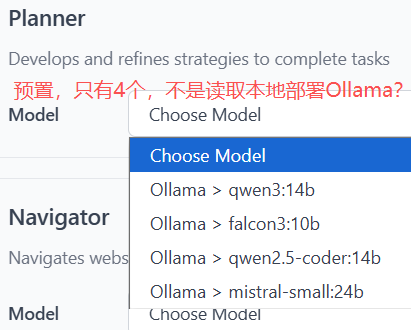
模型配置,主要是3个:
- 规划:MAS多智能体架构核心角色
- 网页浏览:浏览器核心操作
- ASR:语音识别
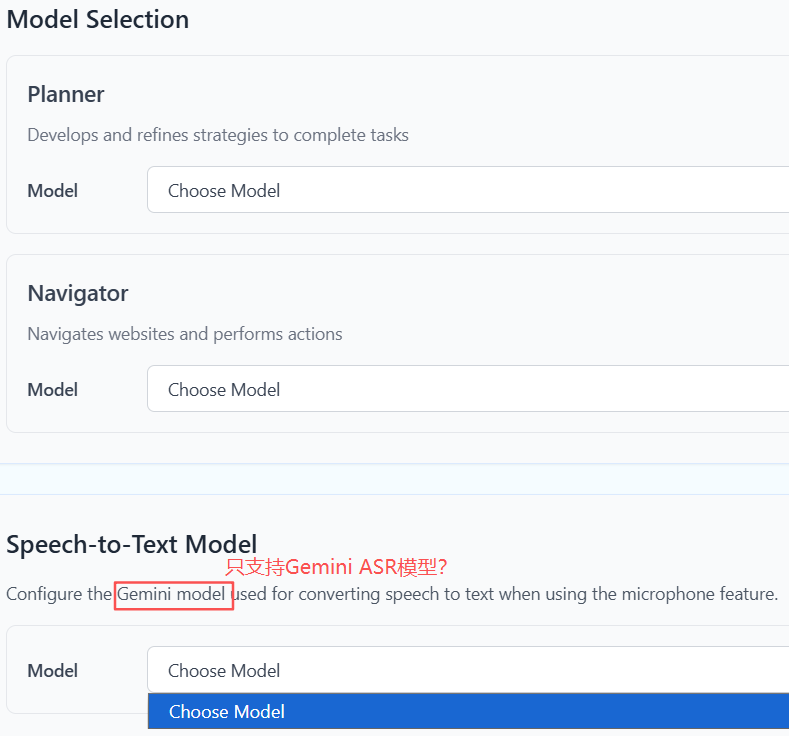
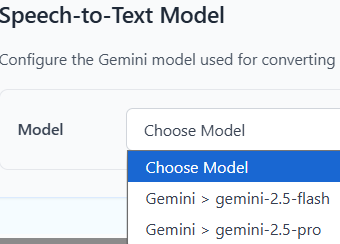
配置Gemini API Key之后,ASR模型下拉框
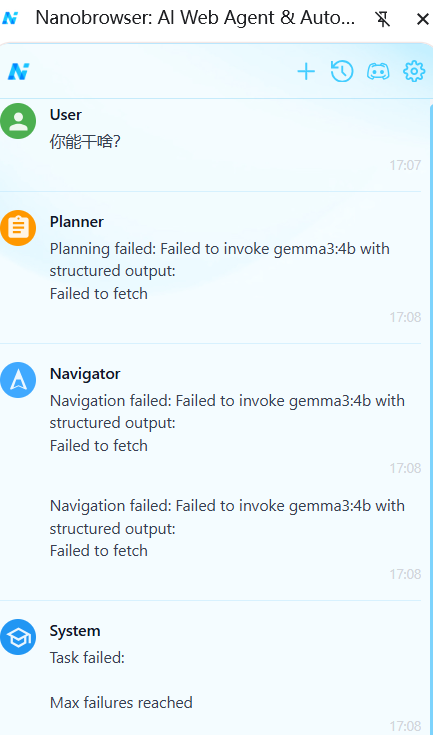
遇到的问题:配置好gemma3:4b模型,无法完成对话
防火墙
这种工作方式,和Page Assist、Ollama-UI很类似,都是以浏览器插件形式,与AI对话。参考LLM交互工具汇总:Open WebUI、ChatBot-UI、浏览器插件、Studio