快速入门(基于 Lora )
前言
为什么需要微调模型?因为全量预训练参数量很大(就是所谓的满血版模型),相应的成本就会很高。而微调模型可以实现针对特定任务的微调,比如求职领域就需要求职知识的沉淀,所需要的数据就会与其他行业的不一样;同时也可以节省时间与资源成本。
为了简化微调的过程,于是就有了像 LLaMA-Factory 这样的微调框架。LLaMA-Factory 的使用场景有:
-
文本分类:实现情感分析、主题识别等功能。
-
序列标注:如 NER(命名实体识别)、词性标注等任务。
-
文本生成:自动生成文本摘要、对话等。
-
机器翻译:优化特定语言对的翻译质量。
而微调过程主要包括以下几个步骤:
-
数据准备:收集和准备特定任务的数据集。
-
模型选择:选择一个预训练模型作为基座模型。
-
迁移学习:在新数据集上继续训练模型,同时保留预训练模型的知识。
-
参数调整:根据需要调整模型的参数,如学习率、批大小等。
-
模型评估:在验证集上评估模型的性能,并根据反馈进行调整。
魔搭平台搭建 GPU 环境
想要使用框架,就需要有对应的环境。一般训练模型都是在 GPU 上面进行,想知道为什么的可以看一下这个视频:
为什么玩游戏、挖矿、跑AI必须用显卡,而不是CPU?_哔哩哔哩_bilibili
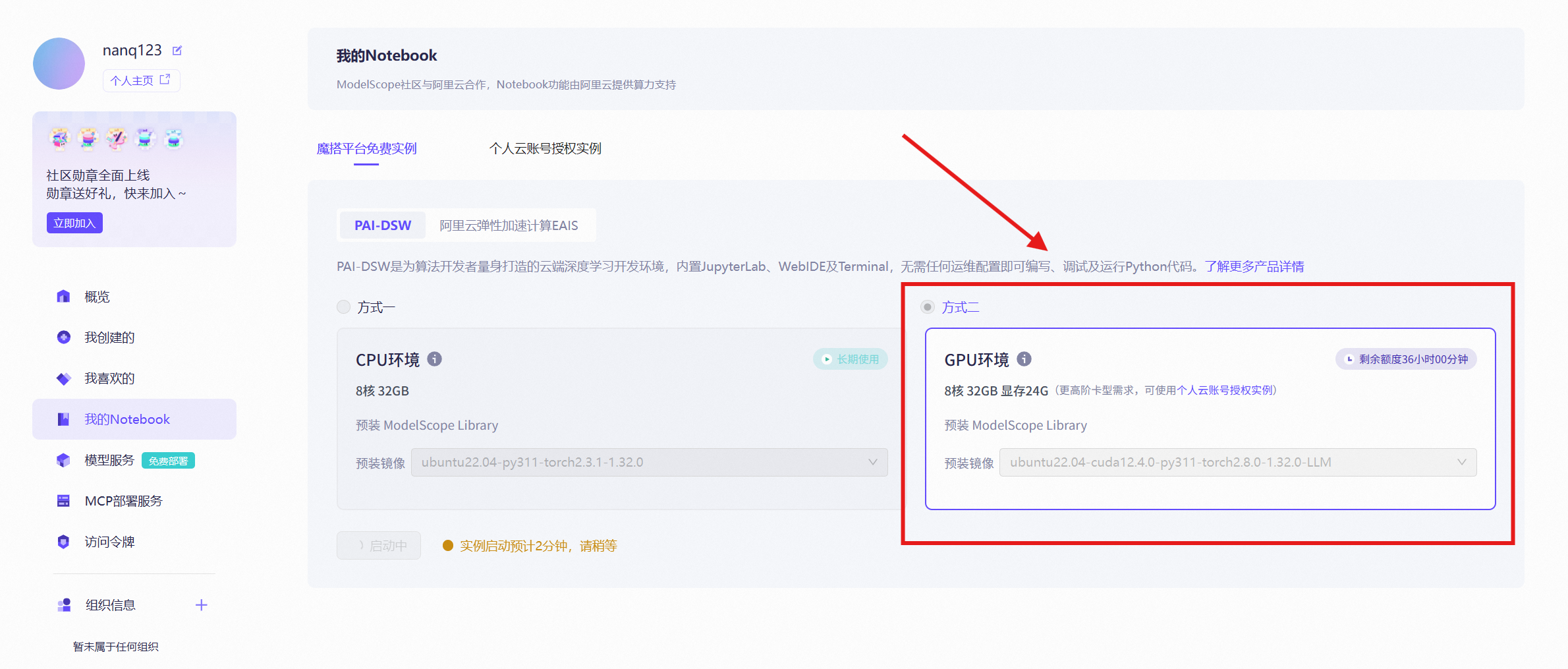
接下来就以魔搭云服务器为例子来配置环境,在【我的 Notebook】选项中选择最新的 GPU 环境,CUDA 什么的里面已经内置好啦。
下载 LLaMA-Factory 框架

在打开的控制台点击 【Terminal】,把下面的安装命令挨个复制即可:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
pip install -e "./[torch,metrics]"
如果环境有冲突,就运行以下命令:
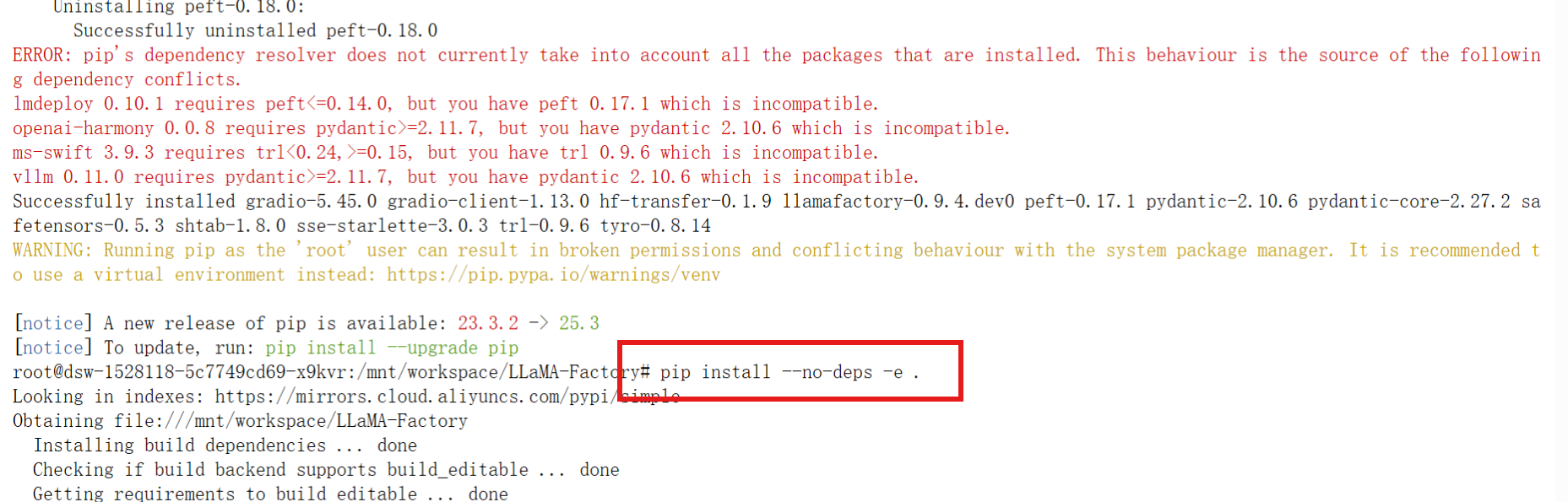
pip install --no-deps -e .验证LLaMA-Factory 框架是否安装好的命令如下:
llamafactory-cli version
微调简要步骤
添加自定义数据集
还记得微调的第一步是什么吗?我们需要收集和准备特定任务的数据集。数据集格式也有很多种,具体可以查看官方的文档:数据处理 - LLaMA Factory
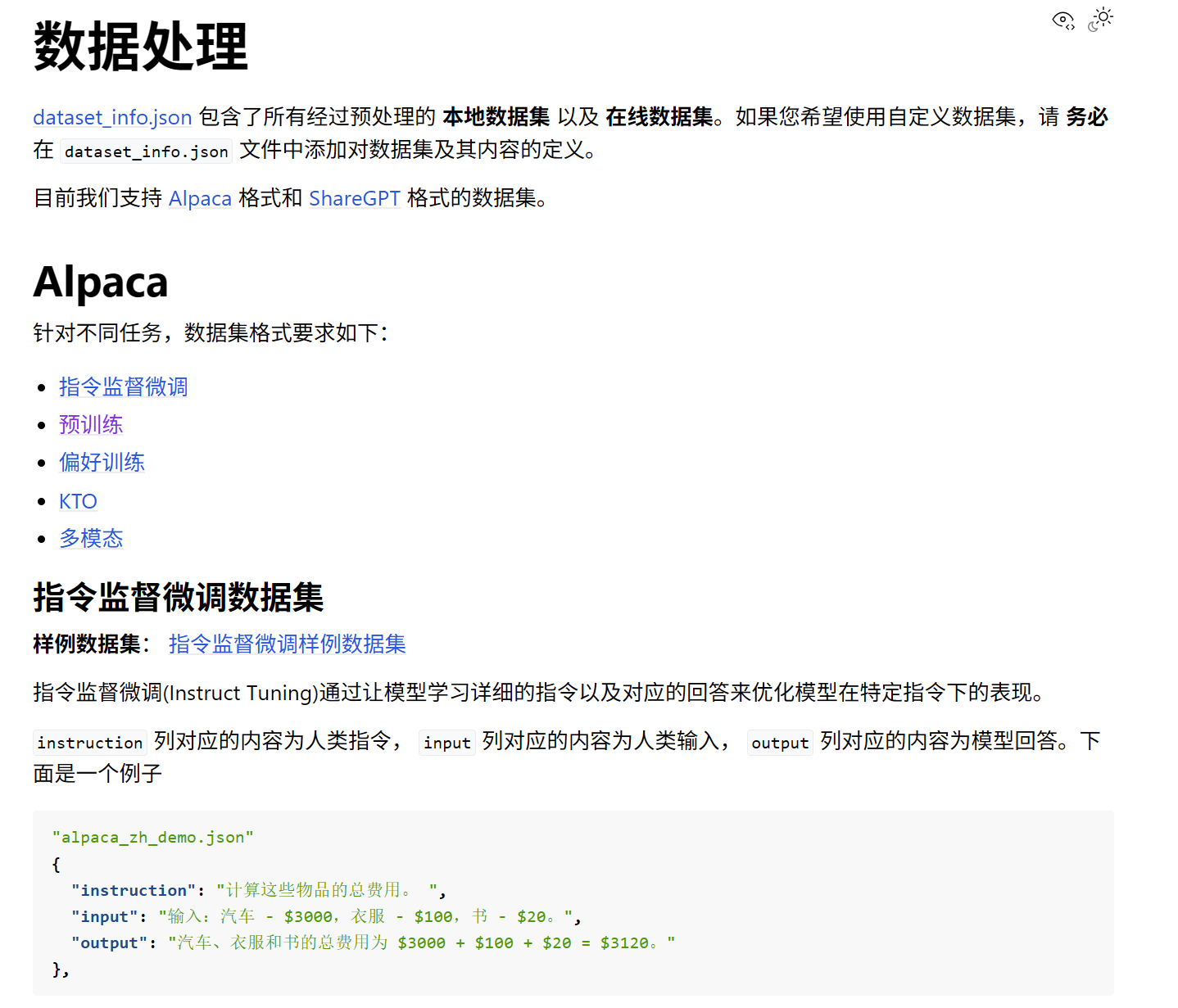
一般会有输入内容,以及基于输入内容的输出结果,让大模型去进行学习输入输出的内容长什么样子:
-
instruction 列:对应人类给出的指令。
-
input 列:对应人类提供的输入或上下文。
-
output 列:对应模型应给出的理想回答。
{
"instruction": "计算这些物品的总费用。",
"input": "输入:汽车 - 3000,衣服 - 100,书 - 20。", "output": "汽车、衣服和书的总费用为 3000 + 100 + 20 = $3120。"
}
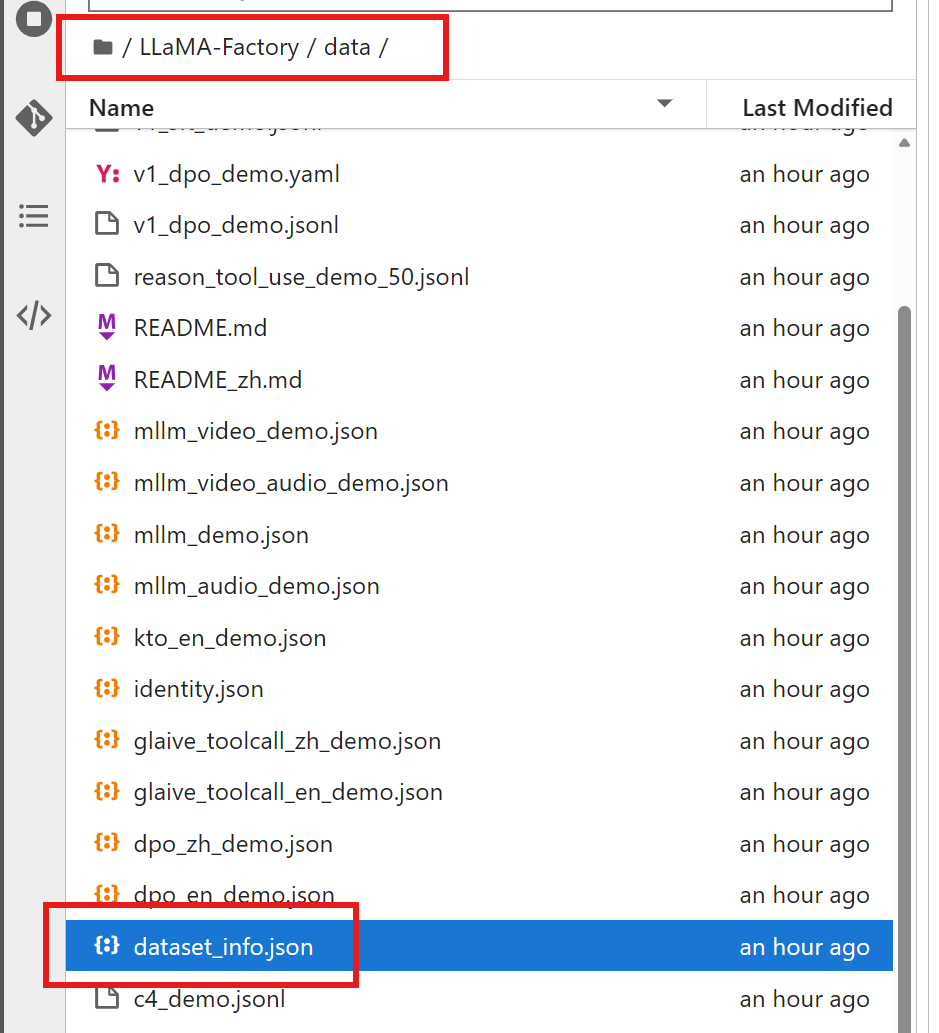
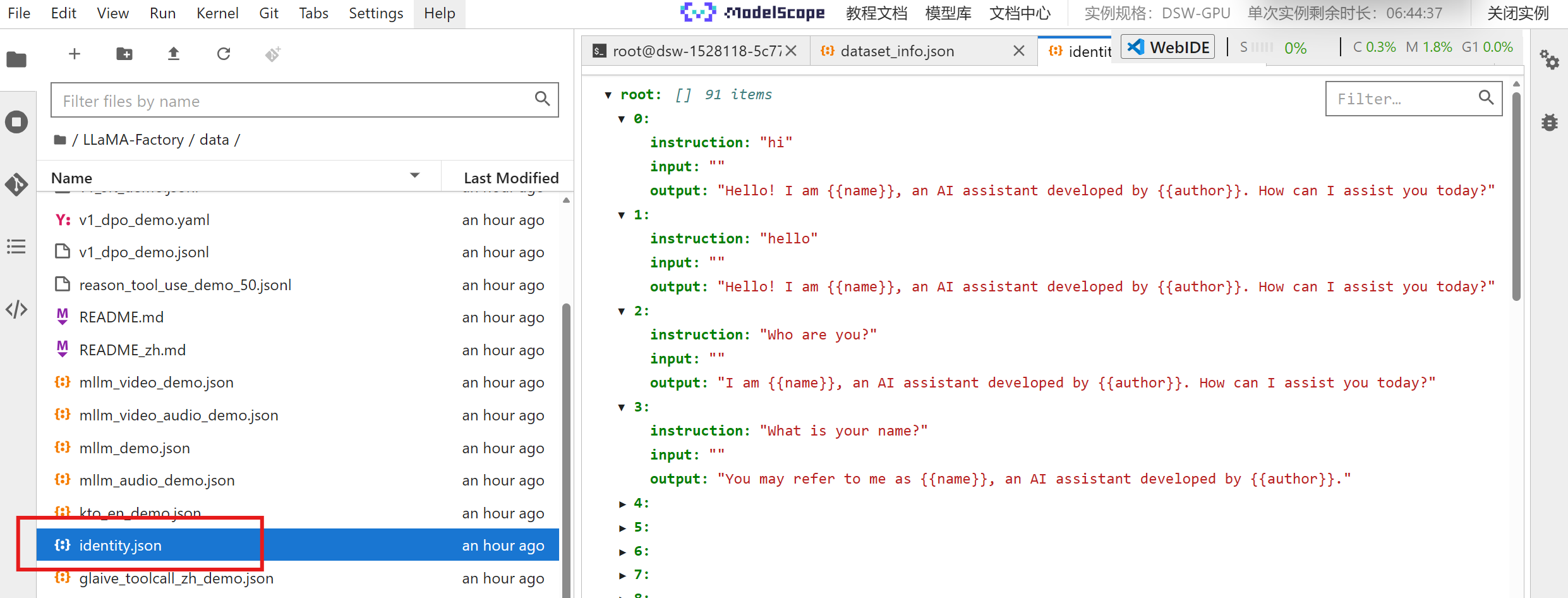
如果自己做了一个数据集想要集成到 LLaMA-Factory 做训练微调,就必须需要在 dataset_info.json 里添加对数据集及其内容的定义,在下面红圈所示的目录中能找到:
通过观察 dataset_info.json 的内容,首先是定义了模型自我认知的文件: identity.json 。
模型都会有自我认知的过程,就相当于对于模型做一个基础定义。我们找到这个文件,点进去发现主要是模型首先需要知道他自己是什么、要做什么的一系列问答问题的定义。
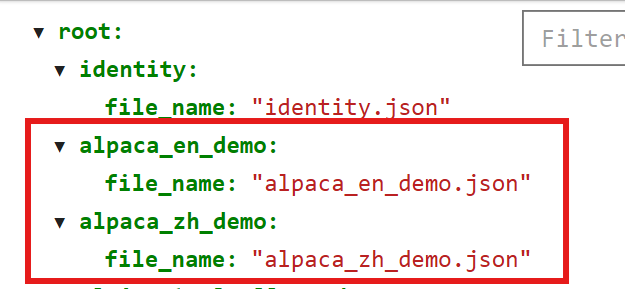
其次是业务数据的训练。首先官方提供了中文与英文两种训练数据语言:
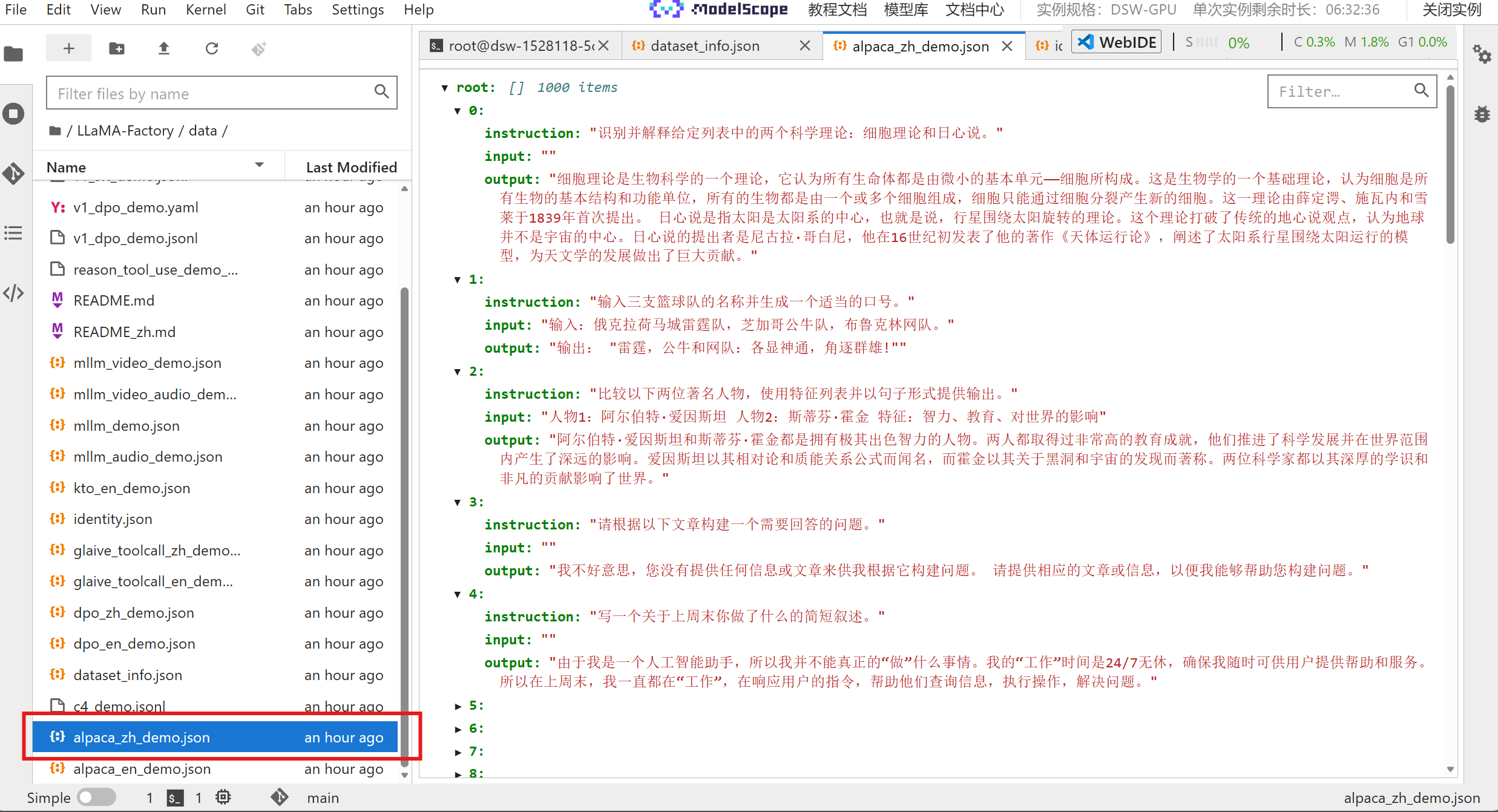
点击官方默认的训练数据集,可以发现里面就是很多常见的科普问答:
当然如果想要更多的数据集,可以在魔搭平台进行搜索:
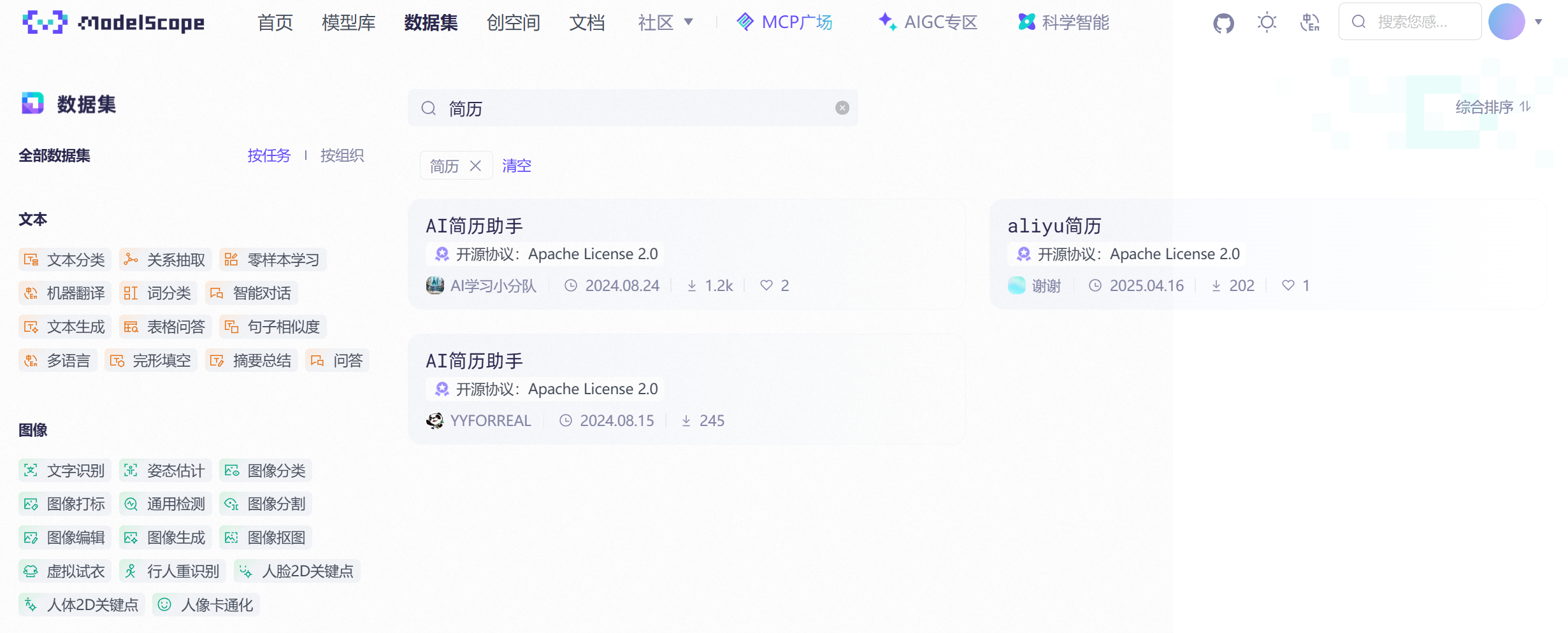
在 dataset_info.json 文件中,也定义了官方默认的下载路径,国内一般使用魔搭的路径:

模型训练
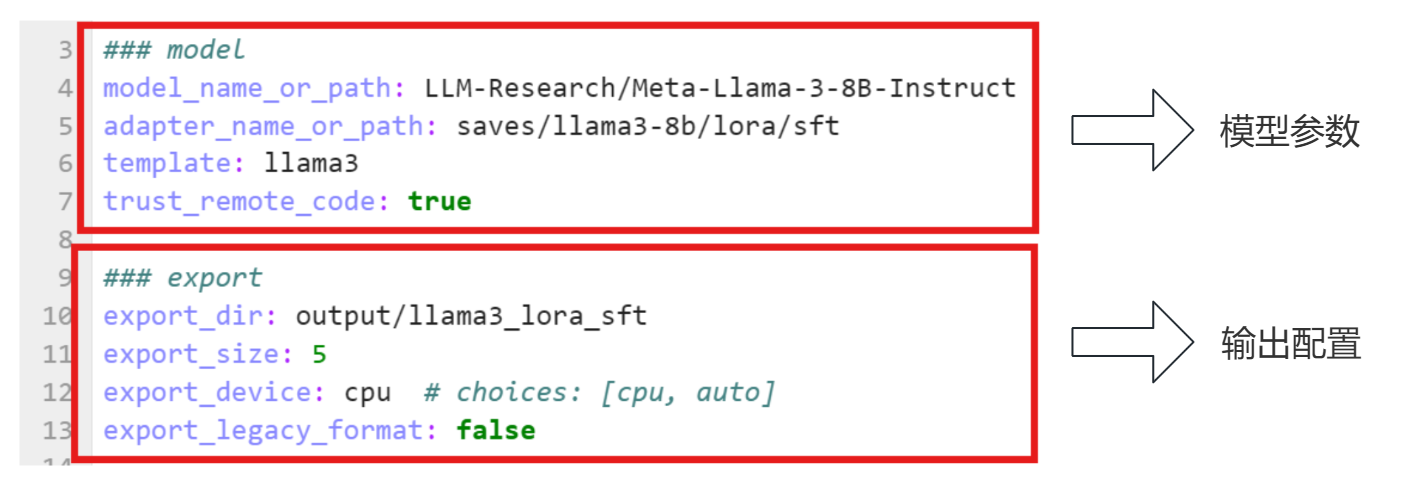
在官方的项目里,我们可以找到模型的配置文件,如下:

首先定义了模型名字,这个模型名字,以及对应的路径在魔搭平台可以搜索到:
### model
model_name_or_path: LLM-Research/Meta-Llama-3-8B-Instruct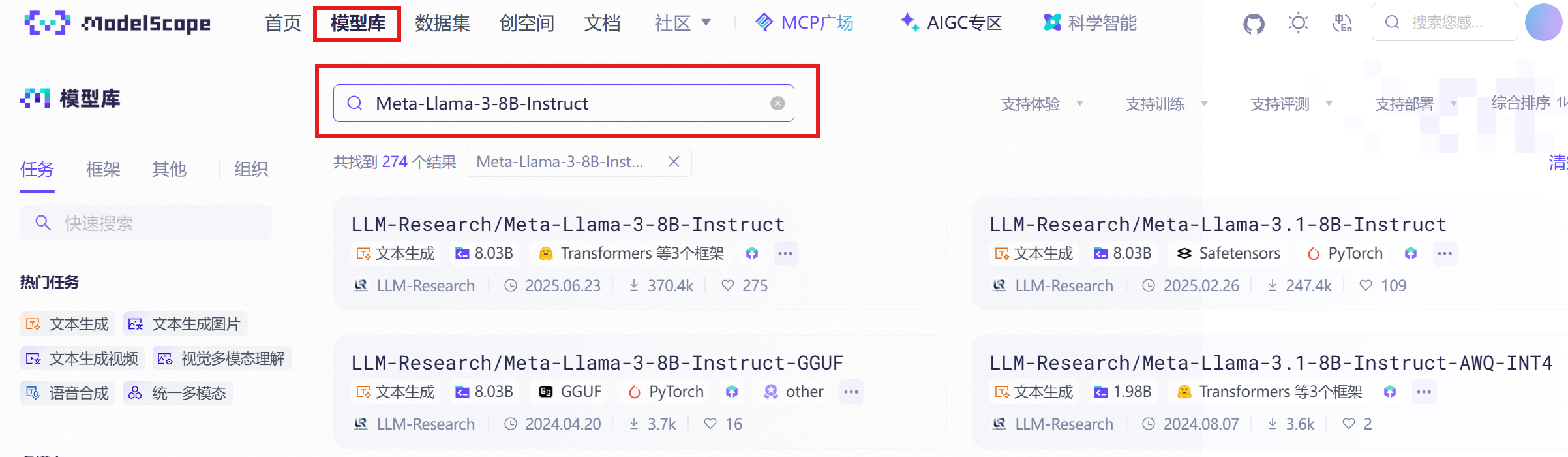
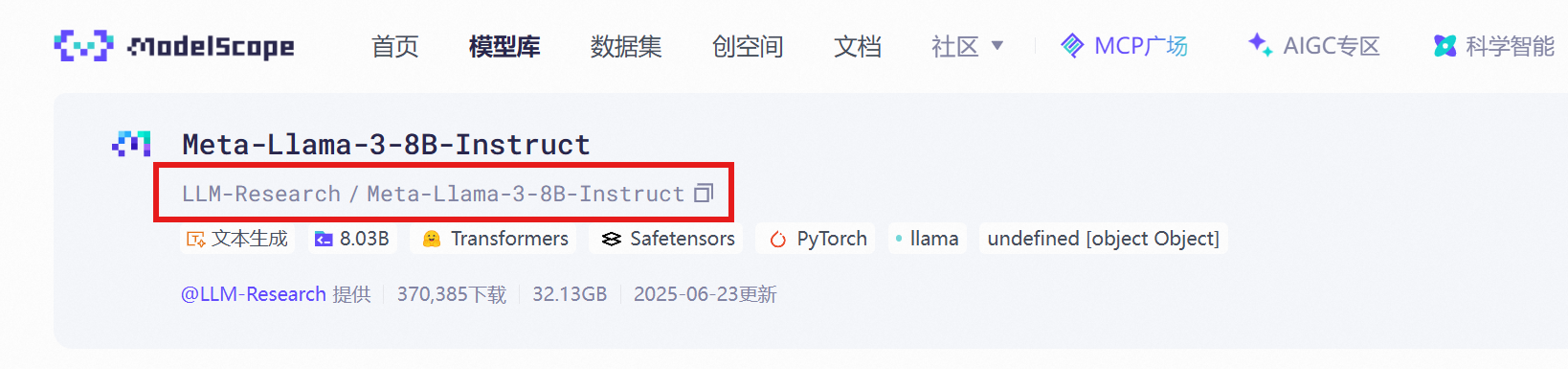
如果想要本地已经下载好的模型,路径也需要变更:

以及之前提到的训练所需的数据集文件:
### dataset
dataset: identity, alpaca_en_demo其余的内容看上面的图吧。接着就是需要执行训练命令:
llamafactory-cli train 训练文件路径比如:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml如果是像我一样用的是魔搭上面的模型,在运行训练的命令前,还需要设置环境变量:
export USE_MODELSCOPE_HUB=1 # Linux 上使用的命令当 USE_MODELSCOPE_HUB 的值为 1 时框架才会使用 ModelScope 在线资源。
查看训练结果
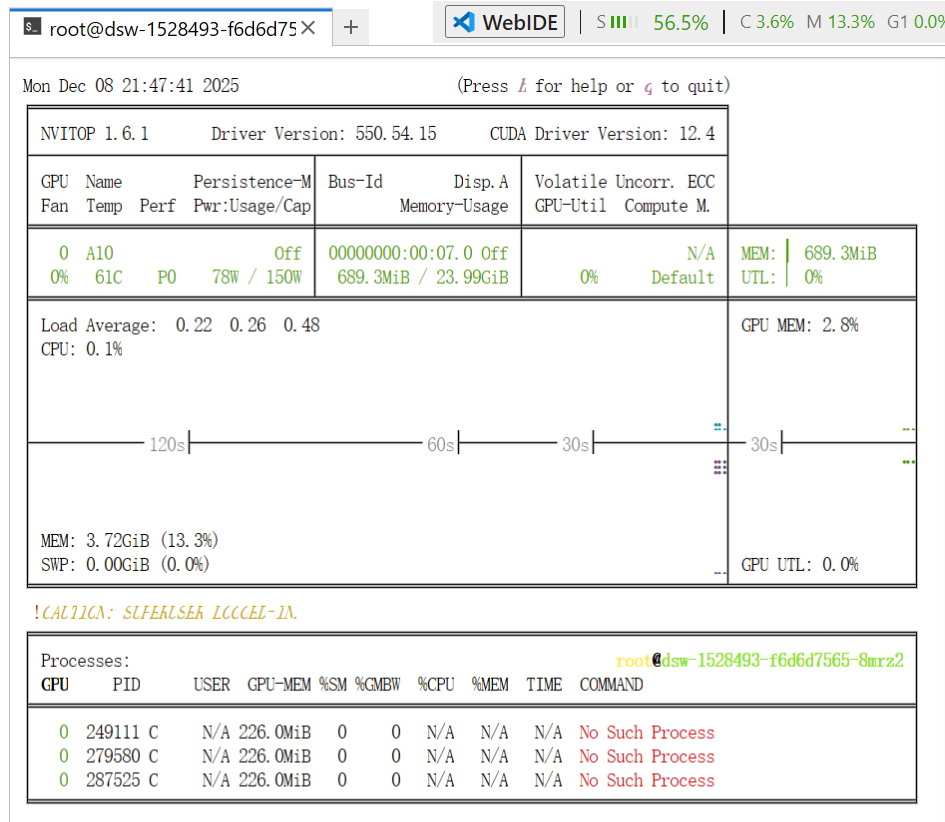
如果想要更好的查看显卡使用的情况,可以用命令:
pip install nvitop
nvitop -m auto如下的界面就是了:
最后训练结束后,训练结果在 saves 文件夹可以找到:
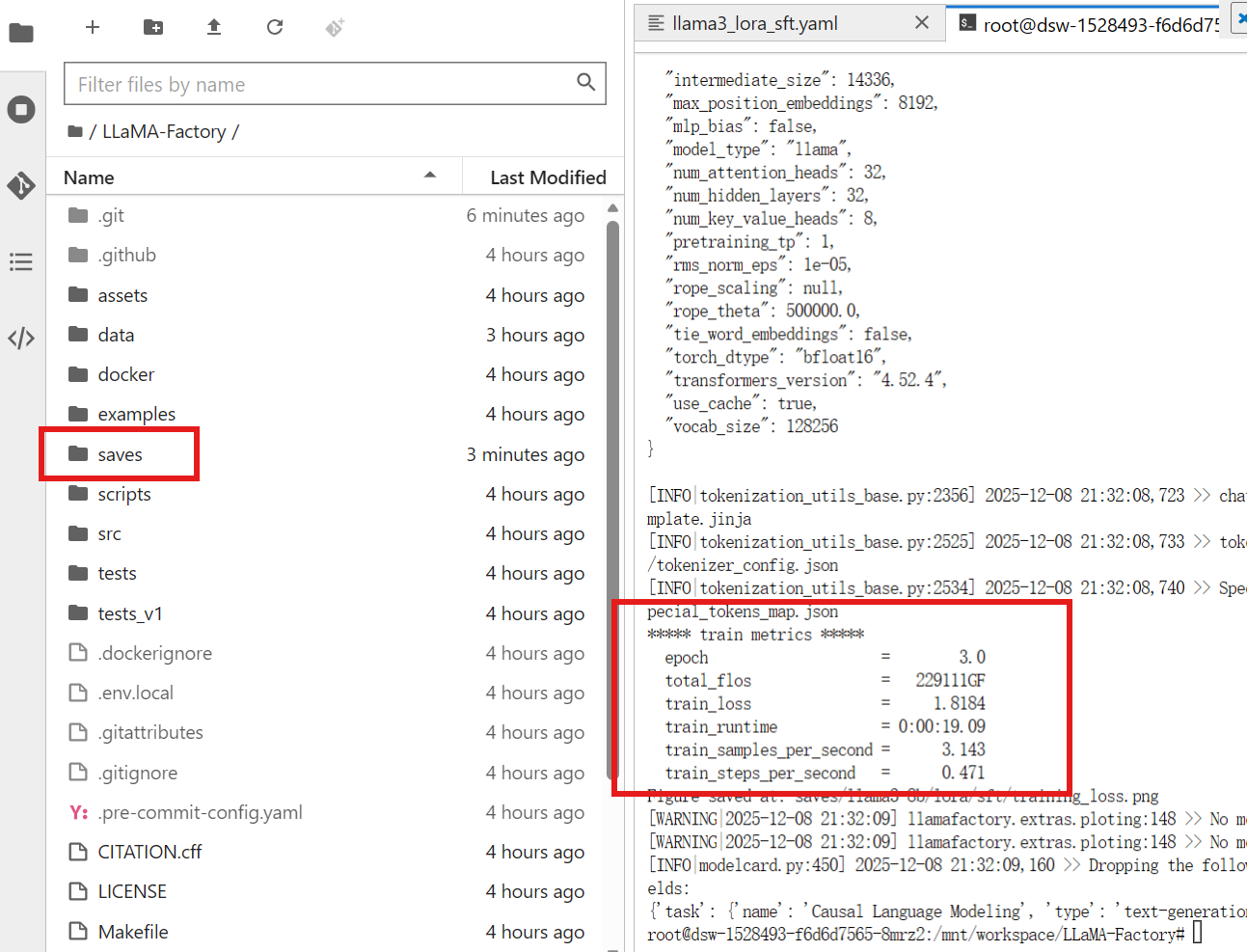
观察训练结果,epoch 就是跑的轮数(3轮),损失(train_loss)降到了 1.81 左右(无限接近于 0 就是损失精度低),训练的时间为 19 秒。
其中在 checkpoint 文件夹里的文件,就是我们的训练结果。这里的 checkpoint 文件夹的序号就表示每几步就保存一个检查点,在之前我们也配置过,最大的数字就表示最近的一次检查点,也就是最后的训练结果。
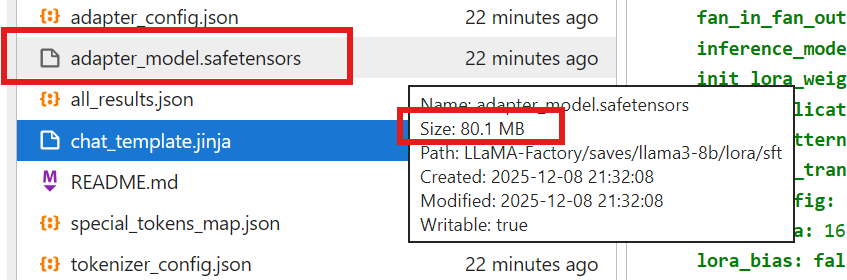
其中下面红框圈出的就是我们训练出来的小模型,可以看到只有80.1MB的大小:
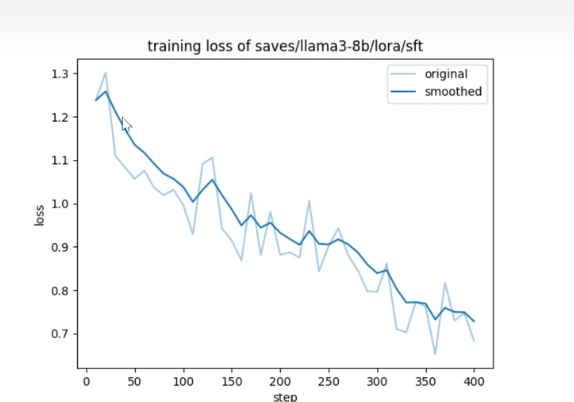
同时还有一张训练损失的图,可以看出损失精度是越来越低的。但是只有在训练轮次足够的情况下才有:
模型推理
接着就可以对模型进行简单的推理,在 inference 目录下可以找到:
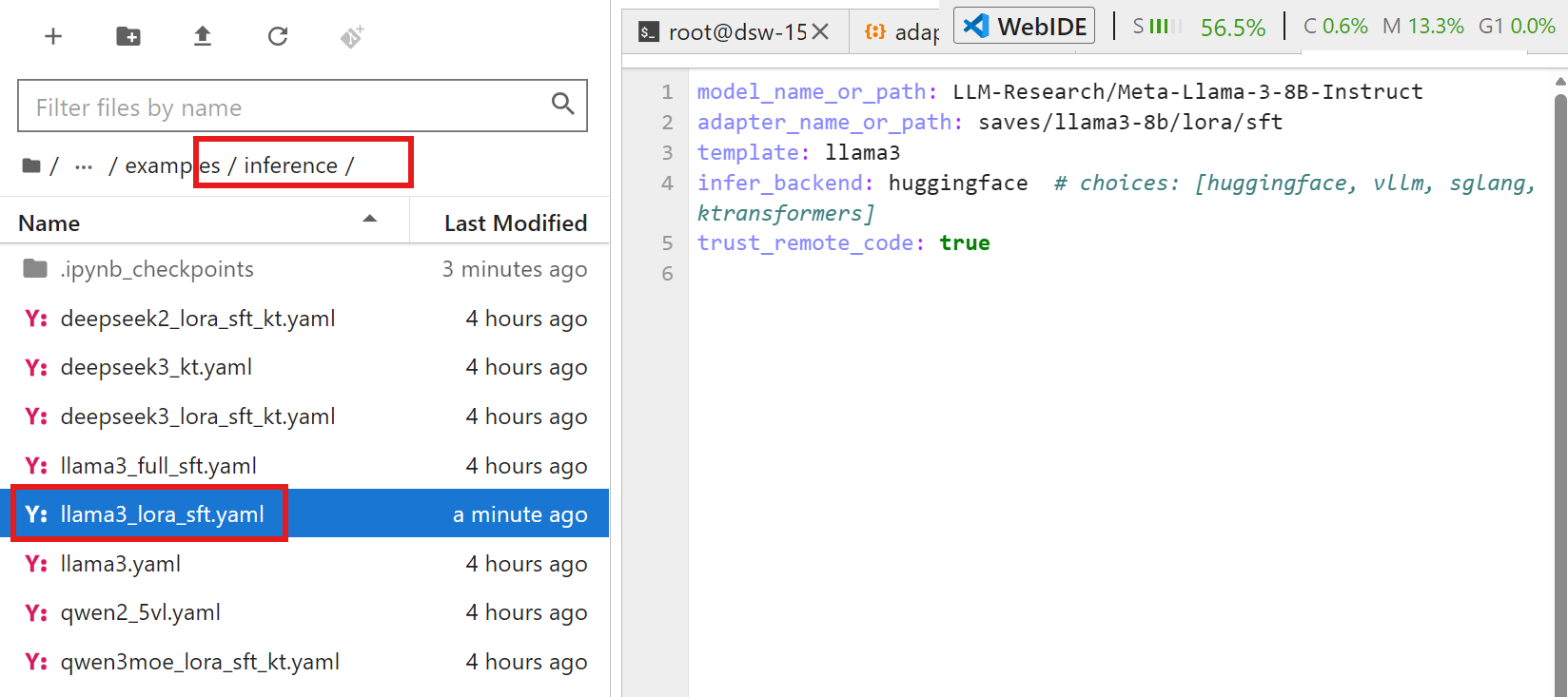 下面的命令就是对模型进行 LoRA 推理:
下面的命令就是对模型进行 LoRA 推理:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml会弹出来一个聊天框:

也可以通过追加参数更新 yaml 文件中的参数:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml \
learning_rate=le-5 \
logging_steps=1模型合并和推理
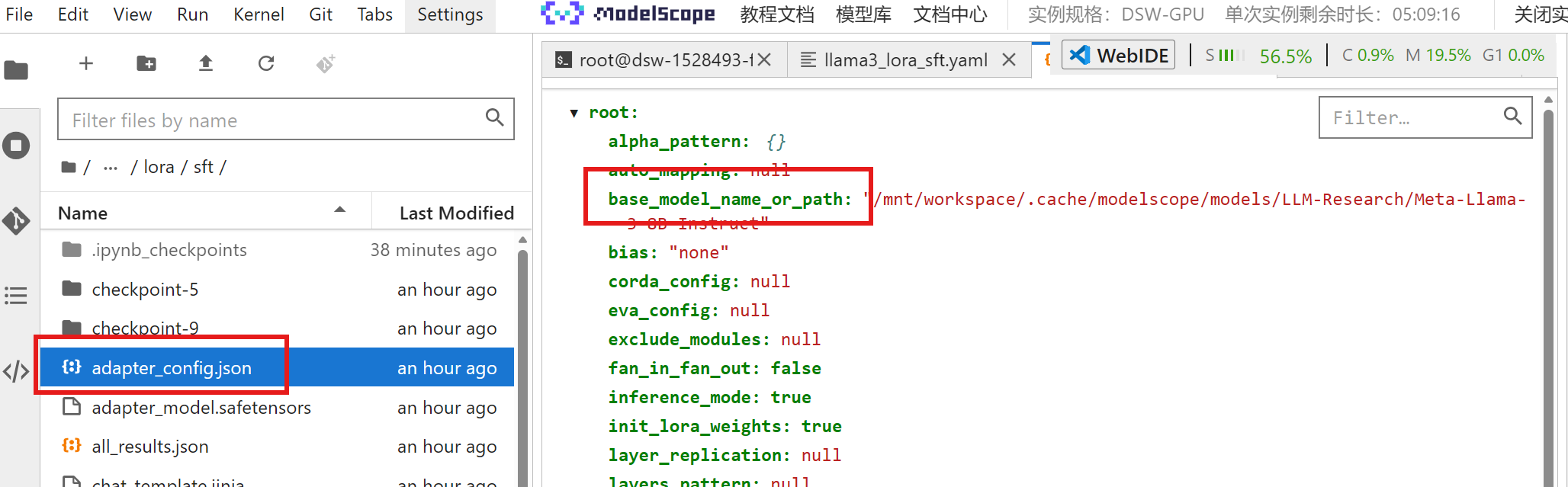
所谓的模型合并,就是把我们训练的小模型与基座模型进行合并。基座模型在 adapter_config.json 文件里有记录:
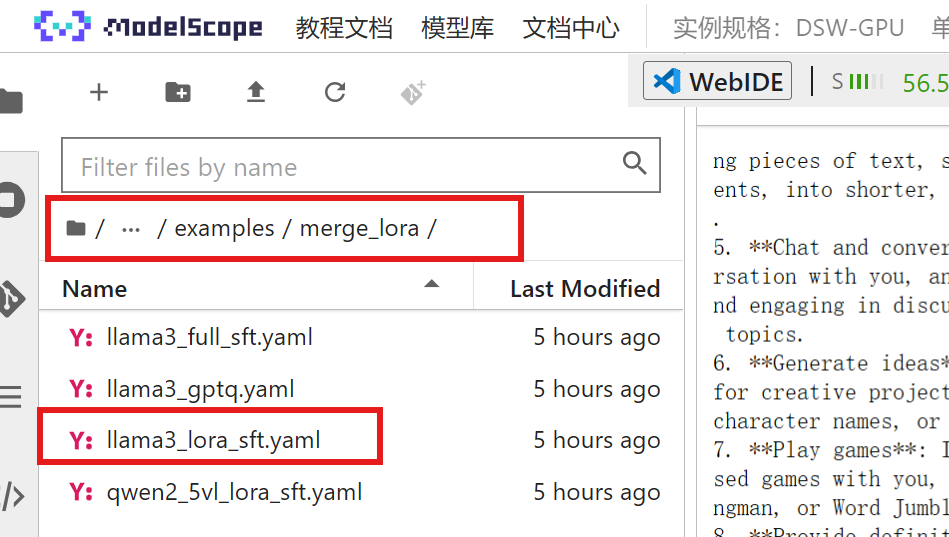
在 examples 目录下,可以找到专门用于合并模型的文件:
运行合并命令:
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml合并完后可以在 output 目录下找到合并后的模型,可以观察到与基座模型的目录结构是一致的:
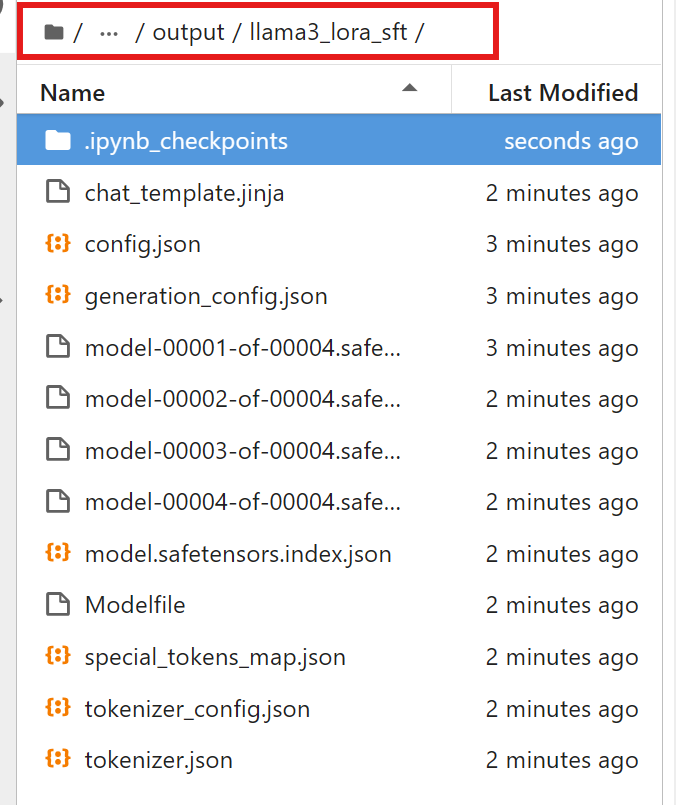
之前是基于原始微调后的模型进行推理,但是现在就需要对于合并后的模型进行推理。首先需要修改在推理文件夹下的原有的模型目录:
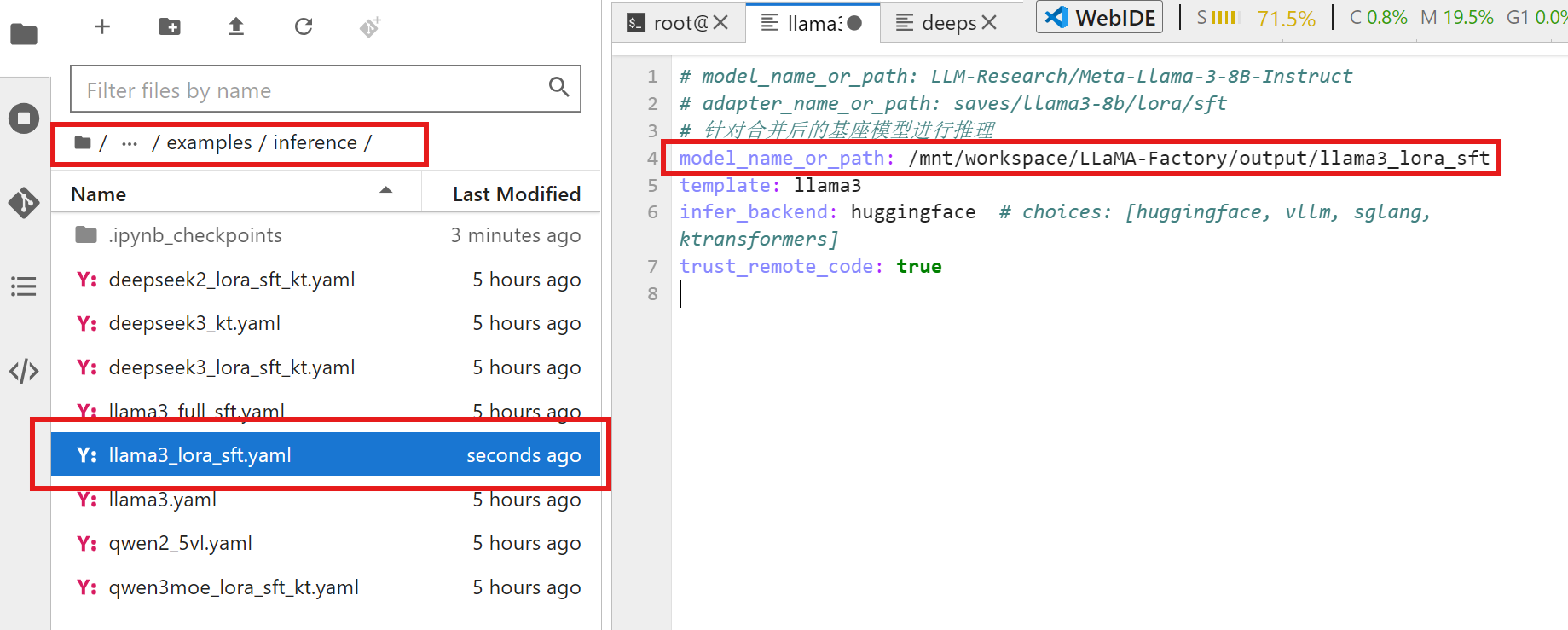
然后还是继续使用推理的命令即可:
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml模型评估
后面写
模型部署与接口调用
后面写
参考
大模型微调!3小时手把手带你用LLaMA-Factory工具微调Qwen大模型从入门到精通!_哔哩哔哩_bilibili