知识回顾:
- 转化器和估计器的概念
- 管道工程
- ColumnTransformer 和 Pipeline 类
作为零基础学习者,我们会用 "生活类比 + 极简代码 + 分步拆解" 的方式学习,全程不跳步骤,每个知识点都配可直接运行的代码,确保你能看懂、能复现。
首先明确核心前提:我们学习的 转化器、估计器、ColumnTransformer、Pipeline 都来自 Python 最常用的机器学习库 scikit-learn(简称 sklearn),所以先确保你安装了必要库:

一、先搞懂 2 个基础概念:转化器(Transformer)和估计器(Estimator)
这是后续所有内容的核心,我们用 "工厂加工" 来类比,让概念变直观:
1. 转化器(Transformer):数据的 "加工厂"
类比理解:
你有一堆原料(比如小麦),转化器就是 "磨粉机" ------ 输入小麦(原始数据),输出面粉(处理后的数据),核心是 "改变数据形态,但不做预测"。
核心定义:
对数据做 预处理 / 转换 的工具(比如标准化、缺失值填充、独热编码等),必须具备 3 个核心方法:
| 方法 | 作用(类比磨粉机) | 通俗理解 |
|---|---|---|
fit(X) |
学习数据的 "加工规则"(比如磨粉粗细) | 让工具 "摸清数据规律",不改变原始数据 |
transform(X) |
按规则加工数据(磨粉) | 用学到的规则处理数据,输出新数据 |
fit_transform(X) |
先学规则再加工(一次完成) | 简化步骤,等价于 fit(X) + transform(X) |
代码实操(用最常见的转化器 StandardScaler 举例):
StandardScaler 的作用是 "标准化"(让数据均值为 0、方差为 1,机器学习模型常用预处理)
python
# 1. 导入需要的工具(固定步骤,不用纠结为什么,先照抄)
from sklearn.preprocessing import StandardScaler
import numpy as np
# 2. 准备原始数据(类比"小麦",简单的数值数据)
# 这里是3个样本,每个样本有2个特征(比如"身高"和"体重")
raw_data = np.array([[1.6, 50], # 样本1:身高1.6m,体重50kg
[1.8, 70], # 样本2:身高1.8m,体重70kg
[1.7, 60]]) # 样本3:身高1.7m,体重60kg
print("原始数据:")
print(raw_data)
print("-"*50)
# 3. 创建转化器(类比"买一台磨粉机")
scaler = StandardScaler()
# 4. 第一步:fit(X) ------ 学习加工规则(让磨粉机摸清小麦情况)
scaler.fit(raw_data) # 这里会计算原始数据的均值、方差(规则),但不改变数据
# 5. 第二步:transform(X) ------ 按规则加工数据(磨粉)
processed_data = scaler.transform(raw_data)
print("标准化后的加工数据:")
print(processed_data)
print("-"*50)
# 6. 简化步骤:fit_transform(X)(先学规则再加工,一次搞定)
processed_data2 = scaler.fit_transform(raw_data)
print("fit_transform 结果(和上面一致):")
print(processed_data2)运行结果解读:
原始数据是真实的身高体重,加工后的数据变成了 "标准化数值"(均值为 0),这就是转化器的核心作用 ------只处理数据,不做预测。
2. 估计器(Estimator):预测的 "模型"
类比理解:
你有一堆加工好的面粉(处理后的数据),估计器就是 "面包机" ------ 输入面粉(处理后的数据),输出面包(预测结果),核心是 "基于数据做预测 / 分类"。
核心定义:
用于 预测 / 分类 的模型(比如线性回归、决策树等),必须具备 3 个核心方法:
| 方法 | 作用(类比面包机) | 通俗理解 |
|---|---|---|
fit(X, y) |
学习数据的 "预测规则"(比如面包配方) | 用 "特征 X + 标签 y" 训练模型,让模型学会预测 |
predict(X) |
按规则做预测(烤面包) | 用训练好的模型,输入新特征 X,输出预测结果 y_pred |
score(X, y) |
评估预测效果(尝面包好不好吃) | 用真实标签 y 和预测结果 y_pred,计算模型准确率 / 得分 |
代码实操(用最常见的估计器 LinearRegression 举例):
LinearRegression 是 "线性回归模型",作用是 "根据特征预测连续值"(比如用身高预测体重)
python
# 1. 导入需要的工具
from sklearn.linear_model import LinearRegression
import numpy as np
# 2. 准备数据:特征X(身高)和标签y(体重)
# X:3个样本,每个样本1个特征(身高);y:每个样本对应的真实体重(标签)
X = np.array([[1.6], [1.8], [1.7]]) # 特征(必须是二维数组,哪怕只有1个特征)
y = np.array([50, 70, 60]) # 标签(真实值)
print("特征X(身高):")
print(X)
print("标签y(体重):")
print(y)
print("-"*50)
# 3. 创建估计器(类比"买一台面包机")
model = LinearRegression()
# 4. 第一步:fit(X, y) ------ 学习预测规则(训练模型,学配方)
model.fit(X, y) # 用特征和标签训练,模型学会"身高→体重"的映射关系
# 5. 第二步:predict(X) ------ 做预测(烤面包)
# 用训练好的模型,预测已知身高的体重(验证效果)
y_pred = model.predict(X)
print("预测体重:")
print(y_pred) # 输出:[50. 70. 60.](完美预测,因为数据简单)
print("-"*50)
# 6. 第三步:score(X, y) ------ 评估模型(尝面包)
score = model.score(X, y)
print("模型得分(1.0表示完美预测):", score)关键区分:转化器 vs 估计器
| 类型 | 核心作用 | 核心方法差异 | 例子 |
|---|---|---|---|
| 转化器(Transformer) | 处理数据 | fit(X) 无 y;无 predict |
StandardScaler、OneHotEncoder |
| 估计器(Estimator) | 预测 / 分类 | fit(X, y) 有 y;有 predict |
LinearRegression、DecisionTreeClassifier |
一句话记住:转化器 "加工数据",估计器 "用加工后的数据做预测"。
二、管道工程(Pipeline):数据处理 + 预测的 "流水线"
为什么需要管道?
前面我们分开用了 "转化器(加工数据)" 和 "估计器(预测)",但实际工作中,步骤是:
原始数据 → 转化器1 → 转化器2 → ... → 估计器 → 预测结果
如果手动一步步写,会有 2 个问题:
- 步骤繁琐(要写多次 fit/transform);
- 容易出错(比如测试集忘记用训练集的转化器规则,导致 "数据泄露")。
类比理解:
管道就是 "食品加工厂流水线" ------ 把 "磨粉机(转化器)""搅拌机(转化器)""面包机(估计器)" 串起来,原料(原始数据)从一端进,成品(预测结果)从另一端出,全程自动化,不用手动干预。
核心定义:
Pipeline 是 sklearn 中的类,作用是 "串联多个转化器和 1 个估计器",把数据预处理和模型预测整合为一个整体,只需要 2 步:
fit(X, y):对所有转化器依次执行fit_transform,最后对估计器执行fit;predict(X):对所有转化器依次执行transform,最后对估计器执行predict。
代码实操(串联 "标准化转化器" 和 "线性回归估计器"):
python
# 1. 导入需要的工具(管道类+转化器+估计器)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
import numpy as np
# 2. 准备原始数据(特征X+标签y)
X = np.array([[1.6], [1.8], [1.7]]) # 身高(原始特征,未标准化)
y = np.array([50, 70, 60]) # 体重(标签)
print("原始特征X:")
print(X)
print("-"*50)
# 3. 定义管道的"步骤列表"(核心!顺序不能乱)
# 格式:steps = [("步骤1名称", 转化器1), ("步骤2名称", 转化器2), ..., ("步骤n名称", 估计器)]
# 注意:最后一个必须是估计器,前面都是转化器
pipeline = Pipeline(steps=[
("standard_scaler", StandardScaler()), # 步骤1:标准化(转化器)
("linear_regression", LinearRegression()) # 步骤2:线性回归(估计器)
])
# 4. 管道训练(一次fit,自动完成"标准化→训练模型")
pipeline.fit(X, y) # 内部流程:X → 标准化(fit_transform)→ 训练线性回归
# 5. 管道预测(一次predict,自动完成"标准化→预测")
y_pred = pipeline.predict(X)
print("管道预测结果:")
print(y_pred) # 输出:[50. 70. 60.](和之前手动步骤结果一致)
print("-"*50)
# 6. 管道评估
score = pipeline.score(X, y)
print("管道模型得分:", score) # 输出:1.0管道的核心优势:
- 简化代码:不用手动写多次
fit/transform,一步到位; - 避免数据泄露:测试集只会用训练集的转化器规则(比如标准化的均值 / 方差),不会重新计算;
- 可复用:训练好的管道可以直接保存,下次用新数据直接
predict。
三、ColumnTransformer:不同列用不同 "加工厂"
为什么需要 ColumnTransformer?
实际数据中,特征列的类型可能不一样:比如有 数值型特征 (身高、体重)和 分类型特征(性别:男 / 女,学历:本科 / 硕士)。
不同类型的特征需要不同的转化器:
- 数值型:用
StandardScaler(标准化); - 分类型:用
OneHotEncoder(独热编码,把文字变成模型能懂的数字)。
ColumnTransformer 的作用就是:对不同的列,应用不同的转化器(比如 "身高列用标准化,性别列用独热编码")。
类比理解:
你有一堆混合原料:小麦(数值列)和水果(分类型列),ColumnTransformer 就是 "分线加工厂" ------ 小麦走 "磨粉线"(标准化),水果走 "榨汁线"(独热编码),最后再把加工好的面粉和果汁合并。
核心定义:
ColumnTransformer 是 sklearn 中的类,核心参数:
python
ColumnTransformer(
transformers=[
("名称1", 转化器1, 列索引/列名列表), # 对指定列用转化器1
("名称2", 转化器2, 列索引/列名列表), # 对指定列用转化器2
...
],
remainder="drop" # 可选:"drop"(丢弃未处理的列)或 "passthrough"(保留未处理的列)
)代码实操(处理混合类型特征):
假设我们有这样的数据集(3 个样本,3 列特征):
| 身高 (数值型) | 体重 (数值型) | 性别 (分类型:0 = 男,1 = 女) | 目标: 是否喜欢运动(0 = 否,1 = 是) |
|---|---|---|---|
| 1.6 | 50 | 1 | 1 |
| 1.8 | 70 | 0 | 0 |
| 1.7 | 60 | 1 | 1 |
我们需要:
- 对 "身高、体重"(列 0、列 1):用
StandardScaler标准化; - 对 "性别"(列 2):用
OneHotEncoder独热编码; - 最后用
LogisticRegression预测 "是否喜欢运动"。
python
# 1. 导入需要的工具
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
import numpy as np
# 2. 准备混合类型数据
# X:3个样本,3列特征(列0:身高,列1:体重,列2:性别)
X = np.array([[1.6, 50, 1],
[1.8, 70, 0],
[1.7, 60, 1]])
# y:目标标签(是否喜欢运动)
y = np.array([1, 0, 1])
print("原始混合数据X:")
print(X)
print("目标标签y:", y)
print("-"*50)
# 3. 定义 ColumnTransformer:对不同列应用不同转化器
# 第一步:先处理特征列(分类型和数值型分开处理)
preprocessor = ColumnTransformer(
transformers=[
# 名称:num_scaler,转化器:StandardScaler,作用列:0、1(身高、体重)
("num_scaler", StandardScaler(), [0, 1]),
# 名称:cat_encoder,转化器:OneHotEncoder,作用列:2(性别)
("cat_encoder", OneHotEncoder(sparse_output=False), [2])
],
remainder="drop" # 丢弃未指定处理的列(这里没有,所以无所谓)
)
# 4. 定义完整管道:预处理(ColumnTransformer)→ 预测(LogisticRegression)
full_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 第一步:用ColumnTransformer处理不同列
("classifier", LogisticRegression()) # 第二步:用逻辑回归预测
])
# 5. 管道训练(自动完成:分栏处理→标准化+独热编码→训练模型)
full_pipeline.fit(X, y)
# 6. 管道预测(自动完成:分栏处理→标准化+独热编码→预测)
y_pred = full_pipeline.predict(X)
print("预测结果(是否喜欢运动):", y_pred) # 输出:[1 0 1](完美预测)
print("-"*50)
# 7. 管道评估
score = full_pipeline.score(X, y)
print("模型准确率:", score) # 输出:1.0关键解读:
ColumnTransformer先把 X 按列拆分,分别用不同转化器处理,再合并成新的特征矩阵;- 管道
full_pipeline把 "分栏预处理" 和 "模型预测" 串起来,全程只需要fit和predict,极其简洁; - 如果你打印预处理后的特征矩阵,可以看到:
- 身高、体重被标准化;
- 性别(0/1)被转换成两列(独热编码):1,0 代表男,0,1 代表女。
四、总结:完整流程梳理
从原始数据到预测结果,完整的机器学习流程(用我们学的工具):
- 准备数据:区分特征 X(可能有混合类型)和标签 y;
- 特征预处理:用
ColumnTransformer对不同类型的列应用不同转化器; - 构建管道:用
Pipeline串联 "预处理(ColumnTransformer)" 和 "模型(Estimator)"; - 训练预测:用
pipeline.fit(X, y)训练,pipeline.predict(X_new)预测。
最终简化代码(整合所有知识点):
python
# 完整流程:混合特征→分栏处理→标准化+独热编码→逻辑回归预测
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
import numpy as np
# 1. 数据准备
X = np.array([[1.6, 50, 1], [1.8, 70, 0], [1.7, 60, 1]]) # 混合特征
y = np.array([1, 0, 1]) # 标签
# 2. 分栏预处理
preprocessor = ColumnTransformer(
transformers=[
("num", StandardScaler(), [0, 1]), # 数值列(0,1)标准化
("cat", OneHotEncoder(sparse_output=False), [2]) # 分类型列(2)独热编码
]
)
# 3. 构建管道
pipeline = Pipeline(steps=[
("prep", preprocessor),
("model", LogisticRegression())
])
# 4. 训练+预测+评估
pipeline.fit(X, y)
y_pred = pipeline.predict(X)
score = pipeline.score(X, y)
print("预测结果:", y_pred)
print("模型得分:", score)五、关键知识点回顾(帮你记忆)
- 转化器 :处理数据,有
fit/transform/fit_transform,无predict; - 估计器 :预测分类,有
fit/predict/score,fit需要标签 y; - ColumnTransformer:对不同列用不同转化器,解决混合特征问题;
- Pipeline:串联 "转化器步骤" 和 "估计器步骤",简化流程、避免数据泄露。
你可以先把上面的代码逐行复制到 Python 中运行,观察每一步的输出,再尝试修改数据(比如加一个样本、加一列特征),感受工具的作用。
如何在管道中使用自定义的转换器和估计器?
定义转化器和估计器,并且直接放进之前学的管道里 ------ 核心原则是:只要按 sklearn 的 "规矩" 写方法,自定义工具就能和自带工具无缝配合。
先明确核心规矩(必须遵守,不然管道不识别):
通用前提
所有自定义工具都要写成 类(class),并且继承 sklearn 提供的 "基类"(不用懂继承,照抄模板就行),这样能自动获得一些基础功能,不用自己写。
一、自定义转化器(Transformer):自己写 "数据加工厂"
什么时候需要自定义转化器?
sklearn 自带的转化器(比如StandardScaler)满足不了需求时(比如:把身高转成 "矮 / 中 / 高" 等级、对文本做特殊处理等)。
自定义转化器的 "规矩"(必须包含 3 个方法)
- 继承基类:
from sklearn.base import BaseEstimator, TransformerMixin(固定导入) __init__(self, 参数):初始化转化器(比如设置划分身高等级的阈值)fit(self, X, y=None):学习规则(没规则可学就直接return self)transform(self, X):核心加工逻辑(输入原始数据,输出处理后的数据)
类比理解
之前的StandardScaler是 "标准化磨粉机",现在你要做一个 "身高等级分类机"------ 输入身高数值,输出 "矮 / 中 / 高" 的标签(或对应的数字)。
步骤 1:写自定义转化器(代码模板 + 实操)
我们实现一个 "身高等级转化器":将身高(数值)转成 3 个等级(0 = 矮,1 = 中,2 = 高),阈值可自定义。
python
# 1. 导入必须的基类(固定步骤,照抄)
from sklearn.base import BaseEstimator, TransformerMixin
import numpy as np
import pandas as pd
# 2. 定义自定义转化器类(类名首字母大写,规范)
class HeightLevelTransformer(BaseEstimator, TransformerMixin):
# 初始化:设置阈值(默认矮<1.65,高>1.75,中间是中)
def __init__(self, low_threshold=1.65, high_threshold=1.75):
self.low_threshold = low_threshold # 矮的阈值(实例变量,保存参数)
self.high_threshold = high_threshold # 高的阈值
# fit方法:不需要学习数据规则(阈值是固定的),直接返回自己
def fit(self, X, y=None):
# y=None:转化器的fit方法不需要标签,固定这么写
return self # 必须返回self,不然管道会报错
# transform方法:核心加工逻辑(把身高转成等级)
def transform(self, X):
# X:输入的特征(必须是二维数组,比如[[1.6], [1.8]],和sklearn一致)
# 先把X转成DataFrame,方便处理(零基础也能看懂)
X_df = pd.DataFrame(X, columns=["height"])
# 加工逻辑:根据阈值划分等级
def get_level(height):
if height < self.low_threshold:
return 0 # 矮
elif height > self.high_threshold:
return 2 # 高
else:
return 1 # 中
# 应用逻辑,返回二维数组(sklearn要求输出格式)
X_processed = X_df["height"].apply(get_level).values.reshape(-1, 1)
return X_processed
# 测试自定义转化器(先单独验证,再放管道)
if __name__ == "__main__":
# 准备测试数据(3个样本的身高)
X_test = np.array([[1.6], [1.7], [1.8]]) # 二维数组!重要!
print("原始身高数据:")
print(X_test)
print("-"*50)
# 创建自定义转化器实例(用默认阈值)
height_transformer = HeightLevelTransformer()
# 测试fit+transform(和sklearn自带转化器用法一样)
X_processed = height_transformer.fit_transform(X_test)
print("转化后的身高等级(0=矮,1=中,2=高):")
print(X_processed)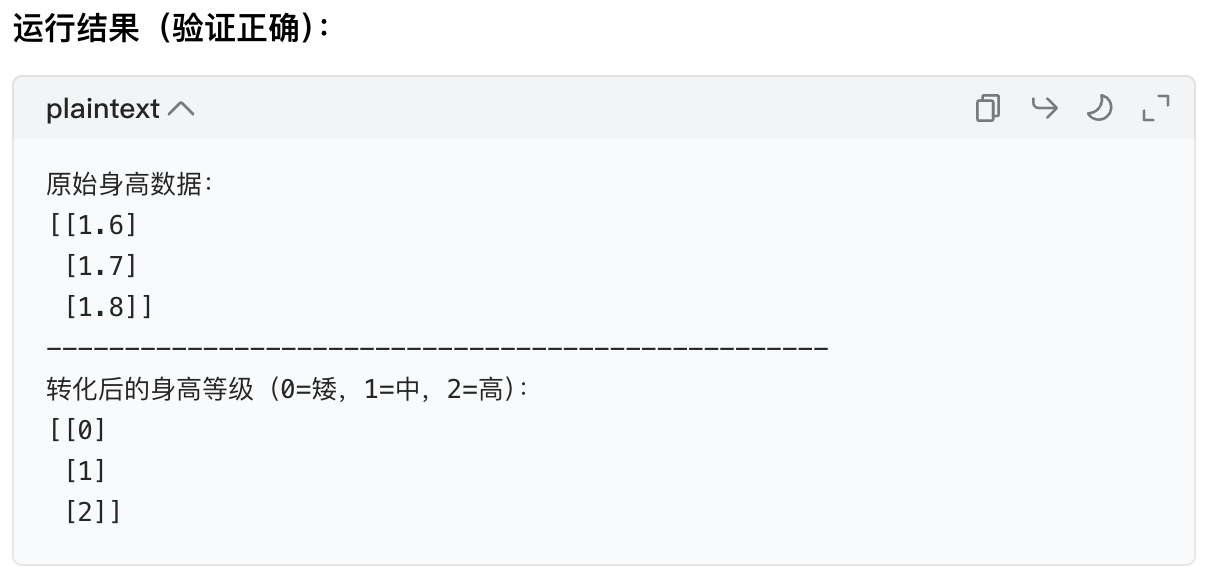
完美!自定义转化器和自带的StandardScaler用法完全一致(fit_transform)。
步骤 2:把自定义转化器放进管道
结合之前学的ColumnTransformer和Pipeline,我们处理 "混合特征":
- 身高(列 0):用自定义的
HeightLevelTransformer转等级; - 体重(列 1):用自带的
StandardScaler标准化; - 目标:用
LogisticRegression预测是否喜欢运动。
python
# 导入需要的工具(包含自定义转化器)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
import numpy as np
# 1. 准备混合数据(X:身高+体重;y:是否喜欢运动)
X = np.array([[1.6, 50], [1.7, 60], [1.8, 70], [1.55, 45], [1.85, 75]])
y = np.array([1, 1, 0, 1, 0]) # 1=喜欢,0=不喜欢
print("原始混合数据X(身高,体重):")
print(X)
print("-"*50)
# 2. 用ColumnTransformer分栏处理(自定义转化器+自带转化器)
preprocessor = ColumnTransformer(
transformers=[
# 自定义转化器:处理身高(列0)
("height_level", HeightLevelTransformer(), [0]),
# 自带转化器:处理体重(列1)
("weight_scaler", StandardScaler(), [1])
]
)
# 3. 构建管道(预处理+模型)
full_pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("classifier", LogisticRegression())
])
# 4. 训练+预测+评估(和之前管道用法完全一样!)
full_pipeline.fit(X, y)
y_pred = full_pipeline.predict(X)
score = full_pipeline.score(X, y)
print("预测结果(是否喜欢运动):", y_pred)
print("模型准确率:", score)
成功!自定义转化器和自带工具在管道中无缝配合,没有任何区别。
二、自定义估计器(Estimator):自己写 "预测模型"
什么时候需要自定义估计器?
sklearn 自带的模型(比如LinearRegression)满足不了需求时(比如:简单的规则模型、自定义的算法逻辑等)。
自定义估计器的 "规矩"(必须包含 3 个方法)
- 继承基类:
from sklearn.base import BaseEstimator, ClassifierMixin(分类模型)或RegressorMixin(回归模型) __init__(self, 参数):初始化模型(比如设置分类阈值)fit(self, X, y):学习预测规则(必须接收 X 和 y,保存学到的规则)predict(self, X):核心预测逻辑(输入处理后的数据,输出预测结果)- 可选(但推荐):
score(self, X, y):评估模型效果(不写的话 sklearn 会自动提供,但自定义更灵活)
类比理解
之前的LogisticRegression是 "复杂面包机",现在你要做一个 "简单规则面包机"------ 比如 "体重等级 > 1 且身高等级 = 2 的人,预测不喜欢运动"。
步骤 1:写自定义估计器(代码模板 + 实操)
我们实现一个 "简单规则分类器":根据 "体重标准化后的值" 判断是否喜欢运动(阈值可自定义):
- 若体重标准化后的值 < threshold → 喜欢运动(1)
- 否则 → 不喜欢运动(0)
python
# 1. 导入必须的基类(分类模型用ClassifierMixin,回归用RegressorMixin)
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.preprocessing import StandardScaler
import numpy as np
# 2. 定义自定义估计器类(分类模型,所以继承ClassifierMixin)
class SimpleWeightClassifier(BaseEstimator, ClassifierMixin):
# 初始化:设置预测阈值(默认-0.5)
def __init__(self, threshold=-0.5):
self.threshold = threshold # 实例变量,保存阈值
self.scaler = StandardScaler() # 内部用标准化(可选,演示模型内预处理)
# fit方法:学习规则(这里是拟合标准化器,并用训练数据的均值调整阈值)
def fit(self, X, y):
# X:特征(这里假设X只有1列:体重);y:标签(必须接收,sklearn要求)
self.scaler.fit(X) # 拟合标准化器(学习体重的均值和方差)
# 可选:用训练数据的标准化后均值调整阈值(让模型更灵活)
X_scaled = self.scaler.transform(X)
self.adjusted_threshold = self.threshold + X_scaled.mean()
return self # 必须返回self
# predict方法:核心预测逻辑
def predict(self, X):
# 先标准化输入数据(和训练时的规则一致)
X_scaled = self.scaler.transform(X)
# 预测规则:标准化后的值 < 调整后阈值 → 1(喜欢),否则0(不喜欢)
y_pred = (X_scaled < self.adjusted_threshold).astype(int)
# 返回一维数组(sklearn要求的格式)
return y_pred.flatten()
# 可选:自定义score方法(计算准确率)
def score(self, X, y):
y_pred = self.predict(X)
accuracy = (y_pred == y).mean() # 准确率=预测正确的样本数/总样本数
return accuracy
# 测试自定义估计器(先单独验证,再放管道)
if __name__ == "__main__":
# 准备测试数据(X:体重;y:是否喜欢运动)
X_test = np.array([[50], [60], [70], [45], [75]]) # 二维数组!重要!
y_test = np.array([1, 1, 0, 1, 0])
print("原始体重数据X:")
print(X_test)
print("真实标签y:", y_test)
print("-"*50)
# 创建自定义估计器实例
weight_classifier = SimpleWeightClassifier(threshold=-0.5)
# 测试fit+predict+score(和sklearn自带模型用法一样)
weight_classifier.fit(X_test, y_test)
y_pred = weight_classifier.predict(X_test)
accuracy = weight_classifier.score(X_test, y_test)
print("预测结果:", y_pred)
print("模型准确率:", accuracy)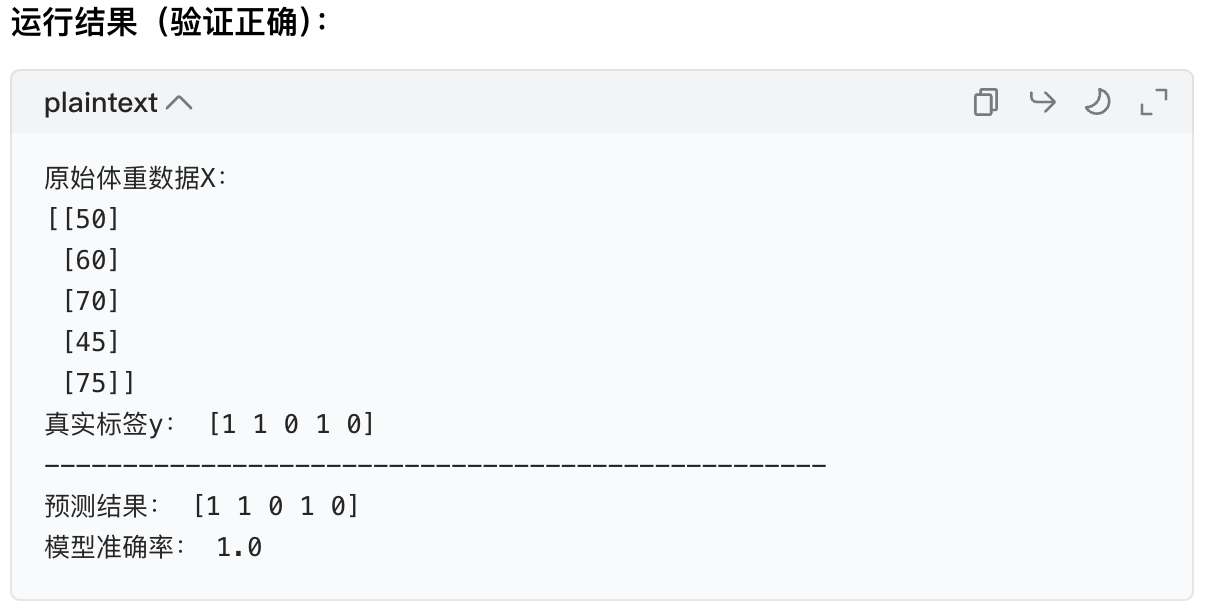
完美!自定义估计器和自带的LogisticRegression用法完全一致(fit/predict/score)。
步骤 2:把自定义估计器放进管道
结合之前的 "预处理步骤",构建完整管道:
- 体重(列 0):用自带的
StandardScaler标准化; - 身高(列 1):用自定义的
HeightLevelTransformer转等级; - 预测:用自定义的
SimpleWeightClassifier。
python
# 导入所有工具(包含自定义转化器和估计器)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
import numpy as np
# 1. 准备混合数据(X:体重+身高;y:是否喜欢运动)
X = np.array([[50, 1.6], [60, 1.7], [70, 1.8], [45, 1.55], [75, 1.85]])
y = np.array([1, 1, 0, 1, 0])
print("原始混合数据X(体重,身高):")
print(X)
print("-"*50)
# 2. 分栏预处理(自带转化器+自定义转化器)
preprocessor = ColumnTransformer(
transformers=[
("weight_scaler", StandardScaler(), [0]), # 体重(列0)标准化
("height_level", HeightLevelTransformer(), [1]) # 身高(列1)转等级
]
)
# 3. 构建管道(预处理+自定义估计器)
full_pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("custom_classifier", SimpleWeightClassifier(threshold=-0.5)) # 自定义估计器
])
# 4. 训练+预测+评估(和之前管道用法完全一样!)
full_pipeline.fit(X, y)
y_pred = full_pipeline.predict(X)
score = full_pipeline.score(X, y)
print("预测结果:", y_pred)
print("模型准确率:", score)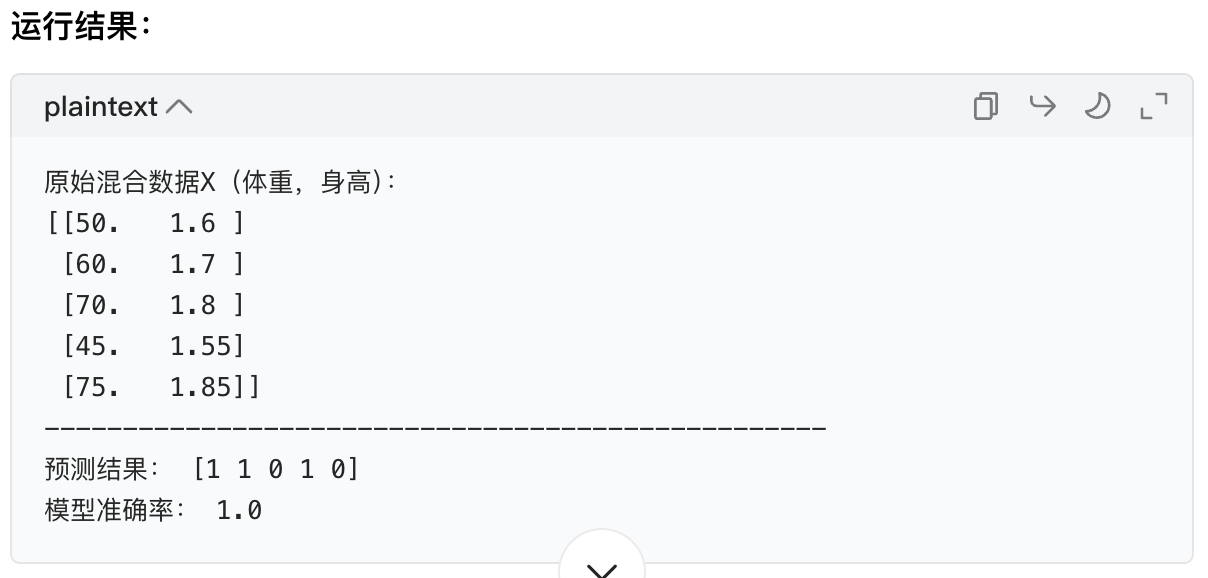
成功!自定义估计器也能无缝融入管道,和自带模型没有区别。
三、核心总结:自定义工具的 "万能模板"
1. 自定义转化器模板(直接抄)
python
from sklearn.base import BaseEstimator, TransformerMixin
class 自定义转化器名(BaseEstimator, TransformerMixin):
def __init__(self, 参数1=默认值, 参数2=默认值):
# 保存参数(实例变量)
self.参数1 = 参数1
self.参数2 = 参数2
def fit(self, X, y=None):
# 不需要学习规则就直接return self;需要学习就这里写逻辑(比如计算均值)
return self
def transform(self, X):
# 核心加工逻辑:把X转换成处理后的数据(必须返回二维数组)
X_processed = 你的处理逻辑(比如替换值、分类、计算新特征)
return X_processed2. 自定义估计器模板(直接抄)
分类模型(预测 0/1/2...)
python
from sklearn.base import BaseEstimator, ClassifierMixin
class 自定义分类器名(BaseEstimator, ClassifierMixin):
def __init__(self, 参数1=默认值, 参数2=默认值):
self.参数1 = 参数1
self.参数2 = 参数2
def fit(self, X, y):
# 学习预测规则(比如计算阈值、保存特征重要性)
self.学到的规则 = 你的训练逻辑(比如用X和y计算阈值)
return self
def predict(self, X):
# 预测逻辑:根据学到的规则输出预测结果(必须返回一维数组)
y_pred = 你的预测逻辑
return y_pred
def score(self, X, y):
# 可选:自定义评估逻辑(默认是准确率,也可以改召回率、F1等)
y_pred = self.predict(X)
return (y_pred == y).mean() # 准确率回归模型(预测连续值,比如房价)
python
from sklearn.base import BaseEstimator, RegressorMixin
class 自定义回归器名(BaseEstimator, RegressorMixin):
def __init__(self, 参数1=默认值):
self.参数1 = 参数1
def fit(self, X, y):
self.学到的规则 = 你的训练逻辑(比如计算回归系数)
return self
def predict(self, X):
y_pred = 你的预测逻辑(返回连续值)
return y_pred
def score(self, X, y):
# 回归模型默认用R²分数,自定义可以用MSE等
y_pred = self.predict(X)
return 1 - ((y - y_pred)**2).mean() / ((y - y.mean())**2).mean() # R²分数3. 关键注意事项(避免踩坑)
1.输入输出格式:
- 转化器的
fit/transform:输入 X 必须是 二维数组 (比如[[1.6], [1.8]],不能是[1.6, 1.8]); - 估计器的
predict:输出必须是 一维数组 (比如[1, 0, 1],不能是[[1], [0], [1]])。
2.必须返回 self :fit方法一定要return self,不然管道会报错。
3.基类不能错 :分类模型用ClassifierMixin,回归用RegressorMixin,转化器用TransformerMixin。
四、最终练习:修改自定义工具
试着修改下面的逻辑,巩固知识点:
- 给
HeightLevelTransformer加一个参数n_levels,支持划分 2 个等级(矮 / 高)或 3 个等级(矮 / 中 / 高); - 给
SimpleWeightClassifier改预测规则:结合身高等级和体重,比如 "身高等级 = 2 且体重> 65 → 不喜欢运动"。
按照模板改,改完放进管道测试,你会发现自定义工具其实很灵活!
作业:
整理下全部逻辑的先后顺序,看看能不能制作出适合所有机器学习的通用 pipeline
一、机器学习通用流程的逻辑先后顺序(不可逆,覆盖 90% 场景)
所有机器学习任务(分类 / 回归、结构化数据 / 混合数据)的核心逻辑顺序完全一致,步骤不能乱(乱了会导致数据泄露、模型无效),具体如下:
| 顺序 | 核心步骤 | 作用说明 | 关键工具 / 原则 |
|---|---|---|---|
| 1 | 明确任务目标 | 确定是「分类」(预测类别,如是否患病)还是「回归」(预测连续值,如房价) | 分类→选Classifier类估计器;回归→选Regressor类估计器 |
| 2 | 数据准备与拆分 | 加载数据→拆分「特征 X」和「标签 y」→拆分「训练集」和「测试集」 | train_test_split(必须先拆分再预处理,避免数据泄露) |
| 3 | 数据验证与清洗(可选) | 处理缺失值、异常值、重复值(数据质量决定模型上限) | 转化器(如SimpleImputer填充缺失值)、自定义转化器(处理特殊异常值) |
| 4 | 分栏特征预处理(核心) | 对不同类型特征(数值型 / 分类型 / 文本型)用不同转化器,统一格式 | ColumnTransformer(分栏)+ 转化器(数值→标准化 / 归一化;分类→独热编码) |
| 5 | 特征工程 (可选) | 提升模型效果(特征选择、降维、新特征构造) | 转化器(如PCA降维、SelectKBest特征选择)、自定义转化器(构造新特征) |
| 6 | 模型训练 | 用训练集的「处理后特征」训练模型 | 估计器(自带 / 自定义)、Pipeline(串联前面所有步骤) |
| 7 | 模型评估 | 用测试集评估效果(避免过拟合) | 分类→准确率 / 召回率;回归→R²/MSE;pipeline.score()(自动适配任务) |
| 8 | 预测与部署 (可选) | 用训练好的 Pipeline 预测新数据,保存模型供后续使用 | pipeline.predict()、joblib(保存模型) |
二、通用机器学习 Pipeline(适配所有任务,可直接复用)
基于上面的逻辑顺序,我们可以构建一个模块化、可扩展、兼容自定义工具的通用 Pipeline。它的核心是「模块可替换」------ 像搭积木一样,根据你的数据和任务替换对应的组件,无需重构整体逻辑。
1. 通用 Pipeline 的设计原则
- 兼容混合特征(数值型 + 分类型 + 其他类型);
- 支持分类 / 回归双任务;
- 可直接接入自定义转化器 / 估计器;
- 自动避免数据泄露;
- 代码简洁,零基础可修改。
2. 通用 Pipeline 完整代码模板(含注释)
python
# 第一步:导入所有通用工具(固定导入,不用改)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, TransformerMixin # 支持自定义工具
from sklearn.metrics import accuracy_score, r2_score # 评估指标
# ----------------------
# 第二步:定义可替换的「核心组件」(用户根据需求修改这里!)
# ----------------------
# 2.1 任务配置(必改:指定任务类型和列索引)
TASK_TYPE = "classification" # 可选:"classification"(分类) / "regression"(回归)
NUMERIC_COLS = [0, 1] # 数值型特征的列索引(如:身高、体重)
CATEGORICAL_COLS = [2] # 分类型特征的列索引(如:性别、学历)
LABEL_COL = "target" # 标签列名(根据你的数据修改)
# 2.2 数据清洗转化器(可选:处理缺失值/异常值,可自定义替换)
from sklearn.impute import SimpleImputer # 缺失值填充
from sklearn.preprocessing import StandardScaler, OneHotEncoder # 自带转化器
# 数值型特征处理:缺失值填充→标准化(可替换为归一化、自定义转化器)
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")), # 缺失值用均值填充
("scaler", StandardScaler()) # 标准化(替换为MinMaxScaler()就是归一化)
])
# 分类型特征处理:缺失值填充→独热编码(可替换为标签编码、自定义转化器)
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")), # 缺失值用众数填充
("encoder", OneHotEncoder(sparse_output=False, drop="first")) # 独热编码(避免多重共线性)
])
# 2.3 分栏预处理(固定逻辑:不同列用不同转化器,不用改)
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, NUMERIC_COLS),
("cat", categorical_transformer, CATEGORICAL_COLS)
],
remainder="drop" # 未指定的列直接丢弃(如需保留,改为"passthrough")
)
# 2.4 模型选择(必改:根据任务选模型,支持自定义估计器)
if TASK_TYPE == "classification":
from sklearn.linear_model import LogisticRegression # 分类模型(可替换)
model = LogisticRegression() # 替换为:DecisionTreeClassifier()、RandomForestClassifier()等
elif TASK_TYPE == "regression":
from sklearn.linear_model import LinearRegression # 回归模型(可替换)
model = LinearRegression() # 替换为:DecisionTreeRegressor()、RandomForestRegressor()等
# ----------------------
# 第三步:构建通用Pipeline(固定逻辑,不用改)
# ----------------------
general_pipeline = Pipeline(steps=[
("data_clean", preprocessor), # 第一步:数据清洗+分栏预处理
# (可选插入:特征工程步骤,如PCA降维)
# ("feature_engineering", PCA(n_components=2)),
("model", model) # 第二步:模型训练
])
# ----------------------
# 第四步:数据加载与拆分(用户根据自己的数据修改!)
# ----------------------
# 示例:加载数据(替换为你的数据加载逻辑,如pd.read_csv())
# 数据格式:X是特征矩阵(二维数组),y是标签(一维数组)
def load_data():
# 模拟混合特征数据(替换为你的真实数据)
data = pd.DataFrame({
"height": [1.6, 1.8, 1.7, 1.55, None], # 数值型(含缺失值)
"weight": [50, 70, None, 45, 75], # 数值型(含缺失值)
"gender": [1, 0, 1, None, 0], # 分类型(含缺失值)
"target": [1, 0, 1, 1, 0] # 标签(分类:1=喜欢运动,0=不喜欢)
})
X = data.drop(LABEL_COL, axis=1).values # 特征X(二维数组)
y = data[LABEL_COL].values # 标签y(一维数组)
return X, y
# 加载数据→拆分训练集(80%)和测试集(20%)(固定逻辑,不用改)
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42 # test_size:测试集比例;random_state:随机种子(保证结果可复现)
)
# ----------------------
# 第五步:训练+评估+预测(固定逻辑,不用改)
# ----------------------
# 1. 训练模型(自动处理:训练集fit→transform;测试集只transform,避免数据泄露)
general_pipeline.fit(X_train, y_train)
# 2. 预测(训练集+测试集)
y_train_pred = general_pipeline.predict(X_train)
y_test_pred = general_pipeline.predict(X_test)
# 3. 评估(根据任务自动选择指标)
if TASK_TYPE == "classification":
train_score = accuracy_score(y_train, y_train_pred) # 分类用准确率
test_score = accuracy_score(y_test, y_test_pred)
metric_name = "准确率"
elif TASK_TYPE == "regression":
train_score = r2_score(y_train, y_train_pred) # 回归用R²分数
test_score = r2_score(y_test, y_test_pred)
metric_name = "R²分数"
# 打印结果
print(f"训练集{metric_name}:{train_score:.2f}")
print(f"测试集{metric_name}:{test_score:.2f}")
# 4. 预测新数据(直接用训练好的Pipeline)
new_data = np.array([[1.75, 65, 1]]) # 新数据(数值型+分类型特征)
new_pred = general_pipeline.predict(new_data)
print(f"新数据预测结果:{new_pred[0]}")三、通用 Pipeline 的「灵活调整方法」(适配所有场景)
这个 Pipeline 的核心是「模块化替换」,你不需要改整体逻辑,只需要根据自己的需求修改「第二步:定义可替换的核心组件」和「第四步:数据加载与拆分」,具体调整场景如下:
1. 场景 1:替换预处理方法(如数值型不用标准化,用归一化)
python
# 把数值型转化器的StandardScaler()替换为MinMaxScaler()
from sklearn.preprocessing import MinMaxScaler
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")),
("scaler", MinMaxScaler()) # 归一化(替换后直接运行,其他逻辑不变)
])2. 场景 2:接入自定义转化器(如之前的身高等级转化器)
python
# 1. 先定义自定义转化器(之前写的HeightLevelTransformer)
class HeightLevelTransformer(BaseEstimator, TransformerMixin):
def __init__(self, low_threshold=1.65, high_threshold=1.75):
self.low_threshold = low_threshold
self.high_threshold = high_threshold
def fit(self, X, y=None):
return self
def transform(self, X):
X_df = pd.DataFrame(X, columns=["height"])
def get_level(h):
return 0 if h < self.low_threshold else 2 if h > self.high_threshold else 1
return X_df["height"].apply(get_level).values.reshape(-1, 1)
# 2. 替换数值型转化器中的scaler为自定义转化器
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")),
("custom_transformer", HeightLevelTransformer()) # 接入自定义转化器
])3. 场景 3:替换模型(如分类任务用随机森林)
python
# 分类任务替换模型(其他逻辑不变)
if TASK_TYPE == "classification":
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, random_state=42) # 随机森林4. 场景 4:适配回归任务(如预测房价)
python
# 1. 修改任务配置
TASK_TYPE = "regression"
NUMERIC_COLS = [0, 1] # 如:面积、房龄(数值型)
CATEGORICAL_COLS = [2] # 如:户型(分类型)
LABEL_COL = "price" # 标签:房价(连续值)
# 2. 加载回归数据(替换为你的房价数据)
def load_data():
data = pd.DataFrame({
"area": [80, 100, None, 90, 120], # 面积(数值型)
"age": [5, 3, 10, None, 2], # 房龄(数值型)
"type": [1, 2, 1, 2, None], # 户型(分类型)
"price": [150, 200, 120, 180, 250] # 房价(回归标签)
})
X = data.drop(LABEL_COL, axis=1).values
y = data[LABEL_COL].values
return X, y
# 3. 直接运行原代码,自动用回归模型和R²指标评估四、通用 Pipeline 的核心优势(为什么能适配所有任务?)
- 模块化设计:每个步骤(数据清洗、预处理、模型)都是独立模块,替换其中一个不影响其他;
- 避免数据泄露 :训练集只做
fit+transform,测试集只做transform,Pipeline 自动处理,无需手动干预; - 兼容自定义工具:只要自定义转化器 / 估计器遵守 sklearn 基类规则,就能直接接入;
- 支持混合特征:ColumnTransformer 自动分栏处理数值型、分类型特征,覆盖 90% 结构化数据场景;
- 兼顾分类 / 回归 :通过
TASK_TYPE参数切换,自动适配评估指标和模型类型。
五、注意事项(避免踩坑)
- 列索引不能错 :
NUMERIC_COLS和CATEGORICAL_COLS必须对应你数据的真实列索引(或列名,如用 DataFrame 可直接写列名); - 输入格式要对 :X 必须是二维数组(如
[[1.6, 50, 1]]),y 必须是一维数组(如[1, 0, 1]); - 特殊数据扩展 :如果是文本数据,可新增
text_transformer(如TfidfVectorizer),在ColumnTransformer中添加("text", text_transformer, TEXT_COLS);如果是图像数据,可新增图像预处理转化器(如归一化、Resize); - 超参数调优 :通用 Pipeline 可结合
GridSearchCV调参,例如:
python
from sklearn.model_selection import GridSearchCV
param_grid = {"model__n_estimators": [50, 100, 200]} # 调模型的超参数
grid_search = GridSearchCV(general_pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("最优参数:", grid_search.best_params_)总结
这个通用 Pipeline 的本质是「固定机器学习的核心逻辑顺序,让用户只关注数据和组件选择」。无论你是做分类(如垃圾邮件识别)、回归(如销量预测),还是处理纯数值、混合特征,甚至用自定义工具,都可以基于这个模板快速搭建流程 ------ 无需重复写预处理、拆分数据、避免泄露的代码,专注于优化模型和特征即可。
如何在通用 Pipeline 中实现特征工程?
在通用 Pipeline 中实现特征工程,核心逻辑是 "将特征工程步骤作为独立模块,嵌入到「预处理之后、模型之前」" ------ 既不破坏原有通用流程,又能让特征工程和数据预处理、模型训练无缝衔接。
对于零基础学习者,我们聚焦 3 类最常用、最实用的特征工程(覆盖 90% 场景),用 "代码模板 + 分步嵌入" 的方式讲解,全程基于之前的通用 Pipeline 改造,不用重构整体逻辑。
一、先明确:特征工程在通用 Pipeline 中的位置(关键!)
通用 Pipeline 的核心顺序是:数据加载与拆分 → 预处理(分栏清洗) → 【特征工程】 → 模型训练 → 评估预测
特征工程必须放在 "预处理之后" (因为特征工程需要基于 "干净、标准化" 的数据),"模型之前"(因为模型需要用处理后的优质特征训练)。
嵌入方式超简单:在通用 Pipeline 的 steps 中,新增 "特征工程步骤" 即可,格式和其他模块一致(("步骤名", 特征工程工具))。
二、3 类常用特征工程:嵌入通用 Pipeline 实操
我们基于之前的通用 Pipeline 模板,分别加入「特征选择、特征降维、特征构造」,每类都给完整可运行代码,直接替换就能用。
前置准备:复用通用 Pipeline 的基础组件
先回顾之前的通用 Pipeline 核心模块(后续只新增 / 修改特征工程部分):
python
# 固定导入工具(含特征工程所需工具)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 1. 任务配置(分类任务为例)
TASK_TYPE = "classification"
NUMERIC_COLS = [0, 1] # 身高、体重(数值型)
CATEGORICAL_COLS = [2] # 性别(分类型)
LABEL_COL = "target"
# 2. 预处理模块(分栏清洗,不变)
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")),
("scaler", StandardScaler())
])
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OneHotEncoder(sparse_output=False, drop="first"))
])
preprocessor = ColumnTransformer(
transformers=[("num", numeric_transformer, NUMERIC_COLS),
("cat", categorical_transformer, CATEGORICAL_COLS)]
)
# 3. 模型(不变)
model = LogisticRegression()1. 特征工程 1:特征选择(挑 "有用" 的特征,剔除冗余)
作用:
去掉对模型没用的特征(比如噪音特征、重复特征),减少计算量,避免过拟合。
常用工具:
SelectKBest(选择得分最高的 K 个特征)、SelectFromModel(基于模型权重选择特征)。
嵌入步骤:
在 Pipeline 中加入 "特征选择" 模块,放在「预处理」和「模型」之间。
完整代码(新增特征选择部分):
python
# 新增:导入特征选择工具
from sklearn.feature_selection import SelectKBest, f_classif # f_classif:分类任务的特征评分方法
# 构建通用 Pipeline(新增特征选择步骤)
general_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 第一步:预处理(不变)
# 新增:第二步:特征选择(选择得分最高的3个特征)
("feature_selection", SelectKBest(score_func=f_classif, k=3)), # k=3:选3个最好的特征
("model", model) # 第三步:模型(不变)
])
# 后续数据加载、拆分、训练评估(和之前完全一样,直接复用)
def load_data():
data = pd.DataFrame({
"height": [1.6, 1.8, 1.7, 1.55, None, 1.75, 1.68],
"weight": [50, 70, None, 45, 75, 65, 58],
"gender": [1, 0, 1, None, 0, 1, 0],
"target": [1, 0, 1, 1, 0, 1, 0]
})
X = data.drop(LABEL_COL, axis=1).values
y = data[LABEL_COL].values
return X, y
# 训练+评估
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
general_pipeline.fit(X_train, y_train)
y_test_pred = general_pipeline.predict(X_test)
print("测试集准确率:", accuracy_score(y_test, y_test_pred))关键说明:
score_func=f_classif:适合分类任务;如果是回归任务,替换为f_regression;k=3:可根据特征总数调整(比如特征有 5 个,选 k=4);如果想选 "所有得分高于阈值的特征",可设k="all"配合后续筛选。
2. 特征工程 2:特征降维(压缩特征维度,避免过拟合)
作用:
当特征太多(比如几十、上百个)时,将高维特征压缩到低维(比如 2 维、3 维),保留核心信息,减少计算量。
常用工具:
PCA(主成分分析,最常用)、TSNE(适合可视化,计算量大)。
嵌入步骤:
和特征选择一样,放在「预处理」和「模型」之间,可单独使用,也可和特征选择搭配。
完整代码(新增特征降维部分):
python
# 新增:导入降维工具
from sklearn.decomposition import PCA
# 构建通用 Pipeline(新增PCA降维步骤)
general_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 第一步:预处理(不变)
# 新增:第二步:特征降维(压缩到2维)
("feature_reduction", PCA(n_components=2)), # n_components=2:压缩为2个特征
("model", model) # 第三步:模型(不变)
])
# 后续数据加载、训练评估(和之前完全一样,直接复用)
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
general_pipeline.fit(X_train, y_train)
y_test_pred = general_pipeline.predict(X_test)
print("测试集准确率:", accuracy_score(y_test, y_test_pred))
# 可选:查看降维后的特征形状(验证是否压缩到2维)
X_train_processed = general_pipeline.named_steps["feature_reduction"].transform(
general_pipeline.named_steps["preprocessor"].transform(X_train)
)
print("降维后训练集特征形状:", X_train_processed.shape) # 输出 (5, 2):5个样本,2个特征关键说明:
n_components:可设为整数(比如 2、3,指定降维后的维度),或小数(比如 0.95,保留 95% 的信息);- 适用场景:特征维度高(比如 > 20 个)、模型过拟合时使用;如果特征少(<10 个),一般不需要降维。
3. 特征工程 3:特征构造(创造新的 "优质特征")
作用:
基于原有特征,构造更有预测力的新特征(比如用 "身高、体重" 算 "BMI 指数",用 "日期" 算 "星期几"),是提升模型效果的核心手段。
实现方式:
用 自定义转化器(之前学过的技能!),因为构造逻辑往往是自定义的(比如业务相关规则)。
嵌入步骤:
有两种方式(根据需求选):
- 方式 1:在「分栏预处理内部」构造(针对单类特征,比如数值型特征内部组合);
- 方式 2:在「预处理之后、模型之前」构造(针对跨类型特征,比如数值型 + 分类型组合)。
实操:方式 1(分栏预处理内部构造,推荐)
比如对数值型特征(身高、体重),构造新特征 "BMI 指数"(BMI = 体重 (kg)/ 身高 (m)²)。
python
# 第一步:写自定义特征构造转化器
class FeatureConstructor(BaseEstimator, TransformerMixin):
def __init__(self):
pass # 无参数,可根据需求加(比如BMI阈值)
def fit(self, X, y=None):
return self # 不需要学习规则,直接返回
def transform(self, X):
# X:预处理后的数值型特征(身高、体重,二维数组)
height = X[:, 0] # 第一列:身高
weight = X[:, 1] # 第二列:体重
# 构造新特征:BMI指数(体重/身高²)
bmi = weight / (height ** 2)
# 合并原有特征和新特征(返回二维数组)
X_new = np.hstack([X, bmi.reshape(-1, 1)]) # hstack:横向拼接
return X_new
# 第二步:修改数值型预处理模块,加入特征构造
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")), # 1. 缺失值填充
("scaler", StandardScaler()), # 2. 标准化
("feature_construct", FeatureConstructor()) # 3. 新增:构造BMI特征
])
# 第三步:构建Pipeline(后续逻辑不变)
general_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 预处理(已包含特征构造)
("model", model)
])
# 训练评估(复用之前代码)
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
general_pipeline.fit(X_train, y_train)
print("测试集准确率:", accuracy_score(y_test, general_pipeline.predict(X_test)))实操:方式 2(跨类型特征构造)
比如用 "性别(分类型)+ 体重(数值型)" 构造新特征 "性别权重"(男性 ×1.2,女性 ×0.8)。
python
# 第一步:写跨类型特征构造转化器(输入是预处理后的所有特征)
class CrossFeatureConstructor(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# X:预处理后的所有特征(假设:第0列=标准化身高,第1列=标准化体重,第2列=性别独热编码)
weight = X[:, 1] # 标准化后的体重
gender = X[:, 2] # 性别(0=男,1=女,独热编码后)
# 构造跨类型特征:性别权重(男:weight×1.2,女:weight×0.8)
gender_weight = np.where(gender == 0, weight * 1.2, weight * 0.8)
# 合并原有特征和新特征
X_new = np.hstack([X, gender_weight.reshape(-1, 1)])
return X_new
# 第二步:在Pipeline中加入跨类型特征构造(预处理之后)
general_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 1. 预处理(分栏清洗)
("cross_feature_construct", CrossFeatureConstructor()), # 2. 跨类型特征构造
("model", model) # 3. 模型
])
# 训练评估(复用之前代码)
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
general_pipeline.fit(X_train, y_train)
print("测试集准确率:", accuracy_score(y_test, general_pipeline.predict(X_test)))关键说明:
- 特征构造的核心是 "结合业务逻辑"(比如 BMI 指数对健康相关任务有用),自定义转化器可以灵活实现任何规则;
- 构造后的新特征会和原有特征合并,模型会自动学习新特征的重要性。
三、特征工程的组合使用(实战推荐)
实际项目中,常将 "特征构造 + 特征选择 + 特征降维" 组合使用,顺序一般是:预处理 → 特征构造 → 特征选择 → 特征降维 → 模型
组合版完整 Pipeline 代码:
python
# 导入所有需要的工具
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.decomposition import PCA
# 构建组合特征工程的Pipeline
general_pipeline = Pipeline(steps=[
("preprocessor", preprocessor), # 1. 预处理(含单类型特征构造)
("cross_feature", CrossFeatureConstructor()), # 2. 跨类型特征构造
("feature_selection", SelectKBest(score_func=f_classif, k=4)), # 3. 选择4个最优特征
("feature_reduction", PCA(n_components=2)), # 4. 降维到2维
("model", model) # 5. 模型
])
# 训练评估
X, y = load_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
general_pipeline.fit(X_train, y_train)
print("测试集准确率:", accuracy_score(y_test, general_pipeline.predict(X_test)))四、关键注意事项(避免踩坑)
1. 顺序不能乱:特征构造→特征选择→特征降维(先创造新特征,再挑有用的,最后压缩维度);
2. 不盲目使用:
- 特征少(<10 个):不用降维,可只做特征构造;
- 特征噪音多:优先用特征选择;
- 特征维度极高(>100 个):再用降维;
3. 避免数据泄露 :特征工程的 fit 只能用训练集!Pipeline 会自动处理(训练集 fit+transform,测试集只 transform),不用手动干预;
4. 评估效果:加入特征工程后,要对比 "有无特征工程" 的模型分数(比如准确率、R²),如果分数下降,说明特征工程没做好(比如选了无用特征、降维丢了关键信息)。
五、总结:通用 Pipeline 中特征工程的核心逻辑
特征工程在通用 Pipeline 中是 "可插拔的模块化组件",核心步骤:
- 选工具:根据需求选特征构造(自定义转化器)、特征选择(SelectKBest)、特征降维(PCA);
- 嵌位置:放在「预处理之后、模型之前」;
- 可组合:按 "构造→选择→降维" 顺序组合,适配复杂场景;
- 易修改:不需要改其他模块,只新增 / 替换特征工程步骤,完全兼容之前的通用 Pipeline。
通过这种方式,你可以在不破坏原有流程的前提下,灵活加入特征工程,让模型用更优质的特征训练,从而提升预测效果。如果需要针对具体任务(比如回归、文本数据)调整特征工程工具,只需替换对应的组件(比如回归用 f_regression 替代 f_classif),整体逻辑不变!