简述
最近发现了个宝藏项目,把Agents推理能力向上拔高了一个台阶
https://github.com/aiwaves-cn/agents![]() https://github.com/aiwaves-cn/agents架流程图
https://github.com/aiwaves-cn/agents架流程图
简介里说明这个项目的作用
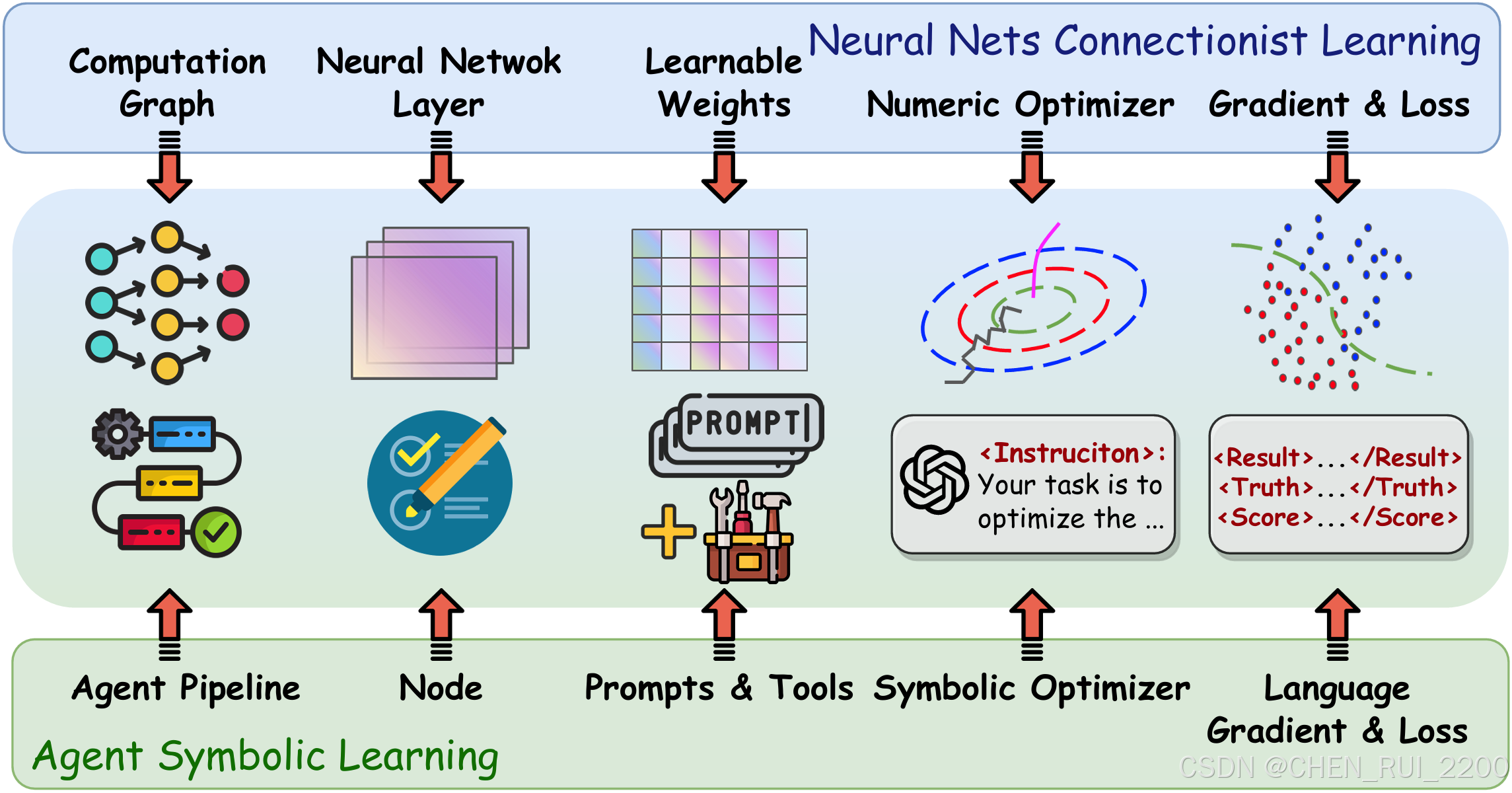
"智能体符号学习是一个用于训练语言智能体的系统框架,其灵感来源于用于训练神经网络的连接主义学习过程。我们将语言智能体与神经网络进行类比:智能体的流水线对应于神经网络的计算图,流水线中的一个节点对应于神经网络中的一个层,而节点的提示和工具则对应于该层的权重。这样,我们就能够在智能体训练的背景下,利用基于语言的损失、梯度和权重,实现连接主义学习的主要组成部分,即反向传播和基于梯度的权重更新。
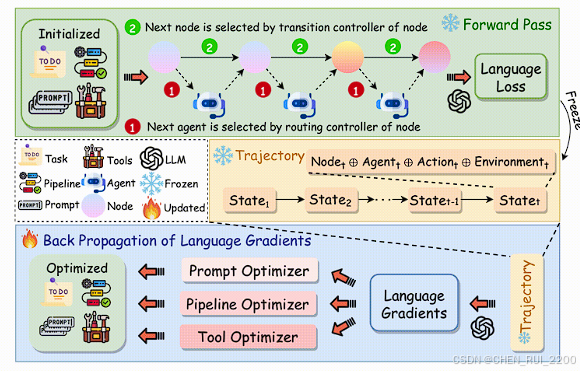
利用精心设计的提示流水线,在智能体训练的背景下实现了损失函数、反向传播和权重优化器。对于一个训练示例,我们的框架首先执行"前向传播"(智能体执行),并将每个节点的输入、输出、提示和工具使用情况存储在一个"轨迹"中。然后,我们使用基于提示的损失函数来评估结果,从而得到"语言损失"。随后,我们沿着轨迹从最后一个节点反向传播语言损失到第一个节点,从而对每个节点内的符号组件进行文本分析和反思,我们称之为语言梯度。最后,我们根据语言梯度,并借助另一个精心设计的提示,更新每个节点中的所有符号组件以及由节点及其连接构成的计算图。我们的方法也自然地支持优化多智能体系统,可以将节点视为不同的智能体,或者允许多个智能体在一个节点中执行操作。"
分析
框架作用
Agents2.0 它可不是普通的 Agent 框架,而是一个能自我进化、会"反向传播"的语言智能体系统!用一句话概括它的"人设"就是:
"我不仅会推理,还会学习------像神经网络那样训练自己!"
项目定位:Agents 2.0 = LLM Agent + Symbolic Learning
Agents 最初(v1)是个"静态执行者",靠 prompt 和工具调用完成任务;
Agents 2.0(2024年6月重磅升级)则让它变成了一个"会成长的智能体学生" ------具备 Symbolic Learning(符号学习) 能力!它把 语言智能体的 pipeline(执行流程) 类比为 神经网络的计算图:
| 神经网络 | ↔ | 语言智能体(Agents 2.0) |
|---|---|---|
| Layer(层) | ↔ | Node(Agent 节点 / Agent 本身) |
| Weights(权重) | ↔ | Prompts + Tools + Logic(可学习的"符号组件") |
| Forward Pass(前向传播) | ↔ | Agent 执行任务的完整轨迹(Trajectory) |
| Loss(损失函数) | ↔ | Language Loss:用 LLM 打分的"语言化损失" |
| Backprop(反向传播) | ↔ | Language Gradient:用自然语言写的"反思建议" |
| Optimizer(优化器) | ↔ | Prompt-based Update:用大模型"重写"prompt/tool逻辑 |
是瞬间有种"大模型版 PyTorch"的既视感
核心技术亮点(逐个击破)Trajectory Recording(轨迹捕获)
当一个智能体处理一个任务时,系统会像"黑匣子飞行记录仪"一样,完整记录:
- 每个节点的输入/输出
- 使用的 prompt 模板
- 调用的 工具及参数
- 中间思考过程(如 Chain-of-Thought)
- 作用:为后续"反向传播"提供"证据链",是学习的基础!
Language Loss(语言化损失函数)
传统 loss 是数字(如 MSE),这里 loss 是一段自然语言 比如:
"最终答案错误:混淆了'出生地'和'居住地';步骤3缺乏权威来源验证。"
📌 实现方式:
用一个"评估智能体"(Evaluator Agent)分析最终输出 vs 真实答案,用 prompt 引导其生成结构化反馈 → 这就是 loss!
Language Backpropagation(语言反向传播)
最惊艳的部分来了!
系统从输出节点倒推回输入节点 ,对每个节点生成 Language Gradient(语言梯度) ------即:
"如果你在第2步这样修改 prompt,结果会更好..."
举个栗子:
- 节点3(答案生成)失败 → 归因到节点2(信息抽取)漏掉了关键实体
- 于是给节点2的提示词加一句:"请特别关注人物生平中的地点信息,并标注来源段落"
- 这个"修改建议"本身就是 Language Gradient!
类比:就像老师批改作文,在每个段落旁写"此处论证不足,建议补充数据"。
Prompt-based Weight Update(基于提示的参数更新)
有了语言梯度,怎么"更新权重"?
→ 用一个 Optimizer Prompt,让 LLM 自动重写:
- 节点 prompt 模板
- 工具调用策略
- 甚至节点间的连接逻辑(增删节点、调整顺序)
例如输入:
"你的 prompt 在处理模糊日期时表现不佳。请重写以下 prompt,使其更强调日期格式标准化和歧义澄清。"
LLM 输出新 prompt,直接替换旧的------**自动迭代进化!**支持两种学习模式:
- 单智能体学习:优化一个 pipeline 内的多个节点
- 多智能体协同学习:把每个 node 当作独立 agent,联合优化分工与协作
为什么说它"颠覆范式"?
| 传统 Agent 开发 | Agents 2.0 |
|---|---|
| Prompt 工程靠人工试错 | ✅ 自动优化、数据驱动 |
| 失败=重启调试 | ✅ 失败=学习信号! |
| 多 Agent 协作靠硬编码流程 | ✅ 自动发现协作模式(如"先查再验再总结") |
| 模型能力天花板=初始 prompt 质量 | ✅ 能力随训练数据持续进化 |
它真正实现了:让智能体像人一样------从错误中学习。下一步构思
- 轻量级自归因 Agent → 这项目提供完整归因+学习闭环!
- 多 Agent 协同 → 支持 node = agent 的灵活架构
- 本地部署 + FastAPI 集成 → 可把训练好的 Agent Pipeline 封装为 REST 服务
业务融合
配置信息
训练入口
from agents import TriageDataset
import litellm
from agents.optimization.trainer import Trainer, TrainerConfig
from user_specific_provider import TenantCandidatesProvider
litellm.set_verbose = False
if __name__ == "__main__":
# Prepare data
dataset = TriageDataset()
# Trainer training
trainer_config_path = "configs/trainer_config.json"
# Option 1: Use tenant candidates provider (full candidate sets)
candidates_provider = TenantCandidatesProvider()
trainer = Trainer(
config=TrainerConfig(trainer_config_path),
dataset=dataset,
candidates_provider=candidates_provider
)
trainer.train()trainer_config.json 配置信息
{
"batch_size": 10,
"max_step": 100,
"log_path": "logs",
"sample_kind": "random",
"allow_duplicate_samples": false,
"has_ground_truth": true,
"has_eval_score": true,
"early_stop_threshold": 0.9,
"max_exceed_threshold_count": 3,
"max_score_decline_count": 5,
"use_early_stop_threshold": true,
"use_early_stop_score_decline": true,
"use_roll_back": true,
"parallel": true,
"parallel_max_num": 8,
"initial_solution_path": "solution.json",
"optimizer_config_path": "optimizer_config.json",
"optim_order": "order",
"optimizers": [
"prompt"
],
"additional_info": {
"loss": "Focus on reflection from labeled examples to improve triage accuracy",
"sop": "Emphasize reflective reasoning in classification predictions",
"node": "Ensure each node contributes to improved accuracy through example-based learning",
"prompt": "Prompts should guide models to reflect on labeled examples for better predictions"
},
"wandb_config": {
"project": "Agent2",
"name": "triage_reflective_learning",
"mode": "online"
}
}重要概念
"loss": "注重对已标注示例的反思,以提高分类准确率",
"sop": "强调在分类预测中进行反思性推理",
"node": "确保每个节点都能通过基于示例的学习来提高准确率",
"prompt": "提示应引导模型反思已标注示例,以获得更好的预测结果"
Agents 的配置
角色定义
triage_agent_team.json 配置
{
"agents": {
"Alice": {
"agent_name": "Analyzer_Alice",
"agent_roles": {
"Receive_Ticket": "Ticket_Analyzer"
},
"agent_style": null,
"agent_description": null,
"LLM_config": {
"LLM_type": "Azure",
"model": "gpt-4.1-int",
"temperature": 0,
"log_path": "logs/Alice",
"API_KEY": "",
"API_BASE": "",
"MAX_CHAT_MESSAGES": 10,
"ACTIVE_MODE": false,
"SAVE_LOGS": true
},
"toolkit": null,
"memory": null,
"is_user": false
},
"Bob": {
"agent_name": "Predictor_Bob",
"agent_roles": {
"Predict_Classifications": "Classification_Predictor"
},
"agent_style": null,
"agent_description": null,
"LLM_config": {
"LLM_type": "Azure",
"model": "gpt-4.1-int",
"temperature": 0,
"log_path": "logs/Bob",
"API_KEY": "",
"API_BASE": "",
"MAX_CHAT_MESSAGES": 10,
"ACTIVE_MODE": false,
"SAVE_LOGS": true
},
"toolkit": null,
"memory": null,
"is_user": false
},
"Charlie": {
"agent_name": "Formatter_Charlie",
"agent_roles": {
"Finalize_Predictions": "Result_Formatter"
},
"agent_style": null,
"agent_description": null,
"LLM_config": {
"LLM_type": "Azure",
"model": "gpt-4.1-int",
"temperature": 0,
"log_path": "logs/Charlie",
"API_KEY": "",
"API_BASE": "",
"MAX_CHAT_MESSAGES": 10,
"ACTIVE_MODE": false,
"SAVE_LOGS": true
},
"toolkit": null,
"memory": null,
"is_user": false
}
},
"environment": {
"environment_type": "cooperative",
"shared_memory": null,
"shared_toolkit": null
}
}基于对配置文件来解释 Analyzer_Alice、Predictor_Bob 和 Formatter_Charlie 这三个角色的工作职责及合作方式:
各角色的工作职责
1. Analyzer_Alice (Ticket_Analyzer)
Analyzer_Alice 是流程的第一个角色,主要负责:
-
接收并分析工单内容,理解其上下文和需求
-
提取工单中的关键信息,包括:
-
工单描述的主要问题或请求
-
相关的技术细节和上下文
-
紧急指标或业务影响
-
客户公司和联系人信息
-
清晰地总结发现的信息
2. Predictor_Bob (Classification_Predictor)
Predictor_Bob 是第二个角色,主要负责:
-
基于工单分析结果预测正确的分类
-
使用反射推理(reflective reasoning)方法,基于标记的示例进行分类预测
-
预测六个维度的分类:
-
board(板块)
-
priority(优先级)
-
type(类型)
-
sub_type(子类型)
-
item(项目)
-
work_type(工作类型)
此外,Predictor_Bob 还必须遵循严格的依赖规则,比如特定的板块只能对应特定的类型,类型又决定了可用的子类型等。
3. Formatter_Charlie (Result_Formatter)
Formatter_Charlie 是最后一个角色,主要负责:
-
格式化和最终确定分类预测结果
-
将结果整理成标准的 JSON 格式输出
-
验证输出是否满足所有依赖关系
-
确保所有的值都在候选列表范围内
-
确保分类在工单上下文中是有意义的
角色间的合作方式
这三个角色按照顺序协作完成工单分类任务:
- **顺序执行流程**:
-
首先由 Analyzer_Alice 分析工单内容
-
然后 Predictor_Bob 基于分析结果进行分类预测
-
最后 Formatter_Charlie 格式化输出最终结果
- **信息传递机制**:
-
每个角色的输出会作为下一个角色的输入
-
通过共享内存机制在整个流程中传递信息
- **流程控制**:
-
系统使用控制器来决定何时从一个节点转移到下一个节点
-
只有当前节点的任务完成后才会转移到下一节点
这种分工明确的设计使得每个角色可以专注于自己的专业领域,从而提高整体系统的准确性和效率。Analyzer_Alice 专注于理解问题,Predictor_Bob 专注于分类预测,Formatter_Charlie 则专注于结果验证和格式化。这样的架构也有利于系统的维护和扩展,如果需要改进某个环节,可以单独优化相应的角色而不影响其他部分。
优化器
optimizer_config.json
{
"task_setting": {
"has_ground_truth": true,
"has_result": true,
"sample_kind": "order"
},
"log_path": "examples/triage/logs",
"loss": {
"llm_config": {
"LLM_type": "Azure",
"API_KEY": "",
"API_BASE": "",
"temperature": 0.3,
"model": "gpt-4.1-int",
"SAVE_LOGS": false,
"log_path": "logs/trainer_god"
},
"meta_prompt": {
"loss": {
"order": [],
"extract_key": [
"requirement_for_previous"
],
"part1_with_gt_and_score": "You are a large language model fine-tuner specialized in triage classification tasks. I will provide you with a model's output and the expected correct result. \nYou need to evaluate it and suggest modifications to the model's output by reflecting on labeled examples. Please use `<requirement_for_previous></requirement_for_previous>` to enclose your feedback.\n\n",
"part1_no_gt_with_score": "You are a large language model fine-tuner specialized in triage classification tasks. I will provide you with a model's output and the evaluation score. \nYou need to evaluate it and suggest modifications to the model's output by reflecting on labeled examples. Please use `<requirement_for_previous></requirement_for_previous>` to enclose your feedback.\n",
"part1_with_gt_no_score": "You are a fine-tuner of a large model specialized in triage classification tasks. I will provide you with some output results from the model and the expected correct results. \nYou need to evaluate these data and provide a score out of 10 by reflecting on labeled examples, please wrap the score using <score></score>. Additionally, please provide some suggestions for modifying the model's output, using <requirement_for_previous></requirement_for_previous> to wrap your suggestions.\n",
"part1_no_gt_no_score": "You are a fine-tuner of a large model specialized in triage classification tasks. I will provide you with some output results from the model and the task description it is trying to solve.\nYou need to evaluate these data and provide a score out of 10 by reflecting on labeled examples, please wrap the score using <score></score>. Additionally, please provide some suggestions for modifying the model's output, using <requirement_for_previous></requirement_for_previous> to wrap your suggestions.\n",
"task_description": "The description of this task is as follows:\n<task_description>{task_description}</task_description>\n\n",
"model_output": "Below is the model's output:\n<result>{result}</result>\n\n",
"ground_truth": "The expected result is:\n<ground_truth>{ground_truth}</ground_truth>\n\n",
"score": "Here is the evaluation score for the model. Your goal is to optimize this score by reflecting on labeled examples:\n<score>{score}</score>\n\nThe relevant information about this score is as follows:\n<evaluation_info>{score_info}</evaluation_info>\n\n",
"note_output_score": "Please note:\n1. Ensure that the output is wrapped with <score></score> and <requirement_for_previous></requirement_for_previous> respectively.\n2. The output should be as consistent as possible with the expected result while being correct. For example, if the expected result is "BUST", and the model's output is "The women's lifestyle magazine is 'BUST' magazine.", even though the answer is correct, you should advise the model to be more concise.\n3. The standard for a score of 10 is that the model's output is exactly the same as the expected result in a case-insensitive manner, and without any unnecessary content. Even if the model's output is semantically correct, if it includes superfluous content, points should be deducted.",
"note_not_output_score": "Please Note:\n1. Ensure that `<requirement_for_previous></requirement_for_previous>` exists and appears once.\n2. If the model's output is satisfactory, you can output <requirement_for_previous>The output is satisfactory, no additional requirements</requirement_for_previous>.\n3. The output should be as close to the expected result as possible while ensuring correctness. For example, if the expected result is \"BUST\" and the model's output is \"The women's lifestyle magazine is 'BUST' magazine.\", even though this answer is correct, you should remind the model to be concise."
}
}
},
"prompt_optimizer": {
"allow_delete_template_variable": false,
"needed_optim_component": [
"TASK",
"RULE",
"STYLE",
"EXAMPLE",
"COT"
],
"needed_optim_padding": true,
"llm_config": {
"LLM_type": "Azure",
"API_KEY": "",
"API_BASE": "",
"temperature": 0.3,
"model": "gpt-4.1-int",
"SAVE_LOGS": false,
"log_path": "logs/trainer_god"
},
"meta_prompt": {
"backward": {
"order": [
"prom_backward"
],
"extract_key": [
"suggestion",
"requirement_for_previous"
],
"prom_backward": "You are now a prompt optimization specialist for a large language model performing triage classification tasks. You need to provide optimization suggestions for the prompt templates by reflecting on labeled examples. Please use `<suggestion></suggestion>` to wrap your suggestions, for example, `<suggestion>can be shorter</suggestion>`.\n\nThe entire task is completed in multiple steps. I will provide you with the output of the previous step, the requirements for the current step, the output of the current step, and the prompt_components. You need to propose improvements for the prompt_components of the current step by reflecting on labeled examples. The actual prompt used is assembled from prompt_components.\n\n- The current prompt_components are: <prompt_components>{prompt_components}</prompt_components>\n\n- The prompt can be composed by concatenating the prompt_components in the following order: <order>{prompts_order}</order>\n\n- The output of the previous step is: <previous_output>{previous_output}</previous_output>\n\n- The output of the current step is: <output>{response}</output>\n\n- The requirement for the current step's output is: <requirement>{requirement_for_previous}</requirement>\n\n- The field of the prompt template that needs to be optimized is: {needed_optim_component}\n\nYou need to optimize the specified field in the prompt_components by reflecting on labeled examples. Please provide suggestions in natural language and wrap them with `<suggestion></suggestion>`. \nPropose modifications to the current prompt. You also need to propose requirements for the output of the previous step. Please use `<requirement_for_previous></requirement_for_previous>` to wrap them, for example: `<requirement_for_previous>The analysis should include a comparison of the original data</requirement_for_previous>`.\n\nNote:\n1. Please ensure that the output is wrapped with `<requirement_for_previous></requirement_for_previous>` and `<suggestion></suggestion>`, and appears only once.\n2. If you are the first node, use `<requirement_for_previous>Current is the first node</requirement_for_previous>`.\n3. Please remember that this prompt template will be applied to multiple different data sets, so your suggestions should be general and not just focused on the provided example.\n4. Please analyze step by step and reflect on labeled examples."
},
"optimization": {
"order": [
"prom_start_1",
"prom_start_2",
"prom_suggestion",
"prom_end_1",
"prom_end_2"
],
"loop": [
"prom_suggestion"
],
"extract_key": [
"new_prompt",
"analyse"
],
"prom_start_1": "You are now a fine-tuner for a large language model prompt performing triage classification tasks. I will provide you with a prompt template and its corresponding input and output information. Please modify the prompt based on the given data by reflecting on labeled examples:\n\n- The current `prompt_components` are: <prompt_components>{prompt_components}</prompt_components>\n- The prompt can be composed by concatenating the prompt_components in the following order: <order>{prompts_order}</order>\n\n",
"prom_start_2": "Here is some explanatory information about the `prompt_components`, which are the basic building blocks for constructing the `prompt_template`:\n```json\n{\n \"TASK\": \"Description related to this task\",\n \"RULE\": \"Some rules to constrain the output\",\n \"STYLE\": \"The style to constrain the response\",\n \"EXAMPLE\": \"Examples for better understanding\",\n \"COT\": \"Used to prompt the model to think step by step, e.g., please think step by step\"\n}\n```\n\nBelow is some information about the model's performance with this template:\n\n",
"prom_suggestion": "# Instance {index}\n- Suggestions for prompt modification by reflecting on labeled examples: <suggestion>{suggestion}</suggestion>\n\n",
"prom_end_1": "You need to analyze the above content and output an optimized prompt result by reflecting on labeled examples. You only need to optimize the following fields: {needed_optim_component}.\n",
"prom_end_2": "Wrap the analysis process with <analyse></analyse>, and the new prompt with <new_prompt></new_prompt>. The specific content should be given as a JSON formatted dictionary, which can be directly converted to a dictionary using the json.loads() method.\n\nFor example, when fields \"COT\" and \"STYLE\" need to be optimized, your output would be a dictionary containing these two keys, as shown in the following example: <new_prompt>{\"COT\": \"Please think step by step\",\"STYLE\": \"Please answer in an essay style\"}</new_prompt>.\nIf you believe the original \"COT\" field is already excellent, the optimized prompt dictionary should not include the \"COT\" field. If you believe all fields are already excellent, please output an empty dictionary, i.e., <new_prompt>{}</new_prompt>.\n\nNotes:\n1. When using the prompt template in practice, the python format() method is used to fill the variables into the prompt, so please ensure that the content wrapped in {} remains the same in both the new and old prompts. Avoid adding or removing variables as much as possible.\n2. Ensure that your outputted new prompt template can be directly converted to a dictionary using the json.loads() method, so you need to pay attention to the use of double quotes and escape characters.\n3. Ensure that <analyse></analyse> and <new_prompt></new_prompt> appear only once each.\n4. If you believe the current prompt template performs excellently, please output <new_prompt>{}</new_prompt>."
}
}
},
"node_optimizer": {
"llm_config": {
"LLM_type": "Azure",
"API_KEY": "",
"API_BASE": "",
"temperature": 0.3,
"model": "gpt-4.1-int",
"SAVE_LOGS": false,
"log_path": "logs/trainer_god"
},
"meta_prompt": {
"backward": {
"order": [
"prom_start",
"prom_node_config",
"prom_run_instance",
"prom_end"
],
"loop": [],
"extract_key": [
"analyse",
"suggestion",
"requirement_for_previous"
],
"prom_start": "You are a large model fine-tuner specialized in triage classification tasks. Now you need to try to optimize the information of a node. For a complex task, it has been divided into multiple nodes, each of which contains multiple roles that work together to complete the task of this node. Each role is backed by an LLM Agent, and you need to optimize the configuration information of one of the nodes by reflecting on labeled examples.\n\nHere is an example of a Node configuration in JSON format:\n```json\n{\n \"node_name\": \"summary_node\",\n \"controller\": {\n \"route_type\": \"order\",\n \"route_system_prompt\": \"\",\n \"route_last_prompt\": \"\"\n },\n \"begin_role\": \"role_summary\",\n \"node_description\": \"Summarize the findings from the previous step\",\n \"node_roles_description\": {\n \"role_summary\": \"The role needs to summarize the key findings from the previous step concisely and present the final result within <result></result> tags.\"\n }\n}\n```\n\nHere are the relevant explanations for the Node configuration:\n- The fields in the \"controller\" indicate the scheduling method of the model. If there is only one role, this item does not need to be optimized:\n - \"route_type\" indicates the scheduling method, which has three values: \"random\" means random scheduling, \"order\" means sequential scheduling, and \"llm\" means scheduling determined by the LLM model.\n - \"route_system_prompt\" and \"route_last_prompt\" are used when \"route_type\" is \"llm\" and are respectively the system prompt and last prompt given to the LLM model responsible for scheduling.\n- \"begin_role\" is a string indicating the name of the starting role of this node.\n- \"roles\" is a dictionary where the key is the role name, and the value is the prompt used by this role.\n\nYou need to decide how to optimize the configuration of this node. Specifically, you need to try to provide suggestions in the following aspects:\n1. Update the node description field. This field describes the function of the node and is also an important indicator to measure the performance of a node.\n2. Update the scheduling method of the role. Note that if there is only one role, no optimization is needed.\n3. Add a new role, and you need to clearly describe the function of this role.\n4. Delete a role, and you need to clearly describe the reason for deleting this role.\n5. Update a role, and you need to indicate how to update the description of this role.\n\n",
"prom_node_config": "Next, I will give you a Node configuration, and you need to provide optimization suggestions based on the current Node configuration by reflecting on labeled examples. Please use <suggestion>[put your suggestion here]</suggestion> to enclose your suggestions. \nAt the same time, you also need to make some requirements for the performance of the previous node based on the information of the current node, please use <requirement_for_previous>the [put your requirement here] <requirement_for_previous>package.\n\n## Current Node Config\n{node_config}\n\n",
"prom_run_instance": "## Run Instance\nPrevious node information: <previous_node>{previous_node_summary}</previous_node>\nCurrent node output: <current_node>{role_chat}</current_node>\nNext node's requirement for the current node: <next node's requirement>{requirement_for_previous}</next node's requirement>\n",
"prom_end": "You need to first provide your analysis process, then give your optimized result. Please use <analyse></analyse> to enclose the analysis process. Please use <suggestion></suggestion> to enclose the optimization suggestions for the current node. Please use <requirement_for_previous></requirement_for_previous> to enclose the requirements for the previous node. If you think the current node does not need optimization, you need to output <suggestion>The performance is good enough, no modification suggestions</suggestion>.\n\nNote: The suggestions provided need to be in one or more of the five aspects mentioned above."
},
"optim": {
"order": [
"prom_start",
"prom_node_config",
"prom_suggestion",
"prom_end"
],
"loop": [],
"extract_key": [
"result"
],
"prom_start": "You are a large model fine-tuner specialized in triage classification tasks. Now you need to try to optimize the information of a node. For a complex task, it has been divided into multiple nodes, each containing multiple roles that work together to complete the task of this node. Each role is backed by an LLM Agent, and you need to optimize the configuration information of one of the nodes by reflecting on labeled examples.\n\nHere is an example of a Node configuration in JSON format:\n```json\n{\n \"node_name\": \"summary_node\",\n \"controller\": {\n \"route_type\": \"order\",\n \"route_system_prompt\": \"\",\n \"route_last_prompt\": \"\"\n },\n \"begin_role\": \"role_summary\",\n \"node_description\": \"Summarize the findings from the previous step\",\n \"node_roles_description\": {\n \"role_summary\": \"The role needs to summarize the key findings from the previous step.\"\n }\n}\n```\n\nHere are the relevant explanations for the Node configuration:\n- The fields in the \"controller\" indicate the scheduling method of the model. If there is only one role, this item does not need to be optimized:\n - \"route_type\" indicates the scheduling method, which has three values: \"random\" means random scheduling, \"order\" means sequential scheduling, and \"llm\" means scheduling determined by the LLM model.\n - \"route_system_prompt\" and \"route_last_prompt\" are used when \"route_type\" is \"llm\" and are respectively the system prompt and last prompt given to the LLM model responsible for scheduling.\n- \"begin_role\" is a string indicating the name of the starting role of this node.\n- \"roles\" is a dictionary where the key is the role name, and the value is the prompt used by this role.\n\nNext, I will give you a Node configuration and several modification suggestions. You need to modify the Node configuration based on the suggestions by reflecting on labeled examples:\n\n",
"prom_node_config": "## Current Node Config\n{node_config}\n\n",
"prom_suggestion": "## Suggestions\n{suggestions}\n\n",
"prom_end": "When providing the modification plan, you need to give the optimized result in the following format. It is a list, each element is a dict, and the dict contains an action field indicating the operation on the Node, as well as other fields as follows:\n```json\n[\n {\n # Add a role named role_check, you need to provide role_name, role_description, role_prompt\n \"action\": \"add_role\",\n \"role_name\": \"role_check\",\n \"role_description\": \"Check the result of the previous step\",\n \"role_prompt\": \"Output your thinking steps firstly, and if the answer is correct, output <result>1</result>, if the answer is incorrect, output <result>0</result>, <answer></answer>\"\n },\n {\n # Delete a role, you need to provide role_name\n \"action\": \"delete_role\",\n \"role_name\": \"role_analyse\"\n },\n {\n # Update the description of the role_summary node\n \"action\": \"update_role_description\",\n \"role_name\": \"role_summary\",\n \"role_description\": \"The role needs to summarize the key findings from the previous step concisely and present the final result within <result></result> tags.\"\n },\n {\n # Update the transfer method between roles, you need to provide route_type, route_system_prompt, route_last_prompt\n \"action\": \"update_controller\",\n \"route_type\": \"order\",\n \"route_system_prompt\": \"\",\n \"route_last_prompt\": \"\"\n },\n {\n # Update the node description\n \"action\": \"update_node_description\",\n \"node_description\": \"Summarize the findings from the previous step and output the final result. The results are usually between 1 and 5 words.\"\n }\n]\n```\n\nYour optimized result should be enclosed in <result></result>, that is, the content inside <result></result> should be a JSON-formatted list, which should be able to be directly loaded by json.loads().\n\nNote:\n1. If you think the current configuration is already excellent and does not need modification, you can directly output an empty list.\n2. The format of <result>[optimization method]</result> needs to strictly follow the given format, otherwise, it will be judged as incorrect."
}
}
},
"sop_optimizer": {
"llm_config": {
"LLM_type": "Azure",
"API_KEY": "",
"API_BASE": "",
"temperature": 0.3,
"model": "gpt-4.1-int",
"SAVE_LOGS": false,
"log_path": "logs/trainer_god"
},
"meta_prompt": {
"backward": {
"order": [
"prom_part1",
"prom_info",
"prom_end"
],
"loop": [],
"extract_key": [
"analyse",
"suggestion"
],
"prom_part1": "You are a large model fine-tuner specialized in triage classification tasks. There is a process that needs adjustment, and I will now provide you with a standard operation procedure (SOP) for handling a task. This SOP consists of multiple nodes, each responsible for completing specific tasks to accomplish the overall mission.\n\nI will provide you with an SOP and a runtime instance. You need to analyze this SOP and provide your optimization suggestions by reflecting on labeled examples. Each node corresponds to certain tasks, and you can find the task description in `node_description`.\n\nAn SOP mainly consists of nodes, each responsible for completing specific tasks to accomplish the overall mission. Each node has a name, description, and successor nodes. The successor nodes are a dictionary (`edges`), where the key is the successor node's name and the value is the successor node's Node object.\n\nHere is an example of an SOP:\n```json\n{\n \"nodes\": {\n \"Affirmative_Task_Allocation_node\": {\n ...\n },\n \"Negative_Task_Allocation_node\": {\n ...\n },\n \"Debate_Order_node\": {\n ...\n },\n \"Debate_Random_node\": {\n \"node_name\": \"Debate_Random_node\",\n \"node_description\": \"We are now in the open debate phase, where each debater has the freedom to speak as they wish.\\nThe debate topic is as follows: <debate topic>\\n<Theme>should Hermione Granger develop a romantic relationship with Harry Potter or Ron Weasley?</Theme>\\n <Affirmative viewpoint> Supporting Hermione and Harry together.</Affirmative viewpoint>\\n<Negative viewpoint> Supporting Hermione and Ron together</Negative viewpoint>\\n</debate topic>\\n \",\n },\n \"Judge_node\": {\n ...\n }\n },\n \"edges\": {\n \"Affirmative_Task_Allocation_node\": [\n \"Affirmative_Task_Allocation_node\",\n \"Negative_Task_Allocation_node\"\n ],\n \"Negative_Task_Allocation_node\": [\n \"Negative_Task_Allocation_node\",\n \"Debate_Order_node\"\n ],\n \"Debate_Order_node\": [\n \"Debate_Order_node\",\n \"Debate_Random_node\"\n ],\n \"Debate_Random_node\": [\n \"Debate_Random_node\",\n \"Judge_node\"\n ],\n \"Judge_node\": [\n \"Judge_node\",\n \"end_node\"\n ]\n },\n \"root\": \"Affirmative_Task_Allocation_node\",\n \"end\": \"end_node\"\n}\n```\n \nYou need to provide optimization suggestions in natural language by reflecting on labeled examples. Generally, optimizing this SOP can be approached from five aspects, and you can combine multiple aspects to provide comprehensive suggestions.\n\n1. **Add Nodes:** If you believe the SOP lacks certain nodes, you can add these nodes. You need to briefly describe the information about the new node, including the node's name, description, successor nodes.\n2. **Delete Nodes:** If you think some nodes in the SOP are redundant, you can delete these nodes. You need to provide the names of the nodes to be deleted and update the predecessor nodes' successor nodes to replace the deleted node.\n3. **Update Node Descriptions:** If you believe the node descriptions in the SOP are not clear enough, you can update these descriptions. You need to provide the names of the nodes to be updated and the new descriptions.\n4. **Update Relationships Between Nodes:** If you think the relationships between nodes in the SOP are not clear, you can update these relationships. You need to provide the updated relationships between the nodes.\n\nI will provide you with a specific SOP configuration and a runtime instance. You need to analyze this runtime instance and provide optimization suggestions by reflecting on labeled examples. Please use <analyse></analyse> to wrap your analysis and <suggestion></suggestion> to wrap your suggestions. For example:\n<analyse>Debate_Random_node did not perform well, and we could try adding a node before it.</analyse>\n<suggestion>Add a node before Debate_Random_node named Added_Debate_Random_node with the description: \"Further debate to clarify arguments.\" Its successor nodes are itself and Debate_Random_node, with the controller transfer type being \"order\".</suggestion>\n\n",
"prom_info": "Here is the specific task information you need to process:\n## SOP Config\n<sop_config>\n{sop_config}</sop_config>\n\n## Run Instance\n<run_instance>\n{run_instance_summary}</run_instance>\n\n## Evaluation\n<evaluation>\n{loss_info}</evaluation>\n\n",
"prom_end": "Note:\n1. You need to provide your analysis process and then give your optimization suggestions, describing them in natural language.\n2. The analysis process should be wrapped in <analyse></analyse>, and optimization suggestions should be wrapped in <suggestion></suggestion>. Both must be present.\n3. If there are no optimization suggestions, please provide the analysis result in <analyse></analyse> and give <suggestion>There is no need for optimization.</suggestion>.\n4. If the overall SOP is fine, but specific node behaviors need optimization, you may choose not to optimize. There will be further operations to optimize the nodes later.\n"
},
"optim": {
"order": [
"prom_start",
"prom_config",
"prom_suggestion",
"prom_end"
],
"loop": [
"prom_suggestion"
],
"extract_key": [
"analyse",
"result"
],
"prom_start": "You are a large model fine-tuner specialized in triage classification tasks. There is a process that needs adjustment, and I will now provide you with a standard operation procedure (SOP) for handling a task. This SOP consists of multiple nodes, each responsible for completing specific tasks to accomplish the overall mission.\n\nI will provide you with an SOP and a runtime instance. You need to analyze this SOP and provide your optimization suggestions by reflecting on labeled examples. Each node corresponds to certain tasks, and you can find the task description in `node_description`.\n\nAn SOP mainly consists of nodes, each responsible for completing specific tasks to accomplish the overall mission. Each node has a name, description, and successor nodes. The successor nodes are a dictionary (`edges`), where the key is the successor node's name and the value is the successor node's Node object.\n\nHere is an example of an SOP:\n```json\n{\n \"nodes\": {\n \"Affirmative_Task_Allocation_node\": {\n ...\n },\n \"Negative_Task_Allocation_node\": {\n ...\n },\n \"Debate_Order_node\": {\n ...\n },\n \"Debate_Random_node\": {\n \"node_name\": \"Debate_Random_node\",\n \"node_description\": \"We are now in the open debate phase, where each debater has the freedom to speak as they wish.\\nThe debate topic is as follows: <debate topic>\\n<Theme>should Hermione Granger develop a romantic relationship with Harry Potter or Ron Weasley?</Theme>\\n <Affirmative viewpoint> Supporting Hermione and Harry together.</Affirmative viewpoint>\\n<Negative viewpoint> Supporting Hermione and Ron together</Negative viewpoint>\\n</debate topic>\\n \",\n },\n \"Judge_node\": {\n ...\n }\n },\n \"edges\": {\n \"Affirmative_Task_Allocation_node\": [\n \"Affirmative_Task_Allocation_node\",\n \"Negative_Task_Allocation_node\"\n ],\n \"Negative_Task_Allocation_node\": [\n \"Negative_Task_Allocation_node\",\n \"Debate_Order_node\"\n ],\n \"Debate_Order_node\": [\n \"Debate_Order_node\",\n \"Debate_Random_node\"\n ],\n \"Debate_Random_node\": [\n \"Debate_Random_node\",\n \"Judge_node\"\n ],\n \"Judge_node\": [\n \"Judge_node\",\n \"end_node\"\n ]\n },\n \"root\": \"Affirmative_Task_Allocation_node\",\n \"end\": \"end_node\"\n}\n```\n\nI will provide you with an SOP and suggestions for modifications. You need to analyze this SOP and then provide optimization methods by reflecting on labeled examples. You need to first provide your analysis process, and then provide your optimized results. The analysis process should be wrapped in <analyse></analyse>, and the optimized results should be wrapped in <result></result>, which should be directly parsable into JSON.\n\nIf you believe no optimization is needed, leave the inside of <result></result> empty.\n\nIf you believe optimization is needed, use a JSON format to express your optimized results, as shown below:\n```json\n[\n {\n # Add a node named Affirmative_Task_Allocation_node. Provide node_name, node_description, and specify successor nodes.\n \"action\": \"add_node\",\n \"node_name\": \"Affirmative_Task_Allocation_node\",\n \"node_description\": \"It is currently the debate stage, where the positive side is assigning tasks.\",\n \"edges\": {\n \"Affirmative_Task_Allocation_node\": [\n \"Affirmative_Task_Allocation_node\",\n \"Negative_Task_Allocation_node\"\n ]\n }\n },\n {\n # Delete a node. Provide node_name and update the predecessor node's successor nodes. The modified edges should be given, with the nodes being the predecessors of the deleted node.\n \"action\": \"delete_node\",\n \"node_name\": \"Negative_Task_Allocation_node\",\n \"edges\": {\n # Affirmative_Task_Allocation_node is the predecessor of Negative_Task_Allocation_node, so its successor nodes need to be updated.\n \"Affirmative_Task_Allocation_node\": [\n \"Affirmative_Task_Allocation_node\",\n \"Debate_Order_node\"\n ]\n }\n },\n {\n # Update the Node description of Affirmative_Task_Allocation_node. Ensure that the modified description does not have significant semantic changes.\n \"action\": \"update_node_description\",\n \"node_name\": \"Affirmative_Task_Allocation_node\",\n \"node_description\": \"It is currently the debate stage, where the positive side is assigning tasks.\"\n },\n {\n # Update the edges between nodes. You need to note that each node has a self-loop, so its first successor is itself.\n \"action\": \"update_edges\",\n \"edges\": {\n \"Debate_Order_node\": [\n \"Debate_Order_node\",\n \"Debate_Random_node\"\n ]\n }\n }\n]\n```\n\n",
"prom_config": "Below are the configuration information and suggestions for the SOP that you need to optimize:\n\n## sop config\n{sop_config}\n\n## Suggestion\n\n",
"prom_suggestion": "### Suggestion\n<suggestion_{index}>\n{suggestion}</suggestion_{index}>\n\n",
"prom_end": "Note:\n1. The results should be wrapped in <result></result>, and they need to be directly parsable into JSON. Otherwise, it will be judged as an error.\n2. Both <result></result> and <analyse></analyse> are required. If no optimization is needed, leave the inside of <result></result> empty.\n3. The <result></result> provided should strictly follow the format of the given example JSON.\n4. You can combine actions such as add_node, delete_node, update_node_description, and update_edges. However, ensure your results are reasonable.\n5. When using add_node, you often need to update edges. When using delete_node, you often need to update the predecessor node's successor nodes.\n6. If not necessary, try to avoid adding and deleting nodes. If the problem can be solved by modifying the node description or adjusting the relationships between nodes, that is preferable."
}
}
}
}这个配置(本质上是一个 Agent Symbolic Learning 的训练配置文件 )是为 triage(分类/分诊)任务定制的,完整实现了 Agents 2.0 提出的 Symbolic Learning 框架------即用"语言化反向传播 + 语言梯度 + 提示优化器"的方式,让语言智能体从错误中自动学习、自我进化
整体架构类比
| 医学院角色 | 配置模块 | 职责 |
|---|---|---|
| 👨⚕️ 考官(出题+阅卷) | loss |
给实习生(Agent)打分 + 写评语(Language Loss) |
| 📚 导师 A:教怎么思考 | prompt_optimizer |
优化 prompt 模板(如"请分三步推理...") |
| 🎓 导师 B:教怎么分工协作 | node_optimizer |
优化节点配置(如新增"复核员"角色) |
| 🧭 院长:教整个诊疗流程 | sop_optimizer |
优化 SOP(Standard Operating Procedure),即多节点流水线 |
loss 考官:用 <requirement_for_previous> 写评语
📌 核心目标 :生成语言化损失(Language Loss),即一段带结构化标签的评语,用于后续反向传播。特点:
- 支持四种场景组合(有/无 ground truth + 有/无分数),非常灵活;
- 强调 格式严格 :必须输出
<requirement_for_previous>...</requirement_for_previous>,有时还要<score>7</score>; - 对"答案正确但啰嗦"零容忍------即使语义对,若输出
"The magazine is BUST"而标准答案是"BUST",也要扣分!
这个 <requirement_for_previous> 就是 Language Gradient 的雏形 :它明确告诉上一步的节点 哪里错了、怎么改。
prompt_optimizer ------ 导师 A:优化"思考模板"
它负责优化一个节点内部的 prompt_components ,即五大模块(你指定的 needed_optim_component):
| 字段 | 含义 | 类比 |
|---|---|---|
TASK |
任务描述 | "你现在要判断病人是否需急诊" |
RULE |
输出规则 | "只输出 YES/NO,不要解释" |
STYLE |
回复风格 | "简洁、专业、无废话" |
EXAMPLE |
示范样例 | 给几个正确/错误案例 |
COT |
思考链提示 | "请思考:1. 症状 → 2. 风险等级 → 3. 分类" |
优化流程分两步:
(1)backward:分析问题 + 提建议
→ 输入:
- 上一步输出
- 当前输出
<requirement_for_previous>(来自loss的评语)- 当前
prompt_components
→ 输出:
<suggestion>在 COT 中增加'检查是否含禁忌症'步骤</suggestion>
<requirement_for_previous>上一步需明确标注患者是否有过敏史</requirement_for_previous>它还能**向上游提要求,**这是协同学习的关键。
(2)optimization:生成新 prompt
→ 汇总多个 <suggestion>,输出 JSON:
<new_prompt>
{"COT": "1. Check vital signs\n2. Check allergy history\n3. Decide triage level", "RULE": "Answer only in <result>YES</result> or <result>NO</result>"}
</new_prompt>严格要求:
- 保留原变量
{xxx}(如{symptoms}),避免破坏format(); - 输出必须是合法 JSON(
json.loads()可解析); - 能空就空:若无需改,输出
{}。
node_optimizer ------ 导师 B:优化"角色团队配置"
一个 Node 可含多个 role(如"诊断员""复核员"),由 controller 调度(order/random/llm)。
它能优化五大维度:
| 优化动作 | 作用 | 示例 |
|---|---|---|
add_role |
增新角色 | 加"过敏检查员" |
delete_role |
删冗余角色 | 某角色总输出空 → 删除 |
update_role_description |
改角色职责 | 强调"必须查用药史" |
update_controller |
改调度逻辑 | 从 order 改为 llm |
update_node_description |
改节点总目标 | 更清晰定义本节点使命 |
两阶段:
(1)backward:诊断节点问题
→ 输入:节点配置 + 实际运行记录 + 下游要求
→ 输出:
<analyse>当前节点只有1个角色,但常漏检过敏信息</analyse>
<suggestion>add_role: role_name="role_allergy_checker", ...</suggestion>
<requirement_for_previous>上一节点需提供完整用药清单</requirement_for_previous>(2)optim:生成可执行变更计划
→ 输出 <result>[ {...action dict...} ]:
[
{
"action": "add_role",
"role_name": "role_allergy_checker",
"role_prompt": "Please check if the patient has any drug allergies. If yes, output <result>YES</result>; else <result>NO</result>."
},
{
"action": "update_node_description",
"node_description": "Triage node: assess urgency, check allergies, and assign priority level."
}
]这相当于在"科室"层面做组织架构调整!
sop_optimizer ------ 院长:优化"诊疗全流程"
负责整个多节点 pipeline 的宏观优化(即 SOP = Standard Operating Procedure)。
| 动作 | 说明 |
|---|---|
add_node |
插入新环节(如"预检分诊") |
delete_node |
合并冗余环节 |
update_node_description |
重定义节点职责 |
update_edges |
调整流程走向(谁接谁) |
当前流程:症状收集 → 直接分诊
问题:高风险患者漏判
优化:add_node("Risk_Screening_node"),插在中间,专门做风险评估。它谨慎增删节点------优先改描述或连线,符合"最小改动原则"。
这是一个 端到端的自我进化系统
| 层级 | 对应神经网络 | 本项目实现 | 你的优势匹配 |
|---|---|---|---|
| 权重(weights) | prompt / tools | ✅ prompt_optimizer |
你熟悉 prompt 工程 & Azure |
| 层(layer) | Node | ✅ node_optimizer |
你研究多 agent 协同 |
| 计算图(graph) | SOP | ✅ sop_optimizer |
你关注流程设计 |
| 损失函数(loss) | Language Loss | ✅ loss 模块 |
你重视评估指标 |
它真正实现了:让 triage agent 像学生一样,考一次 → 改一次 → 进步一次。
训练测试
监控指标
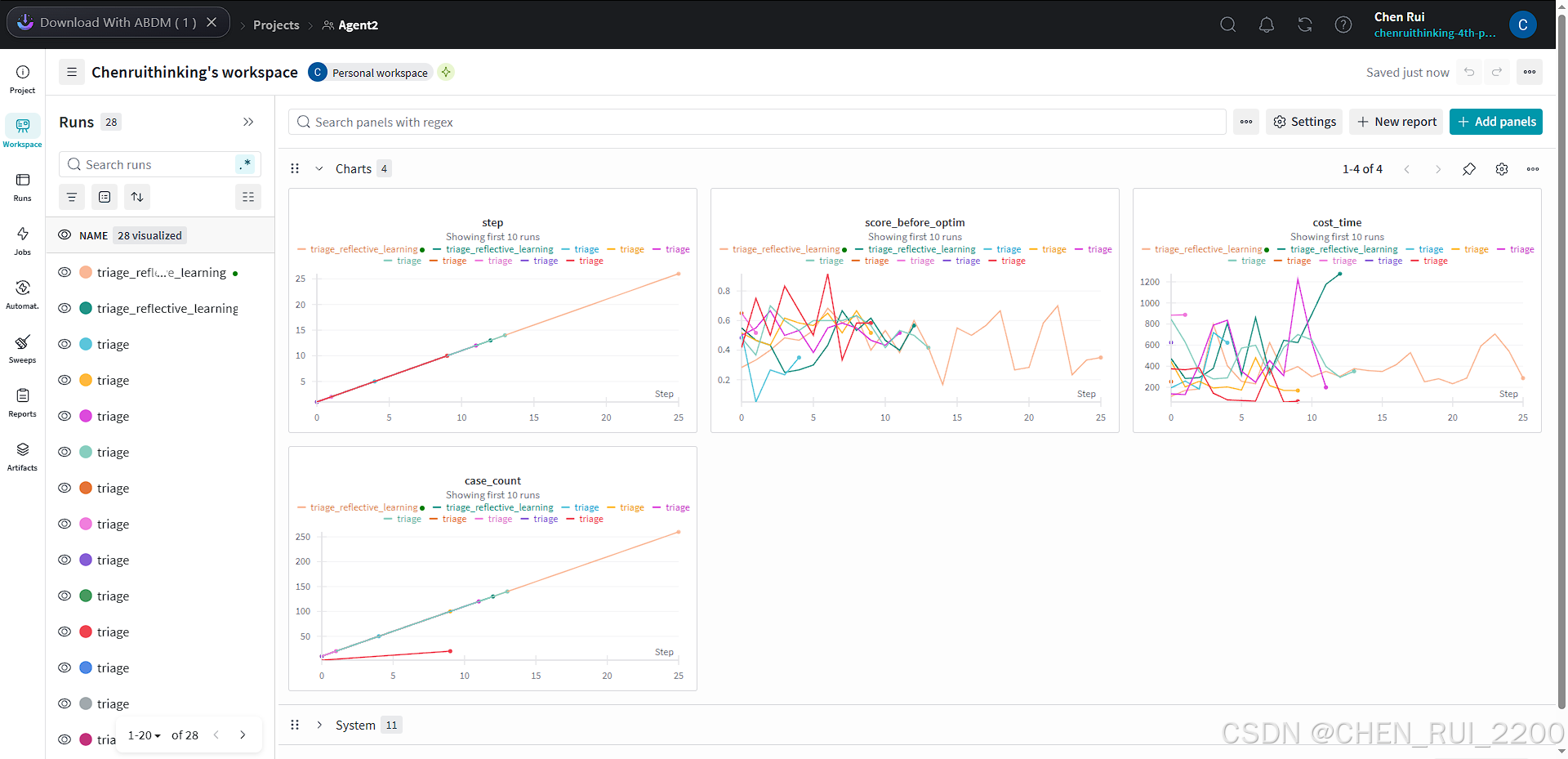
多训练一段时间侯运行eval脚本检查下优化结果