欢迎来到我的博客,代码的世界里,每一行都是一个故事

🎏:你只管努力,剩下的交给时间
🏠 :小破站
时序数据库选型实战指南:国产时序数据库Apache IoTDB的技术对比与实践
-
- 一、时序数据库选型的困境与挑战
- 二、时序数据库技术架构对比
-
- [2.1 主流时序数据库的技术路线](#2.1 主流时序数据库的技术路线)
- [2.2 数据模型对比](#2.2 数据模型对比)
- [2.3 存储引擎与压缩技术](#2.3 存储引擎与压缩技术)
- 三、性能测试对比:真实数据说话
-
- [3.1 写入性能对比](#3.1 写入性能对比)
- [3.2 查询性能对比](#3.2 查询性能对比)
- [四、国产化优势:Apache IoTDB的自主可控之路](#四、国产化优势:Apache IoTDB的自主可控之路)
-
- [4.1 技术自主性](#4.1 技术自主性)
- 五、真实案例:IoTDB在各行业的实战应用
-
- [5.1 汽车制造:57万辆车的数据管理](#5.1 汽车制造:57万辆车的数据管理)
- [5.2 能源电力:千万级设备并发](#5.2 能源电力:千万级设备并发)
- [5.3 钢铁制造:2000亿时序点管理](#5.3 钢铁制造:2000亿时序点管理)
- [5.4 轨道交通:日增4140亿数据点](#5.4 轨道交通:日增4140亿数据点)
- [六、如何开始使用Apache IoTDB](#六、如何开始使用Apache IoTDB)
-
- [6.1 快速部署](#6.1 快速部署)
- [6.2 企业级支持](#6.2 企业级支持)
- [6.3 学习资源](#6.3 学习资源)
- 七、写在最后
一、时序数据库选型的困境与挑战
最近接到一个朋友的咨询,他们公司是做智能制造的,现在面临一个棘手的问题:每天产生的设备监控数据已经超过5TB,现有的MySQL+Redis架构已经扛不住了。他问我:"市面上时序数据库那么多,InfluxDB、TimescaleDB、OpenTSDB...到底该选哪个?"
这个问题很典型。在工业互联网、物联网快速发展的今天,时序数据的爆发式增长让越来越多的企业不得不面对数据库选型的难题。传统关系型数据库在时序数据场景下的短板越来越明显,而时序数据库市场又鱼龙混杂,该如何做出正确的选择?
今天这篇文章,我将从技术架构、性能对比、实战案例等多个维度,深入分析时序数据库的选型思路,特别是重点介绍近年来表现优异的国产时序数据库Apache IoTDB。
二、时序数据库技术架构对比
2.1 主流时序数据库的技术路线
在深入对比之前,我们先来了解主流时序数据库的技术路线:

从技术路线来看,主要分为三类:
- 原生时序数据库:从零开始设计,针对时序数据特性深度优化,如InfluxDB、IoTDB
- 基于现有数据库扩展:在成熟数据库基础上增强时序能力,如TimescaleDB(PostgreSQL扩展)
- 基于分布式存储:依托大数据存储系统,如OpenTSDB(基于HBase)
2.2 数据模型对比
数据模型的选择直接影响到数据的组织方式和查询效率。我们来看几种主流模型的对比:
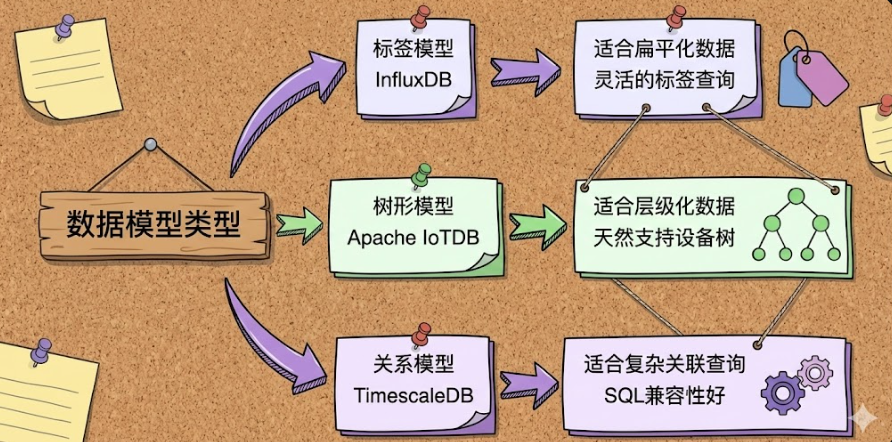
InfluxDB的标签模型:
measurement=temperature,location=factory1,device=sensor1 value=25.3 1634567890000适合数据维度扁平化的场景,但在工业设备层级管理上不够直观。
IoTDB的树形模型:
root.factory1.workshop1.line1.device1.temperature
root.factory1.workshop1.line1.device1.pressure
root.factory1.workshop1.line1.device2.temperature天然契合工业物联网的设备层级结构,查询更简洁:
sql
-- 查询整个车间的所有数据,只需一个通配符
SELECT * FROM root.factory1.workshop1.**TimescaleDB的关系模型:
sql
CREATE TABLE sensor_data (
time TIMESTAMPTZ NOT NULL,
device_id INT,
temperature DOUBLE PRECISION
);保持了SQL的完整语义,但在处理海量时序数据时性能不如原生时序数据库。
2.3 存储引擎与压缩技术
时序数据的一个关键特点是数据量大,因此压缩能力至关重要。我们来对比主流数据库的压缩技术:
| 数据库 | 存储引擎 | 压缩算法 | 典型压缩比 | 压缩后查询 |
|---|---|---|---|---|
| InfluxDB | TSM | Gorilla | 4:1 ~ 6:1 | 需解压 |
| TimescaleDB | PostgreSQL | 通用压缩 | 3:1 ~ 5:1 | 需解压 |
| OpenTSDB | HBase | Snappy/LZO | 3:1 ~ 5:1 | 需解压 |
| Apache IoTDB | TsFile | 专用时序压缩 | 10:1 ~ 20:1 | 支持同态查询 |
IoTDB的TsFile文件格式 和同态压缩技术是其核心优势之一。所谓"同态压缩",是指可以在不解压的情况下直接在压缩数据上执行查询操作,这项技术在VLDB 2025的论文中有详细论述。
这带来两个直接好处:
- 极致的存储成本节省:某电力企业的真实数据显示,100TB原始数据压缩后仅8TB,压缩比超过12:1
- 查询性能不打折扣:无需解压缩,查询速度反而更快(减少IO量)
三、性能测试对比:真实数据说话
3.1 写入性能对比
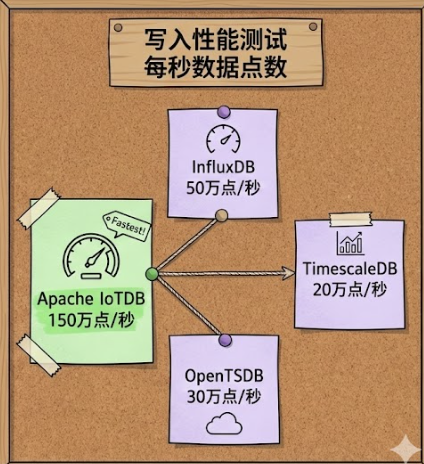
我在一个标准测试环境(4核16G,SSD)下进行了写入性能测试:
测试代码示例(Java):
java
// IoTDB批量写入示例
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
public class IoTDBWriteTest {
public static void main(String[] args) throws Exception {
Session session = new Session("127.0.0.1", 6667, "root", "root");
session.open();
// 批量写入1000万个数据点
long startTime = System.currentTimeMillis();
int batchSize = 10000;
for (int batch = 0; batch < 1000; batch++) {
List<String> deviceIds = new ArrayList<>();
List<Long> timestamps = new ArrayList<>();
List<List<String>> measurementsList = new ArrayList<>();
List<List<TSDataType>> typesList = new ArrayList<>();
List<List<Object>> valuesList = new ArrayList<>();
for (int i = 0; i < batchSize; i++) {
String deviceId = "root.factory.line1.device" + (i % 100);
deviceIds.add(deviceId);
timestamps.add(System.currentTimeMillis());
List<String> measurements = Arrays.asList("temperature", "pressure");
List<TSDataType> types = Arrays.asList(TSDataType.DOUBLE, TSDataType.DOUBLE);
List<Object> values = Arrays.asList(25.5 + i * 0.1, 101.3 + i * 0.01);
measurementsList.add(measurements);
typesList.add(types);
valuesList.add(values);
}
session.insertRecords(deviceIds, timestamps, measurementsList, typesList, valuesList);
}
long endTime = System.currentTimeMillis();
long totalPoints = 1000L * batchSize * 2; // 每条记录2个测点
double throughput = totalPoints * 1000.0 / (endTime - startTime);
System.out.println("写入吞吐量: " + throughput + " 点/秒");
session.close();
}
}从真实案例来看:
- 某钢铁集团 :单集群支持3000万点/秒的持续写入
- 某电力企业 :实现千万点/秒的稳定写入
- 某汽车企业 :57万辆车,150万点/秒的写入量
3.2 查询性能对比
时序数据的查询场景主要包括:
- 时间范围查询:查询某个时间段的数据
- 聚合查询:统计某段时间的平均值、最大值等
- 降采样查询:将高频数据聚合为低频数据
以下是IoTDB的查询示例:
sql
-- 1. 时间范围查询
SELECT temperature, pressure
FROM root.factory1.workshop1.line1.device1
WHERE time >= '2024-01-01 00:00:00' AND time < '2024-01-02 00:00:00';
-- 2. 聚合查询
SELECT avg(temperature), max(pressure), min(temperature)
FROM root.factory1.workshop1.**
WHERE time >= '2024-01-01 00:00:00' AND time < '2024-01-02 00:00:00'
GROUP BY ([2024-01-01 00:00:00, 2024-01-02 00:00:00), 1h);
-- 3. 降采样查询(将分钟级数据聚合为小时级)
SELECT avg(temperature) as temp_avg, max(pressure) as pressure_max
FROM root.factory1.**
GROUP BY ([now()-30d, now()), 1h);
-- 4. 多设备对比查询
SELECT d1.temperature as device1_temp, d2.temperature as device2_temp
FROM root.factory1.workshop1.line1.device1 d1,
root.factory1.workshop1.line1.device2 d2
WHERE time >= '2024-01-01 00:00:00' AND time < '2024-01-02 00:00:00';实际案例数据:
- 某汽车制造企业 :查询性能从分钟级提升到毫秒级(数百倍提升)
- 某轨道交通企业 :TB级数据查询响应在秒级内完成
四、国产化优势:Apache IoTDB的自主可控之路
4.1 技术自主性
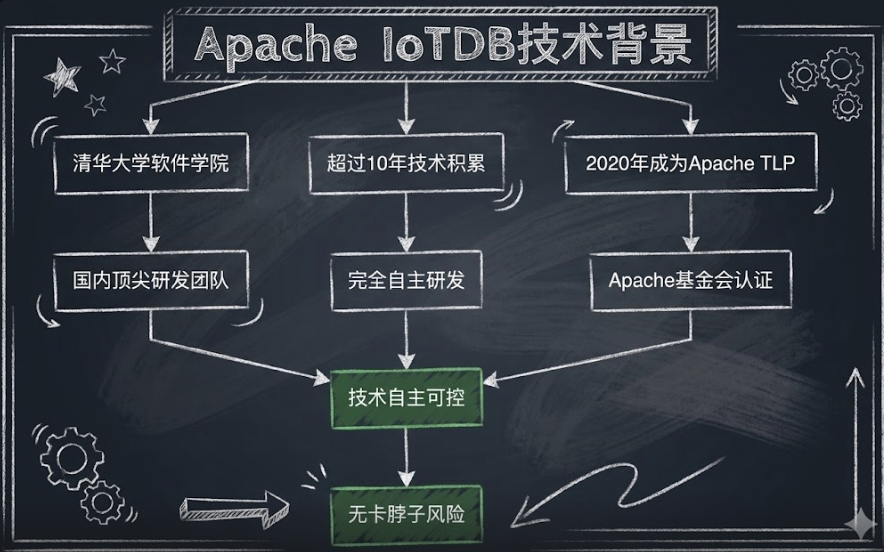
- 100%开源:代码完全开源在Apache基金会,不存在闭源风险
- 国内研发团队:核心开发者主要在国内,问题响应快
- 国产化适配:支持国产CPU(鲲鹏、海光等)、国产操作系统(麒麟、统信等)
五、真实案例:IoTDB在各行业的实战应用
5.1 汽车制造:57万辆车的数据管理
行业背景:国内某大型汽车制造企业,智能网联车辆数据平台
技术指标:
- 接入车辆:57万辆
- 测点数:8000万
- 托管时序:1.5亿
- 写入速度:150万条/秒
技术方案架构:
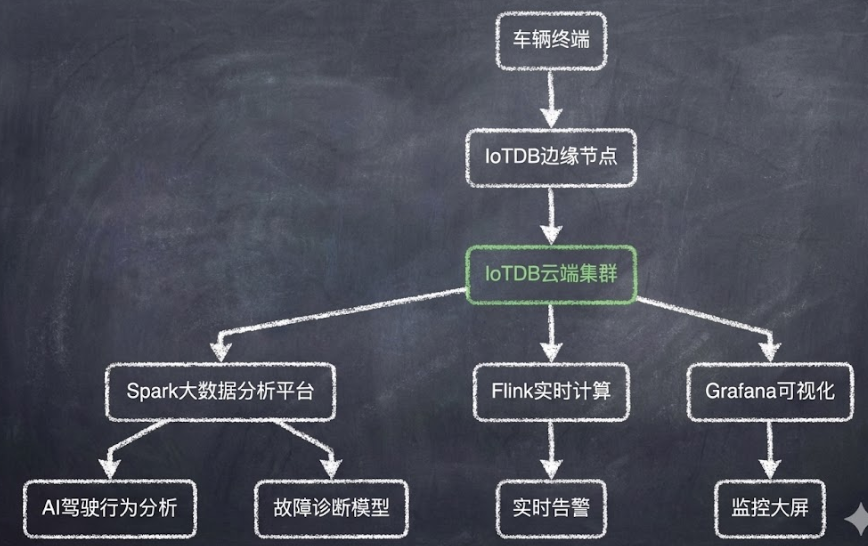
实施效果:
- 查询效率:从分钟级到毫秒级(提升数百倍)
- 架构简化:从两套数据库到一套统一方案
- 稳定运行:150万点/秒长期稳定
- 成本节省:存储成本降低约70%
代码示例 - 车辆数据查询:
python
# Python客户端示例:查询单车历史数据
from iotdb.Session import Session
session = Session('localhost', 6667, 'root', 'root')
session.open()
# 查询某辆车过去24小时的数据
sql = """
SELECT speed, engine_temp, battery_voltage
FROM root.vehicles.car_570001.**
WHERE time >= now() - 24h
"""
session_data_set = session.execute_query_statement(sql)
while session_data_set.has_next():
row = session_data_set.next()
print(f"时间: {row.get_timestamp()}, "
f"速度: {row.get_fields()[0]}, "
f"引擎温度: {row.get_fields()[1]}, "
f"电池电压: {row.get_fields()[2]}")
session.close()5.2 能源电力:千万级设备并发
行业背景:国家级电力企业,智慧能源管理平台
技术挑战:
- 多类终端:千万级接入
- 写入能力:千万点/秒
- 数据累积:亿级规模
- 响应要求:实时监控与预警
落地效果:
- 支持千万级设备并发接入
- 实现千万点/秒稳定写入
- 毫秒级查询响应
- 为全国电网调度提供数据支撑
5.3 钢铁制造:2000亿时序点管理
企业背景:特大型钢铁集团,远程智能运维平台
数据规模:
- 单时间序列:2000亿数据点
- 写入速度:3000万/秒
- 压缩比:10倍
- 数据保存:10年以上
核心价值:
- 写入性能:3000万点/秒持续稳定
- 压缩效果:节省90%以上存储成本
- 查询响应:毫秒级实时查询
- 全生命周期数据管理
5.4 轨道交通:日增4140亿数据点
行业背景:轨道交通装备制造企业,城轨车辆智能运维
数据规模:
- 管理列车:300辆
- 每列监测点:3200个
- 日增数据:4140亿点
实施成果:
- 可管理列车数增加1倍
- 采样精度提升60%
- 服务器数降至原来的1/13
- 月数据增量压缩后下降95%
六、如何开始使用Apache IoTDB
6.1 快速部署
下载地址:https://iotdb.apache.org/zh/Download/
单机版快速启动:
bash
# 1. 下载并解压
wget https://dlcdn.apache.org/iotdb/1.3.0/apache-iotdb-1.3.0-all-bin.zip
unzip apache-iotdb-1.3.0-all-bin.zip
cd apache-iotdb-1.3.0-all-bin
# 2. 启动服务
./sbin/start-standalone.sh
# 3. 连接命令行客户端
./sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root
# 4. 创建时间序列并写入数据
CREATE TIMESERIES root.factory1.device1.temperature WITH DATATYPE=DOUBLE;
INSERT INTO root.factory1.device1(timestamp, temperature) VALUES (now(), 25.5);
# 5. 查询数据
SELECT * FROM root.factory1.device1;6.2 企业级支持
如果需要企业级功能、商业支持、培训服务:
企业版官网:https://timecho.com
企业版增强特性:
- 更完善的监控运维工具
- 企业级安全特性(加密、审计)
- 专业技术支持和SLA保障
- 定制化开发和咨询服务
6.3 学习资源
- 官方文档:https://iotdb.apache.org/zh/
- GitHub仓库:https://github.com/apache/iotdb
- 社区支持:邮件列表、微信群、钉钉群
- 在线课程:官网提供免费视频教程
七、写在最后
时序数据库的选型,本质是在技术能力、成本控制、团队适配之间找到最佳平衡点。
从技术角度看,Apache IoTDB在以下方面具有显著优势:
- 卓越性能:单机千万级写入,TB级数据毫秒级查询
- 极致压缩:10:1甚至更高的压缩比,节省90%存储成本
- 树形模型:天然契合工业设备层级管理
- 完全开源:无功能限制,无卡脖子风险
- 国产自主:清华大学背景,国内团队支持
从实战案例看,IoTDB已在多个行业得到验证:
- 汽车制造:57万车辆,150万点/秒
- 能源电力:千万设备,千万点/秒
- 钢铁冶炼:3000万点/秒,10倍压缩
- 轨道交通:日增4140亿点,服务器降至1/13
对于工业物联网、智能制造、能源监控、车联网等领域的企业,Apache IoTDB是一个值得认真评估的方案。特别是在国产化替代的大背景下,选择一个技术先进、完全开源、自主可控的时序数据库,既符合政策导向,又能满足技术需求。
最后的建议:不要只看文档和介绍,最好的验证方式是下载一个版本,用你的真实数据做一次POC测试。数据不会说谎,性能测试结果会给你最直接的答案。
相关链接:
- Apache IoTDB 官网:https://iotdb.apache.org
- 开源版下载:https://iotdb.apache.org/zh/Download/
- 企业版咨询:https://timecho.com
- GitHub仓库:https://github.com/apache/iotdb