项目背景与意义
在自然语言处理(NLP)领域,文本相似度计算是一项基础且重要的任务,广泛应用于问答系统、信息检索、推荐系统等场景。本文将介绍一个基于双向 LSTM(BiLSTM)的中文文本相似度计算项目,该项目能够量化评估两个中文句子的语义相似程度,输出 0-5 分的相似度分数(分数越高表示越相似)。项目已开源,我的github地址: jiapengLi11/BiLSTM_text_similarity
项目整体架构
本项目采用模块化设计,主要包含以下几个核心模块:
- 数据加载模块(
data_loader.py):负责加载和划分数据集 - 文本预处理模块(
preprocessor.py):处理文本清洗、分词、编码等 - 模型定义模块(
model.py):实现 BiLSTM 相似度模型 - 训练模块(
train.py):模型训练、评估与保存 - 预测模块(
predict.py):使用训练好的模型进行相似度预测 - 配置模块(
config.py):集中管理项目参数
项目文件结构如下:
text_similarity/
├── data_loader.py # 数据加载与划分
├── preprocessor.py # 文本预处理
├── model.py # 模型定义
├── train.py # 模型训练
├── predict.py # 相似度预测
├── config.py # 配置参数
├── chinese_tokenizer.pkl # 保存的分词器
├── chinese_similarity_model.pth # 模型文件
└── STS-B/ # 数据集目录核心技术与实现细节
1. 数据集介绍
本项目使用中文 STS-B(Semantic Textual Similarity Benchmark)数据集,包含大量中文句子对及其对应的相似度分数(0-5 分)。数据以制表符分隔,每行包含两个句子和它们的相似度分数。
2. 文本预处理流程
文本预处理是 NLP 任务的关键步骤,直接影响模型性能。本项目的预处理流程包括:
(1)文本清洗
去除文本中的标点符号、特殊字符和多余空格,只保留中文字符和必要的空格:
python
def clean_chinese_text(text):
"""中文文本清洗:去除标点、特殊字符、多余空格"""
text = str(text).strip()
text = re.sub(r"[^\u4e00-\u9fa5\s]", "", text) # 只保留中文和空格
text = re.sub(r"\s+", " ", text) # 合并多个空格
return text(2)中文分词
使用 jieba 库进行中文分词:
python
def tokenize_chinese(text):
"""中文分词(jieba精确模式)"""
return jieba.lcut(text)(3)词汇表构建
基于训练数据构建词汇表,保留高频词,低频词用<UNK>标记:
python
class Tokenizer:
def __init__(self, num_words=VOCAB_SIZE, oov_token=OOV_TOKEN):
self.num_words = num_words
self.oov_token = oov_token
self.word_index = {oov_token: OOV_INDEX, PAD_TOKEN: PAD_INDEX}
self.index_word = {OOV_INDEX: oov_token, PAD_INDEX: PAD_TOKEN}
self.word_counts = defaultdict(int)
self.vocab_size = 2 # 初始包含PAD和OOV(4)序列填充与截断
将文本序列统一为固定长度(通过计算训练集序列长度的 95 分位数确定):
python
def pad_sequences(sequences, maxlen, padding='post', truncating='post'):
"""序列填充/截断"""
padded_sequences = []
for seq in sequences:
if len(seq) > maxlen:
if truncating == 'post':
seq = seq[:maxlen]
else:
seq = seq[-maxlen:]
else:
pad_length = maxlen - len(seq)
if padding == 'post':
seq = seq + [PAD_INDEX] * pad_length
else:
seq = [PAD_INDEX] * pad_length + seq
padded_sequences.append(seq)
return np.array(padded_sequences, dtype=np.int64)3. 模型架构设计
本项目采用 BiLSTM(双向 LSTM)作为基础模型,通过以下步骤计算文本相似度:
- 嵌入层:将词索引转换为稠密向量
- BiLSTM 层:捕获句子的上下文信息
- 特征融合:结合最后时刻的隐藏状态、序列均值和序列最大值作为句子特征
- 全连接层:通过多层感知机计算最终相似度分数
模型代码实现:
python
class BiLSTMSimilarityModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, lstm_units, dense_units, dropout_rate, max_seq_len):
super(BiLSTMSimilarityModel, self).__init__()
self.max_seq_len = max_seq_len
# 嵌入层
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim,
padding_idx=PAD_INDEX
)
self.embedding_dropout = nn.Dropout(0.3)
# BiLSTM层
self.bilstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=lstm_units,
bidirectional=True,
batch_first=True,
dropout=0.3,
num_layers=2
)
# Dropout层
self.dropout = nn.Dropout(0.4)
# 全连接层
self.fc1 = nn.Linear(lstm_units * 2 * 3 * 2, dense_units)
self.bn1 = nn.BatchNorm1d(dense_units)
self.fc2 = nn.Linear(dense_units, dense_units // 2)
self.bn2 = nn.BatchNorm1d(dense_units // 2)
self.fc3 = nn.Linear(dense_units // 2, 1)
# 激活函数
self.relu = nn.LeakyReLU(0.1)
def forward(self, sent1, sent2):
# 嵌入层 + dropout
embed1 = self.embedding(sent1)
embed1 = self.embedding_dropout(embed1)
embed2 = self.embedding(sent2)
embed2 = self.embedding_dropout(embed2)
# BiLSTM层
out1, (hidden1, _) = self.bilstm(embed1)
out2, (hidden2, _) = self.bilstm(embed2)
# 特征提取
hidden1 = torch.cat((hidden1[0], hidden1[1]), dim=1)
avg1 = torch.mean(out1, dim=1)
max1 = torch.max(out1, dim=1)[0]
feat1 = torch.cat((hidden1, avg1, max1), dim=1)
hidden2 = torch.cat((hidden2[0], hidden2[1]), dim=1)
avg2 = torch.mean(out2, dim=1)
max2 = torch.max(out2, dim=1)[0]
feat2 = torch.cat((hidden2, avg2, max2), dim=1)
# Dropout
feat1 = self.dropout(feat1)
feat2 = self.dropout(feat2)
# 拼接特征
combined = torch.cat((feat1, feat2), dim=1)
# 全连接层
x = self.fc1(combined)
x = self.bn1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.dropout(x)
output = self.fc3(x)
return output4. 模型训练策略
为了提高模型性能并防止过拟合,采用了以下训练策略:
- 损失函数:使用均方误差(MSE)作为损失函数,适合回归任务
- 优化器:使用 AdamW 优化器,带权重衰减的 Adam 优化器,能有效防止过拟合
- 学习率调度:使用 ReduceLROnPlateau,当验证损失不再下降时自动降低学习率
- 早停策略:当验证损失连续多个 epoch 没有改善时,提前停止训练
- 正则化:在嵌入层和全连接层后加入 Dropout,全连接层使用批归一化
训练过程代码片段:
python
def train_epoch(model, train_loader, criterion, optimizer):
model.train()
total_loss = 0.0
total_mae = 0.0
total_samples = 0
for batch in train_loader:
sent1 = batch['sent1'].to(DEVICE)
sent2 = batch['sent2'].to(DEVICE)
scores = batch['score'].to(DEVICE).float()
optimizer.zero_grad()
outputs = model(sent1, sent2)
loss = criterion(outputs, scores)
loss.backward()
optimizer.step()
# 计算MAE
mae = torch.mean(torch.abs(outputs - scores))
total_loss += loss.item() * sent1.size(0)
total_mae += mae.item() * sent1.size(0)
total_samples += sent1.size(0)
avg_loss = total_loss / total_samples
avg_mae = total_mae / total_samples
return avg_loss, avg_mae5. 训练可视化
训练过程中记录损失变化,并绘制训练 / 验证损失曲线和 MAE 曲线,直观展示模型训练过程:
python
def plot_training_history(history):
"""绘制并保存训练曲线:MSE损失曲线 + MAE曲线"""
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# MSE损失曲线
ax1.plot(history['train_loss'], label='训练集MSE', color='#FF6B6B', linewidth=2)
ax1.plot(history['val_loss'], label='验证集MSE', color='#4ECDC4', linewidth=2)
ax1.set_title('训练/验证集MSE损失变化', fontsize=14)
ax1.set_xlabel('Epoch', fontsize=12)
ax1.set_ylabel('MSE损失', fontsize=12)
ax1.legend()
ax1.grid(True, alpha=0.3)
# MAE曲线
ax2.plot(history['train_mae'], label='训练集MAE', color='#FF6B6B', linewidth=2)
ax2.plot(history['val_mae'], label='验证集MAE', color='#4ECDC4', linewidth=2)
ax2.set_title('训练/验证集MAE变化', fontsize=14)
ax2.set_xlabel('Epoch', fontsize=12)
ax2.set_ylabel('MAE', fontsize=12)
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(TRAIN_HISTORY_SAVE_PATH, dpi=300)
plt.close()预测功能实现
训练完成后,可使用predict.py进行文本相似度预测,流程如下:
- 加载保存的模型和分词器
- 对输入的新句子进行清洗、分词、编码和填充
- 使用模型进行预测并输出结果
预测代码示例:
python
def predict_similarity(sent1, sent2):
"""预测两个中文句子的相似度(0-5分 + 归一化0-1分)"""
global model, tokenizer
# 首次调用时加载模型和Tokenizer
if model is None or tokenizer is None:
model, tokenizer = load_model_and_tokenizer()
# 预处理新句子
sent1_clean = clean_chinese_text(sent1)
sent2_clean = clean_chinese_text(sent2)
sent1_token = tokenize_chinese(sent1_clean)
sent2_token = tokenize_chinese(sent2_clean)
sent1_enc = tokenizer.texts_to_sequences([sent1_token])
sent2_enc = tokenizer.texts_to_sequences([sent2_token])
sent1_pad = pad_sequences(sent1_enc, maxlen=MAX_SEQ_LEN)
sent2_pad = pad_sequences(sent2_enc, maxlen=MAX_SEQ_LEN)
# 转换为张量并预测
sent1_tensor = torch.tensor(sent1_pad, dtype=torch.long).to(DEVICE)
sent2_tensor = torch.tensor(sent2_pad, dtype=torch.long).to(DEVICE)
with torch.no_grad():
similarity_score = model(sent1_tensor, sent2_tensor).item()
# 结果处理
similarity_score = max(0.0, min(5.0, similarity_score)) # 限制范围
normalized_score = similarity_score / 5.0 # 归一化
return similarity_score, normalized_score项目运行与结果展示
运行步骤
- 准备 STS-B 数据集,放在
STS-B目录下 - 安装依赖库:
torch,jieba,pandas,numpy,scikit-learn,matplotlib,tqdm - 运行训练脚本:
python train.py - 运行预测脚本:
python predict.py
预测结果示例
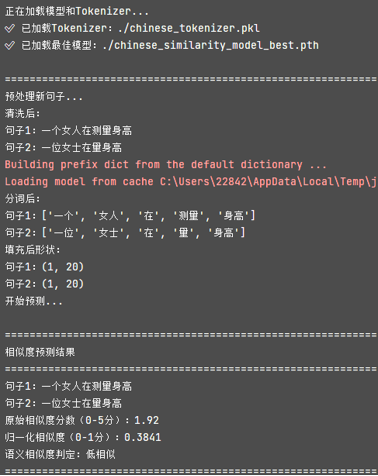
总结与展望
本项目实现了一个基于 BiLSTM 的中文文本相似度计算模型,通过合理的预处理流程和模型设计,能够有效评估中文句子对的语义相似程度。项目采用模块化设计,代码结构清晰,易于维护和扩展。
未来可以从以下几个方面进行改进:
- 使用预训练语言模型(如 BERT、RoBERTa)替换 BiLSTM,提升模型性能
- 增加数据增强策略,扩充训练数据
- 尝试更复杂的注意力机制,让模型更关注句子中的关键信息
- 支持批量预测和 API 服务部署
通过这个项目,我们不仅掌握了文本相似度计算的基本原理和实现方法,也学习了 NLP 任务中常用的预处理技巧和模型训练策略,为更复杂的 NLP 应用打下了基础。# 基于 BiLSTM 的中文文本相似度计算项目实现