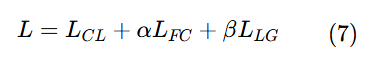研究方向:Image Captioning
论文全名:《PixCLIP: Achieving Fine-grained Visual Language Understanding via
Any-granularity Pixel-Text Alignment Learning》
1. 论文介绍
提升CLIP模型细粒度图像-文本对齐能力仍是一个活跃的研究焦点。为此,大多数现有工作采用
1)增加视觉信息处理粒度的策略(例如,结合视觉提示引导模型关注图像内特定局部区域)。
2)用长且详细的文本描述进行训练提高模型的细粒度视觉-语言对齐。
然而,CLIP文本编码器无法处理嵌入在长文本序列中的更细粒度文本信息。
为了协同利用增强视觉和文本内容处理粒度的优势,我们提出了PixCLIP,一个旨在同时容纳视觉提示输入和处理冗长文本描述的新颖框架。
首先建立一个自动化注释流程,能够为图像生成像素级的局部化、长篇形式的文本描述。利用这个流程,我们构建了LongGRIT,一个包含近150万个样本的高质量数据集。
其次用LLM替换CLIP的原始文本编码器,并提出了一个三分支的图像-文本对齐学习框架,促进图像区域与任意粒度下对应的文本描述之间的细粒度对齐。
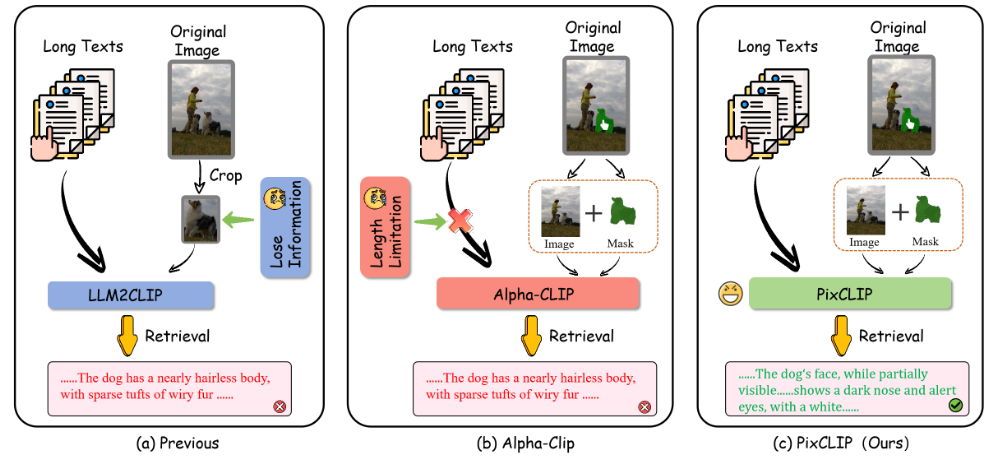
2. 方法介绍
2.1 细粒度数据生成
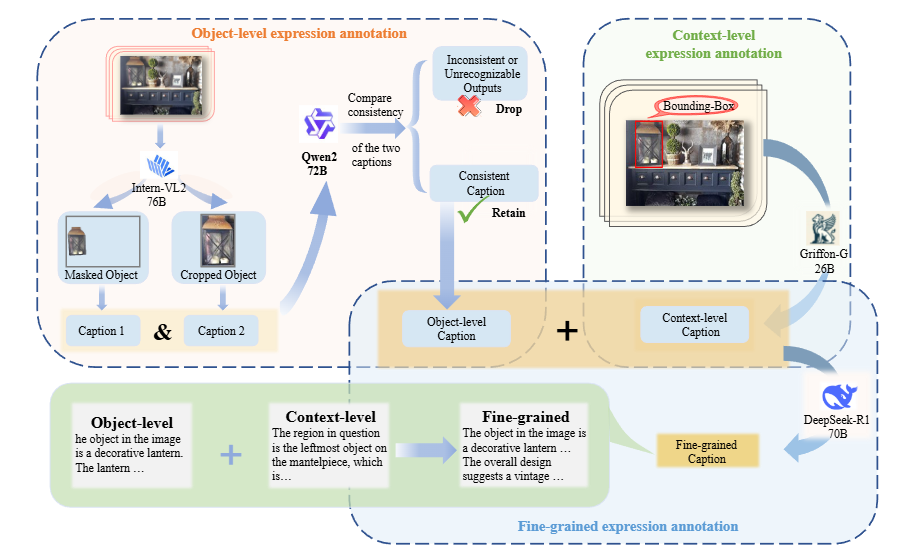
LongGRiT数据集流程建立在GRIT-20M数据集(图像区域-文本对,每张图像中特定区域(由边界框或掩码定义)与对应的文本描述)之上,包括三个阶段:
对象级别表达注释:使用GRIT-20M的分割掩码隔离出每个物体。裁剪后的物体及其掩码被输入到InternVL2-76B中,生成一个初步的、关注视觉属性(例如,形状、颜色、纹理)的物体级标题。
为确保语义一致性,我们采用Qwen2-72B来验证标题与原始图像的一致性。任何被标记为不一致(例如,描述不存在的特征)或在语义上无效(例如,"一个红色的钟"对于一个蓝色花瓶)的标题都被丢弃,而有效的标题则作为物体级注释被保留。
上下文级别表达注释:将原始图像和物体的边界框输入到Griffion-G-26B(专门用于空间推理的视觉语言模型)。该模型生成一个描述物体位置(例如,"壁炉台上最左边的")及其与周围物体关系的上下文级标题。
细粒度表达注释:通过DeepSeek-R1-70B整合对向级和上下文级标题,该模型将两种输入合成为统一的细粒度表达。
例如,如果物体级标题陈述"装饰灯笼",而上下文级标题指出"壁炉台最左边的物体",DeepSeek-R1-70B将它们合并为:"这件物品是一盏装饰灯笼,上面有精美的雕刻,它被放置在木制壁炉架的最左侧,两侧是装裱好的肖像画。"
这种层次化的方法确保描述既精确又具有上下文联系。
2.2 模型结构
引入了一个并行的掩码patch嵌入层,用于接收单通道的二维输入。分别通过各自的patch嵌入层处理输入图像和掩码,然后将它们的输出相加。
输入图像I和掩码M,特征F:
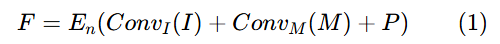
和
是图像和掩码块嵌入层,En是视觉编码器,P 表示位置编码
2.3 多粒度训练方法
PixCLIP 采用三种主要的对齐策略:全局图像-文本对齐、局部掩码-文本对齐和多尺度特征增强。
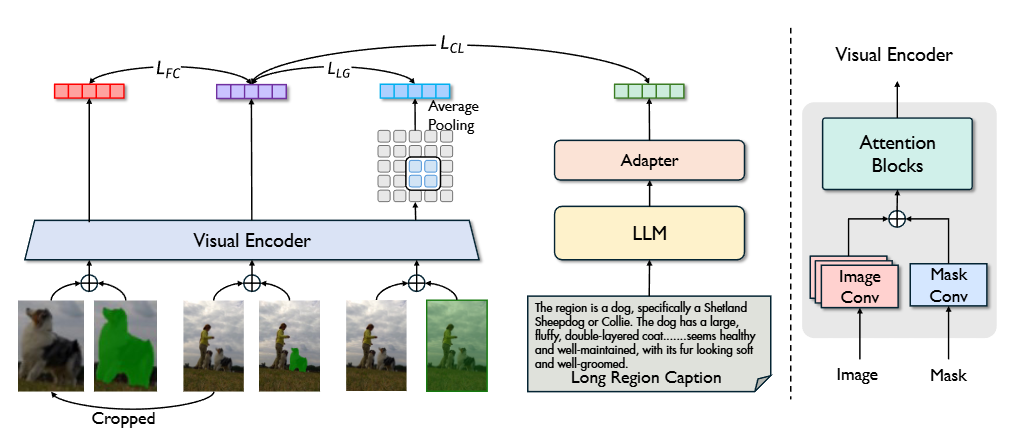
输入: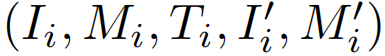 ,原始图像
,原始图像 、掩码
和描述被掩蔽区域的长文本
(LongGRiT),
的裁剪图像
的掩码
。
文本编码器:LLAMA3-8B
适配器:来自LLM2Vec的适配器(一个简单的投影器)
掩码文本对比学习:
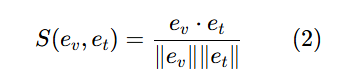
:掩码视觉嵌入,
:长文本嵌入,计算余弦相似度
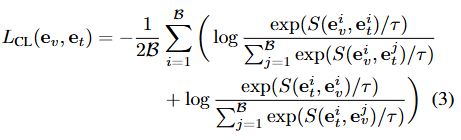
模型通过最大化与相应文本和图像嵌入的余弦相似度,同时最小化与批次中其他非对应嵌入的余弦相似度,来强制学习视觉和文本嵌入。
精细裁剪对齐:
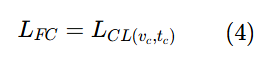
:裁剪图像
和对应裁剪掩码
的视觉嵌入。
:与该裁剪区域对应的文本嵌入
局部-全局表征增强:
输入原始图像与全1掩码
,从全局密集表示中,我们再次提取局部表示。
根据掩码 M 所占区域,对视觉密集特征 {fᵢv}ᵢ≤P 进行池化,使用平均池化提取区域视觉表示:
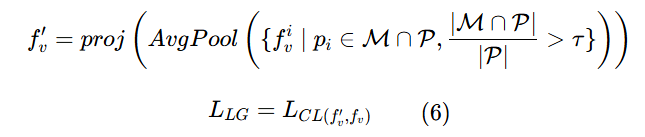
总损失: