30 Content-based Filtering
30.1 Collaborative Filtering vs. Content-based Filtering
协同过滤主要是通过已有的用户评分来推荐,而基于内容的过滤不仅利用已有用户评分,还会利用用户和事物的特征来推荐,所以比协同过滤效果更好
我们仍然用电影来举例,用xu(j)x_u^{(j)}xu(j)表示用户j的特征,用xm(i)x_m^{(i)}xm(i)表示电影i的特征
注:
- 用户或电影的特征包括已知的固有特征,例如用户的年龄,电影的上映年份等,我们也可以根据用户对电影的评分,构建出新的用户或电影特征,例如用户对爱情片的平均评分,电影的平均评分
- 用户特征和电影特征的维度可能相差很大,这是正常的
在协同过滤中,我们用wjx(i)+b(j)w^{{j}}x^{(i)}+b^{(j)}wjx(i)+b(j)预测评分,而在基于内容的过滤中我们去除b参数,事实证明这对预测效果没有影响,并且我们用vu(j)v_u^{(j)}vu(j)这个向量去代表用户的特征(取代w(j)w^{(j)}w(j),两者可以不同维度,这个向量是由用户特征xu(j)x_u^{(j)}xu(j)计算得到的),类似地,用vm(i)v_m^{(i)}vm(i)这个向量去代表电影的特征(取代x(i)x^{(i)}x(i),是由电影特征xm(j)x_m^{(j)}xm(j)计算得到的),两者的点积为预测值(两个v向量同维度)
30.2 Deep Learning for Contend-based Filtering
使用深度学习可以很好地实现基于内容的过滤,由用户和电影的特征,计算出vu(j)v_u^{(j)}vu(j)和vm(j)v_m^{(j)}vm(j)
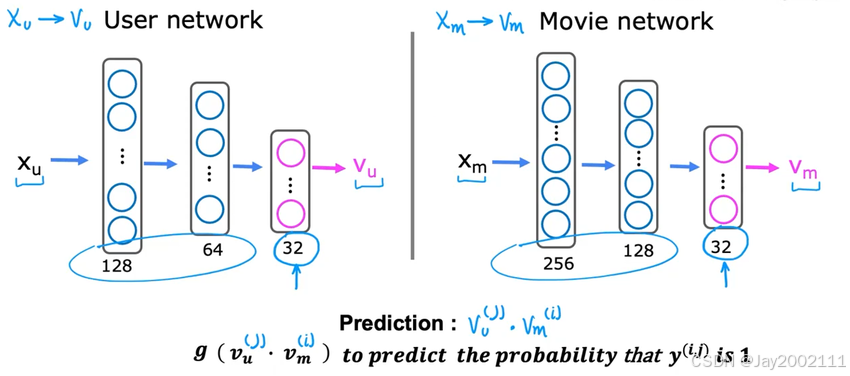
构建用户和电影两个神经网络,输出层分别为vu(j)v_u^{(j)}vu(j)和vm(j)v_m^{(j)}vm(j),计算两者点积即为预测值,如果期望是二元输出,加一层Sigmoid函数即可
两个神经网络是放在一起训练的 ,成本函数:
J=∑(i,j);r(i,j)=1(vu(j)⋅vm(i)−y(i,j))2J = \sum_{(i, j); r(i, j)=1} (v_u^{(j)} \cdot v_m^{(i)} - y^{(i, j)})^2J=(i,j);r(i,j)=1∑(vu(j)⋅vm(i)−y(i,j))2
类似地,我们可以用vm(j)v_m^{(j)}vm(j)之间的距离(∥vmk−vmi∥2\|v_m^k - v_m^i\|^2∥vmk−vmi∥2)去找到相似的电影
30.3 Recommending from a Large Catalogue
大型的推荐系统,推荐的项目往往数量特别庞大,如果每次都要全量推理,显然是不现实的
可以分为两步:检索(Retrieval)和排序(Ranking)
检索阶段用快速的手段,初筛出候选项,例如推荐电影,可以通过用户最近看过的10个电影的相似电影等方法快速检索,然后去重
排序阶段对检索出来的项目列表,利用训练好的模型进行推理,得到预测值
注:检索出更多的项目肯定可以提高表现,但是要考虑成本,可行的方案是离线实验,找出权衡成本与推荐效果的检索方案
30.4 Ethical Use of Recommender Systems
需要注意推荐系统的伦理道德问题。略。
30.5 TensorFlow Implementation
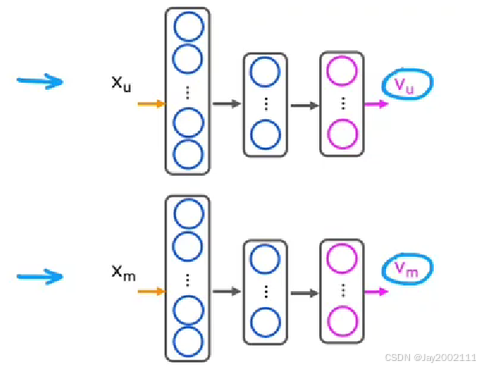
可以使用TensorFlow实现基于内容的过滤方法,示例:
python
user_NN = tf.keras.models.Sequential(
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(32) # 注意这里输出层是32个数字,假设 vu 和 vm 定为32维
)
item_NN = tf.keras.models.Sequential(
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(32) # 注意这里输出层是32个数字,假设 vu 和 vm 定为32维
)
# 用户特征输入层
input_user = tf.keras.layers.Input(shape(num_user_features))
# 通过用户网络得到vu
vu = user_NN(input_user)
# **对用户嵌入向量 vu 进行 L2 范数归一化**
# L2 归一化(即除以向量的欧几里得长度/模长)的目的:
# 1. 约束向量大小:将所有向量都缩放到单位长度(长度为 1)。
# 2. 使得点积只依赖于方向:归一化后,两个向量的点积 v_u · v_m 就等于它们夹角的余弦值(余弦相似度 Cosine Similarity)
# 3. 改善训练稳定性:防止向量元素过大,有助于梯度下降。
# `axis = 1` 表示对每一行(即每一个用户的嵌入向量)进行归一化。
vu = tf.linalg.l2_normalize(vu, axis = 1)
# 物品特征输入层
input_item = tf.keras.layers.Input(shape(num_item_features))
vm = item_NN(input_item)
vm = tf.linalg.l2_normalize(vm, axis = 1)
# 预测层:通过用户向量 vu 和物品向量 vm 的点积计算预测评分
# `axes = 1` 表示沿着第二个维度(即向量维度 32)进行点积。
output = tf.keras.layers.Dot(axes = 1)([vu, vm])
# 构建最终模型,输入是 (用户特征, 物品特征),输出是预测评分
model = Model([input_user, input_item], output)
# 成本函数
cost_fn = tf.keras.losses.MeanSquaredError()
# 模型编译
# 1. 选择优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# 2. 编译
model.compile(
optimizer=optimizer,
loss=cost_fn,
metrics=['mse', 'mae'] # 评估指标:均方误差 (MSE) 和 平均绝对误差 (MAE)
)
# 模型拟合(略)
# 模型推理(略)注:
- 再次说明一下,激活函数的选择和预期输出有关,这里我们的输出层预期是32维向量用于表示用户或电影的特征,所以其值预期正负都可以,且需要是具体的数值而不是表示分类的离散值,用线性激活函数(即不指定激活函数)
- 用户特征和电影特征的原始向量,涉及无序的、离散的分类特征使用独热编码 ,可以消除顺序假设、保证等距离 ,例如用户特征里有国籍,国籍之间没有内在的等级或顺序关系。如果用整数编码(如A国=1, B国=2),模型会错误地认为"B国"比"A国"大,引入偏差,且所有国籍向量之间的欧几里得距离都是2\sqrt{2}2 ,保证了它们在特征空间中是等距离的。涉及数值特征要归一化(如Min-max缩放到0-1)或标准化(例如Z-score缩放) ,可以防止大数值特征主导损失函数以及加速梯度下降收敛。