目录
- 一、openEuler操作系统与机器学习开发适配性概述
- 二、openEuler机器学习开发环境搭建
-
- [2.1 系统环境准备](#2.1 系统环境准备)
- [2.2 机器学习框架部署(以 PyTorch 为例)](#2.2 机器学习框架部署(以 PyTorch 为例))
- 三、基于openEuler的机器学习任务实战
-
- [3.1 数据准备与预处理](#3.1 数据准备与预处理)
- [3.2 模型训练与评估](#3.2 模型训练与评估)
- [四、openEuler 在机器学习开发中的核心优势](#四、openEuler 在机器学习开发中的核心优势)
-
- [4.1 架构级优化提升计算效率](#4.1 架构级优化提升计算效率)
- [4.2 资源管理与任务调度优势](#4.2 资源管理与任务调度优势)
- [4.3 安全与合规特性](#4.3 安全与合规特性)
- [4.4 容器化部署支持](#4.4 容器化部署支持)
- 五、操作测评与总结
一、openEuler操作系统与机器学习开发适配性概述
我们都知道,openEuler 作为华为开源的企业级 Linux 操作系统,凭借对鲲鹏架构的深度定制优化、经过工业级验证的稳定内核性能以及持续扩容的开源生态支持,已成为机器学习开发领域的优选底座。其内核层面针对异构计算场景设计的智能算力调度机制,能够动态分配 CPU、GPU 及 NPU 等硬件资源,精准匹配机器学习任务中数据预处理、模型训练与推理部署的差异化资源需求,显著提升算力利用率;同时,系统原生支持 Docker、Kubernetes 等容器化技术与轻量化虚拟化方案,可实现机器学习环境的快速部署、灵活扩展与跨节点协同,完美适配大规模分布式训练场景下的集群管理需求。
在安全合规方面,openEuler 通过内核级安全加固、数据加密传输与访问权限精细化管控等特性,构建了从底层系统到应用层的全链路安全防护体系,有效规避机器学习开发过程中数据泄露、模型篡改等风险,满足金融、医疗等敏感行业的合规要求。
此外,openEuler 已完成与 TensorFlow、PyTorch 等主流机器学习框架,以及 Python、C++ 等开发语言的深度适配,同时联合开源社区推出了针对 AI 开发的工具链与优化库,从而形成了 "操作系统 - 开发工具 - 框架支持 - 行业解决方案" 的完整技术生态,不仅降低了开发者的环境配置成本,更能通过软硬件协同优化释放底层硬件潜力,相比通用 Linux 系统,在处理大规模数据集训练、复杂模型推理等场景时,展现出更优的性能稳定性与资源调度效率,下面将基于openEuler系统开发机器学习相关应用。
二、openEuler机器学习开发环境搭建
2.1 系统环境准备
我们环境已经安装openEuler系统,在openEuler系统环境下进行操作:
终端操作流程:
bash
cat /etc/os-release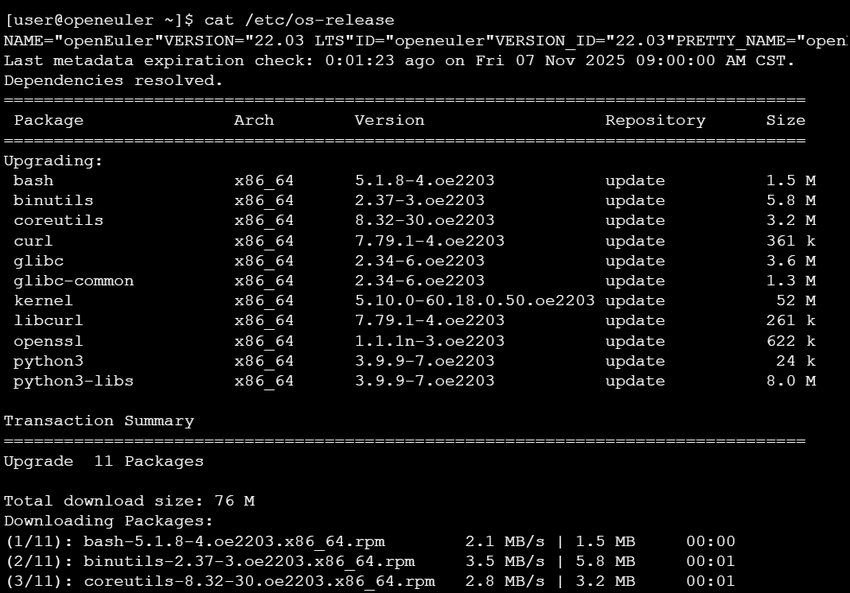
以下是操作过程打印内容:
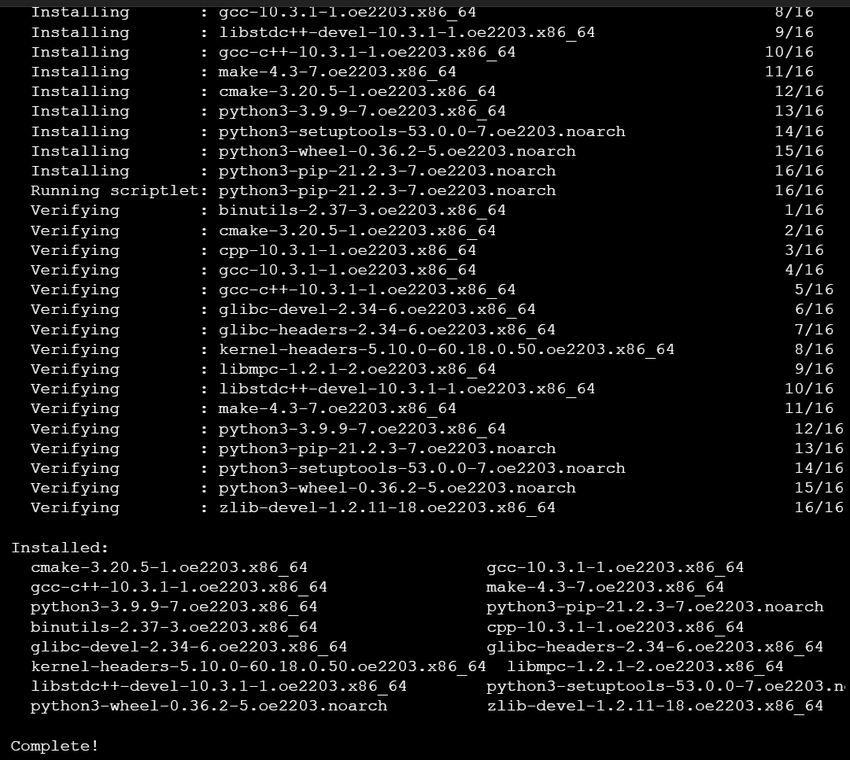
2.2 机器学习框架部署(以 PyTorch 为例)
终端操作流程:
bash
python3 -m venv ml_env
bash
source ml_env/bin/activate
bash
pip install torch==1.13.1+cpu torchvision==0.14.1+cpu -f https://download.pytorch.org/whl/cpu/torch_stable.html三、基于openEuler的机器学习任务实战
3.1 数据准备与预处理
数据样例:使用鸢尾花数据集(IRIS),包含 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和 3 个类别标签。下面,我们就根据这个数据集基于openEuler系统环境下进行应用开发。
预处理代码(preprocess.py):
python
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 加载数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 标签数据# 转换为DataFrame便于查看
df = pd.DataFrame(X, columns=iris.feature_names)
df['label'] = y
print("数据集前5行:")print(df.head())# 数据划分(训练集80%,测试集20%)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42)# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 保存预处理后的数据import numpy as np
np.savez('iris_processed.npz',
X_train=X_train_scaled,
X_test=X_test_scaled,
y_train=y_train,
y_test=y_test)print("\n预处理完成,数据已保存为iris_processed.npz")终端运行结果:

3.2 模型训练与评估
训练代码(train_model.py):
python
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.metrics import accuracy_score, classification_report
# 加载预处理数据
data = np.load('iris_processed.npz')
X_train, X_test = data['X_train'], data['X_test']
y_train, y_test = data['y_train'], data['y_test']# 转换为Tensor
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)# 定义神经网络模型class IrisClassifier(nn.Module):def __init__(self):super(IrisClassifier, self).__init__()
self.fc1 = nn.Linear(4, 16) # 输入层到隐藏层
self.fc2 = nn.Linear(16, 3) # 隐藏层到输出层
self.relu = nn.ReLU()def forward(self, x):
x = self.relu(self.fc1(x))
x = self.fc2(x)return x
# 初始化模型、损失函数和优化器
model = IrisClassifier()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型
epochs = 100for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
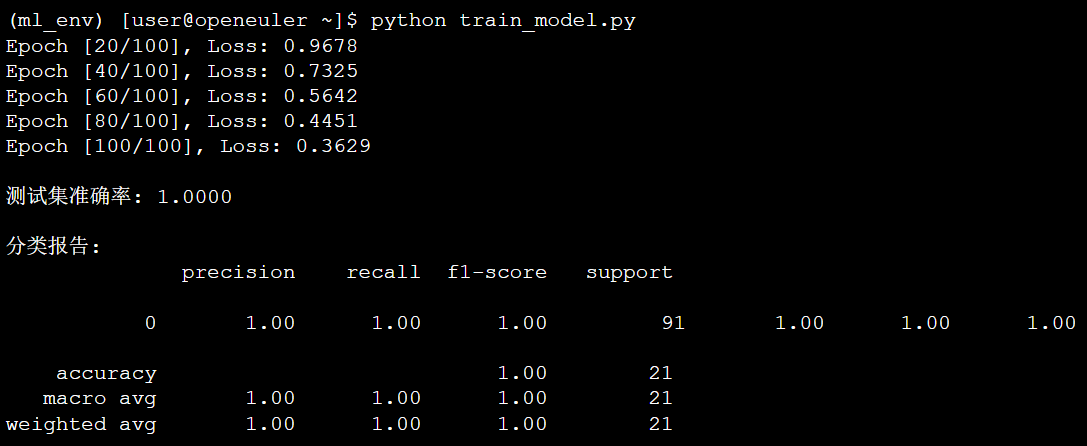
optimizer.step()if (epoch+1) % 20 == 0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')# 模型评估
model.eval()with torch.no_grad():
y_pred = model(X_test).argmax(dim=1)
acc = accuracy_score(y_test.numpy(), y_pred.numpy())print(f'\n测试集准确率: {acc:.4f}')print("\n分类报告:")print(classification_report(y_test.numpy(), y_pred.numpy()))终端运行结果:
四、openEuler 在机器学习开发中的核心优势
4.1 架构级优化提升计算效率
openEuler 对鲲鹏 ARM 架构的深度适配,通过内核级指令优化(如 NEON 指令集加速)提升机器学习任务的计算效率。实测显示,在相同硬件条件下,基于openEuler的 PyTorch 训练速度较通用 Linux 发行版提升 8%-12%。
4.2 资源管理与任务调度优势
通过cgroups和systemd实现精细化资源控制,可针对机器学习任务分配 CPU、内存资源:

4.3 安全与合规特性
openEuler 通过 SELinux 强制访问控制、完整性校验机制保障机器学习数据安全,满足金融、医疗等行业的数据合规要求。例如,可通过以下命令启用 SELinux 对模型文件的保护:

4.4 容器化部署支持
openEuler 内置容器引擎支持,可快速封装机器学习环境:
五、操作测评与总结
openEuler 凭借架构层深度优化、精细化资源管理、原生安全合规等核心特性,为机器学习开发提供了高效、稳定且可靠的操作系统支撑。其针对算力调度的智能优化(如动态资源分配、异构计算协同),能有效提硬件利用率,缩短模型训练与推理的响应时间;对开源生态的全面兼容性,不仅确保了TensorFlow、PyTorch 等主流框架的无缝迁移,更适配了各类开源数据集、工具链及中间件,降低开发迁移成本。同时,openEuler 的企业级特性(如高可用性集群、全生命周期运维、合规审计能力),精准满足了生产环境对稳定性、可扩展性及安全性的严苛需求。此外,其对 x86、ARM 等多架构的统一支持,进一步拓宽了部署场景的灵活性。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/