集群:多个节点(服务器)组合成了一个共同的平台,对外提供相同的服务。--redis集群
之前的redis主从复制,不算是集群。
1、redis集群模型图
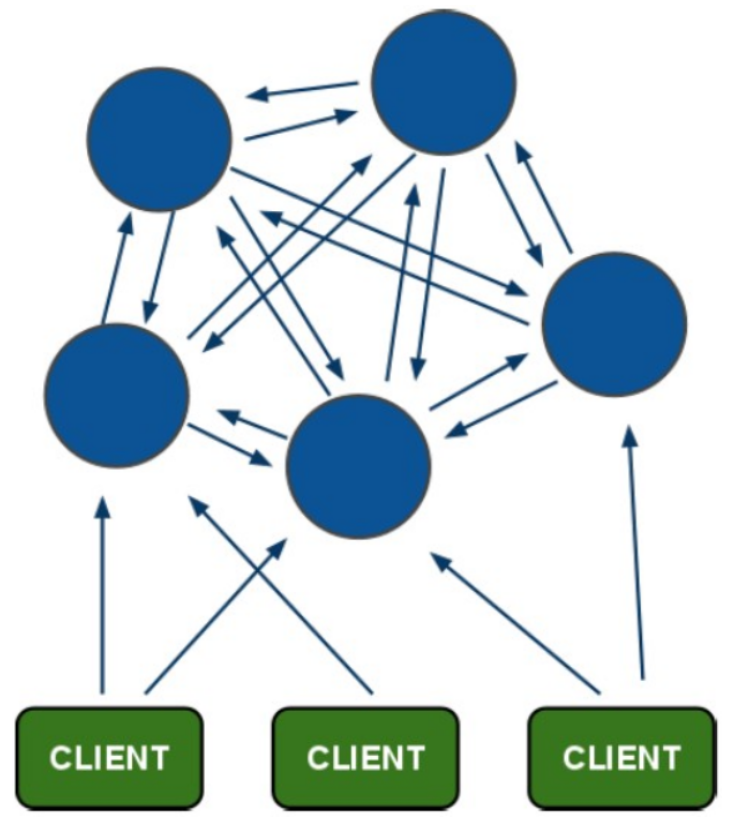
Client 连接上集群中任何一个master节点,都可以使用。
主从模式:总节点和从节点的数据是一模一样的,所以不能达到扩展的目的,比如redis内存不够用了,不能通过搞一个主从模式来拓展。
必须走集群。假如集群中有5台服务器,这5台redis中的数据不一样。为了防止master节点挂掉,每一个master节点都来一个主从复制。
假如有一个数据 set name zhangsan
1、redis集群的高可用,不是依赖于master节点多,而是依赖于主从。
2、redis集群中没有配置哨兵模式,自身有一套自己的机制,可以做到主从切换。
3、假如节点添加或者减少,数据会进行转移,这个转移,手动的。
1、集群通信是通过"ping-pong"机制进行通信;
2、客户端不需要将所有的节点都连接上,只需要连接其中一个节点即可。
3、集群中存储数据是存储到一个个的槽slot中,集群中槽的个数是固定的:16384,槽的编号是【0-16383】。在集群中存储数据时,会根据key进行计算(CRC16校验算法),计算出一个结果,然后将这个结果和16384取余,余数就是这个key将要存储的槽的编号。
比如 set name zhangsan --> crc16(name)%16384 = [0~16383]
注意:槽的编号之间不能断开。
槽的计算会将数据保存的很平均,不会产生一个槽满一个槽空的情况。2、数据分配算法
第一种能想到的是hash算法:比如对name 这个key,进行hash,然后对服务器的数量进行 取模。
1、哈希算法的哈希函数比较简单,一般是根据某个key的值或者key 的哈希值与当前可用的 master节点数取模,根据取模的值获取具体的服务器。
这个算法的缺点是:master节点因为可能挂掉或者追加,此时我们的redis数据需要重新计算一遍,非常的麻烦。
比较简单,可以看出只要你哈希函数设计的好,数据在各个服务器上是比较均匀分布的,但是哈希算法有一个致命的缺点:扩展性特别的差,比如以前5台,现在变为6台,数据又该如何处理?
现在有三个redis服务器 set name zhansgsan --> hash(name) % 3 = [0,1,2]第二种能想到的:一致性hash算法。
数据映射到哈希环上后按照顺时针的方向查找存储节点,即从数据映射在环上的位置开始,顺时针方向找到的第一个存储节点,那么他就存储在这个节点上。
缺点:
一致性哈希算法会会造成数据分布不均匀的问题或者叫做数据倾斜问题,就像我们图中那样,数据分布不均匀可能会造成某一个节点的负载过大,从而宕机。造成数据分布不均匀有以下两种情况:
- 第一:哈希函数的原因,经过哈希函数之后服务器在哈希环上的分布不均匀,服务器之间的间距不相等,这样就会导致数据不均匀。
- 第二:某服务器宕机了,后继节点就需要承受原本属于宕机机器的数据,这样也会造成数据不均匀。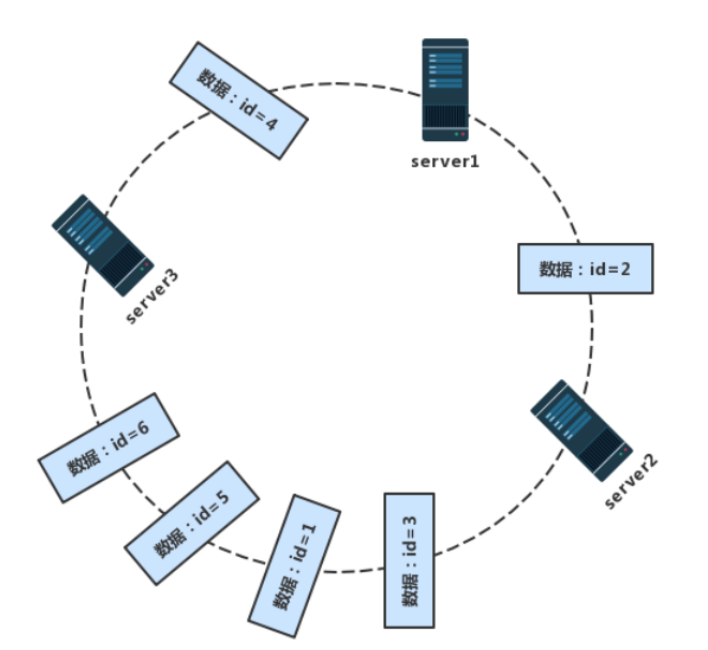
一致性:英语 --> 意思相近的 ,有两个选项意思都差不多 -->选一致性最强的那个。一致性如果也一样,选强度最强的。
第三种:使用虚拟槽分区算法(redis目前正在使用的)
虚拟槽分区是 redis cluster 中默认的数据分布技术,虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,这个整数定义为槽(slot),而且这个槽的个数一般远远的大于节点数。
在 redis cluster 中有16384(0~16383)个槽,会将这些槽平均分配到每个 master 上,在存储数据时利用 CRC16 算法,具体的计算公式为:slot=CRC16(key)% 16384 来计算 key 属于哪个槽。
假如来了一个数据: set name zhangsan
name不是放在服务器上的,是放在槽中的。应该说name放入哪个槽中。
放入哪个槽: slot = CRC16(name)& 16384 = 一个值
假如 name 槽数 10000,这个槽在哪个服务器,不重要,重要的是name 必须在10000这个槽中。数据是跟着槽走的,不是根据服务器走的。
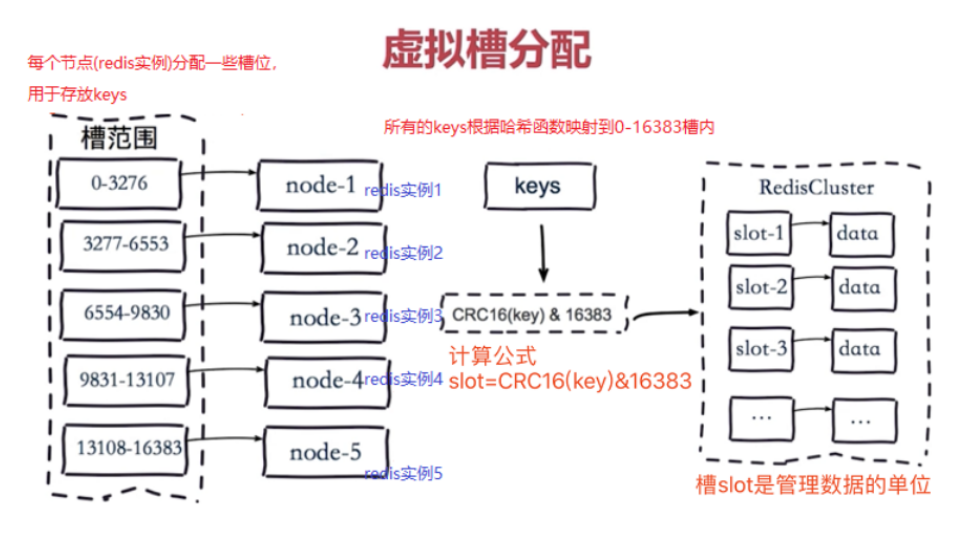
假如使用了槽分区算法,以前有三台服务器,现在追加一台,此时我们这三台服务器上的槽可以分配给第四台服务器一些。数据还在原来的槽中。假如有一天,一个人要想获取数据,只需要计算出来这个数据在哪个槽中就可以成功获取,不需要关心其他的。
假如我想去调一个节点,我可以手动的将这个服务器上的槽分配给别的服务器,在将这个服务器停止运行即可。
3、搭建redis集群
查看所有redis进程:
pgrep -af redis
杀死所有的redis进程
pkill -f redis需要6台服务器:三主三从
第一步,创建文件夹: 在/opt/installs/redis/bin下
mkdir redis_cluster
cd redis_cluster
mkdir 7001 7002 7003 7004 7005 7006第二步:修改配置文件
cp redis.conf redis_cluster/7001
修改7001中的redis.conf 文件
port = 7001
bind 0.0.0.0
daemonize yes
把密码注释掉 # requirepass "123456"
接下来修改集群的配置:
cluster-enabled yes 默认是注释掉的
cluster-config-file nodes-7001.conf
cluster-node-timeout 5000
appendonly yes # 开启了aof持久化功能
修改:为我们的集群专门创建一个文件夹放数据
在 /opt/installs/redis/bin下面
mkdir clusterdata将集群中的每一个redis.conf 再修改一下:
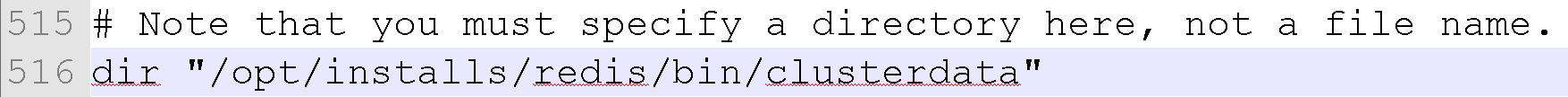
dir "/opt/installs/redis/bin/clusterdata"第三步:将7001中的配置文件,复制到其他文件夹一份
cp redis_cluster/7001/redis.conf redis_cluster/7002
cp redis_cluster/7001/redis.conf redis_cluster/7003
cp redis_cluster/7001/redis.conf redis_cluster/7004
cp redis_cluster/7001/redis.conf redis_cluster/7005
cp redis_cluster/7001/redis.conf redis_cluster/7006第四步:修改各个配置文件的端口号
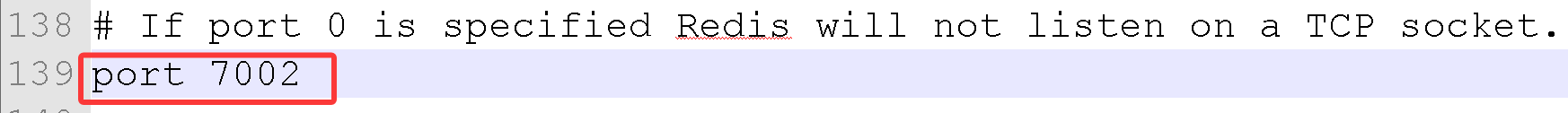

cluster-config-file nodes-7002.conf
port =7002
其他的节点跟这个一样。数字变一下即可。
每个都要改,不要只改7002第五步:启动集群:
redis-server redis_cluster/7001/redis.conf
redis-server redis_cluster/7002/redis.conf
redis-server redis_cluster/7003/redis.conf
redis-server redis_cluster/7004/redis.conf
redis-server redis_cluster/7005/redis.conf
redis-server redis_cluster/7006/redis.conf假如启动报错:

请注释掉每一个 redis.conf 下的
replicaof 192.168.233.128 6380第六步:安装ruby
yum install ruby rubygems -y第七步:安装redis-gem这个工具
需要先下载,上传至 cd /opt/modules/
在这个文件夹下,运行如下命令:
gem install -l redis-3.0.0.gem
第八步:
拷贝redis-trib.rb 到bin目录 在/opt/modules/redis-8.0.1/src 下面
cd /opt/modules/redis-8.0.1/src
cp redis-trib.rb /opt/installs/redis/bin/redis-trib第九步:创建集群的意思
此时的ip不能写为主机名,否则格式化集群失败。
redis5.0 是如下命令:
redis-cli --cluster create 192.168.233.128:7001 192.168.233.128:7002 192.168.233.128:7003 192.168.233.128:7004 192.168.233.128:7005 192.168.233.128:7006 --cluster-replicas 1 -a 123456
假如创建集群的时候出现了权限问题,请使用 -a 密码
[root@bigdata01 src]# redis-trib create --replicas 1 192.168.233.128:7001 192.168.233.128:7002 192.168.233.128:7003 192.168.233.128:7004 192.168.233.128:7005 192.168.233.128:7006
WARNING: redis-trib.rb is not longer available!
You should use redis-cli instead.
All commands and features belonging to redis-trib.rb have been moved
to redis-cli.
In order to use them you should call redis-cli with the --cluster
option followed by the subcommand name, arguments and options.
Use the following syntax:
redis-cli --cluster SUBCOMMAND [ARGUMENTS] [OPTIONS]
Example:
redis-cli --cluster create 192.168.233.128:7001 192.168.233.128:7002 192.168.233.128:7003 192.168.233.128:7004 192.168.233.128:7005 192.168.233.128:7006 --cluster-replicas 1
To get help about all subcommands, type:
redis-cli --cluster help看到如下的提示,输入yes:
Can I set the above configuration? (type 'yes' to accept): yes
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered. 构建成功
第十步:进入集群,查看状态是否正常:
redis-cli -c -h bigdata01 -p 7001 -a 123456
连接集群,需要添加 -c
进入集群查看集群状态
bigdata01:7001> cluster nodes
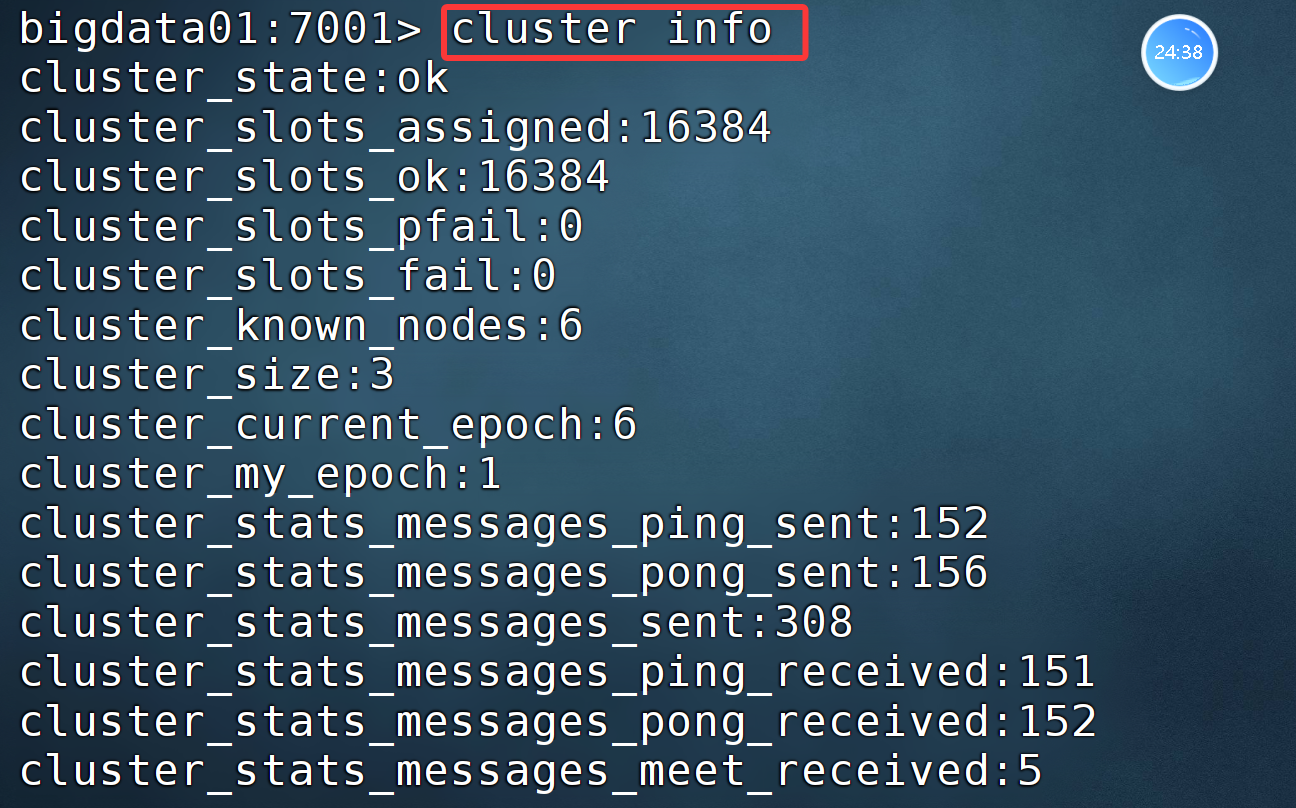
boigdata01:7001> cluster info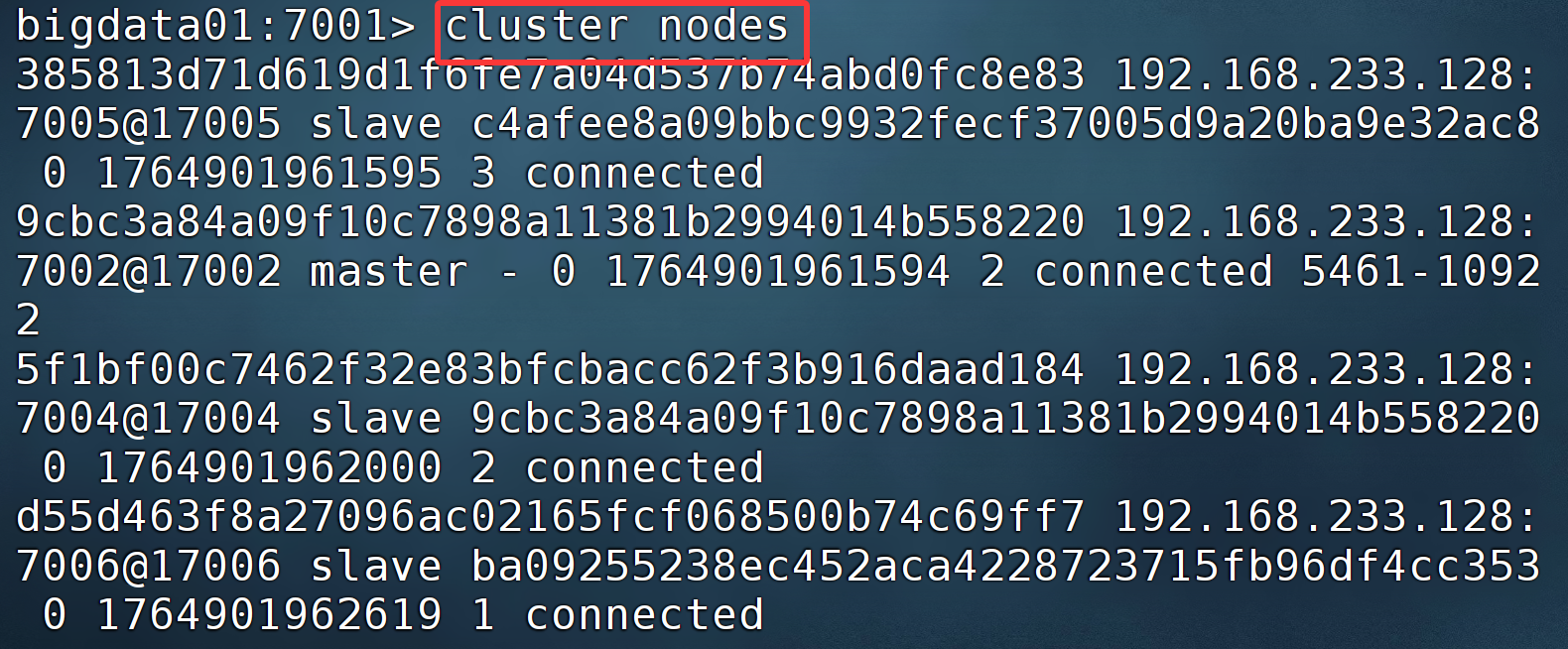
/usr/local/share/gems/gems/redis-3.0.0/lib/redis/client.rb:79:in `call': ERR Slot 0 is already busy (Redis::CommandError)
from /usr/local/share/gems/gems/redis-3.0.0/lib/redis.rb:2190:in `block in method_missing'
from /usr/local/share/gems/gems/redis-3.0.0/lib/redis.rb:36:in `block in synchronize'
from /usr/share/ruby/monitor.rb:211:in `mon_synchronize'
from /usr/local/share/gems/gems/redis-3.0.0/lib/redis.rb:36:in `synchronize'
假如第一次集群创建失败,第二次会报以上错误,可以通过如下方式清理一下:
由于我们这个主节点在 7001 7002 7003
redis-cli -h bigdata01 -p 7001
连接上之后输入:
flushall
cluster reset
接着连接7002 7003 重复以上操作,操作完之后再格式化数据即可连接集群的命令是:
redis-cli -c -h bigdata01 -p 7001 -a 123456
在输入数据的时候,会根据key值不同,来回切换。 -c 的意思是连接集群
集群的关闭:
pkill -ef redis
启动:
只需要把6个服务,一个个启动,集群即可使用4、使用jedis操作redis集群
java
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import redis.clients.jedis.*;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class TestDemo03 {
JedisCluster jedisCluster;
@Before
public void init(){
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
// idle 空闲的 最大空闲
poolConfig.setMaxIdle(200);
// 最大的连接数量
poolConfig.setMaxTotal(1000);
// 最小空闲
poolConfig.setMinIdle(5);
HashSet<HostAndPort> set = new HashSet<HostAndPort>();
set.add(new HostAndPort("bigdata01",7001));
set.add(new HostAndPort("bigdata01",7002));
set.add(new HostAndPort("bigdata01",7003));
/**
connectionTimeout: 100 含义:建立 TCP 连接的超时时间 单位:毫秒(ms)默认值:通常 2000ms
soTimeout: 100 含义:Socket 读取超时(操作超时)单位:毫秒(ms)默认值:通常 2000ms
maxAttempts: 100 含义:命令执行失败后的最大重试次数
**/
jedisCluster = new JedisCluster(set,2000,2000,3,"123456", poolConfig);
}
@After
public void destory() {
jedisCluster.close();
}
@Test
public void testConnect(){
jedisCluster.set("subject","大数据");
}
}