一、概念
本质上是一个分布式消息中间件,用于构建实时数据管道和处理流式数据,横向扩展、容错、快速
1、作用
在实时数据生产、消费过程中起缓冲作用
(1)提供流发布、订阅功能
(2)数据容错
(3)流产生时即处理
2、存储结构
topic:主题,区分不同业务类型的流式数据
record:单条数据由key、value、timestamp构成
partition:分区,parition内数据有序(按照消息写入顺序给每个消息赋予一个递增的offset),partition间数据无序
每个分区可以有多个副本,分散在不同的broker上。
- leader副本:被KafkaController选举出来的,作为该分区的leader,producer只对leader副本发送消息,consumer只从leader副本获得消息
- 其他follower副本:其他副本都作为follower副本,只从leader副本复制数据
- isr列表:简单描述就是,"跟得上"leader的副本列表(包含leader),最开始是所有副本。这里的跟得上是指
- replica.lag.time.max.ms:在0.9.0.0之前表示follower如果在此时间间隔内没有向leader发送fetch请求,则该follower就会被剔除isr列表,在0.9.0.0之后表示如果该follower在此时间间隔内一直没有追上过leader的所有消息,则该follower就会被剔除isr列表
- replica.lag.max.messages(0.9.0.0版本中已被废除):follower如果落后leader的消息个数超过该值,则该follower就会被剔除isr列表
- 废除的主要原因是:目前这个配置是个统一配置,不同的topic速率生产速率不太一样,没办法来指定一个具体的值来应用到所有的topic上。将来可以将这个配置下放到topic级别,关于这个问题,可以见这里的讨论Automate replica lag tuning
- min.insync.replicas:最少需要存活的副本数,默认是1。当acks=-1的时候,leader在处理新消息前,会先判断当前isr列表的的size是否小于这个值,如果小于的话,则不允许写入,返回NotEnoughReplicasException异常。同时,一旦允许写入了之后,在响应producer之前也会判断当前isr列表的size是否小于该值,如果小于返回NotEnoughReplicasAfterAppendException异常
(1)每个partition对应一个目录,目录名:topic名-有序序号(序号从0开始,若有3个partition,则依次是0、1、2)
每个partiton目录内有多个segment段文件,文件生命周期由配置决定
第一个segment的offset是0,后续每个segment文件名是前一个segment最后一条消息的offset值。20位数字,用0左填充
索引文件存储大量元数据,数据文件存储大量消息。索引文件中元数据指向对应数据文件中消息的物理偏移地址
下图 3,497表示此segment第3条消息在497偏移地址

(2)速度快的原因
- 磁盘顺序存取,性能很高,规避了磁盘随机读取效率低的问题,发挥了磁盘容量大的优势。因为每个partition可以看做文件,追加写入文件是顺序的
- MMAP内存映射技术,把文件映射到内存,提升读写效率,可配置producer.type是否在写入内存映射区后等待flush
- 零拷贝,所有的数据读写都在内核态通过DMA完成,不需要等待cpu,也不需要把数据在内核态和用户态间来回拷贝
- 数据批量处理,即使用户只需要一条,也把那条数据所在文件发过去,而且发送文件也方便进行压缩,能产生很高的吞吐量
二、架构
1、producer:生产者
request.required.acks
- acks=0:表示producer不需要leader发送响应,即producer只管发不管发送成功与否。延迟低,容易丢失数据。
- acks=1:表示leader写入成功(但是并没有刷新到磁盘)后即向producer响应。延迟中等,一旦leader副本挂了,就会丢失数据。
- acks=-1:表示leader会等待isr列表中所有副本都写入成功才向producer发送响应。延迟高、可靠性高。但是也会丢数据
leader副本的属性
- highWatermarkMetadata:代表已经被isr列表复制的最大offset,consumer只能消费该offset之前的数据
- logEndOffsetMetadata:代表leader副本上已经复制的最大offset
- 其他副本的记录,保存着他们的如下属性:
- lastCaughtUpTimeMs:记录该follower副本上一次追上leader副本的所有消息的时间
- logEndOffsetMetadata:代表该follower副本已经复制的最大offset
follower副本的属性
- highWatermarkMetadata:follower会获取到leader的highWatermarkMetadata更新到自己的该属性中
- logEndOffsetMetadata:代表follower副本上已经复制的最大offset
- 其中follower会不断的向leader发送fetch请求,如果没有数据fetch则被leader阻塞一段时间,等待新数据的来临,一旦来临则解除阻塞,复制数据给follower。
2、consumer:消费者
一个partition只能同时被不同group内的某个consumer消费
即当有N个consumer group,一个partition可以被N个consumer消费(但这N个分别在不同的group里,注意不是同时,从而不会出现重复消费的情况)
0.10开始偏移量直接从kakfa的__consumer_offsets取,不需要从zookeeper取
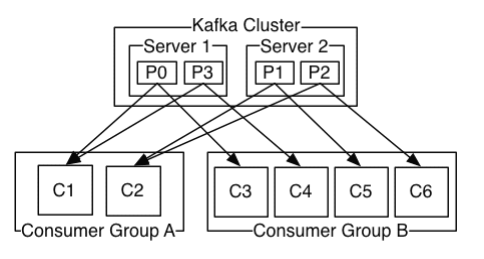
3、Consumer Group:消费组
一个topic可对应多个CG,topic可以提供相同消息给多个CG,但在一个CG内,每个partition只能发送消息给一个consumer
实现广播(topic消息发送给所有consumer):每个consumer单独一个CG
实现单播(topic消息发送给任一个consumer):所有的consumer在同一个CG
4、broker
所有broker会通过ZooKeeper选举出一个作为KafkaController,来负责:
- 监控所有broker的存活,以及向他们发送相关的执行命令。
- 分区的状态维护:负责分区的新增、下线等,分区副本的leader选举
- 副本的状态维护:负责副本的新增、下线等
5、leader副本选举
若某个broker挂了,leader副本在该节点上的分区就要进行重新选举。KafkaController会监听zk的/brokers/ids节点路径,一旦发现有broker挂了,执行如下逻辑(当KafkaController挂了时,各个broker会先重新选出新的KafkaController再进行leader副本选举)
(1)leader副本在该broker上的分区都要重新进行leader选举
- 优先从isr列表中选出第一个作为leader副本;如果isr列表为空,则查看该topic的unclean.leader.election.enable,若为true则允许非isr列表的副本作为leader,也意味着数据可能丢失,若为false则直接抛出NoReplicaOnlineException,leader副本选举失败
(2)一旦选举成功,则将选举后的leader和isr和其他副本信息写入到该分区的对应的zk路径上
(3)KafkaController向上述相关的broker上发送LeaderAndIsr请求,将新分配的leader、isr、全部副本等信息传给他们。同时将向所有的broker发送UpdateMetadata请求,更新每个broker的缓存的metadata数据
(4)如果是leader副本,更新该分区的leader、isr、所有副本等信息。如果自己之前就是leader,则现在什么操作都不用做。如果之前不是leader,则需将自己保存的所有follower副本的LE设置为UnknownOffsetMetadata,之后等待follower的fetch,就会进行更新
(5)如果是follower副本,更新该分区的leader、isr、所有副本等信息,然后将日志截断到自己保存的HW位置,即日志的LE等于了HW(若HW此时未及时更新即HW小于LE,而截断后LE等于HW即变小,相当于没同步成功,需要重新从leader同步,若此时新leader也挂了数据自然就丢失了)。最后创建新的fetch请求线程,向新leader不断发送fetch请求,初次fetch的offset是LE
6、消息完整性
即使当acks=-1,unclean.leader.election.enable=false也会出现数据丢失的情况
原因:一种比较简单的情况是isr列表为空导致leader副本选举失败,数据自然就丢失了;另一种情况是即使选举成功,发生极端情况时也会丢失数据,由于follower的highWatermarkMetadata相对于leader的highWatermarkMetadata是延迟更新的,当leader选举完成后,所有follower副本的LogEndOffsetMetadata都截断到自己的highWatermarkMetadata位置,则可能截断了已被老leader提交了的日志,这样的话,这部分日志仅仅存在新的leader副本中,在其他副本中消失了,一旦leader副本挂了,这部分日志就彻底丢失了
7、消息顺序性
(1)需满足如下条件:
- 生产者按照消息的顺序进行发送
不能使用多线程方式发送,为了效率,通常采用单线程异步发送的方式,此时还需要配置:max.in.flight.requests.per.connection=1(producer发现一旦还有未确认发送成功的消息,后面的消息不允许发送),即生产者异步把消息放到队列,但队列得确认前面消息发送成功后再发送后面的
- 存储端
- 相同key的消息能hash到相同的分区。kafka原生支持,但要设定合适的key(适用于只要求局部有序的场景,如某用户最后一笔订单)
- 一个topic只有一个partition,且只能同步复制(适用于全局有序)
- 消费者按照消息的顺序进行消费
只能使用单线程来保证
(2)实际使用
实现严格的全局有序性,会极大影响效率
所以要从业务角度分析:
- 对于顺序不敏感场景,则不保证顺序
- 对于只要求局部有序场景,只要将相同key的数据发送到同一个partition即可
- 对于要求全局有序场景,只能满足上述要求,单线程异步生产、单partition同步复制、单线程消费
三、常用命令
1、启动
kafka-server-start.sh -daemon config/server.properties
2、创建topic
kafka-topics.sh --create --zookeeper spark:2181 --replication-factor 3 --partitions 3 --topic test
3、查看topic
kafka-topics.sh --describe --zookeeper spark:2181 --topic test
Isr 存活的broker id
Leader 主副本所在的broker id
4、列出所有的topic
kafka-topics.sh --list --zookeeper spark:2181
5、模拟消息生产者
kafka-console-producer.sh --broker-list spark:9092 --topic test
6、模拟消息消费者
--低版本
kafka-console-consumer.sh --zookeeper spark:2181 --topic test --from-beginning
--高版本直接从kafka取偏移量,不用经过zk
kafka-console-consumer.sh --bootstrap-server spark:9092 --topic test --from-beginning
|---------------------------|---------|--------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------|
| 参数 | 值类型 | 说明 | 有效值 |
| --topic | string | 被消费的topic | |
| --whitelist | string | 正则表达式,指定要包含以供使用的主题的白名单 | |
| --partition | integer | 指定分区 除非指定'--offset',否则从分区结束(latest)开始消费 | |
| --offset | string | 执行消费的起始offset位置 默认值:latest | latest earliest |
| --consumer-property | string | 将用户定义的属性以key=value的形式传递给使用者 | |
| --consumer.config | string | 消费者配置属性文件 请注意,consumer-property优先于此配置 | |
| --formatter | string | 用于格式化kafka消息以供显示的类的名称 默认值:kafka.tools.DefaultMessageFormatter | kafka.tools.DefaultMessageFormatter kafka.tools.LoggingMessageFormatter kafka.tools.NoOpMessageFormatter kafka.tools.ChecksumMessageFormatter |
| --property | string | 初始化消息格式化程序的属性 | print.timestamp=true|false print.key=true|false print.value=true|false key.separator= line.separator= key.deserializer= value.deserializer= |
| --from-beginning | | 从存在的最早消息开始,而不是从最新消息开始 | |
| --max-messages | integer | 消费的最大数据量,若不指定,则持续消费下去 | |
| --timeout-ms | integer | 在指定时间间隔内没有消息可用时退出 | |
| --skip-message-on-error | | 如果处理消息时出错,请跳过它而不是暂停 | |
| --bootstrap-server | string | 必需 (除非使用旧版本的消费者),要连接的服务器 | |
| --key-deserializer | string | | |
| --value-deserializer | string | | |
| --enable-systest-events | | 除记录消费的消息外,还记录消费者的生命周期 (用于系统测试) | |
| --isolation-level | string | 设置为read_committed以过滤掉未提交的事务性消息 设置为read_uncommitted以读取所有消息 默认值:read_uncommitted | |
| --group | string | 指定消费者所属组的ID | |
| --blacklist | string | 要从消费中排除的主题黑名单 | |
| --csv-reporter-enabled | | 如果设置,将启用csv metrics报告器 | |
| --delete-consumer-offsets | | 如果指定,则启动时删除zookeeper中的消费者信息 | |
| --metrics-dir | string | 输出csv度量值 需与csv-reporter-enable配合使用 | |
| --zookeeper | string | 必需 (仅当使用旧的使用者时)连接zookeeper的字符串。 可以给出多个URL以允许故障转移 | |
| --message.timestamp.type | | 定义消息中的时间戳是消息创建时间还是日志附加时间。默认是"CreateTime"或"LogAppendTime" | CreateTime LogAppendTime |
7、关闭
kafka-server-stop.sh config/server.properties
8、topic设定partition数
kafka-topics.sh --alter --topic test --zookeeper spark:2181 --partitions 3
9、查看offset
kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list spark:9092 --topic test
kafka-run-class kafka.tools.ConsumerOffsetChecker --zookeeper hostname:2181 --group group123 --topic test
10、删除topic
kafka-topics.sh --zookeeper my:2181 --delete --topic test
11、修改topic
kafka-topics --zookeeper my:2181 --alter --topic test --partitions 4
12、查看消费组
kafka-consumer-groups --bootstrap-server hostname:9092 --list
kafka-consumer-groups --bootstrap-server hostname:9092 --describe --group test-group1
四、API使用
1、生产者
Properties properties = new Properties();
properties.put("metadata.broker.list","spark:9092");
properties.put("serializer.class","kafka.serializer.StringEncoder");
properties.put("request.required.acks","1");
Producer producer = new Producer(new ProducerConfig(properties));
producer.send(new KeyedMessage(topic, message));2、消费者
Properties properties = new Properties();
properties.put("zookeeper.connect","spark:2181");
properties.put("group.id","test_group");
ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
Map topicCountMap = new HashMap<>();
topicCountMap.put(topic, 1);
//String: topic名, List:数据流
Map> > messageStream = consumer.createMessageStreams(topicCountMap);
KafkaStream stream = messageStream.get(topic).get(0); //获取收到的topic数据流
ConsumerIterator iterator = stream.iterator();
while(iterator.hasNext()){
String message = new String(iterator.next().message());
System.out.println("recv: "+message);
}