写在前面
Go的GMP我们很熟悉了,计算密集型和io密集型我们也很熟悉了,但 Go 的GMP在计算密集型和io密集型上有什么区别呢? 这篇文章我们就来探讨一下!
当然这也只是我自己的理解,如果你有不同的理解,可以评论区留言!
GMP
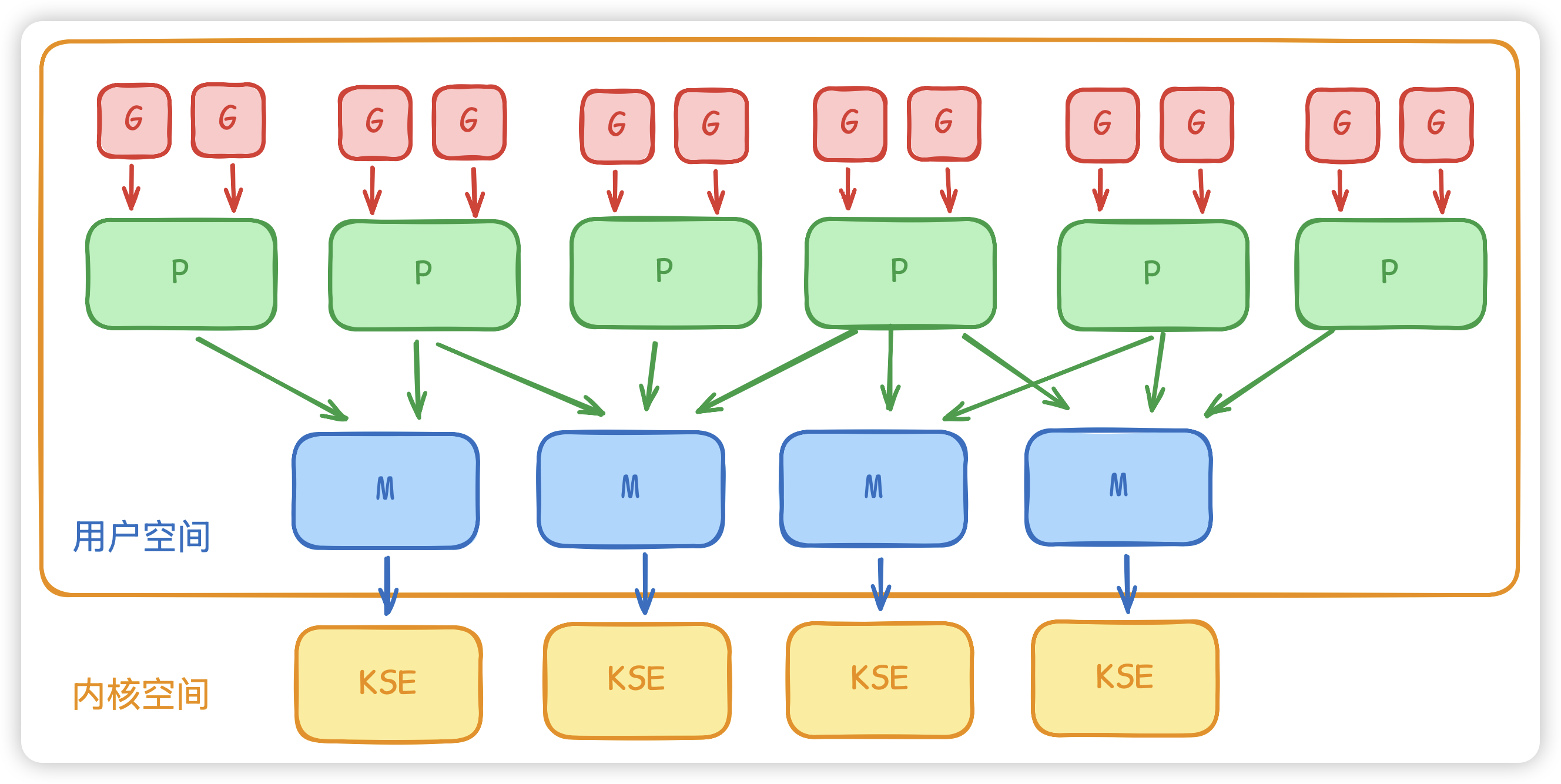
- G(Goroutine):
用户级轻量线程(协程),包含栈、状态、入口函数等,创建和切换成本很低,默认栈按需伸缩。 - M(Machine):绑定到操作系统线程的运行实体,
真正在CPU上执行代码。 - P(Processor):逻辑处理器,承载调度资源(本地运行队列、定时器等),控制并行度 ,上限为
GOMAXPROCS。
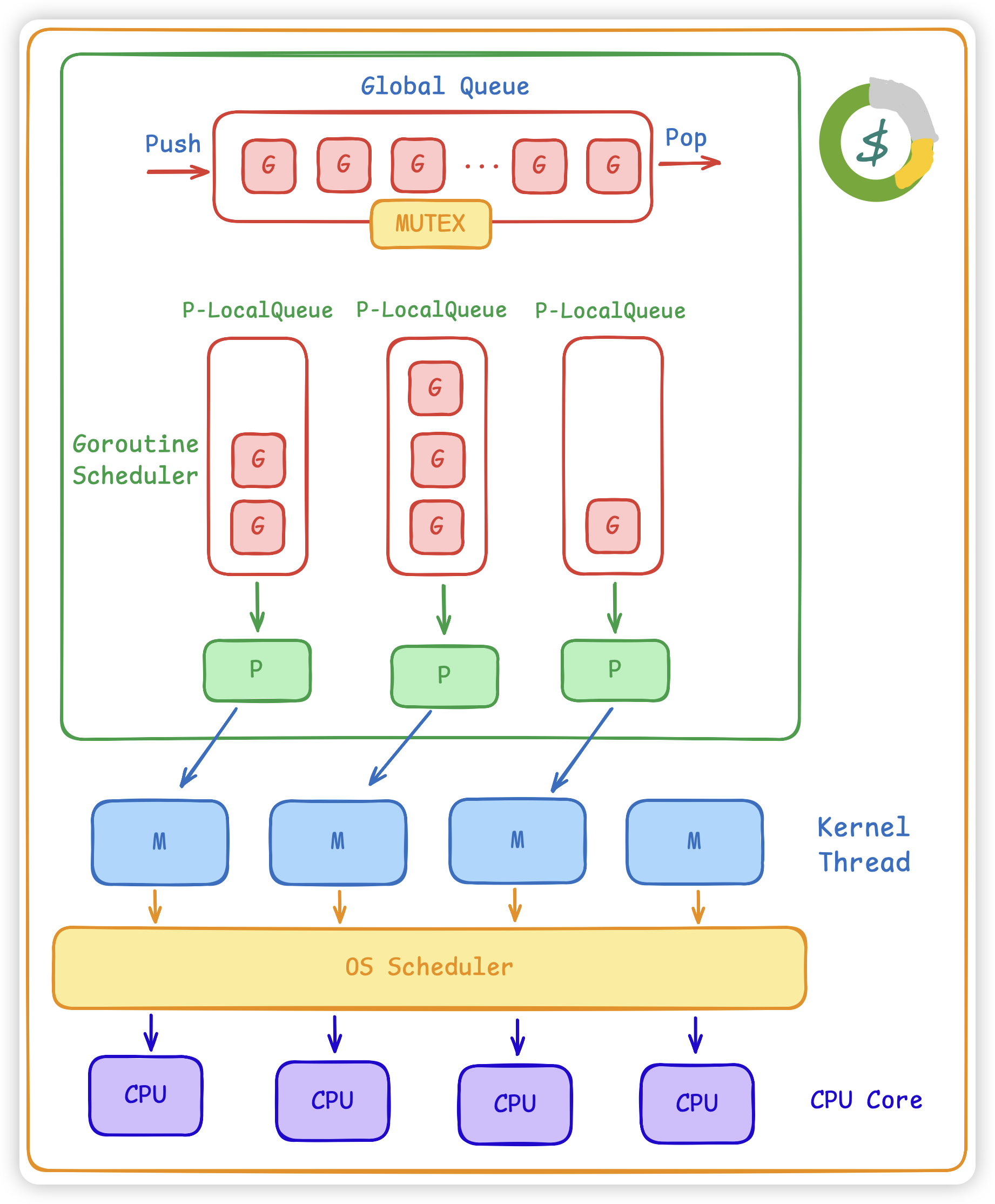
调度模型:
- 本地队列优先:每个 P 有自己运行的本地队列,调度时优先从本地取就绪 G 。
- 全局队列兜底:部分新就绪 G 放入全局队列,
P 本地队列空时尝试取全局任务。 - Work Stealing:
本地无任务时,从随机其他 P 的队列尾部偷一半任务,均衡负载。 - 自旋与休眠:没有可运行 G 时, M 可短暂自旋寻找任务,找不到则休眠以节省资源。
io密集型
大部分时间在等待外部资源(磁盘、网络、数据库)响应,CPU常处于空闲或低占用。
- CPU使用率
低、iowait 高(Linux vmstat / iostat )、会存在大量阻塞/超时日志 - 线程/连接数多、吞吐受外部系统 RT 影响
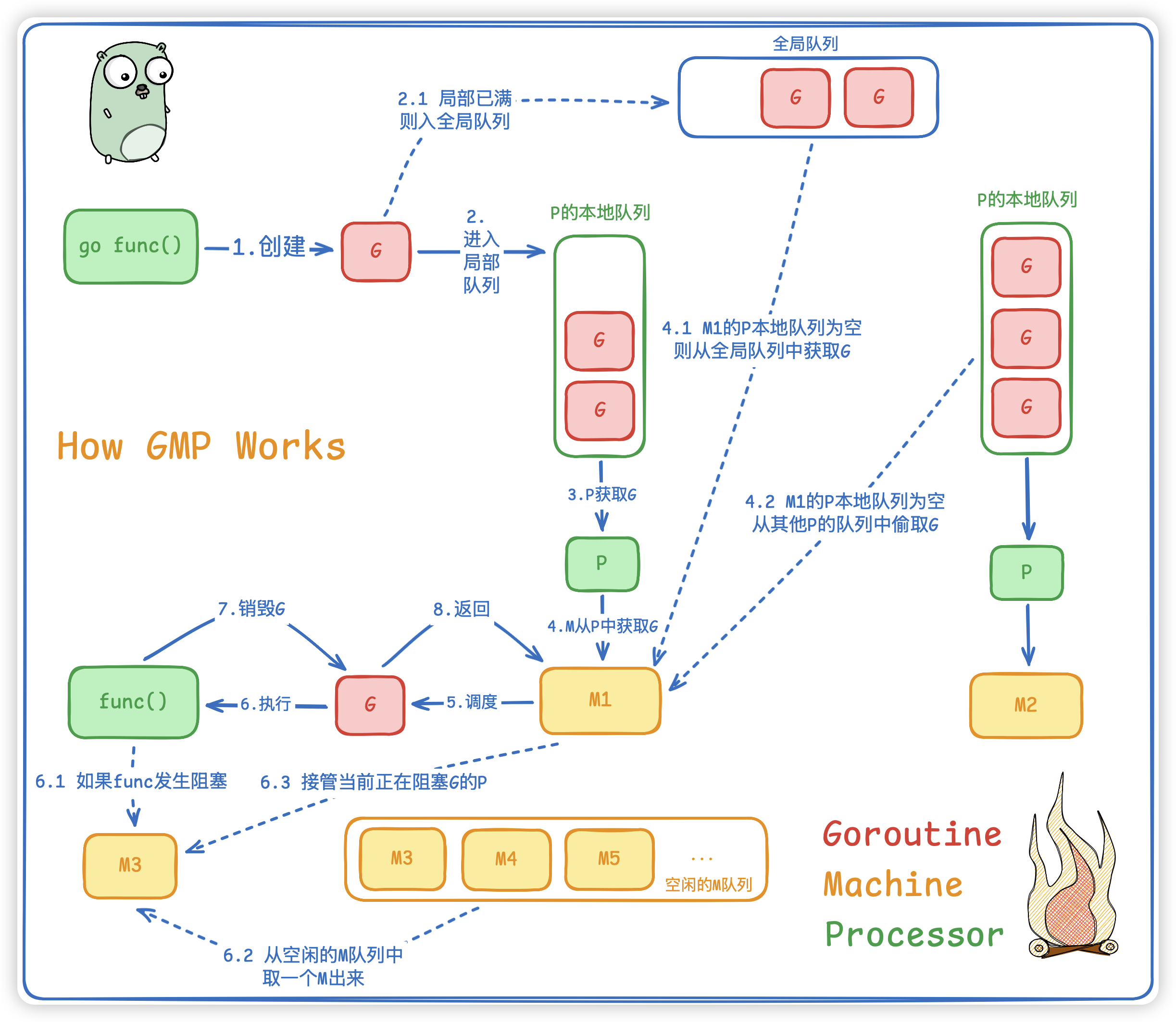
在IO密集型系统中,我们假设每一个G都是请求外部资源,比如RPC、Redis、DB等等... 当我们代码执行一次网络请求 (如http.Get) 时,GMP发生以下事情:
- G (Goroutine): 执行到网络读取操作,发现
数据未就绪。 - G->Netpoller: G将自己
注册到基于epoll的网络轮询器的Netpoller中,状态变为waiting并与M分离。 - M (Machine): M不会阻塞,会立刻通过 P 获取本地队列中的
下一个G继续执行。 - Netpoller->P: 当网络数据到达,Netpoller检测到事件,将之前的G状态改为
running,并将其注入到全局队列或某个P的本地队列。 - P (Processor): 在后续调度中,
P再次拿到这个G,M继续执行之前的上下文。
⚠️ 注意点:M始终在工作,没有空闲。
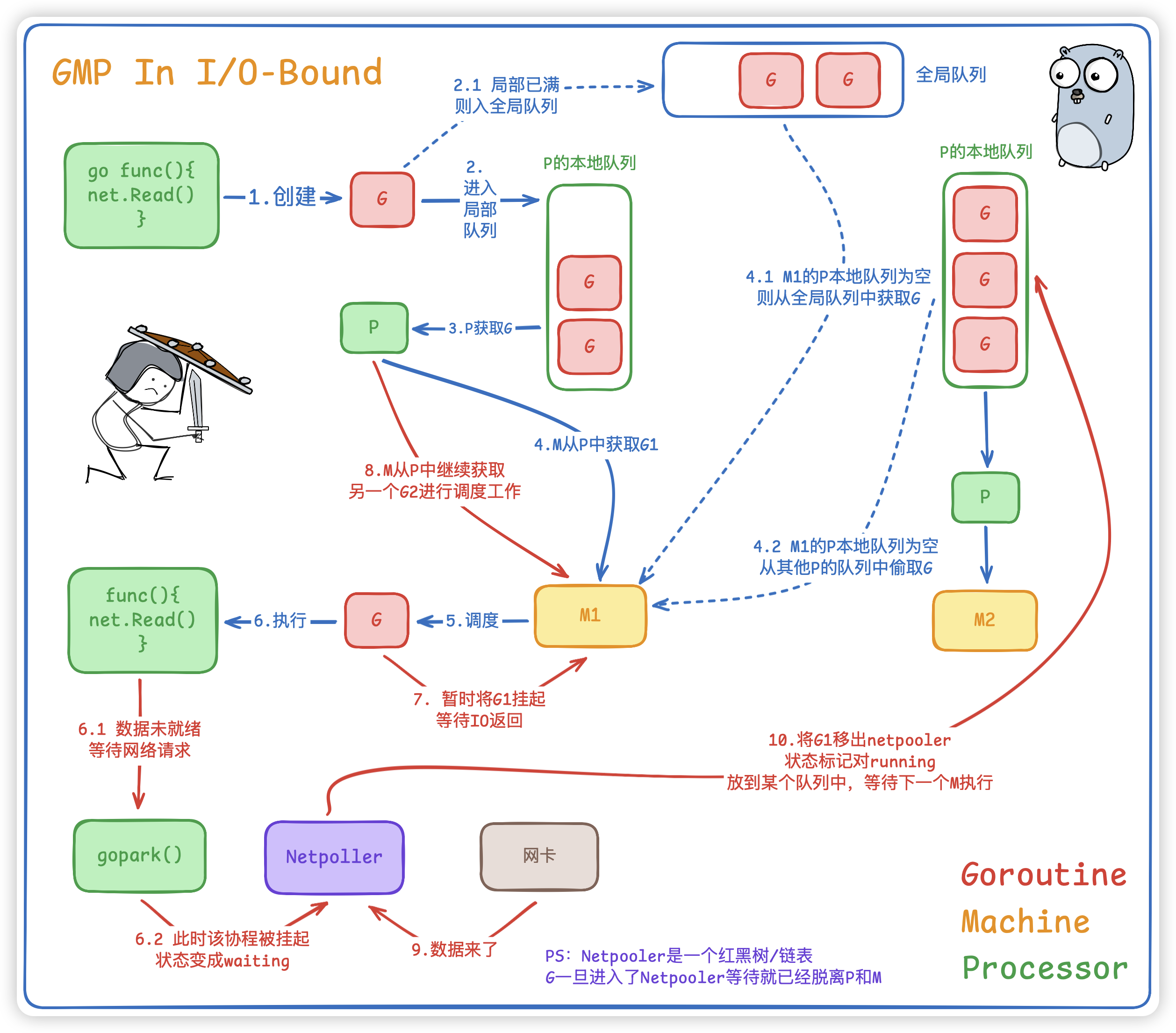
所以对于IO密集型系统,GMP 通过挂起当前在等待数据的G,可以使得M能处理其他的G,利用等待时间,把有限的 CPU 放大成海量的并发处理能力,拆分协程收益巨大,达到四两拨千斤的效果。
计算密集型
大部分时间在执行CPU计算(算法、编码/解码、加密、ML推理),CPU长期接近满载。
- CPU使用率
高、负载 ≈ CPU核心数或更高 - 性能对算法复杂度、指令效率、缓存命中率敏感(perf 、 pprof 显示大量CPU占用)
当我们代码执行一个死循环计算或复杂哈希时,GMP的工作就会是这样:
- G(Goroutine): 在 M 上
疯狂消耗 CPU 周期。 - P(Processor): P 的本地队列里可能还有其他 G 在排队。
- Preemption(抢占): Go 的后台监控线程
sysmon发现某个 G 运行超过 10ms,会发出抢占信号。 - G->Global Queue: G 检测到抢占信号,保存上下文,主动让出 CPU,回到
全局队列队尾等待。
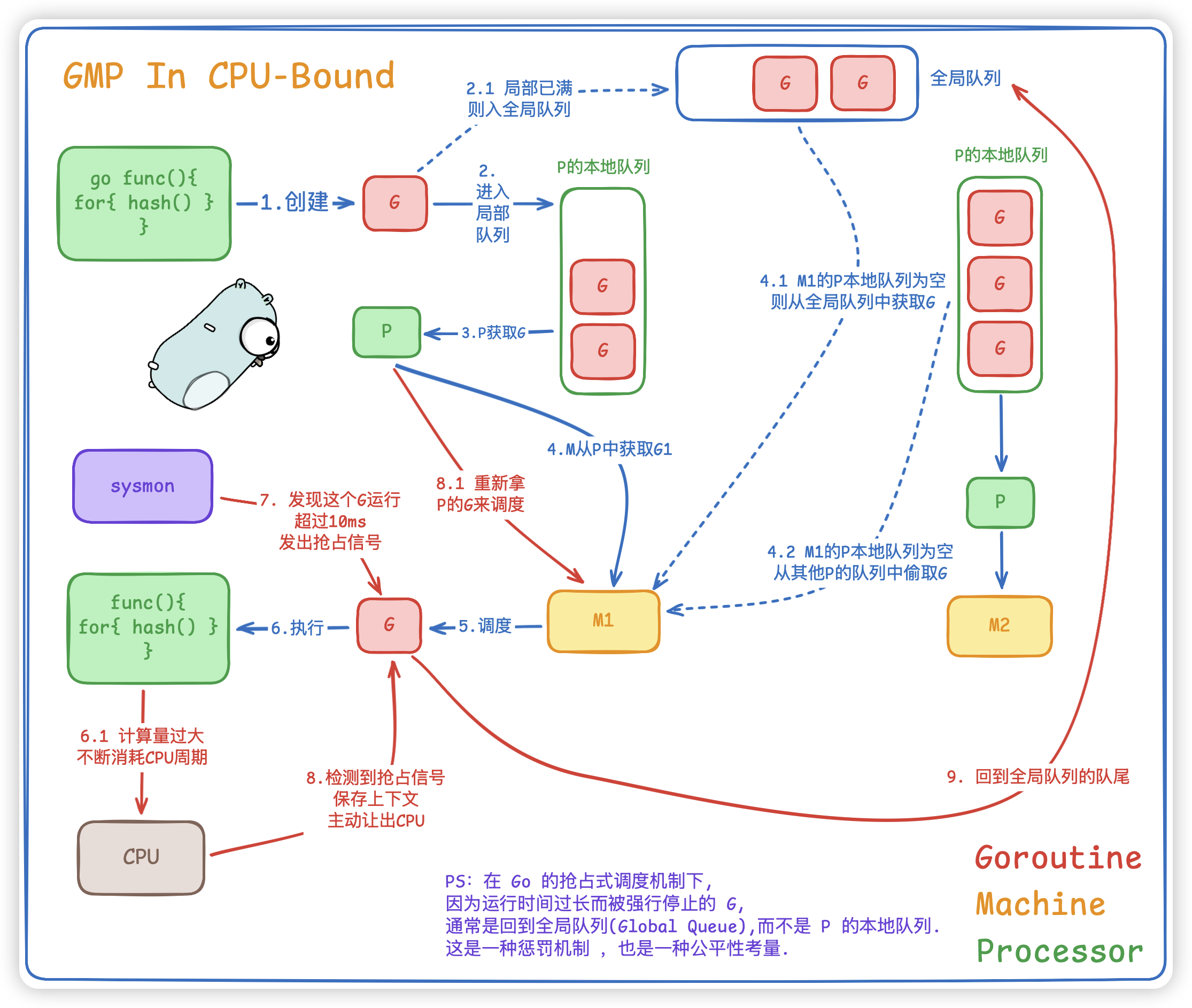
- 为什么拆分成多个协程"没有那么高并发"?
在计算密集型场景下,所谓的高并发其实是假象。
- 真并发 (Parallelism) :同一时刻真的有多个任务在物理CPU上跑,上限就是CPU核数(GOMAXPROCS)。
- 假并发 (Concurrency) :
任务在快速切换,宏观上看好像都在跑,微观上同一时刻只有几个在跑。
对于计算密集型,开一万个G,真正的并行度依然卡死在CPU核数上。反而因为过度的切换(Context Switch)和CPU缓存失效(Cache Miss),导致整体效率不如只开8个G。
所以系统CPU 算力就那么大,在计算密集型系统中,协程越多,调度损耗越多,拆分协程的目的是为了不让某一个协程独占CPU,所以在做计算密集型任务的时候不要滥用 go func() ,最好是 协程数 ≈ CPU 核数 。