【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 单/多线程分析(七)
分析了如果 Python 给每个对象单独加锁的代价,下面继续
Python http.server 单/多线程分析
上篇 blog 分析了,Python 作为解释型语言,操作频繁(一条语义简单的语句,在 CPython 解释器眼中叫字节码,背后可能包含数十,甚至上百条 C 指令),频繁地加解锁也会导致性能严重下降
此外,还有另一个角度,对象模型来看,Python 对象是高度动态的:
- 任何对象都可能被任意线程修改
- 属性可以随时添加或者删除
__setattr__,__getattribute__等对象属性访问方法,也可能触发任意代码(用户可以重写这些方法,在里面加入自己的逻辑)
因此无法像 C 那样知道什么时候可以批量加锁来做优化 ,如果给每个对象加锁,就必须在每一次属性访问,方法调用,容器修改时加锁,因为解释器无法静态推断这段代码是否线程安全
而在 C 语言中,首先数据结构是静态的(内存布局在编译期就可以确定),程序员明确知道哪些数据是共享的,锁的粒度由程序员控制(粒度一般大于字段,对某个过程上锁)
所以综合两个特点操作频繁 + 无法优化 ,一个 Python 进程想要在底层 CPython 解释器做到能并行执行的效果很难,性能会受到严重影响 ,而且大多数情况下,用户根本不用多线程,单线程才是常见情况,所以 GIL 锁就够了(处理 IO 密集型任务)
https://docs.python.org/3/library/threading.html
在 Python 中,threading 实现的是并发(通过 OS 线程切换,配合 GIL 锁占用释放),其另外一个功能 multiprocessing 可以实现并行(让多个进程跑在不同核心)
OK,这里引出 Python 另一个功能,多进程 multiprocessing

multiprocessing 可以绕过 GIL 锁,这是它与 threading 最根本的区别之一,multiprocessing 会创建独立的进程,每个子进程都有:Python 解释器实例,独立的内存空间,独立的 GIL ,因此多个 Python 进程可以真正并行运行在多个 CPU 核心上,彼此不受 GIL 限制
OK,既然 Python 其实是支持使用 CPU 多核心的,那么能不能通过这种方法来实现 http.server 的高并发呢?理论上可以,但实际上没必要
首先,用 multiprocessing 可以启动多个 http.server 实例,但不能让它们都监听同一个端口,因为操作系统不允许两个或多个进程同时监听同一个端口,这是操作系统层面的限制:
- 当 Python 程序调用
socket.bind(('', 2025)),内核会将(ip,port)标记为已被占用 - 此时第二个进程如果也尝试绑定同一个
(ip,port)时,会收到错误码OSError: [Errno 98] Address already in use
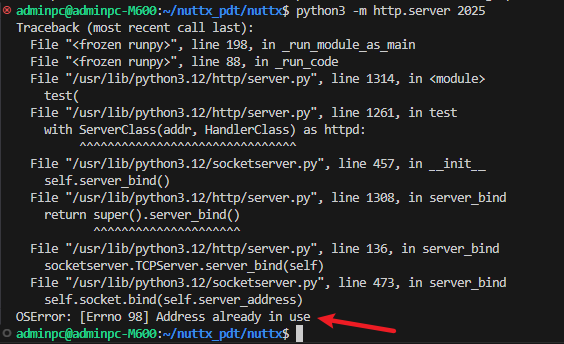
这是为了避免数据包不知道该交给哪个进程处理,注意,这不是 Python 的限制,而是 TCP/IP 协议栈的设计
那么此时还是得配合前端 Nginx 反向代理,比如后端启用多个实例
bash
python server.py 2025 &
python server.py 2026 &
python server.py 2027 &然后前端 Nginx 监听端口 2024 ,用户访问 Web 服务器的 2024 端口,Nginx 再通过负载均衡,将流量通过端口(2025,2026,2027)路由到后端的 Python 进程
→ Python 进程 A (:8001)
→ Python 进程 B (:8002)
→ Python 进程 C (:8003)
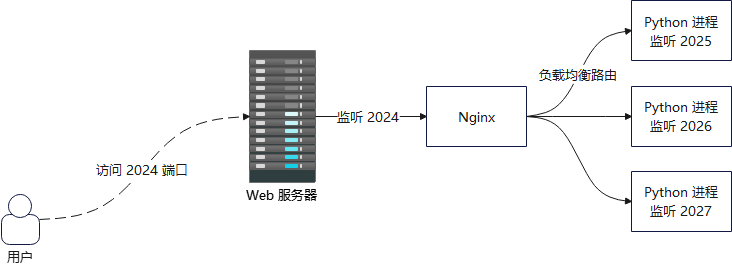
可以看到,即使启动了多进程,最后还是逃不过 Nginx
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:Gitlab 配置审视(一)