锋哥原创的Transformer 大语言模型(LLM)基石视频教程:
https://www.bilibili.com/video/BV1X92pBqEhV
课程介绍

本课程主要讲解Transformer简介,Transformer架构介绍,Transformer架构详解,包括输入层,位置编码,多头注意力机制,前馈神经网络,编码器层,解码器层,输出层,以及Transformer Pytorch2内置实现,Transformer基于PyTorch2手写实现等知识。
Transformer 大语言模型(LLM)基石 - Transformer架构详解 - 输入嵌入层(Input Embeddings)详解以及算法实现
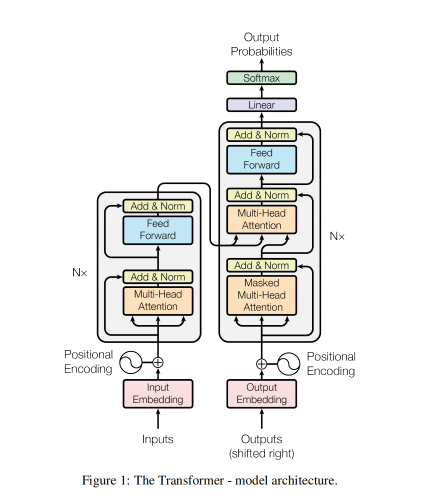
前面我们说过输入嵌入层的作用是将原始的词语表示(通常是单词或子词)转换为高维的密集向量。每个单词或子词通过词嵌入(Embedding)转化为向量,模型之后将处理这些向量。
-
功能:将输入的离散单词映射为连续的高维空间向量,便于后续的处理。
-
结构:该层的输出是一个序列的嵌入矩阵,矩阵的维度为batch_size, seq_len, embedding_dim。
比如我们有一组数据集:

仅仅包含三个句子

N 表示总数,最后的结果是去重之后的词汇量
注意点:这里举例比较简单,是英文,我们直接空格分词就行。如果是中文的话,我们一般用jieba分词。分词结果去重后,就是总的词汇量。
如何将这些词在计算机中表示,以及进行运算。
我们这里介绍先对词进行编码,然后向量化。
首先是Encoding 编码

为每个单独的单词分配一个唯一的数字。
然后就是计算 Embeding
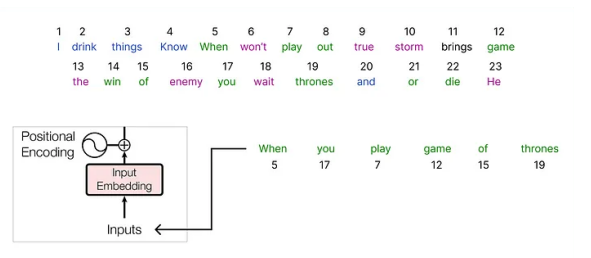
然后我们设计好每个词的词嵌入维度,比如是6,相当于每个词有6个特征。
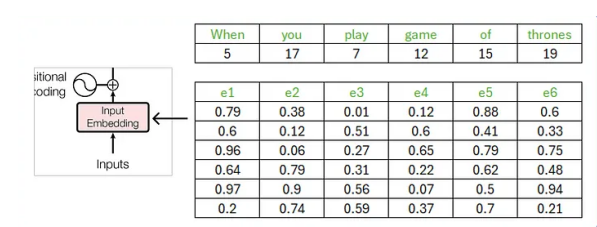
原始论文使用 512 维向量,这里使用嵌入向量的维度为 6,上面是原始数据,下面是解析之后的数据。
我们新建一个Python项目,终端安装下PyTorch
pip install torch==2.9.1 torchvision==0.24.1 -i https://pypi.tuna.tsinghua.edu.cn/simple代码实现:
import math
import torch
from torch import nn
# 输入嵌入层类
class Embeddings(nn.Module):
def __init__(self, vocab_size, embedding_dim): # vocab_size:词表大小 embedding_dim:词嵌入维度的大小
super().__init__()
self.embedding_dim = embedding_dim
self.embedding = nn.Embedding(vocab_size, embedding_dim)
def forward(self, x):
embed = self.embedding(x)
# 缩放词嵌入(原始Transformer论文中的关键细节) 防止向量初始值过大,稳定训练
return embed * math.sqrt(self.embedding_dim)
if __name__ == '__main__':
vocab_size = 2000 # 词表大小
embedding_dim = 512 # 词嵌入维度的大小
embeddings = Embeddings(vocab_size, embedding_dim)
embed_result = embeddings(torch.tensor([[1999, 2, 99, 4, 5], [66, 2, 3, 22, 5], [66, 2, 3, 4, 5]]))
print(embed_result.shape)
print(embed_result)运行结果:
torch.Size([3, 5, 512])
tensor([[[ -6.6145, 0.7250, -25.3896, ..., 1.6865, -12.6732, -5.5132],
[ 19.5802, -1.6906, -36.3070, ..., -5.9230, 9.9505, 49.2125],
[ 7.9797, 11.9496, -15.4930, ..., 72.7194, 10.6238, -19.9825],
[ 16.5478, 16.9025, 33.3123, ..., -14.4243, 12.2261, 53.3915],
[ 5.8041, 7.9344, -8.1885, ..., -45.0107, 30.0579, 21.0987]],
[[-24.4609, 12.4930, -24.3712, ..., 13.3388, -16.3208, -23.2783],
[ 19.5802, -1.6906, -36.3070, ..., -5.9230, 9.9505, 49.2125],
[ 58.9308, 2.7596, 2.6795, ..., 0.6120, 10.8724, 12.0722],
[ 0.4406, -24.8641, -19.6754, ..., -21.1263, -13.1530, 35.8521],
[ 5.8041, 7.9344, -8.1885, ..., -45.0107, 30.0579, 21.0987]],
[[-24.4609, 12.4930, -24.3712, ..., 13.3388, -16.3208, -23.2783],
[ 19.5802, -1.6906, -36.3070, ..., -5.9230, 9.9505, 49.2125],
[ 58.9308, 2.7596, 2.6795, ..., 0.6120, 10.8724, 12.0722],
[ 16.5478, 16.9025, 33.3123, ..., -14.4243, 12.2261, 53.3915],
[ 5.8041, 7.9344, -8.1885, ..., -45.0107, 30.0579, 21.0987]]],
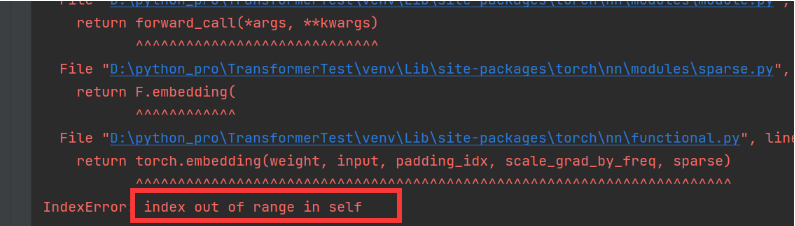
grad_fn=<MulBackward0>)注意点:传入的词向量数值大小不能大于等于定义的vocab_size词表大小。否则越界报错
比如 改成2000
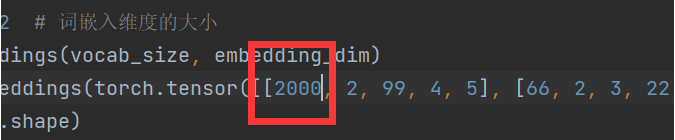
就会报错: