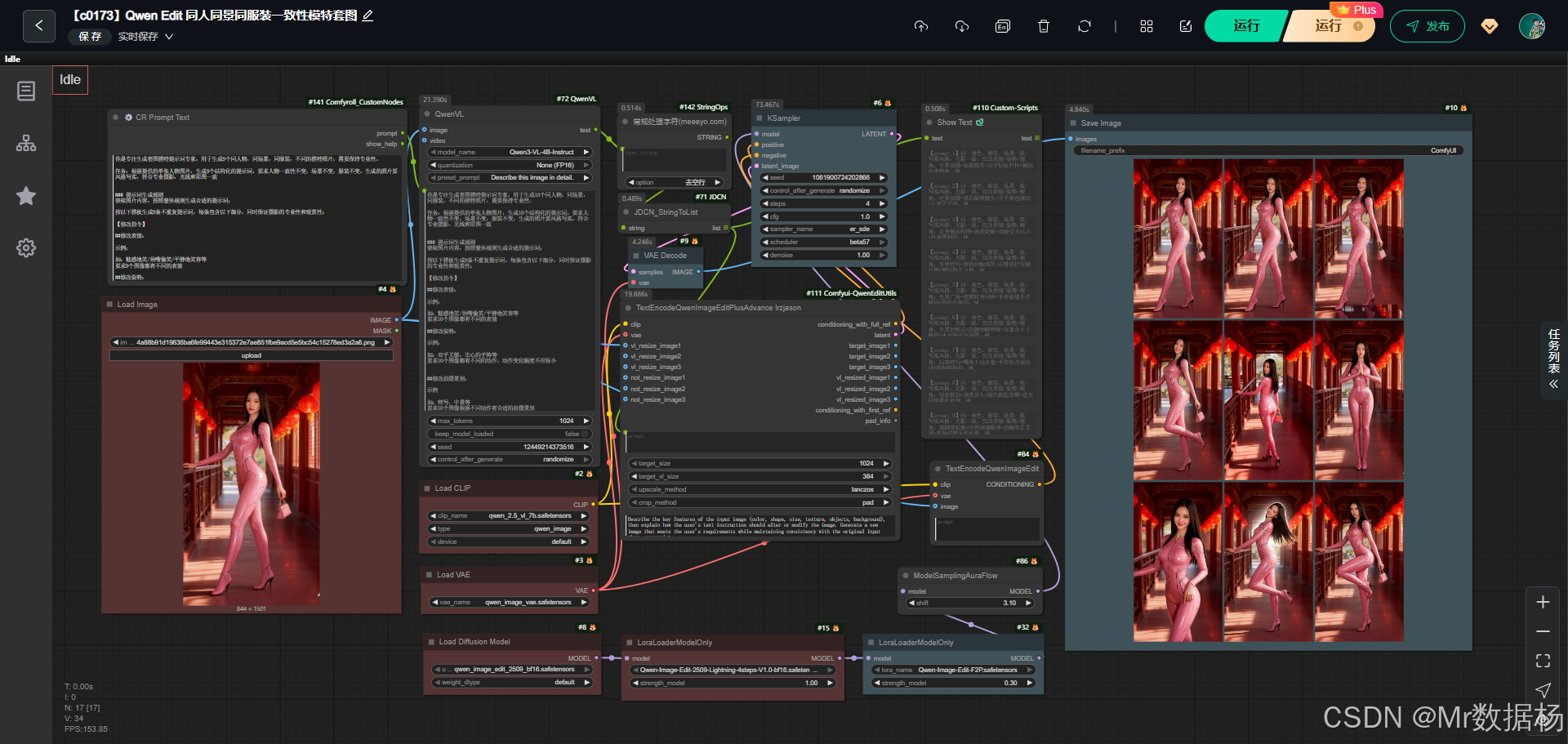
今天给大家演示的,是一个基于 Qwen Edit 的同人同景同服装一致性模特套图生成工作流。它通过单张人物照片自动生成多张保持人物一致、场景一致、服装一致的专业级套图,同时在表情、动作、景别与拍摄角度上灵活变化。

整个流程依靠 Qwen VL 识别人物特征,再由 Qwen Image Edit 系列模型进行图像一致性生成,最终产出高质量、风格统一、真实感强的成片,为模特套图创作带来极高效率。
文章目录
- 工作流介绍
-
- 核心模型
- [Node 节点](#Node 节点)
- 工作流程
- 大模型应用
-
- [AILab_QwenVL 图像内容解析与结构化提示生成](#AILab_QwenVL 图像内容解析与结构化提示生成)
- [CR Prompt Text 自定义提示词规则构建](#CR Prompt Text 自定义提示词规则构建)
- [TextEncodeQwenImageEditPlusAdvance 图像编辑指令编码器](#TextEncodeQwenImageEditPlusAdvance 图像编辑指令编码器)
- [TextEncodeQwenImageEdit 基础图像编辑指令编码器](#TextEncodeQwenImageEdit 基础图像编辑指令编码器)
- 使用方法
- 应用场景
- 开发与应用
工作流介绍
这个工作流围绕「从一张参考图生成多张一致性模特图像」展开,前端由 Qwen-VL 对人物特征、服装、场景进行结构化理解,再将提炼后的提示词送入 Qwen-Image-Edit 系列模型进行编辑与生成。整个系统依靠 CLIP、VAE、UNET、Lora 加载器和多种自定义节点协作,确保输入图像的风格、光线、轮廓与关键特征在所有生成图中保持稳定。
核心模型
本工作流的核心由多个 Qwen 系列模型组成。CLIP 提供视觉编码能力,VAE 负责图像潜空间转换,UNET 担任图像编辑生成的主体网络,同时配合 Lora 加载器提供强化一致性的权重调整。Qwen-VL 则用于解析参考图内容并生成结构化提示词,使生成结果更加贴合人物与场景特征。
| 模型名称 | 说明 |
|---|---|
| qwen_2.5_vl_7b.safetensors | 用于图像理解与内容解析的 Qwen VL 视觉语言模型 |
| qwen_image_vae.safetensors | 图像潜空间编码与解码的 VAE |
| qwen_image_edit_2509_bf16.safetensors | 主图像编辑 UNET,用于一致性图像生成 |
| Qwen-Image-Edit-2509-Lightning-4steps-V1.0-bf16.safetensors | 加速推理的 Lightning 版本,提高生成效率 |
| Qwen-Image-Edit-F2P.safetensors | 作为 LoraLoaderModelOnly 的附加模型强化一致性编辑效果 |
Node 节点
工作流由多种节点构成,它们分工明确:有的负责图像输入与解析,有的构建提示词,有的处理模型加载,还有的负责图像编辑、采样、解码与最终保存。多个自定义节点如 TextEncodeQwenImageEdit、ProcessString、StringToList 等共同组成完整的自动化链路。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载参考图并输出图像数据 |
| AILab_QwenVL | 基于 Qwen-VL 对人物、场景、服装生成结构化提示词 |
| CR Prompt Text | 自定义提示词构建器 |
| ProcessString | 清理与处理生成的提示词文本 |
| JDCN_StringToList | 将文本提示词拆分为结构化列表 |
| TextEncodeQwenImageEdit / PlusAdvance | 核心编辑编码器,将图像与文字指令融合处理 |
| CLIPLoader / VAELoader / UNETLoader | 加载 CLIP、VAE、UNET 模型 |
| LoraLoaderModelOnly | 加载并叠加 Lora 加强一致性编辑能力 |
| ModelSamplingAuraFlow | 控制模型采样方式与风格偏移 |
| KSampler | 执行最终图像采样过程 |
| VAEDecode | 将 latent 解码为最终图像 |
| SaveImage | 输出并保存图像结果 |
工作流程
整个工作流程以「加载参考图 → 解析内容 → 生成结构化提示词 → 编码编辑条件 → 采样生成 → 解码与保存」为主线展开。参考图首先通过 LoadImage 导入,再由 Qwen-VL 深度解析人物信息,随后 CR Prompt Text 与 ProcessString 将提示词加工成精确可控的列表。编辑阶段由 TextEncodeQwenImageEdit 系列节点把图像、结构化指令与编码模型融合,经过模型加载器与采样器的配合完成一致性生成。最后通过 VAE 解码并保存成片。整个链路环环相扣,确保输出图像在人物、服装与场景上保持稳定,同时具备动态变化的表情、姿势与拍摄角度。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 加载与输入 | 读取参考图,为后续识别与编辑提供图像基础 | LoadImage |
| 2 | 内容解析 | 识别人物外观、服装与场景特征,生成初级提示词 | AILab_QwenVL |
| 3 | 文本处理 | 根据生成规则构建结构化提示词,并清洗无效字符 | CR Prompt Text、ProcessString |
| 4 | 提示词结构化 | 将已清洗的提示词拆分成独立指令列表 | JDCN_StringToList |
| 5 | 模型加载 | 加载 CLIP、VAE、UNET 以及增强一致性的 Lora 模型 | CLIPLoader、VAELoader、UNETLoader、LoraLoaderModelOnly |
| 6 | 条件编码 | 结合图像、提示词、VAE、CLIP,将图像编辑条件编码进潜空间 | TextEncodeQwenImageEdit、TextEncodeQwenImageEditPlusAdvance |
| 7 | 采样生成 | 根据正负条件和 UNET 输出执行一致性图像采样 | ModelSamplingAuraFlow、KSampler |
| 8 | 图像解码 | 将 latent 解码为最终可视图像 | VAEDecode |
| 9 | 结果保存 | 生成最终成片并输出到指定目录 | SaveImage |
大模型应用
AILab_QwenVL 图像内容解析与结构化提示生成
该节点负责从输入图像中提取人物、服装与场景的关键要素,并根据预设或自定义 Prompt 自动生成结构化的指令文本。它的核心任务是理解图像语义,并利用 Prompt 控制生成内容的方向、风格及细节粒度。Prompt 在此阶段非常关键,它决定了模型对图像的关注重点、提示词的写法、摄影风格的约束以及输出的整体质量。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| AILab_QwenVL | preset_prompt :Describe this image in detail. custom_prompt :你是专注生成套图模特提示词专家,用于生成10个同人物,同场景,同服装,不同的模特照片,需要保持专业性。 任务:根据提供的单张人物图片,生成10个结构化的提示词...(原文完整保留) | 依据图像内容与 Prompt 指令生成结构化文本,用作后续一致性图像编辑的语义依据 |
CR Prompt Text 自定义提示词规则构建
该节点用于构建、补充和修正规则化 Prompt。它不解析图像,而是专注在文本层面,通过固定结构模板引导大模型生成更稳定、更专业且格式一致的 Prompt。Prompt 在此节点的作用是定义"如何生成提示词",包括拍摄角度、表情、姿势、景别等变化规则,使输出具有更高可控性。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| CR Prompt Text | 你是专注生成套图模特提示词专家,用于生成9个同人物,同场景,同服装,不同的模特照片,需要保持专业性。 任务:根据提供的单张人物图片,生成9个结构化的提示词...(原文完整保留) | 构建规则化 Prompt 模板,确保输出的提示词格式一致并能精确控制表情、姿势、景别与角度的变化 |
TextEncodeQwenImageEditPlusAdvance 图像编辑指令编码器
该节点负责将图像、Prompt 文本与图像编辑指令整合推入模型编码空间,是图像编辑阶段的大模型入口。Prompt 在此节点中承担"编辑控制参数"的角色,影响图像生成时的动作变化、场景一致性、光线控制、细节偏向等关键因素。它是最终图像呈现风格和质量的核心控制点。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlusAdvance | prompt :来自上游提示词列表 instruction:Describe the key features of the input image...(原文完整保留) | 将图像、结构化 Prompt 与编辑指令编码为可供 UNET 使用的潜空间条件,决定最终生成图像的风格与一致性 |
TextEncodeQwenImageEdit 基础图像编辑指令编码器
该节点与高级版功能相似,但主要承担基础的编辑 Prompt 编码任务。它将图像特征与文字 Prompt 进行合并,形成基础编辑条件。Prompt 在此处用于控制图像编辑的方向,包括动作变化、姿态调整、场景保持等。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEdit | prompt :来自上游输入 (无额外复杂结构) | 对图像与文本进行基础结合,用作负向与正向条件输入 KSampler,影响生成图像细节 |
使用方法
这个工作流的使用逻辑是:用户加载一张参考图后,系统会自动由 Qwen-VL 对人物、服装与场景进行解析,并根据节点内的 Prompt 自动生成多条结构化指令。随后,这些提示词被清洗、拆分、编码,并与模型加载器、编辑模型及采样器协作,最终自动生成多张保持人物一致、服装一致、场景一致的专业套图。
用户只需替换参考图片,即可自动触发全套解析与生成流程,无需额外调整其他节点。参考图承担"人物与场景来源"的角色,Prompt 则用于控制风格、姿势变化、情绪变化、景别与角度。整个过程全自动完成,用户只需要准备图像与 Prompt 文本即可快速得到完整套图。
| 注意点 | 说明 |
|---|---|
| 保持提示词结构完整 | Prompt 是整个工作流的控制核心,任何删改都会影响生成质量 |
| 输入图像需清晰 | 模型依赖图像理解人物特征,模糊图会降低一致性 |
| 不要同时修改多个核心节点参数 | 可能破坏一致性,建议保持默认设置 |
| 保持参考图的光线自然 | Qwen 系列模型会尝试保持光线一致,参考图光线越自然效果越佳 |
| 如需调整风格需从 Prompt 控制而非模型参数 | 该工作流以 Prompt 为主要调控方式,模型参数不建议改动 |
应用场景
这个工作流主要用于「单人参考图的一致性套图生成」,尤其适用于写实风格模特图拍摄模拟。其核心优势在于强一致性与可控变化:人物轮廓、光线、服装与背景始终保持不变,而表情、动作、景别和角度可以灵活调整,适合摄影师、电商模特图制作、内容创作者、同人创作者等使用。通过自动化结构化提示与高质量编辑模型,可以在短时间内生成大量风格统一、专业度高的图像,为不同创作场景提升生产效率。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 模特套图生成 | 从单张图扩展为多张一致性照片 | 摄影师、电商设计师、工作室制片人 | 姿势变化、表情变化、拍摄角度变化的连续套图 | 保持人物一致性,制作高质可用的模特系列图 |
| 角色同人集创作 | 为角色生成稳定风格的多张图像 | 同人作者、插画师、创作者 | 同服装同场景下的多视角角色展示 | 维持角色特征不变,同时提供丰富表现力 |
| 视觉内容批量生成 | 快速批量产出统一风格视觉素材 | 品牌方、自媒体运营者 | 风格连贯的成套视觉素材 | 高一致性与高效率内容输出 |
| AI摄影实验 | 研究光线、角度、主体一致性等效果 | AI 艺术研究者、摄影爱好者 | 同主体下的不同拍摄方式 | 稳定主体基础上探索更多摄影表现方案 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用