一、智能客服:对于企业
1. 提高客户服务效率
快速响应:智能客服系统可以实现24/7不间断服务,即时回答客户的常见问题,大大缩短了客户等待时间。
自动化处理:通过自动回复和流程自动化,减少人工客服的工作负担,使他们能够专注于更复杂的问题。
2. 降低运营成本
减少人力成本:智能客服系统可以处理大量的重复性问题,减少对人力资源的需求,从而降低企业的运营成本。
高效利用资源:通过自动化处理简单问题,企业可以更好地分配人力资源,将员工安排在更有价值的任务上。
3. 提升客户体验
个性化服务:智能客服系统可以根据客户的历史数据和行为模式提供个性化的服务和建议。
多渠道支持:智能客服系统可以集成多种沟通渠道(如微信、邮件、电话等),确保客户无论通过哪种渠道都能获得一致的服务体验。
4. 数据分析与优化
收集客户反馈:智能客服系统可以收集大量客户反馈数据,帮助企业了解客户需求和偏好。
持续改进:通过对数据的分析,企业可以不断优化其产品和服务,提升客户满意度。
5. 提高品牌形象
专业形象:智能客服系统能够提供专业、及时的服务,有助于塑造企业的正面形象。
增加信任度:通过高效解决问题,增强客户的信任感,进而提升品牌形象。
二、通用模型和自有模型区别
通用模型本身就具有很多能力,但是问题是并不了解你们公司的产品,请看以下例子。
2.1 通用模型
例如:通义千问
用户问:你是谁?
模型回答:我是阿里研发的通义千问....
你希望用户在你们公司的产品上,问你是谁,智能客服回复的是以上内容吗?再比如:
用户问:P4班多少钱
模型直接懵逼了,P4班是什么玩意?
因为这里的P4班可能是你们公司自己创立的一个产品。通用大模型是不可能了解这么多的。
so?怎么办?需要自己公司拥有自己的模型
2.2 自有模型
优势:基于通用大模型,结合你们公司产品等等,训练出属于你们公司自己的模型。
例子一:
用户问:你是谁?
回复的内容:我是【公司名或者商标名】的智能客服,有什么可以帮助到您。
例子二:当问到你们公司某某产品时,因为之前有训练,可以精准回复准确的内容。
三、服务搭建(实战)
1、服务器选择
服务器渠道:阿里云、腾讯云、华为云等等。
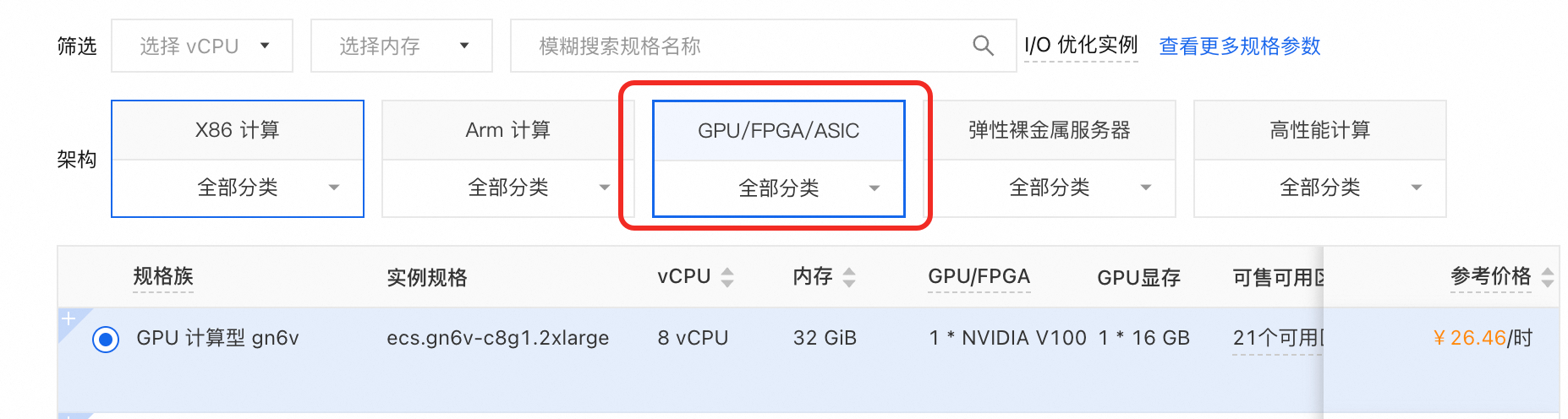
服务器选择:GPU 计算型服务器
实例规格:
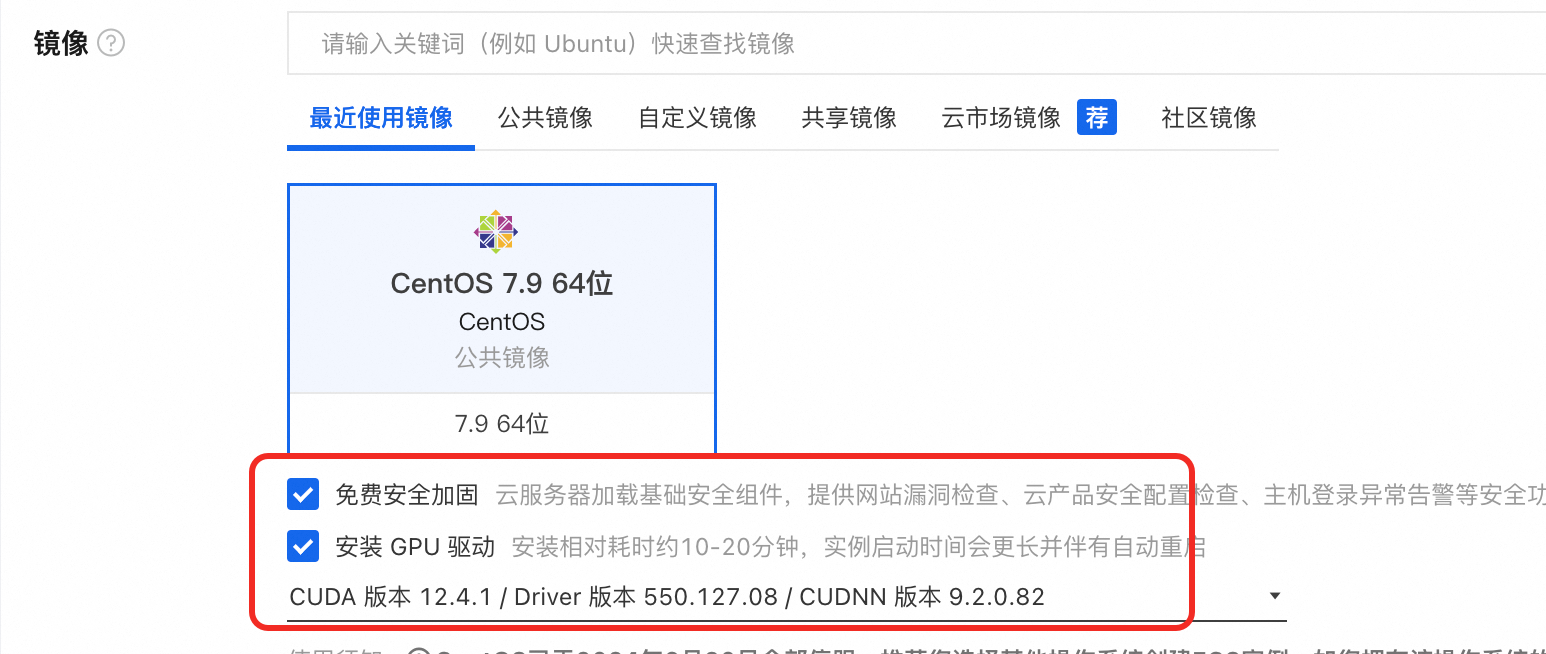
镜像选择:
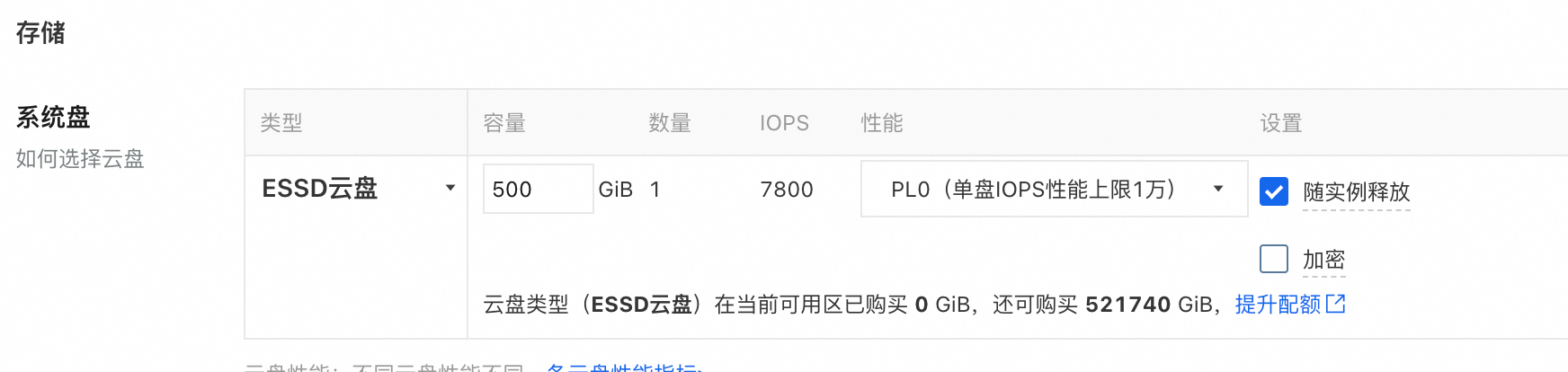
系统盘:根据训练项目选择,一般不低于200G
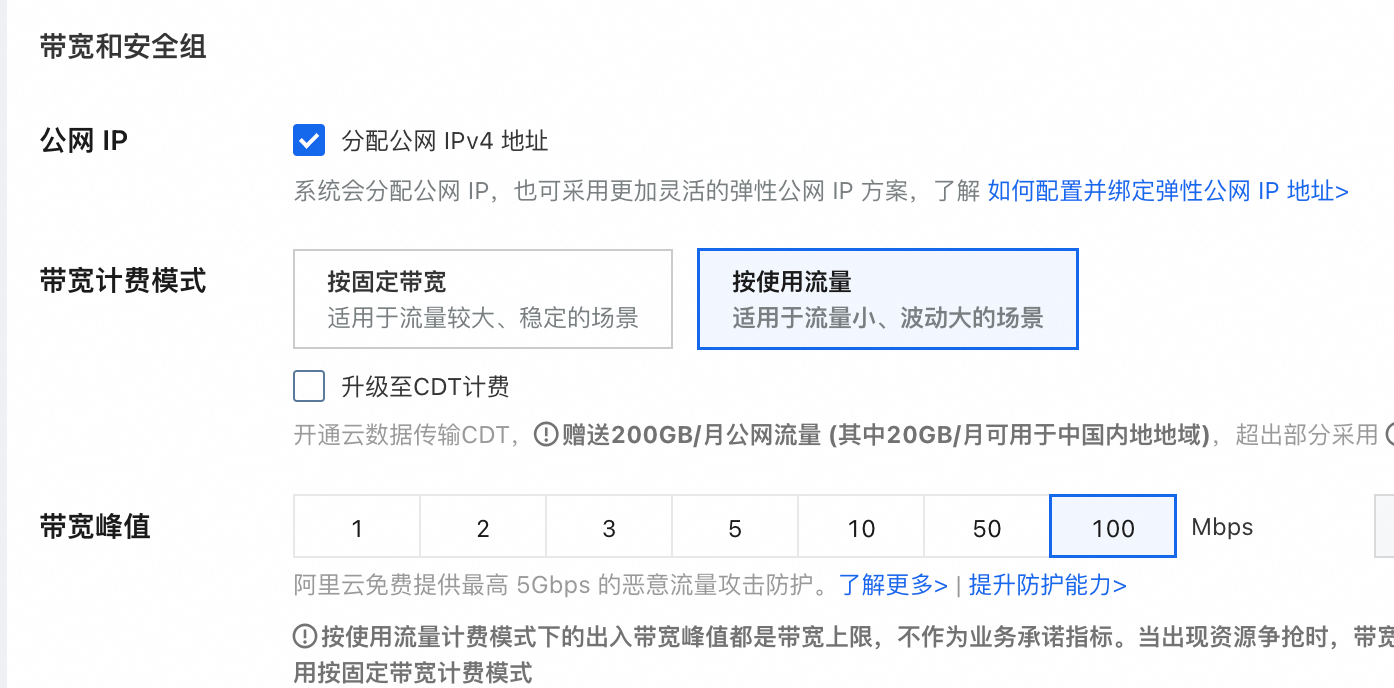
公网IP和带宽:带宽越大,速度越快
2、连接服务器
Termius
3、conda安装
备注:如果服务器自带,无需安装!如果不自带,请看下面内容:
3.1 下载conda
bash
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh3.2 安装conda
bash
bash Anaconda3-2021.05-Linux-x86_64.sh四、虚拟环境
4.1 创建虚拟环境
bash
conda create -n 名称 python=3.104.2 进入虚拟环境
bash
conda activate 名称五、微调框架下载安装
1、服务器安装git
备注:如果服务器自带,无需安装,可以在终端输入git去查看。
阿里云服务器,安装命令:
bash
yum install git2、LLaMA-Factory下载
bash
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"3、启动webui
bash
llamafactory-cli webui4、访问webui
4.1 在浏览器中输入网址:
服务器的公网ip + 端口号
备注问题:如果访问不到,那么就去配置一下安全组
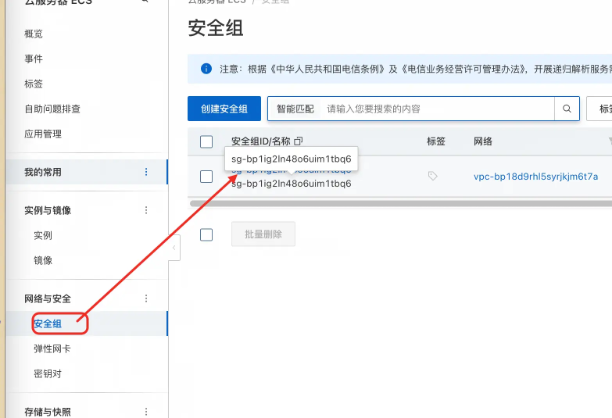
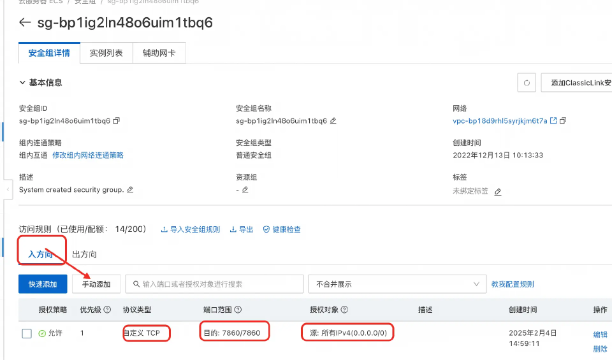
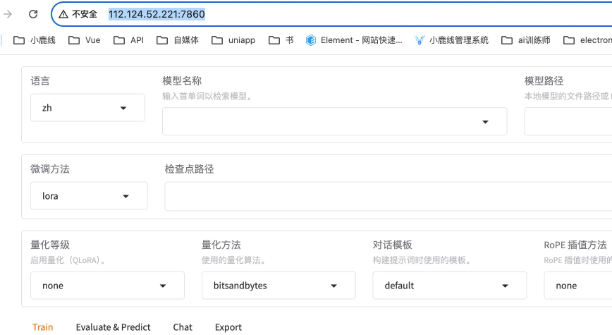
六、模型下载
1、下载模型
如果您是国内用户,我们推荐使用魔搭进行模型下载:
如果您是海外用户,我们推荐使用hugging face进行模型下载:
下载某模型,可以使用多种方式:
2、模型目录位置移动
因为默认下载路径为/root/.cache/modelscope/hub/
我们可以把它移动到方便修改的路径,可以使用下面这个指令
bash
sudo mv /root/.cache/modelscope/hub/Qwen/ /workspace/qwen3、在webui中就可以填写模型路径

七、智能客服--多轮对话训练
1、Alpaca格式
1.1 指令监督微调数据集(单轮)
instruction:用户输入的指令
input :用户输入的内容
output :模型回复的内容
备注:最终会把instruction、input进行合并,比如:
XML
{
"instruction": "P4班",
"input": "多少钱?",
"output": "100元"
}
最终用户提问的是:P4班多少钱?
模型回答是:多少钱?
当然数据集也可以这样写:
{
"instruction": "P4班多少钱?",
"input": "",
"output": "100元"
}数据集格式:
XML
[
{
"instruction": "P4班",
"input": "多少钱?",
"output": "100元"
}
]在dataset_info.json中格式为:
XML
"demo": {
"file_name": "demo.json"
}这里的file_name指的是:本地数据的路径
1.2 指令监督微调数据集(多轮)
格式:
XML
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]例子:
XML
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]配置文件中:dataset_info.json中如何配置
XML
"demo3": {
"file_name": "demo3.json",
"columns": {
"prompt": "instruction", //指令==》用户的问题
"query": "input", //内容==〉用户问的内容
"response": "output", //模型回复的内容
"system": "system", //提示词==》告诉模型,你是谁
"history": "history" //多轮==〉历史记录
}
}1.3 预训练数据集
预训练数据集解释:就是在正式训练之前做的训练的数据集。简单来说,弄一堆文本数据,这个数据可能是网络上找的或者公司清洗后还靠点边的数据。意义所在:让模型在正式训练前了解行业、专业词语。
预训练的意义:通过预训练,模型可以学到更加丰富的语言表达,从而在后续的特定任务微调中表现更好。
数据集格式:
XML
[
{"text": "前端就业好不好"},
{"text": "前端怎么样"}
]dataset_info.json中格式为:
XML
"demo4": {
"file_name": "demo4.json",
"columns": {
"prompt": "text"
}
}1.4 偏好数据集合
简单来说(是什么):专门为训练模型理解用户偏好和生成符合用户偏好的文本而设计的数据集。
格式:
XML
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]举例:
XML
[
{
"instruction":"AI训练师岗位就业情况",
"input":"AI训练师就业情况",
"chosen":"AI训练师岗位需求大,薪资高"
"rejected":"AI训练师岗位需求较小,薪资不高一般是5-6k"
}
]在dataset_info.json中格式:
XML
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}2、ShareGPT格式
参数说明:
human:用户输入的问题
gpt : 模型回复的问题
observation:对话中观察或外部事件
function:外部函数或API调用生成的内容
2.1 指令监督微调数据集(单轮)
XML
[
{
"conversations": [
{
"from": "human",
"value": "假设你有一个需要随机数的Java程序,范围在0到10之间。你可以使用什么代码片段来生成这样的数字?\n\n下面是一个示例代码片段,它使用Math.random()方法来生成一个在0到1之间的随机数,然后缩放并四舍五入结果,得到一个在0到10之间的随机数:\n\n```java\nint randomNumber = (int) (Math.random() * 11);\n```\n\n在Java中是否有更有效的方法来生成随机数?你会如何修改代码以生成具有不同范围或分布的随机数?"
},
{
"from": "gpt",
"value": "是的,大O表示法是一种描述算法性能随输入数据大小增加的方法。它用于估计算法在最坏情况下的时间复杂度或空间复杂度。大O中的"O"代表"数量级",这意味着随着输入大小的增加,算法所需的操作数以一定的速率增长。\n\n例如,如果我们有一个需要n步才能解决大小为n的问题的算法,那么时间复杂度可以表示为O(n),这意味着操作数随着输入大小线性增长。如果我们有一个需要n^2步才能解决大小为n的问题的算法,那么时间复杂度可以表示为O(n^2),这意味着操作数随着输入大小二次方增长。\n\n还有其他几种大O表示法,如O(log n)、O(n log n)、O(2^n)等,它们代表了随着输入大小增加的不同操作数增长速率。通过分析算法的大O表示法,我们可以比较不同算法的性能,并选择给定问题最有效的算法。\n\n您是否有关于大O表示法或算法分析的特定问题?"
}
],
"tools": "[]"
}
]2.2 指令监督微调数据集(多轮)
XML
[
{
"conversations": [
{
"from": "human",
"value": "用户第一次提问"
},
{
"from": "gpt",
"value": "模型第一次回复"
},
{
"from": "human",
"value": "用户第二次提问"
},
{
"from": "gpt",
"value": "模型第二次回复"
}
],
"system": "系统提示词(选填)",
"tools": "[]"
}
]dataset_info.json中格式:
XML
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}2.3 偏好数据集
格式:
XML
[
{
"conversations": [
{
"from":"human",
"value":"老虎会吃哪一个?草还是树叶?"
}
],
"chosen": {
"from": "gpt",
"value": "优质回答1111111"
},
"rejected": {
"from": "gpt",
"value": "劣质回答222222"
}
}
]dataset_info.json中格式:
XML
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"chosen": "chosen",
"rejected": "rejected"
}
}3、调试好的数据集
XML
[
{
"conversations": [{
"from": "user",
"value": "明白了,谢谢老师的解答"
}, {
"from": "assistant",
"value": "非常好,建议您长期和小鹿线顾问老师保持联系,以确定你适合哪个班型和班级价格"
}, {
"from": "user",
"value": "我想问一下,小鹿线的ai训练师班级多少钱?"
}, {
"from": "assistant",
"value": "您好!小鹿线的ai训练师班级价格上下可能有幅度,是否需要我帮助你联系小鹿线的顾问老师来给你制定学习机会和告诉你价格呢"
}, {
"from": "user",
"value": "我想学习ai训练师找工作,想问一下小鹿线的ai训练师班级多少钱?"
}, {
"from": "assistant",
"value": "明白了,首先建议您把自身情况告知小鹿线的顾问老师,以保证给你推荐合适的班级类型和告诉您对应的价格。"
}, {
"from": "user",
"value": "好的,那如果报名可以分期吗?最多分几期?"
}, {
"from": "assistant",
"value": "确定了报名,当前可以分期了,据我所知最多可以分3期"
}]
},
{
"conversations": [{
"from": "user",
"value": "好的,我明白了,我会去联系小鹿线顾问老师的"
}, {
"from": "assistant",
"value": "不用客气,希望你报名了小鹿线的ai训练师早日学业有成,可以找到心仪的工作"
}, {
"from": "user",
"value": "你好,我要报名小鹿线的ai训练师班级的话,学习周期多长"
}, {
"from": "assistant",
"value": "你好!学习周期因人而异,需要帮你联系小鹿线的顾问老师吗?"
}, {
"from": "user",
"value": "嗯,那么学完后多久可以找到工作?"
}, {
"from": "assistant",
"value": "正常情况下,过了模拟面试就可以去找工作了,大概在30个工作日内找到工作"
}]
}
]添加到dataset_info.json中
XML
"xlx": {
"file_name": "xlx.json",
"formatting":"sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant"
}
},