TL;DR
- 场景:在日志检索、站内搜索、大数据分析中,Elasticsearch 查询性能和结果相关性经常"黑箱化"。
- 结论:理解倒排索引 + 分片路由 + Query/Fetch 两阶段,是排查"搜不全、搜不准、搜很慢"的前提。
- 产出:一套围绕倒排索引和读写流程的知识框架 + 版本适用矩阵 + 常见错误速查卡。

版本矩阵
| Elasticsearch 版本 | 已验证 | 说明 |
|---|---|---|
| 6.x | 否 | 概念层基本一致,但部分 API 与默认分词配置已有差异,需结合当时官方文档对照。 |
| 7.x | 是 | 文中涉及的倒排索引原理、分片路由计算、主副本写入流程、Query/Fetch 两阶段与 7.x 实践高度吻合。 |
| 8.x | 是 | 核心机制与 7.x 一致,安全默认值与部分配置项有增强,但不影响文中原理性内容。 |
倒排索引
Elasticsearch 是一个基于 Apache Lucene 构建的开源分布式搜索引擎,它能够以近乎实时的速度执行复杂的全文搜索查询。作为当前最流行的企业级搜索解决方案之一,Elasticsearch 被广泛应用于日志分析、电子商务搜索、应用内搜索等各种场景。
在 Elasticsearch 的核心架构中,倒排索引(Inverted Index)是最关键的数据结构之一。与传统数据库使用的正排索引不同,倒排索引采用了"词项→文档"的映射方式。具体来说,当文档被索引时,Elasticsearch 会:
- 对文本内容进行分词处理(Tokenization),将句子分解为独立的词项(Terms)
- 建立词项到文档ID的映射关系
- 记录词项在每个文档中的出现频率(TF)和位置信息
例如,假设有三个文档:
- 文档1:"Elasticsearch is fast"
- 文档2:"Elasticsearch is scalable"
- 文档3:"Search is fast"
构建的倒排索引会类似这样:
arduino
"elasticsearch" → [文档1, 文档2]
"fast" → [文档1, 文档3]
"scalable" → [文档2]
"search" → [文档3]这种数据结构设计使得 Elasticsearch 在执行搜索查询时,只需查找查询词项对应的文档列表,然后进行合并操作即可得到结果,而无需扫描所有文档内容。这种机制正是 Elasticsearch 能够实现毫秒级搜索响应的关键所在。理解倒排索引的工作原理对于优化 Elasticsearch 查询性能、设计合适的分词策略以及解决搜索相关问题时都至关重要。
什么是倒排索引?
倒排索引是一种用于快速查找包含特定词汇的文档的数据结构。它类似于一本书的索引页,但结构上是"倒过来"的,因此得名。
正向索引 vs. 倒排索引
-
正向索引(Forward Index)
- 是基于文档的索引结构,以文档为中心组织数据
- 存储方式:为每个文档建立一个条目,记录该文档包含的所有词汇及其出现位置
- 典型实现:文档ID → 词项1:位置列表, 词项2:位置列表,...
- 应用场景:
- 文档内容检索(如显示搜索结果时获取完整文档内容)
- 文档相似度计算
- 搜索引擎的文档存储层
- 示例:文档D1包含"搜索引擎"(位置5)、"技术"(位置8);文档D2包含"数据库"(位置3)
-
倒排索引(Inverted Index)
- 是基于词汇的索引结构,以词项为中心组织数据
- 存储方式:为每个词项建立一个条目,记录包含该词项的所有文档及出现位置
- 典型实现:词项 → 文档ID1:位置列表, 文档ID2:位置列表,...
- 核心优势:
- 快速定位包含特定词项的文档
- 支持高效的布尔查询(AND/OR/NOT)
- 便于实现相关性排序
- 应用场景:
- 搜索引擎的核心检索组件
- 大规模文本检索系统
- 广告定向投放
- 示例:词项"技术" → D1:8, D3:2, D5:15;词项"数据库" → D2:3, D4:7
例如,假设有三篇文档如下:
- "Elasticsearch 是一个分布式搜索引擎"
- "分布式系统可以提供高可用性"
- "搜索引擎使用倒排索引进行高效搜索"
正向索引会记录每个文档中有哪些词:
shell
Doc1: ["Elasticsearch", "是", "一个", "分布式", "搜索", "引擎"]
Doc2: ["分布式", "系统", "可以", "提供", "高", "可用性"]
Doc3: ["搜索", "引擎", "使用", "倒排索引", "进行", "高效", "搜索"]而倒排索引则会记录每个词在哪些文档中出现:
shell
"Elasticsearch": [1]
"分布式": [1, 2]
"搜索": [1, 3]
"引擎": [1, 3]
"倒排索引": [3]这样,当你查询一个词汇时,比如 "搜索",Elasticsearch 可以通过倒排索引立即返回它出现在 Doc1 和 Doc3 中,而不需要遍历所有的文档。
倒排索引的构建
在 Elasticsearch 中,文档首先会被分析和处理,然后生成倒排索引。其过程大致如下:
-
文档分词:每个文档都会经过 分析器(Analyzer) 的处理,分析器负责将文档的文本分解成词项(terms)。例如,句子 "Elasticsearch 是一个分布式搜索引擎" 可能被分解为 "elasticsearch", "分布式", "搜索", "引擎"。
-
标准化和过滤:分词后,分析器通常会进行进一步的处理,例如将所有词项转为小写、删除停用词(如 "是", "一个")等。这一步使得倒排索引更具可查询性。
-
构建倒排列表:倒排索引将每个词项与它所出现的文档ID关联。词项是倒排索引的键,文档ID列表则是值。对于每个词项,Elasticsearch 还可能记录一些额外信息,如词频(TF)和词项在文档中的位置(用于短语匹配和邻近查询)。
倒排索引的结构
倒排索引的核心部分可以分为以下几个组成部分:
-
词汇表(Term Dictionary):词汇表保存了所有被索引的词项,通常是以字典形式存储。通过这个表,Elasticsearch 可以快速定位某个词项是否存在。
-
倒排列表(Posting List):对于每个词项,倒排列表记录了所有包含该词项的文档ID。倒排列表还可以包含附加信息,如:
-
词项频率(Term Frequency, TF):记录该词项在文档中出现的次数。
-
文档频率(Document Frequency, DF):记录该词项在整个索引中出现的文档总数。 位置(Position):词项在文档中的位置,用于支持短语和邻近查询。 例如,对于词项 "搜索",倒排列表可能是这样的:
shell
"搜索": [(Doc1, Position: 5), (Doc3, Position: 3, 7)]这意味着 "搜索" 在文档1中出现过,并且在文档3中出现过两次,分别位于位置3和7。
倒排索引的查询原理
倒排索引使得 全文搜索查询 变得非常高效。例如,当你向 Elasticsearch 发起搜索请求时,比如查找包含词项 "搜索引擎" 的文档,Elasticsearch 可以执行以下步骤:
查找词项:Elasticsearch 首先在词汇表中查找 "搜索" 和 "引擎" 这两个词项,找到它们的倒排列表。
合并倒排列表:Elasticsearch 会合并这两个词项的倒排列表,找到同时包含 "搜索" 和 "引擎" 的文档。由于每个词项都与它的文档ID相关联,合并列表的操作非常快速。
计算相关性:在找到匹配的文档后,Elasticsearch 会根据一些算法(如 TF-IDF 或 BM25)对文档进行评分,衡量它们与查询的相关性。这个步骤基于词项频率、文档频率等信息,最终返回最相关的文档。
倒排索引的优势
- 快速检索:倒排索引的结构使得对于某个词项的检索速度极快,尤其在海量文档中,查询性能仍能保持在毫秒级别。
- 低内存占用:虽然倒排索引记录了大量的词项和文档ID,但通过压缩算法和优化的数据结构,倒排索引可以保持较低的内存使用率。
- 支持复杂查询:倒排索引不仅支持简单的关键词查询,还支持短语、前缀、邻近查询等复杂的搜索条件。
测试分析
Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复的列表构成,对于其中每个词,有一个包含的它的文档列表。 假设我们有两个文档,每个文档的内容如下:
shell
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer要创建倒排索引,首先要将每个文档内容拆分成单独的词,创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下图所示:  现在我们想要搜索 quick down,我们只需要查找包含每个词条的文档:
现在我们想要搜索 quick down,我们只需要查找包含每个词条的文档: 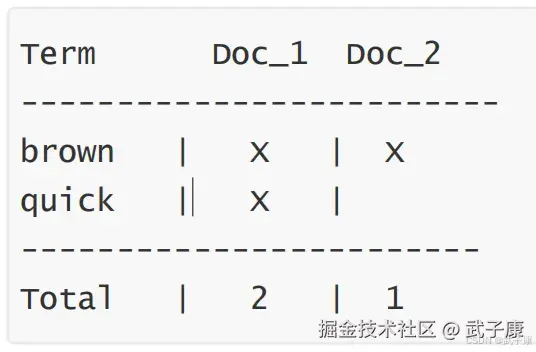 两个文档都匹配,但是第一个文档比第二个匹配度更高,如果我们使用仅计算匹配条数量的简单相似性算法,那么对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
两个文档都匹配,但是第一个文档比第二个匹配度更高,如果我们使用仅计算匹配条数量的简单相似性算法,那么对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
读写流程
创建文档
向Elasticsearch中添加一个文档对象,由于ES是分布式集群并且底层设计了一个索引由众多Shard分片,所以添加文档时需要确定该文档属于哪个分片,确定规则为:
shell
shard = has(routing) % number_of_primary_shards- routing 是一个可变值,默认是文档的ID,也可以设置成一个自定义的值
- routing 通过hash函数生成一个数字,然后这个数字再除以number_of_primary_shards(主分片的数量)后得到余数,这个分布在0到number_of_primary_shards - 1 之间的余数,就是我们寻求的文档所在分片的位置。
写文档流程
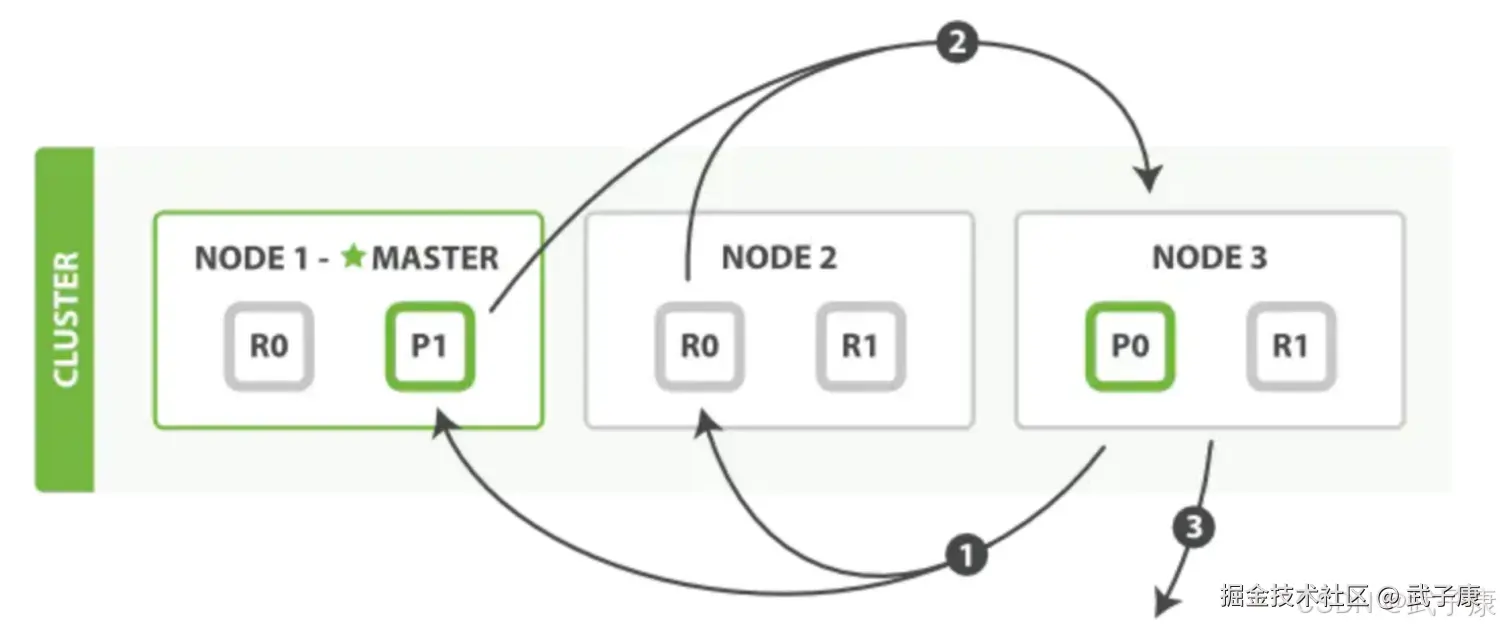
以官网的例子进行分析,从图中可看出一个集群由三个节点组成,有两个分片,两个副本。
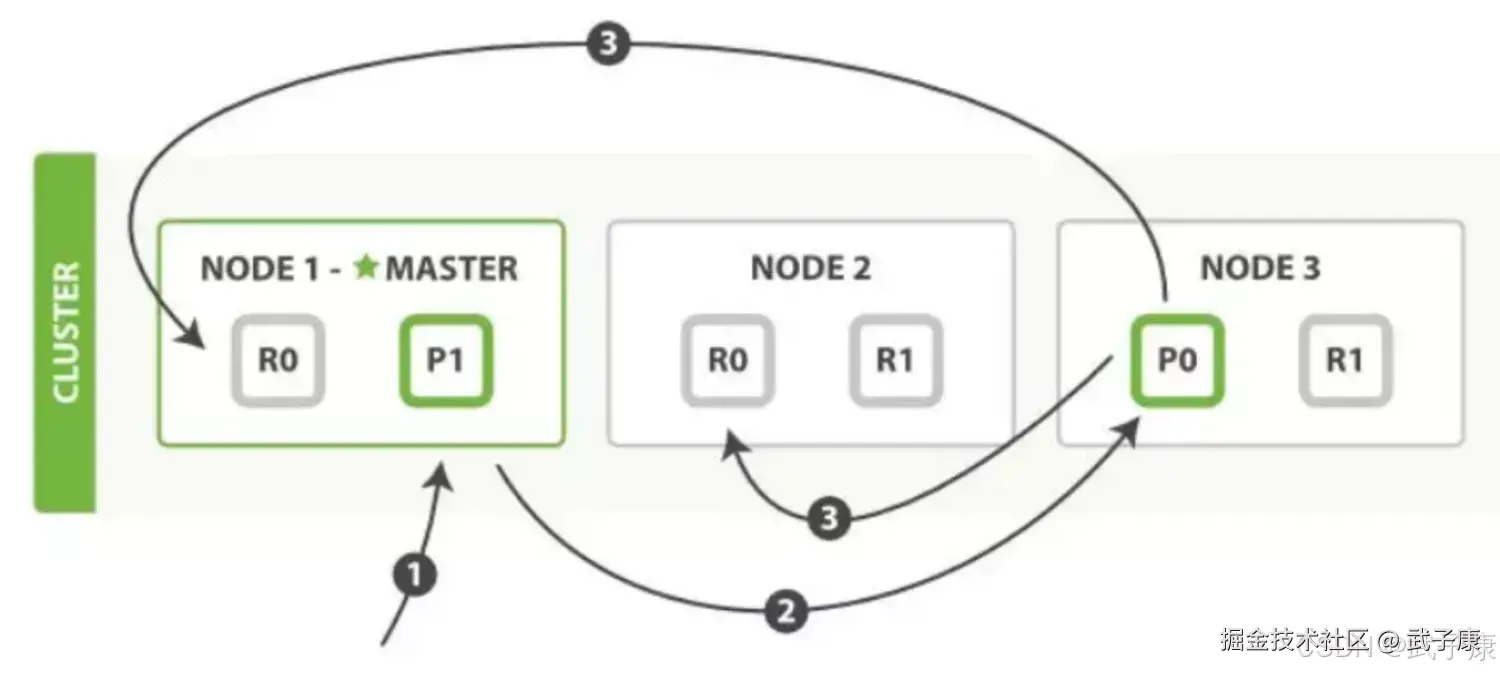 写操作必须在主分片上面完成之后,才能被复制到其他节点作为分片副本,新建、索引和删除请求都是写操作。
写操作必须在主分片上面完成之后,才能被复制到其他节点作为分片副本,新建、索引和删除请求都是写操作。
- 客户端向Master发送写入请求,该节点作为协调节点
- 根据文档的_id确定分片,图中请求文档属于分片0,协调节点请求转到节点的主分片
- 在节点3上执行请求,成功之后,节点3根据副本数将请求并行转到副本分片对应节点,一旦副本分片执行完成,都向节点3报告成功,节点3将协调节点报告成功,协调节点向客户端报告成功
读文档流程
一个搜索请求必须询问请求的索引中所有分片的某个副本来进行匹配,假设一个索引由5个主分片,每个主分片有一个副本分片,共10个分片,一次搜索请求会由5个分片来共同完成,他们可能是主分片,也可能是副分片。也就是说,一次搜索请求只会命中所有分片副本中的一个。 一次检索流程主要分为两个阶段:
- Query阶段
- Fetch阶段
Query阶段
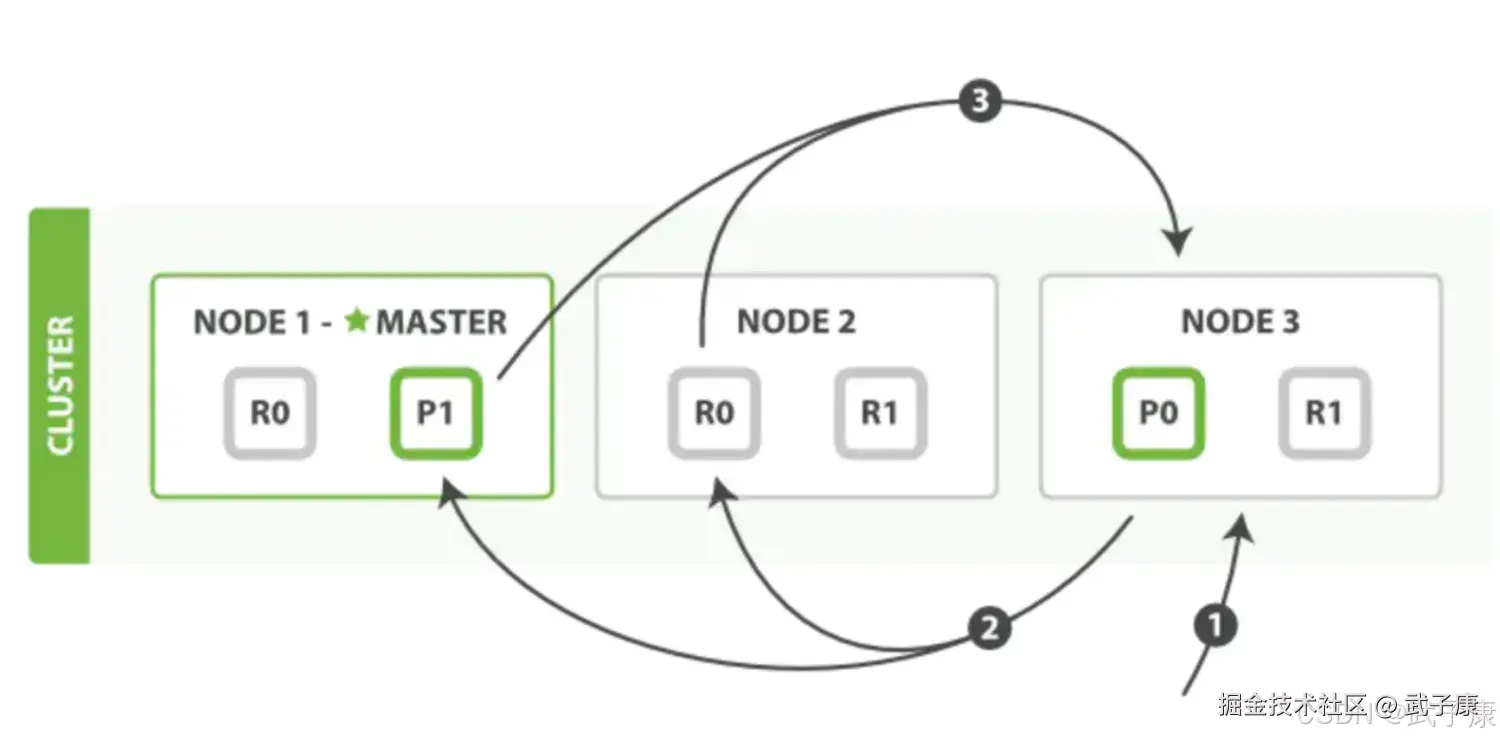
- 客户端发送Search请求到Node3
- Node3将查询请求转发到索引的每个主分片或副分片中
- 每个分片在本地执行查询,并使用本地的Term/DocumentFrequency信息进行打分,添加结果到大小 from+size的本地优先队列中
- 每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表
Fetch阶段
- 协调节点相关Node发送GET请求
- 分片所在节点向协调节点返回数据
- 协调节点等待所有文档数据被取得,然后返回给客户端
分片所在节点在返回文档时,处理有可能出现的 _source 字段和高亮参数
错误速查
| 症状 | 根因定位 | 修复关键词 |
|---|---|---|
| 能写入,搜索却查不到或结果很少 | 分词器不一致:索引时和查询时使用了不同 analyzer,或被停用词过滤 | 用 _analyze API 查看索引与查询实际生成的 terms;检查 mapping 中的 analyzer 设置统一索引与查询使用的 analyzer;必要时为字段单独定义自定义分词器与搜索分词器 |
| 查询只命中部分文档,相关性排序"很奇怪" | 倒排索引中 TF/DF 与 BM25 打分机制未理解,误以为"包含越多词一定排越前" | 使用 explain API 查看单条命中文档的评分构成;对比不同字段、不同词频下的得分为重要字段提升权重(boost),控制字段是否参与评分(norms、constant_score),合理设计字段粒度 |
| 写入后立刻搜索,短时间内查不到新文档 | 不了解 refresh 机制:索引到倒排索引之间存在 refresh 周期(近实时) | 查看索引的 refresh_interval 配置;对比写入时间与可见时间对实时性要求高的索引调小 refresh_interval 或在关键写入后手动调用 _refresh(注意性能成本) |
| 部分分片 QPS 明显过高,集群负载不均 | routing 设计不当,导致文档集中落在少数分片,倒排索引"热点" | 使用 _cat/shards 看各分片文档数与大小,结合 Slowlog 观察热点分片合理选择 routing 字段,避免低基数字段;必要时重建索引并重新规划分片数和 routing 策略 |
| 搜索整体变慢,CPU 使用率高 | 倒排索引膨胀:字段过多、text 字段滥用、未关闭不需要的索引 | 查看 mapping,统计需要索引的字段数量;用 _stats 查看每索引存储和查询开销对只用于展示的字段设置 index: false 或 keyword 精准匹配;关闭不必要的 _all、_source 或裁剪字段 |
| 短语/邻近查询效果差,明明文档里有整句 | 未开启或未正确使用位置(position)信息,或使用了不支持短语查询的字段类型 | 检查字段是否为 text 且保留 position 信息;对比 term 查询与 match_phrase 查询结果使用 match_phrase/span 系列查询,确保分词与位置信息保留;避免对 keyword 等不适合的字段做短语检索 |
| 集群偶发写入失败或"版本冲突"异常 | 对同一文档频繁更新,未理解主分片 + 副本异步复制与乐观锁版本机制 | 检查应用端写入模式,统计单文档更新频率;查看失败请求中 _version 信息合理设计更新策略,减少无意义的全量覆盖更新;必要时使用局部更新(update)或幂等写入设计 |
| 搜索结果跨页翻页越深越慢 | 使用高 from + size 深分页,导致多个分片上的倒排结果集合反复合并 | 分析慢查询日志,关注大 from/size 参数;对比 search_after 与 Scroll 性能对业务深分页使用 search_after 或游标/滚动查询;前端做"查看更多"与结果截断设计,避免无限深翻页 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解