把 智能体 的「记忆」装进文件系统?这篇论文让大模型像操作系统一样管理上下文!

为什么 智能体 需要一个"文件系统"?
想象一下,你正在和 ChatGPT 或 Claude 聊天,聊了很久之后,它突然"失忆"了------之前说过的话、达成的共识、积累的知识全都忘得一干二净。这就是当前大模型面临的核心问题:它们本质上是"无状态"的,每次对话结束后就像失忆症患者一样,什么都不记得。
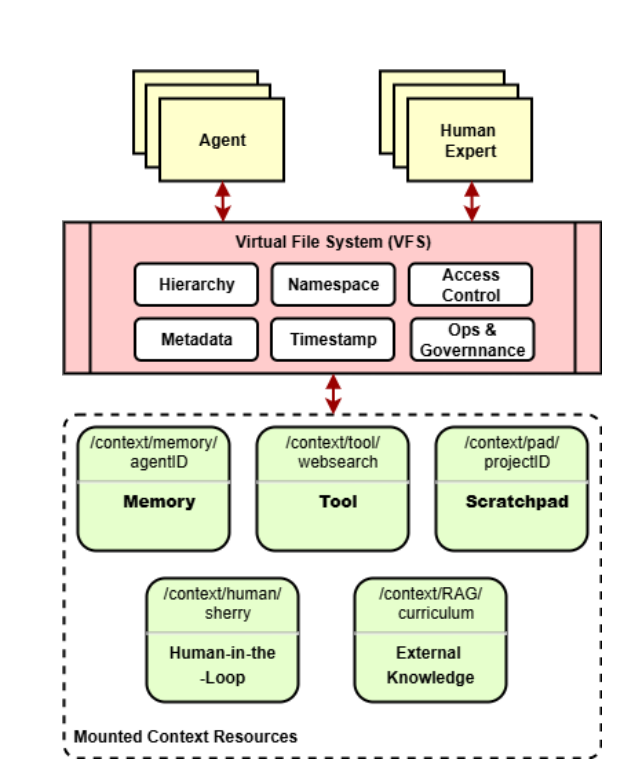
这篇来自 CSIRO 和澳大利亚新南威尔士大学的论文,提出了一个非常有意思的解决方案:把 Unix 系统"一切皆文件"的哲学思想应用到 智能体 的上下文管理中。什么意思呢?就像你的电脑用文件系统来组织文档、照片、程序一样,这篇论文认为 智能体 的记忆、工具、知识库、人类输入等各种"上下文资源",也应该用统一的文件系统来管理。
研究动机非常明确:当前的 智能体 系统在管理上下文时非常混乱。像 LangCh智能体n、AutoGen 这些主流框架虽然提供了一些记忆和工具管理功能,但都是各自为政、临时拼凑的,缺乏统一的架构基础。更要命的是,这些系统生成的上下文信息往往是"用完即扔"的,没有可追溯性,也无法审计------这在工业应用中是个大问题。
论文的核心贡献可以概括为三点:
- 提出了文件系统抽象:把各种异构的上下文资源(记忆、工具、知识库、人类反馈等)统一挂载到一个虚拟文件系统中,就像 Unix 系统管理硬件设备一样
- 设计了完整的上下文工程流水线:包括上下文构造器(Context Constructor)、上下文加载器(Context Loader)和上下文评估器(Context Evaluator),系统化地管理上下文的整个生命周期
- 在开源框架 智能体GNE 中实现并验证:不只是纸上谈兵,而是真的做出来了,并通过两个实际案例(带记忆的智能体和基于 MCP 的 GitHub 助手)展示了可行性
相关工作:智能体 界的"操作系统梦"
要理解这篇论文的价值,得先看看学术界和工业界都在尝试什么。
LLM-as-OS(大模型即操作系统)范式最近很火。智能体OS 项目把大模型比作操作系统内核,负责调度任务、分配资源、管理内存,就像多核 CPU 管理多个程序一样。这个想法很酷,但问题在于:它只是个概念框架,缺少具体的软件架构设计。换句话说,大家都知道应该这么做,但没人说清楚到底怎么做。
在上下文工程领域,LangCh智能体n 和 AutoGen 这些框架已经做了不少探索。它们提供了记忆模块、工具编排等功能,但都是"头痛医头、脚痛医脚"式的------需要记忆就加个记忆模块,需要工具就加个工具接口,彼此之间缺乏统一的治理机制。最近的一些研究开始关注"链接式上下文",把上下文看作可发现、可互联的资源,但同样缺少可验证的架构基础。
在长期记忆方面,业界大致分为两大阵营:一类是基于向量嵌入的方案(如 mem0、Letta),另一类是基于知识图谱的方案(如 Zep/Graphiti、Cognee)。但它们都主要聚焦于存储和检索优化,对于上下文的治理、访问控制、多智能体共享等问题,基本都是"能用就行"的态度,谈不上系统化的架构设计。
这篇论文的独特之处在于:它不是发明一个新的记忆方案或检索算法,而是提供了一个统一的基础设施层。就像高速公路系统不生产汽车,但让所有汽车都能高效通行一样,这个文件系统抽象让各种记忆方案、工具、知识库都能"挂载"进来,统一管理。
把上下文"装进"文件系统
文件系统抽象:五大软件工程原则
论文的核心创新是把软件工程的经典原则应用到 智能体 上下文管理中。具体来说,文件系统实现了五个关键特性:
1. 抽象(Abstraction) :无论底层是知识图谱、向量数据库还是人类笔记,统统用标准化的文件接口表示。就像你不需要知道硬盘是机械硬盘还是固态硬盘,只要能读写文件就行。更厉害的是,系统支持 Schema 驱动的自动映射------REST API、GraphQL、MCP 工具等异构资源可以自动投射到文件命名空间,完全不需要写集成代码。
2. 模块化与封装(Modularity & Encapsulation) :每个上下文资源都是独立挂载的组件,有明确的边界和元数据。想换个数据库?没问题,只要接口一致,换什么都不影响其他部分。这就像搭积木一样灵活。
3. 关注点分离(Separation of Concerns) :数据文件(如 config.yaml)和可执行工具(如 analyser.py)清楚地区分开来。访问控制、日志、元数据管理都有专门的机制,不和功能逻辑混在一起。
4. 可追溯性与可验证性(Traceability & Verifiability) :每一次操作(无论是 智能体 还是人类发起的)都会记录成事务日志,保存在持久化仓库中。这意味着你可以回溯整个推理过程------这个结论是怎么得出的?用了哪些数据?谁修改了什么?全都有据可查。
5. 可组合性与可演化性(Composability & Evolvability) :通过统一的命名空间和元数据模式,不同的上下文元素可以无缝组合。想添加新的后端(比如全文检索引擎或向量数据库)?直接挂载就行,不需要改其他代码。
更酷的是,文件系统中的每个文件或目录还可以关联自定义动作(Actions)。这些动作是可发现、可调用的行为,从数据分析、验证、同步到领域特定的转换都可以。这让每个文件节点都变成了"活"的,智能体 可以直接通过文件系统接口执行工具调用。
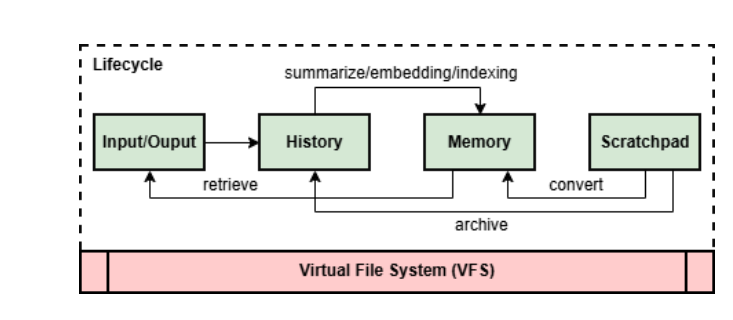
持久化上下文仓库:History、Memory 和 Scratchpad
大模型是无状态的,对话一结束就什么都忘了。要实现跨会话的连贯推理,必须有个外部的持久化记忆仓库。论文设计了一个三层架构:
History(历史) 是不可变的真相来源。所有用户输入、模型输出、中间推理步骤都会被原封不动地记录下来,附带时间戳、来源、模型版本等元数据。它是全局的、永久的,可以跨多个智能体和会话共享,提供完整的溯源能力。
Memory(记忆) 是经过结构化和索引的视图。原始 History 太冗长了,直接塞给模型会爆掉 token 限制。Memory 就是把 History 通过摘要、嵌入、索引等方式提炼成高效的表示形式。论文把记忆分成多种类型(见表格):
| 记忆类型 | 时间范围 | 结构单元 | 表示方式 |
|---|---|---|---|
| 草稿本(Scratchpad) | 临时的,任务级 | 对话轮次,临时推理状态 | 纯文本或嵌入 |
| 情节记忆(Episodic Memory) | 中期,会话级 | 会话摘要,案例历史 | 摘要文本或嵌入 |
| 事实记忆(Fact Memory) | 长期,细粒度 | 原子级事实陈述 | 键值对或三元组 |
| 经验记忆(Experiential Memory) | 长期,跨任务 | 观察-行动轨迹 | 结构化日志 |
| 过程记忆(Procedural Memory) | 长期,系统级 | 函数、工具定义 | API 或代码引用 |
| 用户记忆(User Memory) | 长期,个性化 | 用户属性、偏好、历史 | 用户画像、嵌入 |
Scratchpad(草稿本) 是临时工作区,智能体 在推理过程中会在这里写草稿、做计算、测试假设。会话结束后,有价值的内容会被提取到 Memory 或归档到 History,完成整个循环。
这三者的关系是:History 是"原始素材库",Memory 是"精选剪辑",Scratchpad 是"工作台"。所有的状态转换都以文件级事件记录,带有时间戳和血缘元数据,确保可重放、可审计。
上下文工程流水线:三大组件协同作战
有了基础设施(文件系统 + 持久化仓库),接下来就是如何实际使用这些上下文。论文设计了一个闭环流水线,由三个组件组成:
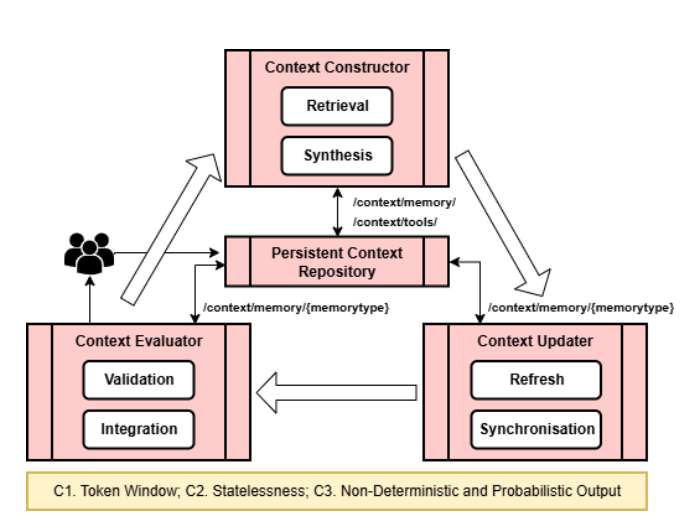
上下文构造器(Context Constructor) 负责"挑选"和"压缩"。它从持久化仓库中检索相关信息,根据任务需求、优先级、元数据(如时间戳、来源)进行筛选和排序。因为大模型有 token 限制(比如 GPT-5 的 128K、Claude Sonnet 4.5 的 200K),构造器必须在"完整性"(覆盖所有相关信息)和"有界性"(不超预算)之间做权衡。选出来的内容会进一步通过摘要、嵌入、聚类等方式压缩,最后对齐模型的输入格式。
整个过程会生成一个上下文清单(Context Manifest),记录哪些元素被选中了、哪些被排除了、为什么。这让构造过程从"黑盒操作"变成了"透明流程"。
上下文更新器(Context Updater) 负责"装载"和"刷新"。它把构造好的上下文注入到模型的 token 窗口中。根据任务类型,可能是一次性注入静态快照(单轮任务),也可能是增量流式加载(多轮交互),还可能是自适应刷新(根据模型反馈或人类干预动态替换过时片段)。
所有的加载和替换操作都会在文件系统中记录元数据事件,包括时间戳、源路径、推理标识符,确保完全可追溯。在多智能体场景下,更新器还要保证资源隔离------一个智能体的上下文不能泄露到另一个。
上下文评估器(Context Evaluator) 负责"验证"和"反馈",闭合整个循环。模型的输出不一定靠谱,可能产生幻觉、矛盾或上下文漂移。评估器会将输出与源上下文进行语义比对、事实一致性检查,或者与权威来源交叉验证。评估指标(如置信度分数、事实对齐度、人工覆盖率)都会记录为结构化元数据。
通过验证的输出会被转换成结构化的记忆元素,更新持久化仓库------可能是追加新条目、修订旧条目或生成摘要。所有更新都带版本号、时间戳和血缘元数据,确保演化过程透明且可逆。当置信度低或检测到矛盾时,评估器会触发人工审核,人类的标注和洞察会作为"一等公民"存储到知识库中。
设计约束:为什么要这样设计?
整个流水线的设计不是拍脑袋想出来的,而是由大模型的三个内在约束决定的:
约束 1:Token 窗口限制。大模型一次能处理的信息量是有上限的,而且输入越长,计算成本越高(注意力机制的平方复杂度)。这个硬约束迫使系统必须精心策划、压缩、增量传输上下文。
约束 2:无状态性。大模型不记得之前的对话,必须依赖外部持久化仓库。但持久化又带来新问题:记忆增长、冗余、检索精度下降。这要求系统有去重和整合策略。
约束 3:非确定性输出。同样的输入可能产生不同的输出(取决于采样参数如 temperature)。这给可追溯性、测试、验证带来挑战,必须保存完整的输入-输出对、元数据和血缘信息,支持审计和重放。
正是这三个约束,驱动了整个架构的设计------从文件系统抽象到持久化仓库,再到三组件流水线,每一步都是有的放矢。
实验效果
纸上谈兵不如真刀真枪。论文团队把整个架构实现在了开源框架 智能体GNE 中。智能体GNE 是一个用于快速开发生成式 智能体 智能体的函数式框架,原生支持多种主流大模型(Open智能体、Gemini、Claude、DeepSeek、Ollama)和通过 MCP(模型上下文协议)接入的外部服务。
在 智能体GNE 中,核心模块是 AFS(Agentic File System,智能体文件系统),提供虚拟文件系统接口。它支持:
- 标准文件操作:list(列出)、read(读取)、write(写入)、search(搜索)
- 导航嵌套子目录,可配置深度限制
- 集成 ripgrep 实现高效内容搜索
- 访问文件时间戳、大小、类型及自定义元数据
- 沙盒访问限制,确保隔离和安全
所有挂载的资源(MCP 模块、记忆存储、数据库、外部 API)通过**可编程解析器(Resolvers)**投射到文件系统中。这些解析器实现声明式映射(类似 GraphQL/OpenAPI schema),无需修改底层存储格式就能将内部结构转换为 AFS 节点,实现异构系统的无缝集成。
案例 1:带记忆的智能体
第一个例子展示了如何让智能体跨会话保持上下文连贯性。通过在构造时声明式激活 DefaultMemory 模块,对话历史会自动持久化为可检索的上下文。存储位置可以指定为文件路径(如 file:./memory.sqlite3),这样数据在会话间可以保存和重载。每轮对话都会追加到记忆中,并自动融入后续推理,无需显式的状态管理。
代码示例非常简洁:
javascript
const sharedStorage = { url: "file:./memory.sqlite3" };
const afs = new AFS()
.mount(new AFSHistory({ storage: sharedStorage }))
.mount(new UserProfileMemory({ storage: sharedStorage }));
const agent = 智能体Agent.from({
instructions: "You are a friendly chatbot",
inputKey: "message",
afs,
});短短几行代码,就实现了带历史记忆和用户画像记忆的智能体。所有记忆资源通过文件系统统一管理,智能体可以像访问文件一样读写记忆。
案例 2:基于 MCP 的 GitHub 助手
第二个例子展示了如何将任意 MCP 服务器挂载为 AFS 模块,通过统一文件系统接口暴露其能力。以 GitHub MCP 服务器为实际案例,智能体可以像访问文件一样与 GitHub 交互。挂载后,智能体可以直接通过 afs_exec 调用 GitHub 工具,比如 /modules/github-mcp/search_repositories 和 /modules/github-mcp/list_issues。
代码示例:
javascript
const mcpAgent = aw智能体t MCPAgent.from({
command: "docker",
args: ["run", "-i", "--rm",
"-e", `GITHUB_PERSONAL_ACCESS_TOKEN=${process.env.GITHUB_PERSONAL_ACCESS_TOKEN}`,
"ghcr.io/github/github-mcp"],
});
const afs = new AFS().mount(mcpAgent); // 挂载到 /modules/github-mcp
const agent = 智能体Agent.from({
instructions: "Help users interact with GitHub via the github-mcp-server module.",
inputKey: "message",
afs,
});这个例子的亮点在于:任何符合 MCP 规范的服务都可以即插即用,不需要为每个服务单独写集成代码。文件系统抽象充当了"万能转接头",让异构服务在统一的命名空间下和谐共存。
这两个案例虽然简单,但充分展示了架构的灵活性和可扩展性。开发者可以快速组装复杂的智能体系统,而不必陷入底层集成的泥潭。
论文总结
这篇论文的核心洞察是:上下文工程需要从"临时拼凑"升级为"系统工程"。当前主流框架虽然提供了记忆、工具等功能,但都是各自为政、缺乏统一治理的。论文提出的文件系统抽象,就像给混乱的施工现场搭了一套脚手架------所有材料(记忆、工具、知识库、人类输入)都有固定的位置,所有操作都有标准的流程,所有变更都有清晰的记录。
这种"一切皆文件"的思想并不新鲜(Unix 从 1970 年代就在用了),但应用到 智能体 上下文管理却是个创新。它让 智能体 系统获得了三个关键能力:可追溯 (每一步都有据可查)、可审计 (所有操作都有日志)、可演化(新组件可无缝接入)。这对于工业级应用至关重要------毕竟,没人愿意用一个"黑盒"智能体 做关键决策。
当然,论文也指出了未来的研究方向:比如让智能体在文件系统中"自主导航",自己构建索引、演化数据结构,甚至让文件系统成为一个"活的知识织物",推理、记忆、行动在其中有机融合。这些愿景听起来很科幻,但有了坚实的架构基础,或许离实现也不远了。