作者:来自 Elastic Mirko Bez 及 Alessandro Brofferio

Elastic Observability 允许你通过使用 Elastic Distributions of OpenTelemetry,将 OTel traces 与 ECS 日志关联,从而拥有 OpenTelemetry 和 ECS 语义。
OpenTelemetry (OTel) 正迅速成为厂商中立的标准仪表化工具。然而,许多组织仍依赖基于 Elastic Common Schema (ECS) 的日志管道和他们多年构建和优化的仪表板。Elastic Observability 提供了一种方法,将现代可观测性仪表化(特别是使用 Elastic Distribution of OpenTelemetry,EDOT)的优势与现有 ECS 系统兼容地结合起来。
我们将通过一个 Java 应用演示:
- 使用现有 ECS 日志库(Log4j2/ECS-Java)修改应用,以注入 EDOT SDK 生成的 trace.id 和 span.id 上下文。
- 配置 EDOT Collector 从文件中采集这些 ECS 格式的日志,并转发回 Elasticsearch,确保跟踪数据和日志数据完全关联,并可立即在 Kibana 内置仪表板和工具中使用。
这种方法允许完全采用 OTel 的统一可观测性(traces、metrics 和 logs),而无需放弃或修改已建立的基于 ECS 的日志管道和仪表板。
在博客的最后部分,我们将讨论如何采用 OpenTelemetry-first 方法收集数据。
ECS 基础与 EDOT 的兴起
想象一个应用生态系统,已经配置为以 ECS 格式发送日志。这是结构化日志的良好起点。历史上,在 Elastic 生态系统中,Elastic Common Schema (ECS) 被采用为日志格式的标准。Elastic 通过提供 ECS 日志插件,在源头简化了这一标准化,这些插件可以轻松集成到各种编程语言的常用日志库中。这些插件会自动生成遵循 ECS 的结构化 JSON 日志。为了演示,我们将使用一个自定义 Java 应用,它生成随机日志,依赖配置了 ecs-java-plugin 库的 Log4j2 日志库。
Elastic 文档提供了一个示例配置,为应用程序的设置提供了可靠基础。该过程包括引入必要的 ECS Java 日志插件库,并修改 Log4j2 配置文件以使用 ECS layout 配置。此设置假设已预先配置 Log4j2 依赖以包含所需的 ECS 插件库。以下是 Log4j2 配置模板的摘录:
xml
`
1. <?xml version="1.0" encoding="UTF-8"?>
2. <Configuration status="DEBUG">
3. <Appenders>
4. <Console >
5. <EcsLayout service/>
6. </Console>
7. </Appenders>
8. <Loggers>
9. <Root level="info">
10. <AppenderRef ref="LogToConsole"/>
11. </Root>
12. </Loggers>
13. </Configuration>
`AI写代码引入 Elastic Distribution of OpenTelemetry (EDOT)
Elastic Distribution of OpenTelemetry (EDOT) 是由 Elastic 定制的一套 OpenTelemetry 组件(OTel Collector 和语言 SDK)。在 Elastic Observability v8.15 发布时推出,EDOT Collector 通过使用标准 OTel Collector 接收器收集和转发应用日志、基础设施日志、指标和 traces,增强了 Elastic 现有的 OTel 功能。EDOT 用户可以自动使用 Kubernetes 元数据丰富容器日志,利用 Elastic 提供的强大日志解析器。
EDOT 的主要优势:
-
提前提供增强功能:提供在 "原生" OTel 组件中尚不可用的功能,Elastic 持续向上游贡献这些功能。
-
增强的 OTel 支持:为标准 OTel 发布周期之外的问题提供企业级支持和维护。
接下来的问题是:用户如何在保持收集 ECS 格式日志能力的同时,将其采集架构过渡到 OTel 原生方法?
这涉及替换经典的采集和仪表化组件(如 Elastic Agent 和 Elastic APM Java Agent)。我们将逐步展示如何使用 EDOT 提供的完整组件套件完成替换。下面展示了 Kubernets 中 EDOT 架构组件的全面视图。
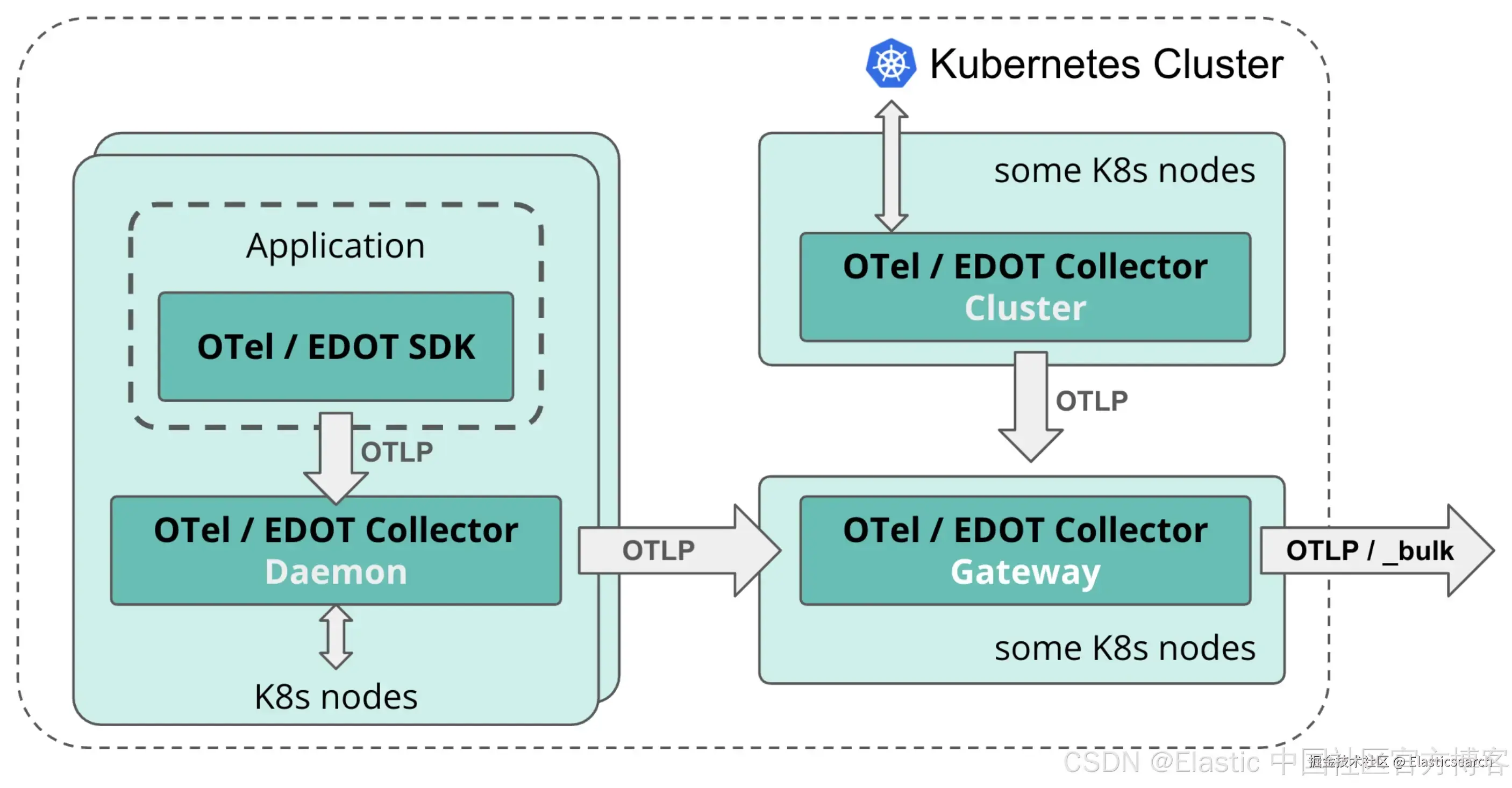
在 Kubernetes 环境中,EDOT 组件通常通过 OTel Operator 和 HELM chart 安装。主要组件包括:
- EDOT Collector Cluster:用于收集集群范围指标的 deployment。
- EDOT Collector Daemon:用于收集节点指标、日志和应用遥测数据的 daemonset。
- EDOT Collector Gateway:执行数据的预处理、聚合,并将其导入 Elastic。
Elastic 为所有 EDOT 组件提供了精选配置文件,作为 OpenTelemetry Operator 的一部分,通过 opentelemetry-kube-stack Helm chart 提供。可从此处下载。
使用 EDOT SDK 进行 Trace 和日志关联
我们的 Java 应用需要使用 EDOT Java SDK 进行监测,以收集 traces 并将 trace 上下文传播到日志中。虽然 EDOT SDK 可以直接收集日志,但通常更稳健的方法是坚持文件采集。这很重要,因为如果 OTel Collector 宕机,写入文件的日志会在本地磁盘缓冲,避免 SDK 内存队列达到上限并开始丢弃新日志时可能发生的数据丢失。关于此主题的深入讨论,请参阅 OpenTelemetry 文档。
应用程序监测
EDOT Java SDK 是 OpenTelemetry Java Agent 的定制版本。在 Kubernetes 中,通过在 deployment manifest 的 pod 模板配置中添加注解,支持零代码 Java 自动监测:
markdown
`
1. apiVersion: apps/v1
2. kind: Deployment
3. ...
4. spec:
5. ..
6. template:
7. metadata:
8. # Auto-Instrumentation
9. annotations:
10. instrumentation.opentelemetry.io/inject-java: "opentelemetry-operator-system/elastic-instrumentation"
`AI写代码编排:EDOT SDK 和 ECS 日志
将日志与 traces 关联依赖于两部分编排:
- Injector(EDOT Java SDK) :每当一个 span 活跃(表示一个被跟踪的操作)时,EDOT agent 会提取当前的 Trace 和 Span ID,并将其注入到 Java 日志库的 MDC(Mapped Diagnostic Context)中。默认情况下,SDK 使用 trace_id 和 span_id。为了符合 ECS 标准,我们必须配置仪表化对象,将注入的字段名改为 trace.id 和 span.id。这可以通过设置以下环境变量实现:
yaml
`
1. instrumentation:
2. java:
3. image: ...
4. env:
5. # disable direct export (we rely on filelog collection)
6. - name: OTEL_LOGS_EXPORTER
7. value: none
8. # Override default keys to match ECS standard
9. - name: OTEL_INSTRUMENTATION_COMMON_LOGGING_SPAN_ID
10. value: span.id
11. - name: OTEL_INSTRUMENTATION_COMMON_LOGGING_TRACE_ID
12. value: trace.id
`AI写代码- Formatter(ECS 日志插件):ECS Java 日志插件(如 EcsLayout)将日志事件格式化为结构化 JSON。由于我们在上面重新配置了 injector,该插件现在可以将线程上下文中的数据无缝映射到最终的 JSON 日志中:
| MDC | JSON Log |
|---|---|
| trace.id | trace.id |
| span.id | span.id |
使用 EDOT Collector 收集和处理日志
应用现在以漂亮的 ECS JSON 格式输出日志,并包含正确的 trace.id 和 span.id 字段,我们配置 EDOT Collector 从文件 pod 标准输出文件收集这些日志。
EDOT Collector 配置:动态工作负载发现和 filelog 接收器
运行在容器中的应用对监控系统来说是移动目标。为应对这一点,我们依赖 Kubernetes 上的动态工作负载发现。这允许 EDOT Collector 跟踪 pod 生命周期,并根据特定注解动态附加日志收集配置。
在我们的示例中,我们有一个包含单个容器的 Deployment Pod。我们使用 Kubernetes 注解来:
- 启用自动检测(Java)。
- 为该 pod 启用日志收集。
- 指示 collector 立即将输出解析为 JSON(json-parser 配置)。
- 添加自定义属性(例如识别应用源代码)。
Deployment 清单示例
yaml
`
1. apiVersion: apps/v1
2. kind: Deployment
3. metadata:
4. name: logger-app-deployment
5. labels:
6. app: logger-app
7. spec:
8. replicas: 1
9. selector:
10. matchLabels:
11. app: logger-app
12. template:
13. metadata:
14. annotations:
15. # 1. Turn on Auto-Instrumentation
16. instrumentation.opentelemetry.io/inject-java: "opentelemetry-operator-system/elastic-instrumentation"
17. # 2. Enable Log Collection for this pod
18. io.opentelemetry.discovery.logs/enabled: "true"
19. # 3. Provide the parsing "hint" (Treat logs as JSON)
20. io.opentelemetry.discovery.logs.ecs-log-producer/config: |
21. max_log_size: "2MiB"
22. operators:
23. - type: container
24. id: container-parser
25. - type: json_parser
26. id: json-parser
27. # 4. Identify this application as Java (To allow for user interface rendering in Kibana)
28. resource.opentelemetry.io/telemetry.sdk.language: "java"
29. labels:
30. app: logger-app
31. spec:
32. containers:
33. - name: logger-app-container
`AI写代码该配置提供了用于采集 ECS 库日志的最基本配置。关键在于,它将日志收集与应用逻辑解耦。开发者只需通过注解提供日志为 JSON 格式的提示(由 ECS 库结构保证)。然后,我们在(Daemon)EDOT Collector 的处理器层集中定义标准化的丰富和处理规则。
这种集中化确保了平台的一致性:如果以后需要更新标准格式或丰富策略,只需在 collector 中应用一次,更改会自动传播到所有服务,无需开发者修改其清单。
(Daemon)EDOT Collector 配置
为启用此功能,我们在 Daemon Collector 中配置了一个 Receiver Creator。该组件使用 k8s_observer 扩展来监控 Kubernetes 环境,并根据上述注解自动发现目标 pod。
yaml
`
1. daemon:
2. ...
3. config:
4. ...
5. extensions:
6. extensions:
7. k8s_observer:
8. auth_type: serviceAccount
9. node: ${env:K8S_NODE_NAME}
10. observe_nodes: true
11. observe_pods: true
12. observe_services: true
13. ...
14. receivers:
15. receiver_creator/logs:
16. watch_observers: [k8s_observer]
17. discovery:
18. enabled: true
19. ...
20. ...
`AI写代码最后,我们在 pipeline 中引用 receiver_creator,而不是使用静态 filelog 接收器,并确保包含 k8s_observer 扩展:
yaml
`
1. daemon:
2. ...
3. config:
4. ...
5. service:
6. extensions:
7. - k8s_observer
8. pipelines:
9. # Pipeline for node-level logs
10. logs/node:
11. receivers:
12. # - filelog # We disable direct filelog receiver
13. - receiver_creator/logs # Using the configured receiver_creator instead of filelog
14. processors:
15. - batch
16. - k8sattributes
17. - resourcedetection/system
18. exporters:
19. - otlp/gateway # Forward to the Gateway Collector for ingestion
`AI写代码日志转换
为了完成 pipeline,我们使用 transform 处理器,它允许使用 OpenTelemetry Transformation Language (OTTL) 修改和重构遥测信号。
虽然我们的日志现在是有效的结构化 JSON(ECS),但 OpenTelemetry Collector 最初将其读取为通用日志属性。为了实现正确的关联和后端存储,我们必须将这些属性映射到严格的 OpenTelemetry Log Data Model。
我们使用处理器将特定 ECS 字段提升到顶级 OpenTelemetry 字段,并根据 OpenTelemetry 语义约定重命名属性:
- 将 message 属性提升为顶级 Body 字段。
- 将 log.level 属性提升为 OTel SeverityText 字段。
- 将 @timestamp 属性移动到 OTel Time 字段。
- 将 trace.id 和 span.id 重命名为 OTel 合规的对应字段。
- 将 resource 属性如 service.name 移动到其资源属性对应字段。
这确保所有日志数据都标准化,实现与 traces 和 metrics 的无缝关联,并简化最终导入任何 OTel 兼容的后端。
bash
`1. processors:
2. transform/ecs_handler:
3. log_statements:
4. - context: log
5. conditions:
6. # Only apply if the log was actually generated by our ECS library
7. - log.attributes["ecs.version"] != nil
8. statements:
9. # 1. Promote message to Body
10. - set(log.body, log.attributes["message"])
11. - delete_key(log.attributes, "message")
13. # 2. Parse and promote Timestamp
14. - set(log.time, Time(log.attributes["@timestamp"], "%Y-%m-%dT%H:%M:%SZ"))
15. - delete_key(log.attributes, "@timestamp")
17. # 3. Map Trace/Span IDs for correlation
18. - set(log.trace_id.string, log.attributes["trace.id"])
19. - delete_key(log.attributes, "trace.id")
20. - set(log.span_id.string, log.attributes["span.id"])
21. - delete_key(log.attributes, "span.id")
23. # 4. Map log level to severity text
24. - set(log.severity_text, log.attributes["log.level"])
25. - delete_key(log.attributes, "log.level")
27. # 5. Map resource attributes
28. - set(resource.attributes["service.name"], log.attributes["service.name"]) where resource.attributes["service.name"] == null
29. - delete_key(log.attributes, "service.name")
30. - set(resource.attributes["service.version"], log.attributes["service.version"]) where resource.attributes["service.version"] == null
31. - delete_key(log.attributes, "service.version")
33. # Add here additional transformations as needed...`AI写代码我们需要在 Daemon Collector 日志 pipeline 中引用新创建的处理器:
bash
`
1. service:
2. pipelines:
3. logs/node:
4. receivers:
5. - receiver_creator/logs
6. processors:
7. - batch
8. - k8sattributes
9. - resourcedetection/system
10. - transform/ecs_handler # Newly created transform processor
11. exporters:
12. - otlp/gateway
`AI写代码以 ECS 兼容性导出到 Elasticsearch
最后一步是配置 EDOT Gateway Collector 导出数据。为了在支持 OTel 原生信号的同时保持与现有 ECS 仪表板的兼容性,我们依赖两个关键组件:Elasticsearch Exporter 的映射模式和 Routing Connector。
映射模式
Elasticsearch Exporter 支持映射设置,决定遥测数据如何发送到后端。以下重点介绍两种模式:
- mode: otel(默认):使用 Elastic 首选的 OTel 原生 schema 存储文档,保留 OTLP 事件的原始属性名称和结构。
- mode: ecs:尝试将 OpenTelemetry 语义约定自动映射回 Elastic Common Schema (ECS)。这是保持旧仪表板正常工作的必要设置。
更多细节请参阅Mapping Modes 和 ECS & OpenTelemetry。
Routing Connector
由于我们可能有混合的日志类型(如 k8sevents 或其他未使用 ECS 的容器日志),我们使用 Routing Connector。该组件会检查传输中的日志,如果检测到 ecs.version 属性(在前面步骤中保留),则将日志路由到专用 ECS pipeline。其他日志则回退到默认 pipeline。
综合配置
以下是在 Gateway Collector 的 Elasticsearch exporter 配置中提供的设置:
yaml
`
1. gateway:
2. ...
3. config:
4. ...
5. connectors:
6. routing/logs:
7. match_once: true
8. default_pipelines: [logs]
9. table:
10. - context: log
11. condition: attributes["ecs.version"] != null
12. pipelines: [logs/ecs]
14. exporters:
15. elasticsearch/ecs:
16. endpoint: <<Your Elasticsearch Endpoint URL>>
17. # **Crucial setting for ECS compatibility**
18. mapping:
19. mode: ecs
20. headers:
21. Authorization: <<Your API Key>>
`AI写代码最后,确保你创建的 exporter 已包含在 Gateway Collector 的日志 pipeline 中:
yaml
`
1. service:
2. pipelines:
3. logs:
4. receivers: [otlp]
5. processors: [batch]
6. exporters: [routing/logs]
7. logs/otel:
8. receivers: [routing/logs]
9. processors: [batch]
10. exporters: [elasticsearch] # use default elasticsearch exporter
11. logs/ecs:
12. receivers: [routing/logs]
13. processors: [batch]
14. exporters: [elasticsearch/ecs] # use elasticsearch ecs exporters
`AI写代码结论
通过实施该架构,我们成功地过渡到 OTel 原生可观测性堆栈,同时保留了对基于 ECS 工具的投资。
我们使用 EDOT SDK 在源头关联日志和 traces,使用 EDOT Collector 处理"重工作"---集中发现、丰富和 schema 转换。这让我们兼得两者优势:OpenTelemetry 的现代灵活性和 ECS 的稳健结构。
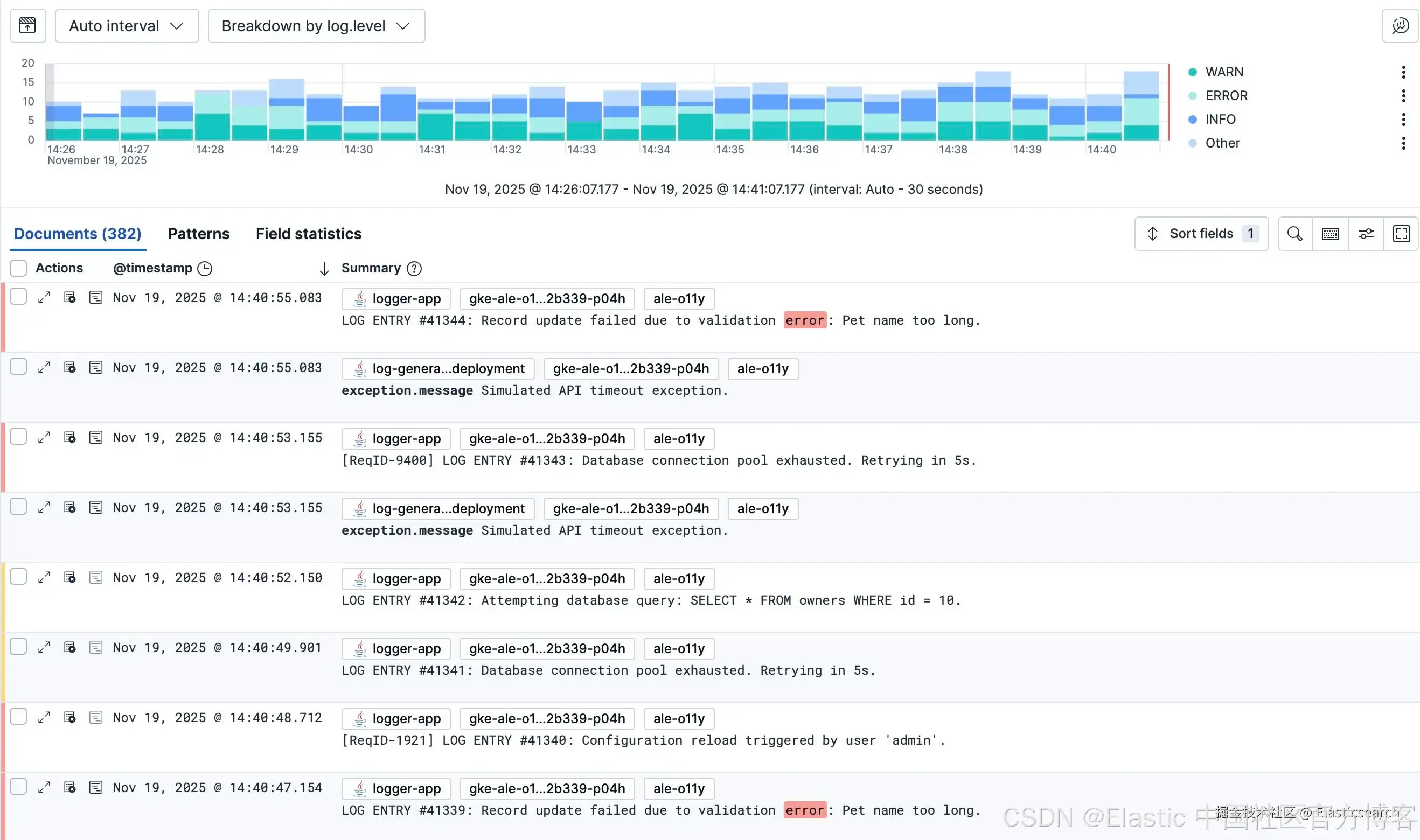
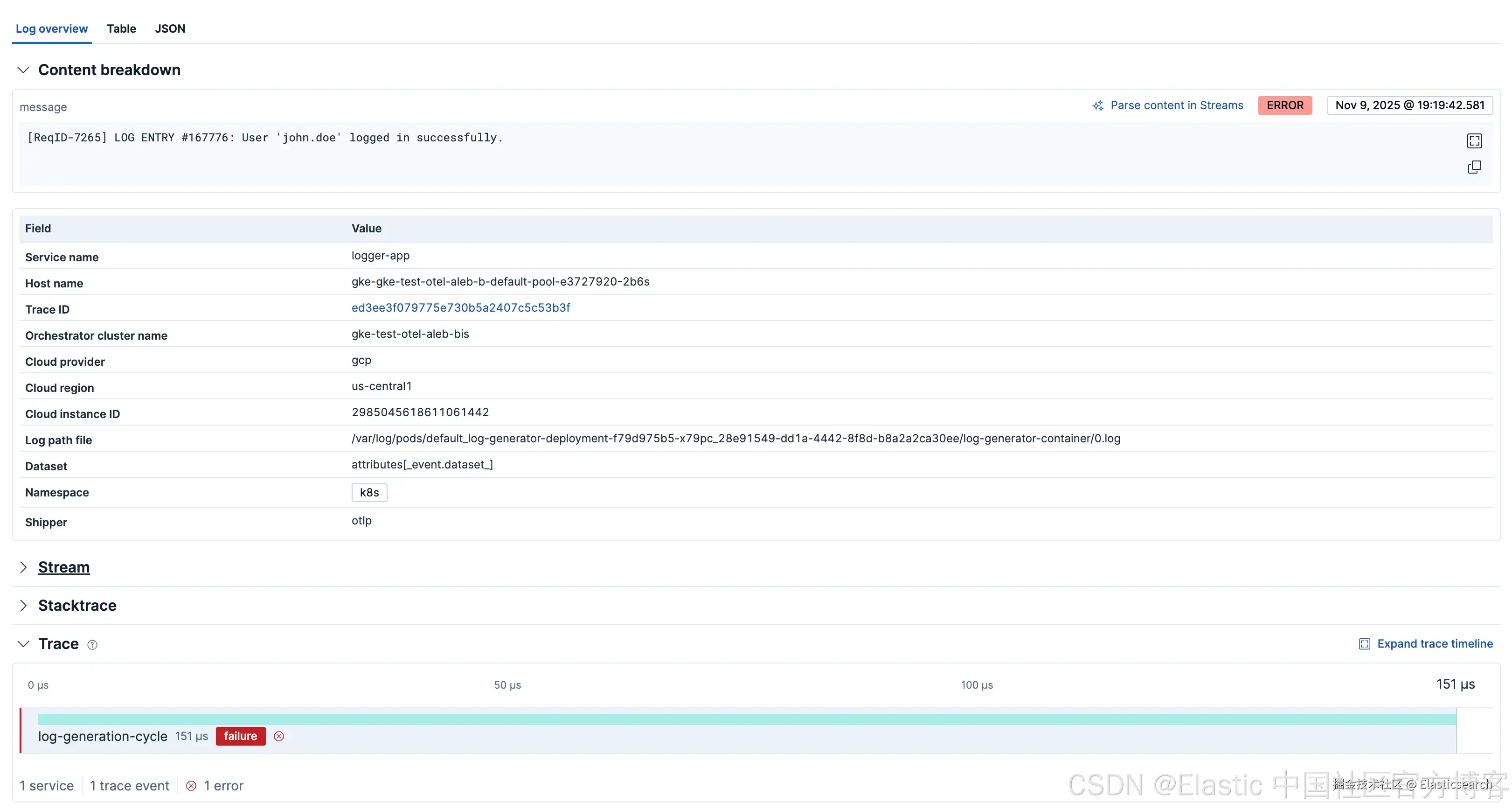
展望未来:迈向纯 OTel
OTel 原生架构的最大优势是 pipeline 的灵活性。由于我们之前使用 Transform Processor 将日志映射到 OTel(Log)Data Model,我们的数据在内部已经合规。
当你准备完全采用 OpenTelemetry 语义约定(SemConv)并摆脱 ECS 时,无需重写或重新部署应用程序。只需更新 Collector 停止路由到 ECS pipeline,并依赖默认的 OTel 原生导出即可。
这是通过使用默认的 elasticsearch exporter 配置实现的(其中 mapping: mode 设置为 otel):
markdown
`
1. gateway:
2. ...
3. config:
4. service:
5. pipelines:
6. metrics:
7. ...
8. logs:
9. receivers: [otlp]
10. processors: [batch]
11. exporters: [elasticsearch]
12. traces:
13. ...
`AI写代码总结
在本文中,我们演示了如何使用 Elastic Distribution of OpenTelemetry (EDOT) 过渡到 OTel 原生仪表化和采集架构。
我们采用了混合方法:建立了厂商中立的 OTel 可观测性堆栈(用于 traces、metrics 和 logs),同时保证与现有基于 ECS 的组件(如仪表板和 pipeline)完全向后兼容。
最后,我们展示了完整采集架构部署后,只需点击按钮即可部署完全兼容的 OTel 原生 collector,将日志以 SemConv 发送到 Elasticsearch 后端。该策略使团队能够平稳、定期地过渡到完全 OTel 就绪的环境而不产生中断。